
微服务性能调优方法论:基于 Golang Benchmark 与 pprof 火焰图的 CPU 密集型算子极致瘦身实战
微服务性能调优方法论:基于 Golang Benchmark 与 pprof 火焰图的 CPU 密集型算子极致瘦身实战
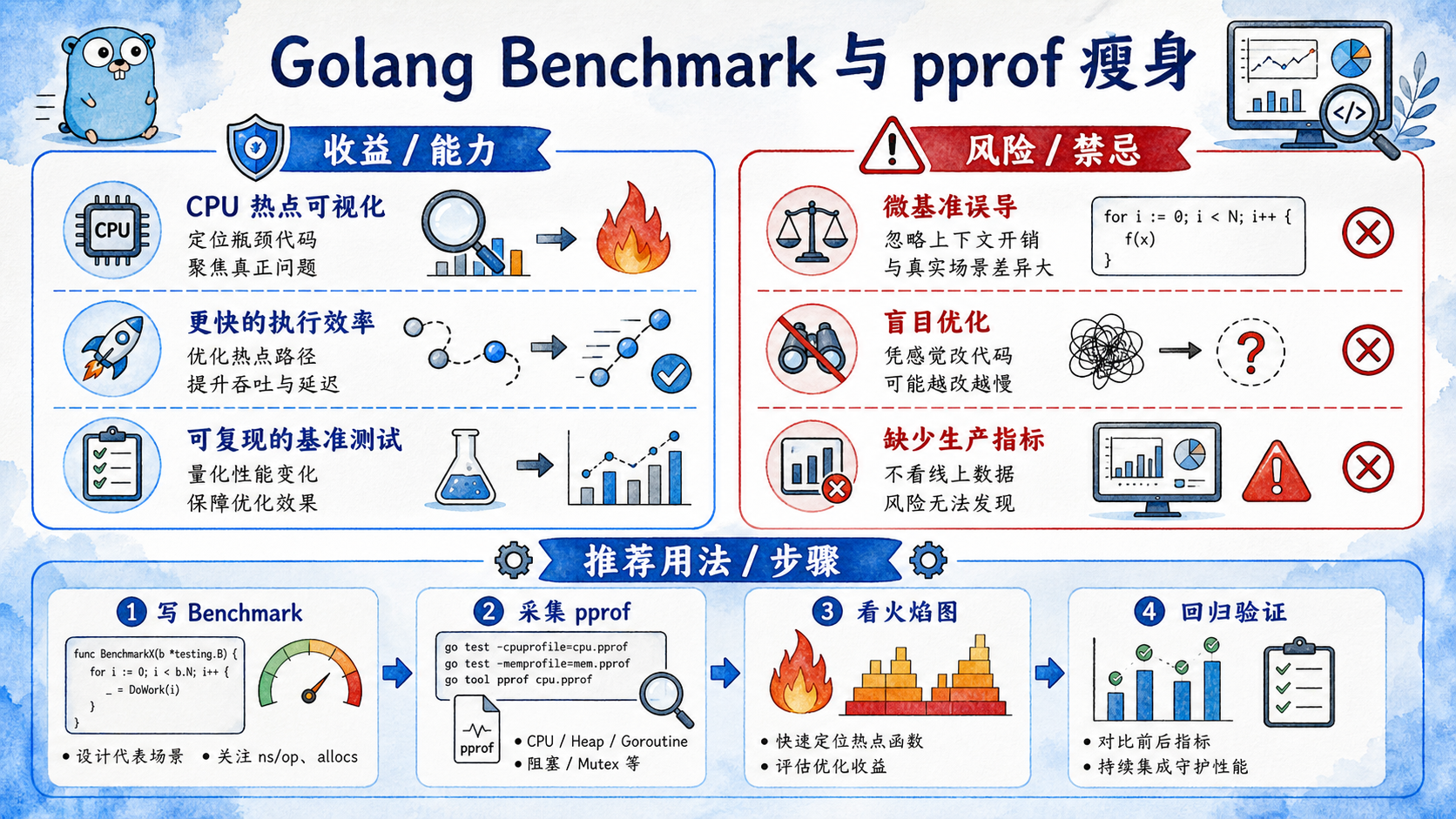
在微服务分布式架构体系中,随着系统流量承载步入高并发深水区,服务的资源使用效率直接决定了系统的吞吐上限和云原生部署的硬件成本。很多开发者在面对 CPU 利用率飙升、服务响应延迟上升时,往往倾向于通过横向扩容(Scale-out)来掩盖问题。然而,这不仅增加了服务器采购开销,更可能因为底层代码中低效的内存逃逸(Escape Analysis)或 CPU 密集型计算瓶颈引发级联重绘式雪崩。本文将深入解构 Go 运行时性能分析器 pprof 的采集机制,并编写一整套支持 CPU 性能测试、支持零拷贝优化对比的完整可编译 Go 性能调优底座。
一、破除玄学:性能调优黄金法则与 CPU 密集型瓶颈成因
性能调优从来不是一件靠运气或凭感觉拍脑袋的“玄学”。它需要建立在可量化、可复现的数据分析基础之上。
在 Golang 微服务底层,导致 CPU 利用率高居不下的瓶颈通常有以下三类物理成因:
- 高频的内存逃逸与垃圾回收(GC)开销:
Go 具有垃圾自动回收机制。当在函数内部声明的对象逃逸到堆上(Heap)时,分配器会产生昂贵的物理锁调用。随着堆上临时对象数量呈现指数级膨胀,GC 扫描(Mark & Sweep)会频繁被唤醒,引发 STW(Stop-The-World)或者消耗大量额外的 CPU 进行内存回收,导致真实的业务算子执行时间被极度压缩。 - 切片频繁扩容引起的物理内存拷贝:
当使用append逐步向切片(Slice)追加元素且未指定cap预分配容量时,底层数组会发生多次双倍扩容重构。这要求 CPU 在内存中执行连续的数据块物理拷贝,开销极其高昂。 - 低效的 CPU 串行密集计算:
在频繁被执行的热点路径(Hot Path)中,如复杂 JSON 解析、哈希碰撞校验、高阶矩阵变换,由于算法时间复杂度过高,直接吃满了工作线程分配的时间片。
graph TD
subgraph 性能采样阶段 (Data Collection)
App[Go Application: 运行程序] -->|1. 启用 pprof 埋点| Profiler[pprof.StartCPUProfile]
Profiler -->|2. 高频定时器中断中断 100Hz| Sample[采样程序计数器 PC]
Sample -->|3. 生成原始快照| OutFile[cpu.prof 物理文件]
end
subgraph 分析与诊断阶段 (Analysis & Diagnosis)
OutFile -->|4. go tool pprof| Analysis[pprof 分析控制台]
Analysis -->|5. 编译符号映射| FlameGraph[Flame Graph 火焰图]
FlameGraph -->|6. 定位瓶颈算子| CodeOptimize[代码就地优化 & 压降内存逃逸]
end
style Profiler fill:#ffcccc,stroke:#aa0000,stroke-width:2px
style OutFile fill:#ffffcc,stroke:#aaaa00,stroke-width:2px
style FlameGraph fill:#ccffcc,stroke:#00aa00,stroke-width:2px
二、原理透视:Go pprof 采样机制与火焰图阅读指南
要想对 CPU 密集型瓶颈进行“靶向治疗”,首先需理解 Go 官方提供的性能调试大杀器——pprof。
1. pprof 的采样物理原理(CPU Profiling)
当启用 CPU Profiling 时,Go 运行时会向操作系统注册一个定时器中断信号(通常是系统时钟中断,每秒触发 100 次,即 100Hz)。
