
Java EE:2.多线程-初阶(第七弹):多线程案例-阻塞队列
目录
书接上文:Java EE:2.多线程-初阶(第六弹)~
阶段性小结
单例模式=>典型的设计模式
一个进程中,包含唯一的实例对象
1)饿汉(创建早)
2)懒汉(创建迟)=>效率高
构造方法设为private
饿汉/懒汉=>线程安全?
饿汉=>只是读操作=>线程安全
懒汉=>涉及条件判断=>线程不安全
解决方式:
1)加锁,要把 if 和 new 都包含进去
2)双重 if 判定
3)volatile=>禁止指令重排序,保证内存可见性
a)创建内存
b)构造对象,初始化
c)把内存地址赋值给引用
面试技巧=>引导面试官提问
8.2阻塞队列
回顾队列:
队列:先进先出,很多场景下,尤其时现在搞后端开发,动不动
优先级队列:指定一个优先级(比较大小的规则),每次出队列都是优先级最高或最低的元素,底层结构是堆
阻塞队列是什么
阻塞队列,其实就是一种更复杂的队列
1.线程安全
2.阻塞特性
a)队列为空时,继续出队列就会阻塞,直到有其他线程往队列里添加元素(没了出不了)
b)队列为满时,继续入队列也会阻塞,直到有其他线程从队列中取走元素(满了加不了)
阻塞队列,一个最主要的应用场景,就是实现“生产者消费者模型”
生产者消费者模型
“生产者消费者模型”是多线程编程中,一种典型的开发模型
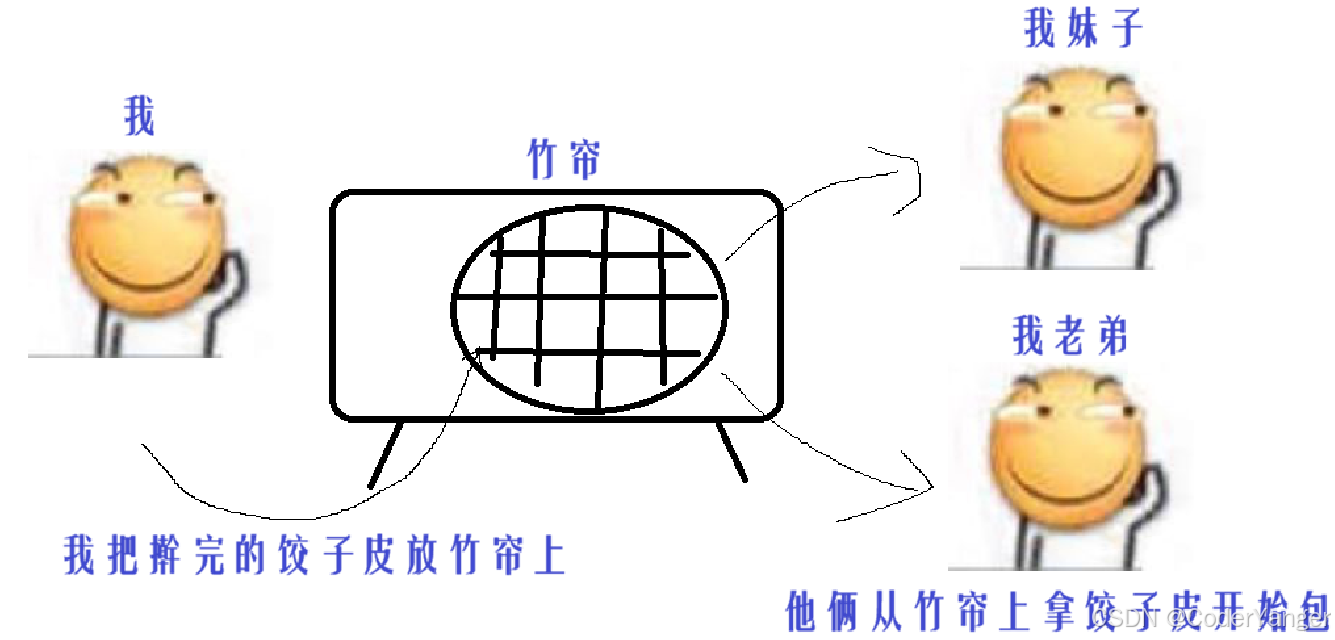
拿包饺子为例:我,我妹子,我老弟, 我仨一起包饺子~~
包饺子中有个环节:擀饺子皮、包饺子~
1)我们三个人,每个人都分别擀一个饺子皮儿,包一个饺子~~
那么我们三个就会竞争同一个资源=>擀面杖
2)我专门负责擀饺子皮,他俩负责包~~
这个过程就是一个典型的生产者消费者模型
资源=>饺子皮
我就是“生产者”
我妹子和我老弟就是“消费者”
竹帘就是“生产消费的交易场所”,此处的交易场所,就是一个阻塞队列(进行生产者和消费者之间相互交互数据的数据结构)
此处谈到的阻塞,是“极端情况”时,生产者和消费者之间速度不协调的时候才发生
换言之,阻塞的概率相比于1)会大大降低
两个重要优势~
1.解耦合
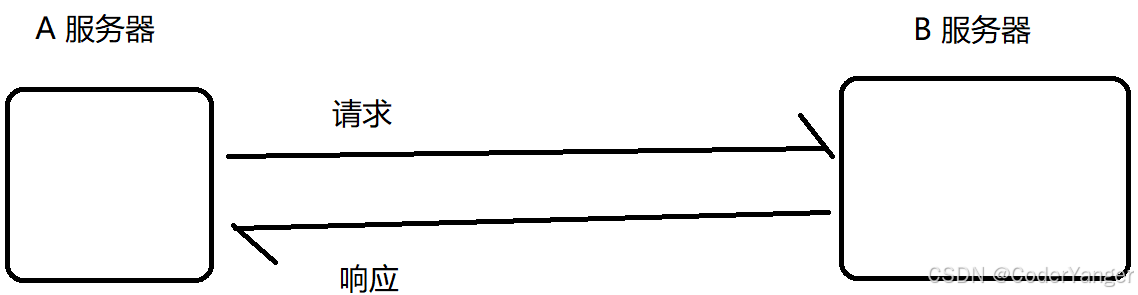
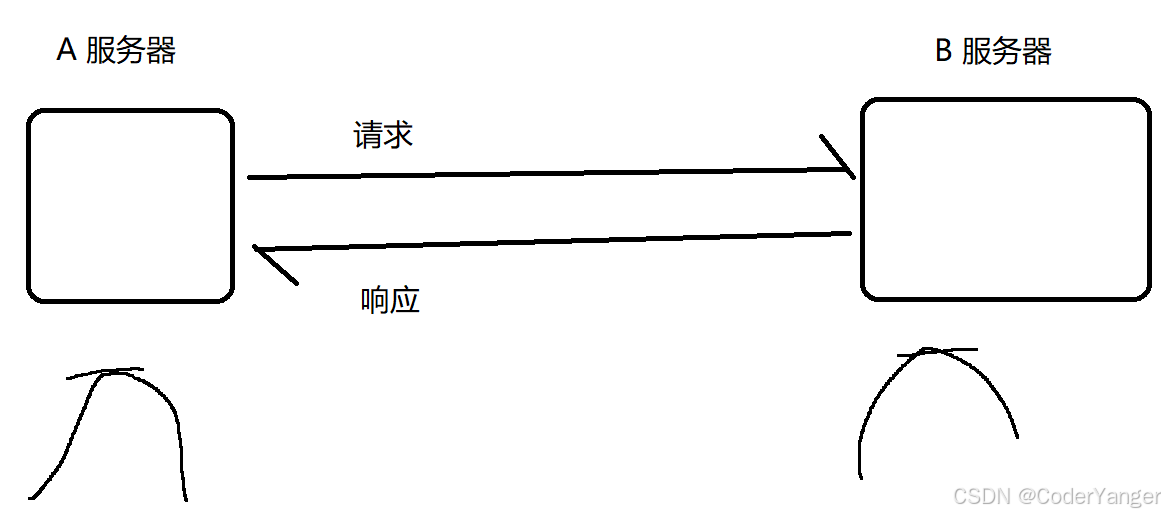
解耦合不一定是两个线程之间,也可以是两个服务器之间👇
如果是A直接访问B,此时A和B的耦合就更高
编写A的代码时,多多少少会有一些和B相关的逻辑
编写B的代码时,也会有一些A的相关逻辑
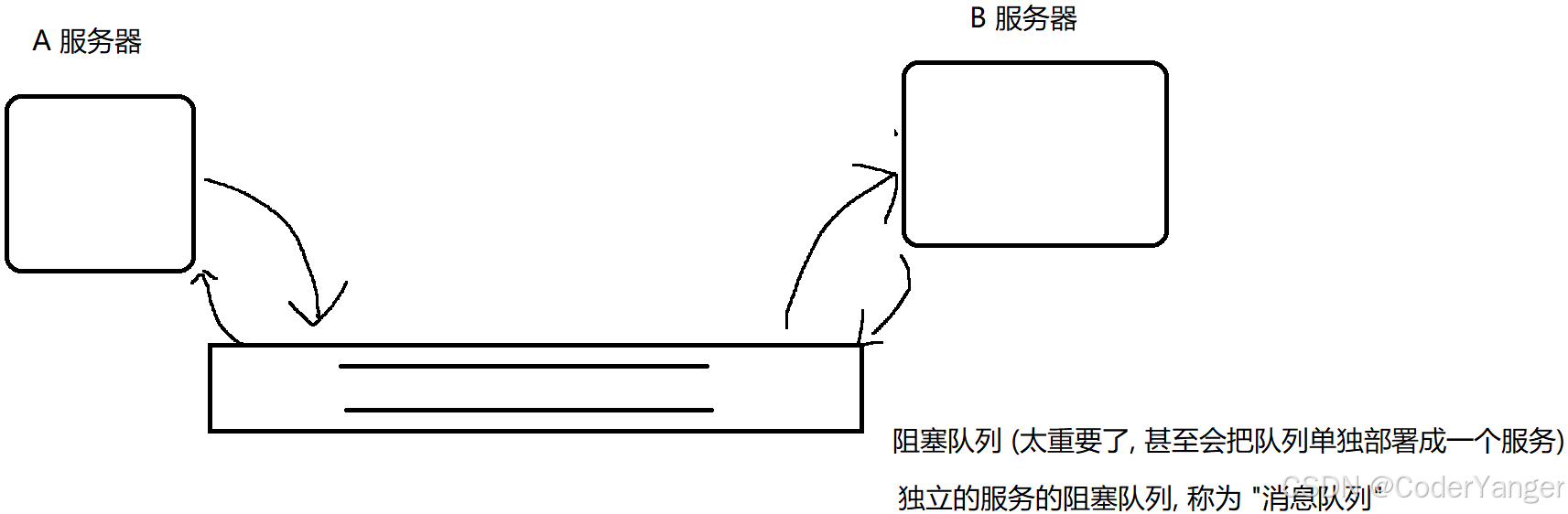
使用阻塞队列之后👇
此时:
A和队列交互,A的代码中就看不见B了
B和队列交互,B的代码中也看不见A了
A和B不再直接交互了,A的代码和B的代码中只能看到队列~~
答疑:
Q1:这个是双端队列吗?
