
清华 DeepDive 开源|深度搜索 Agent 以“知识图谱+多轮强化学习”训练,BrowseComp 14.8% 超 WebSailor-32B,复杂多步骤网页推理再进阶(2025)
猫头虎AI开源项目分享:清华的深度搜索Agent项目,我是猫头虎,今天分享一个来自清华的开源深度搜索 Agent 项目——DeepDive:它将知识图谱自动数据合成与端到端多轮强化学习(RL)结合,面向复杂多步骤任务与长程推理的网页浏览智能体。在 BrowseComp 基准上,DeepDive-32B 实测 14.8% 准确率,超越阿里 WebSailor-32B,虽与 OpenAI DeepRe
猫头虎AI开源项目分享:清华的深度搜索Agent项目:DeepDive,自动化方式来训练能完成复杂多步骤任务的深度搜索智能体
大家好,我是猫头虎,今天给大家分享一个来自清华大学AI实验室的最新开源项目——DeepDive深度搜索Agent。这是一个将知识图谱自动数据合成与端到端多轮强化学习结合的前沿研究成果,旨在打造能够执行复杂长程推理与网页浏览任务的智能体(AI Agent)。
在最新的深度搜索基准测试 BrowseComp 上,DeepDive-32B 模型取得了 14.8% 的准确率,超越了阿里的 WebSailor-32B,虽然距离 OpenAI DeepResearch 还有差距,但已经展现出强大的潜力和研究价值。
这个项目不仅展示了自动化训练复杂智能体的新方法,也为未来的多步骤推理Agent、网页搜索AI、强化学习智能体提供了新的开源思路。代码即将放出,GitHub 地址在这里 👉 https://github.com/THUDM/DeepDive。
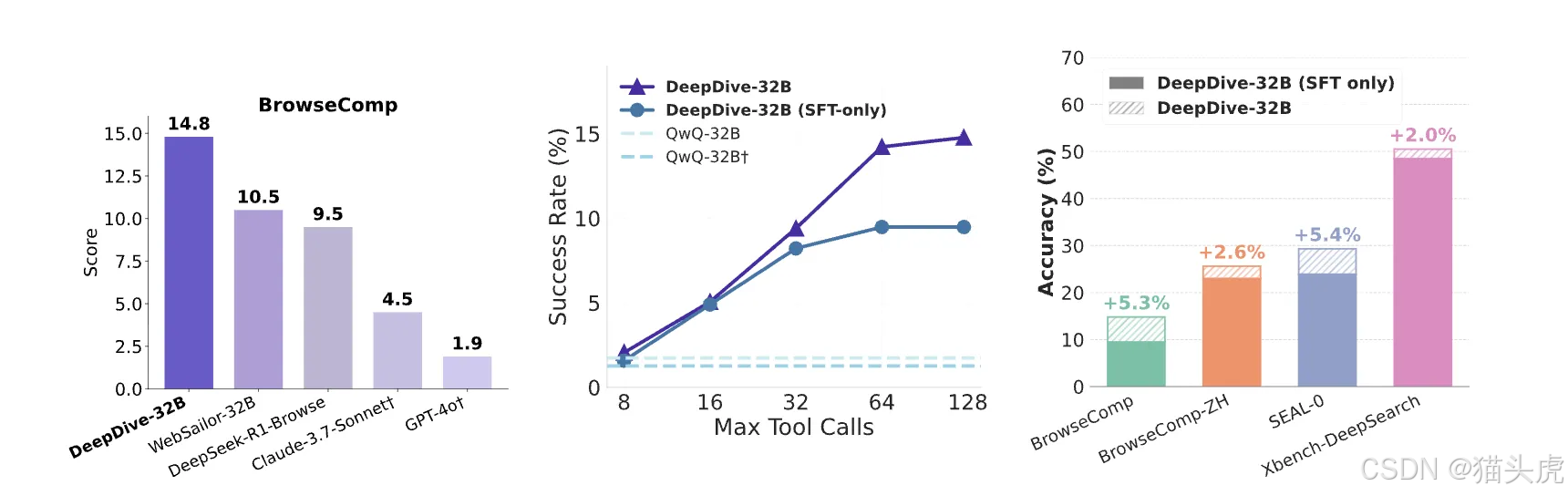
DeepDive 项目结合知识图谱的自动数据合成与多轮强化学习,旨在创建具备复杂长程推理和网页浏览能力的智能体。在 BrowseComp 上的准确率为 14.8%,超越阿里的 WebSailor-32B,与 OpenAI 的 DeepResearch 有一定差距。
清华的深度搜索 Agent 项目:DeepDive
DeepDive 通过自动化方式训练能够完成复杂多步骤任务的深度搜索智能体。
DeepDive: Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL
🔥 News
- 2025/09/17:已完整开源 QA 对与 SFT 轨迹,共计 4,108 条。数据集地址:Hugging Face Dataset DeepDive
- 模型与代码正在完善中,即将开源。
概览(Overview)
DeepDive 提出一种自动化训练深度搜索智能体的方法,面向复杂、多步骤的信息检索任务。核心思路是把来自知识图谱的自动数据合成与端到端的多轮强化学习(RL)结合起来,从而让 Agent 具备长程推理与网页浏览能力,并在推理链路上实现可扩展的测试时缩放(test-time scaling)。