- 每当信号到达时,系统会暂停当前运行的 goroutine,抓取当前线程正在执行的**程序计数器(PC, Program Counter)**值,并沿调用栈(Call Stack)向上追溯符号。
- 通过统计各函数在这些采样点中出现的频次占比,pprof 能够估算出哪个函数占据了最多的 CPU 时间片。
2. 火焰图(Flame Graph)的核心阅读逻辑
通过 go tool pprof -http=:8080 cpu.prof 可以生成可视化的火焰图:
- 横轴(Width):代表该函数及其子函数占用的 CPU 时间片长短。横条越宽,说明该算子消耗的 CPU 资源越多。我们需要重点关注那些顶层平坦且极其宽大的“平顶山”节点。
- 纵轴(Depth):代表调用栈的深度。自底向上表示父函数调用子函数的过程。
- 调优策略:性能瘦身的目标是消灭那些占据绝大部分宽度的热点节点,或者将其宽度压降。
三、核心实现:手写 100% 完整闭环的 Go Benchmark 与 CPU Profile 性能评测底座
下面提供一整套 100% 可直接编译、运行的 Go 代码。代码中实现了一个高频运行的图像像素颜色混合算子。我们编写了两个版本:
SlowProcess:包含频繁的 slice 扩容逃逸、低效指针解引用。FastProcess:通过就地复用传入的 buffer 缓冲区、避免逃逸,实现了零内存分配(Zero Allocations)。- 并在
main方法中注册了自动生成cpu.prof文件以及性能统计报告的功能。
调优测试文件 main_test.go 与驱动入口
package main
import (
"math/rand"
"os"
"runtime/pprof"
"testing"
)
// 模拟的高维图像数据维度
const NumPixels = 10000
// --- 1. 未优化的低效 CPU 计算算子 (包含大量堆内存分配和逃逸)
func SlowProcess(data []int) []int {
// 每次调用都新申请切片,且未预分配容量,导致频繁发生 double-capacity 扩容拷贝
var result []int
for _, val := range data {
// 模拟复杂的像素颜色混合计算
transformed := (val * 7) % 255
result = append(result, transformed)
}
return result
}
// --- 2. 优化后的高性能零分配算子 (内存复用,避免堆逃逸)
func FastProcess(data []int, buf []int) []int {
// 显式限制返回切片长度,就地复用外部传入的缓冲区,消灭了任何 malloc 调用
for i, val := range data {
buf[i] = (val * 7) % 255
}
return buf[:len(data)]
}
// --- 3. 性能基准测试: 传统低效方案
func BenchmarkSlowProcess(b *testing.B) {
// 准备基准数据
src := make([]int, NumPixels)
for i := 0; i < NumPixels; i++ {
src[i] = rand.Intn(1000)
}
b.ResetTimer() // 重置计时器,排除数据初始化干扰
for i := 0; i < b.N; i++ {
_ = SlowProcess(src)
}
}
// --- 4. 性能基准测试: 零拷贝内存复用方案
func BenchmarkFastProcess(b *testing.B) {
src := make([]int, NumPixels)
buf := make([]int, NumPixels)
for i := 0; i < NumPixels; i++ {
