
【实战】:零成本配置 AMD ROCm 云环境并跑通 Gemma4-E4B云端大模型
标签:#AMD #ROCm #Gemma4 #vLLM #大模型部署 #云环境 #Datawhale #AI开发 #深度学习 #GPU计算
今天在Datawhale × AMD 开发者云 的Hello-ROCm 学习,成功在 AMD 开发者云上把 Google 的 Gemma4-E4B-it 跑起来并完成简单对话。
这篇笔记我把完整流程、坑点和心得整理出来,方便回看也供同样在学的同学参考。
一、整体流程概览
整个任务可以拆成两个主要阶段:
第一阶段:云环境准备
- 登录与授权:通过魔搭账号登录 AMD 开发者云平台
- 启动环境:打开 Hello ROCm Notebook 容器
- GPU 检查:使用
amd-smi命令确认 GPU 可用 - 框架验证:验证 PyTorch 能够识别并调用 AMD ROCm
第二阶段:模型部署与测试
- 环境配置:切换国内 pip 源并安装 ModelScope
- 下载模型:拉取 Gemma4-E4B-it 模型权重
- 安装推理框架:重装适配 ROCm 的 vLLM 版本
- 启动服务:使用 vLLM 启动模型推理服务
- 对话测试:在新终端中连接服务并进行对话测试
- 清理资源:关闭服务并销毁云实例
整个流程从登录到完成测试约 20 分钟,无需购买显卡或配置复杂环境,浏览器打开即可配置。接下来我们检查 GPU 状态:
amd-smi
能看到 AMD-SMI 版本、ROCm 版本、显存占用等信息,就说明 GPU 可用。这一步相当于 NVIDIA 环境下的 nvidia-smi,是 ROCm 生态里的设备监控命令。
2. 验证 PyTorch 能否识别 AMD GPU
python -c "import torch; print('PyTorch:', torch.__version__); print('ROCm available:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')"
输出里 ROCm available: True 是正确标准。
这里有个容易踩的小坑:在 ROCm 环境下,PyTorch 仍然用 torch.cuda.is_available() 这个接口来判断 GPU 是否可用,名字里带 cuda 但实际走的是 HIP/ROCm 后端,容易被名字误导。
四、下载 Gemma4 模型
1. 切国内 pip 源
pip config set global.index-url https://mirrors.cloud.tencent.com/pypi/simple/
国内环境直接走默认源会卡顿,切到腾讯云镜像后下载速度明显提升。
2. 安装 ModelScope
pip install modelscope
ModelScope 是阿里达摩院的国内开源模型社区,服务器在国内,下大模型权重比 HuggingFace 稳定太多,所以这里用 ModelScope。
3. 拉取 Gemma4-E4B-it 权重
modelscope download --model google/gemma-4-E4B-it --cache_dir "./models"
E4B 是 Gemma 4 家族里较小的型号,4.5B 有效参数、128K 上下文、原生支持文本/图像/音频,单卡就能跑,比较适合上手学习。下载大约 8 分钟,成功提示比较隐蔽,耐心等到提示符回来即可。
4. 确认权重完整
ls -lh ./models/google/gemma-4-E4B-it/
看到约 15G 的 model.safetensors(模型权重)在列表里,说明配置到位了。
五、启动 vLLM 推理服务
1. 更新 vLLM 版本
云环境自带的 vLLM 版本跑不了 Gemma4,需要卸载重装:
uv pip uninstall torchvision torchaudio
uv pip install 'vllm==0.23.0+rocm723' torchvision torchaudio 'fastapi[standard]==0.136.0' \
--no-cache \
--index-url https://mirrors.aliyun.com/pypi/simple/ \
--extra-index-url https://wheels.vllm.ai/rocm/ \
