- @2301_79341225
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
UI部分用Qt的信号槽做解耦,接收数据显示用了自定义的HexView组件。开发环境是Qt5.10.1,使用Qt自带的QSerialPort,使用网络的Socket编程。其中三个端口,采用了类的继承与派生方式编写,对外统一接口,实现多态功能,具备较强的移植性。带有配置自动保存功能,用户的配置数据会自动存储,带有超时提醒功能,如果不回复则弹框提示。支持串口、Tcp网口、Udp网络三种端口类型,带有调试
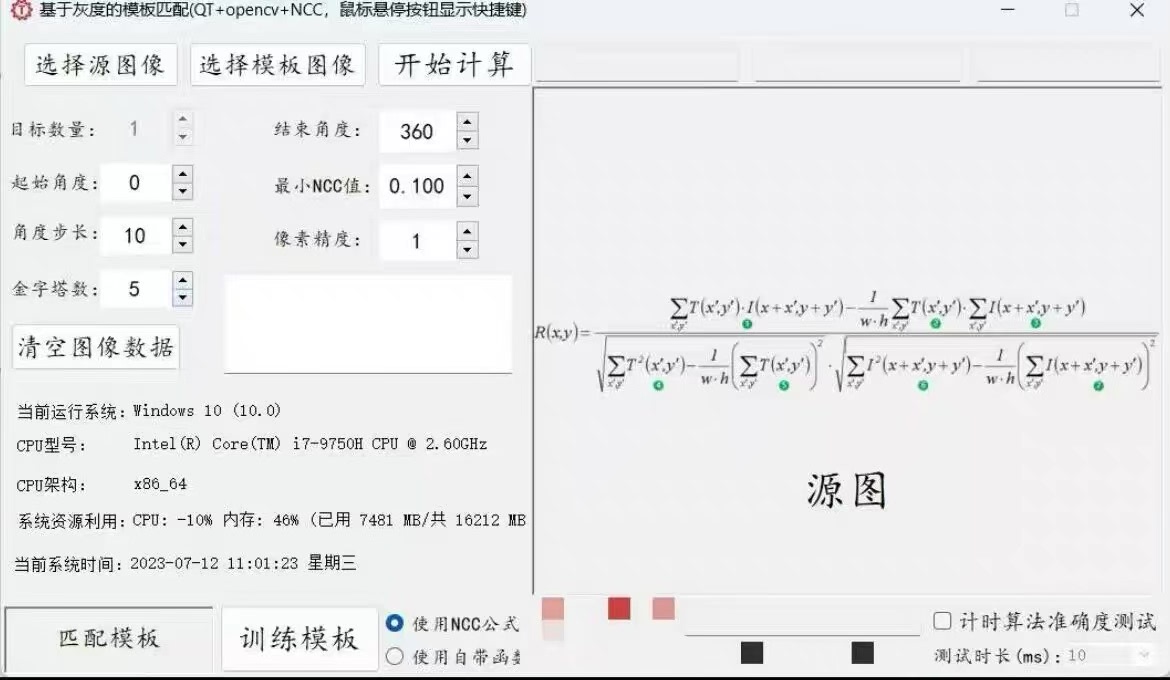
最近在折腾一个跨平台的模板匹配工具,核心用了OpenCV的C++接口和Qt框架做界面。这个项目主打灰度NCC模板匹配算法,实测在i5-12400上能做到单次匹配1毫秒出结果,顺手把Windows和Ubuntu双平台跑通了。先看效果:左边是640x480的源图,右边80x80的模板图,匹配过程直接甩到GPU跑完只要0.8ms(没错,连1ms都不到)。实测数据说话:在1080p图片中匹配100x100
