
动态图机制:为什么 PyTorch 调试起来更舒服
前 5 章我们已经知道:Tensor 承载数据,Autograd 负责求导。现在把两件事连起来:当 Python 代码执行 Tensor 运算时,PyTorch 会边计算结果,边把反向传播需要的历史记录下来。
这就是动态图。它让深度学习模型看起来像普通 Python 程序。能断点,能打印,能写 if,能写 for,也能在出错时更快定位问题。
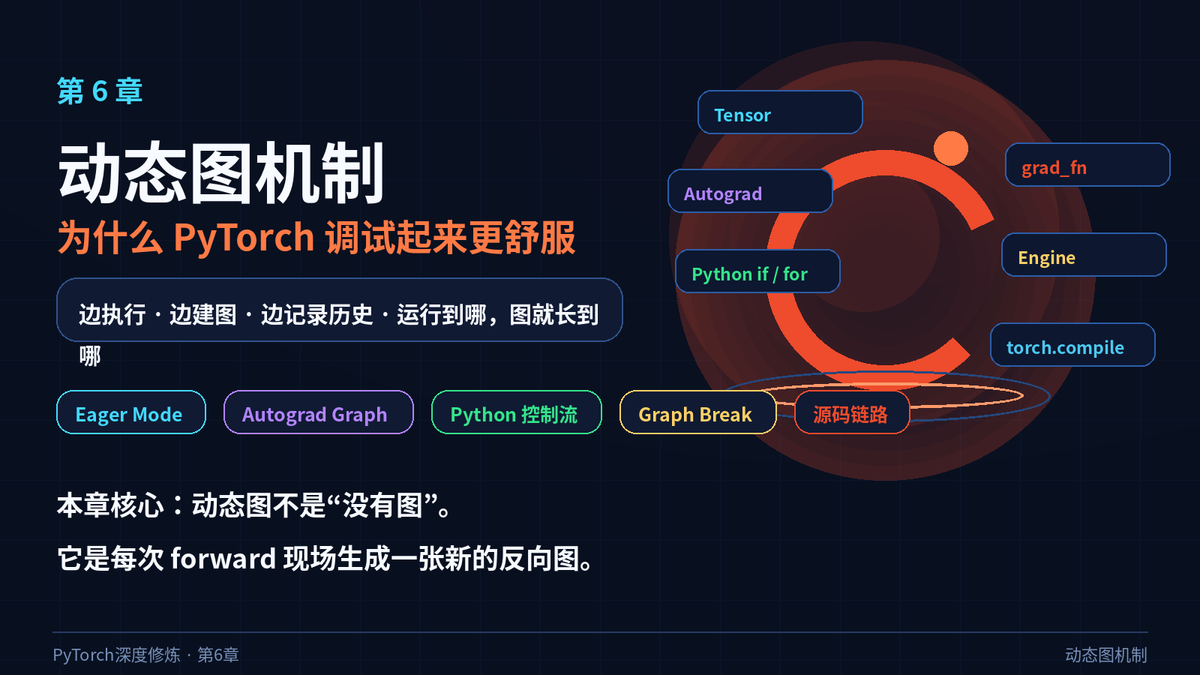
动态图的直觉:执行一行,记录一段历史
一、动态图解决的不是数学问题,而是开发体验问题
静态图更像“先画施工图,再统一施工”。动态图更像“边施工边记录每一步”。
PyTorch 默认采用 Eager Mode。你调用一行 Tensor 运算,这一行就马上执行。不是先把整张模型图声明完,再交给另一个运行时。
这带来一个巨大好处:模型代码就是普通 Python 代码。你怎么写,PyTorch 就怎么跑;这次跑了哪条分支,Autograd 就记录哪条分支。

二、动态在哪里:每次 forward 都重新建图
动态图的“动态”,主要体现在三件事。
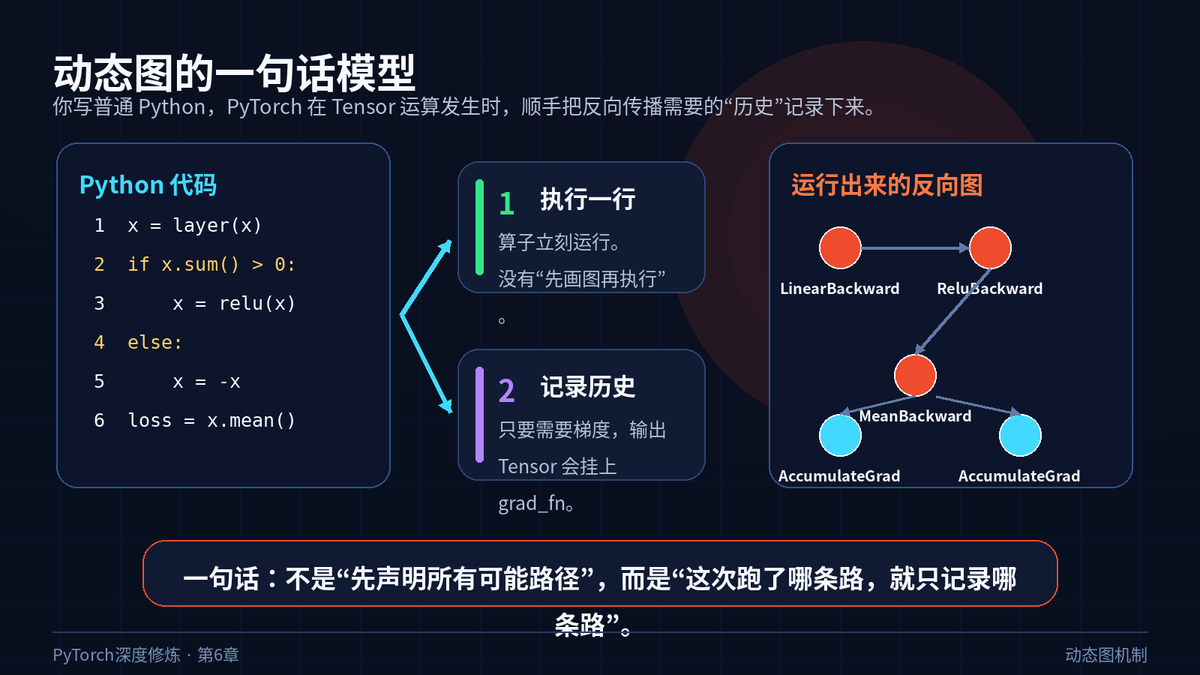
第一,图不是预先固定的。每次 forward 执行时,PyTorch 都会重新根据真实执行路径生成一张反向图。