关键特性
- 自动深度搜索数据合成:基于知识图谱随机游走生成高难度 QA;
- 多轮 RL 浏览训练:端到端优化多步交互式搜索能力;
- 测试时缩放:支持工具调用预算放大与并行采样。
方法(Method Overview)
阶段一:基于知识图谱的自动数据合成
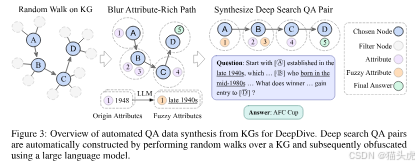
- 知识图谱随机游走:从初始节点 v 0 v_0 v0 出发走 k k k 步得到路径 P = [ v 0 , … , v k ] P=[v_0,\dots,v_k] P=[v0,…,vk];选取更长的路径(如 k > 5 k>5 k>5)以提高推理难度。
- 实体模糊化:把每个节点与属性合并得到属性化路径 P A P_A PA,再通过 LLM 对细节做“去特征化/模糊化”,形成需要深度搜索才能还原的“模糊实体”。
- 难度筛选:使用前沿模型(如 GPT-4o)+基础搜索尝试 4 次;四次全败的问题才被保留,确保高难度。
阶段二:端到端多轮强化学习
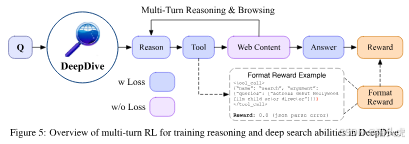
训练时,智能体在每步 t t t 生成推理链 c t c_t ct、执行浏览动作 a t a_t at、观察网页内容 o t o_t ot,循环迭代。
Multi-Turn GRPO(组相对策略优化)
归一化优势函数:
A_i = (r_i − mean(r_k, k=1..G)) / std(r_k, k=1..G)
严格二元奖励(Strict Binary Rewards)
仅当格式正确且答案准确同时满足时,整条轨迹给 +1 奖励:
r(T) = 1, 若 (∀i, Format(c_i, a_i)) ∧ Judge(a_eos, a*)
= 0, 其他情况
模型(Models)
| Model | Parameters | HuggingFace Hub | Performance (BrowseComp) |
|---|---|---|---|
| DeepDive-9B | 9B | coming soon | 6.3% |
| DeepDive-32B | 32B | coming soon | 14.8% |
数据(Data)
合成数据流水线:使用 KILT、AMiner 等知识图谱进行多跳( k = 5 ∼ 9 k=5\sim9 k=5∼9)路径抽样 + 实体模糊化 + 难度筛选,得到高难度 QA 对与搜索轨迹。
| Component | Size | Explanation |
|---|---|---|
| Total Dataset | 3,250 | 全部训练语料的 QA 对 |
| SFT Portion | 1,016 | 用于 SFT 的子集 |
| ↳ SFT Trajectories | 858 | 通过拒绝采样得到的 SFT 搜索轨迹 |
| RL Portion | 2,234 | 用于 RL 训练的子集 |
数据示例

