
告别手写Prompt!2026年AI编程新风口:掌握Loop Engineering,让Agent自主运转!
一、为什么需要区分这两个概念?
过去一两年,Context Engineering、Harness Engineering 相继走红。它们分别解决「单次会话里给 Agent 什么上下文」和「单次运行里 Agent 活在什么环境里」。但生产里真正难的不是「这一轮 prompt 写得好不好」,而是:
• 谁去发现待办?
• 谁决定先做哪件?
• 上一轮做到哪了?
• 改代码的和验代码的是不是同一个人?
• 出事了什么时候必须喊人?
• 这套东西每天跑会不会把 token 烧穿?
Agent Loop 回答的是「怎么让它转起来」;Loop Engineering 回答的是「怎么让它转得久、转得稳、转得在你睡着的时候也不闯祸」。
Addy Osmani 的概括很准:
Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead.
杠杆点已经从「打磨单条 prompt」移到「设计编排 Agent 的控制系统」。
二、Agent Loop 是什么?
Agent Loop 是 Agent 工具里的一种递归执行原语(primitive)。
你定义一个目的,系统按固定节奏(或直到满足停止条件)反复调用 Agent:读状态 → 行动 → 写回结果 → 下一轮。Claude Code 的 /loop、/schedule、/goal,Grok 的 /loop [interval],GitHub Actions 的 cron,本质都是同一类东西。
cobusgreyling/loop-engineering 里的定义:
A loop is a recursive goal: define purpose, let the agent iterate (with sub-agents and external memory) until done or until the loop escalates to a human.
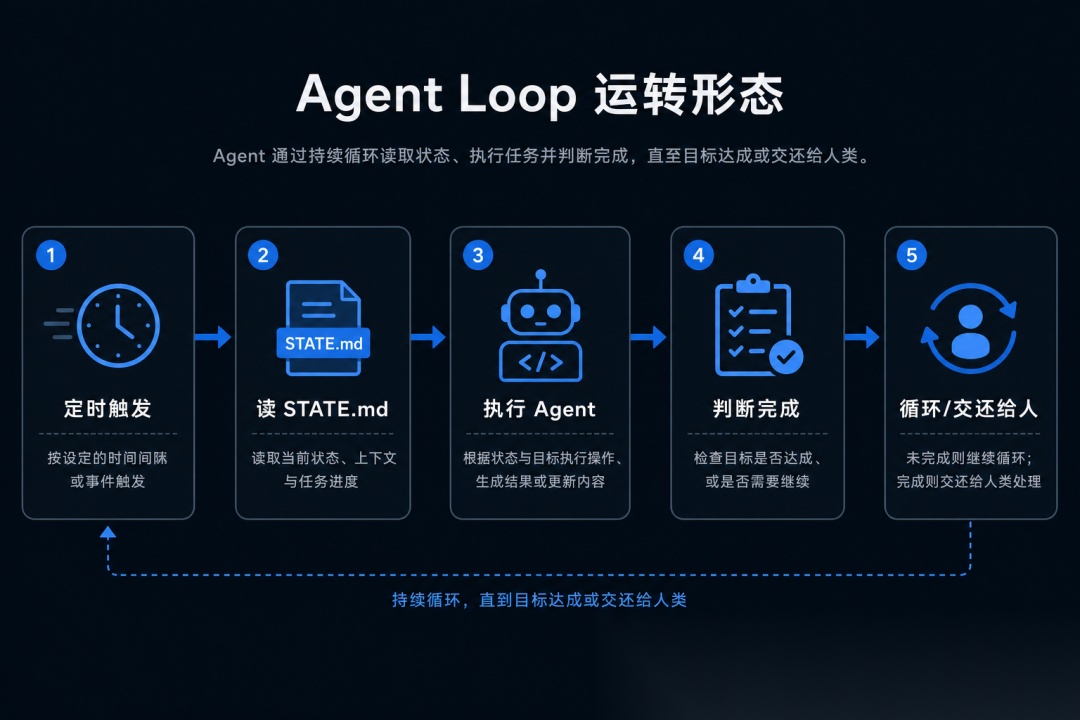
图 1:Agent Loop 的核心是「定时触发 → 读状态 → 执行 → 判断 → 循环或交还给人」。
Agent Loop 解决什么问题?