第二,图可以变形。输入不同,if 条件不同,循环次数不同,最后生成的计算图也可以不同。
第三,图默认是一次性的。通常一次 backward 结束后,中间保存的反向历史会被释放,下一轮 forward 重新开始。
|
PyTorch 官方 Autograd mechanics 文档也强调:计算图会在每次迭代从头重新创建,这正是它能支持任意 Python 控制流的原因。 |
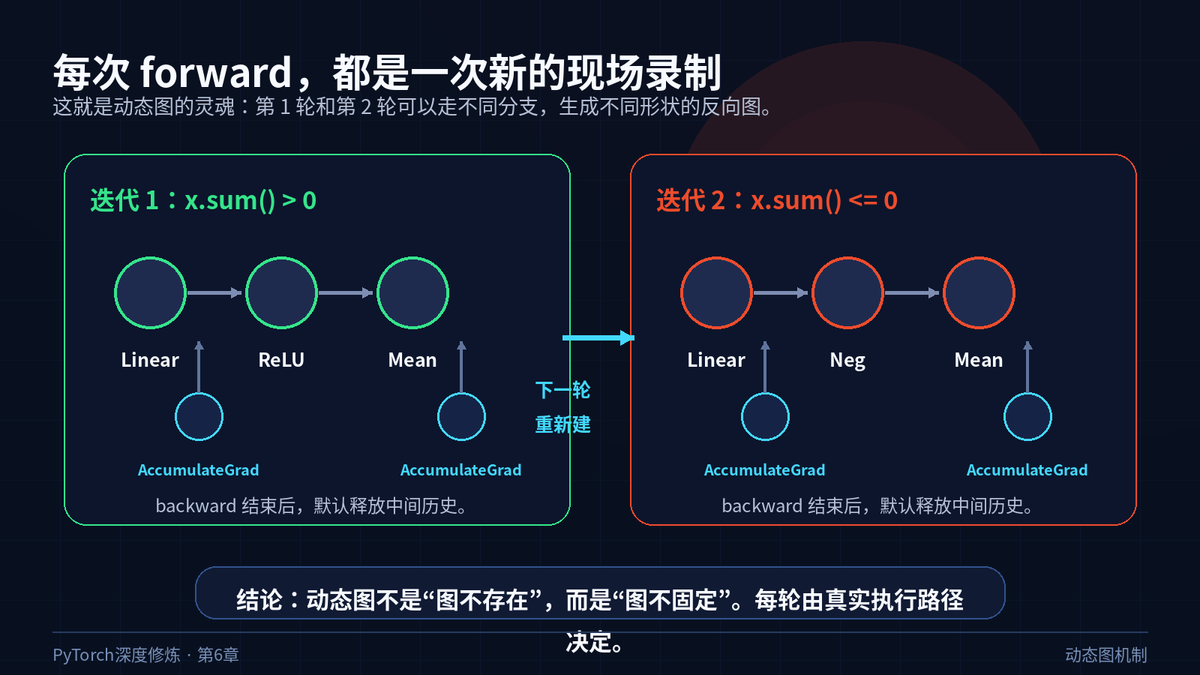
两次迭代可以生成不同的反向图
三、为什么 if / for 能自然参与模型
因为 PyTorch 没有要求你提前把所有路径都描述出来。Python 解释器先决定这次走哪条路,PyTorch 只记录实际发生的 Tensor 运算。
看一个最小例子。代码很短,但能说明动态图的本质。
|
def f(x): |
如果这次 y.sum() > 0,图里会出现 ReluBackward。
如果下次 y.sum() <= 0,图里会出现 NegBackward。
没有走过的分支,不会进入这次的反向图。
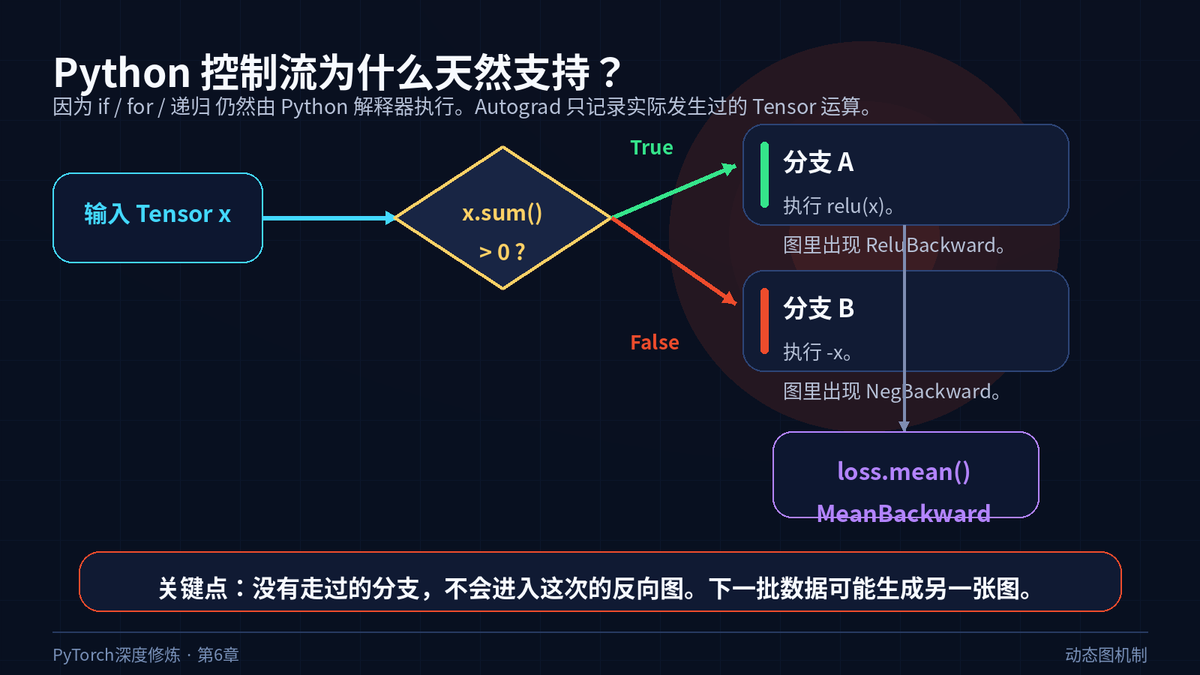
Python 控制流先决定路径,Autograd 再记录路径
四、为什么它好调试:Eager Mode 让错误离代码更近
