
调查研究-206 DeepSeek DSpark 深度解析:大模型推理加速,正在从“模型能力”转向“系统工程”
DeepSeek DSpark 深度解析:大模型推理加速,正在从「模型能力」转向「系统工程」
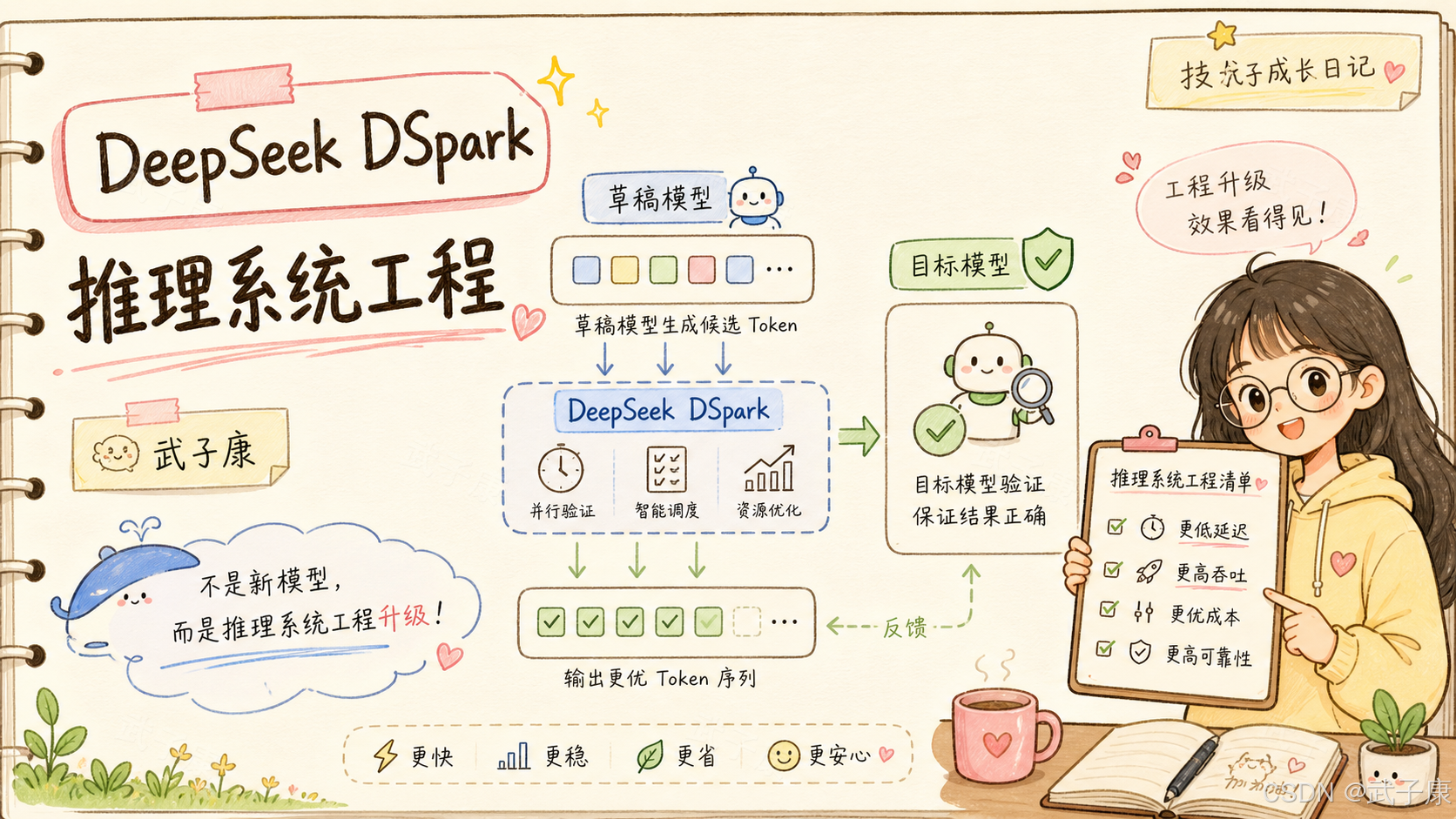
TL;DR
- 场景:DeepSeek-V4-Flash / DeepSeek-V4-Pro 预览版生产推理、Eagle3 / DFlash 之后的下一代 speculative decoding 框架,以及围绕 draft model 训练/评估的开源工程基建 DeepSpec。
- 结论:DSpark 用 semi-autoregressive drafting 缓解并行草稿的 suffix decay,再用 confidence-scheduled verification 让验证长度随草稿置信度和系统负载动态变化,把 speculative decoding 从离线方法推进到生产级 serving。
- 产出:一套可直接落地的推理加速框架 + 一个 full-stack 开源 codebase(数据准备、draft 实现、训练、评估、DSpark/DFlash/Eagle3 三算法、Qwen3/Gemma checkpoint 指引)。DeepSeek-V4-Flash 在 80–120 tok/s/user SLA 下相比 MTP-1 提升 51%–661% aggregate throughput,per-user generation speed 提升 60%–85%。
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| DSpark 论文公开 | ✅ 已验证 | DeepSeek + 北大,2026-06-27 发布 |
| DeepSpec GitHub 开源 | ✅ 已验证 | deepseek-ai/DeepSpec,MIT 协议 |
| Semi-autoregressive drafting 设计 | ✅ 已验证 | 并行 backbone + 轻量 sequential module,缓解 suffix decay |
| Confidence-scheduled verification 设计 | ✅ 已验证 | 按草稿置信度与系统负载动态调整验证长度 |
| 接入 DeepSeek-V4-Flash preview 生产服务 | ✅ 已验证 | 替换 MTP-1 baseline |
| 接入 DeepSeek-V4-Pro preview 生产服务 | ✅ 已验证 | 替换 MTP-1 baseline |
