- @2301_79516858
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
原子操作也让并发访问。Cryptography API 和Notifications API,只为一个特性定义了一个API。API 可以通过腻子脚本来模拟,但腻子脚本通常会带来性能问题,此外也会增加网站JavaScript 代码的。一些规范如HTML5,定义了一批增强已有标准的API 和浏览器特性。随着Web 浏览器能力的增加,其复杂性也在迅速增加。最终,是否使用这些比较新的API 还要看项目是支

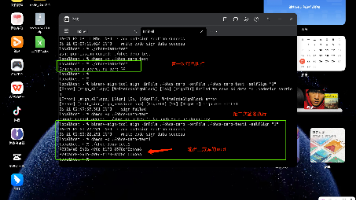
Rust通过类型系统强制线程安全:MutexGuard利用RAII自动解锁,避免手动解锁错误;编译器阻止不安全的线程共享(如Rc/RefCell),只允许Sync类型(如Arc/Mutex)。Atomic类型提供原子操作,但需注意事务完整性。展示死锁的哲学家就餐问题,说明即使语言安全,逻辑错误仍可能导致死锁。
Rayon是Rust的并行计算库,可将顺序任务轻松转为并行执行。它提供两种API:并行迭代器(par_iter/par_iter_mut)和join函数,前者用于数据并行,后者适用于分治算法。Rayon采用"work steal"策略高效分配任务,保证线程安全且性能优异。示例展示了数组平方和计算、快速排序等场景的并行实现,只需简单替换iter()为par_iter()或使用ra
React Native分页视图组件应用摘要 react-native-pager-view是一个跨平台分页组件,支持Android和iOS平台,提供流畅的页面切换体验。该组件基于原生模块封装,Android端使用ViewPager2,iOS端采用UIPageViewController。工程中通过两种方式集成:1)ArkTS版本需在buildCustomComponent中映射组件并添加Stac

本文介绍了一个基于华为鸿蒙操作系统与React Native集成的沙箱环境应用入口组件。项目包含两个演示:OpenHarmony侧推送文件到沙箱并加载,以及React Native侧加载沙箱中的图片。系统架构采用模块化设计,支持动态资源管理和沙箱环境运行,通过条件渲染和异步操作实现bundle文件的下载、验证和加载。项目实现了跨平台资源管理,确保文件在鸿蒙和React Native系统间无缝传递。

华为MateChat是一款专为AI生成内容(AIGC)场景设计的开源UI组件库,由华为DevUI团队开发。它提供完整的对话式交互组件,如消息气泡、输入框等,支持快速集成到React、Vue等主流框架中。具有轻量化、高扩展性特点,可自定义消息格式和主题样式,兼容OpenAI、Gemini等主流AI模型。该组件已应用于华为内部多个产品,如CodeArts、InsCode AI IDE等,帮助开发者高效
封装成Django标准校验器,可直接给/ Form字段使用# 邮箱校验器raise ValidationError("邮箱格式非法")# 手机号校验器raise ValidationError("手机号格式错误")# URL校验器raise ValidationError("网址格式错误")
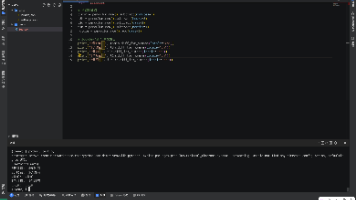
本文介绍了在开源鸿蒙PC社区搭建Python开发环境的方法,并详细讲解了Python的Arrow时间处理库。主要内容包括: 鸿蒙PC环境搭建:通过Harmonybrew安装适配版Python,使用ohos-pip-autosign解决签名限制,完成NumPy测试。 Arrow库详解: 解决了原生datetime繁琐的痛点 提供链式调用、智能时间操作等功能 支持时区转换、人性化时间显示 核心功能演示
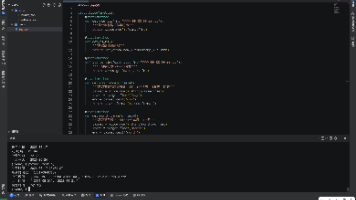
摘要 本文分为两部分:第一部分介绍在鸿蒙PC系统上搭建Python开发环境的完整流程,包括使用Harmonybrew包管理器安装Python、配置自动签名工具ohos-pip-autosign,以及通过NumPy测试环境;第二部分详细讲解Python轻量级数据校验库validators的使用方法。 validators库提供开箱即用的数据校验功能,支持邮箱、URL、IP、手机号、身份证等常见格式验
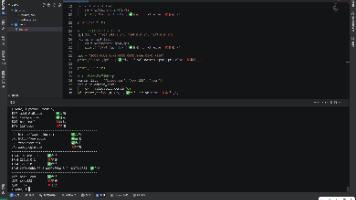
Windows 平台搭建 Rust 跨平台编译环境指南 本文详细介绍了在 Windows 系统上配置 Rust 开发环境并实现 OpenHarmony 鸿蒙系统交叉编译的完整流程。主要内容包括: 通过 rustup 工具一键安装 Rust 开发环境,自动配置 MSVC 编译工具链和 Windows SDK 依赖 验证 Rust 环境安装成功,检查 rustc、cargo 和 rustup 的版本信