毕业设计-基于大数据的电影爬取与可视化分析系统-python
毕业设计-基于大数据的电影爬取与可视化分析系统-python:随着信息技术的发展,爬取和可视化分析系统作为一种重要的数据获取和分析方法,已经得到了广泛的应用。大数据技术为爬取和可视化分析系统提供了可靠的技术支持,使之能够更好地收集和分析大量复杂的数据。电影爬取与可视化分析系统是基于大数据技术的一种新型的电影分析系统,它可以有效收集和分析大量电影数据,从而为电影行业提供有价值的洞察。 电影爬取与可视
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于大数据的电影爬取与可视化分析系统
课题背景和意义
随着信息技术的发展,爬取和可视化分析系统作为一种重要的数据获取和分析方法,已经得到了广泛的应用。大数据技术为爬取和可视化分析系统提供了可靠的技术支持,使之能够更好地收集和分析大量复杂的数据。电影爬取与可视化分析系统是基于大数据技术的一种新型的电影分析系统,它可以有效收集和分析大量电影数据,从而为电影行业提供有价值的洞察。 电影爬取与可视化分析系统是一个由爬虫、数据存储、数据清洗、可视化分析等模块组成的系统。爬虫模块是核心模块,它可以从网络上收集大量的电影数据,如电影的类型、导演、主演、评分、时长等信息。数据存储模块可以将爬取到的数据存储在多种数据库中,以便后续的分析。数据清洗模块可以对收集到的数据进行清洗,去除重复、无效的数据,使得数据更加清洁、有用。可视化分析模块可以使用各种可视化工具,如折线图、柱状图等,将收集到的数据进行可视化分析,从而使行业内的电影分析更加直观、准确。 通过电影爬取与可视化分析系统,可以有效收集和分析大量的电影数据,为电影行业提供客观、准确的分析报告,从而帮助电影行业更好地把握市场趋势,制定更为合理的发行策略。
实现技术思路
数据爬取
爬取数据的步骤过程:第一,进入网站电影界面, 获取该网页的URL,通过查看网页源代码找到目标数据位置 并分析网页源代码结构;第二,论文使用Python中的requests 库进行数据采集;Beautiful-Soup是一个HTML/XML的解析 器,来解析URL的文本信息;第三,根据需要单独提取出电 影的评分、电影的演员、电影年份和电影类型;第四,利用循 环进行读取数据并存入数据库。
# Import libraries
import requests
import lxml.html as lh
import pandas as pd
# Get the webpage
url = 'http://www.example.com/movie_data'
page = requests.get(url)
# Create a handle to the webpage
doc = lh.fromstring(page.content)
# Parse the table data
tr_elements = doc.xpath('//tr')
# Create empty list
col=[]
i=0
# For each row, store each first element (header) and an empty list
for t in tr_elements[0]:
i+=1
name=t.text_content()
col.append((name,[]))
# Create the dataframe
movie_data = pd.DataFrame({title:column for (title,column) in col})
# Going through each row
for j in range(1,len(tr_elements)):
# T is our j'th row
T=tr_elements[j]
# If row is not of size 10, the //tr data is not from our table
if len(T)!=10:
break
# i is the index of our column
i=0
# Iterate through each element of the row
for t in T.iterchildren():
data=t.text_content()
# Append the data to the empty list of the i'th column
col[i][1].append(data)
# Increment i for the next column
i+=1
