一、Spark专栏开篇:它从何而来,为何而生,凭何而强?
Spark可以看作是Hadoop MapReduce的“高速升级版”。它最大的优势是把计算数据都放在内存里,速度飞快,解决了MapReduce频繁读写硬盘的慢问题。它本身也是个全能平台,自带SQL、实时处理等多种功能。现实中它常和Hadoop搭档:Hadoop负责存数据,Spark负责跑计算。
在大数据的世界里,如果说 Hadoop 是一位力大无穷但步履稳健的巨人,那么 Apache Spark 就是一位身手敏捷、快如闪电的超级英雄。凭借其惊人的速度、一专多能的本领和简单易用的操作,Spark 迅速成为了处理海量数据的明星工具,让以前不敢想的数据分析变得轻而易举。
一、Spark 的诞生记
Spark 的诞生故事,源于一群聪明的科学家对Hadoop MapReduce某些“慢性子”的不满。
-
起源 (2009年):故事开始于加州大学伯克利分校的一个实验室。研究人员发现,Hadoop MapReduce 处理一次性的大批量数据很在行,但每次计算的中间结果都必须费力地存到硬盘 (HDFS) 上,然后再读出来进行下一步计算。这就像做一道菜,每切完一种食材都要放回冰箱,再拿出来切下一种,效率极低。对于需要反复计算的机器学习或需要快速反馈的交互式查询来说,这种基于磁盘的方式太慢了。
-
诞生与开源 (2010-2013年):为了解决这个问题,他们想出了一个绝妙的主意:让数据尽可能地待在内存里! 他们发明了一种叫做“弹性分布式数据集” (RDD) 的东西,它就像一个智能的、分布在多台机器内存中的大表格。这样一来,多步骤的计算就可以在内存中“一条龙”完成,速度自然就快得飞起。这个新项目就是Spark。 2013年,Spark 被捐赠给Apache软件基金会,正式走向世界。
-
一鸣惊人与生态繁荣 (2014年至今):2014年,Spark 在一次大数据排序比赛中,以绝对优势击败了Hadoop MapReduce,一战成名。自此,Spark 一路高歌猛进,不断进化。它引入了更高级、更智能的 DataFrame 和 DataSet API,让处理结构化数据变得像操作电子表格一样简单,并且性能越来越好,功能也越来越完善。

