
仿小红书源码架构解析,瀑布流、Redis缓存、搜索与WebSocket消息设计
仿小红书产品的技术核心,不只是图文发布、短视频发布、多图上传、点赞评论、收藏关注这些表层功能,更重要的是内容流如何稳定分发、图片视频如何存储、搜索结果如何快速返回、即时消息如何触达、多端数据如何保持一致。
在 Spring Boot 架构下,仿小红书源码通常会涉及 Redis、EasyES、WebSocket、Quartz、Shiro、Druid、对象存储、内容审核、短信服务等技术。不同技术并不是孤立存在,而是围绕内容社区的核心链路协同工作。
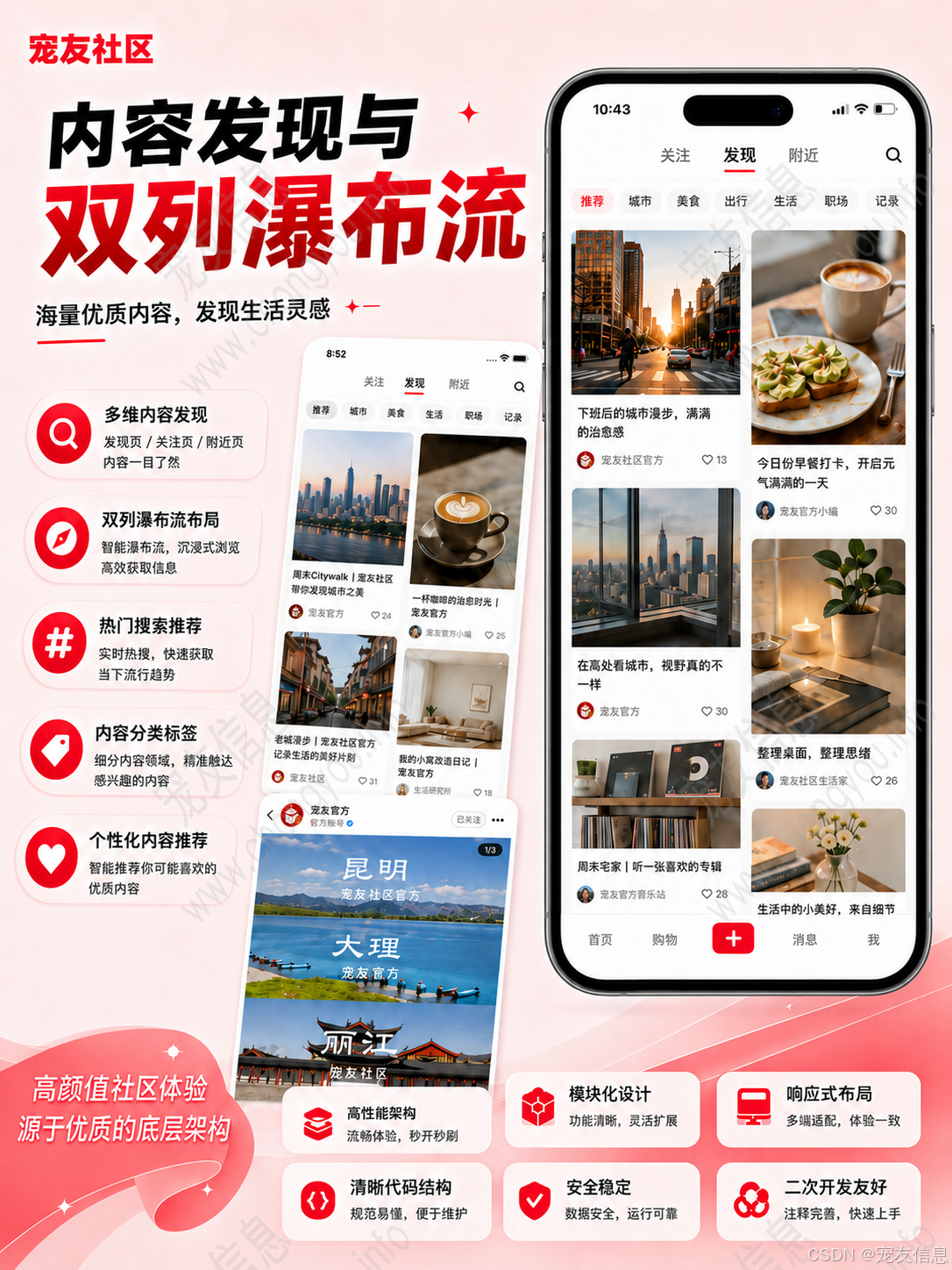
一、从内容流角度理解系统架构
仿小红书类应用的核心入口通常包括发现页、关注页、附近页、内容详情页和个人主页。发现页强调内容推荐和瀑布流展示,关注页依赖用户关系链,附近页需要结合定位数据,详情页承载评论、点赞、收藏、关注等互动行为,个人主页则聚合作品、收藏、浏览记录、关注列表和粉丝列表。
从后端设计来看,这些页面并不是简单查询某一张表,而是内容、用户、互动、搜索、消息等多类数据的组合结果。
例如发现页中的一条内容卡片,至少可能包含内容标题、封面图、作者信息、点赞数、收藏状态、评论数、发布时间、内容类型等字段。如果是短视频,还需要返回视频封面、视频地址、播放时长等数据。如果是附近页,还可能涉及经纬度和距离排序。
因此,仿小红书源码在设计时,不能只按照页面拆接口,更适合按照业务域拆分,例如内容域、用户域、互动域、搜索域、消息域、商品订单域和系统权限域。这样可以降低功能之间的耦合,也方便后续维护。
二、内容发布链路:草稿、上传、审核、入库、索引
图文发布、短视频发布、多图上传、话题标签和草稿保存,属于内容发布链路中的核心环节。
一个较完整的发布流程可以理解为:
内容编辑
↓
草稿保存
↓
图片或视频上传
↓
内容审核
↓
内容数据入库
↓
话题关系绑定
↓
搜索索引同步
↓
进入内容流展示图片和视频文件不适合直接写入数据库。常见做法是将图片、视频、封面等资源上传到腾讯云对象存储,数据库只保存资源地址、文件类型、宽高、大小、时长、排序等元数据。
内容主表主要保存标题、正文摘要、作者 ID、分类 ID、发布状态、审核状态、发布时间、点赞数、评论数、收藏数、浏览数等字段。图片、视频、话题、内容与话题关系可以拆成独立表,避免所有字段堆在内容主表中。
草稿保存和正式发布也需要分开。草稿不一定进入审核流程,也不需要写入搜索索引。正式发布后,才需要触发内容审核、搜索索引同步和内容流分发。
@Transactional
public Long publishPost(PostPublishDTO dto, Long userId) {