| 维度 | Agent Loop 提供的能力 |
|---|---|
| 持续性 | 不用你每次打开终端重新 prompt |
| 递归性 | 同一目标可多轮迭代直到「够好」 |
| 自动化 | 把「我每天早上该查 CI」变成系统行为 |
Agent Loop 的边界
仅有 /loop 不等于 一套可上线的工程系统。一个裸 loop 往往缺:
• 分诊规则(什么该做、什么该忽略)
• 外部记忆(跨 session 的状态)
• Maker/Checker 分离(写代码的自己验自己)
• 人工闸门(高风险路径必须升级)
• 成本上限与可观测性
所以:Agent Loop 是零件;Loop Engineering 是用这些零件造一台能跑的生产机器。
三、Loop Engineering 是什么?
Loop Engineering 是围绕 Agent Loop 展开的系统设计方法论——你如何发现工作、分配任务、验证结果、持久化状态,并在该交还时交还给人。
Cobus Greyling 的开源参考库 把它具象化为:模式(patterns)、启动模板(starters)、检查清单(checklist)、审计工具(loop-audit)、成本估算(loop-cost)和真实踩坑故事(stories)。
与相关概念的三层关系
参考库的 concepts 文档 把几层概念捋得很清楚:
Harness = 单次 Agent 运行的环境(工具、权限、规则)
Loop = Harness + 调度 + 状态 + 验证链
Loop Engineering = 设计并运营上述 Loop 系统的工程实践
| 概念 | 关注点 | 类比 |
|---|---|---|
| Agent Harness Engineering | 一次会话里 Agent 能用什么、知道什么 | 单个工位的工具箱 |
| Agent Loop | 让 Agent 按节奏反复跑 | 传送带的运转 |
| Loop Engineering | 整条产线如何发现任务、分工、质检、交接 | 工厂设计与 SOP |

图 2:Harness 管单次运行,Loop 管重复编排,Loop Engineering 管整套系统设计与运营。
Loop Engineering 的六大构件 + 记忆
一个能「无人值守」地跑起来的 loop,通常不是一条长 prompt,而是六个部分:
| 构件 | 在 Loop 里的职责 |
|---|---|
| Automations / Scheduling | 心跳:按 cadence 发现与分诊 |
| Worktrees | 并行执行时文件隔离,避免 merge 灾难 |
| Skills | 持久项目知识,偿还 intent debt |
| Plugins & Connectors (MCP) | 连 GitHub、Linear、Slack 等真实系统 |
| Sub-agents | Maker / Checker 分工,禁止自评 |
| + Memory / State | STATE.md 等外部状态,跨 session 的脊柱 |

图 3:从调度到人工闸门的完整 Loop 流水线(来源:loop-engineering 参考库)。
Loop Engineering 还管什么?
除了「怎么转」,它还管:
- 分阶段上线:L1 只报告 → L2 小步自动修复 → L3 无人值守
- 模式选型:Daily Triage、PR Babysitter、CI Sweeper、Dependency Sweeper 等
- 安全与闸门:denylist、禁止盲目 auto-merge、MCP 权限最小化
- 成本与可观测性:
loop-budget.md、loop-run-log.md、loop-cost估算 - 多 Loop 协调:多个 loop 同时跑时的优先级与冲突处理
参考库自己就在吃自己的狗粮:用 validate-patterns + audit workflow 维护仓库,并在根目录用 LOOP.md 记录「这个参考库自己跑哪些 loop」。
