
写文章




- @2301_80226956
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
认知科学与类脑计算 第二章 神经系统的生理学基础 模拟卷及答案
认知科学与类脑计算 第二章 神经系统的生理学基础 模拟卷及答案
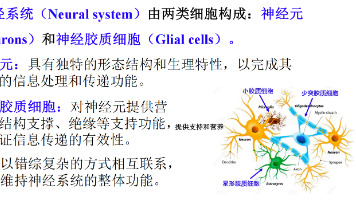
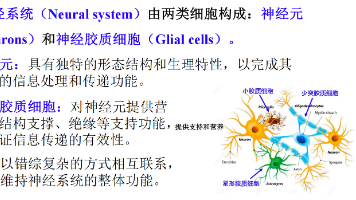
认知科学与类脑计算 第二章 神经系统的生理学基础 考点压缩
认知科学与类脑计算 第二章 神经系统的生理学基础 考点压缩
认知科学与类脑计算 第一章 背景介绍 模拟卷及答案
认知科学与类脑计算 第一章 背景介绍 模拟卷及答案
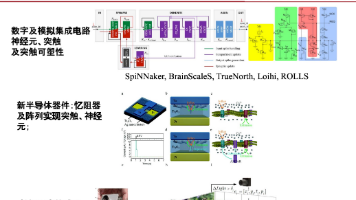
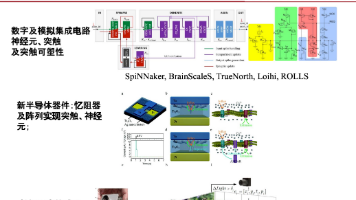
认知科学与类脑计算 第一章 背景介绍 考点压缩
认知科学与类脑计算 第一章 背景介绍 考点压缩
强化学习理论6 大语言模型(LLM)的强化学习
摘要:本文系统探讨了大语言模型(LLM)强化学习框架,重点解析了状态-动作-奖励三元组在文本生成中的映射关系,并提出三种改进算法:GRPO通过组内相对奖励替代价值网络,降低计算成本;DAPO采用不对称剪贴机制鼓励探索;GSPO将优化粒度细化到Token级别解决信用分配问题。研究揭示了传统PPO在LLM应用中的局限性,并通过蒙特卡洛采样、KL散度约束等技术创新,构建了更高效的文本生成优化体系,为资源
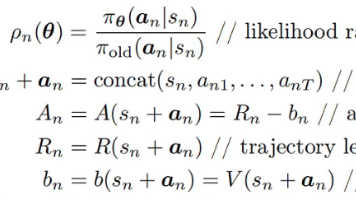
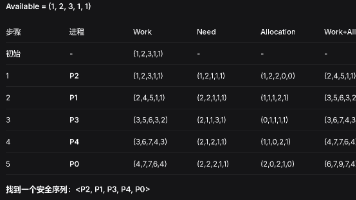
操作系统 AI 模拟试卷2及答案
操作系统 AI 模拟试卷1及答案
操作系统 AI 模拟试卷1及答案
操作系统 AI 模拟试卷1及答案
操作系统代码改错题专项练习(10题)
操作系统代码改错题专项练习(10题)
操作系统 填空专项练习(70题)
操作系统 填空专项练习(70题)

操作系统 单选专项练习(70题)
操作系统 单选专项练习(70题)
