
Flink standalone 集群会话模式部署搭建
1、下载 flink-1.17.0-bin-scala_2.12.tgz 放到指定的目录下,然后解压。启动成功后,可以访问 http://hadoop:8081 对 flink 集群和任务进行监控管理。如果执行报错,bash: jps: command not found, 则需要在各个节点上执行。2、flink-1.17.0-bin-scala_2.12.tgz 安装包,节点服务器的 flink
环境准备
1、Centos7集群环境搭建
2、flink-1.17.0-bin-scala_2.12.tgz 安装包,下载地址
规划
| 服务器 | 角色 | ip |
|---|---|---|
| hadoop01 | JobManager TaskManager | 192.168.140.132 |
| hadoop02 | TaskManager | 192.168.140.133 |
| hadoop03 | TaskManager | 192.168.140.134 |
安装
1、下载 flink-1.17.0-bin-scala_2.12.tgz 放到指定的目录下,然后解压。
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /root/software
2、修改集群配置信息。
1)进入解压的目录下的 conf 路径,修改 flink-conf.yaml 文件。修改内容如下:
# JobManager 节点地址
jobmanager.rpc.address: hadoop01
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop01
rest.bind-address: 0.0.0.0
# TaskManager 节点地址, 配置为当前主机名
taskmanager.host: hadoop01
taskmanager.bind-host: 0.0.0.0
2)修改 workers 文件,指定 hadoop01 、hadoop02 、hadoop03 为 TaskManager
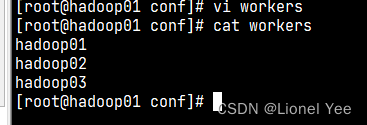
3) 修改 masters 文件

4)在 flink-conf.yaml 文件中还可以对集群中的 JobManager 和 TaskManager 组件进行优化配置,主要配置项如下:
- jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1728M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个 TaskManage r能够分配的 Slot 数量进行配置,默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓 Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink 任务执行的并行度,默认为 1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