四、核心对比:一张表看懂区别
| 维度 | Agent Loop | Loop Engineering |
|---|---|---|
| 本质 | 运行机制 / 产品功能 | 系统设计 / 工程方法论 |
| 你在做什么 | 启动一个会重复的 Agent 任务 | 设计发现→执行→验证→交接的完整系统 |
| 粒度 | 一次递归目标 + 调度 | 模式、技能、状态 schema、安全策略、成本模型 |
| 成功标准 | 「它又在跑了」 | 「它跑得对、跑得省、出事能停、人能看懂它干了什么」 |
| 典型产物 | /loop 1d ... 一条命令 |
STATE.md + Skills + Worktree 策略 + Verifier + Checklist |
| 风险 | 可能空转、重复犯错、烧 token | 若设计不当,会放大错误判断;设计得当,则放大工程产能 |
再打个比方:
• Agent Loop 像 while (!done) { agent.run(); } —— 循环语句本身。
• Loop Engineering 像写整个 main():输入从哪来、状态存哪、谁写谁验、超时怎么办、日志打哪、什么时候 break 叫人。
五、从 Agent Loop 到 Loop Engineering:一个具体例子
假设你想「每天早上自动看 CI 挂了什么」。
只有 Agent Loop(初级阶段)
/loop 1d 检查 CI 失败,尝试修复
问题很快会出现:
• 昨天修过的 flaky test,今天又被当成新故障
• Agent 自己改、自己说「好了」
• 没有记录「哪些该忽略」(Dependabot PR、噪音告警)
• 每天早上跑满 context,月底账单难看
做了 Loop Engineering(可上线阶段)
你会补齐一整套设计:
1. 选对模式 — Daily Triage,第一周 L1 只报告、不自动修。
2. 写 Triage Skill — 固定输出格式:High Priority / Watch List / Noise。
3. 建 STATE.md — 每轮必读必写:
Loop State — Project X
Last run: 2026-06-11 08:15 UTC
High Priority
- #1241 — auth flow flaky test (CI red on main)
Loop action: worktree fix proposed, waiting human PR review.
Watch List
- PR #1238 open 4 days, no activity.
Recent Noise (ignored)
- Dependabot PRs
4. 分阶段放权 — L1 人读报告 → L2 小修复 + 独立 Verifier 跑测试 → L3 才考虑无人 merge。
5. 加护栏 — loop-budget.md 日 token 上限;auth/payment 路径进 denylist;同一 PR 自动修超过 3 次就升级给人。
6. 可审计 — npx @cobusgreyling/loop-audit . --suggest 打出 Loop Readiness Score。
同一条 /loop 命令,有没有 Loop Engineering,差的是整个操作系统。
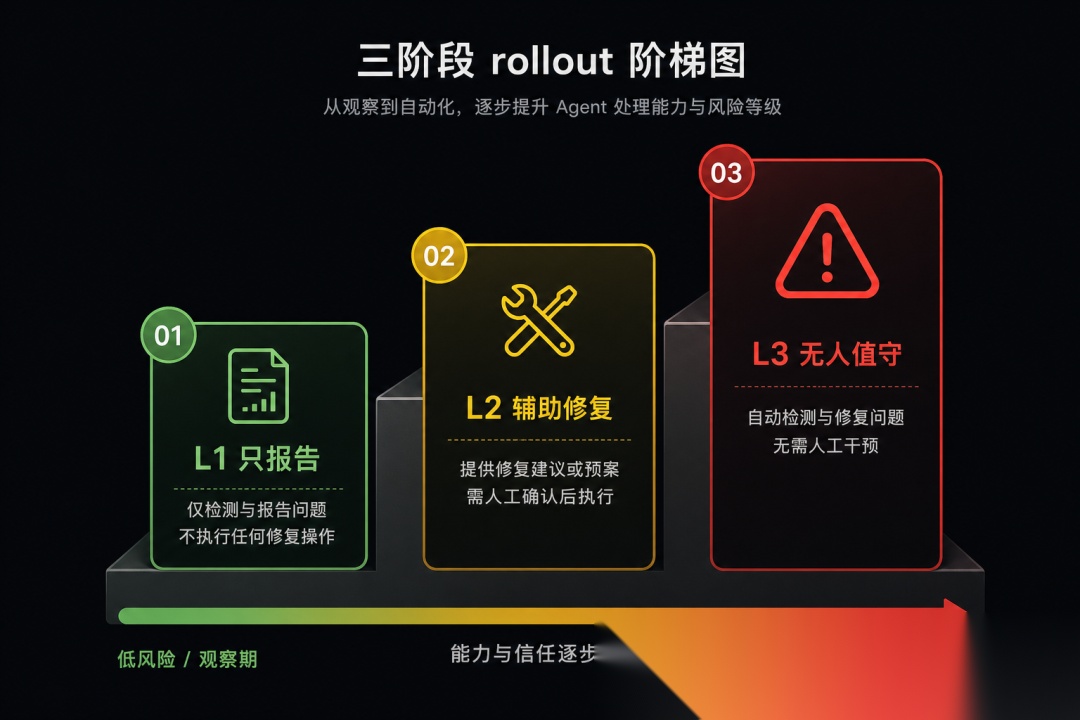
图 4:参考库建议的 L1 报告 → L2 辅助修复 → L3 无人值守分阶段路径。
六、Loop Engineering 必须正视的三笔「债」
参考库在 concepts 和 README 的 Caveats 里反复强调:
1. Intent Debt(意图债)
每个 session Agent 都是「冷启动」。团队约定、构建命令、「我们从不那样做」——若不写进 Skills / AGENTS.md,每轮 loop 都在重新猜。
2. Comprehension Debt(理解债)