| 相比 Eagle3 accepted length 提升 ~26–31% | ✅ 已验证 | Qwen3-4B / 8B / 14B macro-average |
| 相比 DFlash accepted length 提升 ~16–19% | ✅ 已验证 | Qwen3-4B / 8B / 14B macro-average |
| DeepSeek-V4-Flash 80 tok/s/user SLA 下吞吐 +51% | ✅ 已验证 | 论文公开数字,对比 MTP-1 baseline |
| DeepSeek-V4-Flash 120 tok/s/user SLA 下吞吐 +661% | ⚠️ 待验证 | 论文公开数字,但属高 SLA 名义上限,主要说明系统边界扩展 |
| DeepSeek-V4-Flash per-user generation speed +60–85% | ✅ 已验证 | matched practical throughput 下 |
| DeepSpec Qwen3-4B 默认 target cache ≈ 38TB | ⚠️ 待验证 | 用户原文给出,独立信源未完整核实,部署前应实测 |
1. 先说人话:speculative decoding 是什么?
大语言模型正常生成文本时,是一个 token 一个 token 往外吐。
比如模型要生成一句话:
今天的天气很好,适合出去走走。
它不是一次把整句话写完,而是先生成"今天",再生成"的",再生成"天气",再生成"很"。
每一步都要跑一次目标大模型。
这就是 decode 慢的根源。
speculative decoding 的思路可以理解成:
先让一个小模型当草稿员,提前猜后面几个 token;
再让目标大模型当审核员,一次性检查这几个 token 能不能用。
如果小模型猜对了,目标大模型一次接受多个 token,生成速度就变快。
如果小模型猜错了,目标大模型不会输出错误内容。它会从第一个错误位置重新采样,并丢弃后续草稿。
所以 speculative decoding 最关键的一点是:
它不是用低质量换速度,而是在保持目标模型输出分布不变的前提下,
通过更聪明的草稿和验证机制减少目标大模型的有效调用成本。
普通解码像是:
大模型写一个字,停一下;
再写一个字,再停一下。
speculative decoding 更像是:
小模型先写一小段草稿;
大模型快速批改;
对的直接通过,错的地方重新写。
这对聊天、代码生成、结构化输出、实时语音对话、Agent 多轮调用都很重要。因为这些场景真正敏感的不是离线 benchmark,而是用户能不能更快看到下一段输出,服务端能不能用同样 GPU 扛住更多请求。
