
基于Java Web的个人博客系统
一、前言
在完成图书馆管理系统和表白墙案例的学习后,我们继续完成更复杂的博客系统
我们先来看这个博客系统的架构图,看看这个项目是怎么分层的
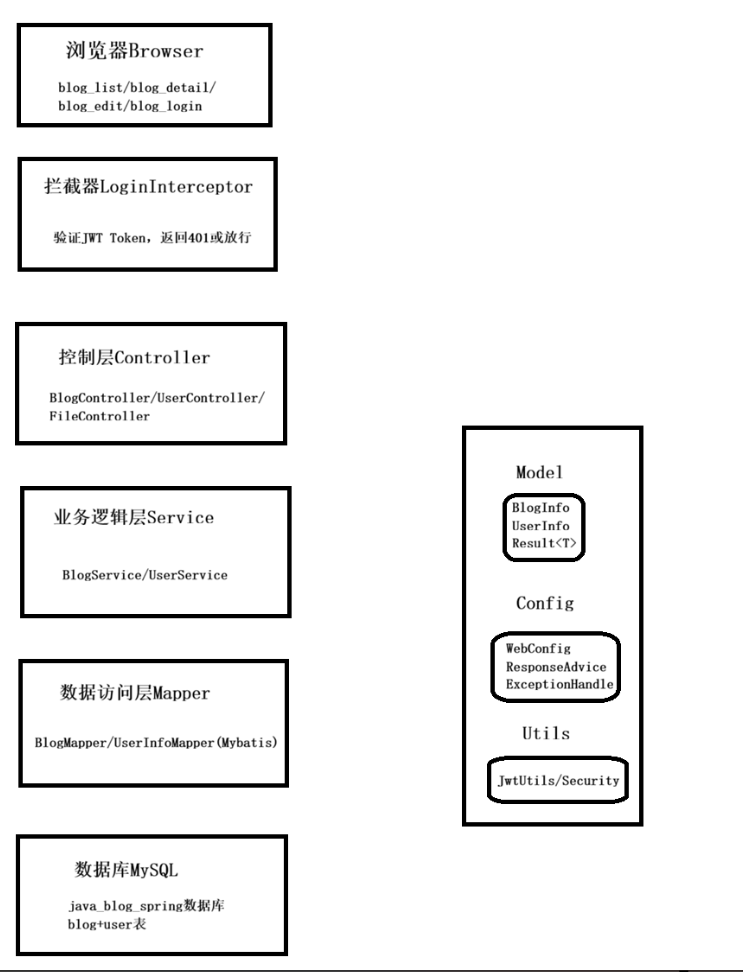
上面这张图就是这个项目的整个结构,请求从浏览器发出,经过拦截器,Controller,Service,Mapper,最后到达MySQL数据库。
搭建这个项目需要用到的工具:
JDK17,Maven,MySQL,navicat,IntelliJ IDEA
二、数据库设计
先创建数据库java_blog_spring
-- 创建数据库
CREATE DATABASE IF NOT EXISTS java_blog_spring
DEFAULT CHARACTER SET utf8mb4
DEFAULT COLLATE utf8mb4_unicode_ci;
USE java_blog_spring;我们要设计两张表,因为这个博客系统有两个实体
一个是用户,写博客的人,即user,用户表
一个是blog,被写出来的文章,即blog,博客表

所以我们要在java_blog_spring中创建这两个表
创建user表
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT, -- ① 主键
user_name VARCHAR(128) NOT NULL, -- ② 用户名
password VARCHAR(128) NOT NULL, -- ③ 密码
github_url VARCHAR(256), -- ④ GitHub主页
delete_flag INT DEFAULT 0, -- ⑤ 删除标记
create_time DATETIME DEFAULT CURRENT_TIMESTAMP, -- ⑥ 创建时间
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP -- ⑦ 更新时间
);
其中密码存的是加密后的明文,delete_flag=0说明博客正常,=1说明博客已2被删除
方便后续找回已删除的博客
UPDATE blog SET delete_flag = 0 WHERE id = ?