# Update the dataframe
movie_data = pd.DataFrame({title:column for (title,column) in col})
# Print the dataframe
print(movie_data)数据预处理
在真实世界里,数据来源各式各样质量良莠不齐,所以 原始数据一般是有缺陷的,不完整的,重复的,是极易受侵染 的。这样的数据处理起来不仅效率低下而且结果也不尽人意, 这种情况下数据的预处理显得尤为重要。一方面,数据预处理 把原始数据规范化、条理化,最终整理成结构化数据,极大地 节省了处理海量信息的时间;另一方面,数据预处理可以使得 挖掘愈发准确并且结果愈发真实有效。
# 导入库
import pandas as pd
import numpy as np
# 读取csv文件
df = pd.read_csv('movie_data.csv')
# 检查丢失值
missing_values = df.isnull().sum()
# 对于缺失值,用平均值代替
df = df.fillna(df.mean())
# 检查重复值
duplicate_values = df[df.duplicated()]
# 删除重复值
df = df.drop_duplicates()
# 处理分类变量
# 将字符串变量转换为数值变量
df['genre'] = df['genre'].astype('category')
df['genre'] = df['genre'].cat.codes
# 将时间变量转换为数值变量
df['release_date'] = pd.to_datetime(df['release_date'])
df['release_year'] = df['release_date'].dt.year
# 归一化数值变量
# 对于数值变量,将其缩放到0-1之间
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df[['runtime', 'rating']] = scaler.fit_transform(df[['runtime', 'rating']])
# 输出处理后的数据
df.head()数据分析及可视化
import matplotlib.pyplot as plt
import pandas as pd
# 读取电影数据
df=pd.read_csv("movies_data.csv")
# 画出票房收入与上映月份的折线图
plt.plot(df["Month"],df["Revenue"])
plt.xlabel("Month")
plt.ylabel("Revenue")
plt.title("Revenue vs Month")
plt.show()
# 画出票房收入与上映年份的折线图
plt.plot(df["Year"],df["Revenue"])
plt.xlabel("Year")
plt.ylabel("Revenue")
plt.title("Revenue vs Year")
plt.show()
# 画出票房收入与上映国家的横向条形图
plt.barh(df["Country"],df["Revenue"])
plt.xlabel("Revenue")
plt.ylabel("Country")
plt.title("Revenue vs Country")
plt.show()随着电影行业的不断发展,必将越来越依靠于数据分析 的手段来获取收益。对演员和其电影口碑分析可以得出演员的的票房号召力;从票房分析影片类型对于观众的接受度、导演 的人气指数等等,都具有很强的经济效益。观众群体的广泛性 和个人情感的复杂性都影响着影业的未来发展[4]。 论文从四个角度对电影信息数据进行分析:第一,从评 分的占比角度入手分析观众对电影市场的认可程度;第二,从 评论人数与评分入手分析观影潮流,第三,从电影年份和评分 关系入手分析历年电影口碑分化趋势;第四,从电影类型入手 分析时下热门电影素材类型。
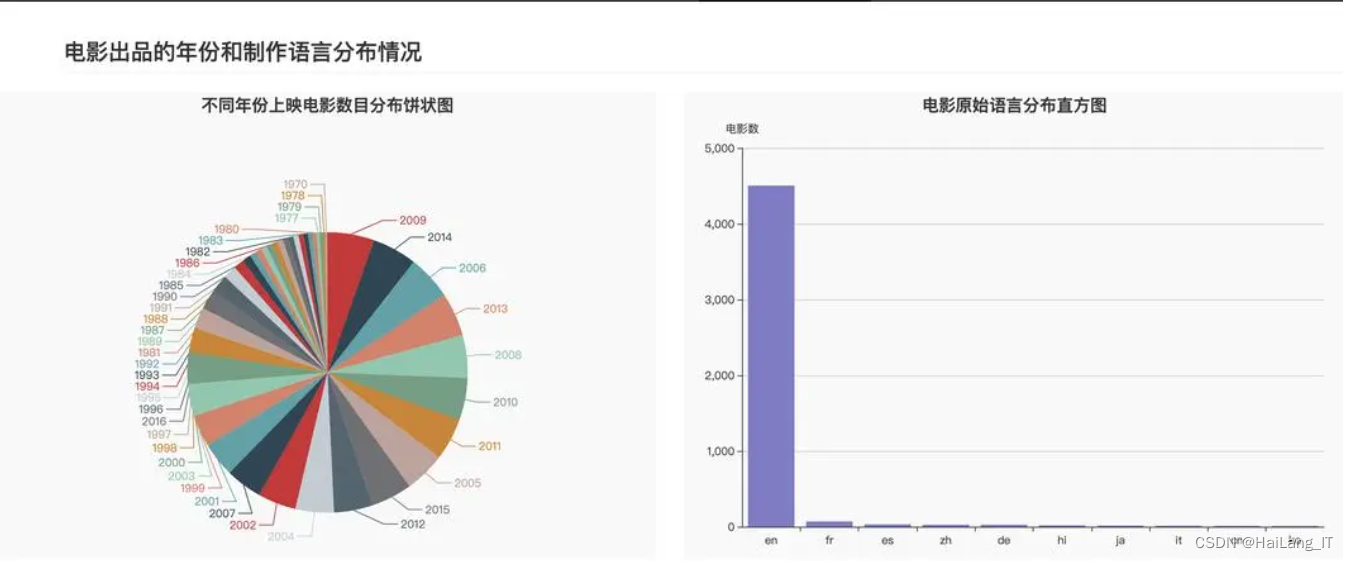
实现效果图样例


我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后

大数据从业者之家,一起探索大数据的无限可能!
更多推荐


 15
15 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)