LMDeploy全面升级,FP8、MXFP4一网打尽,推理性能再创新高!
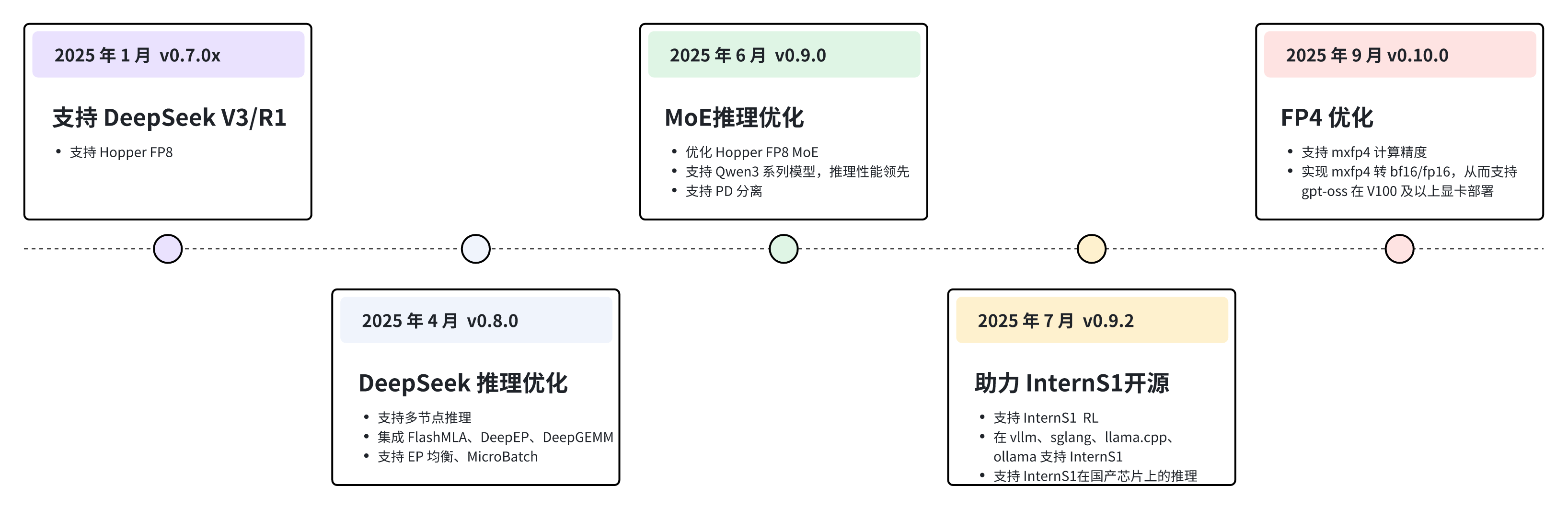
9 月 9 日,上海人工智能实验室(上海AI实验室)大模型推理部署工具 LMDeploy 迎来重磅更新——v0.10.0版本正式发布,进一步为社区提供更高效、更稳定、可扩展的推理部署方案。今年以来,LMDeploy 已持续迭代多个版本,实现了等一系列关键突破。:LMDeploy 新增对多机部署的全面支持,显著提升超大规模模型的推理效率。该能力已成功应用于 DeepSeek 大模型的分布式推理场景,
9 月 9 日,上海人工智能实验室(上海AI实验室)大模型推理部署工具 LMDeploy 迎来重磅更新——v0.10.0版本正式发布,进一步为社区提供更高效、更稳定、可扩展的推理部署方案。
今年以来,LMDeploy 已持续迭代多个版本,实现了多机扩展、推理加速、强化学习集成、国产化适配等一系列关键突破。
亮点速览:
-
拓展多机多卡分布式推理能力:LMDeploy 新增对多机部署的全面支持,显著提升超大规模模型的推理效率。该能力已成功应用于 DeepSeek 大模型的分布式推理场景,并与 DeepLink、Mooncake等团队深度合作,实现了 PD 分离部署。
-
推理性能持续升级:TurboMind 核心引擎在多方面实现重大提升,包括优化卡间通信、高效支持 MoE 模型结构、全面引入 FP8 和 FP4 量化计算,显著降低显存占用并提升计算效率,使推理性能实现质的飞跃。TurboMind 致力于英伟达显卡架构上的推理优化,全面支持从 V100(含)以来所有版本的英伟达显卡架构(除B200),包括 Jetson 边缘侧设备。
-
集成至 Intern-S1 强化学习训练框架:LMDeploy 已作为推理基座,集成到 Intern-S1 的强化学习(RL)系统中,能够持续且稳定运行在 256 卡的集群环境中,为模型的训练与推理提供高效支撑,极大助力 Intern-S1 大模型的研发进程。
