基于django的民族服装数据分析系统的设计与实现 spark爬虫民族服装数据采集 大数据可视化
本文介绍了一个基于Django的民族服装数据分析系统,该系统结合Python、爬虫技术及Hadoop+Spark大数据处理框架,实现了民族服装数据的采集、存储、分析和可视化展示。系统功能包括用户注册登录、服装信息浏览、资讯获取、个人收藏管理,以及管理员后台的数据统计和可视化分析。通过多维度数据展示(价格分布、地区统计、民族分类等),为商家和消费者提供决策支持,促进民族服装文化的传承与发展。
🔥作者:it毕设实战小研🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java实战项目
Python实战项目
微信小程序实战项目
大数据实战项目
PHP实战项目
💕💕文末获取源码
文章目录
本次文章主要是介绍基于django的民族服装数据分析系统的设计与实现的功能,
1、民族服装数据分析系统-前言介绍
1.1背景
民族服装作为中华优秀传统文化的重要载体,承载着深厚的历史底蕴和文化内涵。根据国家统计局发布的数据显示,2023年中国服装行业规模以上企业营业收入达到1.38万亿元,而民族服装细分市场年增长率保持在15%以上,市场潜力巨大。电商平台数据表明,民族服装相关商品在各大电商平台的年销售额已突破200亿元,消费群体呈现年轻化趋势,其中18-35岁用户占比超过70%;与此同时,传统民族服装产业面临着信息化程度低、数据分析能力不足的现实困境。当前市场上缺乏专门针对民族服装的数据分析平台,商家无法准确把握市场趋势和消费者偏好,消费者也难以获取全面的民族服装信息和价格对比数据。文化和旅游部相关报告指出,民族服装产业数字化转型迫在眉睫,急需建立完善的数据收集、分析和展示体系,为产业发展提供科学的数据支撑和决策依据。
1.2课题功能、技术
本系统采用Python作为主要开发语言,结合Django web框架构建稳定可靠的后端服务架构,为用户提供完整的民族服装数据分析解决方案。系统功能模块涵盖用户注册登录、民族服装信息浏览、服装资讯获取、个人收藏管理等核心业务功能,管理员端则具备用户管理、服装数据管理、统计分析等后台管理功能;技术架构方面,系统运用网络爬虫技术实现多平台民族服装数据的自动化采集,通过Hadoop分布式存储框架处理海量服装数据,结合Spark大数据处理引擎完成数据清洗、转换和分析任务。数据可视化大屏展示价格分布情况、地区销售统计、支付方式分析、商家商品分布以及民族分类统计等多维度数据分析结果,为用户和管理者提供直观的数据洞察;MySQL数据库负责存储结构化数据,保证数据的一致性和完整性,PyCharm集成开发环境提供高效的代码编写和调试支持。整个技术栈的选择充分考虑了系统的扩展性、稳定性和维护便利性,能够满足民族服装数据分析的实际需求。
1.3 意义