创建blog表
CREATE TABLE blog (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(256) NOT NULL, -- ① 标题
content MEDIUMTEXT, -- ② 内容(Markdown)
user_id INT NOT NULL, -- ③ 作者ID(外键)
delete_flag INT DEFAULT 0,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP,
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
content使用的markdown格式,MEDIUMTEXT 数据类型能存16MB,能满足文章的存储需求
这里采用的是逻辑删除,只是把delete_flag标记为1,没有真正删除数据,可以随时恢复数据
三、pom.xml
我们先看pom文件在整体架构图:
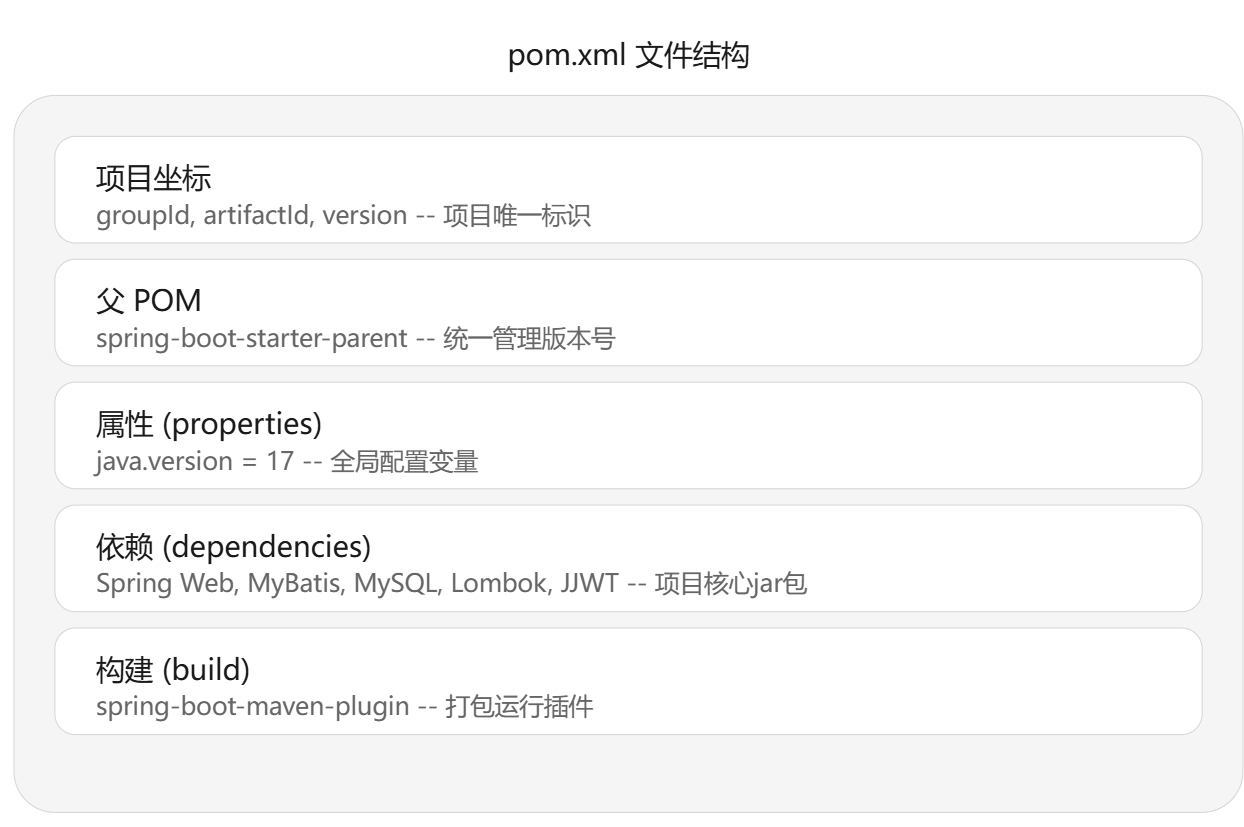
1.Maven是什么?