-
推进大模型推理国产化适配:LMDeploy 与 DeepLink-dlinfer 团队一起积极适配国产软硬件生态,支持多种国产 AI 加速卡及操作系统,包括华为昇腾、沐曦、寒武纪等,助力实现大模型技术全栈自主可控。
GitHub 主页:
https://github.com/InternLM/lmdeploy
官方文档:
https://lmdeploy.readthedocs.io/
dlinfer:
https://github.com/DeepLink-org/dlinfer
MoE FP8 扬帆起航
研究团队自上半年起,围绕 H800 (Hopper) 架构展开开发与优化工作,重点对 MoE 模型与 FP8 计算精度进行了深入适配与优化。 为全面评测 LMDeploy 在 H800 上的推理性能,研究团队在参考多方测试数据的基础上,设计了以下 4 种典型测试场景:
ShareGPT 短输入输出
使用 ShareGPT 中的短对话样本作为测试基准,ShareGPT 已被各类推理框架广泛采用,成为公认的标准性能评测数据集。
固定输入、输出各 1K token
采用被 PyTorch CI HUD vLLM benchmark、SGLang benchmark 和 TensorRT-LLM benchmark 普遍使用的参数配置,以便在固定条件下进行性能对比。
长思考场景
随着强化学习技术的发展,模型思考能力显著提升。随之而来的是,模型在生成阶段的算力消耗显著增加。根据 DeepSeek 报告,“平均每输出一个 token 的 KVCache 长度是 4989”,接近 5000 token。为模拟该类场景,团队设置输入 2000 token、输出 6000 token,用以评估模型在长思考场景下的推理性能。
长输入场景
基于“长思考场景”,将输入与输出互换,设置输入 6000 token、输出 2000 token,以模拟长输入场景对推理性能的影响。