理论意义方面,本课题为民族服装领域的数字化研究提供了新的技术思路和实践案例,丰富了文化遗产数字化保护的理论体系;系统将爬虫技术、大数据分析技术与传统文化产业相结合,为跨领域技术融合应用提供了有益探索,推动了数据科学在文化产业中的理论发展和应用创新。实际意义层面,系统能够帮助民族服装商家准确掌握市场动态和消费趋势,通过数据分析优化商品定价策略和库存管理,降低经营风险并提升经济效益;对于消费者而言,平台提供了便捷的民族服装信息查询和比较功能,有助于做出更加理性的购买决策,同时促进了民族服装文化的传播和普及。系统的建设还为相关政府部门制定民族服装产业扶持政策提供了数据参考,有利于推动民族服装产业的健康发展和文化传承;从社会价值角度来看,该系统有助于提升社会对民族服装文化的认知度和重视程度,为传统文化的保护传承和创新发展贡献力量。
2、民族服装数据分析系统-研究内容
1、民族服装数据分析系统需求调研与总体设计:深入分析传统民族服装行业信息化程度低、数据分散的现状问题,通过市场调研和用户访谈收集民族服装商家和消费者的实际需求。基于Django MVT架构模式设计系统整体框架,采用前后端分离的技术路线构建Web应用架构,制定MySQL数据库设计方案和RESTful API接口标准;运用UML建模技术绘制系统用例图、类图、序列图等设计文档,结合Hadoop+Spark大数据处理架构规划数据流转和分析流程,确保系统架构具备良好的扩展性和稳定性,为民族服装数据分析功能的实现提供技术保障。
2、用户端Web应用开发与功能实现:基于Django模板引擎和Bootstrap响应式框架构建用户端Web界面,实现用户注册登录、个人信息管理、民族服装浏览查看等基础功能模块。开发民族服装信息展示系统,支持按民族分类、价格区间、地区分布等多维度检索和筛选功能;构建服装资讯模块,提供行业动态、文化背景、搭配技巧等内容展示。集成个人收藏功能,允许用户保存感兴趣的服装信息并进行分类管理,通过Ajax异步交互技术提升页面响应速度和用户操作体验,打造便捷高效的民族服装信息获取平台。
3、数据采集处理与后端服务构建:运用Python爬虫技术开发多平台数据采集模块,实现电商网站民族服装商品信息的自动化抓取和数据清洗处理。基于Django REST framework搭建后端API服务系统,提供用户认证、数据查询、业务逻辑处理等核心功能接口;设计MySQL数据库表结构,包含用户信息表、服装数据表、收藏记录表、资讯内容表等关键数据表,通过Django ORM框架实现数据持久化操作。建立Hadoop分布式文件系统存储海量爬虫数据,利用Spark计算引擎完成数据预处理、特征提取、统计分析等大数据处理任务,确保系统能够高效处理和分析大规模民族服装数据。
4、管理员后台系统与数据可视化开发:采用Django Admin框架构建管理员后台管理系统,实现用户账户管理、民族服装信息维护、系统配置等管理功能。开发数据统计分析模块,支持服装销量统计、价格趋势分析、用户行为分析等数据挖掘功能;构建大屏数据可视化展示系统,运用ECharts图表库实现价格分布情况、地区销售统计、支付方式分析、商家商品分布、民族分类统计等多维度数据展示。集成Spark MLlib机器学习库进行数据挖掘和预测分析,为管理决策提供科学的数据支撑,帮助管理员全面掌握民族服装市场动态和发展趋势。