3、分发安装目录
1)xsync 脚本编写
由于 xsync 是对 rsync 的再封装,因此需要先安装 rsync :yum install -y rsync
新建 xsync.sh, 将以下内容粘贴到 xsync.sh 脚本中。
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop02 hadoop03
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
赋予执行权限 chmod 777 xsync.sh
2)分发 flink
./xsync.sh flink-1.17.0/
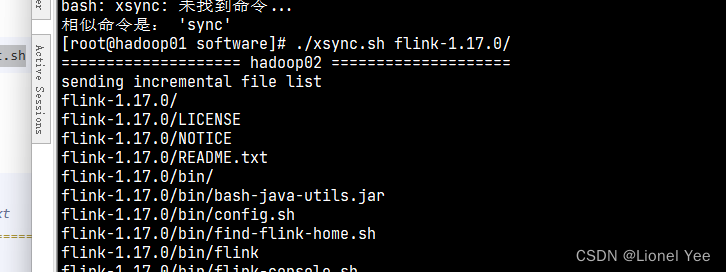
- 修改
hadoop02和 的hadoop03的flink-conf.yaml中的taskmanager.host,修改为本机主机名。
taskmanager.host: hadoop02
taskmanager.host: hadoop03
4、启动集群
在 hadoop01 节点服务器的 flink 的 bin 目录下,执行 ./start-cluster.sh 启动集群。
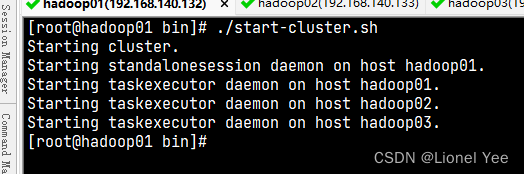
查看进程信息:
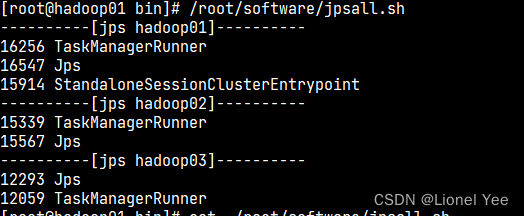
编写
jpsall.sh脚本,批量返回各个机器的 jps 命令返回值。
vijpsall.sh`,添加如下内容:#!/bin/bash for host in hadoop01 hadoop02 hadoop03 do echo "----------[jps $host]----------" ssh $host "jps" done赋予执行权限,
chmod +x jpsall.sh
如果执行报错,bash: jps: command not found, 则需要在各个节点上执行vi ~/.bashrc, 将 JAVA 环境变量加入到最后。如:export JAVA_HOME=/usr/java/jdk1.8.0_321 export PATH=$PATH:${JAVA_HOME}/bin
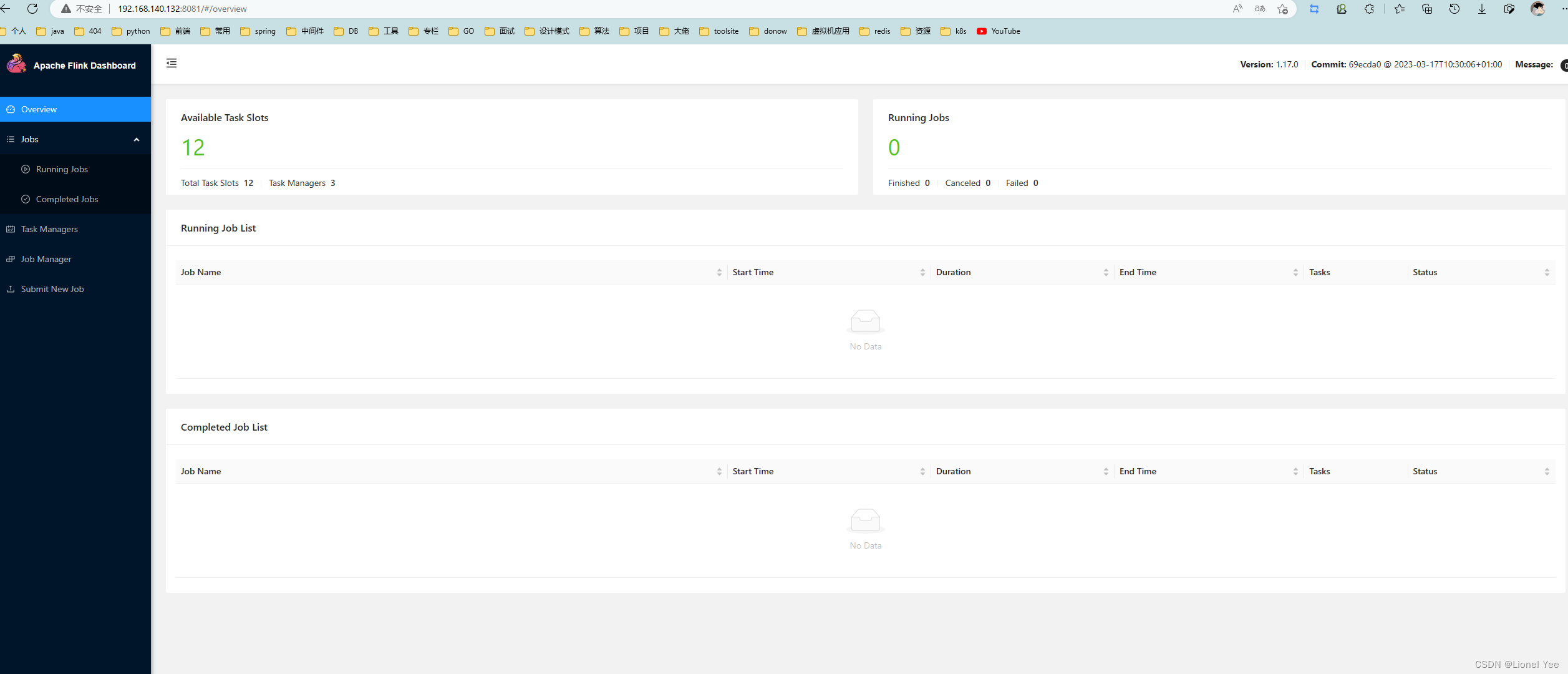
5、访问 Web UI
启动成功后,可以访问 http://hadoop:8081 对 flink 集群和任务进行监控管理。

大数据从业者之家,一起探索大数据的无限可能!
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)