结果(Results)
我们在四个深度搜索难集上评测:BrowseComp、BrowseComp-ZH、Xbench-DeepSearch、SEAL-0。DeepDive 在开源模型中表现稳健,其中 DeepDive-32B 在 BrowseComp 上达 14.8%。
| Model | Reason | Browse | BrowseComp | BrowseComp-ZH | Xbench-DeepSearch | SEAL-0 |
|---|---|---|---|---|---|---|
| Proprietary Models | ||||||
| GPT-4o | ✗ | ✗ | 0.9* | 11.1 | 18.0* | 0.9 |
| GPT-4o† | ✗ | ✓ | 1.9* | 12.8 | 30.0 | 9.1 |
| Claude-3.7-Sonnet | ✗ | ✗ | 2.3 | 11.8 | 12.0 | 2.7 |
| Claude-3.7-Sonnet† | ✗ | ✓ | 4.5 | 14.2 | 29.0 | 14.4 |
| o1 | ✓ | ✗ | 9.9* | 29.1* | 38.0 | 11.7 |
| o4-mini | ✓ | ✗ | 6.1* | 15.2* | 22.3* | 2.7 |
| Claude-4-Sonnet-Thinking | ✓ | ✓ | 2.6 | 21.5 | 27.0 | 9.0 |
| Claude-4-Sonnet-Thinking† | ✓ | ✗ | 14.7 | 30.8 | 53.0 | 37.8 |
| Grok-DeepResearch | ✓ | ✓ | - | 12.9* | 50+ | - |
| Doubao-DeepThink | ✓ | ✓ | - | 26.0* | 50+ | - |
| DeepResearch | ✓ | ✓ | 51.5* | 42.9* | - | - |
| Open-Source Models | ||||||
| GLM-Z1-9B-0414 | ✗ | ✗ | 0.6 | 2.4 | 8.0 | 7.2 |
| GLM-Z1-9B-0414† | ✗ | ✓ | 0.6 | 1.7 | 3.0 | 2.7 |
| Qwen2.5-32B-Instruct | ✗ | ✗ | 0.6 | 9.3 | 8.7* | 2.7 |
| Qwen2.5-32B-Instruct† | ✗ | ✓ | 1.5 | 1.7 | 12.0 | 0.9 |
| Qwen3-235B-A22B-Instruct-2507 | ✗ | ✗ | 0.9 | 17.6 | 17.0 | 6.3 |
| Qwen3-235B-A22B-Instruct-2507† | ✗ | ✓ | 0.9 | 14.9 | 26.0 | 9.1 |
| Qwen3-235B-A22B-Thinking-2507 | ✗ | ✗ | 3.1 | 20.1 | 22.0 | 9.0 |