想象你写了一个购物清单,需要别人帮你按找清单采购需要的物品。Maven就是那个清单,上面pom.xml的五个部分就是需要采购的物品。
Maven作为清单,会自动去中央仓库中下载,不用我们手动下载
2.项目坐标
<groupId>com.bite</groupId>
<artifactId>spring-blog</artifactId>
<version>0.0.1-SNAPSHOT</version>
有了groupId,artifactId,version,maven就能从仓库璃找到唯一的jar包,可以依赖jar包中已经写好的功能,不用自己再重新写一遍。
groupId 是组织/团队名,通常是公司域名倒过来写
artifactId 是项目模块名
version是版本号
3.父pom
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>4.0.5</version>
</parent>
是pom.xml中最关键的两行
Spring 官方提供了一个“父POM”,帮我们管理所有spring相关的jar包版本号。
我们的依赖<dependency>里没有写版本号,是英文父pom中已经定义好了继承了父pom的版本,不会出现版本冲突问题。
4.依赖们

--spring-boot-starter-web 是Web的核心
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
是SpringBoot的全家桶之一,自动引入:
内嵌Tomcat (把Tomcat打包成一个jar包,程序启动Tomcat自动启动)Tomcat启动后,java程序能够接收 http 请求和发送响应
SpringMVC 让我们能写@RestController和@RequestMapping(定义 URL 与 HTTP 方法的映射规则)
Jackson 让Java对象和json对象互相转换
--mybatis-spring-boot-starter
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>4.0.1</version>
</dependency>
操作数据库,博客数据在mysql中,mybatis负责与数据库建立连接
MyBatis不属于Spring,父pom不管它的版本
--mysql-connector-j 是数据库驱动
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
是MySQL的官方的JDBC驱动
--lombok
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
不用手写getter,setter,toString,只需要加上@Data
在打包时会把Lombok排除,因为它的工作只在编译期间完成(生成代码),运行时不需要
--JJWT三件套--登录令牌
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt-api</artifactId> <!-- API 接口 -->
</dependency>
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt-impl</artifactId> <!-- 实现 -->
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt-jackson</artifactId> <!-- JSON 序列化 -->
<scope>runtime</scope>
</dependency>
作用:用户登录后,服务器生成一个加密令牌返回给浏览器,后续请求带上这个令牌,服务器就知道"你是谁"了。
--测试依赖类
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