Post post = new Post();
post.setUserId(userId);
post.setTitle(dto.getTitle());
post.setContent(dto.getContent());
post.setCategoryId(dto.getCategoryId());
post.setAuditStatus(AuditStatus.WAITING);
post.setCreateTime(LocalDateTime.now());
postMapper.insert(post);
savePostMedia(post.getId(), dto.getMediaList());
savePostTopics(post.getId(), dto.getTopicIds());
return post.getId();
}这段代码只展示内容发布的主流程。实际项目中还需要处理参数校验、文件归属校验、话题合法性校验、审核状态回写、异常回滚等问题。
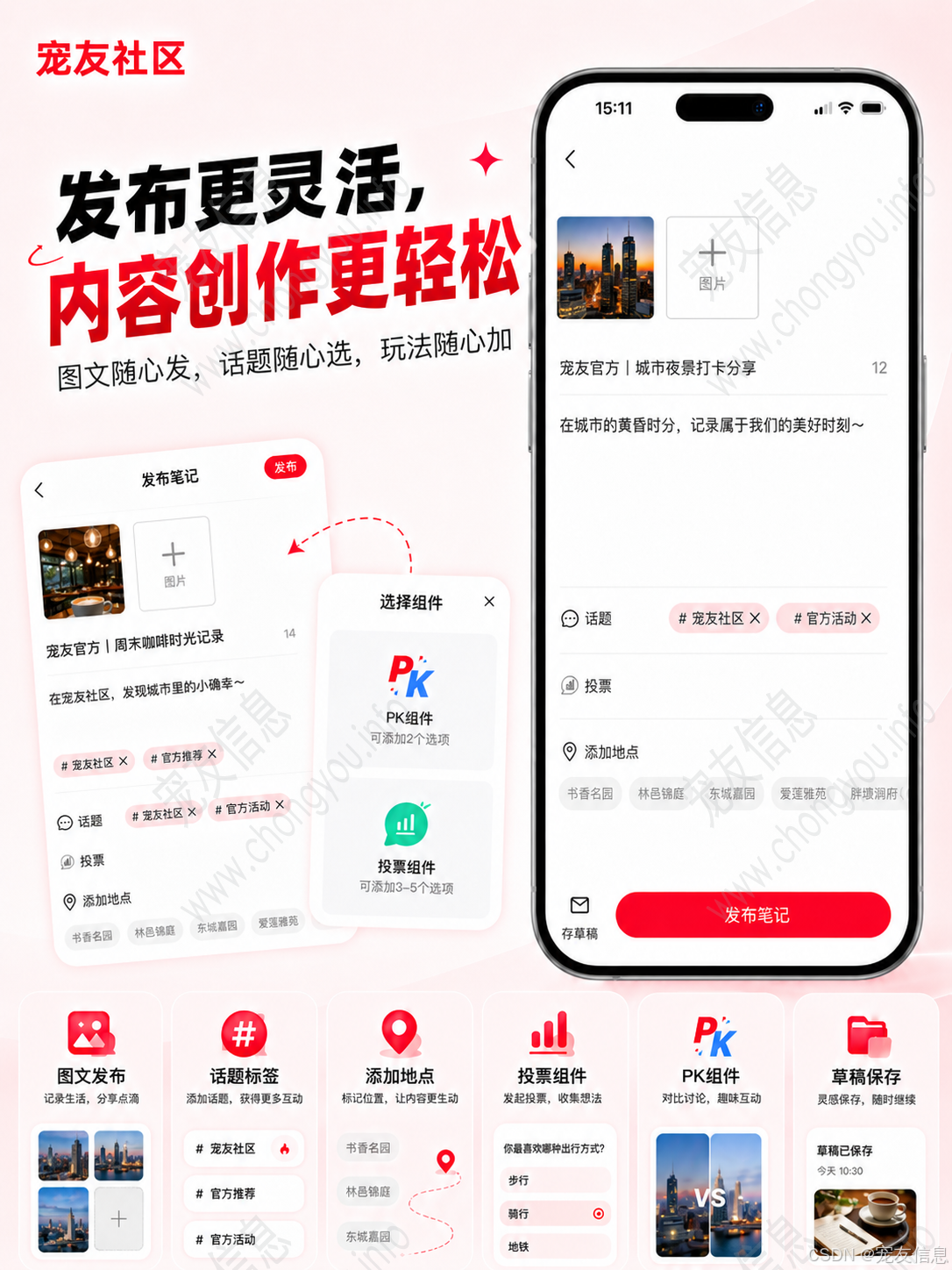
三、双列瀑布流:重点在分页稳定性
仿小红书页面常见双列瀑布流布局。前端负责根据图片比例展示卡片,后端负责提供稳定的数据顺序。
如果使用普通的 pageNum + pageSize 分页,在内容持续新增的情况下,用户下拉加载时可能会遇到重复数据或漏数据。内容流更适合使用游标分页。
游标分页可以基于发布时间、内容 ID、推荐分数等字段。例如发现页可以使用 score + id,关注页可以使用 create_time + id,附近页可以结合距离、发布时间和内容 ID 做排序。
public List<PostVO> queryWaterfallFeed(Long lastId,
LocalDateTime lastTime,
Integer size) {
LambdaQueryWrapper<Post> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Post::getStatus, PostStatus.NORMAL);
if (lastId != null && lastTime != null) {
wrapper.and(w -> w.lt(Post::getCreateTime, lastTime)
.or()
.eq(Post::getCreateTime, lastTime)
.lt(Post::getId, lastId));
}
wrapper.orderByDesc(Post::getCreateTime)