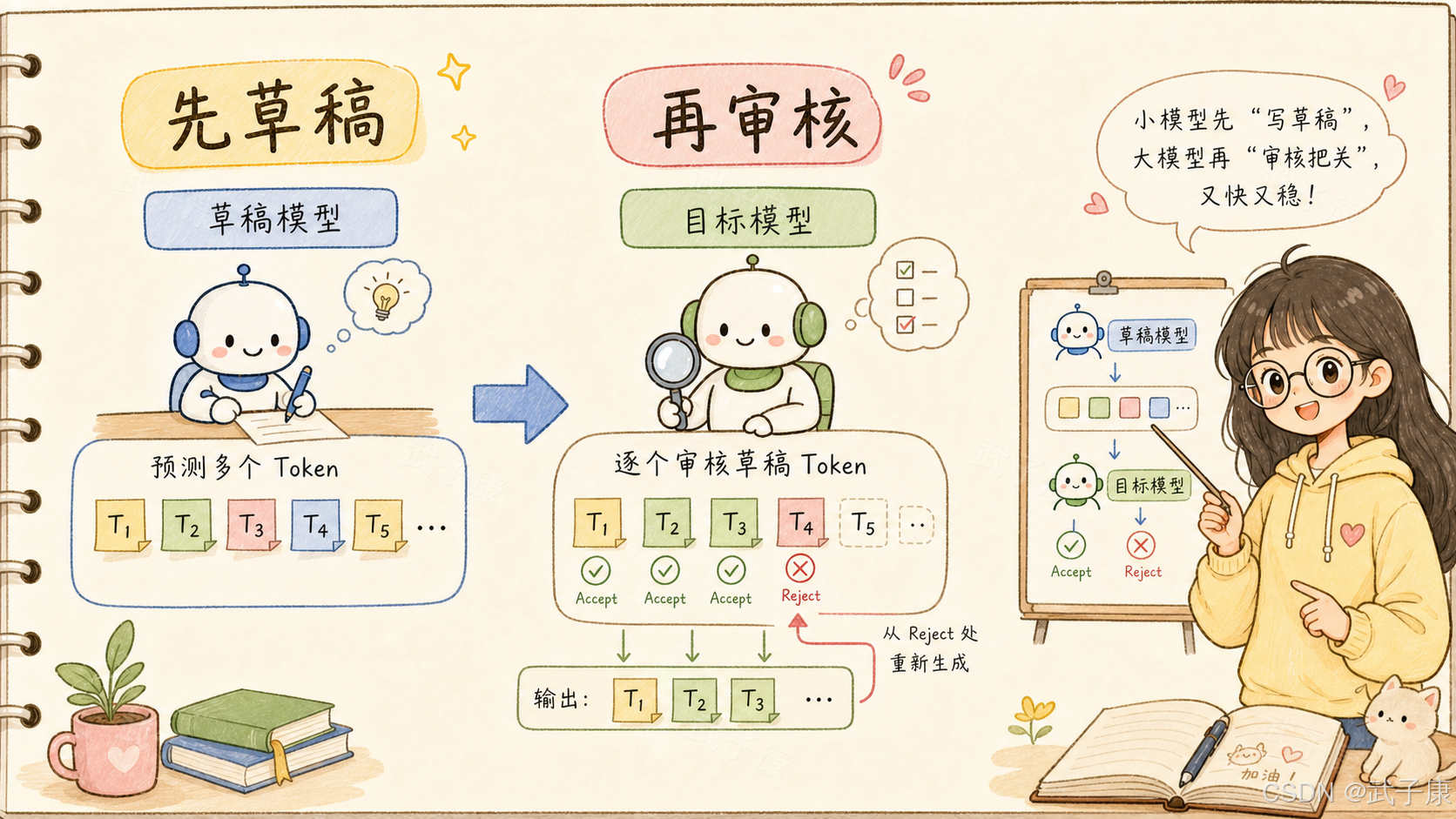
2. DSpark 到底解决了什么问题?
speculative decoding 的难点不是"让小模型先猜",而是:
小模型猜得越多,后面的 token 越容易不稳。
这叫 suffix decay。
假设 draft model 一次猜 8 个 token。第 1 个 token 可能很准,第 2 个也还行,但越往后,路径分歧越多。到了第 5、第 6 个 token,草稿可能已经开始偏离目标模型真正会走的分布。
目标模型一旦在前面某个位置拒绝,后面的 token 基本都白算。
所以 speculative decoding 一直有一个矛盾:
草稿太短,加速有限。
草稿太长,拒绝率升高,验证浪费变大。
已有 draft model 大致可以分成两类。
第一类是 autoregressive draft model,例如 Eagle3 这类思路。它按顺序生成草稿 token,后面的 token 能看到前面已经生成的草稿,块内依赖更强,质量更稳。但代价是 draft 阶段也变成一步步生成,草稿越长,draft latency 越高。
第二类是 parallel draft model,例如 DFlash 这类思路。它一次性并行生成多个 token,draft latency 更低,也更适合长 draft block。但因为 block 内 token 之间缺少足够依赖,后面位置容易出现 acceptance decay。
DSpark 的设计是折中,但不是简单折中。
它的核心叫 semi-autoregressive generation:
用并行 backbone 保留高吞吐草稿生成能力;
再加一个轻量 sequential module,引入块内 token 依赖;
从而缓解 suffix decay。
也就是说,DSpark 不是完全并行,也不是完全串行。
