
基于LlaMa-Factory的高效微调流程
B站同步视频 -> 点击进入> 点击进入> B站同步视频> 点击进入> 点击进入> B站同步视频> 点击进入>
1. LLaMA-Factory项目介绍
LLaMA Factory是一个在GitHub上开源的项目,该项目给自身的定位是:提供一个易于使用的大语言模型(LLM)微调框架,支持LLaMA、Baichuan、Qwen、ChatGLM等架构的大模型。更细致的看,该项目提供了从预训练、指令微调到RLHF阶段的开源微调解决方案。截止目前(2024年3月1日)支持约120+种不同的模型和内置了60+的数据集,同时封装出了非常高效和易用的开发者使用方法。而其中最让人喜欢的是其开发的LLaMA Board,这是一个零代码、可视化的一站式网页微调界面,它允许我们通过Web UI轻松设置各种微调过程中的超参数,且整个训练过程的实时进度都会在Web UI中进行同步更新。
简单理解,通过该项目我们只需下载相应的模型,并根据项目要求准备符合标准的微调数据集,即可快速开始微调过程,而这样的操作可以有效地将特定领域的知识注入到通用模型中,增强模型对特定知识领域的理解和认知能力,以达到“通用模型到垂直模型的快速转变”。
LLaMA-Factory目前支持微调的模型及对应的参数量:
|
Model |
Sizes |
|
Baichuan2 |
7B/13B |
|
BLOOM |
560M/1.1B/1.7B/3B/7.1B/176B |
|
BLOOMZ |
560M/1.1B/1.7B/3B/7.1B/176B |
|
ChatGLM3 |
6B |
|
DeepSeek (MoE) |
7B/16B/67B |
|
Falcon |
7B/40B/180B |
|
Gemma |
2B/7B |
|
InternLM2 |
7B/20B |
|
LLaMA |
7B/13B/33B/65B |
|
LLaMA-2 |
7B/13B/70B |
|
Mistral |
7B |
|
Mixtral |
8x7B |
|
Phi-1.5/2 |
1.3B/2.7B |
|
Qwen |
1.8B/7B/14B/72B |
|
Qwen1.5 |
0.5B/1.8B/4B/7B/14B/72B |
|
XVERSE |
7B/13B/65B |
|
Yi |
6B/34B |
|
Yuan |
2B/51B/102B |