二、Spark vs Hadoop
首先要澄清一个误解:Spark 通常不是要干掉整个Hadoop,而是取代Hadoop中那个叫做 MapReduce 的“慢速引擎”。在现实世界中,它们常常是好搭档:Hadoop的HDFS负责像仓库一样存储海量数据,YARN负责像工头一样分配工作资源,而Spark则作为超级计算引擎在上面飞速地完成计算任务。
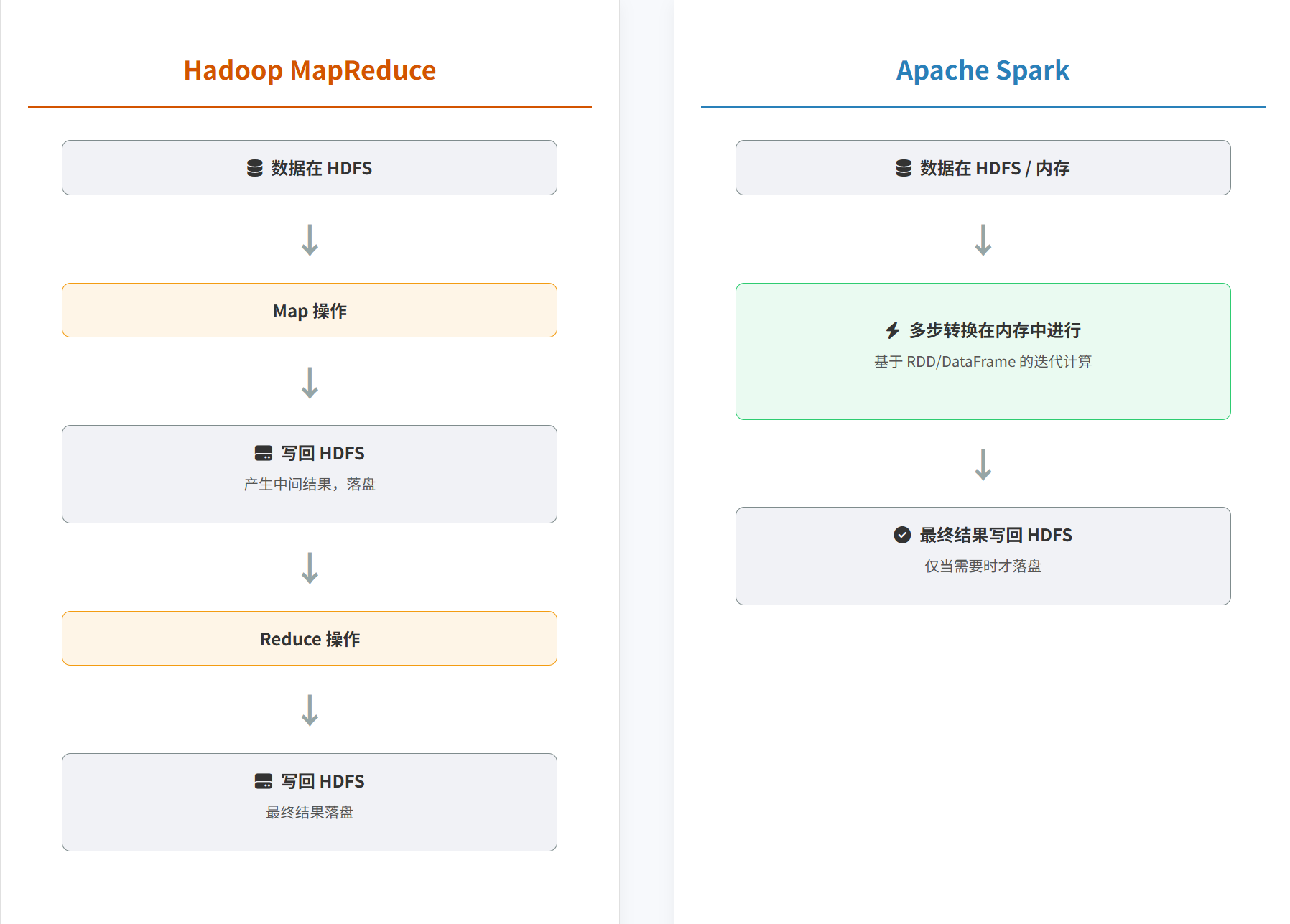
核心区别与优劣势对比:
-
速度 (Speed)
- Hadoop MapReduce: 慢,因为每一步计算的中间结果都得存到硬盘上。
- Spark: 快,因为中间数据都放在内存里,读写速度比硬盘快几个数量级。在需要反复计算的场景下,速度优势尤其明显。
-
功能 (Functionality)
- Hadoop MapReduce: 专科生,只擅长做离线批处理这一件事。想做别的 (如实时分析、SQL查询),就得另外找别的工具来搭配。
- Spark: 全能选手。它自己就集成了批处理、SQL查询、实时流处理、机器学习、图计算等多种功能。一个Spark就能搞定一大堆事,开发和维护都简单多了。
-
易用性 (Ease of Use)
- Hadoop MapReduce: 编程复杂,代码又长又啰嗦。
- Spark: 编程简单,API友好,代码简洁优雅。还提供交互式命令行,可以边想边试,对数据科学家和分析师非常友好。
-
容错性 (Fault Tolerance)
- Hadoop MapReduce: 非常可靠。因为每一步都存盘,所以就算有机器挂了,也很容易从上一步的存档恢复。
- Spark: 同样可靠。Spark 聪明地记录了每个数据是如何一步步计算出来的 (这叫“血缘关系”)。如果某块内存数据丢失了,Spark 可以根据这个“菜谱”快速地重新把它做出来,而不是靠笨重的数据备份。