5、系统集成测试与性能优化:完成各功能模块开发后,进行前后端集成联调测试,验证爬虫数据采集的准确性和API接口调用的稳定性。设计涵盖功能测试、性能测试、数据一致性测试、安全性测试的完整测试体系,通过单元测试、集成测试、压力测试等多层次测试手段确保系统质量;针对大数据处理响应时间、并发用户访问能力、数据库查询效率等关键性能指标进行调优,建立系统监控预警机制和异常恢复策略。部署Redis缓存系统提升数据访问速度,优化Spark作业配置参数提高数据处理效率,确保民族服装数据分析系统能够稳定可靠地服务于实际业务场景。
3、民族服装数据分析系统-开发技术与环境
1、开发环境: Python环境,pycharm,mysql(5.7或者8.0)
2、技术栈:Python+Djingo+爬虫,hadoop+spark
4、民族服装数据分析系统-功能介绍
2个角色:用户/管理员(亮点:爬虫、大屏可视化)
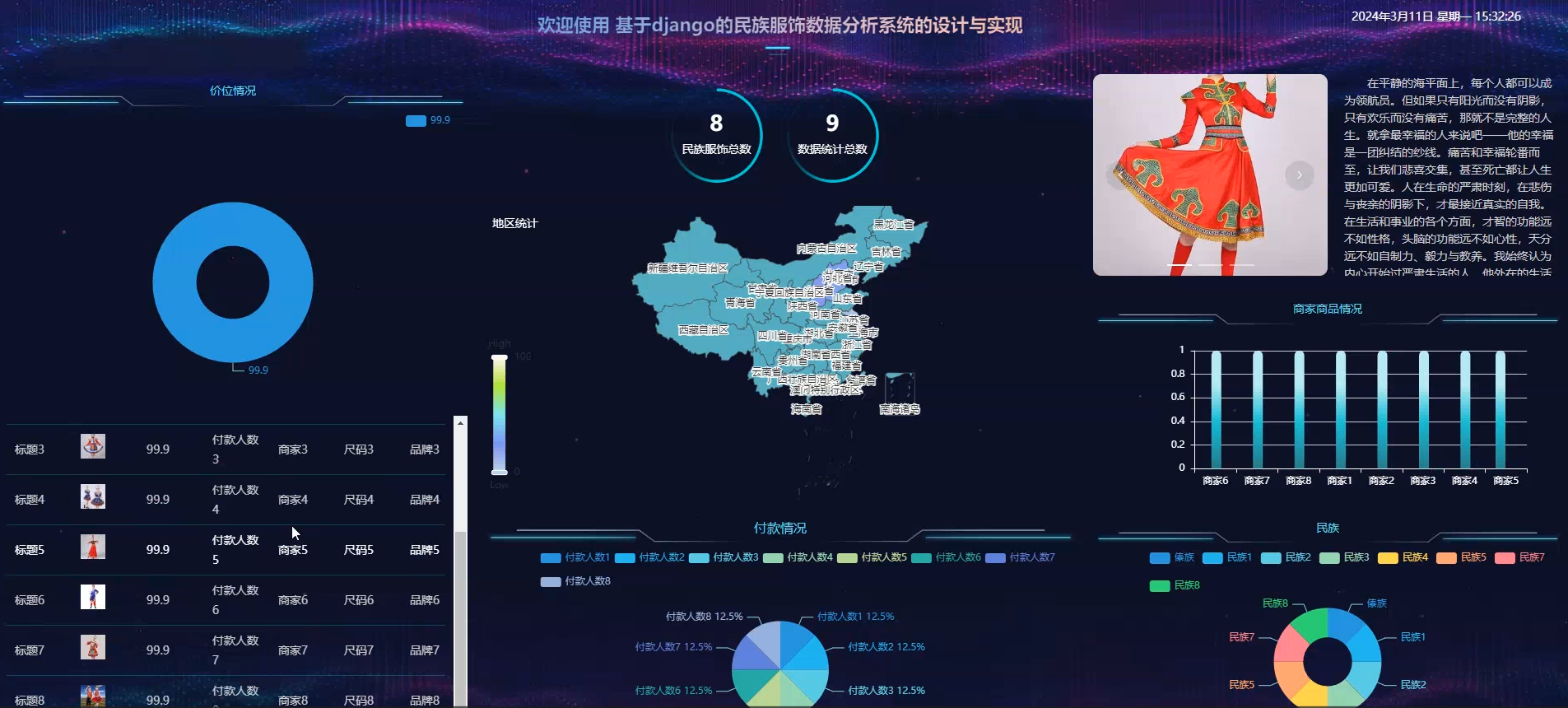
用户:登录注册、查看民族服装、服装资讯、我的收藏 大屏可视化(价格情况、地区统计、付款情况、商家商品情况、民族)
管理员:用户管理、民族服装管理、数据统计管理、个人中心、系统管理
5、民族服装数据分析系统-成果展示
5.1演示视频
基于django的民族服装数据分析系统的设计与实现 spark爬虫民族服装数据采集 大数据可视化
5.2演示图片
1、用户端页面:
☀️登录注册☀️
☀️查看民族服装☀️
☀️查看服装资讯☀️
☀️我的收藏☀️
2、管理员端页面:
☀️用户管理☀️
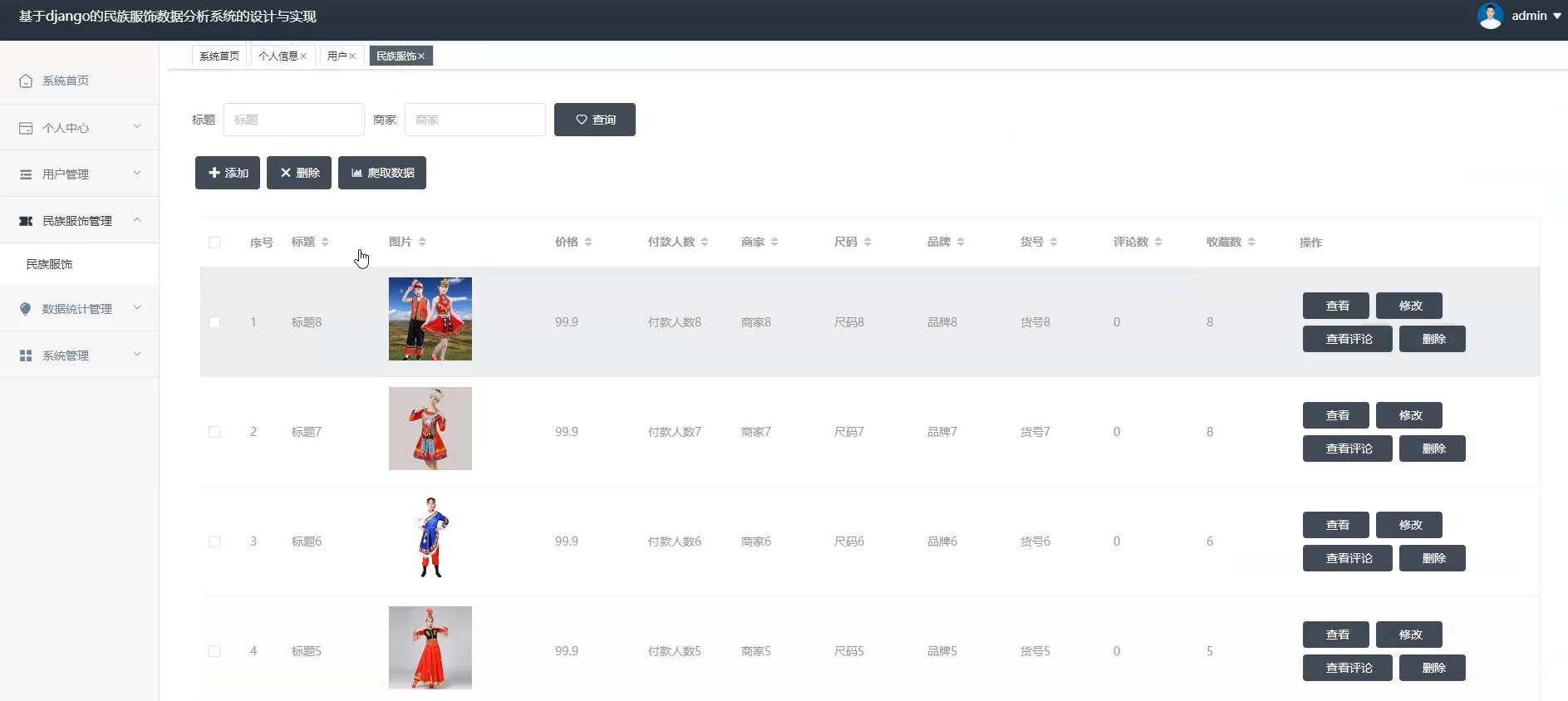
☀️民族服装管理☀️
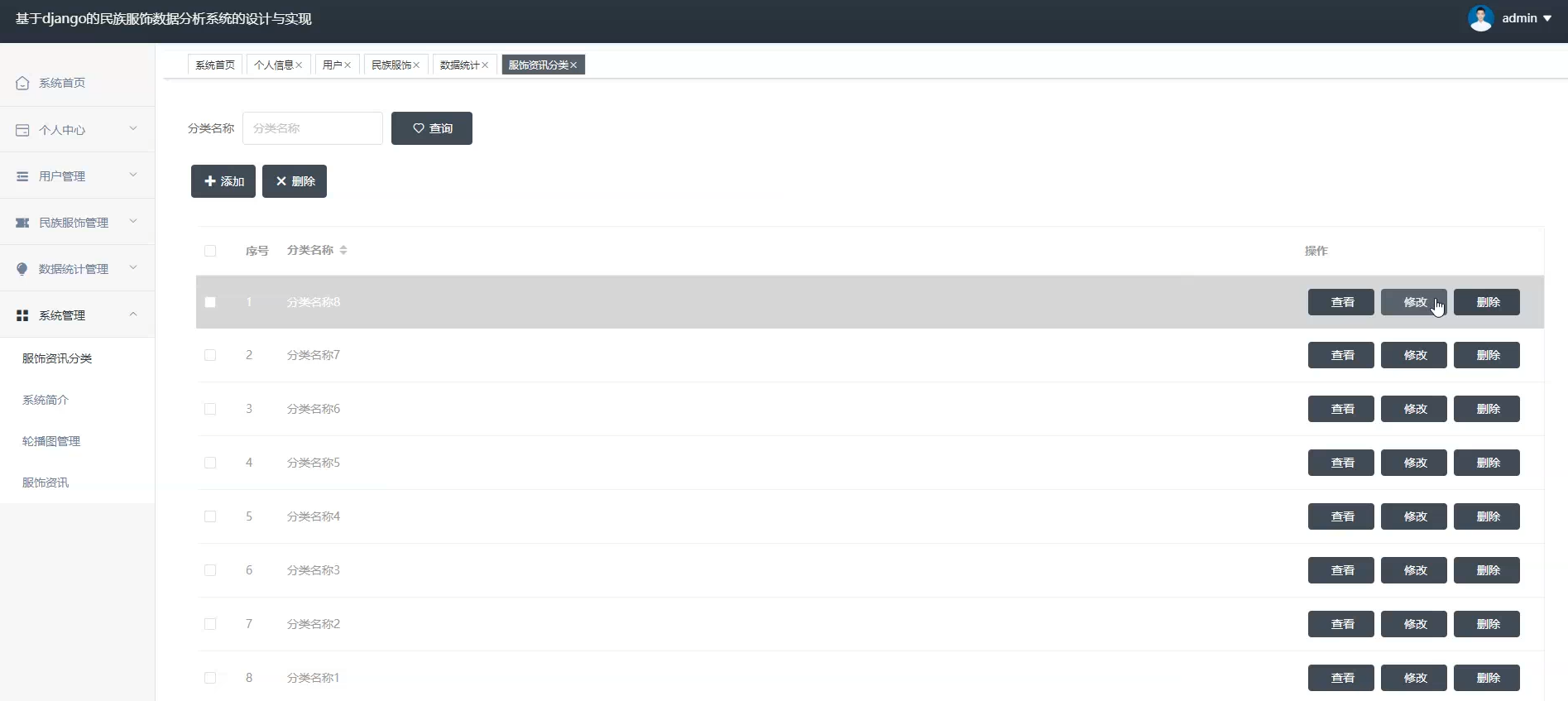
☀️系统管理☀️
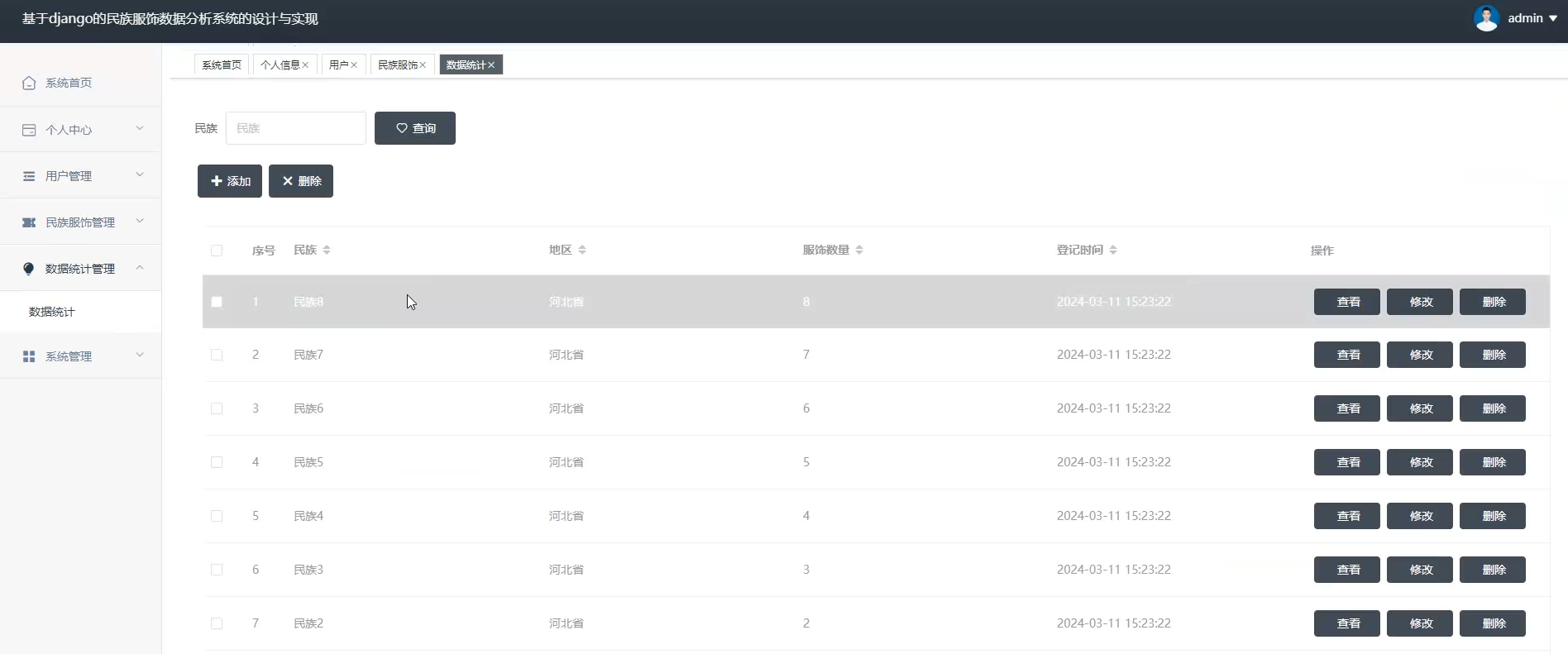
☀️数据统计管理☀️
☀️数据可视化☀️
民族服装数据分析系统-代码展示
1.数据爬虫【代码如下(示例):】
class EthnicClothingSpider:
def __init__(self):
self.session = requests.Session()
self.setup_headers()
self.setup_logging()
self.setup_database()
def setup_headers(self):
"""设置请求头,模拟正常浏览器访问"""
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
}
self.session.headers.update(self.headers)
def setup_logging(self):
"""设置日志记录"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('spider.log', encoding='utf-8'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