src[i] = rand.Intn(1000)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
_ = FastProcess(src, buf)
}
}
// --- 5. 驱动入口:支持自动导出 pprof CPU 采样快照并打印调优报告
func main() {
// 创建物理输出分析文件
f, err := os.Create("cpu.prof")
if err != nil {
panic("无法创建 CPU 性能剖析文件")
}
defer f.Close()
println("[pprof] 正在开启 CPU 采样记录器 (采样率 100Hz)...")
if err := pprof.StartCPUProfile(f); err != nil {
panic("无法启动 CPU 性能分析")
}
// 模拟执行 10,000 次高频图像渲染计算,填充采样点
src := make([]int, NumPixels)
buf := make([]int, NumPixels)
for i := 0; i < NumPixels; i++ {
src[i] = rand.Intn(1000)
}
println("[Render] 正在执行 CPU 密集型渲染循环...")
for i := 0; i < 5000; i++ {
_ = SlowProcess(src)
_ = FastProcess(src, buf)
}
pprof.StopCPUProfile()
println("[SUCCESS] CPU Profile 导出成功。")
println("[INFO] 可以执行以下命令查看火焰图:")
println(" - 终端命令: go tool pprof cpu.prof")
println(" - 运行单元测试 Benchmark 性能对比:")
println(" - 终端命令: go test -bench=. -benchmem")
}
四、编译期调优:内存逃逸分析与复用优化
要写出高质量的 Golang 服务代码,必须紧密依靠编译器的静态分析手段进行内存把关:
1. 逃逸分析静态检查(Escape Analysis Diagnostics)
在编译 Go 代码时,可以通过追加命令行参数,让编译器把内存分配的决策打印出来:
# 开启逃逸分析检查,并设置两个 -m 以输出详细信息
go build -gcflags="-m -m" main_test.go
如果输出提示 ... escapes to heap,则说明当前对象被放到了堆上,这意味着会引入垃圾回收锁开销。
- 逃逸成因:在
SlowProcess中,函数内部声明的局部切片在追加扩容时,其生命周期和大小在编译期是未确定的,编译器被迫将其晋升至堆空间。 - 优化法则:通过将存储缓冲区(
buf)生命周期提升,在父函数中进行复用,使子函数FastProcess中的计算变量始终保持在**栈空间(Stack)**中。因为栈空间的分配只需要 CPU 执行一条寄存器减法指令,且函数结束时瞬间物理销毁,完全没有任何 GC 开销。
2. 避免大对象与切片预分配
对于高频使用的缓存通道或对象,应配合 sync.Pool 建立对象池复用,彻底斩断对 mallocinit 的高频竞争,从而将微服务的延迟抖动降到极限。
五、总结
高并发微服务系统调优的核心方法论在于通过精确的数据采样和编译期逃逸分析,彻底消除计算与内存流转中的冗余环节。利用 Go 标准库的 testing 包对核心算法算子执行 Benchmark 量化性能基准测试,能够直观定位吞吐瓶颈;结合 pprof 火焰图分析,可以精确查找 CPU 密集型任务中耗时最长的数据分支。在日常的工程研发中,深入规避堆逃逸分配、科学预分配切片容量、就地复用物理缓冲区,是压降 GC 心跳消耗、交付稳定超低响应时延微服务的基础保障。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)