How LLM Works 大语言模型是如何工作的
摘要:本文系统介绍了大语言模型的训练过程,重点对比了基础补全模型与生成式模型(如ChatGPT)的区别。模型训练分为三个关键阶段:1)预训练阶段建立基础模型,通过Transformer架构处理海量互联网数据;2)微调阶段使用人工标注的对话数据训练模型生成类人回复;3)强化学习阶段通过人类反馈优化输出准确性。文章以解释登月为例,展示了RLHF优化后模型输出的显著改进。最后指出用户反馈数据为模型持续优
1.一个补全模型的工作原理如下:
用户的问题是:
香蕉是
香蕉是
2.一个生成模型的工作原理如下:

用户的问题是:
我想买一个新的汽车
你想买什么车?
注意以上两者之间的区别。
第一个模型只是一个补全器,它只会根据找到的最有可能成为下一个字符的内容来补全提示词。这是我们在大量互联网数据上训练的模型,被称为基础模型。
第二种模型是生成器,它会根据提示问题生成更像人类回复的内容。这就是ChatGPT模型。
ChatGPT模型是一种推理模型,它可以根据提示问题生成回复。我认为它99%是基础模型,但多了两个额外的训练步骤:一个微调步骤和一个基于人类反馈的强化学习步骤。
模型训练第一步:预训练:基础模型(## Pre-training: Base Model)
这构成了人工智能革命的核心,也是真正神奇之处所在。训练模型是一个向其输入大量数据并让它从中学习的过程。正如《GPT-3论文》中所述,基础模型是在大量互联网数据上进行训练的。对于像你我这样的普通人来说,这并非易事。它不仅需要获取数据,还需要大量诸如GPU和TPU之类的计算能力。
不过别担心,我们仍然可以学习在自己的电脑上训练一个小型GPT模型。在下一个主题中,我将向你展示如何做到这一点。
大语言模型训练背后的创新之处在于引入了Transformer架构,该架构使模型能够从海量数据中学习,同时保留输入不同部分之间的关键上下文关系。
