
AI Agent 应用应用层学习路线
AI Agent 应用开发工程师学习路线
|
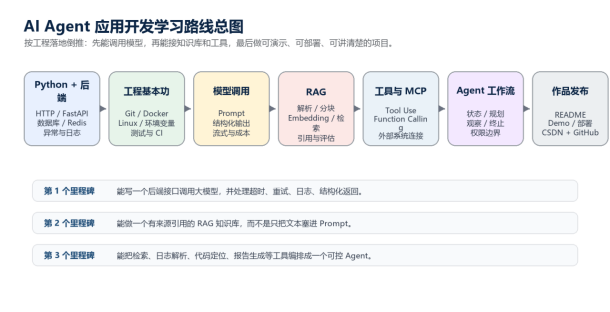
这篇文章的定位 不是把名词堆一遍,而是按项目倒推学习顺序:先会稳定调用模型,再补 RAG、工具调用、MCP、Agent 状态控制,最后用一个能跑、能部署、能讲清楚的项目去承接热度。 |
0. 先给读者一个结论
如果目标是 AI Agent 应用开发工程师,我不建议一上来就纠结训练大模型。更现实的路径是先把 AI 应用层做扎实:模型 API 怎么稳定调用,结果怎么结构化,知识库怎么检索,工具怎么安全暴露,Agent 怎么控制状态,最后怎么把这些东西放进一个项目里。
- 短期目标:能独立做出一个 RAG 或 Agent Demo,并把失败处理、日志、配置、部署补齐。
- 中期目标:能解释数据流、调用链、成本控制、质量评估和安全边界。
- 求职/曝光目标:把项目做成一个别人愿意点进 GitHub 的入口,而不是只有代码没有说明。
这篇笔记参考了我本地的 `03_AI应用开发` 学习目录,核心内容包括 AI 基础技能、Ollama、本地模型、MCP、RAG、Agent Skills、完整 Agent、多 Agent 协作和求职作品。
1. 先分清:AI 应用层到底在做什么
现在很多岗位会说 AI 应用层、AI 中层、AI Infra,刚开始听会有点绕。我的理解是:应用层负责把模型能力变成具体业务功能,中层负责把模型、知识库、工具、评估这些公共能力封装起来,模型层才是训练和推理基础设施。

|
层级 |
你需要会什么 |
作品里怎么体现 |
|
应用层 |
前后端接口、模型调用、RAG、Agent 工作流、权限、日志、部署 |
做一个用户能打开、能上传数据、能看到结果的真实功能 |
|
中层 |
Prompt 模板、模型网关、工具协议、向量检索、评估、监控 |
把能力封装成可复用模块,而不是散在页面逻辑里 |
|
模型层 |
训练、微调、推理优化、GPU、模型评测 |
应用开发岗位了解即可,不必一开始重仓 |
2. 第一阶段:模型调用基础,不要只会写 Prompt
AI 应用开发的第一关不是“会聊天”,而是能稳定调用模型。实际项目里,错误经常不是 Prompt 写得不够玄学,而是参数错、超时、返回结构不稳定、额度耗尽、密钥泄露、日志没打、重试没有边界。
|
能力 |
学到什么程度 |
练习建议 |
|
Prompt Engineering |
能把角色、任务、输入、约束、输出格式写清楚 |
同一个任务写 3 个版本,比较输出稳定性 |
|
AI API 调用 |
会处理 API Key、base_url、模型名、超时、重试、错误码 |
写一个 FastAPI 接口包装模型调用 |
|
结构化输出 |
能让模型返回 JSON,并用 schema 校验 |
生成 Bug 报告字段:type、severity、evidence、fix |
|
流式输出 |
知道 SSE/WebSocket 和模型 stream 的区别 |
做一个边生成边显示的报告页面 |
|
成本控制 |
知道 token、缓存、截断、降级模型的基本策略 |
记录每次请求的模型、token、耗时和异常 |
|
我会优先练的最小闭环 用户输入问题 -> 后端接口接收 -> 调用模型 -> 返回结构化 JSON -> 记录日志 -> 前端展示。这个闭环跑稳了,再去叠 RAG 和 Agent。 |
3. 第二阶段:RAG 是 AI 应用层的硬通货
RAG 的价值是让模型基于外部资料回答,而不是靠模型自己记忆。很多新人会把 RAG 简化成“向量数据库”,这会漏掉真正决定效果的部分:文档解析、分块策略、召回、重排、引用来源和评估集。

|
环节 |
重点 |
容易踩的坑 |
|
文档解析 |
PDF、Word、Markdown、网页转成干净文本,并保留标题/页码/来源 |
页眉页脚、表格、换行污染会影响检索 |
|
分块 |
根据标题、段落、代码函数或语义边界切 chunk |
只按固定字数切,容易把关键条件切散 |
|
Embedding |
文档入库和查询必须用同一 embedding 模型 |
换模型后忘了重新向量化 |