| Qwen3-235B-A22B-Thinking-2507† | ✗ | ✓ | 4.6 | 22.5 | 37.0 | 13.5 |
| QwQ-32B | ✓ | ✗ | 1.7 | 13.5 | 10.7* | 5.4 |
| QwQ-32B† | ✓ | ✓ | 1.3 | 14.5 | 27.0 | 4.5 |
| DeepSeek-V3-0324 | ✗ | ✗ | 1.5 | 24.6 | 36.0 | 6.3 |
| DeepSeek-R1 | ✓ | ✗ | 2.0 | 23.2 | 32.7* | 5.4 |
| DeepSeek-R1-0528 | ✓ | ✗ | 3.2 | 28.7 | 37.0 | 5.4 |
| GLM-4.5-Air | ✓ | ✓ | 21.3 | 36.3 | 65.0 | 30.6 |
| GLM-4.5 | ✓ | ✓ | 26.4 | 37.5 | 68.0 | 36.0 |
| Web Agents | ||||||
| Search-o1-32B | ✓ | ✓ | 2.8* | 17.9* | 25.0* | - |
| WebThinker-32B | ✓ | ✓ | 2.8* | 7.3* | 24.0* | - |
| WebDancer-32B | ✓ | ✓ | 3.8* | 18.0* | 39.0* | - |
| WebSailor-7B | ✓ | ✓ | 6.7* | 14.2* | 34.3* | - |
| WebSailor-32B | ✓ | ✓ | 10.5* | 25.5* | 53.3* | - |
| DeepDive (Ours) | ||||||
| DeepDive-9B (sft-only) | ✓ | ✓ | 5.6 | 15.7 | 35.0 | 15.3 |
| DeepDive-9B | ✓ | ✓ | 6.3 | 15.1 | 38.0 | 12.2 |
| DeepDive-32B (sft-only) | ✓ | ✓ | 9.5 | 23.0 | 48.5 | 23.9 |
| DeepDive-32B | ✓ | ✓ | 14.8 | 25.6 | 50.5 | 29.3 |
注:
*表示来自已有研究的汇报结果;†表示通过函数调用启用浏览(工具)能力。
在简单搜索任务上的泛化
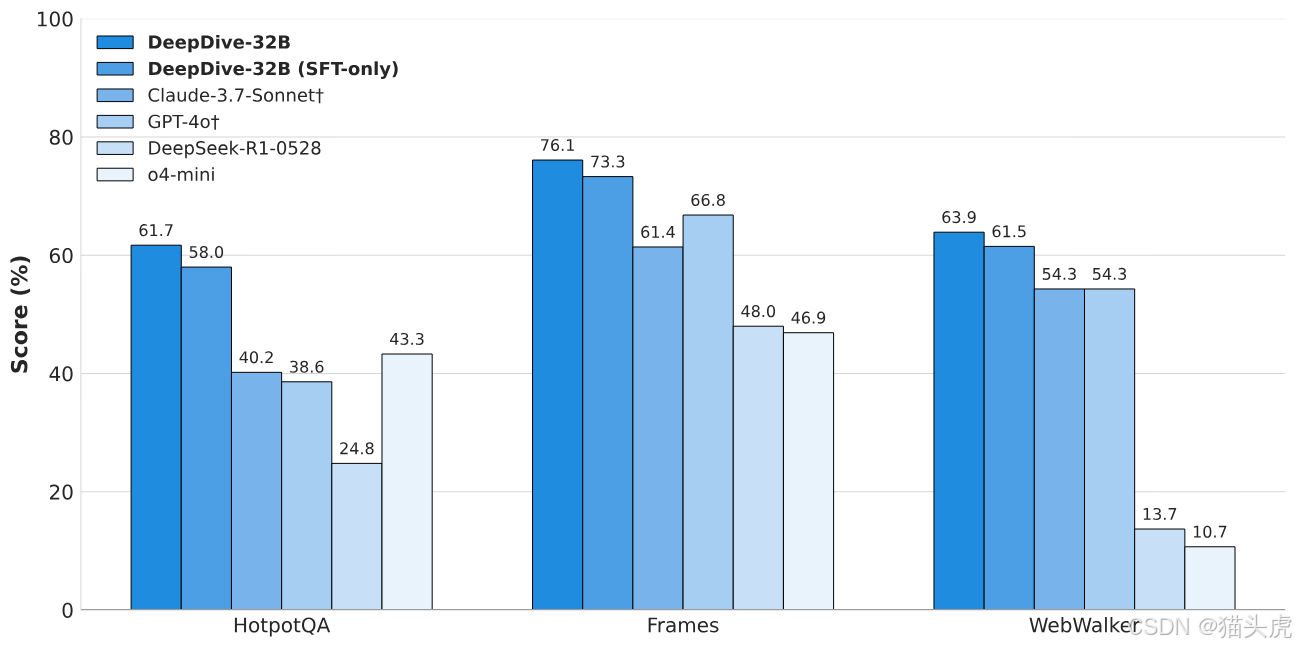
除了上述难集,DeepDive 也在 HotpotQA、Frames、WebWalker 等更“浅”的检索任务上评估。DeepDive-32B(SFT+RL) 在 WebWalker 上超过 60 分,优于 WebShaper-72B(52.2),显示了良好的跨任务泛化。
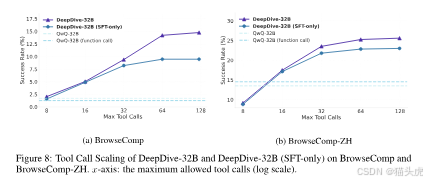
测试时缩放(Test-Time Scaling)
1)工具调用预算放大