消息队列服务器,里面不只是一个队列~~
可以有N个队列~~
Q2:本来是A和B耦合,现在成了A和队列耦合,B和队列耦合了,一样还是强耦合啊?
降低耦合的目的,是为了让后续修改的时候,成本更低~~
服务器三天两头老是改,而队列一般不会修改~~
之前AB耦合带来的问题,担心修改A的代码时,B也得同时改,反之亦然~
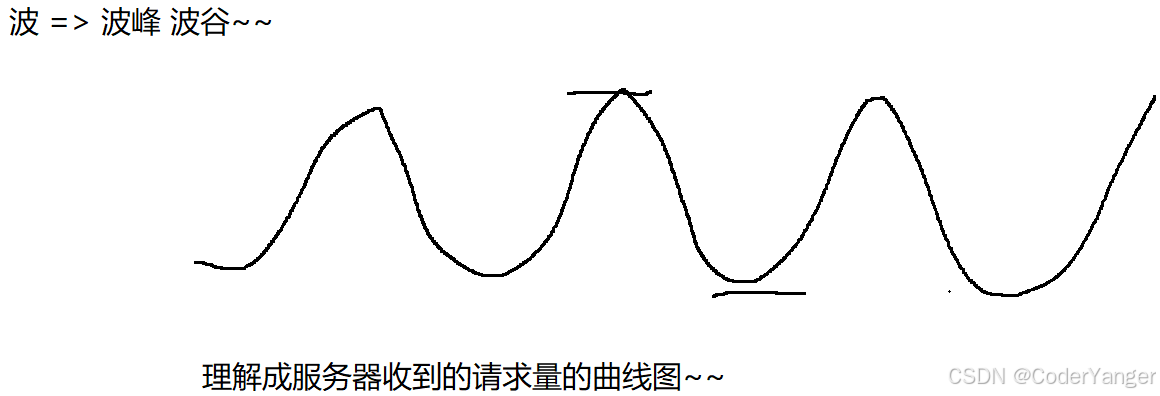
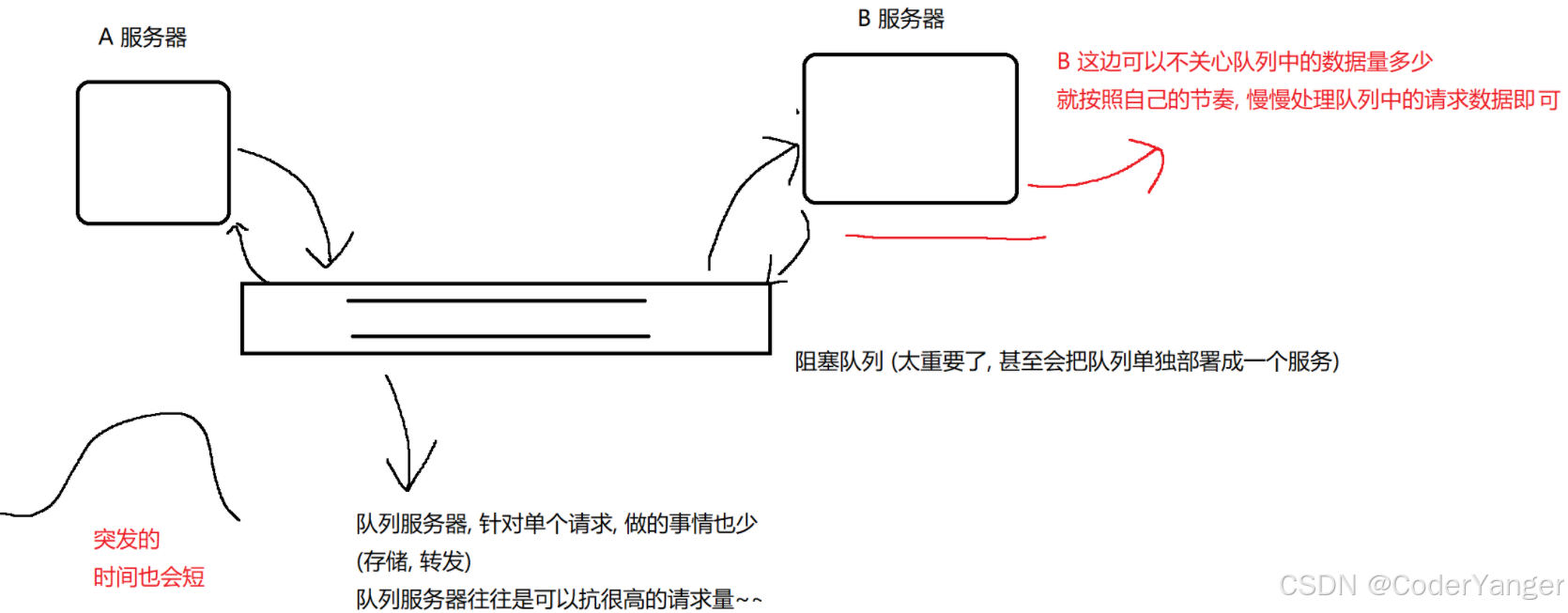
2.削峰填谷
阻塞队列相当于一个缓冲区,平衡了生产者和消费者的处理能力
比如说,当A服务器遇到一波流量激增,此时每个请求都会转发给B,B也会承担一样的压力,很容易就把B给搞挂了~~👇
答疑:
Q1:为啥服务器会挂??
像每次开学的选课网站一样~
服务器处理每个请求的时候,都是需要消耗一定的硬件资源的~~
这里的硬件资源包括但不限于CPU、内存、硬盘、网络宽带……
一个请求自然消耗很小,那要是N个请求呢?消耗的量必然×N
一旦消耗的总量,超出了机器硬件资源的上限,此时对应的进程就可能会崩溃,或者操作系统产生卡顿=>挂了
闲聊:12306表示,老弟菜还得练~~
12306确实老牛逼了,中国甚至世界上互联网产品中的巅峰之作~~毕竟像春运这样的场景,只是国内独一份
Q2:为啥是相同的流量激增,A服务器不挂,偏偏是B服务器挂了??
一般来说,A这种上游的服务器,尤其是入口的服务器,干的活更简单,单个请求消耗的资源数少
像B这种下游的服务器,通常承担更重的任务量、复杂的 计算/存储 工作,单个请求消耗的资源数更多
日常工作中,确实是会给B这样的角色的服务器分配更好的机器,即使如此,也很难保证B承担的访问量能够比A更高
使用阻塞队列后👇
于是,就能够达到“A那边还波涛汹涌呢,B这边还是波澜不惊”,B依旧可以按照自己节奏处理数据,趁着峰值过去了,B仍然继续消费数据,利用波谷的时间,来赶紧消费之前积压的数据
闲聊:“三峡大坝”起到的效果,同样也是“削峰填谷”
98年抗洪抢险→人民子弟兵,用血肉之躯,抗洪救灾
2021年河南洪涝灾害(长江流域),上游的降水量和98年时旗鼓相当的→虽然解放军也上了,但感觉也没干啥,很快洪灾就解决了~~
原因就是上游的压力,被三峡给抗住了
科普一下:如果有的同学是在读书期间入伍的话,有这样的履历,后续秋招会非常好找~~
认可度非常高
之前峡科大有个小伙,入伍两年,秋招毕业去了美团(不是送外卖,做安卓开发)
深圳的妹子,去过海军陆战队,毕业去了字节~~
付出的代价
1.引入队列之后,整体的结构会更复杂
此时,就需要更多的机器,进行部署,生产环境的结构会更复杂,管理起来更麻烦
2.效率会有影响
闲聊:爬虫
不是Python可以爬虫吗,别的语言也行嘛??