.orderByDesc(Post::getId)
.last("limit " + size);
return postMapper.selectList(wrapper)
.stream()
.map(this::convertToPostVO)
.toList();
}瀑布流接口还需要返回图片宽高。前端拿到宽高后,可以提前计算卡片高度,减少图片加载完成后的页面抖动。短视频内容则需要返回封面图、视频时长、播放地址和内容类型,方便前端在同一条内容流中区分图文与视频。
四、Redis缓存:热点内容、热门搜索和互动计数
仿小红书产品中,Redis 的使用频率很高。首页推荐、热门搜索、热点内容、短信验证码、用户 Token、未读消息数、点赞数、收藏数、浏览数等,都可以结合 Redis 处理。
热门搜索适合使用 Redis ZSet。用户每搜索一次关键词,就增加对应分值。搜索页展示时,取分值靠前的关键词即可。
public void recordSearchKeyword(String keyword) {
if (!StringUtils.hasText(keyword)) {
return;
}
redisTemplate.opsForZSet()
.incrementScore("hot:search:keywords", keyword, 1);
}
public Set<String> listHotKeywords() {
return redisTemplate.opsForZSet()
.reverseRange("hot:search:keywords", 0, 9);
}点赞、收藏、浏览这类数据属于高频变化数据。如果每次操作都直接更新数据库,容易增加数据库写入压力。可以先将计数写入 Redis,再通过 Quartz 定时任务批量同步到数据库。
但缓存设计不能只考虑性能,还要考虑一致性。例如内容被删除、审核未通过、设置隐藏后,对应的首页缓存、搜索索引、热门榜单都需要同步处理,否则可能出现内容状态不一致的问题。
五、EasyES搜索:内容、话题、商品的检索设计
内容搜索、热门搜索、商品搜索、话题搜索和用户搜索,都是仿小红书系统中的高频入口。数据库 LIKE 查询适合小规模数据,但面对标题、正文、话题、分类、昵称等多字段检索时,扩展性会比较有限。
EasyES 可以简化 Elasticsearch 的接入。内容审核通过后,将内容标题、正文摘要、话题名称、分类名称、作者昵称、封面图、发布时间、内容状态等字段写入索引。
搜索时,先从 EasyES 中查询内容 ID,再回到业务数据库补充用户互动状态,例如当前用户是否点赞、是否收藏、是否关注作者。这样可以避免搜索索引承担过多业务判断。
