
大数据之足球盘口赔率凯利必发数据采集爬虫
这期主要介绍足球类数据的获取即爬虫相关知识,主要是针对足球/体育类网站平台都爬虫工程师。如果您是单纯的进行数据分析,利用赔率、亚盘、凯利、必发等各指标找出与赛果的关系,可以通过网络获得即可,不要先消耗大量的时间和精力去做爬虫,因为即便你爬到了数据,预测结果分析完后也不一定有任何帮助和启示。由第2步,我们知道,需要采集的数据内容分布在不同页面。这里需要强调的是,绝大多数足球类网站经历了多年的开发,展
·
这期主要介绍足球类数据的获取即爬虫相关知识,主要是针对足球/体育类网站平台都爬虫工程师。如果您是单纯的进行数据分析,利用赔率、亚盘、凯利、必发等各指标找出与赛果的关系,可以通过网络获得即可,不要先消耗大量的时间和精力去做爬虫,因为即便你爬到了数据,预测结果分析完后也不一定有任何帮助和启示。作为足球数据类采集的思路:
1. 导入库
import re, requests, time, random, pymysql, os #主要为请求类,连接数据库类,时间模块
import pandas as pd #利用pandas处理数据
from sshtunnel import SSHTunnelForwarder #远程连接服务器
from bs4 import BeautifulSoup2. 确定采集目标
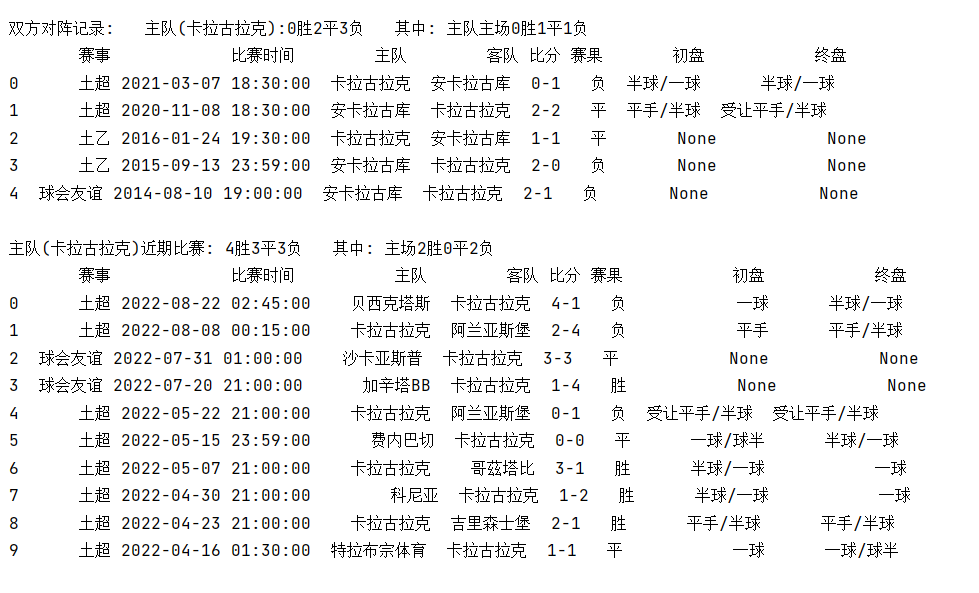
足球相关数据的收集,所有的赛事信息包括且不仅限于:
球队信息,
天气和场地信息,
所有比赛列表,
积分榜,
对战历史,
近期战绩,
未来赛事,
实时比分,
历史欧指数据,
实时欧指数据,
历史亚盘数据,
实时亚盘数据,
历史大小球数据,
实时大小球数据,,
凯利指数,
必发数据
3. 构建采集框架流程
由第2步,我们知道,需要采集的数据内容分布在不同页面。因此要找到这些网页的共同入口。利用入口进行不同赛事分类和提取,具体到某一网站的总体思路如下:
def get_year_page(urls):
res = get_requests12(urls,headers)
ret = re.findall(r'arr\[0\].*?=(.*);', res.text, re.S)[0].replace('\n', '').replace(' ', '') #将,,转为,'',是为了list能转化为json
ret_list = ret.split(';')
for i in range(len(ret_list)):
ret = ret.replace('arr[%s]=' % (i), '')
respon = ret.strip(';').split(';')
for group_id in respon:
db = pymysql.connect()
cur = db.cursor()
group_Info = group_id.split(',[')
group_con_tab = group_Info[0].replace('[', '').replace('"', '')
group_con_game = group_Info[1].replace('[', '').replace(']]', '')
group_gam_tab = group_con_game.split('","')
for group_gam in group_gam_tab:
group_gam = group_gam.replace('"', '')
group_gam_info = group_gam.split(',')
leagueid = group_gam_info[#]
league_or_cup = group_gam_info[#]
league_or_subleague = group_gam_info[#]
if int(leagueid) in league_id :
b = len(group_gam_info)
if int(league_or_cup) == ### and int(league_or_subleague) == ###:
for season in range(###, ###):
url
elif int(league_or_cup) == ### and int(league_or_subleague) == ###:
for season in range(###,, ###):
url
get_real_url(url, group_gam_info[season], leagueid, league_or_cup, league_or_subleague)
del_lishi_league(group_gam_info[season], leagueid)
elif int(league_or_cup) == ###:
for season in range(###,, ###):
url
get_real_url(url, group_gam_info[season], leagueid, league_or_cup, league_or_subleague)
del_lishi_league(group_gam_info[season], leagueid)
else:
pass4. 找出一场比赛唯一标识
这里需要强调的是,绝大多数足球类网站经历了多年的开发,展现给用户的页面看起来都是统一规范的,但是底层数据结构已经不一样了。
5. 按需求对不同数据分类采集
完整的代码有十几万行,珍惜劳动成果,请勿私信索要免费源代码。谢谢。
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)