通过维持这些联系,该模型能够基于所提供的上下文,无论是单个单词、句子、段落或更复杂的内容,有效地推断出新的见解。凭借这种能力,大语言模型训练为自然语言处理和生成任务开辟了新的机遇,使机器能够更好地理解并回应人类的交流。
用于训练基础模型的Transformer架构如下所示:
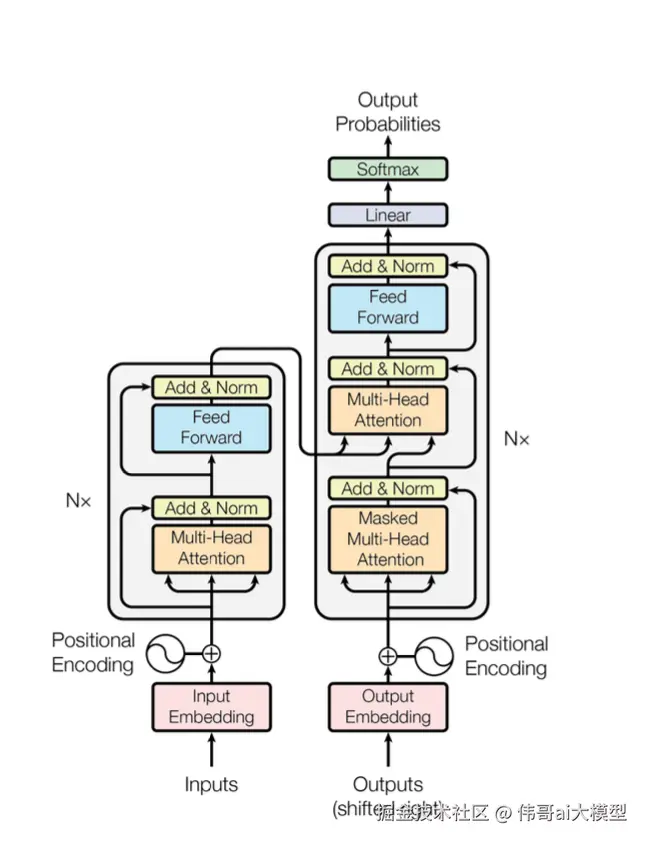
这是一个基于神经网络的模型训练,采用了一些新旧技术:tokenization、embedding、position encoding、feed-forward、normalization、softmax、linear transformation,最重要的是,multi-head attention。
这部分内容是你我都最感兴趣的。我们想要清楚地了解该架构背后的理念,以及具体是如何进行训练的。因此,从下一个主题开始,我们将深入研究用于训练基础模型的论文、代码和数学原理。
这部分出来的代码效果是补全式的模型 用户问:我今天想去游乐园玩
模型输出情况一:我今天想去游乐园玩大风车 模型输出情况二:我今天想去游乐园玩过山车
但是你在训练数据中给模型的数据应该是 1.某某去游乐园玩过山车 2.我妈妈和某某去游乐园玩大风车 3.我爸爸和某某去游乐园玩大风车 4.小妹去游乐园玩过山车
只是因为你给模型训练数据中去游乐园玩的内容不一样,且数据中内容多的部分在模型整体参数中占比比较大,少的部分占比比较少。 如果当你询问模型时,它根据你的输入在它的模型参数数据中匹配合适的(一般是概率最高的,参数可以控制)内容。这是模型只会补全你的内容。
微调 (Fine-tuning: Train the Assistant )
微调是一种非常巧妙的实现方式。我猜它最早是由OpenAI完成的。这个想法极其简单,但却十分巧妙地发挥了作用:聘请人类标注员创建大量问答对话对(比如10万个对话)。然后将这些对话对输入模型,让模型从中学习。