它承认真实工程里的核心约束:理论上能不能一次猜 16 个 token 不够重要,真正重要的是能不能在极低额外延迟下,让目标模型实际接受更多 token。

3. accepted length:看 DSpark 不要只看"快了多少"
评价 speculative decoding,不能只看"吞吐提升多少"。
更关键的指标是 accepted length。
accepted length 可以理解成:
每一轮 draft 里,平均有多少个 token 被目标模型接受。
这个数字越高,说明 draft model 的草稿越贴近目标模型,大模型每次验证能批量通过的 token 越多。
DSpark 论文里,在 Qwen3-4B、Qwen3-8B、Qwen3-14B 这些 target model 上,DSpark 相比 Eagle3 的 macro-average accepted length 分别提升约 30.9%、26.7%、30.0%;相比 DFlash 分别提升约 16.3%、18.4%、18.3%。
这说明 DSpark 的优势不是一个单点 trick,而是在不同模型规模和任务类型上都提升了"草稿被接受的长度"。
更有意思的是,不同任务的 accepted length 差异很大。
论文里提到,在 Qwen3-4B 上,DSpark 在数学任务上的 accepted length 大约是 5.57,代码任务大约是 5.12,聊天任务大约是 3.49。
这个结果很符合直觉。
数学和代码更结构化,后续 token 的路径更集中。聊天更开放,同一句话可以有很多种合理表达,draft model 更难猜中目标模型下一步到底怎么说。
这说明一个现实问题:
固定 draft 长度并不合理。
有的任务可以多猜几个 token,有的任务应该保守一点。有的时刻 GPU 还有余量,可以多验证;有的时刻系统已经高并发,就应该减少无效验证。
这就引出了 DSpark 更工程化的一部分:confidence-scheduled verification。