基于 Qwen3-235B-A22B-FP8 模型,研究团队在 H800 上分别测试了 LMDeploy、vLLM、SGLang 在上述 4 种场景下的推理性能。实验结果显示,LMDeploy 的 token 输入输出吞吐量约是 vLLM 的 1.2~1.4 倍,居于领先地位。详细的测试方法和结果请参考 https://github.com/lvhan028/llm_benchmark
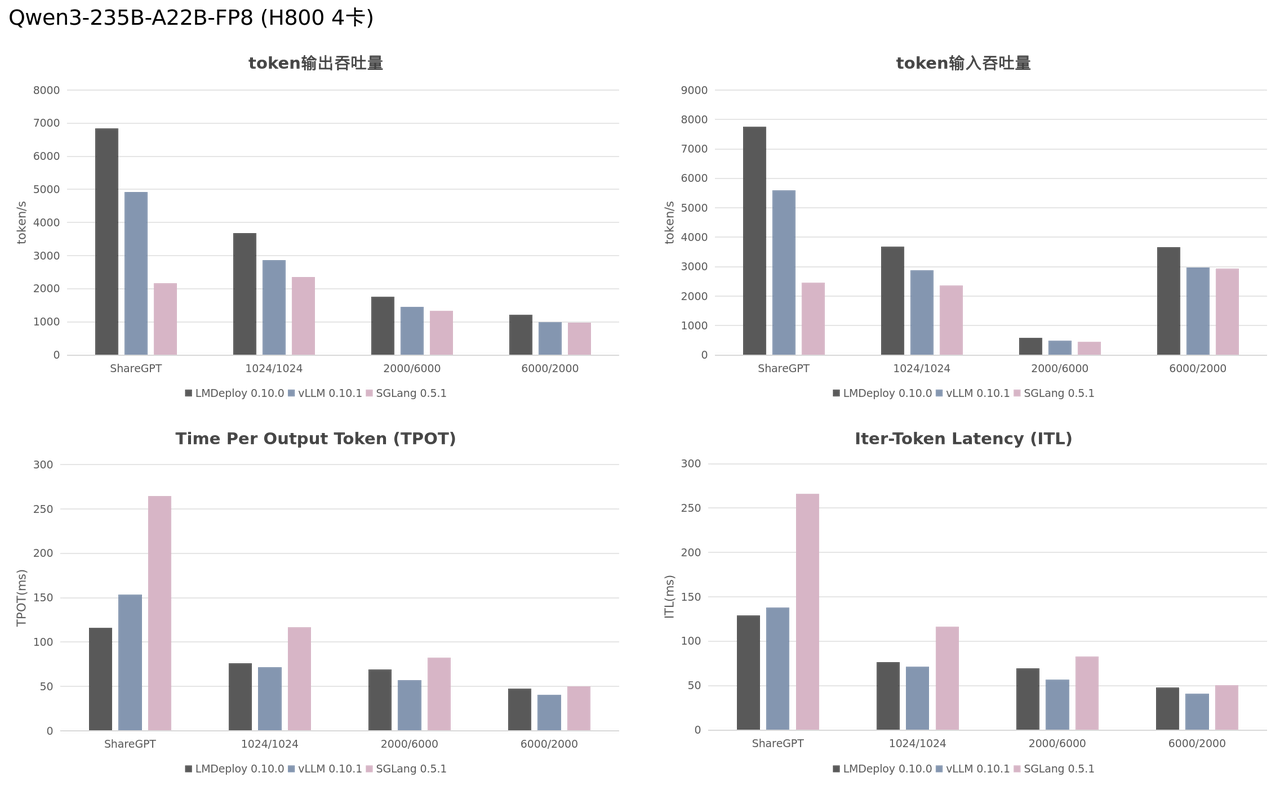
说明:
-
在对 vLLM 和 SGLang 进行 benchmark 测试时,研究团队使用的是各推理框架默认的参数。
-
在使用 SGLang 推理 MoE-FP8 模型时,研究团队遇到 “Using default MoE kernel config. Performance might be sub-optimal! Config file not found” 的告警。尝试使用 tuning 脚本调优参数,但是脚本执行失败。
-
LMDeploy 服务开启 --enable-metrics,与其他框架保持一致。同时也开启了通信优化选项 --communicator cuda-ipc。
MoE FP4 破界前行
近日,OpenAI 发布了其首个采用 MXFP4 格式的开源模型 GPT-OSS。该模型现已丝滑嵌入至 LMDeploy 的量化 Gemm Pipeline 中,能够部署在 V100 及其以上的显卡上。通过对 MXFP4 格式的支持,LMDeploy 进一步增强了大模型低精度推理的能力,不仅显著提升了性能效率,也为未来支持更多不同 bit 位宽的模型奠定了坚实的技术基础。

研究团队在 H800 和 A100 显卡上,对 LMDeploy 和 vLLM 在 GPT-OSS 模型上的推理性能进行了对比测试。实验结果表明,LMDeploy 在所有测试场景下均显著优于 vLLM。