def setup_database(self):
"""设置数据库连接"""
try:
self.db_config = {
'host': 'localhost',
'user': 'root',
'password': 'your_password',
'database': 'ethnic_clothing_db',
'charset': 'utf8mb4'
}
self.connection = pymysql.connect(**self.db_config)
self.cursor = self.connection.cursor()
self.create_tables()
except Exception as e:
self.logger.error(f"数据库连接失败: {e}")
def create_tables(self):
"""创建数据表"""
create_table_sql = """
CREATE TABLE IF NOT EXISTS ethnic_clothing (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(255) NOT NULL,
price DECIMAL(10,2),
original_price DECIMAL(10,2),
brand VARCHAR(100),
category VARCHAR(100),
ethnic_type VARCHAR(50),
description TEXT,
image_urls TEXT,
shop_name VARCHAR(100),
location VARCHAR(100),
sales_count INT DEFAULT 0,
rating DECIMAL(3,1),
url VARCHAR(500),
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
platform VARCHAR(50)
)
"""
try:
self.cursor.execute(create_table_sql)
self.connection.commit()
self.logger.info("数据表创建成功")
except Exception as e:
self.logger.error(f"数据表创建失败: {e}")
def get_selenium_driver(self):
"""获取Selenium浏览器驱动"""
chrome_options = Options()
chrome_options.add_argument('--headless') # 无头模式
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--window-size=1920,1080')
