
ollama本地部署模型
ollama本地部署
最近,OLLAMA平台迅速走红!
随着开源浪潮的兴起,越来越多的AI模型选择开放其代码与架构,其中不仅包括国际主流项目,更值得关注的是国内如 DeepSeek、Qwen 等优秀模型的加入。用户可通过 [OLLAMA中文官网](https://ollama.org.cn/) 快速浏览、下载这些开源模型,并查阅相关文档与技术说明。
开源技术的深远意义
开源模式的普及,不仅降低了技术应用门槛,更通过知识共享与协作加速了技术迭代,成为推动社会进步的重要力量。例如,DeepSeek与Qwen等模型的开源,为开发者提供了灵活的工具支持,同时也为中国AI生态的繁荣注入了活力。
每个模型对于硬件的要求各有不同,大于7B的模型通常对CPU、内存和显卡都有一定的需求。然而,对于老旧的四核电脑来说,这些硬件要求可能会成为一道难以跨越的门槛。
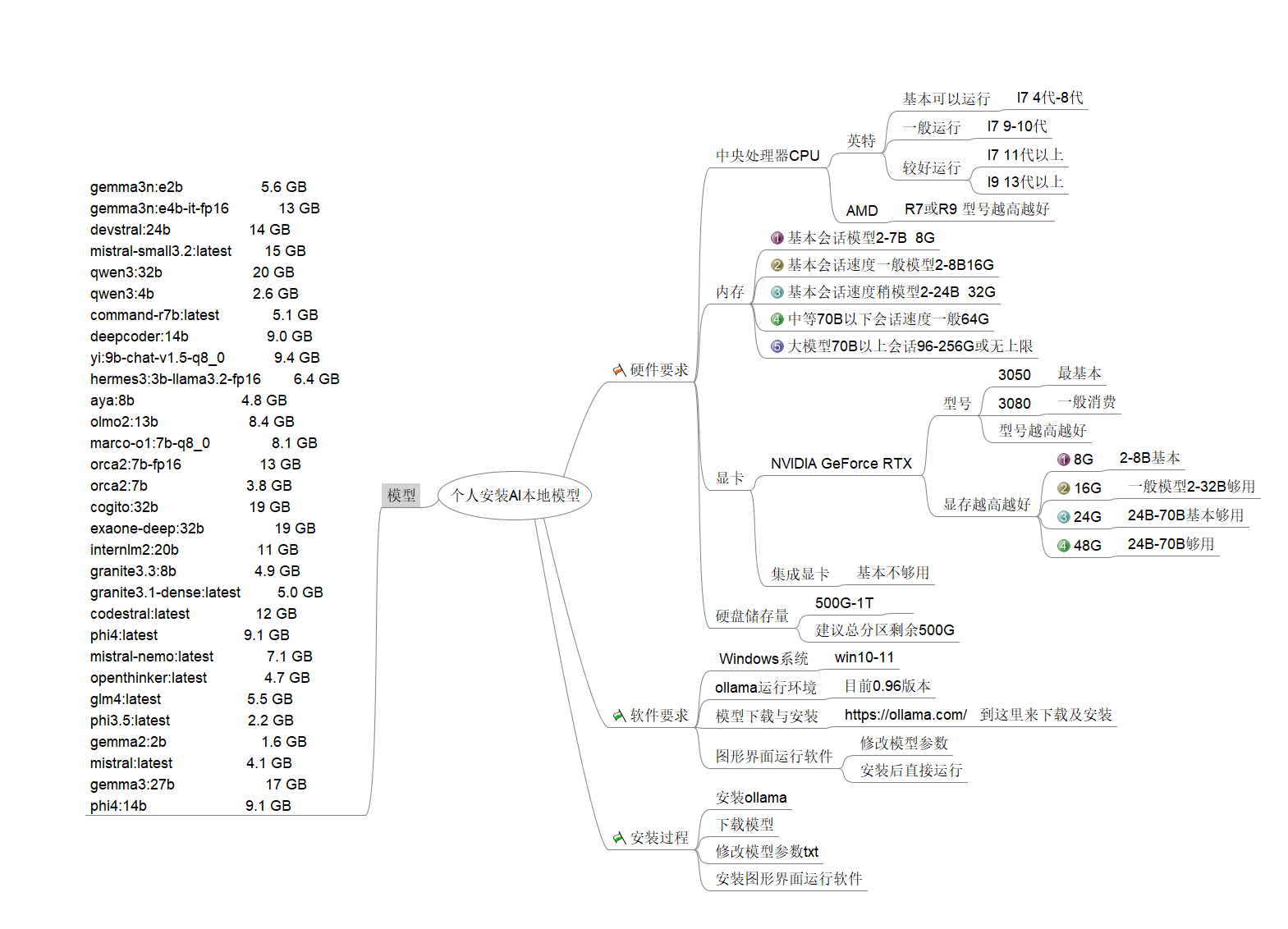
备硬件:
怀旧地环视9年前的I7四代电脑,发现它仍然可以派上用场,例如作为口语听力培训工具。由于DDR3内存非常便宜(一条8G只需35元,两条才70元),升级内存变得非常划算。因此,预计这个电脑可以流畅运行7B以下的模型,甚至1.5-3B的模型也完全不在话下。总的来说,这个电脑的配置如下:
- CPU:4代I7,双核四线程
- 内存:8G(有机会升级到16G)
- 硬盘:512G
- 显卡:自带集成显卡
这个配置对于运行小型AI模型来说已经足够,值得考虑恢复使用。
备软件:
1. Ollama - Ollama 框架 , 下载ollama, 安装ollama
2. 下载模型:
phi4:latest ac896e5b8b34 9.1 GB 3 days ago
mistral-nemo:latest 994f3b8b7801 7.1 GB 6 days ago
