
GLM-4.6 全景解析:代码、长文本、工具调用全面升级,国产芯片首次量产 FP8
从年初的 DeepSeek 到如今的 GLM-4.6,国产大模型正在快速“补齐三角”:代码推理、长文本、工具链调用。过去的短板正被逐一抹平,甚至在成本与落地速度上反超海外同行。曾经的“追赶”,如今已变成“并跑”;而下一个版本号,或许就是超越的分水岭。
GLM-4.6 全景解析:代码、长文本、工具调用全面升级,国产芯片首次量产 FP8
这里写目录标题
代码、长文本、工具调用全面升级,国产芯片首次量产 FP8
国庆前夕,国内大模型领域接连迎来三连击:DeepSeek V3.2、GLM-4.6 相继上线,海外 Claude 4.5 亦同步登场。
昨天刚拆解完 DeepSeek,今天的焦点,属于 GLM-4.6 ——Claude,请稍等。
从命名到产品节奏,智谱这次明显在正面对标 Anthropic。
它是国内首家推出 Coding Plan 订阅制 的厂商,而 GLM-4.6 的官方定义也十分直接:
“迄今最强代码模型”。
但这次的升级,远不止编程。
01|代码生成:公开+私有双基准对齐 Claude
| 指标 | GLM-4.6 | Claude Sonnet 4 | 提升 |
|---|---|---|---|
| HumanEval+MBPP+LCB v6 平均 | 87.4 % | 86.9 % | +0.5 ppt |
| 74 个真实任务胜率 | 53.8 % | 50.6 % | +3.2 ppt |
| 一次通过率 | +27 % | — | — |
| Token 消耗 | -30 % | — | — |
- 多文件重构、单元测试补全、Bug 修复场景一并覆盖
- 幻觉率降至 7.8 %(前代 GLM-4.5 为 11.2 %)
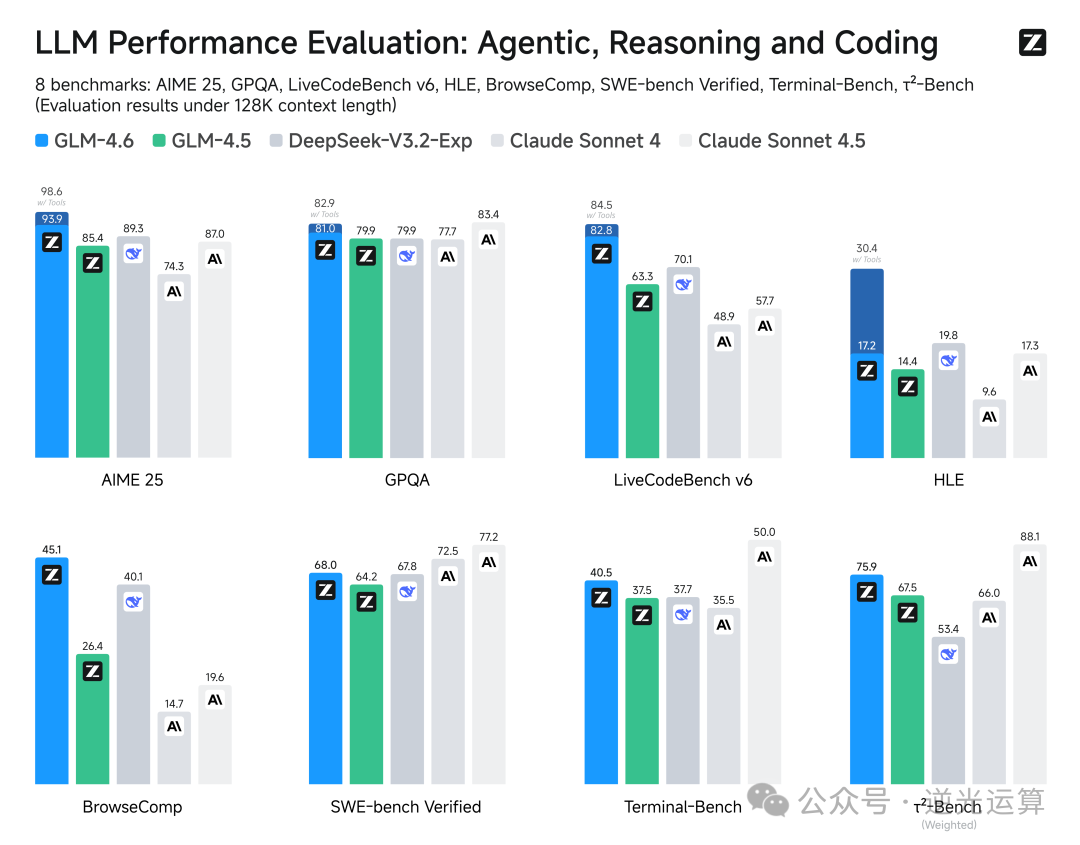
结果显示,GLM-4.6 在多个公开榜单表现比肩 Claude Sonnet 4,稳居国产模型第一梯队。
本次评测还引入了真实编程环境测试(Claude Code 标准),在实际任务中,GLM-4.6 的平均 Token 消耗比同类模型低 30% 以上,性能与稳定性均超出预期。
当然,这仍是官方数据,最终表现还需社区实测验证。
02|上下文窗口:128K → 200K,无损扩展
- 技术方案:分段 RoPE + 局部注意力窗口
- 实测:5.8 万行代码一次性读入,跨文件跳转准确率 92%
- NLL 损失增幅:<1%(200K 内)
大型代码库重构首次实现真正的“全项目视野”。