允许更多工具调用能稳步提升复杂任务的准确率:
- 在 BrowseComp 上,从 8 次工具调用的 8% 提升到 128 次时的 15%;
- DeepDive-32B 在工具调用 >32 的区域相对 SFT-only 版本提升更显著,说明 RL 更好地学习了“长链路利用”。
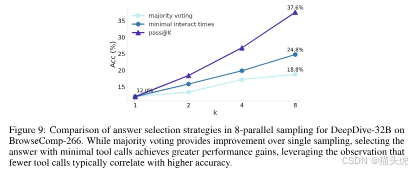
2)并行采样(Parallel Sampling)
为每个问题并行生成 8 条独立推理轨迹,采用三种提交策略:
- 单样本提交;
- 多数投票;
- 最少工具调用提交(选用最早收敛的答案)。
实证显示:更早、调用更少的答案往往更准。从单样本的 12.0% 提升到多数投票 18.8%,再到最少工具调用策略的 24.8%。
额外研究:半自动 i.i.d. 深度搜索 QA 用于 RL
为了进一步提升深搜任务表现,DeepDive 构建了一个半自动的 i.i.d. QA 生成流程。使用 i.i.d. 数据训练能带来更大增益:32B-RL 在 BrowseComp 上从 14.8% 升至 22.2%,中文集也同步提升。
| Model | Data | BrowseComp | BrowseComp-ZH | Xbench-DeepSearch | SEAL-0 |
|---|---|---|---|---|---|
| 32B (sft-only) | KG | 9.5 | 23.0 | 48.5 | 23.9 |
| 32B | KG | 14.8 | 25.6 | 50.5 | 29.3 |
| 32B (sft-only) | i.i.d. | 11.4 | 26.6 | 47.5 | 22.5 |
| 32B | i.i.d. | 22.2 | 33.9 | 56.0 | 23.0 |
注:污染分析显示,开源的 GLM-4.5 模型采用了 DeepDive 的 KG 与 i.i.d. 数据,并在 BrowseComp 上取得强势表现。
复现与工程要点(Practical Notes)
- 模型底座:基于 GLM-4、QwQ;
- RL 框架:使用 Slime;
- 网页访问:基于 Serper 与 Jina API;
- 数据与代码:数据已放出,代码与模型即将在 GitHub 开源:https://github.com/THUDM/DeepDive。
小结
DeepDive 把知识图谱驱动的数据合成和多轮 RL整合,推动了“深度搜索”智能体在长程推理 + 网页浏览上的上限;通过工具调用预算与并行采样的测试时缩放,进一步挖掘推理潜力。在 BrowseComp 上拿到 14.8% 的开源强基线,同时在更广泛的检索任务上也显示出良好的泛化能力。期待代码与模型放出后的更多实操与复现结果。

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐



 15
15 0
0- 0



 已为社区贡献178条内容
已为社区贡献178条内容

所有评论(0)