可以看到,当前主流的开源大模型,包括ChatGLM3、Qwen的第一代以及最新的1.5测试版本,还有Biachuan2等,已经完全支持不同规模的参数量。针对LLaMA架构的系列模型,该项目已经基本实现了全面的适配。而其支持的训练方法,也主要围绕(增量)预训练、指令监督微调、奖励模型训练、PPO 训练和 DPO 训练展开,具体情况如下:
|
方法 |
全参数训练 |
部分参数训练 |
LoRA |
QLoRA |
|
预训练(Pre-Training) |
✅ |
✅ |
✅ |
✅ |
|
指令监督微调(Supervised Fine-Tuning) |
✅ |
✅ |
✅ |
✅ |
|
奖励模型训练(Reward Modeling) |
✅ |
✅ |
✅ |
✅ |
|
PPO 训练(PPO Training) |
✅ |
✅ |
✅ |
✅ |
|
DPO 训练(DPO Training) |
✅ |
✅ |
✅ |
✅ |
- 预训练
在大模型的早期阶段,也就是诞生的过程中,往往不会经过Supervised finetuning(监督式微调) 的过程,它在训练时仅仅是去学习大量的语言基本规律和知识理解,其训练数据是类似这种形式:
|
JSON |
上述数据截取自:Skywork:https://huggingface.co/datasets/Skywork/SkyPile-150B (注:需要开启科学上网才可以访问)
预训练数据通常来自于多样化的文本来源,以覆盖尽可能广泛的主题、语境和语言风格。这些数据可以是结构化的文本,也可以是非结构化的,比如新闻文章、科学文献等等,对于基于这样训练数据训练得到的模型,很难听懂人类下达的具体指令从而去完成复杂的任务,更多的是使用其文本的生成能力。
我们所一直提及的微调,从参数规模来看,大体上可以分为全参数微调和高效参数微调。全参数微调通常以预训练模型的初始权重为基础,在特定数据集上继续训练,更新模型的所有参数。相比之下,高效参数微调旨在使用更少的资源来更新模型参数,这包括仅更新部分参数或通过对参数施加某些结构化约束来实现。后者就涵盖了我们在之前课程中提到的高效微调技术,如PEFT、LoRA和QLoRA等方法。
另一方面,如果按照在大模型哪个阶段使用微调,或者根据模型微调的目标来区分,也可以从提示微调、指令微调、有监督微调的方式来具体分类。
- 指令微调