openthinker:latest aaffe05a5e2e 4.7 GB 7 days ago
glm4:latest 5b699761eca5 5.5 GB 7 days ago
phi3.5:latest 61819fb370a3 2.2 GB 10 days ago
gemma2:2b 8ccf136fdd52 1.6 GB 10 days ago
qwen2.5:3b 357c53fb659c 1.9 GB 10 days ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 10 days ago
mistral:latest f974a74358d6 4.1 GB 12 days ago
deepseek-r1:latest 0a8c26691023 4.7 GB 6 weeks ago
2. 安装 kokoro-onnx
4.开发可视界面:

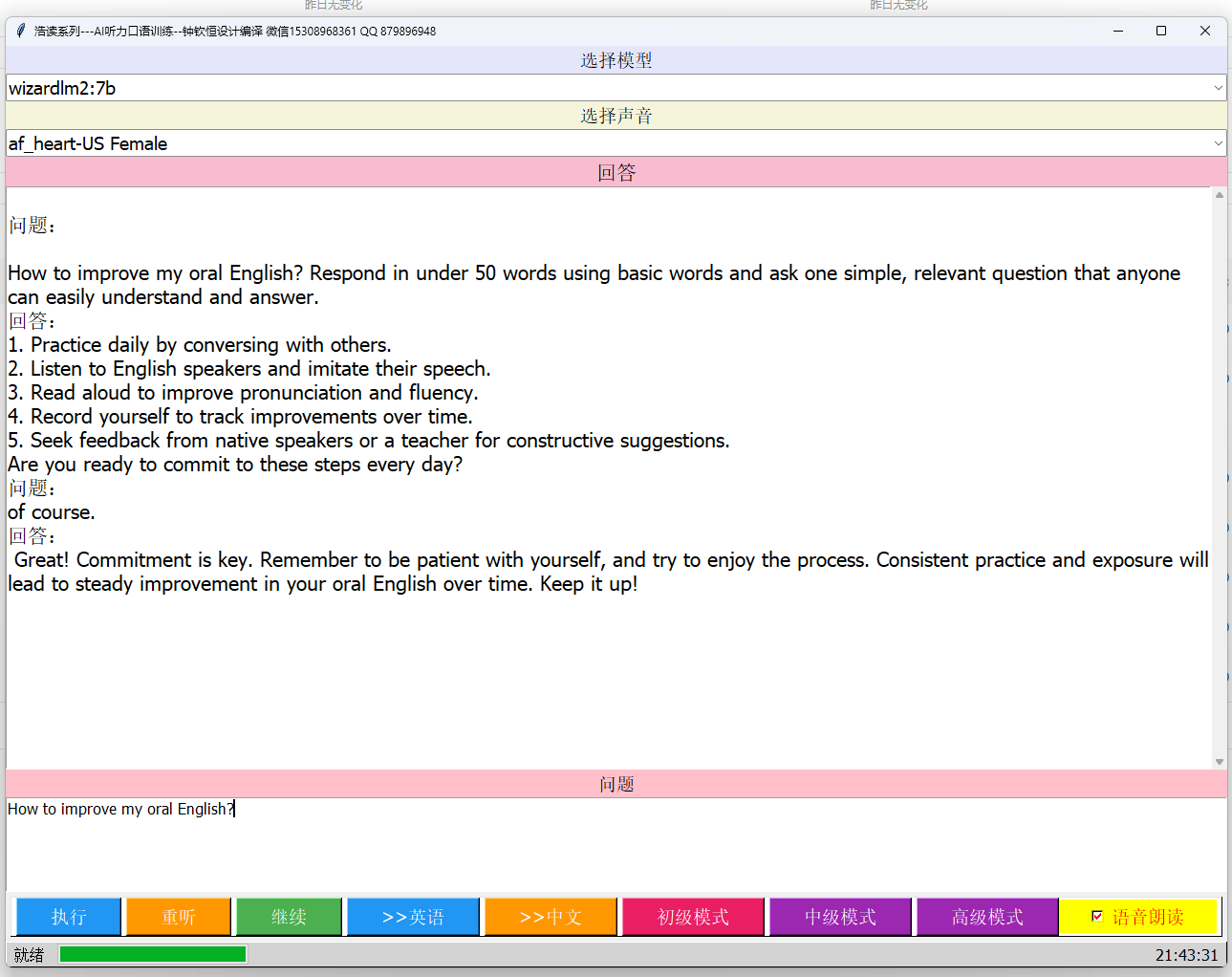
5.安装讯飞语音输入法
6. 运行模型核心代码:
def run_model(self):
self.question = self.question_entry.get("1.0", "end-1c")
self.answer_entry.insert("end", "\n问题:\n" + self.question + "\n回答:\n")
self.question_entry.delete("1.0", "end")
self.conversation_history.append({
'role': 'user',
'content': self.question
})
self.status_label.config(text="处理中...")