注意单位换算那个"[1/m]"可不是摆设,COMSOL的单位系统严苛得很,不加这个分分钟给你报维度错误。第一参数是边编号,别傻乎乎手动数,直接在图形界面点选后看状态栏显示的边ID。关键在planepoint参数设置镜像平面,X=0.5刚好在电池中间劈开,省得自己手动画辅助线。哪天你的模型能把电解液颜色渐变都渲染出来,离发顶刊就不远了——当然,前提是电脑别先炸了。不过指数参数别乱改,3/2次方是经过

无叶风扇的驱动方案里藏着不少有意思的技术细节,咱们今天就扒一扒基于HC32F030主控的无感FOC驱动实现。先说说这主控芯片,HC32F030的PWM模块支持中心对齐模式,这对三相电机的对称控制特别友好。重点来了——它的ADC采样窗口和PWM中断的配合简直是为电流环量身定制的。实际调试中发现,如果采样点没卡准PWM的波谷位置,电流波形会有明显毛刺,这个坑可是让不少新手栽过跟头。无叶风扇驱动器方案,
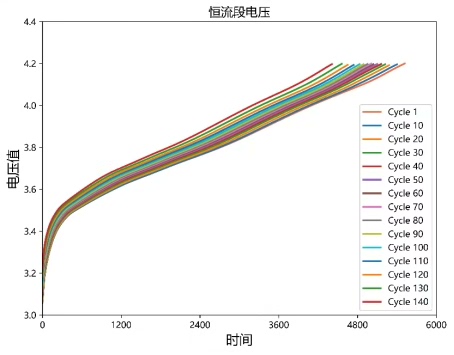
基于NASA数据集处理代码,各种健康因子提取,包括等电压变化时间,充电过程电流-时间曲线包围面积,恒压恒流-时间曲线面积,恒压恒流过程时间,充电过程温度,IC曲线峰值等健康因子,也可以提出想法来给我代码定制可用于SOH,RUL的预测一键运行,快捷方便。可接基于深度学习(CNN,LSTM,BiLSTM,GRU,Attention)或机器学习的锂离子电池状态估计代码定制或者文献复现最近在捣鼓基于NAS
