
GPT-5.5教程:多轮对话上下文管理,一次处理大量链接的知识工作流
# GPT-5.5教程:多轮对话上下文管理,一次处理大量链接的知识工作流
你有没有遇到过这种场景:收藏夹里攒了几十篇文章,Notion、飞书、浏览器标签页开了一堆,真正要整理时却不知道从哪篇开始。尤其是做知识管理时,链接多、信息杂、结论分散,手动归纳非常耗时间。我的做法是把“链接处理”拆成固定流程,再借助长上下文模型完成批量阅读、提炼和归档。如果你想快速体验多模型对比,也可以使用库拉AI镜像平台,它支持常见大模型的在线使用,注册门槛较低,适合临时测试提示词和工作流。(https://p.877ai.cn/)(复制链接进入)
## 一、为什么多轮对话容易“跑偏”
很多人用长上下文模型处理资料时,第一步就犯了一个错误:把所有链接、需求、格式要求一次性丢进去。
这样做看起来省事,实际很容易出现三个问题:
1. 模型不知道哪些内容更重要
2. 多轮追问后,前面的目标被稀释
3. 输出结果混在一起,难以复用
上下文管理的核心,不是“塞得越多越好”,而是让模型知道:当前任务处于哪个阶段、哪些信息是事实、哪些是你的意图、哪些是输出约束。
## 二、推荐的四层上下文结构
在处理大量链接时,可以把上下文拆成四层。
### 1. 任务层:告诉模型最终目标
例如:
> 我正在整理一批关于知识管理和AI检索的文章,请帮我提炼主题、观点、可执行方法,并输出为CSDN文章素材库。
任务层要稳定,后续对话尽量不要频繁改。
### 2. 资料层:分批输入链接内容
如果一次有30个链接,不建议全部塞入。可以按主题分组,比如:
- 个人知识库
- 长上下文模型
- 信息筛选方法
- 自动化归档
每次输入一组,让模型先做结构化摘要。
### 3. 规则层:固定输出格式
比如要求每篇资料都输出:
- 标题
- 核心观点
- 可引用金句
- 方法步骤
- 适合写入文章的位置
格式固定后,后续内容才方便拼接。
### 4. 状态层:让模型维护进度
每处理完一批资料,让模型更新“当前资料索引”。这一步很重要,它能减少重复分析,也能避免遗漏。
## 三、实战流程:一次处理大量链接
下面给出一个适合CSDN读者的工作流。
### 第一步:建立总控提示词
你可以先发送这段:
```text
你是我的知识管理助手。接下来我会分批提供多个链接的正文或摘要。
请不要急着写文章,先按固定结构整理资料。
每批资料处理完成后,请更新:
1. 已处理资料编号
2. 主要主题
3. 关键观点
4. 可合并的重复观点
5. 下一步建议
如果发现信息不足,请明确指出缺口。
```
这段提示词的作用是“定规则”。它能让后续多轮对话保持一致。
### 第二步:分批输入链接内容
如果链接不能直接访问,建议你自己先复制网页正文或摘要。每批控制在3到5篇,格式如下:```text
第1批资料:
[资料1]
标题:
来源:
正文摘要:
[资料2]
标题:
来源:
正文摘要:
请按前面约定的结构整理,不要写最终文章。
```
这里不要急着让模型输出完整内容。先让它成为“资料管理员”。
### 第三步:生成资料索引表
处理几批后,可以要求模型汇总:
```text
第1批资料:
[资料1]
标题:
来源:
正文摘要:
[资料2]
标题:
来源:
正文摘要:
请按前面约定的结构整理,不要写最终文章。
```
这样你会得到一张非常有用的素材地图。后面写文章、做PPT、写技术方案,都能直接调用。