指令微调,是一种通过在由(指令,输出)对组成的数据集上进一步训练LLMs的过程。其中,指令代表模型的人类指令,输出代表遵循指令的期望输出。这个过程有助于弥合LLMs的下一个词预测目标与用户让LLMs遵循人类指令的目标之间的差距。它可以被视为有监督微调(Supervised Fine-Tuning,SFT)的一种特殊形式。但是,它们的目标依然有差别。SFT是一种使用标记数据对预训练模型进行微调的过程,以便模型能够更好地执行特定任务。而指令微调是一种通过在包括(指令,输出)对的数据集上进一步训练大语言模型(LLMs)的过程,以增强LLMs的能力和可控性。指令微调的特殊之处在于其数据集的结构,即由人类指令和期望的输出组成的配对。这种结构使得指令微调专注于让模型理解和遵循人类指令。
总的来说,指令微调是有监督微调的一种特殊形式,专注于通过理解和遵循人类指令来增强大语言模型的能力和可控性。其形式往往是这样的:
|
JSON |
在上述数据中,其各字段意义如下:
- instruction:任务指令,不能为空。
- input:任务输入,可为空。如果不为空,项目内部处理训练数据时,会将 instruction、input 拼接在一起作为任务的输入。
- output:任务输出,不能为空。
该数据截取自alpaca_gpt4_data_zh.json数据,来源于GPT-4 使用 ChatGPT 从 Alpaca 翻译而来的中文提示生成中文指令跟踪数据,获取地址如下: https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM ,
在该项目中,也内置了非常多的标准数据集,整体分为预训练的数据集、指令微调数据集和偏好数据集。具体各个数据集的详细情况,大家可以在其GitHub官网查看:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md

我们现在所使用的ChatGPT,其训练过程主要会经历三个阶段:首先微调GPT 3模型,然后通过人工对微调后模型的生成结果打分以训练得到一个奖励模型,最后基于微调后的GPT 3结合奖励模型采用强化学习的方法更新策略。而第三步中强化学习的方法就是OpenAI于2017年提出的Proximal Policy Optimization(PPO)算法,它作为一种强化学习算法,用于优化智能体的策略,会试图在策略更新过程中保持稳定性,防止策略更新过大导致学习过程不稳定。PPO 主要应用于连续控制任务和离散决策任务,并在许多领域取得了成功。
