论文阅读笔记-POSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition
论文阅读笔记。我是初学者,对很多专业知识的理解可能不够透彻,文中要是有分析不到位或者错误的地方,恳请大家不吝赐教,我会及时改正,非常感谢大家的帮助!
文章目录
一、前言
哈喽,大家好,本文我将来带大家阅读一篇顶会论文《POSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition》,我将会分为两大部分来完成介绍。分别为论文代码复现和论文内容介绍,本篇我将详细介绍论文内容。
二、简要介绍
我们先简单介绍一下论文相关内容:
课题:POSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition
领域:计算机视觉——面部表情识别(FER)
会议:CVPR
作者:Ce Zheng, Matias Mendieta, Chen Chen
三、论文内容
1.内容概要
①研究目的:本文旨在同时解决面部表情识别领域的三个常见问题——类间相似性、类内差异性、尺度敏感性。
②主要方法:文章提出了一种金字塔交叉融合 Transformer 网络(POSTER),该网络采用双流架构(图像流和地标流),通过交叉融合 Transformer 结构实现特征协作,并结合金字塔结构捕捉不同分辨率特征。
③论文贡献:提出了金字塔交叉融合 Transformer 网络,以统一框架解决面部表情识别中的类间相似性、类内差异性和尺度敏感性问题;设计的交叉融合 Transformer 结构实现了图像特征与 landmark 特征的有效协作,使图像特征能借助 landmark 的显著区域先验信息,同时 landmark 特征能获得图像的全局上下文;通过整合特征金字塔结构,POSTER 在RAF-DB、FERPlus、AffectNet数据集上取得了新的最优结果,验证了其有效性。
2.课题背景
面部表情识别是计算机视觉中的一项关键任务,它在理解人类情感和意图方面起着至关重要的作用。FER在人机交互、教育、医疗保健和在线监控等领域有各种实际应用。因此,近年来它受到了越来越多的关注。
传统方法通常采用手工设计的特征(方向梯度直方图 HOG、局部二值模式 LBP、尺度不变特征变换 SIFT 等)进行面部表情识别,但这些特征往往不够鲁棒和准确。
近年来,深度学习方法(区域注意力网络 RAN、自修复网络 SCN、知识迁移网络 KTN 等)成为研究热点,它们借助大规模数据集(包含真实场景中的挑战性训练数据),在性能上显著优于传统方法。
然而,FER 仍面临三大核心挑战:
① 类间相似性:差异细微的图像可能分属不同表情类别(例如,嘴巴区域的微小变化即可决定表情类别,下图1左边所示);
② 类内差异性:同一表情类别下的图像可能因肤色、性别、年龄、背景等存在显著差异,下图1右边所示;