两个都是 scope=test,打包成 jar 时不会带进去。前者提供 JUnit 5 测试框架,后者让测试环境能识别 MyBatis 的 Mapper。
四、application.yml配置文件怎么写
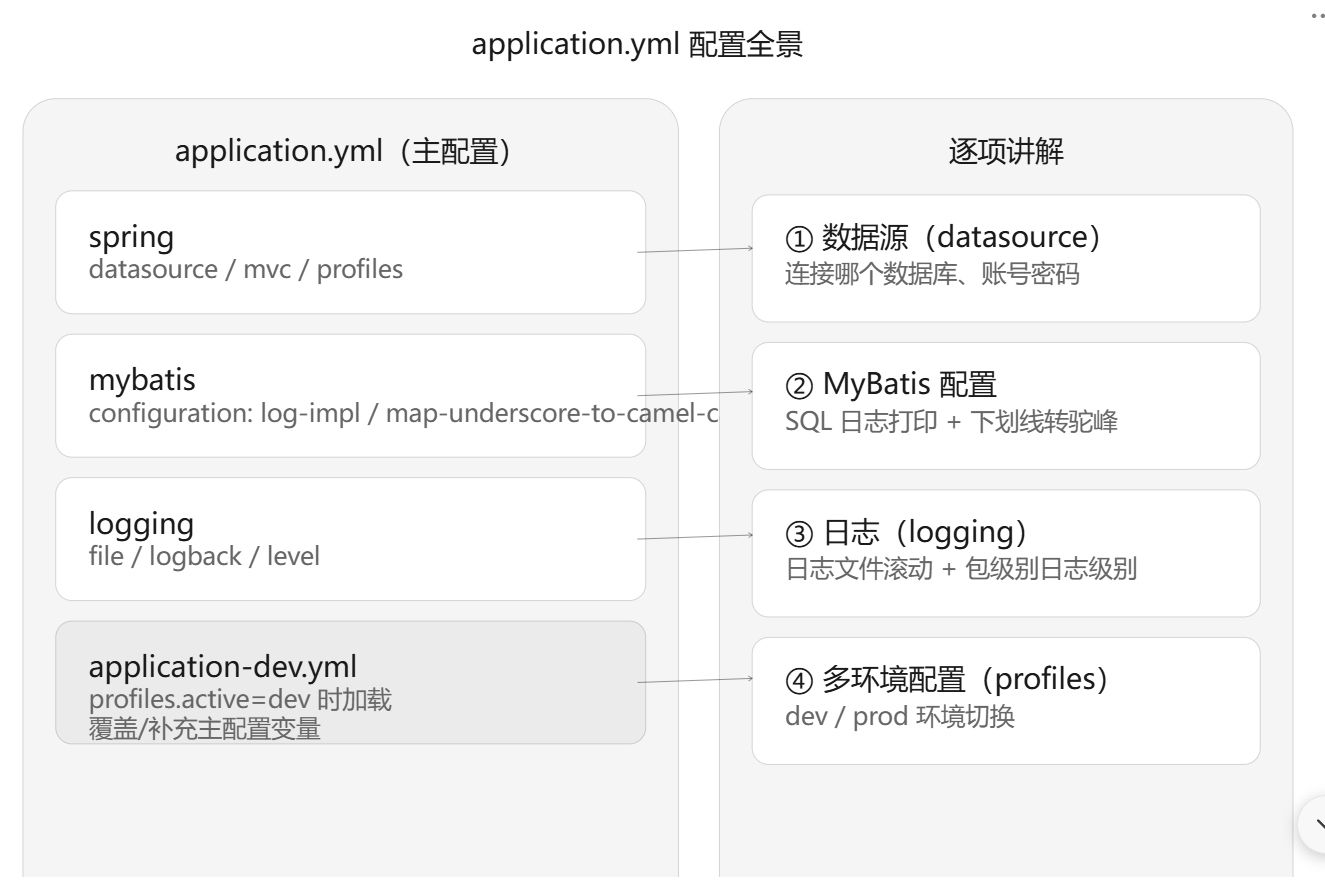
1.yml文件是什么格式?
yml是用缩进表示层级的配置文件格式,yml用缩进表示“谁属于谁”
java的poperties文件时另一种写法,是key=value平铺的写法
# properties 写法(平铺)
spring.datasource.url=jdbc:mysql://...
spring.datasource.username=root
# yml 写法(层级)
spring:
datasource:
url: jdbc:mysql://...
username: root
2.spring.datasource 数据库连接配置
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/java_blog_spring?characterEncoding=utf8&useSSL=false
username: root
password: 1234
driver-class-name: com.mysql.cj.jdbc.Driver
-127.0.0.1:3306是MySQL的默认端口
-java_blog_spring是数据库名
-characterEncoding=utf8 字符编码设为utf8,防止中文乱码
-useSSL=false 关闭SSL加密
-driver-class-name指定MySQL的驱动名
com.mysql.cj.jdbc.Driver是MySQL Connnector/J 8 的驱动,老版本是com.mysql.jdbc.Driver
spring.mvc.favicon.enable=false --关闭默认图标
spring:
mvc:
favicon:
enable: false
-
当用户访问你网站的任何一个页面(比如
http://localhost:8080/hello),浏览器会自动额外发一个请求去问:/favicon.ico。这个文件就是浏览器标签页上显示的那个小图标(比如知乎的小蓝标、GitHub 的小猫) -
就是告诉 Spring Boot:你别再插手
/favicon.ico请求了。 -
禁掉之后:
-
浏览器依然会请求
/favicon.ico(这是浏览器的天性,禁不掉)。但 Spring Boot 不再自动去 classpath 里找图标,也不再打印那条“找不到图标”的警告日志。
3.spring.profiles.active=dev --多环境切换
spring:
profiles:
active: dev
实际开发中,至少有两套环境
| 环境 | 用途 | 去表 |
| dev(开发) | 本地跑代码 | 连接本地数据库、日志开debug、端口随意 |
| prod(生产) | 上线给用户用 | 连线上数据库、日志只打error、端口80/443 |
active:dev的意思是当前激活dev环境
Spring Boot会去加载名为application-dev.yml的配置文件,它里面配置会覆盖/补充主application.yml(当前项目没有,至少留个坑位)
4.mybatis配置块
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
配置1:log-impl:org.apache.ibatis.logging.stdout.StdOutImpl
作用:打印SQL日志,MyBatis执行SQL语句时,把SQL语句直接打印到控制台
==> Preparing: SELECT * FROM blog WHERE id = ?