try:
driver = webdriver.Chrome(options=chrome_options)
return driver
except Exception as e:
self.logger.error(f"浏览器驱动初始化失败: {e}")
return None
def random_delay(self, min_delay=1, max_delay=3):
"""随机延时,避免被反爬虫检测"""
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)
def safe_request(self, url, retries=3):
"""安全的HTTP请求,包含重试机制"""
for attempt in range(retries):
try:
self.random_delay()
response = self.session.get(url, timeout=10)
response.raise_for_status()
return response
except requests.exceptions.RequestException as e:
self.logger.warning(f"请求失败 (尝试 {attempt + 1}/{retries}): {e}")
if attempt == retries - 1:
self.logger.error(f"请求最终失败: {url}")
return None
return None
2.数据清洗【代码如下(示例):】
class EthnicClothingDataCleaner:
def __init__(self):
self.setup_logging()
self.setup_database()
self.init_cleaning_rules()
self.init_spark()
def setup_logging(self):
"""配置日志系统"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('data_cleaning.log', encoding='utf-8'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
def setup_database(self):
"""数据库连接配置"""
self.db_config = {
'host': 'localhost',
'user': 'root',
'password': 'your_password',
'database': 'ethnic_clothing_db',
'charset': 'utf8mb4'
}
def init_spark(self):
"""初始化Spark会话"""
try:
self.spark = SparkSession.builder \