搜索索引需要跟随内容状态变化。内容删除、隐藏、审核失败时,索引也要同步更新。否则用户搜索时可能看到已经不可访问的内容。
六、互动系统:点赞、评论、回复、收藏、关注
点赞、评论、回复、收藏、关注和粉丝管理,是仿小红书源码中非常重要的一部分。
点赞表一般包含 user_id、target_id、target_type、create_time。target_type 可以区分内容点赞、评论点赞等场景。收藏表记录用户与内容之间的收藏关系。关注表记录关注者和被关注者之间的关系。
评论系统通常需要支持一级评论和二级回复。可以在评论表中设计 parent_id 和 root_id。parent_id 表示当前评论回复的是哪一条评论,root_id 表示它属于哪一条一级评论。这样在内容详情页展示评论时,可以先加载一级评论,再按需加载二级回复。
互动模块要特别注意重复操作问题。点赞表、收藏表、关注表都需要建立联合唯一索引,例如 user_id + target_id + target_type。这样即使前端重复点击,数据库层也能避免重复写入。
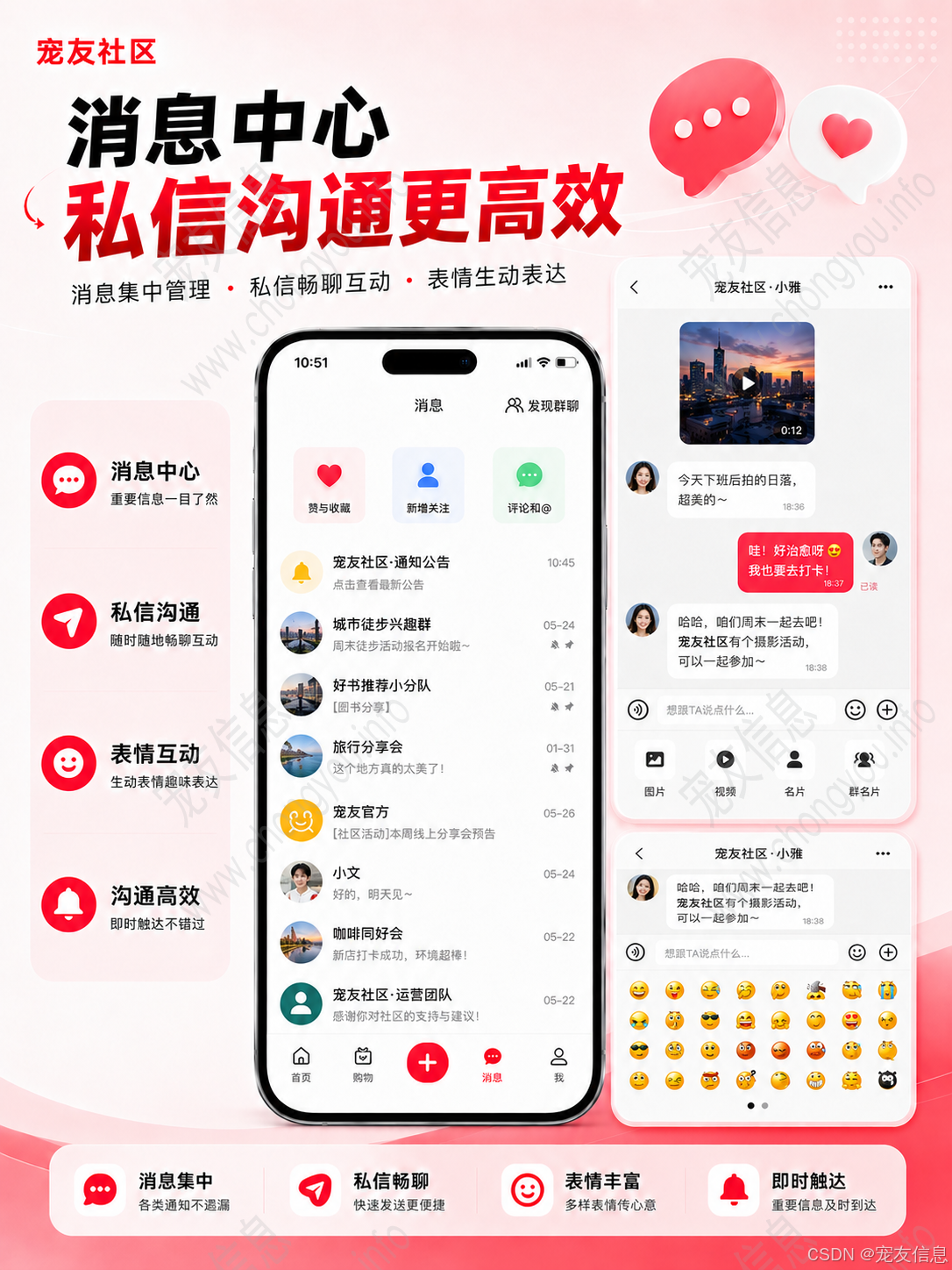
七、WebSocket即时通讯:单聊与通知触达
单聊、消息已读未读、图片发送、表情发送、系统通知、评论通知、点赞提醒和关注提醒,都属于消息体系。
WebSocket 适合处理在线消息推送。用户登录后建立连接,服务端维护 userId 与连接 Session 的映射。发送消息时,后端应先保存消息记录,再判断接收方是否在线。如果接收方在线,则实时推送;如果不在线,则保留未读状态,用户下次进入消息页时再拉取。
消息设计中需要区分私信消息和业务通知。私信消息更强调会话关系、发送者、接收者和已读状态;业务通知更关注触发来源,例如评论、点赞、关注、系统通知等。
未读数可以放在 Redis 中,例如 unread:user:{userId}。当用户进入会话详情或通知列表时,再清空对应未读数并更新数据库状态。
八、商品、购物车与订单数据设计
商品分类、商品列表、商品详情、商品搜索、购物车、立即购买、订单管理和在线支付,属于交易相关数据。虽然这些功能可能出现在同一个内容社区中,但数据库结构上应尽量与内容模块保持边界。
商品表保存商品名称、封面图、价格、库存、分类 ID、状态等信息。购物车表记录用户 ID、商品 ID、数量和选中状态。订单表记录订单号、用户 ID、订单金额、支付状态、订单状态和创建时间。订单明细表保存商品快照,避免商品后续修改影响历史订单。
支付状态应以后端支付回调为准。前端页面跳转到支付成功,并不能作为订单状态更新的最终依据。后端收到支付回调后,需要校验订单号、支付金额、支付状态,再更新订单数据。