==> Parameters: 1(Integer)
<== Total: 1
配置2:map-underscore-to-camel-case: true --下划线转驼峰
MyBatis的自动映射功能
数据库字段名习惯用下划线:user_id,Java对象属性名习惯用驼峰:userId,开了这个配置后,MyBatis查询时会自动把下划线字段名樱色到驼峰属性名,不用手写@Result注解
5.logging配置块
logging:
file:
name: spring-blog
logback:
rollingpolicy:
max-file-size: 100KB
file-name-pattern: ${LOG_FILE}.%d{yyyy-MM-dd}.%i
level:
com:
example:
demo: debug
rollingpolicy--日志滚动策略
日志文件不能无限增大,超过max-file-siza:100KB,就会自动新建一个文件,就按file-name-pattern归档
${LOG_FILE}.%d{yyyy-MM-dd}.%i 这个模式的意思是:
%d{yyyy-MM-dd}:按日期归档%i:同一天内的序号(第几个滚动文件)
最终文件名类似:spring-blog.2026-05-27.0(第一天的第一个滚动文件)
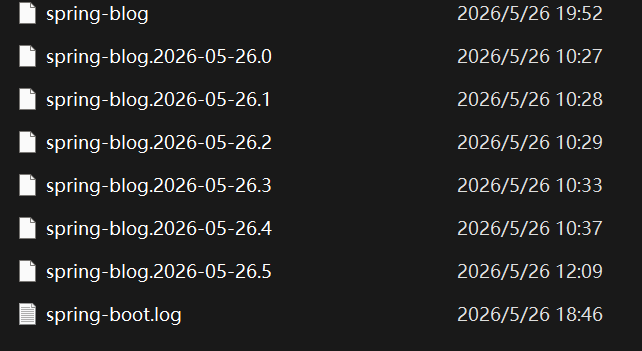
level --日志级别
level:
com:
example:
demo: debug
意思是:com.example.demo 包下所有类的日志级别设为 debug。
日志级别从高到低:ERROR > WARN > INFO > DEBUG > TRACE

程序启动流程:
- Spring Boot 启动,读取
application.yml - 看到
profiles.active=dev,再去读application-dev.yml(目前还不存在,是个待补全的坑) - 根据
spring.datasource配置,建立数据库连接池 - 根据
mybatis.configuration配置,初始化 MyBatis(开启驼峰映射、SQL 日志打印) - 根据
logging配置,初始化日志系统,开始往spring-blog.log写日志
五、入口类


@SpringBootApplication // ← 这行是全部秘密
public class SpringBlogApplication {
public static void main(String[] args) { // ← 普通 java 程序入口
SpringApplication.run( // ← 启动 Spring 容器
SpringBlogApplication.class, // ← 告诉 Spring:"从我这个类的包路径开始扫描"
args // ← 命令行参数
);
}
}
@SpringBootApplication是三个注解的组合
@SpringBootConfiguration
@EnableAutoComfiguration
@ComponentScan
这三类注解相当于一个注解@SpringBootApplication
1.@ComponentScan --扫描自己的类
Spring启动时,从SpringBlogApplication所在的com.bite.springblog包开始扫描所有子包
扫描子包时,寻找这些注解:
@RestController @Service @Mapper @Configuration @Component
com.bite.springblog ← SpringBlogApplication 在这里
├── controller/
│ ├── BlogController.java ← @RestController → 找到了!
│ ├── UserController.java ← @RestController → 找到了!
│ └── FileController.java ← @RestController → 找到了!
├── service/
│ └── BlogService.java ← @Service → 找到了!
├── mapper/
│ ├── BlogMapper.java ← @Mapper → 找到了!
│ └── UserMapper.java ← @Mapper → 找到了!
└── config/
├── WebConfig.java ← @Configuration → 找到了!
└── ResponseAdvice.java ← @RestControllerAdvice → 找到了!