③ 尺度敏感性:基于深度学习的网络通常对图像质量和分辨率敏感,而 FER 数据集及真实场景中的图像尺寸差异较大,确保跨尺度的稳定性能至关重要。
针对这些问题,2018 年前的一些早期工作尝试将面部特征点(人脸图像上的关键 keypoints,可作为关键面部区域的稀疏表示,补充直接图像特征)融入 FER 的深度学习方法,以增强对细节的关注并提升类内差异不变性,但这些方法通常仅在最后一个全连接层或一组基础模块前简单拼接图像特征和特征点特征,未能充分挖掘两者的相关性。近期研究中,部分方法仅解决类内差异性和类间相似性(基于图像特征),另一部分仅解决尺度敏感性,且均未全面应对三大挑战,同时面部特征点这一在人脸相关任务中广泛应用的信息被多数近期 FER 方法忽略。
为此,本文提出金字塔交叉融合 Transformer 网络POSTER,通过双流架构(图像流和特征点流)、交叉融合 Transformer 结构(实现特征协作)和金字塔架构(捕捉多分辨率特征),在统一框架中全面解决 FER 的三大挑战,并在多个基准数据集上取得新的最优结果。
3.相关工作
(1)FER中的深度学习方法
传统方法依赖HOG、LBP等手工特征,鲁棒性和准确性有限;近年来,RAN、SCN、KTN等深度学习方法借助大规模数据集,在应对遮挡、标注错误等挑战上表现突出,性能远超传统方法。
(2)面部特征点在FER中的应用
面部特征点可定位关键面部区域,早期方法(如Jung等人、Hassani等人的研究)将其与图像特征结合,但仅通过简单加权、相乘等方式整合,未充分挖掘两者相关性;且当前FER的最优方法均未利用面部特征点。
(3)视觉Transformer
Transformer 在自然语言处理领域的突破推动了其在计算机视觉中的应用,ViT 通过将图像分割为补丁,利用自注意力机制捕捉补丁间的长距离依赖。在 FER 领域,Aouayeb 等人直接应用 ViT 结构,在 MLP 头前添加 SE 块以提升性能;Xue 等人提出的 TransFER 方法,先用骨干 CNN 提取特征图,通过局部 CNN 块定位多样的局部补丁,再用 Transformer 编码器结合多头自注意力丢弃模块探索这些局部补丁间的全局关系。
(4)现有方法与POSTER的差异
POSTER采用双流(图像流和landmark流)金字塔交叉融合Transformer网络,通过交叉融合Transformer结构实现特征协作(图像特征借助landmark的显著区域先验,landmark特征获得图像的全局上下文),并结合金字塔结构捕捉多分辨率特征,以同时解决FER中的类间相似性、类内差异性和尺度敏感性问题;而现有方法或仅基于图像特征,或未充分利用特征点与图像特征的相关性,或未解决尺度敏感性问题,均未在统一框架中应对这三类挑战。
4.模型介绍
首先介绍一下基线架构。