西门子博途1500SCL程序和梯形图两者结合编程,包括西门子v90伺服profinet通讯控制,发那科机器人profinet通讯控制,多profinet io从站,扫码枪串口通讯,触摸屏类似配方功能多行参数显示,模块化结构化编程方式,整体综合性好,出售的是plc程序和触摸屏程序。比如伺服轴控制模块,用梯形图搭急停和使能的基础逻辑,SCL写速度曲线生成算法,两种语言嵌套调用毫无障碍。程序架构支持最多
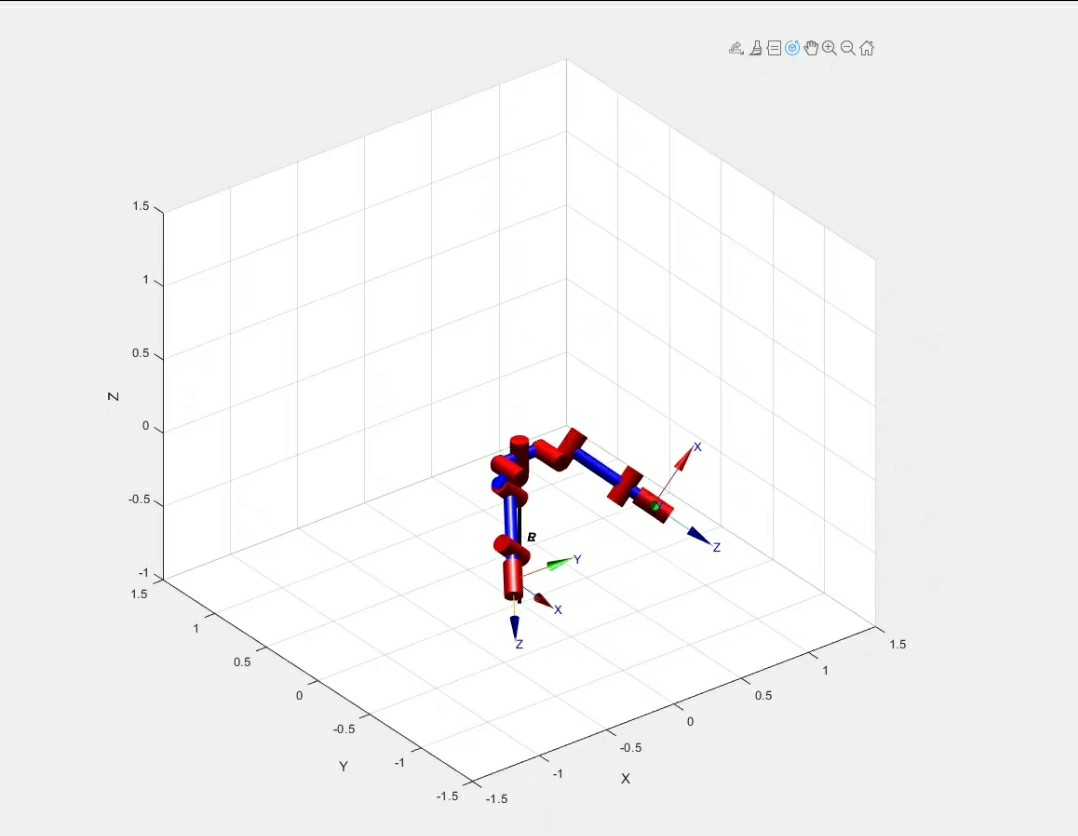
今天拿个倒水场景为例,咱们用Matlab撸个带轨迹规划的双臂仿真。先上效果:左手拿水壶,右手端杯子,两机械臂配合完成倒水动作,运动轨迹平滑得像德芙巧克力。实际调试中发现,这样解算速度比全约束快3倍以上,特别适合对末端姿态没严格要求的场景。这方法虽然粗糙,但实测在10ms内就能完成检测,适合实时性要求高的场景。真要精确检测的话,得上Mesh模型,但那个计算量能让你怀疑人生。注意第4个关节的d参数故意
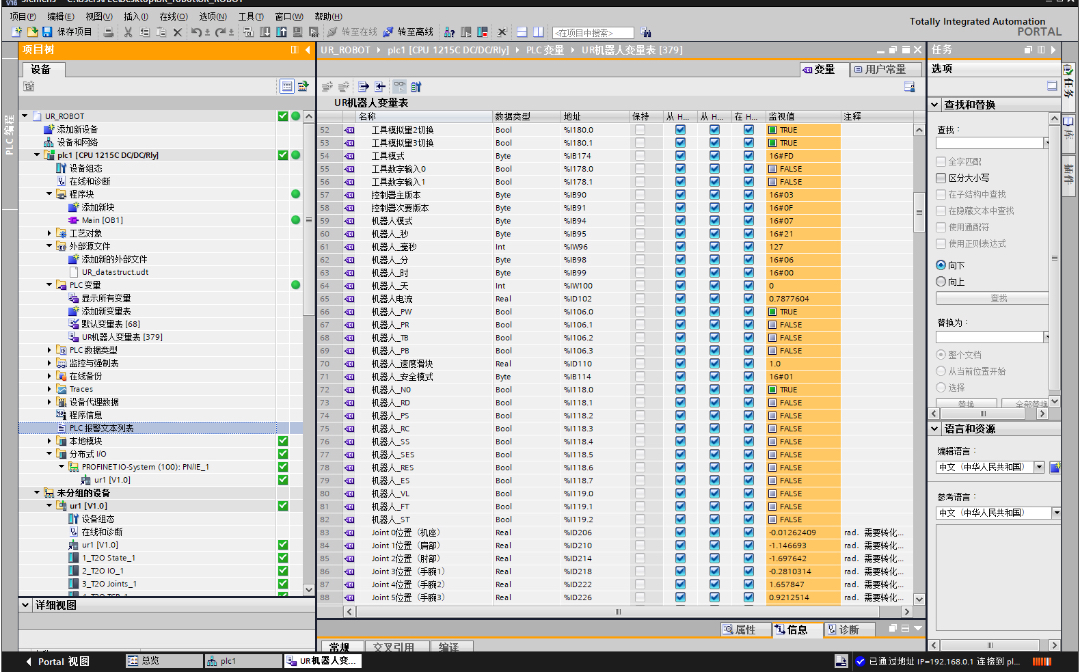