入口类必须放在最外层包,否则同级的包扫描不到
2.EnableAutoConfiguration --自动化大师
我们引入了什么jar包,它就帮我们创建什么Bean
具体流程:
- Spring Boot 启动时,扫描所有引入的 jar 包中
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件 - 每个 starter 包都在这个文件里写了自己要自动创建的配置类
- Spring Boot 用
@ConditionalOnClass等条件注解判断:classpath 里有没有这个类?有就创建,没有就跳过
本项目中,自动装配的决策过程:
| spring-boot-starter-web 在 classpath? | → 启动内嵌 Tomcat,注册 DispatcherServlet |
| mybatis-spring-boot-starter 在 classpath? | → 创建 SqlSessionFactory,扫描 Mapper 接口 |
| mysql-connector-j 在 classpath? | → 根据 application.yml 创建 DataSource 连接池 |
| Jackson 在 classpath? | → 注册 JSON 消息转换器 |
如果你把 mysql-connector-j 从 pom.xml 里删掉,启动时 DataSource 就创建失败了,因为自动装配发现 classpath 里没有 MySQL 驱动类
3.@SpringBootConfiguration --给入口类赋能
告诉Spring和你,这个类可以定义Bean,意味着你可以直接在入口类中写@Bean方法:
@SpringBootApplication
public class SpringBlogApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBlogApplication.class, args);
}
// 可以直接在这里注册自定义 Bean
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
但一般不这样写
总结:
Spring Application.run( )做了什么?
这段代码启动时
- 创建 Spring 容器(ApplicationContext)
- 读取 application.yml,加载所有配置项
- 自动装配(
@EnableAutoConfiguration):根据 classpath 创建 Tomcat、DataSource、SqlSessionFactory 等 - 组件扫描(
@ComponentScan):找到你自己的 Controller、Service、Mapper - 依赖注入:把所有组件之间的引用关系连好(Controller 需要 Service,Service 需要 Mapper)
- 启动内嵌 Tomcat,绑定端口(默认 8080)
- 应用就绪,等待 HTTP 请求
控制台最后打印的那行就是启动完成的标志:
Started SpringBlogApplication in 3.456 seconds六、分层架构
例:Spring Boot三层架构--删除博客
DELETE /blog/delete?blogId=1
|
@RequestMapping("/delete")
public Boolean delete(Integer blogId){
...
blogService.deleteBlog(blogId)
}
BlogController.java
|
public Integer deleteBlog(Integer blogId) {
return blogMapper.deleteBlog(blogId);
BlogService.java
|
@Update("update blog set delete_flag = 1 where id = #{id}")
Integer deleteBlog(@Param("id") Integer id);
BlogMapper.java
|
blog 表 delete_flag 字段置为 1
| 层 | 类 | 只负责 |
| Controller | BlogController | 和HTTP打交道,管进出 |
| Service | BlogService | 业务逻辑,管对不对 |
| Mapper | BlogMapper | 和数据库打交道,管存取数据 |
1.第一层:Model(数据模型)
@Data // Lombok:自动生成 getter/setter/toString/equals/hashCode
public class BlogInfo {
private Integer id;
private String title;
private String content;
private Integer userId;
private boolean isLoginUser; // 不在数据库里,前端判断是否显示编辑按钮用
private Integer deleteFlag;
private Date createTime;
private Date updateTime;
// 覆盖 Lombok 默认的 getCreateTime,返回格式化字符串
public String getCreateTime() {
return DateUtils.dateformat(createTime);
}
}
@Data注解帮我们自动生成getter/setter/toString,使Java文件更加整洁干净
2.第二层:Mapper 只管SQL
@Mapper // MyBatis 扫描这个接口,自动生成实现类
public interface BlogMapper {
@Select("select * from blog where delete_flag = 0")
List<BlogInfo> selectAll();
@Select("select * from blog where id = #{id}")
BlogInfo selectById(Integer id);
@Update("update blog set title = #{title}, content = #{content} where id = #{id}")
Integer updateBlog(BlogInfo blogInfo);
@Insert("insert into blog (title, content, user_id) values (#{title}, #{content}, #{userId})")
Integer insertBlog(BlogInfo blogInfo);
@Update("update blog set delete_flag = 1 where id = #{id}")
Integer deleteBlog(@Param("id") Integer id);
}
(1)Mapper是接口,不是类
interface BlogMapper没有class,不用写实现代码,只需要写方法声明签名+SQL注解
(2)#{xxx}是占位符
#{id}是SQL的占位符?,MyBatis会从方法参数里取id值填进去,防止SQL注入。
区别于 ${ } 直接拼接字符串,有注入风险。
(3)方法参数的对应规则
- 传入
BlogInfo blogInfo→ 用#{title}、#{userId}直接取属性名(走 getter) - 传入基本类型
Integer id且只有一个参数 → 直接#{id}即可 - 传入基本类型但方法有多个参数 → 必须加
@Param("id")明确告诉 MyBatis 这个参数叫什么
(例如 Integer update(Integer id, String title)),MyBatis 就没法知道 #{id} 应该用第一个参数还是第二个参数。此时如果不加 @Param,MyBatis 会提供默认命名:#{arg0}、#{arg1} 或 #{param1}、#{param2}。)
(4)为什么 deleteBlog 用 UPDATE 不用 DELETE?