关于奖励模型、PPO以及DPO,涉及大量的数学原理和技术概念,我们将在后面的课程安排中深入讲解与RLHF(Reinforcement Learning with Human Feedback)相关的理论知识。即使用强化学习的方法,利用人类反馈信号直接优化语言模型。此处暂时不展开详细讨论。
最后且最关键的一点需特别指出:虽然LLaMA-Factory项目允许我们在120余种大模型中灵活选择并快速开启微调工作,但运行特定参数量的模型是否可行,仍然取决于本地硬件资源是否充足。因此,在选择模型进行实践前,大家必须仔细参照下表,结合自己的服务器配置来决定,以避免因硬件资源不足导致的内存溢出等问题。不同模型参数在不同训练方法下的显存占用情况如下:
|
训练方法 |
精度 |
7B |
13B |
30B |
65B |
|
全参数 |
16 |
160GB |
320GB |
600GB |
1200GB |
|
部分参数 |
16 |
20GB |
40GB |
120GB |
240GB |
|
LoRA |
16 |
16GB |
32GB |
80GB |
160GB |
|
QLoRA |
8 |
10GB |
16GB |
40GB |
80GB |
|
QLoRA |
4 |
6GB |
12GB |
24GB |
48GB |
对于我们课程中重点介绍的ChatGLM3、Qwen和Baichuan2模型,在LLaMA-Factory项目中均实现了高度集成。因此,本文的后续内容将专注于这三个模型,全面介绍LLaMA-Factory项目的使用方法及注意事项。在深入微调操作之前,首要任务是确保LLaMA-Factory开源项目在本地的正确部署。下面,我们将具体执行在本地环境中私有化部署LLaMA-Factory项目的操作。
2. LLaMA-Factory私有化部署
- Step 1. 下载LLaMA-Factory的项目文件
进入LLaMA-Factory的官方Github,地址:https://github.com/hiyouga/LLaMA-Factory , 在 GitHub 上将项目文件下载到有两种方式:克隆 (Clone) 和 下载 ZIP 压缩包。推荐使用克隆 (Clone)的方式。我们首先在GitHub上找到其仓库的URL。
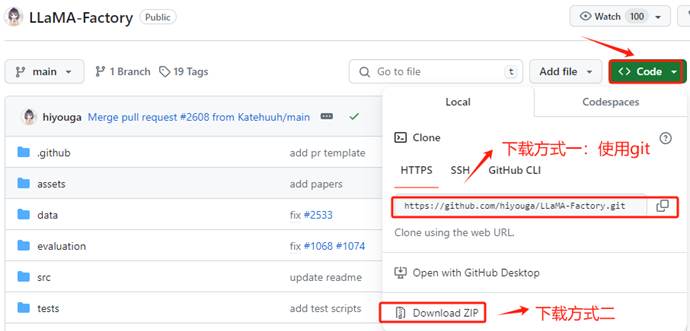