.appName("EthnicClothingDataCleaning") \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.adaptive.coalescePartitions.enabled", "true") \
.getOrCreate()
self.logger.info("Spark会话初始化成功")
except Exception as e:
self.logger.error(f"Spark初始化失败: {e}")
self.spark = None
def init_cleaning_rules(self):
"""初始化数据清洗规则"""
# 民族服装类型标准化映射
self.ethnic_type_mapping = {
'汉服': ['汉服', '汉装', '华服', '襦裙', '齐胸襦裙', '交领襦裙', '唐装'],
'藏服': ['藏服', '藏装', '藏族服装', '藏袍', '邦典'],
'维族服装': ['维族', '维吾尔', '新疆服装', '维族服装', '维吾尔族服装'],
'蒙古服装': ['蒙古', '蒙族', '草原服装', '蒙古袍', '德勒'],
'苗族服装': ['苗族', '苗服', '银饰服装', '苗族盛装'],
'彝族服装': ['彝族', '彝服', '彝族服装'],
'壮族服装': ['壮族', '壮服', '壮族服装'],
'回族服装': ['回族', '回服', '回族服装'],
'满族服装': ['满族', '旗袍', '马褂', '满族服装', '清装'],
'朝鲜族服装': ['朝鲜族', '韩服', '朝鲜族服装', '朝服'],
'傣族服装': ['傣族', '傣服', '傣族服装'],
'土家族服装': ['土家族', '土家服装'],
'哈萨克服装': ['哈萨克', '哈萨克族服装'],
'其他民族': ['民族服装', '少数民族', '传统服装']
}
# 地区标准化映射
self.location_mapping = {
'北京': ['北京', '北京市', 'beijing'],
'上海': ['上海', '上海市', 'shanghai'],
'广东': ['广东', '广州', '深圳', '东莞', '佛山', 'guangdong'],
'浙江': ['浙江', '杭州', '宁波', '温州', 'zhejiang'],
'江苏': ['江苏', '南京', '苏州', '无锡', 'jiangsu'],
'山东': ['山东', '济南', '青岛', '烟台', 'shandong'],
'河南': ['河南', '郑州', '洛阳', 'henan'],
'四川': ['四川', '成都', 'sichuan'],
'湖南': ['湖南', '长沙', 'hunan'],
'湖北': ['湖北', '武汉', 'hubei'],
'新疆': ['新疆', '乌鲁木齐', 'xinjiang'],