update blog set delete_flag = 1 where id = #{id}
这就是逻辑删除:数据还在表里,只是 delete_flag 改成了 1,查询时过滤掉 delete_flag = 1 的行。这样数据可以恢复,也能保留历史记录。
3.第三层:Service业务逻辑层
@Slf4j
@Service // 标记为 Service Bean,Spring 管理它的生命周期
public class BlogService {
@Autowired // Spring 自动注入 BlogMapper 实现类
private BlogMapper blogMapper;
public List<BlogInfo> getList() {
return blogMapper.selectAll(); // 直接转发,无业务逻辑
}
public boolean insertBook(BlogInfo blogInfo) {
try {
Integer result = blogMapper.insertBlog(blogInfo);
if (result == 1) {
return true;
}
} catch (Exception e) {
log.error("添加图书失败, e:", e); // 记录错误日志
}
return false;
}
public Integer deleteBlog(Integer blogId) {
return blogMapper.deleteBlog(blogId);
}
}
(1)@Slf4j是Lombok框架中一个实用的注释,它能帮助我们再类中自动创建一个日志记录器log,避免手动编写日志对象声明代码,让代码更简洁。
log.info("获取博客列表");
log.error("添加博客失败, e:", e);
加上该注解之后就可以直接再代码中使用log对象来记录日志了
(2)@Service告诉Spring要创造Service对象并管理它的声明周期,并且供其他类使用
没有@Service的话还需要手动NewService对象
UserService userService = new UserService();(3)@Autowried依赖注入
因为没有new BlogMapper对象,所以Spring发现BlogService需要BlogMapper时就会自动去容器里找,把它注入进来
(4)保证业务逻辑正确
如发布博客时,标题和内容不能为空,插入失败时catch异常返回false
Mapper只关心SQL执行成功了没有,不会管userId是哪里来的
4.第四层:Controller 最上层,和HTTP打交道
@Slf4j
@RequestMapping("/blog") // 这个类下所有接口路径前缀都是 /blog
@RestController // = @Controller + @ResponseBody
public class BlogController {
@Autowired
private BlogService blogService;
// GET /blog/delete?blogId=1
@RequestMapping("/delete")
public Boolean delete(Integer blogId) {
log.info("删除博客, blogId:{}", blogId);
// 参数校验:这是 Controller 的职责
if (blogId == null || blogId <= 0) {
return false;
}
Integer rows = blogService.deleteBlog(blogId);
// 判断是否真的删了
if (rows == null || rows <= 0) {
log.error("删除博客失败, blogId:{}, 影响行数:{}", blogId, rows);
return false;
}
return true;
}
}
路由映射
@ResquestMapper("/blog") //类映射
@ResquestMapper(“delete”)//方法映射
拼起来就是/blog/delete。浏览器访问的就是这个URL。
七、粘贴功能

图片的粘贴功能涉及前端的两个文件和后端的两个类
首先看static/blog_edit.html和static/blog_update.html这两个类中的粘贴功能
包位置:src/main/resources/static/
// 1. 初始化绑定——等 Editor.md 加载完后执行
function bindPasteImage() {
var cm = editor.cm; // 获取 CodeMirror 实例(注意是 editor.cm,不是 editor.codemirror)
if (!cm) {
setTimeout(bindPasteImage, 1000); // 未初始化则1秒后重试
return;
}
// 监听 DOM 的 paste 事件(不能用 cm.on,必须用 addEventListener)
cm.getWrapperElement().addEventListener("paste", function(e) {
var items = e.clipboardData && e.clipboardData.items;