动态图不是只让模型更灵活。它真正改变的是调试方式。
静态图时代,很多问题会在图执行阶段才暴露,错误栈可能离业务代码很远。
PyTorch 默认立即执行。你可以在 forward 的任意一行打断点,也可以立刻打印 Tensor 的 shape、dtype、device 和数值范围。
这就是 PyTorch 对研究者友好的原因:模型是程序,不是配置文件。

Eager Mode 的调试优势
五、源码级看动态图:不是 nn.Module 魔法,是 Tensor 历史链
很多人以为动态图是 nn.Module 做的。不是。nn.Module 只是组织参数和 forward 的外壳。真正的图来自 Tensor 运算和 Autograd 元信息。
源码里,Variable 现在本质上就是 Tensor。PyTorch 的 variable.h 注释说明:Variable 会沿着 autograd graph 中的 Edge 在 Node 之间流动;叶子变量把梯度累加到自己的 grad;中间变量通过 grad_fn 指向产生它的函数。
理解这句话就够了:Tensor 不只是数据,它还能带着“我从哪里来”的历史。
一个需要梯度的算子执行时,大体做四件事。
1. 检查输入里有没有 requires_grad=True 的 Tensor。
2. 从输入 Tensor 收集 next_edges。
3. 创建对应的 backward Node。
4. 把输出 Tensor 的 grad_fn 指向这个 Node。
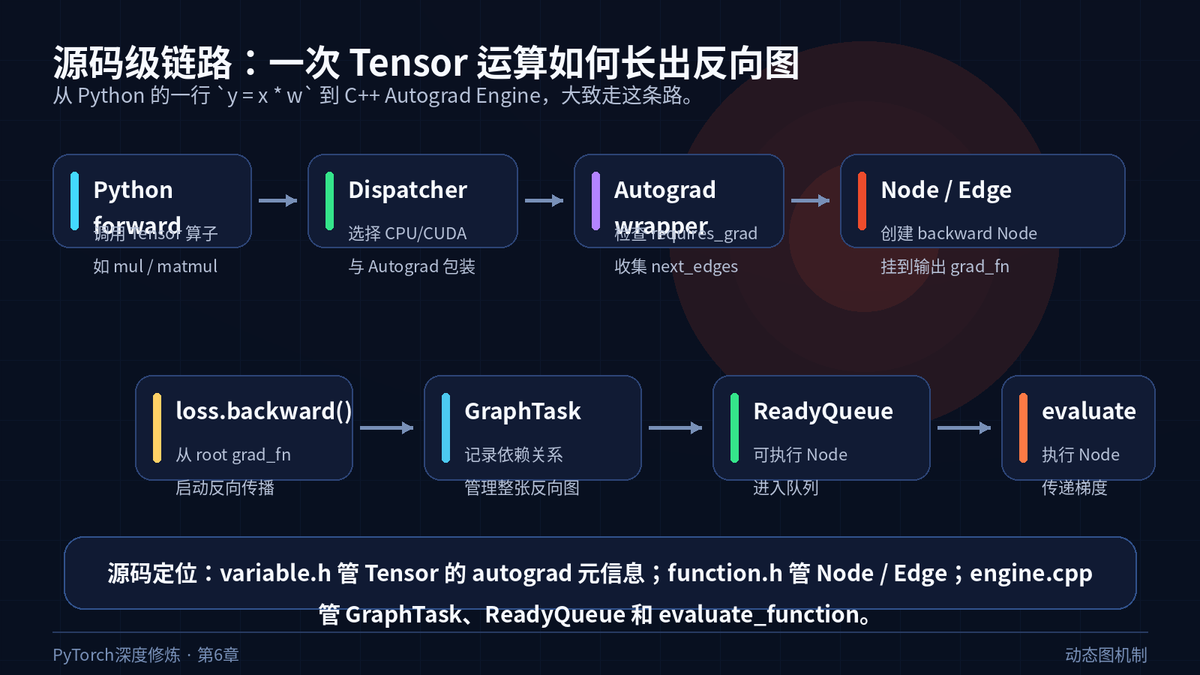
从 Tensor 运算到 Autograd Engine 的源码链路
六、backward 不是递归 Python 调用,而是 C++ 引擎调度
forward 负责“录制”。backward 负责“回放”。
当你调用 loss.backward(),PyTorch 会从 loss 的 grad_fn 出发,沿 next_edges 找到上游节点,建立 GraphTask,计算依赖关系,把可执行节点放入 ReadyQueue,然后由 Engine 执行 evaluate_function。
这也是为什么反向传播不是简单地按 Python 代码倒着跑。它跑的是 forward 过程中记录下来的 Node / Edge 图。
源码文件可以这样定位。
|
torch/csrc/autograd/variable.h # Tensor 的 autograd 元信息:grad_fn、grad、version、view |
把这条链路记住,后面看 retain_graph、detach、no_grad、checkpoint、compile 都会轻松很多。