-U
这一步要把 torchvision 和 torchaudio 一起卸载重装,否则在当前云环境里会冲突报错,建议照做减少错误。
2. 启动服务
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it
vLLM 是一个高性能推理框架,核心是 PagedAttention 机制,对 KV 缓存做了高效管理,吞吐量在开源推理框架里属于第一梯队,而且同时支持 NVIDIA 和 AMD GPU。
关键点:
- 启动后这个终端窗口会被服务"占用",日志在持续输出,不要关闭它、也不要按 Ctrl+C 退出。
- 第一次启动需要加载模型 + 编译内核,等几分钟是正常现象,只要日志还在动就别动它。
六、新终端对话测试
第一个终端在跑服务,需要再开一个新终端当要跟模型对话。
1. 开新终端连接服务
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it
2. 发一条测试消息
你是谁,你能做什么
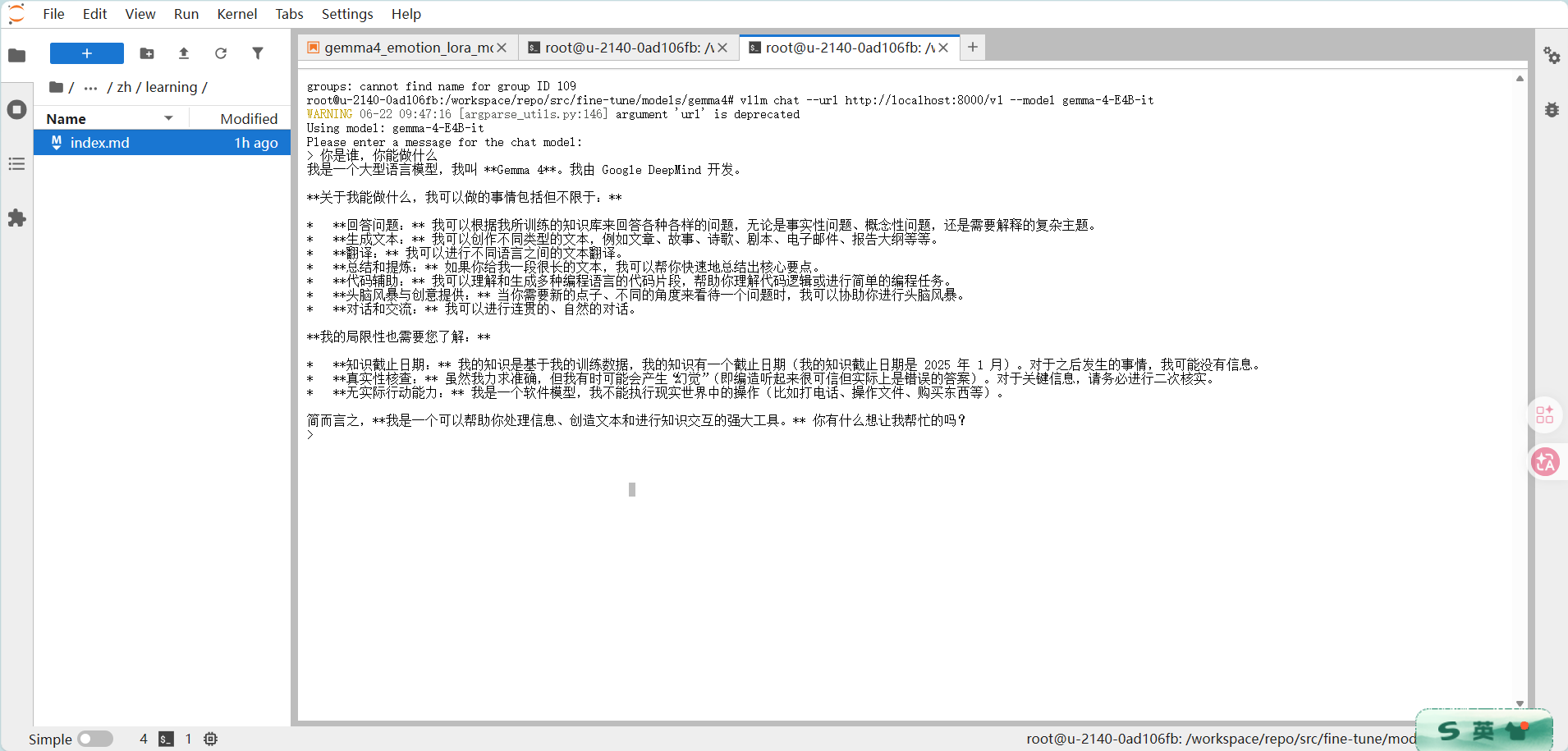
终端返回模型的回答,说明 Gemma4 已经在 AMD ROCm 云环境里正常跑起来了——整个任务的核心目标达成。
3. 关闭 vLLM 服务
后续微调任务要清理显存,需要先把推理服务关掉:
- 新终端:Mac 按 Control+C,Windows 按 Ctrl+C,退出聊天
- 第一个终端:同样按 Ctrl+C,结束 vLLM 服务
七、关键命令速查表
| 阶段 | 命令 | 作用 |
|---|---|---|
| GPU 检查 | amd-smi |
查看 AMD GPU 状态,对应 nvidia-smi |
| 框架验证 | python -c "import torch; ..." |
确认 PyTorch 能调用 ROCm |
| 换源 | pip config set global.index-url ...tencent... |
加速 pip 下载 |
| 装下载器 | pip install modelscope |
国内模型下载工具 |
| 下权重 | modelscope download --model google/gemma-4-E4B-it --cache_dir "./models" |
拉取 E4B 权重 |
| 查权重 | ls -lh ./models/google/gemma-4-E4B-it/ |
确认 15G safetensors 在位 |
| 重装 vLLM | uv pip install 'vllm==0.23.0+rocm723' ... |
适配 ROCm 7.2 的 vLLM 版本 |
| 启服务 | vllm serve ... --served-model-name gemma-4-E4B-it |
把模型装载成 HTTP 服务 |
| 对话测试 | vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it |
客户端连服务端对话 |
八、踩坑记录与排查
1. modelscope download 命令找不到
先 pip show modelscope 确认是否装成功,没装上就 pip install -U modelscope 重装一次。
2. vLLM 启动很慢
第一次启动要加载模型权重 + 编译 ROCm 内核,等几分钟是正常的,只要日志还在输出就别中断。
3. 显存不足
启动时加 --max-model-len 8192 降低最大上下文长度,还不够就继续降到 4096:
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it --max-model-len 8192
4. vllm chat 连接失败
回第一个终端确认服务是否已经出现 Application startup complete.,没启动完成就先等着,完成后再发 chat 命令。
5. 忘记关 Instance
这是最容易被忽略的一步。任务做完务必回 Profile 页点 Destroy Instance,否则 10 小时免费额度会持续消耗。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)