for (var i = 0; i < items.length; i++) {
if (items[i].type.indexOf("image") !== -1) {
e.preventDefault();
uploadPasteImage(items[i].getAsFile());
break;
}
}
});
}
// 2. 上传图片
function uploadPasteImage(file) {
// 先插入占位符
var placeholder = "\n![上传中...]()\n";
var cm = editor.cm;
cm.replaceSelection(placeholder);
var formData = new FormData();
formData.append("editormd-image-file", file); // 字段名必须是这个
$.ajax({
url: "/upload",
type: "POST",
data: formData,
processData: false,
contentType: false,
success: function(response) {
var result = response.data || response; // 兼容 ResponseAdvice 包装
if (result.success === 1) {
// 替换占位符为真实图片链接
var content = cm.getValue();
cm.setValue(content.replace(placeholder, "\n\n"));
}
}
});
}
这里涉及到三个部分
第一部分是 bindPasteImage(),是绑定粘贴图片功能的函数
cm 是 CodeMirror 的简写,是一个编辑器
CodeMirror 是一个开源网页代码的编辑器库。editor.cm 就是拿到 CodeMirror 的实例对象,通过它获取编辑器的 DOM 容器、监听事件等,来完成编辑区绑定粘贴事件。
看到 if(!cm) 是为了保证编辑器 cm 已经加载好了,如果没有加载好,就调用 setTimeOut 这个 JavaScript 中的延时定时器,延迟 1000 毫秒之后再执行这个 bindPasteImage 函数。保证编辑器已经准备好了,再去执行图片粘贴功能,避免编辑器没加载好直接粘贴导致报错。
第二部分是监听 DOM 的 paste 事件
cm.getWrapperElement() 是为了在页面中找到编辑器的编辑框。就是把整个页面的导航页,侧边栏等排除在外,精准定位到中间的文本编辑框,给这个编辑框实现 “监听”功能,只要在这个编辑框内按 Ctrl+V 就能触发后面的图片上传逻辑。如果在该页面的其他位置粘贴,就不会误触上传。
这个 addEventListener() 这个方法,就是给刚刚的文本编辑器加上一个监听器。其中监听的是 “paste” 事件,就是监听按 Ctrl+V 这个动作,监听到这个动作之后就执行 function(e) 这个回调函数。(回调函数就是把一个函数当作参数传给另一个函数,等预定动作发生之后,再执行这个函数。就是等目标事件发生之后才被调用的函数)
这个回调函数里的 e.clipboardData() 是事件对象里专门用来读取剪贴板的属性,本质是一个对象。
items 是剪贴板里所有数据项的集合,我们复制的图片、文本会作为一个个独立的项存在这里,再通过 clipboardData 拿到总容器,在 items 属性里也能精准地找到图片数据。
为什么要写成 e.clipboardData && e.clipboardData.items; 呢?是为了兼容浏览器的“短路判断”,,有些低版本的浏览器中 e 对象中根本没有 clipboardData 这个对象,所以要加上 &&,要先判断 e.clipboardData 是否存在,如果存在再取 items,不存在就会返回 undefined,不会让代码崩掉。
items 里面存了粘贴板里不同格式的数据项。如果单纯复制文本,items 里就只存有文本项,如果复制带图的内容,就会同时存在图片、文本甚至 HTML 格式的项。所以我们要在集合中“筛选出”图片项来处理,其他项跳过。
剪切板的设计是尽可能保留所有格式。如果在网页上复制一张图,浏览器会同时保存图片上的二进制数据、带 img 标签的 HTML 代码、甚至是图片的 alt 文本描述,这些都会变成 items 里的不同项,但顺序不一定固定。但如果是用系统自带的截图工具,或者在微信上保存图片,就只会保存图片的二进制数据项,不会带多余的 HTML 或者文本格式。
这里我发现我的博客系统在粘贴网页图片时,会报错
在粘贴微信和系统截图时都不会,通过Cased by发现,是因为max-file-size单个文件和max-request-size请求的最大大小只有1MB,太小了需要在application中修改它们俩的大小,修改完后可以正常上传
然后就是for循环遍历items对象,在对象中找到第一个包含字符串“image”的items对象
第三部分是上传图片方法 uploadPasteImage(flie)
更多推荐


 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)