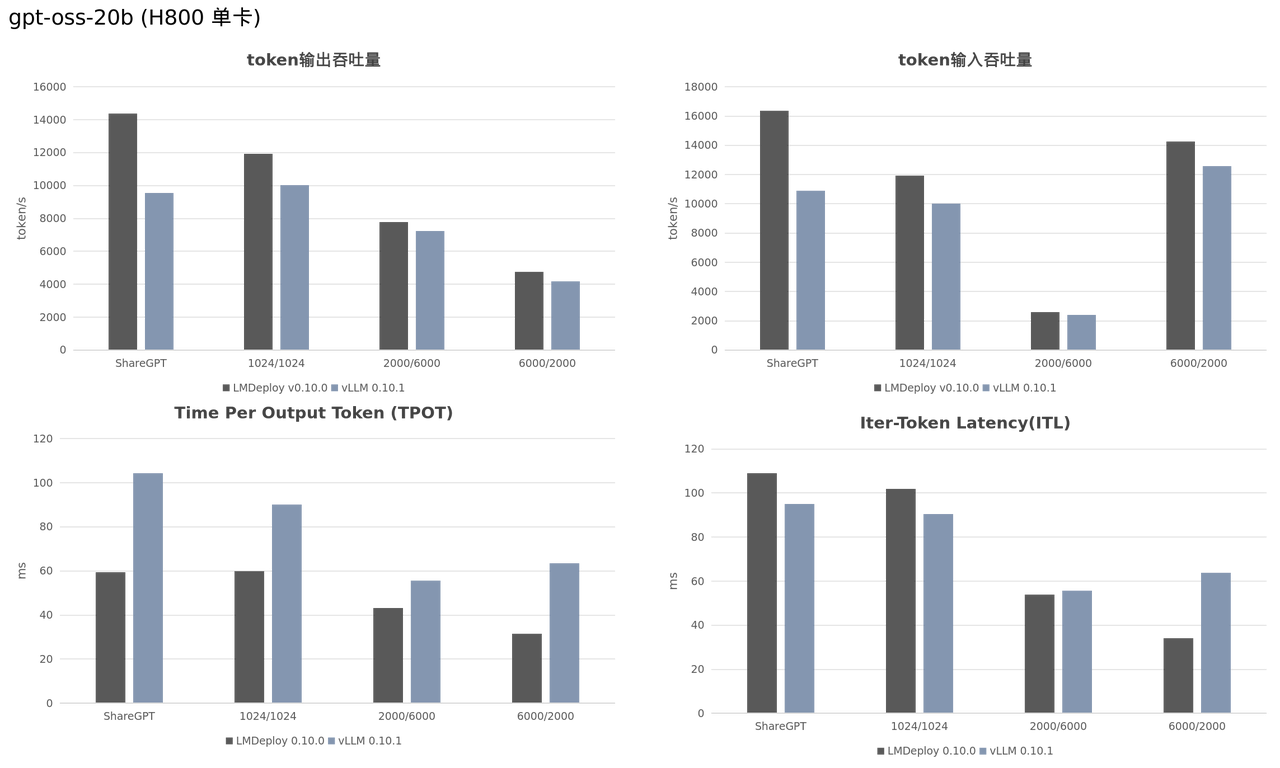
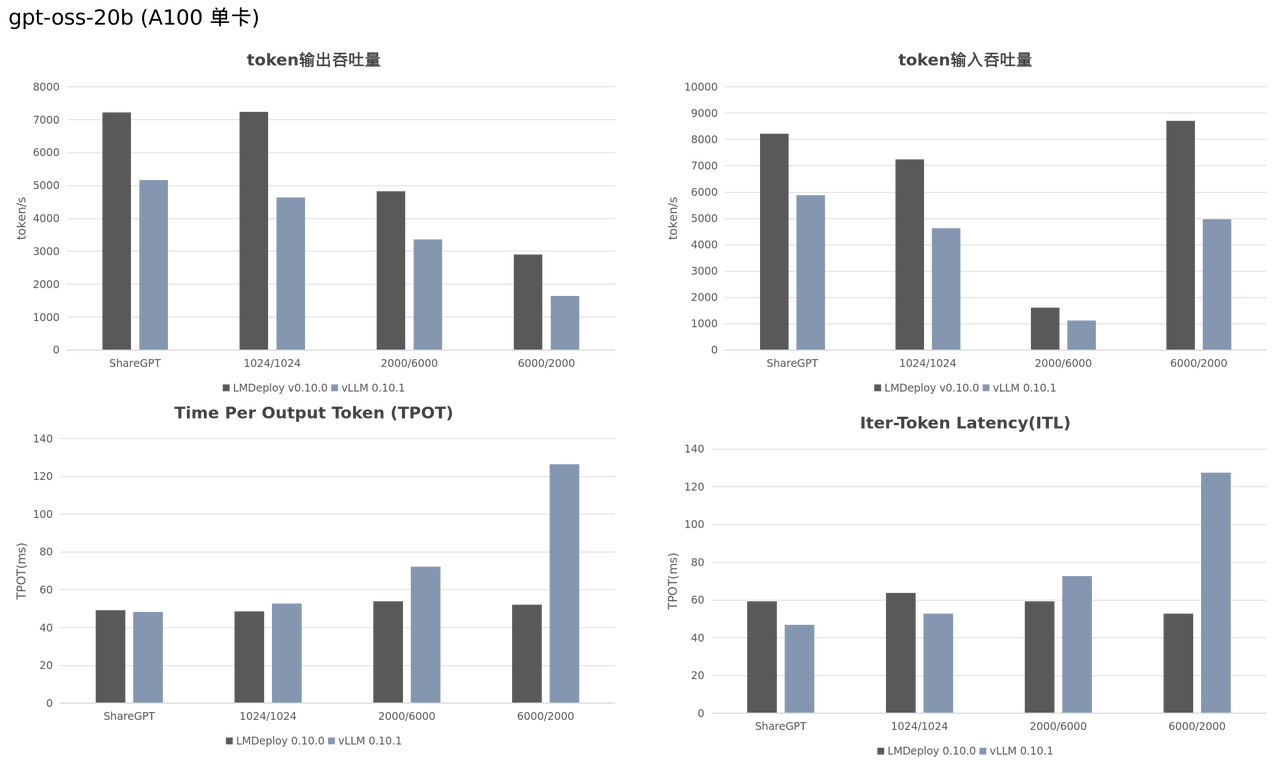
说明:SGLang v0.5.1 无法顺利测完上述 4 种场景,暂不进行对比
通信优化不遑多让
除了计算优化上的深耕,研究团队还深入探究了单节点上卡间通信。通过对通信的优化,以及通信和计算的融合,进一步放大推理效率。在使用 lmdeploy serve api_server 命令部署多卡服务时,增加选项 --communicator cuda-ipc 即可启动此特性。在张量并行(8张H800显卡)时,大约能带来 10+% 的性能提升。以下为 LMDeploy 在 H800 上部署 Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8 模型的实测性能:
|
RPS |
token吞吐量(token/s) |
TPOT (ms) |
ITL (ms) |
|
|
nccl |
19.40 |
3840.49 |
82.30 |
82.94 |
|
cuda-ipc |
21.55(+11.08%) |
4266.21(+11.09%) |
75.31(-9.48%) |
75.68(-8.75%) |
说明:测试场景为 ShareGPT 短输入输出场景
NV 设备支持广泛
在完成 H800 (Hopper) 架构上的开发与优化工作后,研究团队于 7 月份基于 5080 显卡开始探索 Blackwell (sm120)架构上的优化方法。至此,除去因众所周知的原因暂未覆盖 B200 显卡外,LMDeploy 已全面支持从 V100(含)以来所有版本的英伟达显卡架构,包括 Jetson 边缘侧设备,成为开源社区中对英伟达硬件架构支持最全面的大模型推理框架。硬件与计算精度功能矩阵如下:
| 架构 | 计算能力(CC) | 设备 | BF16 | FP16 | FP8 | FP4 | INT8 | INT4 | KV INT8/4 |