Loop 越快,仓库里「你写过但没读过」的代码越多。Loop 交付了,不代表你理解了。
3. Cognitive Surrender(认知投降)
最危险的用法:把 loop 当成逃避思考的按钮。Addy Osmani 提醒:
Build the loop. But build it like someone who intends to stay the engineer, not just the person who presses go.
同一个 loop 设计,可以加速真工程师,也可以加速「只会按 Go 的人」——区别在你有没有把判断力编码进 Skills 和 Verifier。
七、怎么开始:参考库里的 5 分钟路径
cobusgreyling/loop-engineering 提供了从概念到落地的完整路径:
| 步骤 | 做什么 |
|---|---|
| 1 | 读 Substack 长文 建立概念 |
| 2 | 用 Pattern Picker 选第一个 loop |
| 3 | npx @cobusgreyling/loop-init . --pattern daily-triage 脚手架 |
| 4 | npx @cobusgreyling/loop-cost 估算 token |
| 5 | npx @cobusgreyling/loop-audit . --suggest 查就绪分 |
| 6 | 按 Loop Design Checklist 从 L1 起步 |
六种生产模式(Daily Triage、PR Babysitter、CI Sweeper、Dependency Sweeper、Changelog Drafter、Post-Merge Cleanup)都配有 starter kit,可在 Grok、Claude Code、Codex、GitHub Actions 上对照使用。
八、结论:你下一步该升级什么?
| 如果你现在… | 说明你在… | 下一步 |
|---|---|---|
| 手动写每一轮 prompt | Harness + Prompt 阶段 | 先固化 Skills 和项目约定 |
会用 /loop 但无 STATE、无 Verifier |
有 Loop,无 Engineering | 补状态文件 + L1 报告模式 |
| 有分诊 Skill + STATE + Maker/Checker | Loop Engineering 入门 | 跑 audit、设 budget、扩到 L2 |
| 多 loop 并行 + 闸门 + 可观测 | Loop Engineering 成熟 | 读 failure modes、multi-loop 协调 |
Agent Loop 让 AI 编程从「一次性对话」变成「可重复的自动化」。
Loop Engineering 让这种自动化从「个人小技巧」变成「可审计、可交接、可规模化的工程系统」。
Boris Cherny 和 Peter Steinberger 说的其实不是「别写 prompt 了」——而是:你的高杠杆工作,已经从「写下一句话」变成了「设计下一套 loop」。
结语:抓住大模型时代的职业机遇
AI大模型的发展不是“替代人类”,而是“重塑职业价值”——它淘汰的是重复性、低附加值的工作,却催生了更多需要“技术+业务”交叉能力的高端岗位。对于求职者而言,想要在这波浪潮中立足,不仅需要掌握Python、TensorFlow/PyTorch等技术工具,更要深入理解目标行业的业务逻辑(如金融的风险控制、医疗的临床需求),成为“懂技术、懂业务”的复合型人才。
无论是技术研发岗(如算法工程师、研究员),还是业务落地岗(如产品经理、应用工程师),大模型都为不同背景的职场人提供了广阔的发展空间。只要保持学习热情,紧跟技术趋势,就能在AI大模型时代找到属于自己的职业新蓝海。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)

更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)