爬虫就是HTTP客户端,只要编程语言能够操作网络,就能写爬虫~~
写爬虫不难,难的是如何绕开对方的反爬机制……
举个例子,写个爬虫,定时抢京东的茅台,倒卖=>妥妥的进去踩缝纫机~~
12306用爬虫抢票=>妥妥的进去~
做着玩呢?=>也有风险
油猴脚本呢?=>这个还好,只是影响你本机的
曾经有个实习生往商业化整个GPU集群里注入病毒=>妥妥的进去蹲几年,非法破坏计算机系统罪~
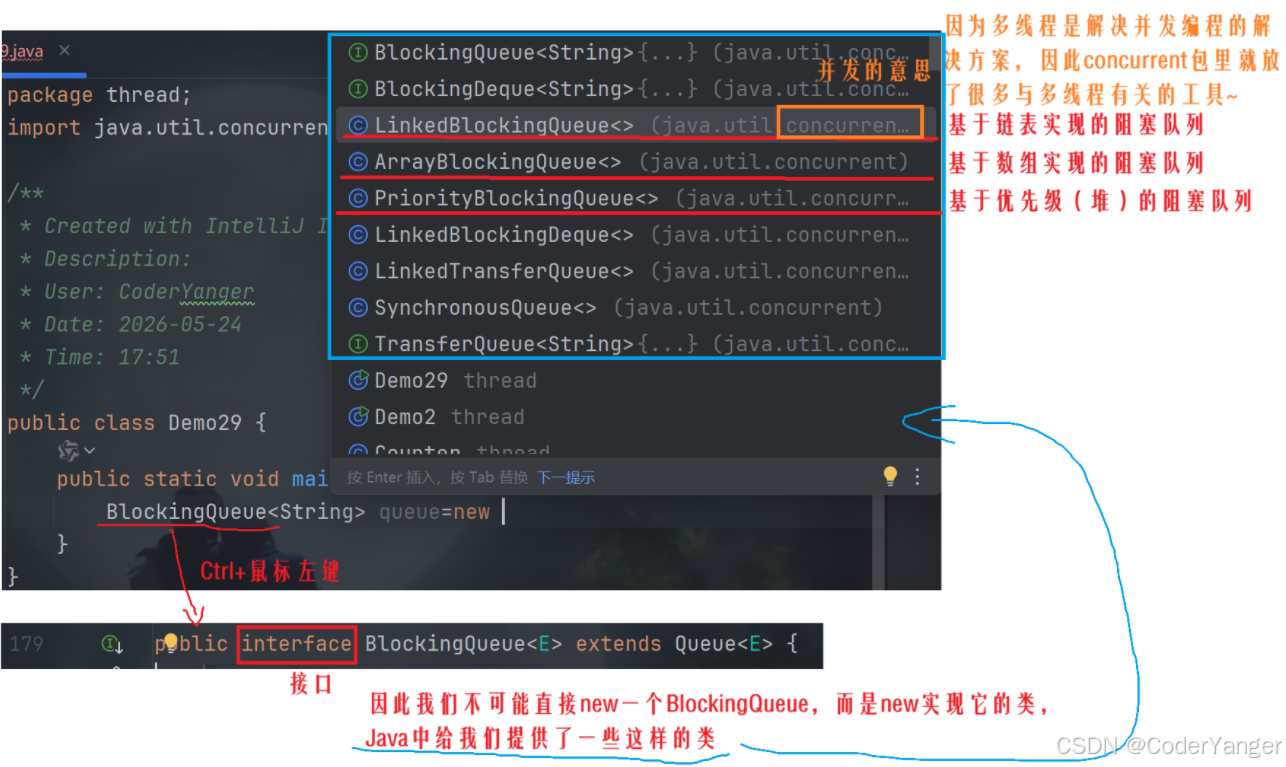
标准库中的阻塞队列
Java标准库中,提供了现成的阻塞队列,我们可以直接拿来用~
BlockingQueue:blcok,阻塞的,阻碍的;queue,队列
由于BlockingQueue本身是一个interface(接口),我们不可能直接new一个BlockingQueue,而是new实现它的类,而Java中也给我们提供了一些这样的类👇
题外话:[非常经典,非常高频的面试题]Java中ArrayList和LinkedList又啥区别??
逻辑连续、物理连续✔
空间占用✔
插入删除效率→这个就得分情况了~
注意,咱们问的不是“顺序表”和“链表”
顺序表:尾插尾删,还不错→O(1)
头插头删,中间位置插入删除→O(N)
链表:任意位置插入删除→O(1)
以上是关于顺序表和链表的,但对于ArrayList和LinkedList可不仅仅是这样👇
LinkedList这个类,进行中间位置插入:add(插入的值,插入的下标)
问题就出在“插入的下标”→需要从头找到指定下标位置,才能插入→O(N)(中间位置的删除,同理)
这个完全就属于接口封装没搞好,无法发挥出链表的全部能力~
相比与C++,C++的std::list就对标Java的LinkedList,进行插入删除操作中指定的位置,不是下标,而是“迭代器”,根据迭代器的位置,O(1)完成插入删除
因此即使Java是一个非常流行的语言,也不能认为,Java每个地方都是好的,比如说获取长度就不统一,数组.length、String.length()、List.size()
当然,C++的问题更多~~
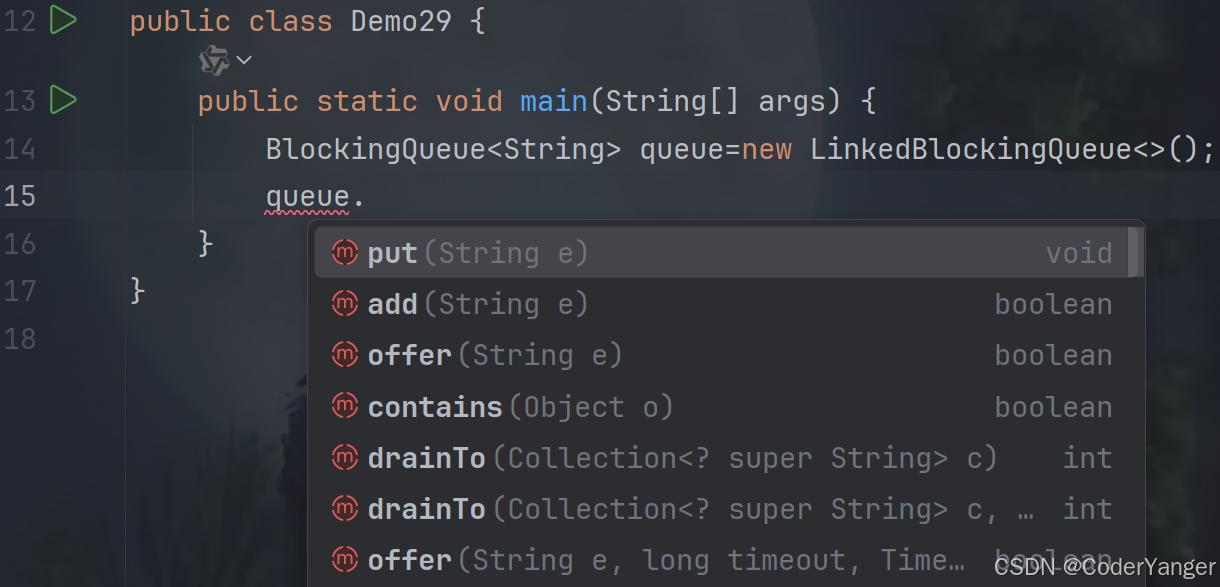
那么我们如何对其进行添加删除元素呢?它的核心方法又该怎么操作呢??👇
我们再次Ctrl+鼠标左键找到BlockingQueue源码👇
我们发现,它继承了Queue,意味着Queue的方法也都是支持的👇
但是我们入队列和出队列却分别使用 put 和 take 👇
package thread; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; public class Demo29 { public static void main(String[] args) throws InterruptedException { BlockingQueue<String> queue=new LinkedBlockingQueue<>(); queue.put("aaa");//入队列 String elem=queue.take();//出队列 } }为啥不用offer和poll??