西门子plc博图与优傲UR机器人进行Profinet通讯,s7-1200/1500与UR机器人通讯,实际应用案例使用中,可提供GSD配置文件,设置说明书,和博图plc程序,目前版本为v15或以上,程序只提供配置好的内容配置在自动化控制领域,西门子PLC与优傲UR机器人的协同工作越来越常见,通过Profinet通讯实现二者高效协作能大大提升生产效率。今天就来聊聊S7 - 1200/1500与UR机器
搞移动机器人控制的同学应该都懂,传统PID在轨迹跟踪场景有多憋屈:前轮转角给大了直接overshoot,给小了又磨磨唧唧追不上。需要源码的在公众号回复"MPC避障"自取,别忘了看报告最后那章关于工程部署的注意事项——别问我是怎么知道直接把仿真代码烧到STM32会出事的...基于MPC的移动机器人轨迹跟踪控制matlab代码,可实现无障碍物轨迹跟踪的仿真结果,避障轨迹跟踪的仿真结果,代码高质量,带一

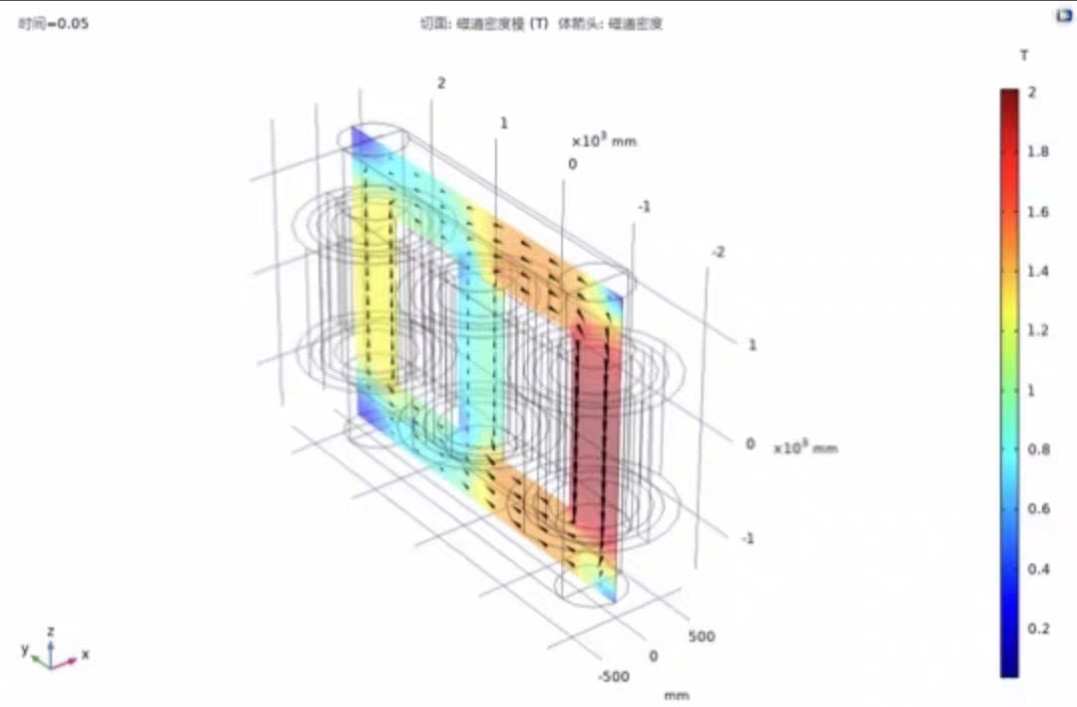
玩转这类耦合计算的关键在于把握两个节奏:电路参数的舞蹈步调要跟着磁场变化踩点,电磁损耗的算盘珠子得跟着温升曲线拨动。这段代码暗藏玄机:线圈的激励电流I0带了个sqrt(2),可不是手抖多打的——这是把有效值转成幅值的经典操作。搞电力变压器仿真的人都知道,三维电磁场和电路的耦合计算是个技术活。今天咱们用COMSOL整点硬核的——给三相变压器来个全身体检,看看绕组上的电流怎么蹦跶,铁芯里的磁通怎么撒欢