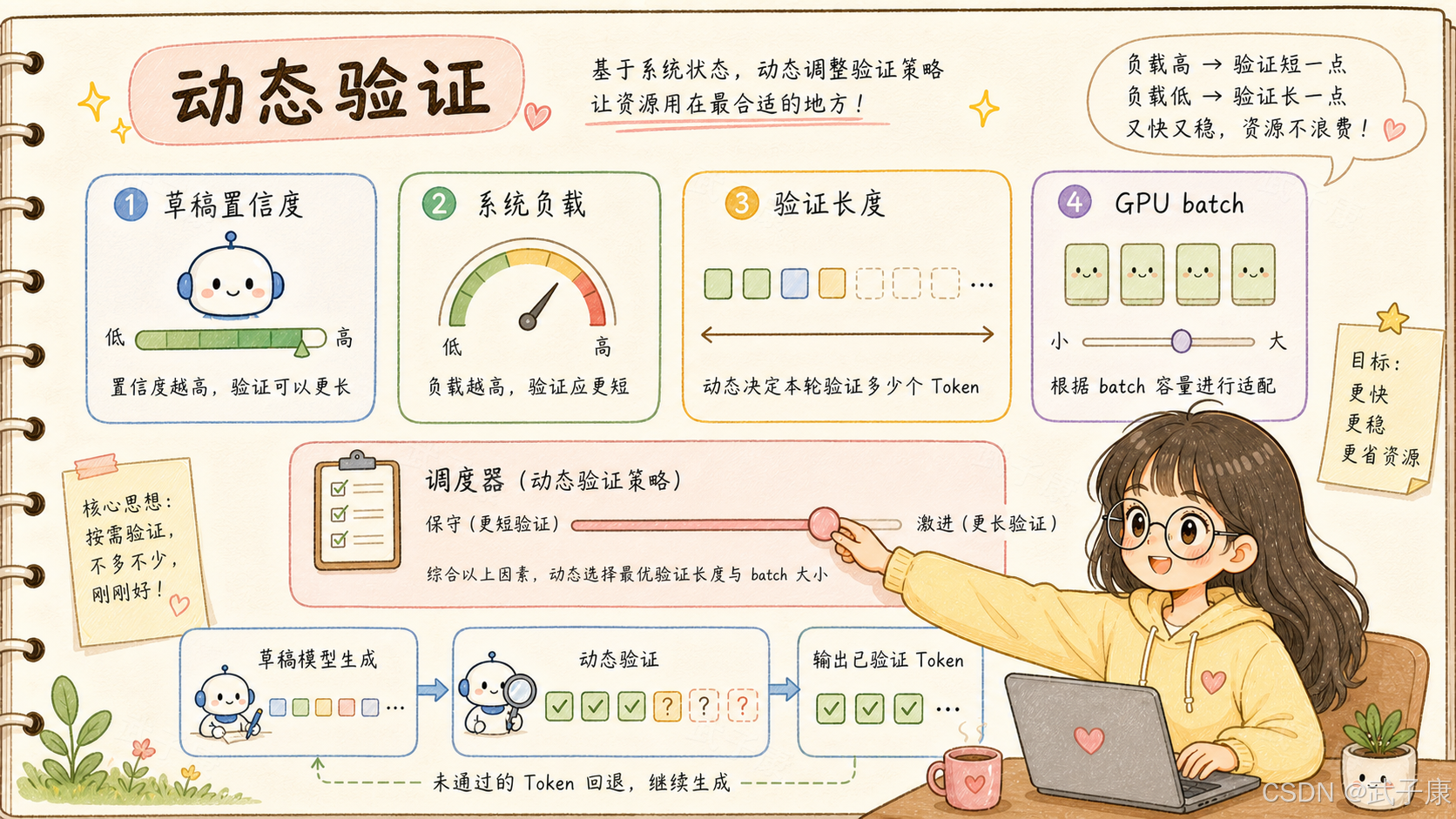
4. DSpark 真正工程化的地方:confidence-scheduled verification
很多 speculative decoding 方法在离线 benchmark 上很好看,但一到线上 serving 就会遇到一个问题:
单请求更快,不等于整个系统更稳。
线上不是一个请求独占 GPU。
真实推理服务里有大量用户同时请求,有动态 batch,有排队,有 KV cache,有吞吐目标,有 p95/p99,有 SLA。
如果 draft model 一口气生成很多 token,而系统又把这些 token 全部送去目标模型验证,可能会占用宝贵的 batch capacity。尤其在高并发下,验证一批很可能被拒绝的尾部 token,可能反而拖累整个系统吞吐。
DSpark 的 confidence-scheduled verification 解决的就是这个问题。
它不是每次都固定验证一样多的 token,而是根据两类信息动态决定验证长度:
草稿侧:后续 token 被接受的概率高不高?
系统侧:当前 engine 在这个负载下,验证更多 token 是否划算?
如果 draft model 对后面几个 token 很有信心,系统负载也允许,那就多验证几个。
如果置信度低,或者 target model 已经接近饱和,那就少验证,避免把 batch capacity 浪费在高拒绝风险 token 上。
这点非常工程化。
因为加速不是无脑多猜,而是在这些变量之间做动态调度:
接受率
验证成本
GPU 负载
batch capacity
用户侧 tokens/s
整体吞吐
尾延迟
这也是 DSpark 和很多"只做离线方法"的推理优化不同的地方。它不是只追求某个 benchmark 上的平均 accepted length,而是把 draft 策略放回真实 serving engine 里看。
5. "51% 到 400%"该怎么理解?