当然也能用,但是 put 和 take 才带有阻塞功能~
接下来,我们会发现 put 和 take 会涉及到一个异常👇
而这个异常 throw InterruptedException 也是我们熟悉的异常,说明我们当前这个线程就被 Interrupted 给唤醒了,给终止了
分析上述代码的阻塞行为
先来看一下正确的情况👇
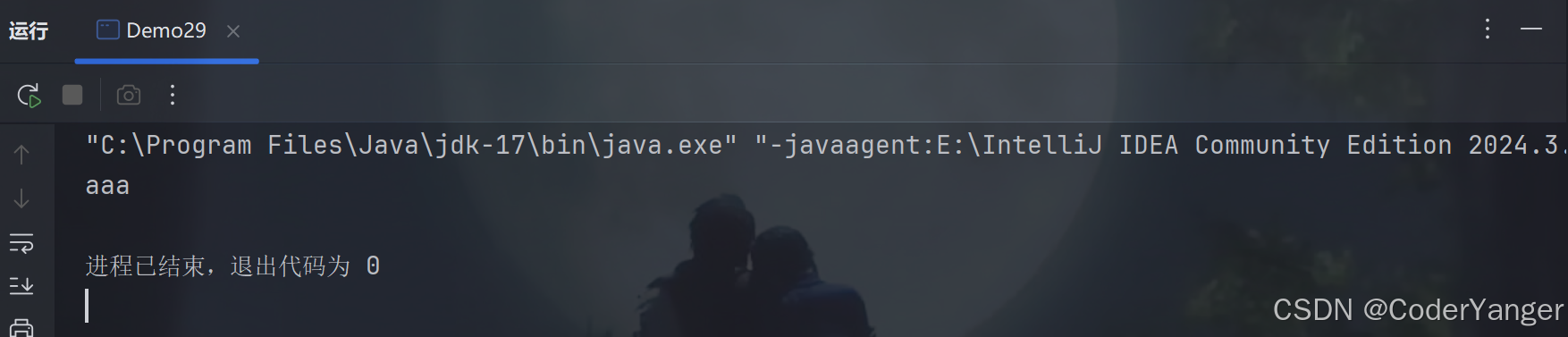
package thread; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; public class Demo29 { public static void main(String[] args) throws InterruptedException { BlockingQueue<String> queue=new LinkedBlockingQueue<>(); queue.put("aaa");//入队列 String elem=queue.take();//出队列 System.out.println(elem); } }
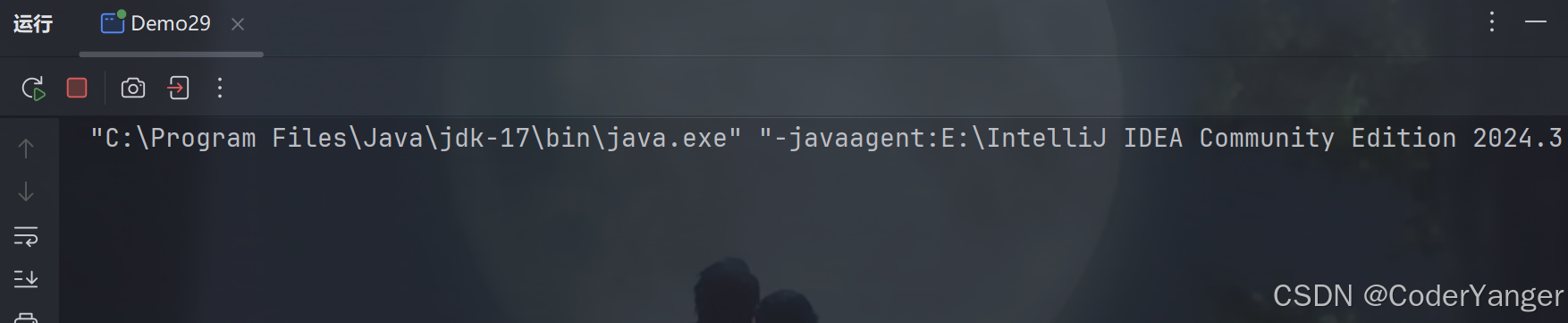
但是如果我们没有 put ,直接 take 👇
package thread; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; public class Demo29 { public static void main(String[] args) throws InterruptedException { BlockingQueue<String> queue=new LinkedBlockingQueue<>(); String elem=queue.take();//出队列 System.out.println(elem); } }我们发现它好像就卡住了👇
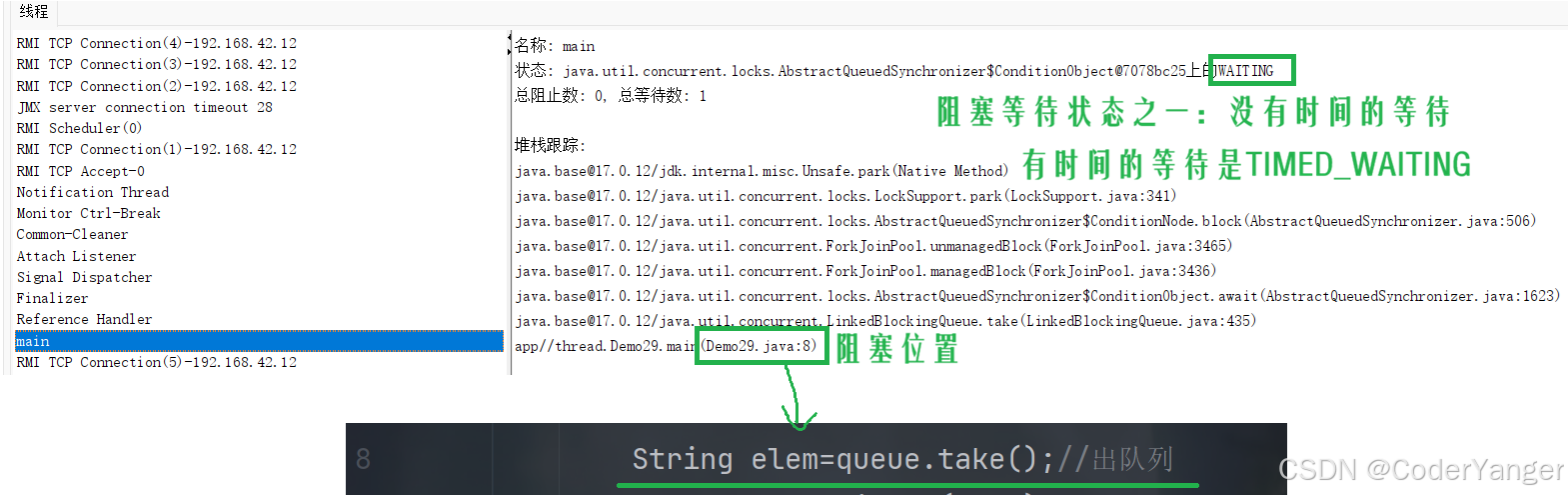
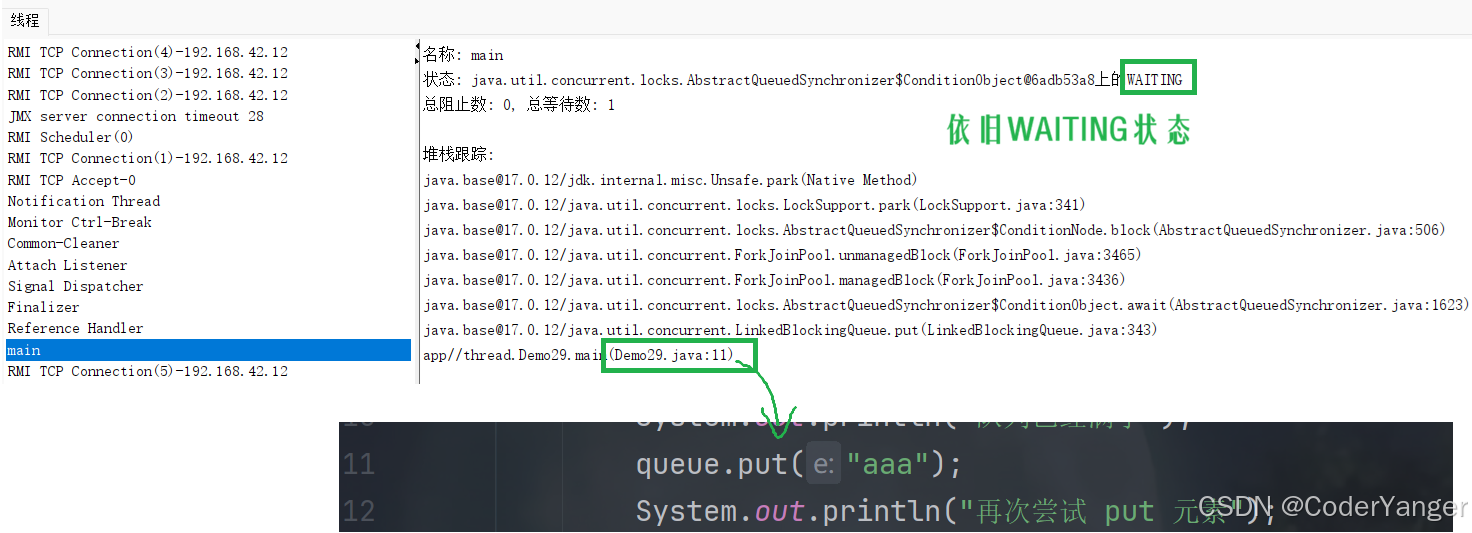
下面我们用 jconsole.exe 来看一下线程状态👇
这就说明我们的 take 因为没有元素而出队列造成阻塞了,对应的,入队列也会造成阻塞👇
我们先指定一个容量100,表示最多能容纳100个元素👇
接下来我们执行下述代码查看效果👇
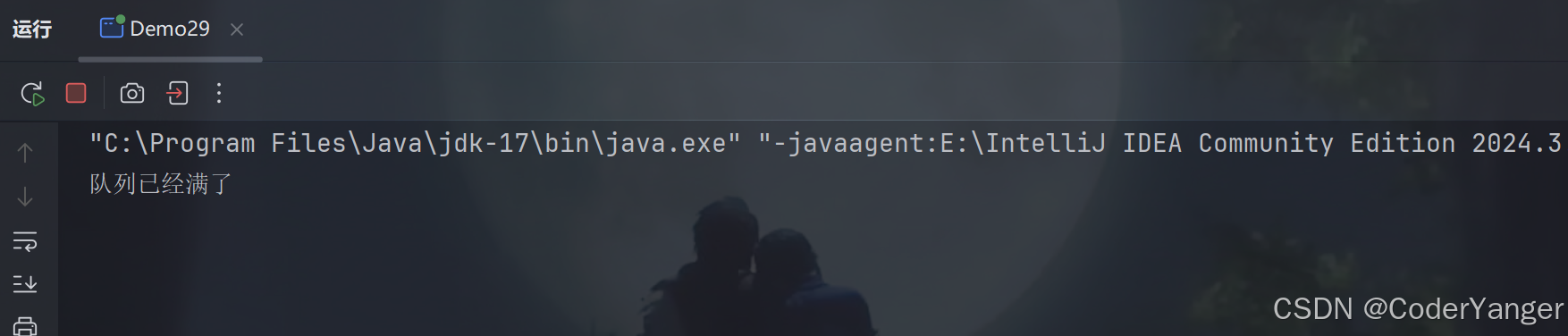
package thread; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; public class Demo29 { public static void main(String[] args) throws InterruptedException { BlockingQueue<String> queue=new LinkedBlockingQueue<>(100); for(int i=0;i<100;i++){ queue.put("aaa"); } System.out.println("队列已经满了"); queue.put("aaa"); System.out.println("再次尝试 put 元素"); } }我们发现,貌似也阻塞住了👇