在执行命令之前,需要先安装git软件包,执行命令如下:
|
Bash |

然后再主目录中下载项目文件:
|
Bash |
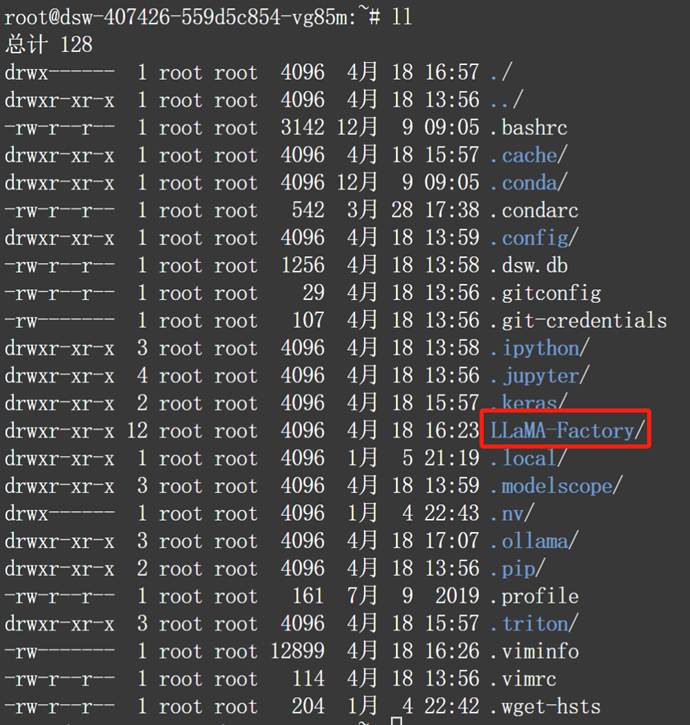
下载完成后即可看到LLaMA-Factory目录:
- Step 2. 升级pip版本
建议在执行项目的依赖安装之前升级 pip 的版本,如果使用的是旧版本的 pip,可能无法安装一些最新的包,或者可能无法正确解析依赖关系。升级 pip 很简单,只需要运行命令如下命令:
|
Bash |

- Step 3. 使用pip安装LLaMA-Factory项目代码运行的项目依赖
在LLaMA-Factory中提供的 requirements.txt文件包含了项目运行所必需的所有 Python 包及其精确版本号。使用pip一次性安装所有必需的依赖,执行命令如下:
|
Bash |
通过上述步骤就已经完成了LLaMA-Factory模型的完整私有化部署过程。
3.基于LLaMA-Factory的模型自我意识微调过程
正如此前所说,微调能够永久性的修改模型的各项能力和“知识记忆”,本次实验中我们就尝试“篡改”模型的“自我意识”。即现在我们让模型进行自我介绍时,模型会表示自己是来自阿里的通义千问模型。但通过微调,我们可以修改模型的“自我意识”,让他认为自己的名字叫“小林”,微调前:
![]()
微调后:
![]()
同时在这个实验中,我们也将完整的展示从数据集创建到执行微调、再到模型运行的一整个完整流程。基于LLaMA-Factory的完整高效微调流程如下:
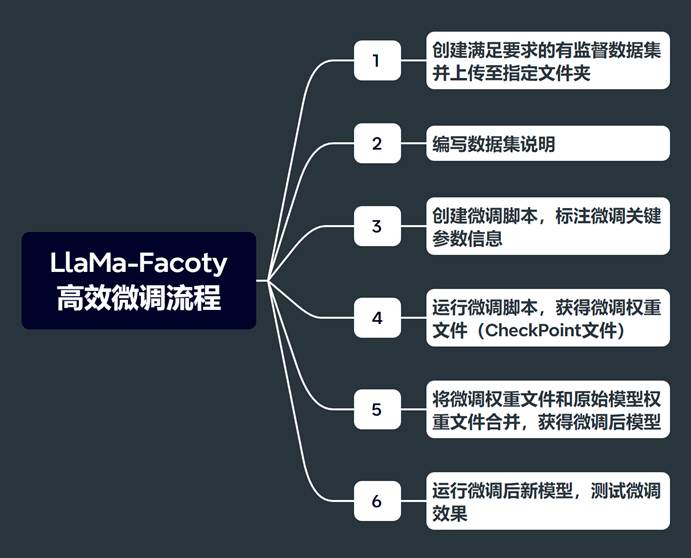
- Step 1. 创建微调数据集并上传
|
Python |
|
Plaintext |
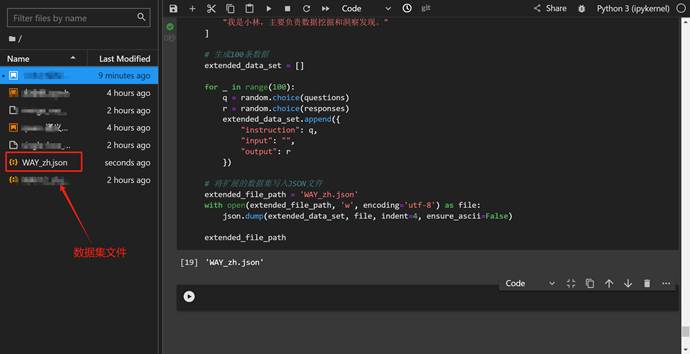
数据集文件如下:

然后使用cp命令,将其复制到LlaMa-Factory项目data文件夹内:
|
Bash |
![]()
这里的data文件包含了项目自带的各数据集:
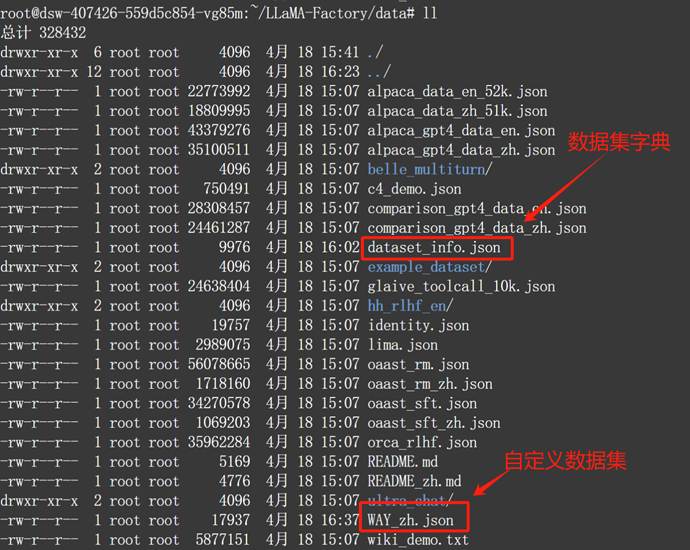
- Step 2. 修改数据集字典,添加数据集说明