网上传播里常见的说法是:DSpark 带来 51% 到 400% 以上的吞吐提升。
这个方向没错,但需要谨慎解释。
根据 DSpark 论文,在 DeepSeek-V4-Flash preview 的生产 serving 里,DSpark 在 80 tok/s/user SLA 下,相比 MTP-1 baseline 的 aggregate throughput 提升 51%。在更严格的 120 tok/s/user SLA 下,MTP-1 已经接近运行边界,只能维持很小并发 batch,因此 DSpark 出现了名义上 661% 的 aggregate throughput 提升。
在 DeepSeek-V4-Pro preview 上,论文给出的对应数字是:35 tok/s/user SLA 下 aggregate throughput 提升 52%;50 tok/s/user SLA 下名义提升 406%。
这里不能简单解读成"每个请求都快 4 倍"。
论文自己的解释更稳:高 SLA 点主要说明 DSpark 扩展了 serving 系统的可行交互边界,而不是一个可以随便迁移到任何 workload 的通用倍数。
对用户体感来说,更接近的指标是 per-user generation speed。
论文给出的结果是:在 matched practical throughput levels 下,DeepSeek-V4-Flash 的 per-user generation speed 提升 60% 到 85%;DeepSeek-V4-Pro 在 matched system capacities 下提升 57% 到 78%。
也就是说,这些数字至少要分成两类看:
吞吐提升:同样 SLA 下,系统能服务更多 token / request。
用户速度提升:同样系统容量下,单用户看到输出更快。
如果你只是一个用户聊天,关心的是输出是否更快、更连贯。
如果你是 API 服务商或私有化部署团队,关心的是同样 GPU 能不能服务更多并发、单位 token 成本能不能下降、SLA 是否更容易守住。
DSpark 对后者尤其关键。
大模型训练一次很贵,但推理是每天、每小时、每秒都在烧钱。只要能在不牺牲质量的前提下降低推理成本,它的商业价值就非常直接。
6. DeepSpec 为什么比 DSpark 更值得关注?
DSpark 是方法。
DeepSpec 是工具链。
DeepSpec 是 DeepSeek 开源的 full-stack codebase,用来训练和评估 speculative decoding 的 draft model。官方 README 里列出的范围包括:
数据准备工具
draft model 实现
训练代码
评估脚本
DSpark / DFlash / Eagle3 三类算法
Qwen3 / Gemma 等 target model checkpoint
它的标准流程大致是三步。
第一步,Data Preparation:下载 prompt,用 target model 重新生成答案,并构建 target cache。
第二步,Training:让 draft model 学习 target model 的输出分布。
第三步,Evaluation:在 GSM8K、MATH500、AIME25、HumanEval、MBPP、LiveCodeBench、MT-Bench、Alpaca、Arena-Hard-v2 等任务上评估 speculative decoding acceptance。
这里最值得注意的是 target cache。
DeepSpec README 里明确提醒:默认 Qwen/Qwen3-4B 设置下,target cache 可能非常大,大约 38TB。
这说明 speculative decoding 的工程门槛并不低。
它不是"随便找个 1B 小模型放到前面猜一下"这么简单。
真正好用的 draft model 要围绕目标模型、目标任务、目标服务形态做训练和评估。draft model 不是通用小模型外挂,而是目标模型的推理伙伴。
对小团队来说,短期可能不会直接复现 DeepSeek-V4 生产系统里的效果,因为训练成本、缓存成本、推理引擎集成成本都不低。
但 DeepSpec 给出了一个很清楚的方向:
以后做私有化模型服务,不只是选 base model,
还可能要为这个 base model 配一个专门的 speculator。
这会成为推理优化栈的一部分。
7. 对普通开发者有什么意义?
如果你只是调用 API,短期最直接的感知可能是:
输出更快
高峰期更稳
长文本生成更顺
Agent 多轮调用更少卡顿
单位 token 成本有下降空间
如果你是做本地部署或私有化推理,意义更大。
过去很多团队优化推理,主要盯着这些东西:
量化:FP8、FP4、INT4
并发:batch size、max num seqs
缓存:KV cache、prefix cache
框架:vLLM、SGLang、TensorRT-LLM
硬件:H100、A100、A6000、4090
路由:小模型路由、大模型兜底
DSpark / DeepSpec 提醒我们,未来还要加一层:
draft model / speculative decoding training
也就是说,模型服务不再只是"把模型跑起来",而要回答一组系统问题:
目标模型是什么?