这个过程被称为微调。你知道将10万个样本对话输入模型进行训练后会发生什么吗?模型将开始像人类一样做出回应!
让我们来看一下那些带标注的示例对话: 问:你叫什么名字? 答:我叫伟哥 问:中国的首都是哪里? 答:中国的首都是北京。
这些问答示例在模仿我们彼此交谈的方式。
通过向模型传授这些回复风格,相关上下文回复的概率将变得非常高,并成为对用户提示的回应。通过以各种对话风格训练模型,我们提高了它针对提示提供相关且符合上下文的回复的可能性。
这就是语言模型看起来如此智能且像人类的原因;通过学习模仿现实世界对话的节奏和模式,它们能够令人信服地模拟与用户之间的来回对话。在这一步,我们可以说我们得到了一个助手模型。
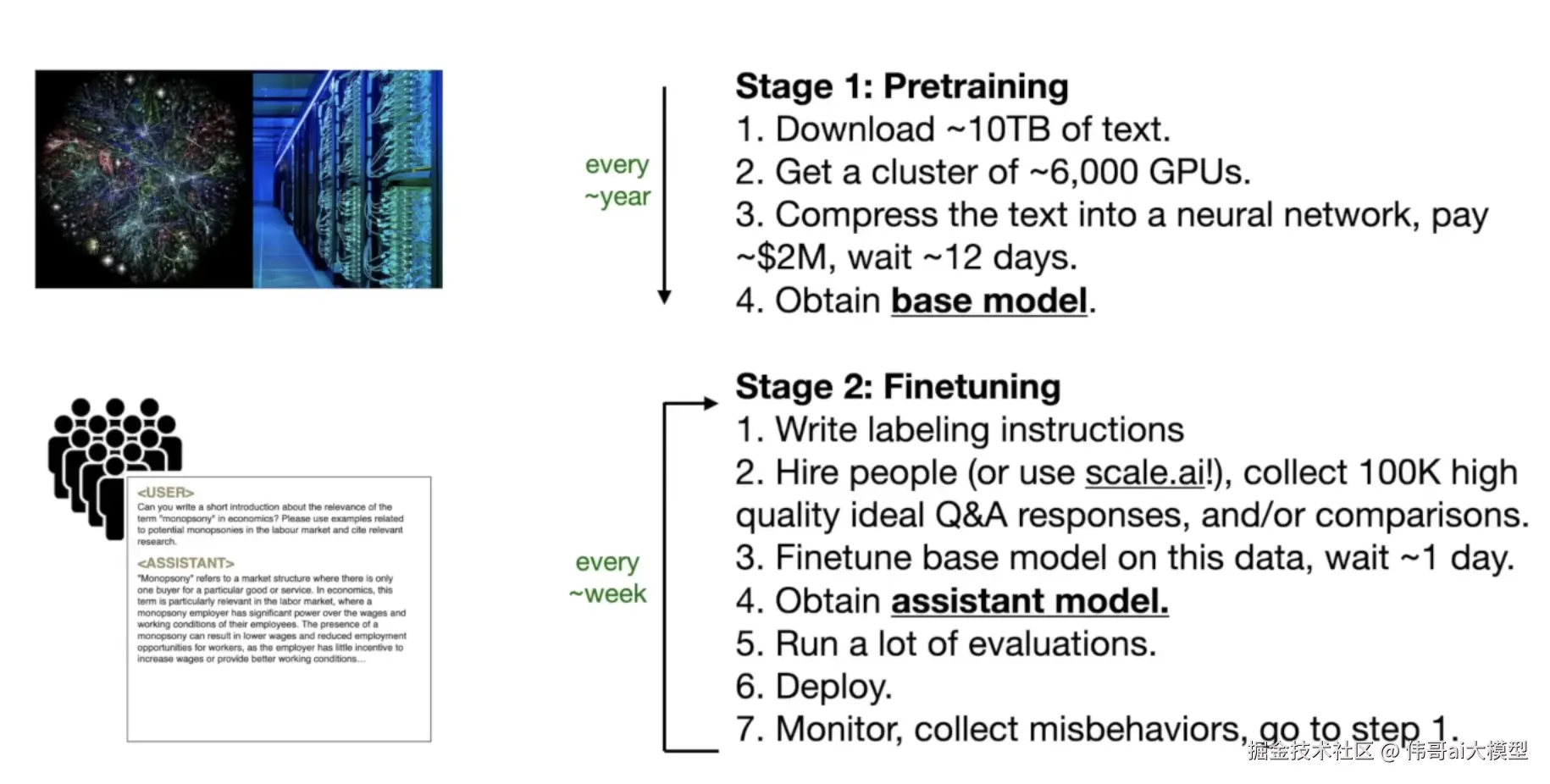
以下是一张图表,展示了从基础模型预训练到助手模型微调的一些要点:
强化学习从人类反馈中学习(RLHF:Reinforcement Learning from Human Feedback)
强化学习是为了让模型的输出更加精确。 比如模型可能对你的生活习惯并不清楚,如果在你询问你的生活安排时,它的回答可能是其他人的生活习惯。甚至是动物的生活习惯。那么你可以通过积极或者消极的反馈给模型,模型相当于接受当了比微调更加精确的训练数据,可以修改它的参数,这样在下次询问时可能就会更加接近你的答案。
为什么是可能会,而不是一定会。我们在使用各大厂家的模型聊天时,都会看到点赞和点踩赞的图标。这就是模型的设计者在征求使用者的使用信息。但是这个信息不会立马反馈给模型。只是暂时的保存。需要训练时将这些数据给模型。这就是强化学习。
2022年1月,OpenAI发表了关于《使语言模型遵循指令》的研究成果。在其博客文章中,他们阐述了如何利用人类反馈对模型进行进一步微调:
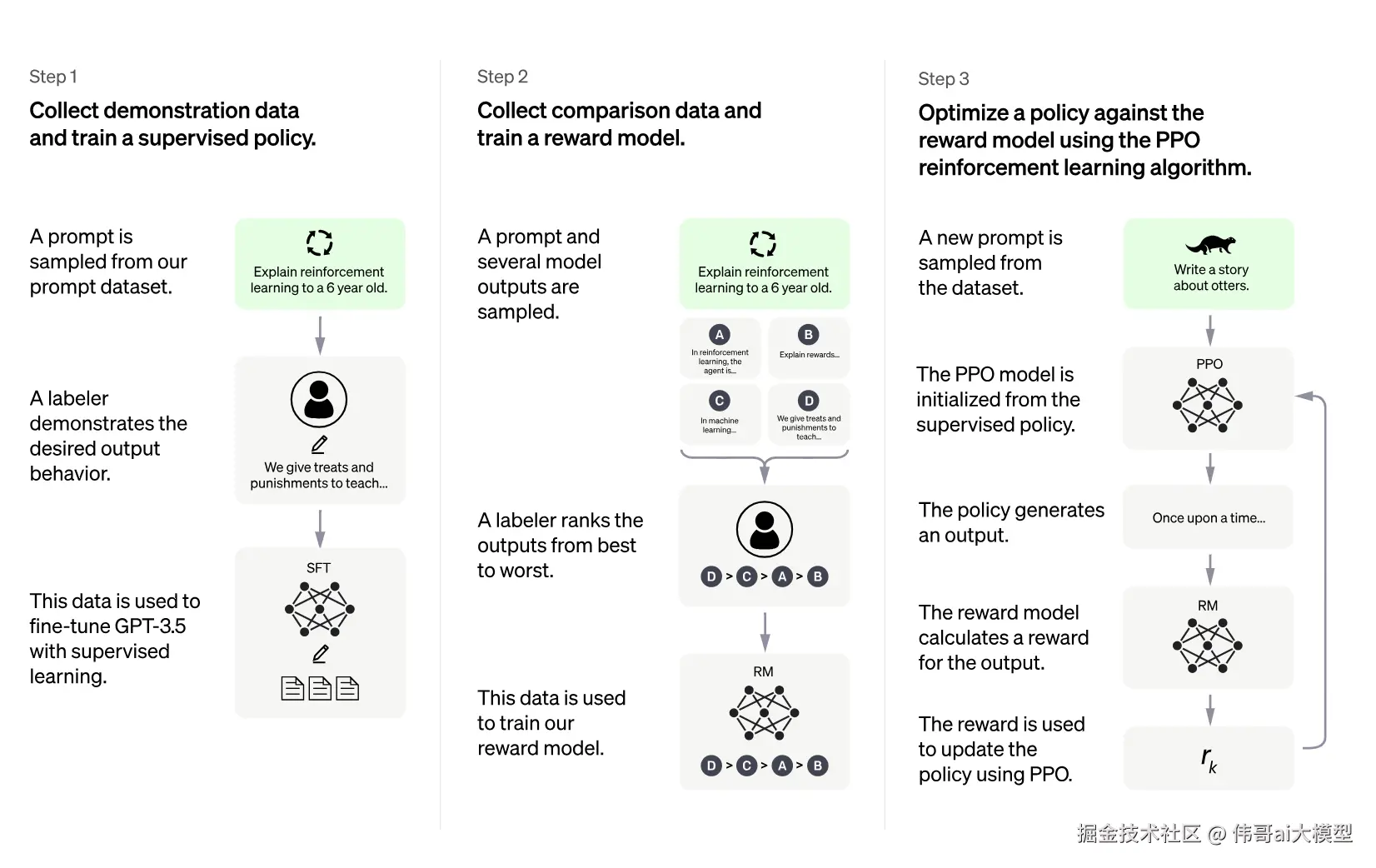
思路是让模型从人类反馈中学习。他们没有提供约10万个带标注的问答对,而是收集用户的提示和模型的回复,然后让人类对它们进行排序。将排序后的对话作为最理想的问答样本,然后再次将它们输入模型,让模型从中学习以提升整体性能。
以下是基础模型与微调/基于人类反馈的强化学习(RLHF)响应的对比:
| prompt: 提示: | Explain the moon landing to a 6 year old in a few sentences.用几句话向一个6岁的孩子解释登月是怎么回事。 |
|---|---|
Base |
Explain the theory of gravity to a 6 year old.向一个6岁的孩子解释万有引力理论。 |
| Explain the theory of relativity to a 6 year old in a few sentences.用几句话向一个6岁的孩子解释相对论。 | |
| Explain the big bang theory to a 6 year old.向一个6岁的孩子解释大爆炸理论。 | |
| Explain evolution to a 6 year old.向一个6岁的孩子解释进化论。 | |
Fine-tuned/RLHF |
People went to the moon, and they took pictures of what they saw, and sent them back to the earth so we could all see them.人们登上了月球,拍摄了他们所看到的景象,并将照片传回地球,这样我们所有人都能看到。 |
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 下方小卡片领取🆓↓↓↓

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)