首先,输入图像通过图像骨干网络(如IR50)提取图像特征X_img,同时利用现成的面部特征点检测器(如MobileFaceNet)获取特征点特征X_lm,其中图像骨干网络在训练时会进行微调,而面部特征点检测器的权重则保持冻结。接着,将图像特征X_img与特征点特征X_l在patch维度进行拼接,得到融合特征X_fuse。之后,直接使用Transformer编码器(包含多头自注意力层和MLP)对融合特征X_fuse进行处理,最后通过MLP头输出预测的表情标签。不过,该基线架构仅通过简单拼接整合两种特征,未能充分挖掘图像特征与特征点特征之间的相关性。
基线架构的示意图如下图2(a)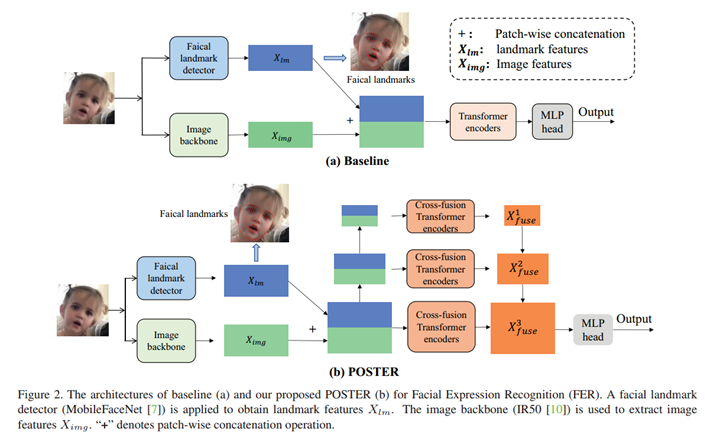
下面将从 POSTER 架构的整体设计出发,分双流特征提取、交叉融合 Transformer 结构、特征金字塔结构三个部分,阐述其结构。POSTER完整架构如图2(b)所示。
(1)双流特征提取
与基线架构一致,通过图像骨干网络(IR50)提取图像特征X_img,借助冻结权重的面部 landmark 检测器(MobileFaceNet)获取 landmark 特征X_lm,两类特征分别作为图像流和 landmark 流的输入。
- 图像流特征:输入图像为 X ∈ R H A ˉ W A ˉ 3 X \in \mathbb{R}^{H \bar{A} W \bar{A} 3} X∈RHAˉWAˉ3( H H H 为高度, W W W 为宽度,3 为 RGB 通道数),通过 IR50 等骨干网络提取为 X i m g ∈ R P A ˉ D X_{img} \in \mathbb{R}^{P \bar{A} D} Ximg∈RPAˉD,其中 P P P 表示特征补丁数量, D D D 为每个补丁的特征维度(如 256 或 512);
- landmark 流特征:通过 MobileFaceNet 等检测器获取人脸关键点,生成 X l m ∈ R P A ˉ D X_{lm} \in \mathbb{R}^{P \bar{A} D} Xlm∈RPAˉD( P P P 与图像流补丁数量一致,确保后续融合维度匹配)。
(2)交叉融合Transformer结构
为实现图像特征与 landmark 特征的深度协作,POSTER 设计了交叉融合 Transformer 编码器,与图 3(a)的 vanilla Transformer 编码器相比,其结构和操作有显著差异。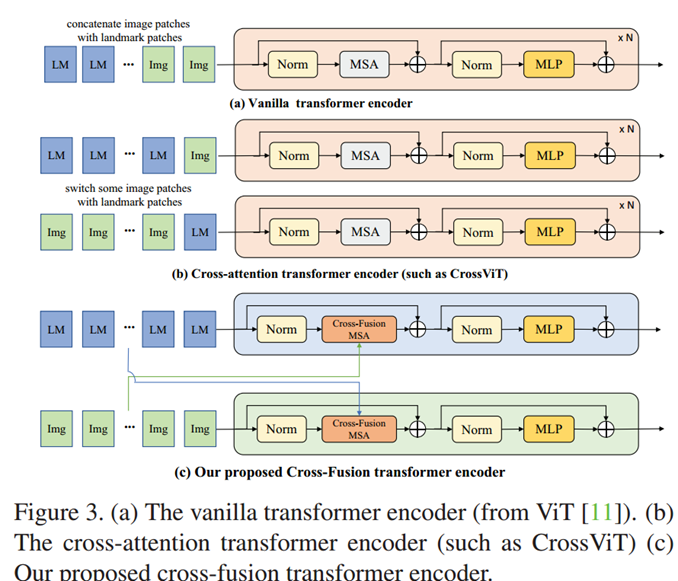
①交叉融合多头自注意力(CFMSA)块(图 4b)
论文指出,面部表情的关键线索同时存在于局部显著区域(如嘴角、眉毛,由 landmark 标记)和全局上下文(如脸颊皱纹、额头状态,由图像特征覆盖)。因此,公式 1 和 2 通过交换查询矩阵Q实现双向引导。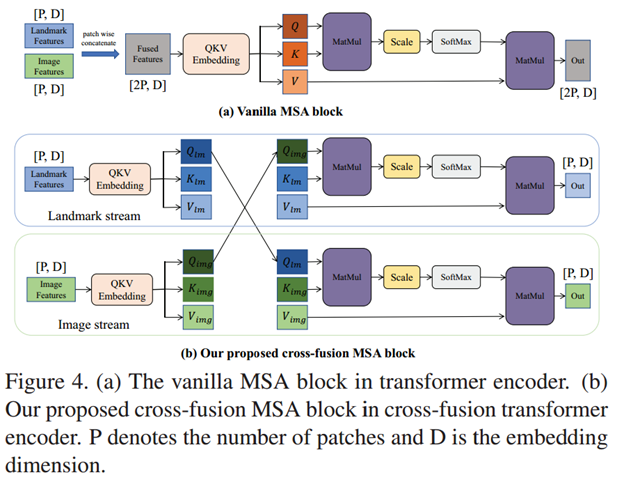
a. 图像流注意力计算