任务类型是什么?
平均输出长度是多少?
用户并发是多少?
是聊天、代码、数学,还是结构化 JSON?
draft 长度怎么设?
confidence threshold 怎么设?
什么负载下多验证,什么负载下少验证?
是否值得为目标模型训练专用 draft model?
推理引擎是否支持对应调度?
这已经是系统工程问题,不是简单参数调优。
8. 对实时语音 AI 为什么特别重要?
我做 AI 语音机器人时,对这类推理优化会格外敏感。
实时语音对话的链路通常是:
VAD → ASR → LLM / Agent → TTS → 播放
这里 LLM 的生成速度非常关键。
如果 LLM 吐字慢,TTS 就无法尽早开始合成。
如果 TTS 等不到足够文本,用户会感到停顿。
如果为了流式体验把文本切得太碎,又容易影响语义完整性和语音自然度。
所以 LLM 推理优化不是锦上添花,而是实时语音体验的核心。
speculative decoding 对这种场景很适合,因为实时语音通常有几个特点:
低延迟敏感
交互式请求多
用户体感强
首句速度很重要
多轮上下文持续存在
生成内容要尽快喂给 TTS
如果 DSpark 这类方法能稳定提高 per-user generation speed,它带来的不是"benchmark 好看",而是用户真实感知:
停顿更短
首句更快
回复更连贯
并发成本更低
设备端体验更像真人对话
真正的 AI 产品不是只看模型聪明,而是要让模型在真实系统里跑得起、跑得快、跑得稳。
9. 不要神化 DSpark
DSpark 很重要,但不能神化。
第一,它不是新模型。它不会让 DeepSeek-V4 的知识、推理、代码能力凭空变强。它主要提升的是推理效率和 serving 系统的交互边界。
第二,speculative decoding 不是所有场景都有效。它通常更适合交互式、低延迟、可预测性较强的生成任务。高并发离线批处理、极高 batch 场景下,收益可能下降。
第三,吞吐提升数字要看上下文。51%、52%、406%、661%、60% 到 85%、57% 到 78% 都来自特定 SLA、特定模型、特定 serving engine 和真实流量分布,不能直接搬到你的模型、硬件和业务上。
第四,DeepSpec 虽然开源,但训练高质量 draft model 仍然需要不小成本。target cache、训练数据、GPU、评估流程、推理引擎集成都会成为门槛。
第五,推理引擎支持很关键。即使有 draft model,vLLM、SGLang、TensorRT-LLM 或自研 serving stack 是否支持对应的验证调度、CUDA graph、batch 管理、KV cache 机制,都会影响最终收益。
所以更准确的判断是:
DSpark 不是魔法。
它是一次扎实的推理系统工程升级。
10. 为什么说这是"real open AI"?
“open AI"不能只理解成"开源一个模型权重”。
真正有价值的开放至少有三层:
第一层:开放模型。
第二层:开放训练或推理方法。
第三层:开放能复现、能改造、能迁移的工程框架。
DeepSeek 这次比较强的地方在第三层。
它不仅发布 DSpark 相关 checkpoint,也开源了 DeepSpec 这个训练和评估框架。DeepSpec 不是一篇概念论文,而是包含数据准备、训练、评估、多个算法实现和 checkpoint 指向的完整代码库。
这对社区更有价值。
因为大家不只是知道"DeepSeek 做了一个很快的方法",而是能看到:
draft model 怎么训
target cache 怎么准备
accepted length 怎么评估
DSpark、DFlash、Eagle3 怎么比较
Qwen3、Gemma 这类模型怎么迁移
这会推动 speculative decoding 从少数大厂内部优化,逐步变成开源推理栈里的标准组件。
11. 最终判断
DSpark 的本质不是"DeepSeek 又发了一个新模型"。
它代表的是一个更重要的趋势:
大模型竞争正在从单纯模型能力,
进入推理效率、服务成本、实时体验、工程开放度的竞争。
训练强模型很重要。
但让强模型便宜、快速、稳定地服务真实用户,同样重要。
DeepSeek 这次做对了三件事。
第一,把 speculative decoding 做到了更实用的工程形态。
第二,把 DSpark 放进 DeepSeek-V4-Flash / DeepSeek-V4-Pro preview 的生产 serving 语境里评估,而不是只停留在离线 accepted length。
第三,把 DeepSpec 作为训练和评估框架开源,让社区能继续复现、比较、迁移。
这才是这次发布真正值得关注的地方。
不是因为一句"DeepSeek is the GOAT"。
而是因为它说明了一件事:
未来的大模型战争,不只是谁的模型更强,
而是谁能把强模型以更低成本、更低延迟、更开放的方式交到真实用户手里。