self.progress_bar["value"] = 0
self.progress_bar["maximum"] = 100
thread = threading.Thread(target=self._run_model)
thread.start()
def run_model2(self):
self.question = "把以上的回答翻译成英语:"
self.answer_entry.insert("end", "\n问题:\n" + self.question + "\n回答:\n")
self.question_entry.delete("1.0", "end")
self.conversation_history.append({
'role': 'user',
'content': self.question
})
self.status_label.config(text="处理中...")
self.progress_bar["value"] = 0
self.progress_bar["maximum"] = 100
thread = threading.Thread(target=self._run_model)
thread.start()
def run_model3(self):
self.question = "把以上的回答翻译成中文:"
self.answer_entry.insert("end", "\n问题:\n" + self.question + "\n回答:\n")
self.question_entry.delete("1.0", "end")
self.conversation_history.append({
'role': 'user',
'content': self.question
})
self.status_label.config(text="处理中...")
self.progress_bar["value"] = 0
self.progress_bar["maximum"] = 100
thread = threading.Thread(target=self._run_model)
thread.start()
def run_model4(self):
self.question = self.question_entry.get("1.0", "end-1c")+ " Respond in under 30 words and ask one simple, relevant question that anyone can easily understand and answer."
self.answer_entry.insert("end", "\n问题:\n" + self.question + "\n回答:\n")
self.question_entry.delete("1.0", "end")
self.conversation_history.append({
'role': 'user',
'content': self.question
})
self.status_label.config(text="处理中...")
self.progress_bar["value"] = 0
self.progress_bar["maximum"] = 100
thread = threading.Thread(target=self._run_model)
thread.start()
def run_model5(self):
self.question = self.question_entry.get("1.0", "end-1c")+ " Answer in up to 100 words and ask one relevant, thought-provoking question suitable for a general audience."
self.answer_entry.insert("end", "\n问题:\n" + self.question + "\n回答:\n")
self.question_entry.delete("1.0", "end")
self.conversation_history.append({
'role': 'user',
'content': self.question
})
self.status_label.config(text="处理中...")
self.progress_bar["value"] = 0
self.progress_bar["maximum"] = 100
thread = threading.Thread(target=self._run_model)
thread.start()
def run_model6(self):
self.question = self.question_entry.get("1.0", "end-1c")+ " Provide a standard response and pose one relevant, in-depth question."
self.answer_entry.insert("end", "\n问题:\n" + self.question + "\n回答:\n")
self.question_entry.delete("1.0", "end")
self.conversation_history.append({
'role': 'user',
'content': self.question
})
self.status_label.config(text="处理中...")
self.progress_bar["value"] = 0
self.progress_bar["maximum"] = 100
thread = threading.Thread(target=self._run_model)
thread.start()
def run_model(self):
self.question = self.question_entry.get("1.0", "end-1c")
self.answer_entry.insert("end", "\n问题:\n" + self.question + "\n回答:\n")
self.question_entry.delete("1.0", "end")
self.conversation_history.append({
'role': 'user',
'content': self.question
})
self.status_label.config(text="处理中...")
self.progress_bar["value"] = 0
self.progress_bar["maximum"] = 100
thread = threading.Thread(target=self._run_model)
thread.start()
def _run_model(self):
messages = self.conversation_history.copy()
finished = False
char_count = 0
model_name = self.options_var.get()
answer = ""
for part in chat(model_name, messages=messages, stream=True):
try:
content = part['message']['content'].replace("*", "").replace("#", "").replace("</think>","").replace("<think>","")
self.answer_entry.insert("end", content)
answer += content
self.answer_entry.see("end")
self.update_idletasks()
char_count += len(content)
progress = min(100, char_count / 50000 * 100)
self.progress_bar["value"] = progress
if char_count > 50000:
finished = True
except KeyError:
print("Error: part does not contain 'message' or 'content'")
if finished:
break
self.conversation_history.append({
'role': 'assistant',
'content': answer
})
self.answer_text = answer
text = answer
print("回答结束")
self.clear_blank_lines()
self.status_label.config(text="就绪")
self.progress_bar["value"] = 100
if self.play_audio_var.get():
self.generate_and_play_audio(text)

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)