足球大数据之机器学习预测大小球
在专攻胜平负大数据预测的几年时间里,积累了大量特征向量、参数标定,分析冷门、下盘和半球以内的胜平负准确率高于75%,综合预测准确率达到85%左右。突然转到预测大小球只有2个结果,一时感觉简单了许多。下面谈谈大小预测的认识:
目录
感谢华为云开发联盟收录我的多篇文章,有动力续写足球预测相关话题了。:)
0. 介绍
大小球预测是北京单场玩法中上下单双类别,与进球数玩法相互对应。
在专攻胜平负大数据预测的几年时间里,积累了大量特征向量、参数标定,分析冷门、下盘和半球以内的胜平负准确率高于75%,综合预测准确率达到85%左右。突然转到预测大小球只有2个结果,一时感觉简单了许多。下面谈谈大小预测的认识:
1. 机器学习之大小预测的目标
公司有两个海龟专攻大小预测,一个英国另一个澳大利亚,都是学算法,起初觉得很简单,在网上搜索如何通过足球基本面在预测大小的资料,再结合各公司的历史盘口,用Linear / logistic regression、Decision trees、RF、ANN、Catboost、Bayes、SVM算法及其改进算法试了个遍,最终理想的预测准确率在65%左右,当把准确率上调至80%以上时,所选的比赛场次非常少,一天就1、2场,甚至还没有,如果出现2天错误,基本就废掉了。
公司还有几个数学专业的研究生后来也参与了大小预测,从离散分布,K线分析、欧亚走势、均差、偏态、峰值、波动、方波这类出发,搞出来的结果不稳定。
大小球预测看似准确率能达到65%也够了,理论可以做到盈利,但在实际操作中很难。普通人花点时间通过常规基本面的比较筛选出60%的胜率也不难。如果模型做出来的准确率未达到70%,次数多了不会亏很多,但是绝对赢不了。
2. 机器学习之大小预测的输出结果分类
大小球预测按照给定的盘口分类划为大和小两种类型。
3. 机器学习的特征向量选择
(1)基本面
主要分析近几轮比赛中,主客两队独自情况和交战情况。 主要计算平均进球数、失球数。
网络上没有人提及但更重要的指标如:最大进球数、最小进球数及其间隔周期、统计进球数的方差和标准差,也需要纳入计算考量,需要基础数据库可以联系。具体计算程序编写并不难:
def jisuan(finaldata,group12,num,how2):
group13 = group12.groupby(['gameid']).apply(lambda x: x.zongjin.mean())
df1 = group13.to_frame().reset_index()
df1.rename(columns={0: 'avg%s'%(num+how2)}, inplace=True)
finaldata = pd.merge(finaldata, df1, on='gameid', how='left')
group13 = group12.groupby(['gameid']).apply(lambda x: x.zongjin.min())
df1 = group13.to_frame().reset_index()
df1.rename(columns={0: 'min%s'%(num+how2)}, inplace=True)
finaldata = pd.merge(finaldata, df1, on='gameid', how='left')
group13 = group12.groupby(['gameid']).apply(lambda x: x.zongjin.max())
df1 = group13.to_frame().reset_index()
df1.rename(columns={0: 'max%s'%(num+how2)}, inplace=True)
finaldata = pd.merge(finaldata, df1, on='gameid', how='left')
group13 = group12.groupby(['gameid']).apply(lambda x: str(x.zongjin.tolist()))
df1 = group13.to_frame().reset_index()