Attention ( i m g ) = Softmax ( Q l m K i m g ⊤ d ) V i m g (公式 1 ) \text{Attention}^{(img)} = \text{Softmax}\left( \frac{Q_{lm} K_{img}^\top}{\sqrt{d}} \right) V_{img} (公式1) Attention(img)=Softmax(dQlmKimg⊤)Vimg(公式1)
- Q l m Q_{lm} Qlm:landmark 流的 “查询矩阵”(Query),包含人脸关键区域的先验信息;
- K i m g K_{img} Kimg:图像流的 “键矩阵”(Key), V i m g V_{img} Vimg:图像流的 “值矩阵”(Value),两者均来自图像特征;
- d \sqrt{d} d:缩放因子( d d d 为特征维度),用于避免矩阵乘法结果过大导致 Softmax 梯度消失;
- 图像流通过 landmark 的查询矩阵,聚焦于与表情相关的显著区域。
公式 1(图像流注意力)中,Q _lm作为 landmark 流的查询矩阵,本质是将人脸关键区域的先验信息注入图像特征。这一设计针对类间相似性问题 :当两个表情的全局图像差异细微时(如图 1a 中中性与开心),landmark 的显著区域(如嘴巴弧度)能帮助图像流聚焦于判别性特征,减少误分类。
b. landmark 流注意力计算
Attention ( l m ) = Softmax ( Q i m g K l m ⊤ d ) V l m (公式 2 ) \text{Attention}^{(lm)} = \text{Softmax}\left( \frac{Q_{img} K_{lm}^\top}{\sqrt{d}} \right) V_{lm}(公式2) Attention(lm)=Softmax(dQimgKlm⊤)Vlm(公式2)
- Q i m g Q_{img} Qimg:图像流的查询矩阵,包含全局图像信息;
- K l m K_{lm} Klm、 V l m V_{lm} Vlm:landmark 流的键矩阵和值矩阵,来自关键点特征;
- landmark 流借助图像的全局上下文(如脸颊红晕、额头皱纹 ),补充关键点之外的表情线索。
公式 2(landmark 流注意力)中,Q _img携带的全局图像信息可弥补 landmark 的稀疏性缺陷。例如,悲伤表情的泪痕、愤怒表情的额头皱纹等非关键点特征,能通过图像流引导 landmark 流关注更全面的表情线索,从而缓解类内差异性(如图 1b 中不同个体的 “开心” 表情因肤色、年龄导致的外观差异)。
②交叉融合 Transformer 编码器
每个编码器包含“交叉融合注意力+MLP”结构,经过注意力计算后,特征通过残差连接与层归一化优化(图 3c 右侧):
X i m g l = CFMSA i m g ( Q l m , K i m g , V i m g ) + X i m g (公式 3 ) X_{img}^l = \text{CFMSA}_{img}(Q_{lm}, K_{img}, V_{img}) + X_{img}(公式3) Ximgl=CFMSAimg(Qlm,Kimg,Vimg)+Ximg(公式3)