三、Spark的核心模块
Spark之所以如此全能,是因为它由几个各怀绝技的核心模块组成,像一个超级英雄团队。
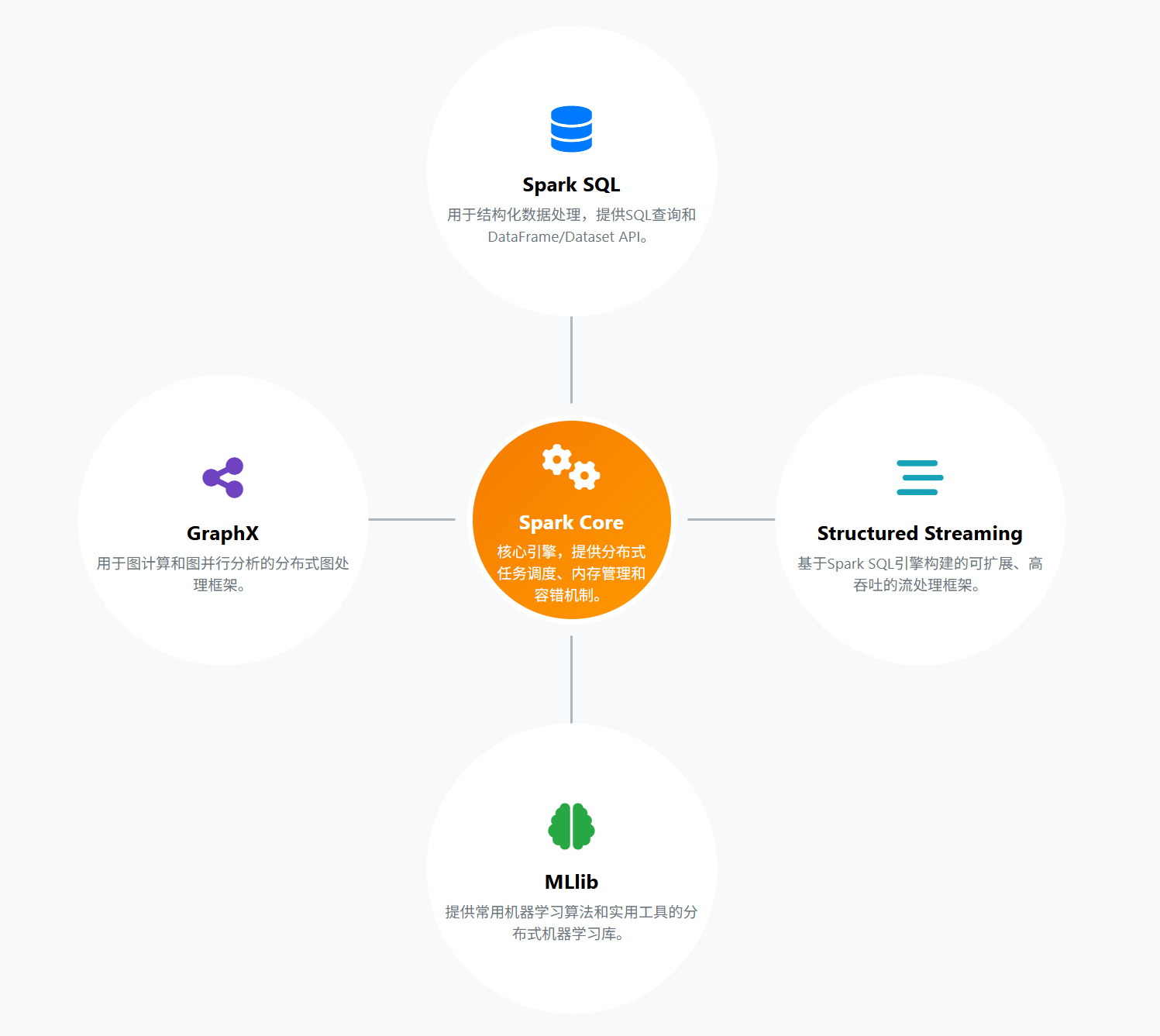
-
Spark Core (团队基石)
- 这是Spark的心脏和灵魂,提供了所有其他功能的基础。
- 核心是RDD: 就是我们前面提到的那个智能的、分布在内存中的大表格。
- 它负责任务调度、内存管理、错误恢复等所有脏活累活。
-
Spark SQL (数据分析专家)
- 专门处理带有清晰结构的数据。
- 核心是DataFrame/DataSet: 可以把它想象成Excel表格,有行有列,操作起来非常方便。
- 你既可以用标准的SQL语句来查询它,也可以用更灵活的编程方式来处理。
-
Structured Streaming (实时信息处理员)
- 处理源源不断涌入的实时数据流。
- 它非常聪明地把实时数据流看作一张“无限增长的表”,让你可以用处理普通表格的方式来处理实时数据,大大简化了编程难度。
-
MLlib (机器学习大师)
- Spark内置的机器学习库。
- 它提供了大量现成的机器学习算法(比如分类、回归、聚类等),让你可以轻松地在海量数据上训练模型。
-
GraphX (社交网络分析师)
- 专门用于处理“图”结构的数据,比如社交网络的好友关系、物流网络的节点和路径。
- 它内置了一些经典的图算法,如PageRank(网页排名)。
结论
Apache Spark 凭借其对速度的极致追求、对多种计算任务的统一支持以及对开发者的友好,已经毫无疑问地成为了现代大数据技术栈的核心引擎。它不仅仅是一个更快的MapReduce,更是一个全面、强大、灵活</-DD>的数据处理平台,让复杂的数据分析和人工智能应用变得触手可及。

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐


 72
72 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)