## 四、用代码管理链接批次
如果你经常处理大量链接,可以用一个简单脚本把链接列表切成批次。下面是Python示例:```python
links = [
"https://example.com/a",
"https://example.com/b",
"https://example.com/c",
"https://example.com/d",
"https://example.com/e",
"https://example.com/f",
]
def chunk_list(data, size=3):
for i in range(0, len(data), size):
yield data[i:i + size]
for idx, group in enumerate(chunk_list(links, 3), start=1):
print(f"第{idx}批资料:")
for link in group:
print("-", link)
print()
```
这个脚本本身不复杂,但它能帮你形成稳定输入节奏。对于长上下文任务来说,节奏比单次输入量更重要。
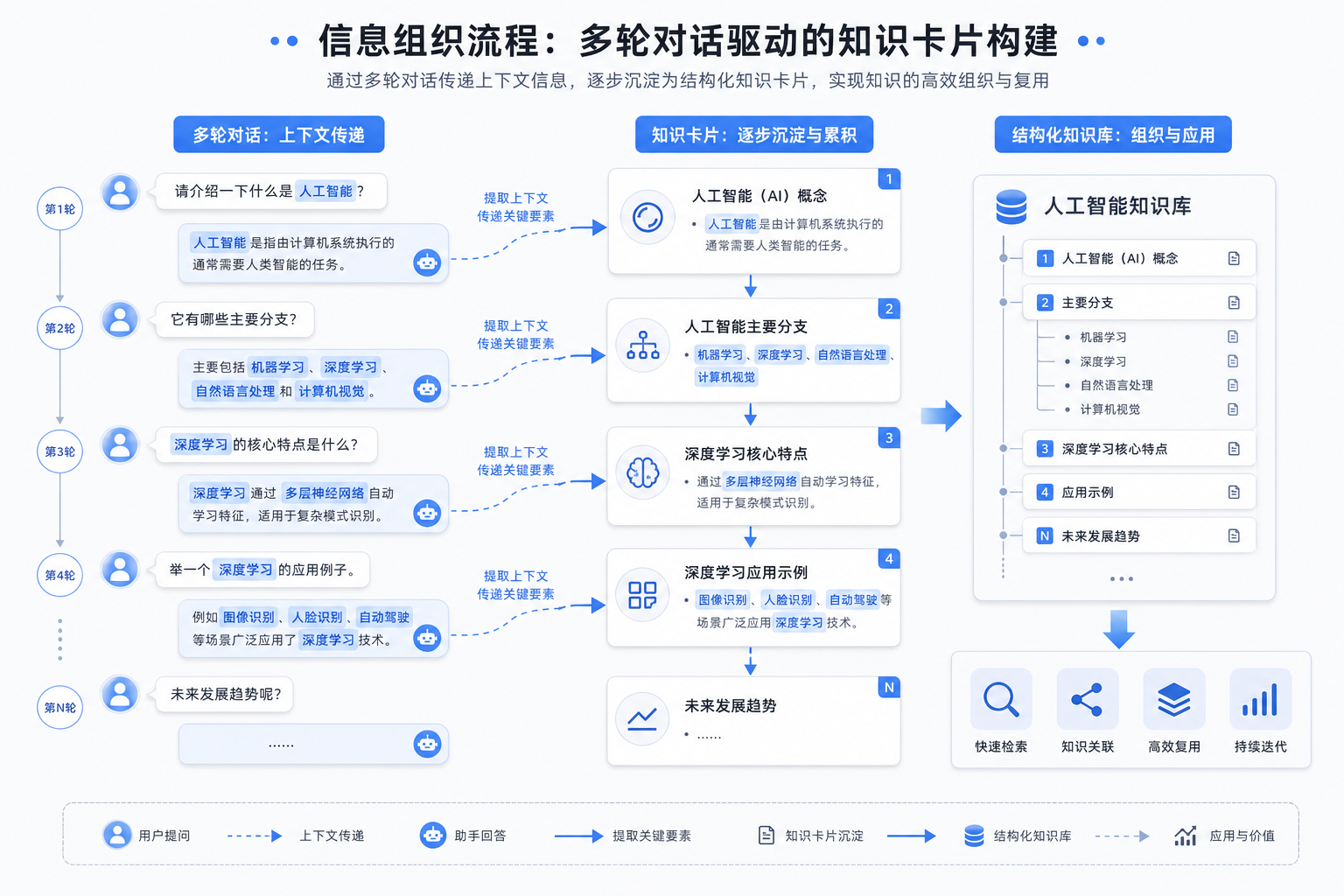
## 五、多轮对话中的“记忆点”怎么写
每轮结束后,建议让模型生成一个“上下文摘要”。格式可以这样:
```text
请生成本轮上下文摘要,要求:
1. 不超过300字
2. 保留已确认结论
3. 标记待验证信息
4. 给下一轮对话使用
```
下一轮开始时,把这段摘要放在最前面。这样即便对话变长,也能把核心信息重新拉回模型注意力范围内。
## 六、常见错误与修正方法
### 错误1:把模型当搜索引擎
模型更适合做整理、归纳、改写和推理。链接内容最好由你提供,或者至少提供网页摘要,否则它可能只能给出泛泛而谈的结果。
### 错误2:每一轮都换格式
今天让它输出表格,下一轮让它写段落,再下一轮又要脑图结构,最后会很乱。建议先固定中间格式,最后再转换成文章。
### 错误3:不区分事实和观点
知识管理最怕“看起来很顺,但来源不清”。可以要求模型标注:
- 原文事实
- 作者观点
- 模型推断
- 需要人工确认
这个习惯能显著提升内容可靠性。
## 七、最终生成文章的提示词
当资料都整理完,再让模型写正文:
```text
基于前面整理的资料,请生成一篇面向CSDN读者的技术文章。
要求:
1. 标题清晰
2. 结构包含背景、方法、示例、总结
3. 保留可执行步骤
4. 不夸大模型能力
5. 重要结论尽量对应资料编号
```
如果你想继续优化,可以追加:
```text
请检查文章是否存在:
1. 概念跳跃
2. 重复表达
3. 缺少示例
4. 结论没有依据
并给出修改版。
```
## 八、总结
用GPT-5.5这类长上下文模型处理大量链接,关键不是一次输入多少,而是建立可持续的上下文管理机制。
可以记住这条主线:
> 总控提示词定规则,分批资料建索引,多轮摘要保状态,最终再统一生成内容。
对知识管理爱好者来说,这套方法的价值不只是写文章。它还能用于读书笔记、行业研究、竞品分析、课程整理和个人知识库建设。只要流程稳定,链接越多,越能体现结构化处理的优势。
注:本文配图由ChatGpt Image-2辅助生成。
【本文完】
更多推荐
 5
5 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)