X i m g _ o u t = MLP ( Norm ( X i m g l ) ) + X i m g l (公式 4 ) X_{img\_out} = \text{MLP}\left( \text{Norm}(X_{img}^l) \right) + X_{img}^l(公式4) Ximg_out=MLP(Norm(Ximgl))+Ximgl(公式4)
landmark 流的更新公式类似(公式 3、4),最终输出 X l m _ o u t X_{lm\_out} Xlm_out 。
其中, X i m g l X_{img}^l Ximgl表示图像流经交叉注意力更新后的特征; Norm ( ⋅ ) \text{Norm}(\cdot) Norm(⋅)表示层归一化操作,用于稳定训练过程; MLP ( ⋅ ) \text{MLP}(\cdot) MLP(⋅)是多层感知机,用于特征非线性变换; 残差连接(“ + X i m g + X_{img} +Ximg” )可避免深层网络梯度消失,保留原始特征信息。
残差连接允许原始特征直接传递至后续层,避免因交叉融合操作过度修改特征而丢失基础信息(如 landmark 的位置坐标、图像的纹理细节),这对保留 FER 所需的关键线索至关重要。
层归一化(Norm)通过标准化特征分布,解决了交叉融合过程中两类特征(图像与 landmark)尺度差异导致的训练波动问题,确保 MLP 模块能有效学习非线性变换。
(3)特征金字塔结构
为解决尺度敏感性问题,构建大、中、小三级特征(embedding维度分别为 512、256、128),每级特征由独立的交叉融合 Transformer 编码器处理,最终聚合所有输出特征,通过 MLP 头输出预测的表情标签。
- 尺度划分:大、中、小特征的嵌入维度分别为 D H = 512 D_H = 512 DH=512、 D M = 256 D_M = 256 DM=256、 D L = 128 D_L = 128 DL=128,每级特征由 8 个交叉融合 Transformer 编码器处理;
- 聚合与输出:三级特征经各自编码器处理后,通过 patch-wise 拼接聚合为融合特征 X fuse X_{\text{fuse}} Xfuse,最终输入 MLP 头输出表情预测结果 Y ∈ R N Y \in \mathbb{R}^N Y∈RN( N N N 为类别数)。
金字塔三级特征的维度设置( D H = 512 D_H = 512 DH=512、 D M = 256 D_M = 256 DM=256、 D L = 128 D_L = 128 DL=128)并非随意选择,而是针对尺度敏感性问题的优化:
①高分辨率特征( D H = 512 D_H = 512 DH=512)保留更多细节信息,适合处理清晰图像中的细微表情;