七、动态图也有代价:灵活不是免费的
动态图最大的代价,是 Python 调度开销和全局优化空间不足。
每次 forward 都按 Python 语义执行。小算子很多时,Python 调用、Dispatcher 分发、Autograd 包装都会产生额外成本。
动态图也很难天然做全局图优化。因为图是运行时生成的,路径还可能变化。
所以 PyTorch 2.x 引入了 torch.compile:不是抛弃动态图,而是在动态图上加一层编译加速。
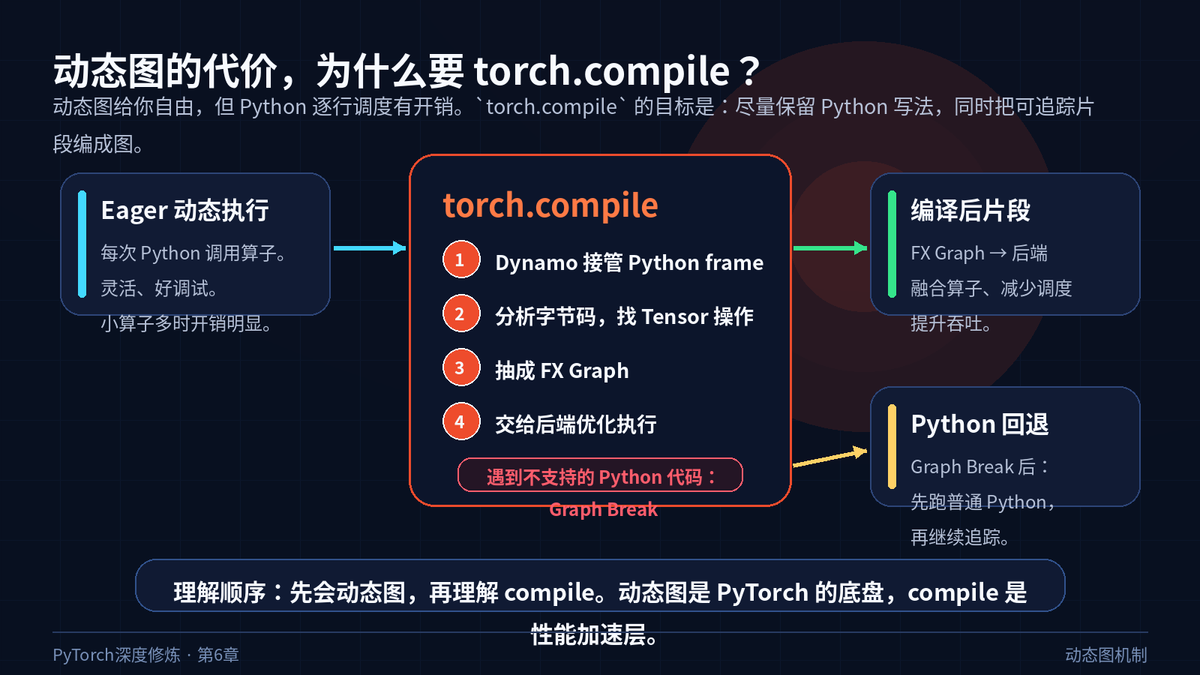
torch.compile:在动态图底盘上抽取可优化子图
八、torch.compile 和动态图不是对立关系
torch.compile 的思路不是让你重写模型。它尽量接管普通 Python 代码,通过 TorchDynamo 分析 Python 字节码,把可追踪的 Tensor 运算抽成 FX Graph,再交给后端优化。
如果遇到难以追踪的 Python 代码,Dynamo 会 graph break:先把已经捕获的图编译, unsupported 部分回到普通 Python 执行,然后继续尝试追踪后面的代码。
这就是 PyTorch 2.x 的设计取向:保持动态图的开发体验,同时尽量拿到静态图的性能收益。
Eager、FX、compile、export 的定位对比