|
检索 |
向量检索 + 关键词检索 + metadata 过滤 |
只看相似度,不看来源和权限 |
|
重排 |
先召回 top 20,再 rerank 到 top 5 |
召回候选太少,重排也救不回来 |
|
引用 |
回答里带 source/page/file_path |
没有引用,业务方很难信 |
|
评估 |
准备问题、标准答案、期望来源和失败样例 |
凭感觉调参数,不知道有没有变好 |
对求职作品来说,RAG 项目不要只做“上传文档问答”。更好的展示方式是把问题做窄一点,例如:代码库问答、论文问答、项目文档问答、客服知识库、历史 Bug 检索。问题越具体,越容易讲清楚技术取舍。
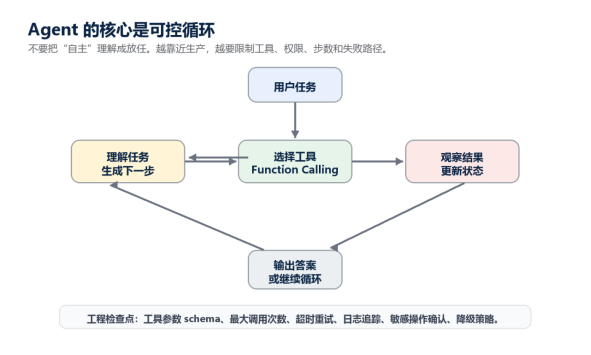
4. 第三阶段:Agent Skills,先学工具调用再谈智能体
Agent 不是让模型随便想办法,而是让模型在你定义好的工具、状态和权限里完成任务。工具调用是 Agent 的地基。没有工具 schema、权限边界和失败处理,Agent 很快就会变成不可控的“自动乱试”。
|
能力 |
具体要会 |
项目里的对应例子 |
|
Tool Use |
定义工具名称、描述、参数 schema、返回格式 |
读取日志、检索代码、生成测试模板 |
|
Function Calling |
模型输出结构化参数,程序负责真正执行函数 |
模型选择 `locate_code`,程序返回候选文件 |
|
Memory |
短期会话上下文、长期用户偏好或历史事实 |
记录用户当前分析任务和已上传证据 |
|
Planning |
把复杂任务拆成步骤,并限制最大步数 |
先解析日志,再看截图,再定位代码,最后生成报告 |
|
Streaming |
边生成边返回,处理客户端断开和错误补偿 |
报告生成时先展示概要,再补完整建议 |
5. MCP 放在哪学:在 Tool Calling 后面
MCP 可以理解成把“AI 客户端能连接哪些工具、资源、提示词”标准化。刚入门不用先背协议细节,先把 Function Calling 和普通工具调用跑明白,再学 MCP Server、MCP Client、工具暴露和外部数据连接。
- MCP Server:把数据库、文件系统、浏览器、业务 API 等能力暴露成标准接口。
- MCP Client:让 AI 客户端发现并调用这些能力。
- Resources:外部上下文,例如文件、数据库 schema、项目文档。
- Tools:可执行动作,例如查询、检索、创建任务、读取日志。
- Prompts:可复用提示词模板,让同类任务保持风格和格式稳定。
|
学习顺序建议 先会写一个普通工具函数,再会让模型用 Function Calling 调它,最后再把工具封装成 MCP Server。这样不容易被协议名词绕晕。 |
6. 本地模型和 Ollama:适合实验,不一定适合生产
Ollama 很适合本地跑开源模型,做离线实验、隐私数据测试和低成本调试。但它不是万能替代品。模型大小、显存、速度、上下文长度、中文能力、工具调用能力都要实际测。
|
适合场景 |
原因 |
注意 |
|
本地实验 |
没有 API 额度压力,方便快速试 prompt |
结果质量和商用模型可能有差距 |
|
隐私样例 |
敏感文档不用发到外部 API |
仍要注意本机环境和日志泄露 |
|
离线 Demo |
展示时不依赖外部网络 |
电脑性能会限制体验 |
|
降级方案 |
云模型不可用时保底运行 |
要给用户明确提示,不要假装效果一致 |
7. 多 Agent:不是越多越高级
多 Agent 的思路是把任务分给不同角色,比如规划、执行、审查、总结。它的好处是职责清楚,坏处是通信成本高、状态更复杂、出错点更多。所以我会把它放在完整 Agent 之后学。
|
模式 |
适合什么 |
不适合什么 |
|
串行协作 |
一个 Agent 产出,另一个 Agent 审查或补充 |
实时性要求很高的简单任务 |
|
并行协作 |
多个角度同时分析,再汇总 |
上下文强依赖的任务 |
|
层级协作 |
Planner 分配任务,Worker 执行,Reviewer 审核 |
小 Demo 或一次性脚本 |