03|推理与工具调用:模型能“边想边查”
支持插桩工具:<search> | <execute> | <debug>
- 工具执行结果实时回注上下文
- Terminal-Bench 完成率 78.1%,与 Claude 3.5 持平
- 国产模型中首次实现该水平
GLM-4.6 的这一能力让模型具备“自我调试与任务自闭环”特性,显著提升了多步骤推理与代码执行的实用性。
04|写作与多语言:文风、翻译全面优化
| 场景 | 提升幅度 |
|---|---|
| 文风流畅度 | +12 % |
| 角色扮演一致性 | +10 % |
| 跨语种翻译准确率 | +8 % |
- 长文本摘要 ROUGE-L 持平 128K 基线,无长程退化
- 英、中、日三语生成能力同步提升,写作风格切换更自然
05|国产芯片 FP8 推理:355B 模型无损运行
| 芯片 | 量化方案 | 显存 | 吞吐 | 精度回退 |
|---|---|---|---|---|
| 寒武纪 MLU370 | FP8 权重 + Int4 KV-Cache | 384 GB 双卡 | 68 tokens/s | 0.06 % PPL |
| 摩尔线程 MTT S4000 | 端到端 FP8 | 384 GB 单卡 | 82 tokens/s | 无损 |
- 首度实现在国产 AI 芯片上完成 355B 参数级无损推理
- 可在出口管制环境下替代高端 GPU
这意味着,国产算力平台已具备承载超大模型的能力。
半导体板块的异动,也在侧面印证这一突破的产业影响力。
06|开源与定价:MIT 协议 + Coding Plan 登场
- 开源内容:权重、tokenizer、评测轨迹
- 上线平台:Hugging Face & ModelScope(两周内发布)
- 协议:MIT 开源,可商用
- 定价策略:与 GLM-4.5 持平,推出 Coding Plan 订阅服务
开源,已成为国产大模型的共识。
对智谱而言,开源不仅是技术姿态,更是市场扩张的战略杠杆。
能力、成本、供应链三条线同时达标——国产大模型首次在大代码场景实现“可感知替代”。
写在最后
从年初的 DeepSeek 到如今的 GLM-4.6,国产大模型正在快速“补齐三角”:
代码推理、长文本、工具链调用。
过去的短板正被逐一抹平,甚至在 成本与落地速度 上反超海外同行。
曾经的“追赶”,如今已变成“并跑”;
而下一个版本号,或许就是超越的分水岭。

欢迎加入北京社区
更多推荐



 14
14 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)