'西藏': ['西藏', '拉萨', 'tibet', 'xizang'],
'云南': ['云南', '昆明', 'yunnan'],
'贵州': ['贵州', '贵阳', 'guizhou'],
'内蒙古': ['内蒙古', '呼和浩特', 'neimenggu']
}
# 品牌标准化映射
self.brand_mapping = {
'重回汉唐': ['重回汉唐', 'chonghuihantang'],
'如梦霓裳': ['如梦霓裳', 'rumengnic', '如梦'],
'汉尚华莲': ['汉尚华莲', 'hanshanghualian'],
'花朝记': ['花朝记', 'huachaoji'],
'十三余': ['十三余', '13yu'],
'兰若庭': ['兰若庭', 'lanruoting'],
'梨花渡': ['梨花渡', 'lihuadu'],
'织造司': ['织造司', 'zhizaosi']
}
# 停用词列表
self.stop_words = set([
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一',
'一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有',
'看', '好', '自己', '这', '件', '衣服', '服装', '穿', '买', '购买'
])
def load_data_from_db(self):
"""从数据库加载原始数据"""
try:
connection = pymysql.connect(**self.db_config)
query = "SELECT * FROM ethnic_clothing"
df = pd.read_sql(query, connection)
connection.close()
self.logger.info(f"从数据库加载数据成功,共 {len(df)} 条记录")
return df
except Exception as e:
self.logger.error(f"数据库加载失败: {e}")
return pd.DataFrame()
def load_data_from_csv(self, filepath):
"""从CSV文件加载数据"""
try:
df = pd.read_csv(filepath, encoding='utf-8')
self.logger.info(f"从CSV加载数据成功,共 {len(df)} 条记录")
return df
except Exception as e:
self.logger.error(f"CSV加载失败: {e}")
return pd.DataFrame()
微信小程序智慧物业系统-结语(文末获取源码)
💕💕
java精彩实战毕设项目案例
小程序精彩项目案例
Python精彩项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)