②低分辨率特征(如 D M = 256 D_M = 256 DM=256)通过压缩维度增强鲁棒性,适合模糊或小尺寸图像(如 FERPlus 的 48×48 灰度图)。
论文强调,这种多尺度设计使 POSTER 在输入图像质量波动时仍能保持稳定性能,在 AffectNet 数据集上的实验显示,金字塔结构相比单尺度特征提升了 1.8% 的准确率。
此外,POSTER 的交叉融合机制不同于 CrossViT 等仅交换模态 patch 的设计,其核心是通过双向特征协作增强表示能力,而非简单拼接或交换输入。
5.实验测试
(1)实验设置
- 数据集:实验选用 RAF-DB、FERPlus 和 AffectNet 三个主流面部表情识别数据集。RAF-DB 含 29,672 张真实场景人脸图像,15,339 张用于 FER 任务(12,271 张训练,3,068 张测试),涵盖 7 种基本表情;FERPlus 基于 FER2013 扩展,含 28,709 张训练图、3,589 张验证图和 3,589 张测试图,均为 48×48 灰度图,标注为 8 类表情;AffectNet 含超 100 万张图像,标注为 8 类表情,训练集存在严重不平衡。
- 评估指标:采用准确率(所有测试样本中正确分类的比例)和平均准确率(各表情类别准确率的平均值),后者用于衡量模型在不平衡类别上的综合性能。
- 实施细节:基于 PyTorch 框架,在 2 台 NVIDIA RTX 3090 GPU 上训练;图像特征由预训练的 IR50 网络(训练时微调)提取,landmark 特征由 MobileFaceNet(权重冻结)提取;特征金字塔分大、中、小三级(维度 512、256、128),每级对应 8 个交叉融合 Transformer 编码器;训练参数为 batch size=100,学习率 = 4×10⁻⁵,采用标签平滑交叉熵损失等。
(2)定量评估
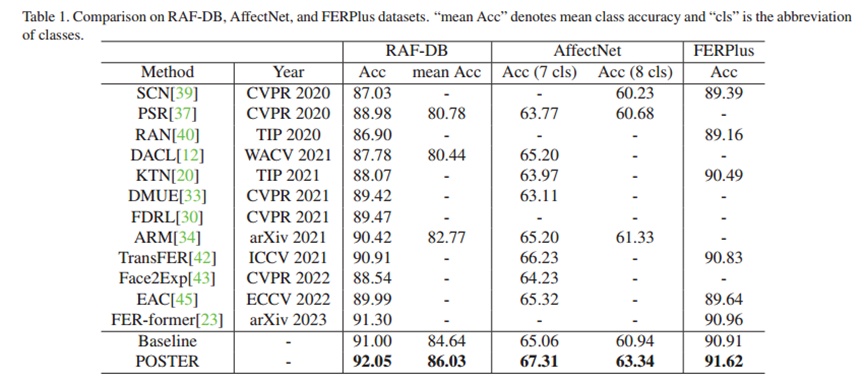
实验将POSTER与 RAN、DACL、SCN、ARM、TransFER 等主流方法在三个数据集上进行了多维度对比。在 RAF-DB 数据集上,POSTER 的整体准确率显著超过传统深度学习方法和基于 Transformer 的方法,平均准确率也领先于次优方法,且在类别不平衡子集中对小众类别的识别能力更强;在 AffectNet 数据集上,无论是针对 7 类表情还是包含 “轻蔑” 类的 8 类评估,POSTER 的准确率均超过对比方法,在处理野外复杂数据和不平衡分布时表现出良好的稳健性;在 FERPlus 数据集上,尽管图像为低分辨率灰度图,POSTER 仍取得较高准确率,超过对比方法,且在 “轻蔑” 等易混淆表情上表现突出,错误矩阵分析显示其有效缓解了类间相似性问题。
实验结果表明 POSTER 在面部表情识别任务中表现优异,在多个数据集上超越现有方法。
(3)定性评估