如果项目本来一个状态图就能讲清楚,不要为了显得高级硬拆多个 Agent。面试时更重要的是能说明:为什么拆、怎么传消息、失败怎么回滚、成本怎么控制。
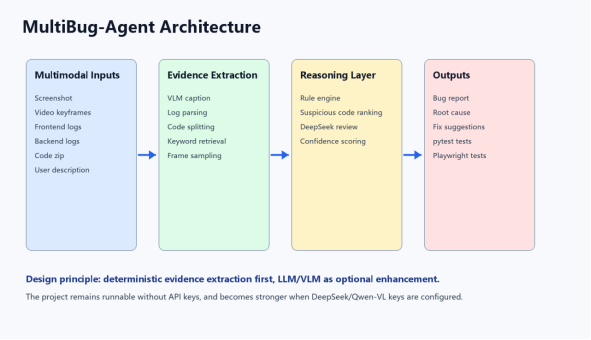
8. 用 MultiBug-Agent 承接这条路线
我的项目 MultiBug-Agent 就可以作为这条路线的一个落地例子。它不是训练模型,而是把截图、录屏、日志、代码和用户描述组织成一个缺陷分析证据包,然后结合规则解析、代码检索、可选 Qwen-VL 视觉分析和 DeepSeek 二次审查,生成 Bug 报告和测试用例。
项目地址:https://github.com/jiuguandemao/multimodal-bug-agent
|
项目模块 |
对应学习能力 |
可以怎么写到文章里 |
|
截图/录屏分析 |
多模态输入、VLM 调用、关键帧 |
不是只做文本聊天,而是把页面状态作为证据 |
|
日志解析 |
规则抽取、错误分类、结构化信号 |
先用稳定规则打底,再让模型增强 |
|
代码定位 |
RAG/检索、关键词匹配、Top-K 排序 |
把排查范围从整个仓库缩小到几个文件 |
|
DeepSeek 审查 |
结构化 Prompt、二次推理、报告补全 |
模型看的是证据包,不是混乱原始材料 |
|
测试生成 |
pytest、Playwright、回归测试思路 |
Bug 定位后要补测试,不止是输出分析文本 |
9. 一份比较现实的 6 周学习计划
|
时间 |
重点 |
产出物 |
|
第 1 周 |
Python 工程基础、Git、虚拟环境、FastAPI、HTTP |
一个能调用模型的后端接口 |
|
第 2 周 |
Prompt、结构化输出、流式、错误处理、日志 |
模型调用封装模块 + 简单 Web 页面 |
|
第 3 周 |
RAG:解析、分块、embedding、向量库、引用 |
一个带来源引用的知识库问答 Demo |
|
第 4 周 |
Tool Use、Function Calling、MCP 入门 |
一个能调用 2-3 个工具的小 Agent |
|
第 5 周 |
Agent 状态控制、LangGraph、评估和安全边界 |
完整任务流:检索 -> 工具 -> 报告 |
|
第 6 周 |
README、部署、截图、演示视频、CSDN 发布 |
GitHub 项目页 + CSDN 技术文章 |
- 每天至少留一半时间写代码。只看资料会让人误以为自己懂了。
- 每个知识点都要有一个最小可运行例子,最好再加一个失败样例。
- 项目文档要同步写,不要等项目快结束才补 README。
- 从第一天就用 Git 提交,commit 记录本身也是工程习惯的展示。
10. 参考资料和来源
|
来源 |
链接或说明 |
|
本地笔记 |
AI应用开发工程师完整学习笔记 / 03_AI应用开发 |
|
本地项目 |
MultiBug-Agent README 与 CSDN 发布稿 |
|
CSDN 创作中心 |
https://mp.csdn.net/ |
|
CSDN 发布入口 |
https://ask.csdn.net/questions/8595416 |
|
CSDN Markdown 编辑器 |
https://blog.csdn.net/2402_84764726/article/details/149290219 |
|
CSDN 创作规范 |
https://blog.csdn.net/blogdevteam/article/details/132072624 |
|
LlamaIndex RAG |
https://docs.llamaindex.ai/en/stable/understanding/rag/ |
|
LangChain RAG/Agents |
https://python.langchain.com/docs/ |
|
OpenAI 文档 |
https://platform.openai.com/docs/ |
更多推荐
 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)