Quartz 可以用于处理超时未支付订单。定时任务扫描待支付订单,如果超过指定时间仍未支付,则修改为已取消,并释放对应库存或占用状态。
九、Shiro权限控制:接口权限比页面权限更重要
账号设置、资料编辑、作品管理、内容分类、商品分类、订单管理、系统通知等功能,都涉及权限控制。Shiro 可以用于登录认证、角色权限和接口鉴权。
在前后端分离架构中,不能只依赖前端隐藏按钮来控制权限。即使页面不展示某个操作入口,接口仍然可能被直接请求。因此,后端必须进行接口级权限判断。
普通用户只能编辑自己的资料、管理自己的作品、查看自己的收藏和浏览记录。后台账号可以根据角色不同,管理内容分类、商品分类、订单数据、系统通知等内容。
权限模型可以基于用户、角色、权限进行设计。用户绑定角色,角色绑定权限,接口再根据权限标识进行校验。这样可以避免所有后台能力都集中在单一身份上。
十、Druid连接池与数据库索引优化
Druid 主要用于数据库连接池管理和 SQL 监控。仿小红书产品中,首页内容流、内容详情、评论列表、个人主页、商品列表、订单列表等接口都可能产生较多数据库访问。
数据库优化不能只依赖连接池,还需要合理设计索引。内容表可以给 user_id、category_id、status、create_time 建立索引。评论表可以给 post_id、root_id、create_time 建立索引。点赞、收藏、关注关系表需要建立联合索引。订单表需要给 user_id、order_no、status 建立索引。
如果首页内容流涉及多表聚合,不建议在高并发接口中做过多实时 join。可以将部分展示字段冗余到内容表或内容统计表中,例如作者昵称、头像、封面图、点赞数、收藏数等。冗余字段需要配合更新策略,避免长期不一致。
十一、多端数据互通:APP、小程序、H5共用后台
安卓 APP、苹果 APP、微信小程序和 H5 网页端共用同一套后台时,接口字段结构要保持稳定。不同端可以有不同页面样式,但内容、用户、评论、消息、订单等数据来源应保持一致。
例如用户在 H5 收藏了一篇内容,APP 打开同一篇内容时,收藏状态也应同步变化。用户在小程序完成订单支付后,APP 订单列表中也应展示最新状态。用户在 APP 已读私信后,H5 端未读数也要减少。
移动端响应式适配主要发生在前端,但后端需要提供足够的数据字段。瀑布流需要图片宽高,短视频需要封面和时长,商品详情需要价格和库存,个人主页需要作品数、关注数、粉丝数、获赞数。
阿里云短信可以用于验证码发送。验证码适合存入 Redis,并设置过期时间。用户登录成功后生成 Token,后续请求通过 Token 识别身份,再结合 Shiro 完成权限校验。