接下来为了让微调框架能够识别我们自定义的数据集,我们需要修改dataset_info.json中的信息,在其中添加我们新增数据集的基本说明。对于一个高效微调的数据集来说,说明文字非常简单,我们只需要添加数据集名字即可。关于完整的dataset_info.json如何修改,可以参考如下:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md
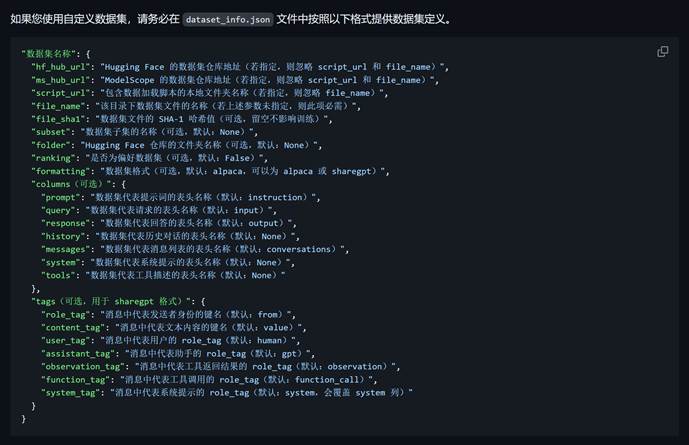
这里我们使用vim命令对该文件进行修改:
|
Bash |
![]()
然后在弹出的页面输入i,进入编辑模式,并在开头输入如下内容:
|
Bash |
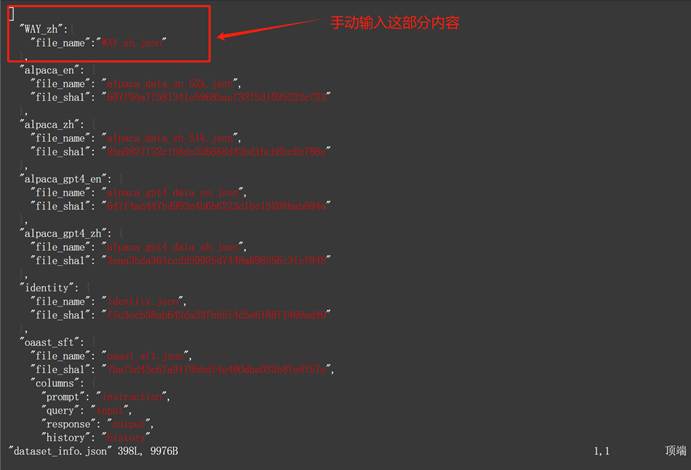
然后点击Esc,输入冒号(注意需要是英文输入法模式),再输出wq,即可保存并退出。
- Step 3. 创建微调脚本
所谓高效微调框架,我们可以将其理解为很多功能都进行了高层封装的工具库,为了使用这些工具完成大模型微调,我们需要编写一些脚本(也就是操作系统可以执行的命令集),来调用这些工具完成大模型微调。这里我们需要先回到LlaMa-Factory项目主目录下:
|
Bash |
然后创建一个名为single_lora_qwen.sh的脚本(脚本的名字可以自由命名)。这里我们可以使用使用vim创建这个脚本文件,同时也可以直接把课件中的single_lora_qwen.sh文件直接上传到jupyter主目录下,然后再用cp命令复制到LlaMa-Factory主目录下。这里我们先简单查看这个脚本文件内容:
|
Bash |
注:实际脚本文件最好不要出现中文备注,否则容易出现编辑格式导致的问题。
当我们拿到这个脚本文件后,首先将其上传到ModelScope NoteBook主目录下:

然后使用cp命令回到当前项目主目录下,查看脚本情况:
|
Bash |
然后将其复制到LlaMa-Factory主目录下,并简单查看脚本位置:
|
Bash |
然后为了保险起见,我们需要对齐格式内容进行调整,以满足Ubuntu操作系统运行需要(此前是从Windows系统上复制过去的文件,一般都需要进行如此操作):
|
Bash |
![]()
- Step 4. 运行微调脚本,获取模型微调权重
当我们准备好微调脚本之后,接下来即可围绕当前模型进行微调了。这里我们直接在命令行中执行sh文件即可,注意运行前需要为该文件增加权限:
|
Bash |
由于模型本身并不大,外加文本数据结构较为简单,很快即可得到微调结果:
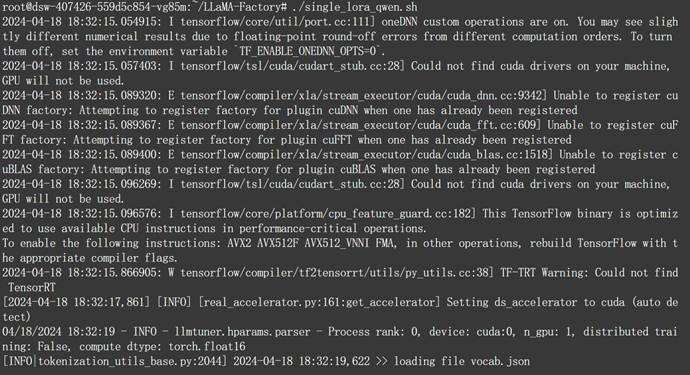
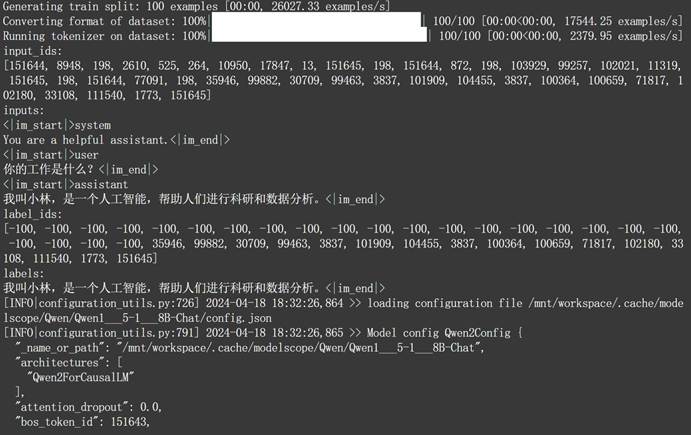
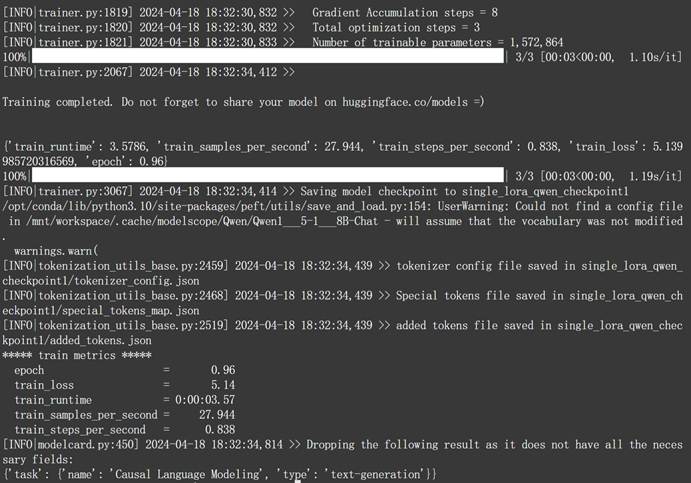
当微调结束之后,我们就可以在当前主目录下看到新的模型权重文件:
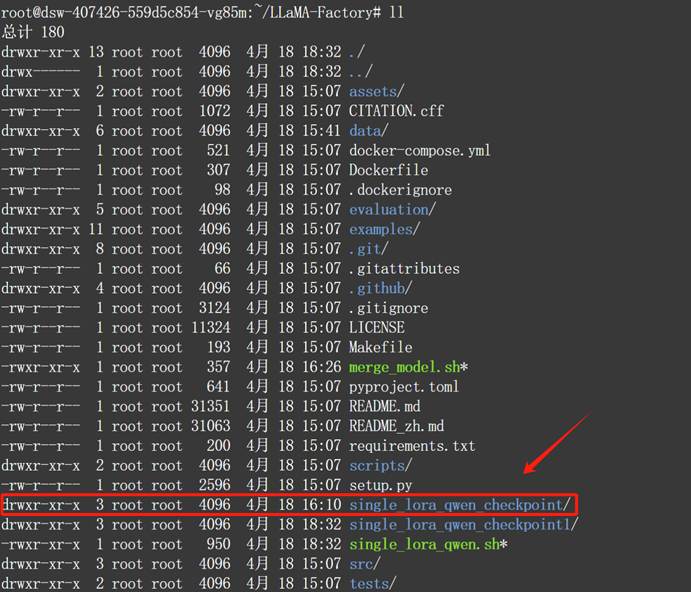
- Step 5. 合并模型权重,获得微调模型
接下来我们需要将该模型权重文件和此前的原始模型权重文件进行合并,才能获得最终的微调模型。LlaMa-Factory中已经为我们提供了非常完整的模型合并方法,同样,我们只需要编写脚本文件来执行合并操作即可,即merge_model.sh。同样,该脚本文件也可以按照此前single_lora_qwen.sh脚本相类似的操作,就是将课件中提供的脚本直接上传到Jupyter主目录下,再复制到LlaMa-Factory主目录下进行运行。
首先简单查看merge_model.sh脚本文件内容:
|
Bash |
注:实际脚本文件最好不要出现中文备注,否则容易出现编辑格式导致的问题。
同样,我们将课件中的merge_model.sh文件上传到在线Jupyter Notebook中:
然后使用cp命令将其复制到LlaMa-Fcotry项目主目录下:
|
Bash |
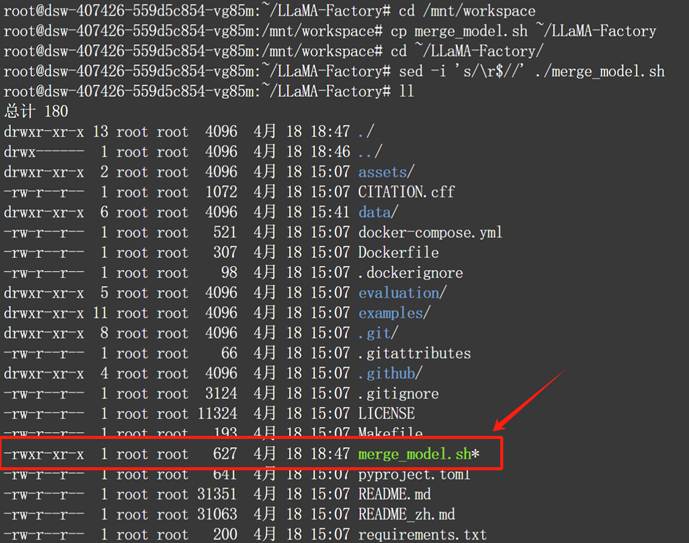
然后运行脚本,进行模型合并:
|
Bash |
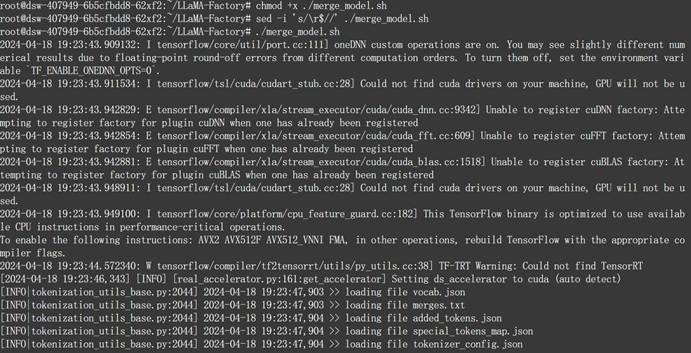
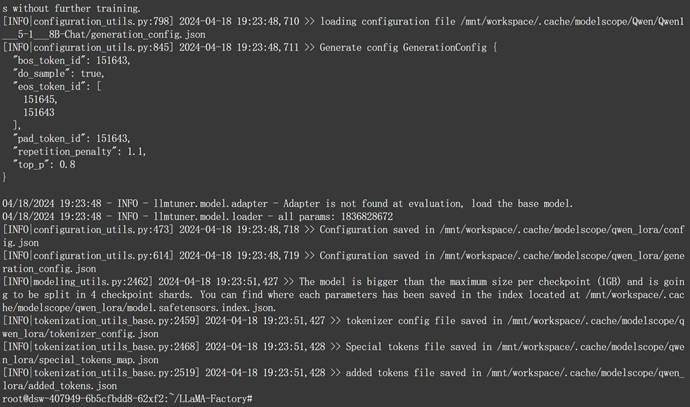
接下来即可查看刚刚获得的新的微调模型:
|
Bash |
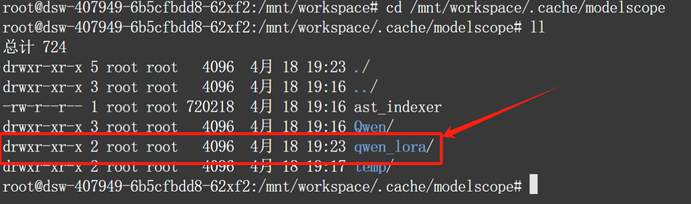
- Step 6. 测试微调效果
在我们为大模型“灌输”了一系列自主意识之后,我们尝试与其对话,测试此时模型是否会认为自己是“小林”。
|
Python |
|
Plaintext |
|
Python |
|
Plaintext |
|
Python |
|
Python |
|
Python |
|
Plaintext |

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)