我们再次连接 jconsole.exe 来看一下线程状态👇
这也就对应着我们刚开始说的阻塞队列的特性:
空了的时候再出队列,就会阻塞
满了的时候再入队列,也会阻塞
另外需要注意的是,如果不设置 capacity ,,就默认是个非常大的数值(7 ffff ffff ffff ffff,大约21亿),就很难看到满了的时候的阻塞效果了~👇
实际开发,一般还是建议大家能够设置上你要求的最大值
否则你的队列可能变的非常大,导致把内存耗尽,产生 内存超出范围 这样的异常
还有一个问题:阻塞队列没有提供一个“阻塞的获取队首元素的操作”,这个本应该提供的,但是Java标准库没提供,那就正常拿出来在用吧,不做过多讨论了~~




生产者消费者模型
了解了阻塞队列基本的使用后,我们可以基于标准库的阻塞队列来实现一个生产者消费者模型,让大家有一个初步的感受
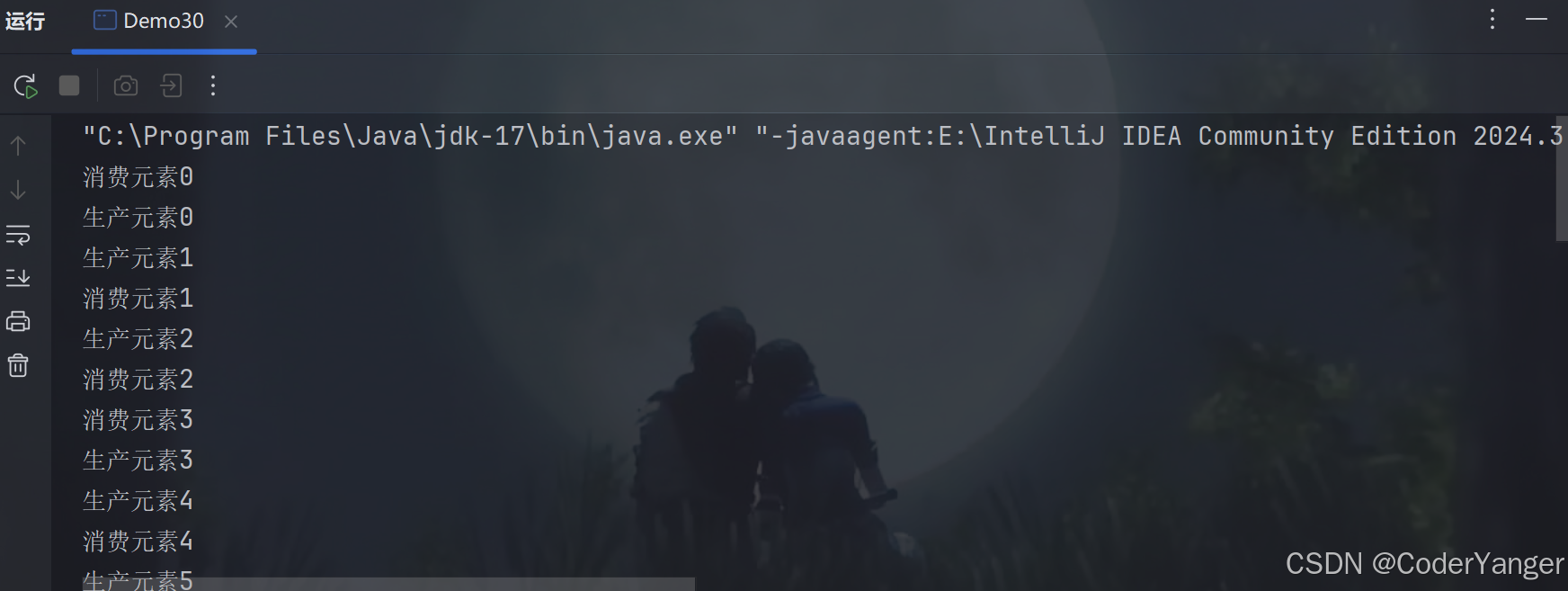
package thread; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; public class Demo30 { public static void main(String[] args) { //至少生产者一个线程,消费者一个线程 BlockingQueue<Integer> queue=new LinkedBlockingQueue<>(1000); Thread producer=new Thread(()->{ int n=0; while(true){ try { queue.put(n);//往队列里塞元素 System.out.println("生产元素"+n); n++; } catch (InterruptedException e) { throw new RuntimeException(e); } } },"producer"); Thread consumer=new Thread(()->{ while(true){ try { int n=queue.take();//从队列里取元素 System.out.println("消费元素"+n); } catch (InterruptedException e) { throw new RuntimeException(e); } } },"consumer"); //启动两个线程 producer.start(); consumer.start(); } }我们会发现生产和消费的速度旗鼓相当,生产一段,消费一段,基本上没啥阻塞👇
接下来我们通过手动设置,来看一下阻塞的效果:(让其中一个转的慢一点)
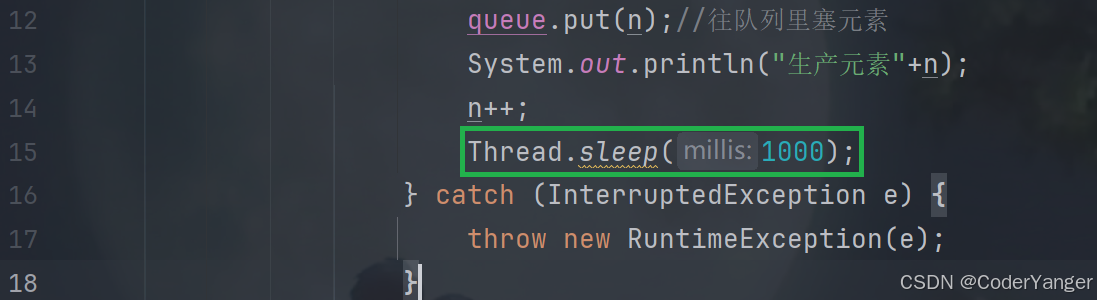
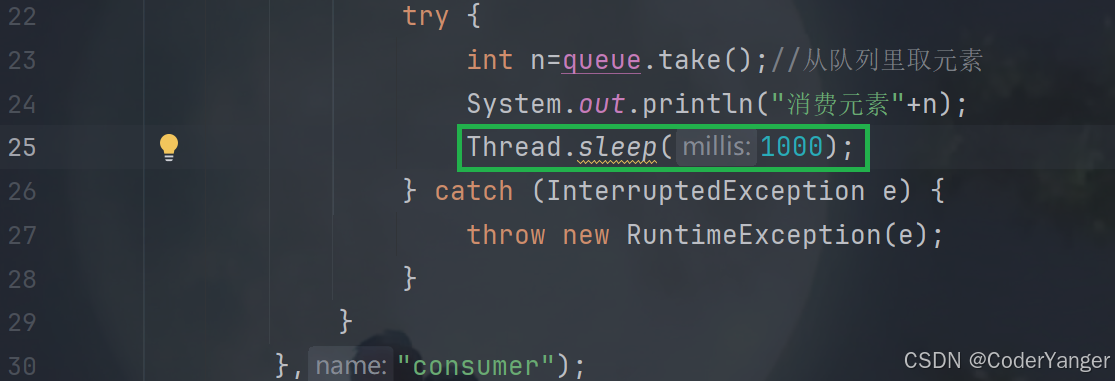
1.在生产者中加个sleep
我们发现,此时就出现了队列为空的情况,消费就得跟着生产走,消费就会因为生产的速度而产生阻塞的效果👇
2.在消费者中加个sleep
我们发现,此时就出现了队列为满的情况,生产就得跟着消费走,生产就会因为消费的速度而产生阻塞的效果👇
答疑:
Q1:没有限制会挂嘛??