十二、定时任务在内容社区中的使用场景
Quartz 定时任务适合处理一些不需要同步完成的任务,例如浏览记录落库、热门搜索刷新、热门内容计算、订单超时关闭、搜索索引修复、消息状态清理等。
这些任务不能只关注是否执行,还要关注幂等性。任务重复执行时,不能导致订单重复取消、浏览数重复增加、索引重复写入异常或消息状态错乱。
下面是核心技术在仿小红书源码中的常见落点:
| 技术 | 主要作用 |
|---|---|
| Spring Boot | 后端接口、业务服务、模块组织 |
| Redis | 热点缓存、验证码、未读数、互动计数、热门搜索 |
| EasyES | 内容搜索、商品搜索、话题搜索 |
| WebSocket | 单聊消息、在线推送、通知触达 |
| Quartz | 订单关闭、缓存同步、浏览记录落库、索引修复 |
| Shiro | 登录认证、角色权限、接口鉴权 |
| Druid | 数据库连接池、SQL监控 |
| 对象存储 | 图片、视频、封面资源存储 |
| 内容审核 | 文本、图片、视频内容检测 |
十三、源码目录结构的拆分思路
仿小红书源码可以按照业务域和基础能力进行目录拆分,而不是把所有代码都堆在一个 service 中。
modules
├── content 图文、短视频、话题、分类、草稿
├── user 用户资料、关注、粉丝、账号设置
├── interact 点赞、评论、回复、收藏、浏览记录
├── search EasyES索引、搜索记录、热门搜索
├── im WebSocket、单聊、未读消息
├── goods 商品分类、商品列表、商品详情
├── order 购物车、订单、支付回调
├── file 图片视频上传、对象存储
├── audit 文本审核、图片审核、视频审核
├── task Quartz定时任务
└── system Shiro权限、角色、菜单、配置这种拆分方式可以让内容、互动、搜索、消息、订单、文件、审核、权限之间保持清晰边界。内容发布不直接处理 WebSocket 推送,搜索模块不直接修改内容状态,订单模块不依赖内容表结构,文件模块只负责资源上传和资源信息返回。
从技术角度看,仿小红书源码的稳定性主要取决于内容流、搜索流、互动流、消息流和订单流之间的协作方式。Redis 负责高频数据处理,EasyES 负责检索体验,WebSocket 负责实时消息,Quartz 负责异步任务,Shiro 负责权限边界,Druid 保障数据库连接稳定,对象存储和内容审核支撑图片视频内容链路。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)