参考来源
- DeepSeek-AI DeepSpec GitHub:https://github.com/deepseek-ai/DeepSpec
- DSpark paper:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 单独推理 demo 提速明显,但接入线上服务后吞吐无提升甚至下降 | 固定 draft 长度没考虑系统负载,尾部高拒绝率草稿占据 batch capacity | 对比 SLA 下 batch size、KV cache 利用率、p95/p99 延迟曲线 | 启用 confidence-scheduled verification,按草稿置信度与系统负载动态缩短或延长验证长度 |
| draft model 越猜越长,越往后被拒绝率越高,整体无效验证增加 | 典型 suffix decay,并行 draft block 内 token 依赖不足 | 看 accepted length 随 draft 位置下降的曲线,对照 Eagle3 / DFlash baseline | 改用 DSpark 这类 semi-autoregressive draft 或在并行 backbone 上加轻量 sequential module |
| 高 SLA(如 120 tok/s/user)下系统无法承载并发 | MTP-1 baseline 在高 SLA 下并发 batch 已被压缩到下限 | 看 aggregate throughput vs per-user tokens/s 曲线,记录 peak 并发 | 切换到 DSpark 这类会扩展可交互边界的方法;用 DeepSpec 训练与 target 匹配的 draft model |
| 直接复用别人开源的 1B draft model,效果远不如论文 | draft model 与目标模型、任务类型和 serving 形态不匹配 | 评估 GSM8K/MATH500/HumanEval/MT-Bench 等任务上 accepted length 分布 | 用 DeepSpec 围绕自己的 base model 重新训练 draft model,并复现 target cache |
| target cache 准备成本高到无法承担(磁盘/IO) | speculative decoding 需要把 target model 在 prompt 上的 KV/分布提前物化 | 检查 Data Preparation 阶段磁盘占用与 ETA | 控制训练数据规模;用压缩存储或分层 cache;先小规模验证再放大 |
| 想接入 vLLM / SGLang 但找不到对应调度器 | speculative decoding 的 confidence-scheduled verification 需要引擎层支持 | 看推理引擎文档与 changelog,确认是否支持自定义 verification length / CUDA graph | 暂时回退到 eager 验证;或选用已经合入该类支持的引擎版本;自研 serving stack 需要补 verification 调度 |
| 对公开的「400% / 661% 吞吐提升」照搬到自有 workload | 数字来自特定 SLA + 模型 + serving engine + 流量分布 | 看论文里的 baseline、模型、SLA、batch 上限 | 自己在 matched practical throughput 下重测 per-user tokens/s;同时测 latency 分布与成本 |
| 把「推理加速框架」当成「模型升级」使用,期待回答质量提升 | DSpark 是推理效率优化,不引入新的知识/能力 | 比对启用前后的任务正确率与一致性指标 | 区分 base model 升级与推理加速两件事;前者要看 DeepSeek-V4 自身的评测 |
| 单卡部署 GPU 显存吃紧,draft 模型与 target 模型共驻内存代价大 | speculative decoding 需要同时持有两个模型 | 监控峰值显存与 expert offload 命中率 | 评估是否走 quant(FP8/FP4)或 MoE-only resident + draft 旁路;先在小流量上验证 |
| 实时语音链路中 TTS 仍出现明显停顿 | LLM 首句生成速度不够,TTS 等待窗口不足 | 测量 LLM first-token latency 与 TTS 触发时机 | 用 DSpark/类似方案提升 per-user generation speed;调整 TTS 触发阈值;控制 prompt 长度 |
作者:武子康的个人博客
更多推荐
 33
33 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)