| Blackwell | 12 | GeForce RTX 50系列 | 😄 | 😄 | 🙁 | 😄 | 😄 | 😄 | 😄 |
| Hopper | 9 | H200, H100 | 😄 | 😄 | 😄 | 😄 | 😄 | 😄 | 😄 |
| Ada Lovelace | 8.9 | GeForce RTX 40系列L40S, L40/20/4/2 | 😄 | 😄 | 🙁 | 😄 | 😄 | 😄 | 😄 |
| Ampere | 8.7 | Jetson Orin 系列 | 😄 | 😄 | 🙁 | 😄 | 😄 | 😄 | 😄 |
| 8.6 | GeForce RTX 30系列A40/16/20/2 | 😄 | 😄 | 🙁 | 😄 | 😄 | 😄 | 😄 | |
| 8 | A100, A30 | 😄 | 😄 | 🙁 | 😄 | 😄 | 😄 | 😄 | |
| Turing | 7.5 | GeForce RTX 20系列GeForce GTX 1660/1650T4 | 😄 | 😄 | 🙁 | 😄 | 😄 | 😄 | 😄 |
| Volta | 7.2 | Jetson Xavier 系列 | 😄 | 😄 | 🙁 | 😄 | 😄 | 😄 | 😄 |
| 7 | TITAN V, V100 | 😄 | 😄 | 🙁 | 😄 | 😄 | 😄 | 😄 |
书生大模型工具链研发团队将持续开源 LMDeploy 相关工作,希望为学术界与工业界提供高效、稳定、可扩展的推理部署解决方案,丰富开源社区的推理部署工具生态,为大模型研发和应用提供坚实易用的基础设施。
未来,在研究范式创新及模型能力提升的基础上,上海AI实验室将持续推进书生大模型及其全链条工具体系的开源,支持免费商用,同时提供线上开放服务,与各界共同拥抱更广阔的开源生态,共促大模型产业繁荣。

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)