我们将上述代码中容量上限1000给去掉:
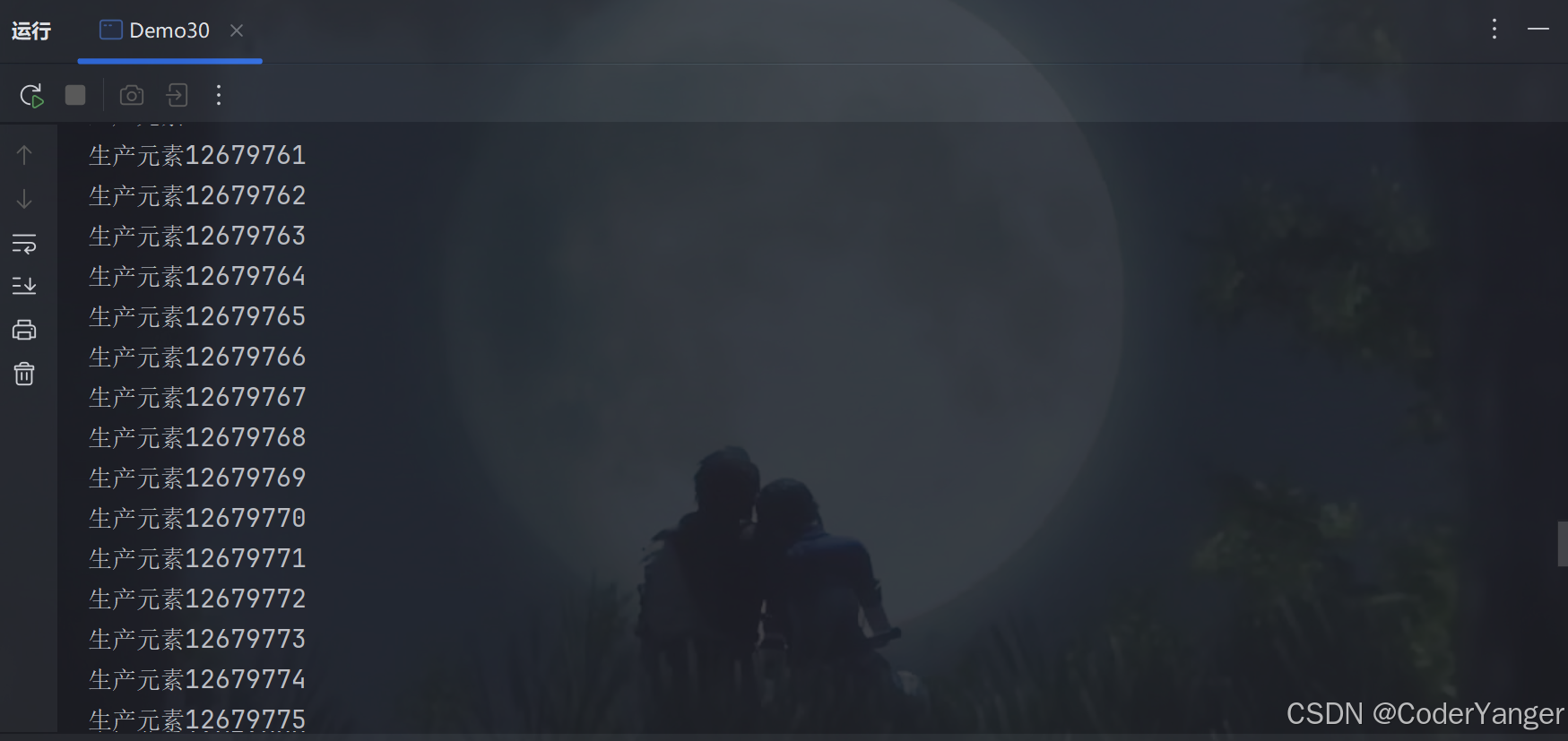
//至少生产者一个线程,消费者一个线程 BlockingQueue<Integer> queue=new LinkedBlockingQueue<>();再运行一下,我们会发现运行好久也不会挂掉~~👇
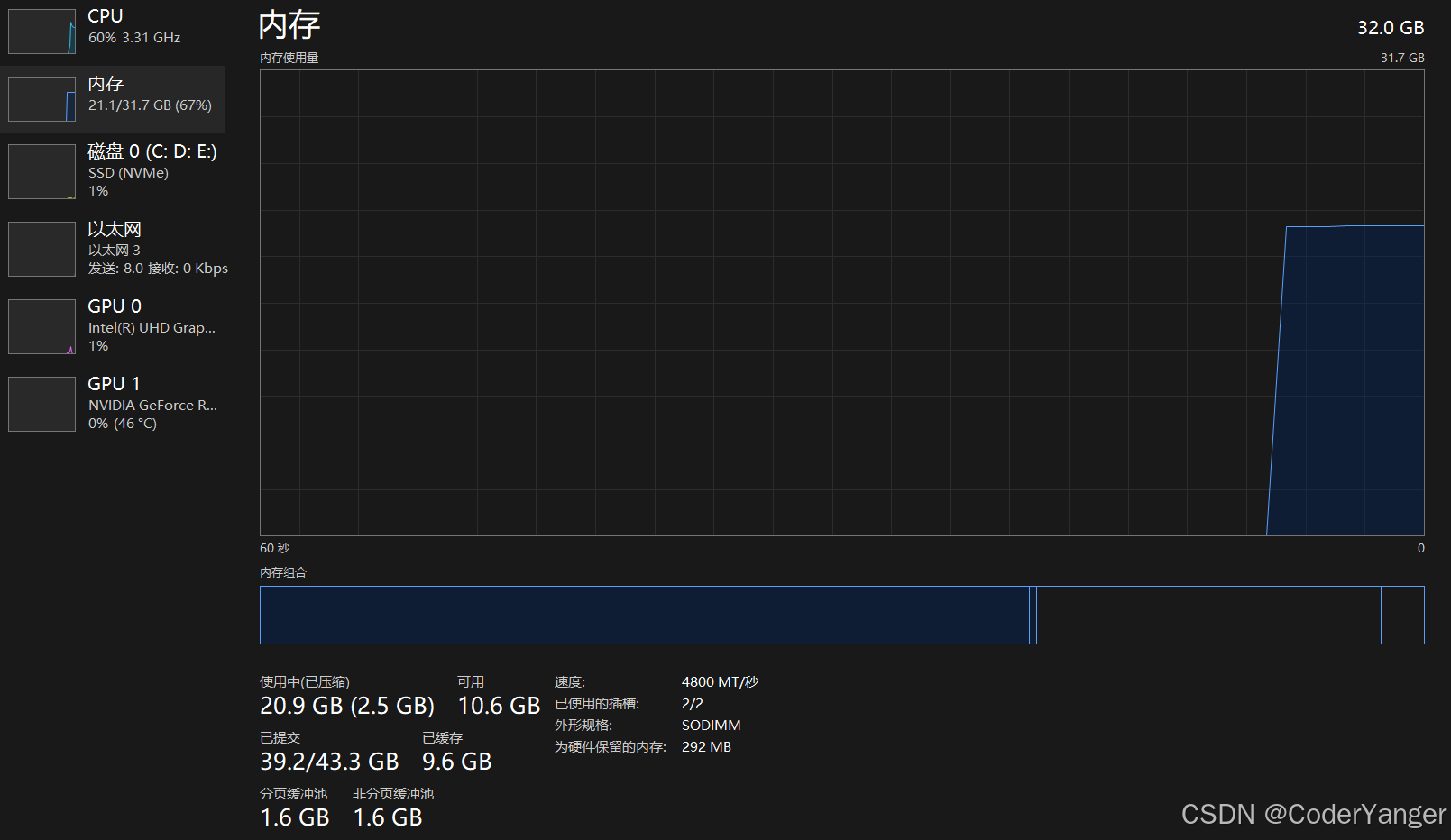
就算填满也没事
咱们这个队列最多是21亿个元素,每个元素是一个int(4个字节),极端情况,打满了也就消耗8GB内存~~
而我们现在的电脑大多都是32GB内存的,相比来说不算啥~~
一个JVM进程也不一定能够利用机器所有的内存,实际工作中是可以在运行JVM的时候通过一定的参数指定JVM最多消耗多少内存
如果实际消耗的内存,超过了JVM运行时候的限制上限,确实会挂~~
科普一个小知识点:21亿×4个字节,咋算出来8GB的??如何1s之内把这个算出来??
记住几个单词:
Thousand:千=>K
Million:百万=>M
Billion:十亿=>G
80亿个字节,自然就是8GB内存~~
因此未来你见到一个“百万级别的数据”,千万别慌,别被唬住
如果一个数据就是十几个字节,几十个字节,完全是小数字
10G数据,已经不是小数字了,即使如此,现代的服务器用内存来处理,还是绰绰有余的~~
Q2:设计模式和生产者消费者模型有啥关系??
生产者消费者模型也可以认为是一种设计模式
Q3:全国大学生软件测试大赛和工作中的测试有关嘛??
工作中主要测试的工作,是设计测试用例
就是验证一个功能,从那些角度来验证
比如买笔记本电脑试试好不好使:
1.不要联网激活(影响售后)
2.验证屏幕,是否有坏点
3.验证键盘,是否所有的键盘按键都有效
4.验证硬盘的通电时间,是否是100小时以内
5.烤机,可以烤,没啥必要
6.机器的唯一序号,官网上验证一下是否正版、生产时间……
以上6条就可以理解为测试用例
买电脑的话:
京东自营>天猫自营>京东第三方==天猫第三方>pdd
其中京东自营是京东自己售后,扯皮的事情最少,最省心也最贵
pdd最便宜,乱七八糟的事儿也最多~
Q4:Java EE学完是Java Web吗?
Java EE进阶 学的就是Java Web 的内容,写网站(Web开发就是做网站)

阻塞队列实现
自己模拟实现一个简单的阻塞队列,并且基于这个阻塞队列来实现 生产者消费者模型~~
1.了解怎么使用
2.了解底层原理=>注意事项,更高效,更稳定的使用
3.能够模拟实现=>有需要的时候,自行造一个/魔改一个出来
因为标准库中搞好的通常是比较通用的,这就需要标准库来做权衡
而实际开发中,我们可能只关注某个点,做到极致,其他的方面可以让步~~
下面通过“循环队列”的方式来实现
循环队列演示
(1)我们首先实现一个简单的队列:
package thread; //写一个基于数组的队列 //此处就不使用泛型了,假设数据类型全是String class MyBlockingQueue{ private String[] data=null; //队首 private int head=0; //队尾 private int tail=0; //元素个数 private int size=0; //容量 public MyBlockingQueue(int capacity){ data=new String[capacity]; } //入队列 public void put(String elem){ if(size>= data.length){ //队列满了,需要阻塞 return;//后续再改 } data[tail]=elem; tail++; if(tail>=data.length){ tail=0; } size++; } //出队列 public String take(){ if(size==0){ //队列空了,需要阻塞 return null;//后续再改 } String ret=data[head]; head++; if(head>=data.length){ head=0; } size--; return ret; } } public class Demo31 { public static void main(String[] args) { } }细节:上述入队列的代码中👇
tail++; if(tail>=data.length){ tail=0; }可以简写为👇
tail=(tail+1)%data.length;这两种写法执行效果是一样的~~那究竟哪个好呢??