df1.rename(columns={0: 'stauts%s'%(num+how2)}, inplace=True)
finaldata = pd.merge(finaldata, df1, on='gameid', how='left')
###无偏方差:统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数
group13 = group12.groupby(['gameid']).apply(lambda x: round(x.zongjin.var(), 2))
df1 = group13.to_frame().reset_index()
df1.rename(columns={0: 'var%s'%(num+how2)}, inplace=True)
finaldata = pd.merge(finaldata, df1, on='gameid', how='left')
###有偏方差:统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数
group13 = group12.groupby(['gameid']).apply(lambda x: round(x.zongjin.values.var(), 2))
df1 = group13.to_frame().reset_index()
df1.rename(columns={0: 'var1%s'%(num+how2)}, inplace=True)
finaldata = pd.merge(finaldata, df1, on='gameid', how='left')
###无偏标准差
group13 = group12.groupby(['gameid']).apply(lambda x: round(x.zongjin.std(), 2))
df1 = group13.to_frame().reset_index()
df1.rename(columns={0: 'std%s'%(num+how2)}, inplace=True)
finaldata = pd.merge(finaldata, df1, on='gameid', how='left')
###有偏标准差
group13 = group12.groupby(['gameid']).apply(lambda x: round(x.zongjin.values.std(), 2))
df1 = group13.to_frame().reset_index()
df1.rename(columns={0: 'std1%s'%(num+how2)}, inplace=True)
finaldata = pd.merge(finaldata, df1, on='gameid', how='left')
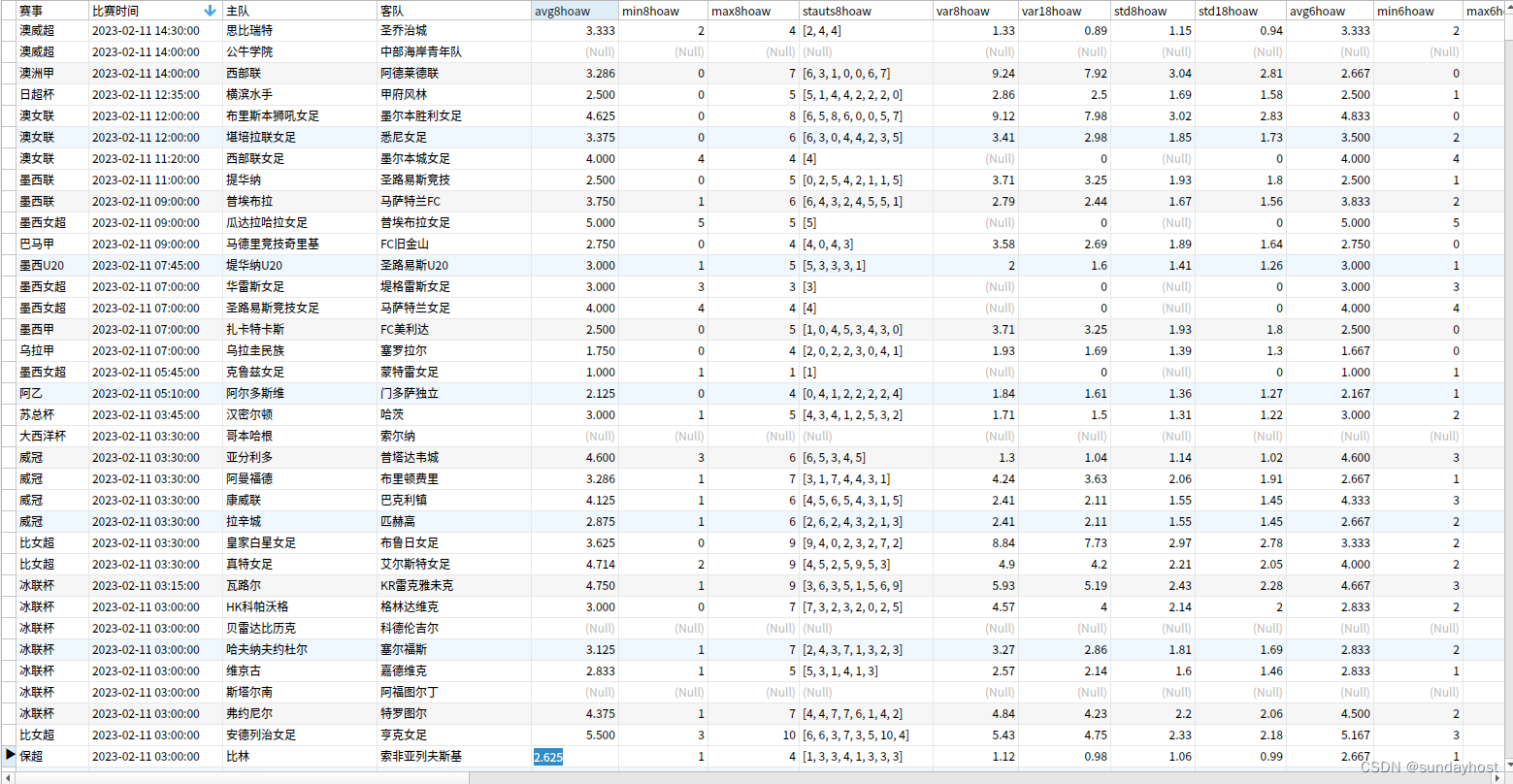
return finaldata最终将各场比赛主客队对应的进球数、失球数、平均值、最大/小值保存,得到:

通过进球个数序列和方差/标准茶,我们可以看出这支球队是否进球数是否稳定。这点非常重要。
(2)各公司的历史记录
做各公司的大小球历史统计,需要的和上文一样也是基础数据库,如果需要可以联系我。
通过调用基础数据库,记录不同公司各大小盘口下的情况。最终我们可以找出关键特征,如各公司不同赛事盘口下的大小情况,隐藏赛事后的结果如下:

(3)基本面加特征向量的处理
这里可以用随即森林、决策树来解决,有现成的模型包,不必展开细说。
4. 结论
当前,多个网站/app/公众号习惯用吸引眼球的标题宣称大小球准确率能达到很高,其实这是很难的,现在专心做模型算法研究的太少了,可笑的是大多数大师/公众号甚至连基础数据库都没有,仅凭借不成熟的技巧很难成功。做好大小球预测,基础数据库是前提,思路是关键,优化是细节,认真理解大小球的处理方式,才可能将准确率提高到理想状态。

大数据从业者之家,一起探索大数据的无限可能!
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)