t-SNE 特征可视化(图 5)结果显示,POSTER 输出的特征在低维空间中呈现出更优的分布模式。与基线模型及其他对比方法相比,其同一表情类别的特征点聚集更为紧密,不同类别之间的边界也更为清晰。这说明POSTER 有效压缩了同类表情内部的差异,同时拉大了不同表情类别之间的距离,从特征层面印证了其对类内差异性和类间相似性的缓解作用。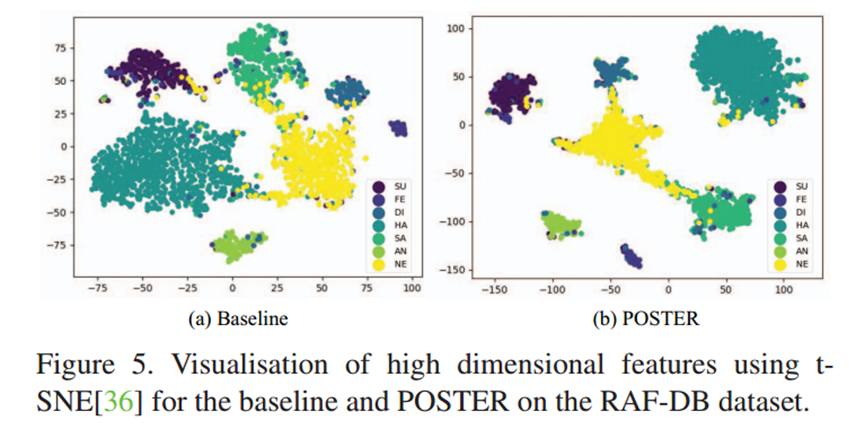
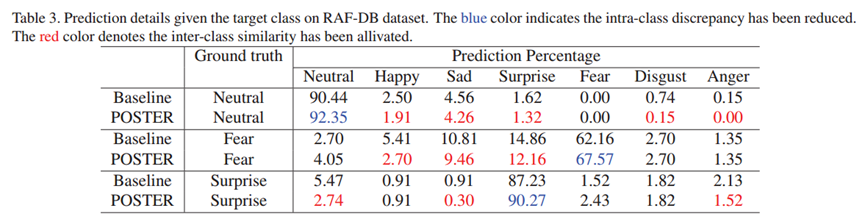
类别预测细节分析(表 3)进一步揭示了 POSTER 在降低错误分类上的表现。通过对易混淆的表情类别对进行统计发现,常见的误判情况明显减少。这一结果说明,POSTER 能够更精准地捕捉不同表情的独特特征,从而有效区分那些在视觉上具有较高相似性的表情类别。
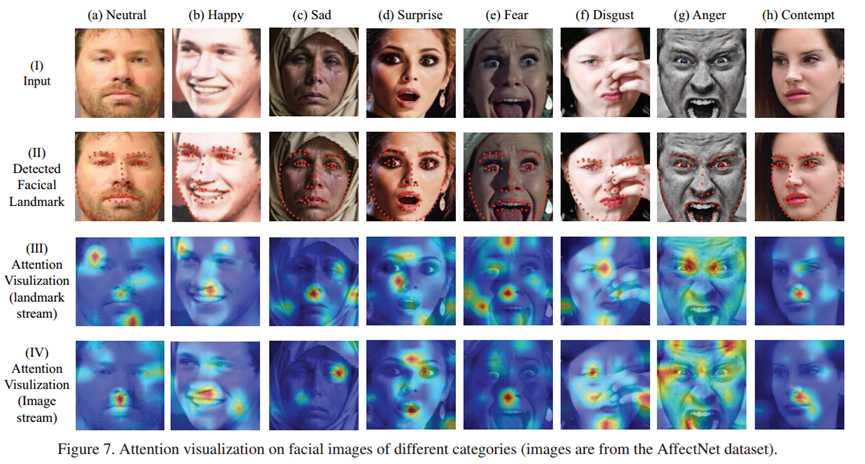
注意力可视化(图 7)展示了 POSTER 两个流的协作机制。其中,landmark 流的注意力主要集中在对表情变化起关键作用的面部区域,比如能够直接反映情绪状态的嘴角、眼角、眉毛等部位;而图像流的注意力范围则更为广泛,除了关注上述关键区域外,还会捕捉到如泪痕、额头皱纹、脸颊肌肉状态等全局线索。两个流的注意力分布相互补充,landmark 流确保了对核心表情区域的精准聚焦,图像流则提供了更全面的上下文信息,共同增强了模型对表情特征的判别能力。
(4)消融实验
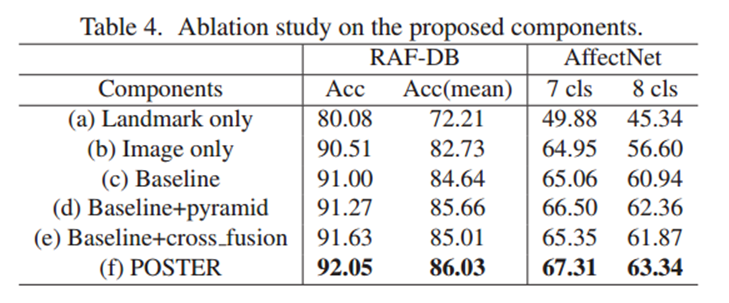
通过控制变量法验证各组件的作用(表 4):
①仅 landmark 特征:RAF-DB 准确率 80.08%,远低于其他组合,说明单一 landmark 特征信息不足。
②仅图像特征:RAF-DB 准确率 90.51%,优于仅 landmark,但弱于融合模型,说明图像特征是基础但需补充。
③基线模型(图像 + landmark 简单拼接):准确率 91.00%,证明融合的有效性,但未充分挖掘相关性。
④基线 + 金字塔结构:准确率提升至 91.27%,说明金字塔结构缓解了尺度敏感性。
⑤基线 + 交叉融合:准确率提升至 91.63%,验证交叉融合对特征协作的促进。
⑥POSTER(全组件):准确率达 92.05%,为最优,证明各组件协同作用的必要性。
四、总结
这篇论文聚焦面部表情识别,创新性地提出双流金字塔交叉融合 Transformer 结构。该结构通过图像流与 landmark 流的双向交叉融合,配合金字塔网络实现多尺度特征提取,有效提升了 FER 任务中对类内差异和类间相似性问题的处理能力,在多个主流数据集上超越了传统和基于 Transformer 的 SOTA 方法。
不过,POSTER 可能也存在一些改进方向。交叉注意力机制计算复杂度为平方级,效率较低,在信息利用和计算效率上有提升空间。

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐

 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)