我们程序员写代码,关注两个点:
1.开发效率是否有影响(是否容易理解,是否容易修改)
你要是懂%运算的话,那确实没啥影响,感觉 just so so~~
但要是不懂,理解成本就很高
闲聊:如果越少越简单,那文言文就特别好学
古人,平时说话,也是白话文
书面上写的时候,就是文言文
因为写字的成本非常高,需要“压缩”
文言文=中文.zip
因此 if 写法更容易理解~~
2.运行效率(代码是否高效)
第一种 if 写法,涉及到两个指令:
if 条件:条件跳转指令, jmp / cmp 类似的指令
赋值操作:读写内存指令,2次读内存,1次写内存
而第二种简化写法
①除了读写内存操作,还多了一次+操作,但加法运算,很快,也没啥
②但除此之外,还有一个%运算,乘除运算相比于加减运算和条件判断,就慢一些
因此这个%运算反而导致这个过程效率变慢了,除非你是针对2的N次方进行乘除,因为此时会把乘除优化成移位运算(跟加减效率差不多)
③而且CPU针对条件,还有分支预测,能够进一步加速
因此我们的第一种写法 if 条件判断更胜一筹
闲聊:
我们Java程序员还是更加关注第一点,第二点运行效率我们不太关注,这是C++关注的
C++考虑性能问题,甚至会走火入魔~~
甚至会讲究 i++ 和 ++i 的性能差异,实际上C++中,地道的代码,清一色都是 ++i ,因为能够少进行一次临时对象的构造
关于C和C++的 ++ 区别:
C++的 ++ 是能够重载的
C的 ++ 其实前置后置影响不大
(2)使用synchronized对入队操作和出队操作加锁
//入队列 public void put(String elem){ synchronized (this){//加锁 if(size>= data.length){ //队列满了,需要阻塞 return;//后续再改 } data[tail]=elem; tail++; if(tail>=data.length){ tail=0; } size++; } } //出队列 public String take(){ synchronized (this){//加锁 if(size==0){ //队列空了,需要阻塞 return null;//后续再改 } String ret=data[head]; head++; if(head>=data.length){ head=0; } size--; return ret; } }(3)使用 wait 触发阻塞+ notify 进行唤醒
1.针对队列满了的操作
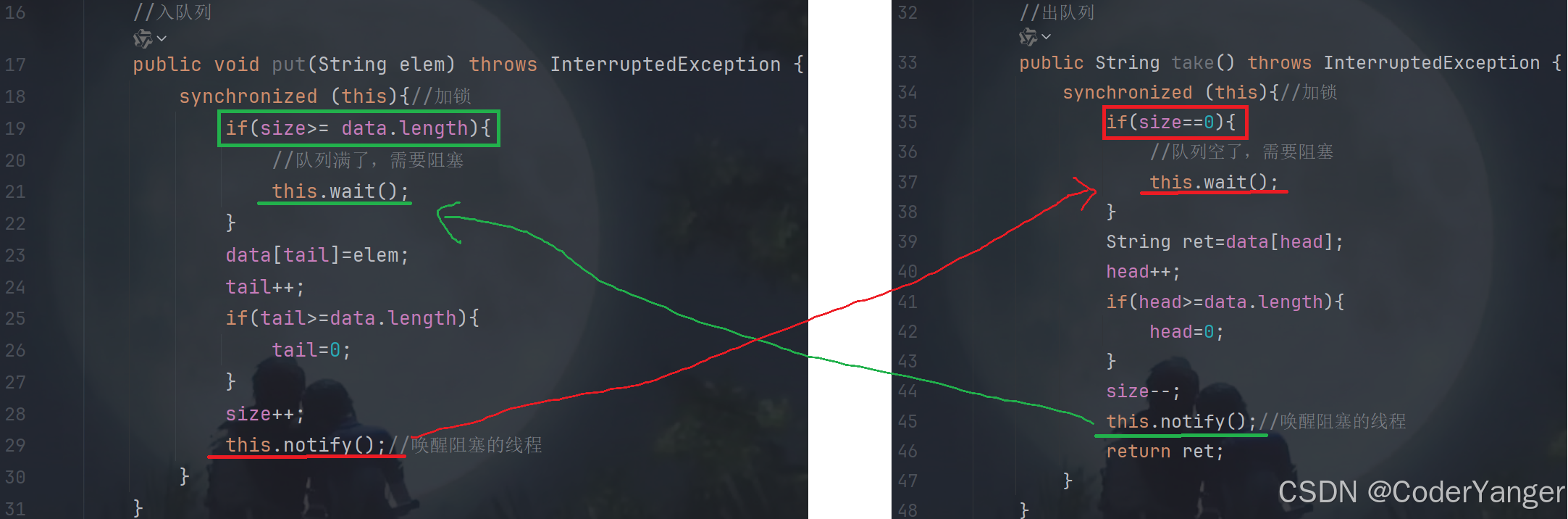
//入队列 public void put(String elem) throws InterruptedException { synchronized (this){//加锁 if(size>= data.length){ //队列满了,需要阻塞 //队列不满的时候,才要唤醒,也就是当其他线程执行take的时候 this.wait(); } data[tail]=elem; tail++; if(tail>=data.length){ tail=0; } size++; } }肯定不能一直让它阻塞着,就需要唤醒它,什么时候唤醒呢?
队列不满的时候,才要唤醒:当其他线程执行成功 take 的时候,因此我们需要在出队列结束前加上 notify 进行唤醒👇
//出队列 public String take(){ synchronized (this){//加锁 if(size==0){ //队列空了,需要阻塞 return null;//后续再改 } String ret=data[head]; head++; if(head>=data.length){ head=0; } size--; this.notify();//唤醒阻塞的线程 return ret; } }2.针对队列空了的操作
与上述逻辑一样👇
//出队列 public String take() throws InterruptedException { synchronized (this){//加锁 if(size==0){ //队列空了,需要阻塞 //队列不空的时候,才要唤醒,也就是当其他线程执行put的时候 this.wait(); } String ret=data[head]; head++; if(head>=data.length){ head=0; } size--; this.notify();//唤醒阻塞的线程 return ret; } }队列不空的时候,才要唤醒:当其他线程执行 put 的时候
//入队列 public void put(String elem) throws InterruptedException { synchronized (this){//加锁 if(size>= data.length){ //队列满了,需要阻塞 //队列不满的时候,才要唤醒,也就是当其他线程执行take的时候 this.wait(); } data[tail]=elem; tail++; if(tail>=data.length){ tail=0; } size++; this.notify();//唤醒阻塞的线程 } }通过上述过程,我们可以知道,put 和 take 是个“相互唤醒”的状态👇
如果有若干个线程使用这个队列,要么所有的线程阻塞在 put,要么所有的线程阻塞在 take
不可能有一些线程阻塞在 put ,有一些阻塞在 take
因为队列不可能既是满、又是空~~(薛定谔的队列~~)
关键环节
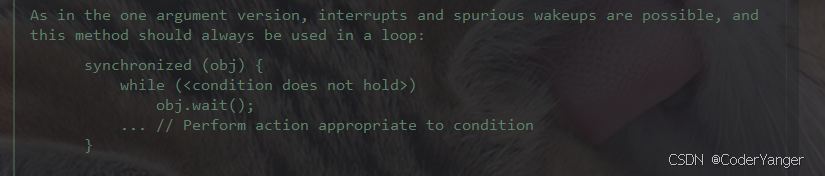
上述代码还有一个关键环节~~肉眼很难看出问题在哪,我们Ctrl+鼠标左键点击wait方法,查看标准库给出的文档说明👇
可见,使用 wait 的时候,标准库建议把 wait 放到 while 循环里去进行判定,而我们只是把它放到了 if 里去进行判定了
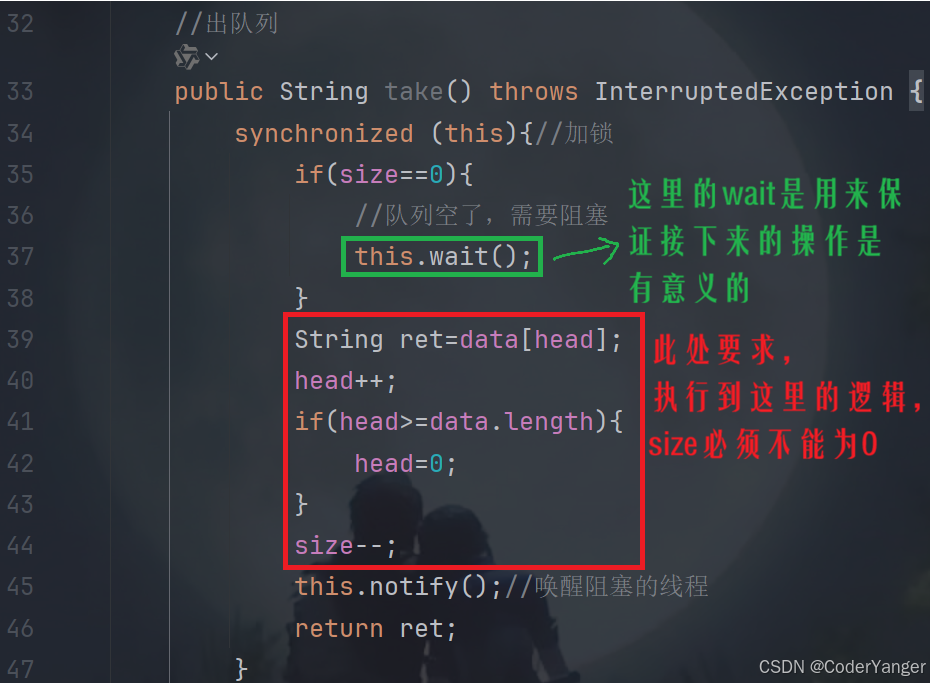
其实我们的 wait 操作是为了确保接下来的操作是有意义的👇
正常来说,wait 的唤醒是通过另一个线程执行 put ,另一个线程 put 成功了,此处的 size 肯定不是0
但 wait 不一定只是被 notify 唤醒,还可能被 Interrupt 这样的方法给中断~~
因为 wait 这个方法是阻塞的,Java中阻塞的方法都可以被 Interrupt 给提前唤醒
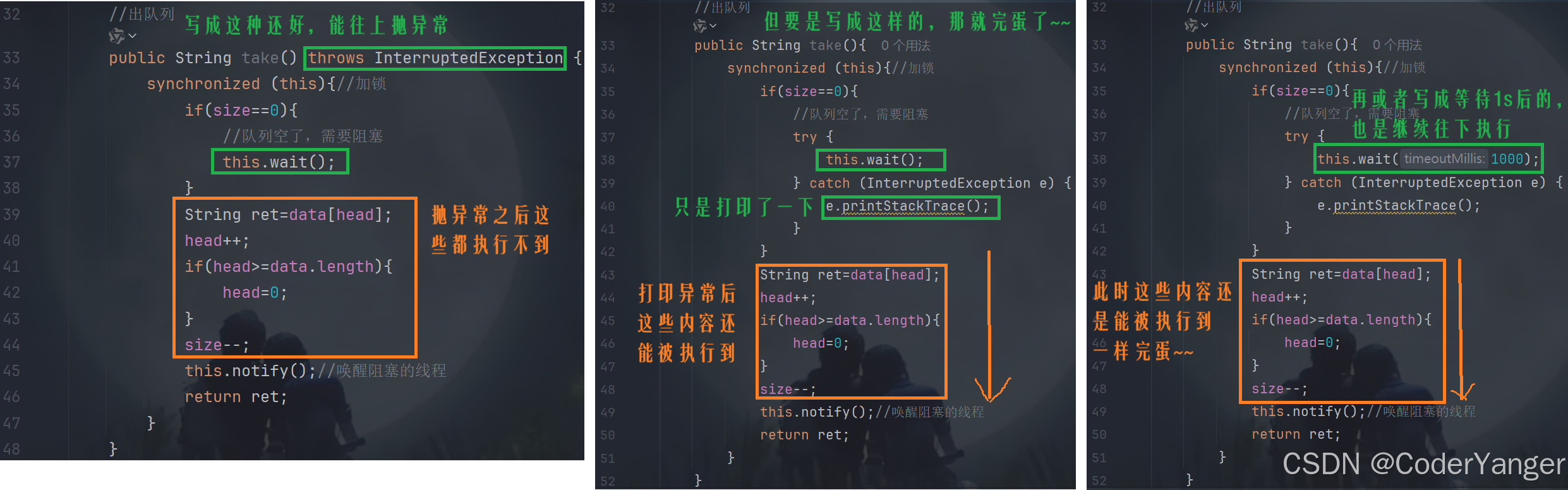
wait 正等着 notify 唤醒呢,结果被别人唤醒了,下面后两种写法就会导致出现问题👇
所以如果使用 if 作为 wait 的条件,此时就存在 wait 被提前唤醒的风险!!
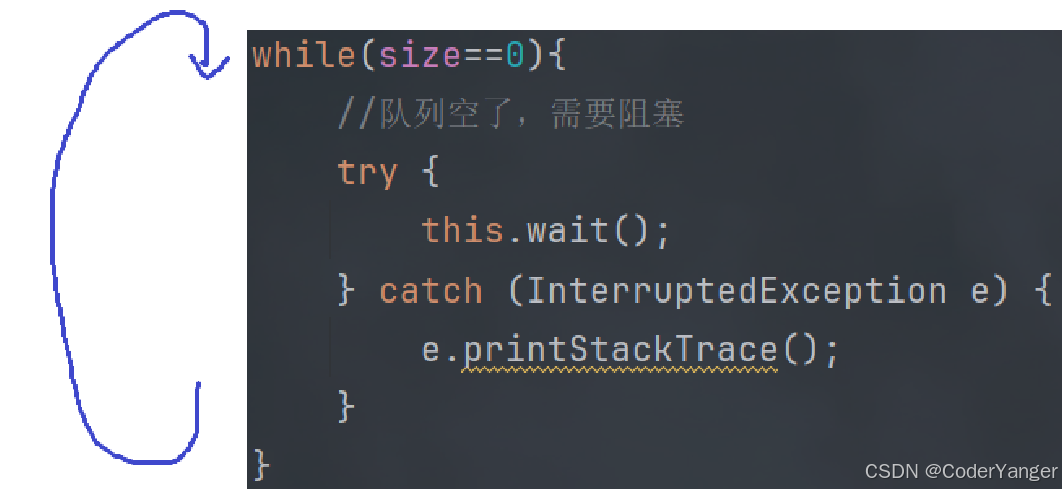
如果我们按照Java标准库说的,写在 while 循环内呢?👇
这里的循环的目的是为了“二次验证”
判定当前这里的条件是否成立
wait 之前先判定一次
wait 唤醒也判定一次(再确认一下,队列是否不空)
这就好比,有一天,我问妹子,大宝贝你还爱我吗~~
妹子表示:小傻瓜,当然爱啦~~
接下来,俺不幸进去踩了几年缝纫机~~
妹子就等了几年~~
等我出来的时候,我当然还得再问问~~
大宝贝,你还爱我吗~~
如果爱,那就继续过,如果不爱了,那就拉倒了~~
答疑:
Q1:会不会自己唤醒自己呢??
不会的,执行不下去,自己睡着了,只能别人唤醒~
Q2:多个线程下唤醒那不是随机唤醒 wait 的吗?
是随机唤醒的呀,但是执行到 notify 的线程必然是唤醒别人呀,一个线程不可能在 wait 阻塞的过程种中去执行 notify ~~
Q1追问:put 操作唤醒其他线程的 put ?
其他线程已经在 put 阻塞了,这个时候又来一个新的 put ,也是在相同的条件(队列满)阻塞
举个更极端的情况:3个线程 put (1、2、3)都因为队列满 阻塞了
第4个线程,take了一下,唤醒上述的线程1,线程1继续往下执行
//入队列 public void put(String elem) throws InterruptedException { synchronized (this){//加锁 if(size>= data.length){ //队列满了,需要阻塞 this.wait(); } data[tail]=elem; tail++; if(tail>=data.length){ tail=0; } size++; this.notify();//唤醒阻塞的线程 } }执行到上述代码中的 notify 时,确实会触发 notify ,此时的 notify 是可能唤醒刚才 put 的阻塞的2、3这俩线程的
但如果我们把 if 条件改成 while 👇
while(size>= data.length){ //队列满了,需要阻塞 this.wait(); }此时即使 wait 被唤醒,此时还会再次判定条件,再次进行阻塞
Q3:性能不会被影响吗?
这里的 put 的阻塞被 take 唤醒,循环不是一直执行的,只是为了 wait 唤醒之后,再次执行一下条件~~
//正常情况就类似于: if(条件) wait if(条件)而且条件一直不成立,就是往下走也容易出现Bug~~
小结一下:
如果只是一个线程 take 一个线程 put ,不会出现自己唤醒自己的情况
多个线程 take ,多个线程 put ,确实有这种风险,但是可以通过 while 循环判定条件,避免这样的唤醒给程序带来负面影响~~
闲聊:
有的同学会觉得 while 有点巧妙~
其实 wait 设计的时候,本身就是搭配 while 使用的~
操作系统原生API(Linux的 wait,也是官方文档建议使用 while),上古时期就是 wait 搭配while 使用的~~
完整代码
下面是用自己的阻塞队列实现生产者消费者模型的代码👇
package thread; //写一个基于数组的队列 //此处就不使用泛型了,假设数据类型全是String class MyBlockingQueue{ private String[] data=null; //队首 private int head=0; //队尾 private int tail=0; //元素个数 private int size=0; //容量 public MyBlockingQueue(int capacity){ data=new String[capacity]; } //入队列 public void put(String elem) throws InterruptedException { synchronized (this){//加锁 while(size>= data.length){ //队列满了,需要阻塞 this.wait(); } data[tail]=elem; tail++; if(tail>=data.length){ tail=0; } size++; this.notify();//唤醒阻塞的线程 } } //出队列 public String take() throws InterruptedException { synchronized (this){//加锁 while(size==0){ //队列空了,需要阻塞 this.wait(); } String ret=data[head]; head++; if(head>=data.length){ head=0; } size--; this.notify();//唤醒阻塞的线程 return ret; } } } public class Demo31 { public static void main(String[] args) { MyBlockingQueue queue=new MyBlockingQueue(1000); Thread producer=new Thread(()->{ int n=0; while(true){ try { queue.put(n+""); System.out.println("生产元素"+n); n++; //Thread.sleep(1000);//让消费的快点,生产的慢点 } catch (InterruptedException e) { throw new RuntimeException(e); } } }); Thread consumer=new Thread(()->{ while(true){ String n=null; try { n=queue.take(); System.out.println("消费元素"+n); //Thread.sleep(1000);//让生产的快点,消费的慢点 } catch (InterruptedException e) { throw new RuntimeException(e); } } }); //启动线程 producer.start(); consumer.start(); } }效果与标准库的相同,我们也可以在生产者和消费者代码中添加休眠机制使得阻塞,这样效果更明显些

更多推荐
 17
17 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)