九、读源码时抓这条主线
不要一上来就陷进几千行 C++。读动态图源码,只抓一条主线。
第一步,看 Tensor 如何带 autograd 元信息。重点是 grad_fn、grad、requires_grad、version。
第二步,看算子执行时如何创建 backward Node。重点是 collect_next_edges 和 create_gradient_edge。
第三步,看 backward 如何调度 Node。重点是 GraphTask、ReadyQueue、evaluate_function。
第四步,再看 torch.compile 如何捕获动态图。重点是 Dynamo 的 frame evaluation hook、字节码分析、FX Graph 和 graph break。
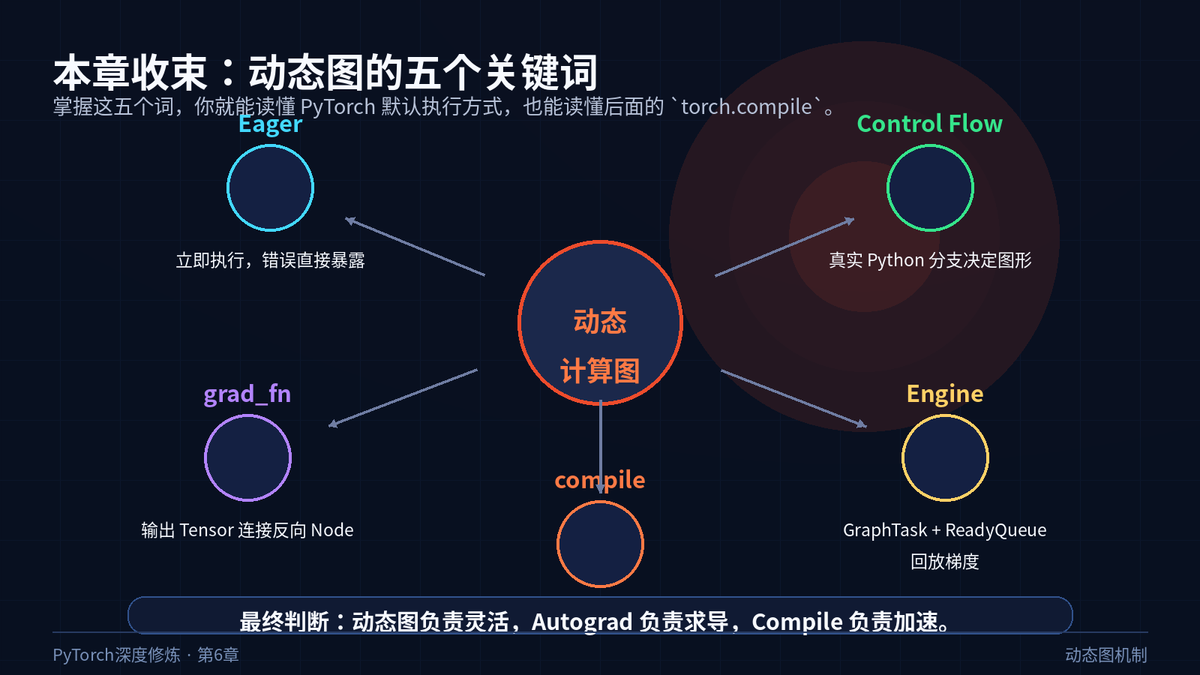
十、总结
|
动态图的本质:Python 负责真实执行,Autograd 负责记录历史,Engine 负责反向回放。 |
PyTorch 调试舒服,不是偶然。它的默认执行方式就是按普通 Python 程序来跑。
动态图让模型更自由,也让错误更接近代码现场。
但自由有代价。性能优化、部署和跨平台推理,需要把动态图中的稳定部分重新抽成图。
这正是后续 torch.compile、torch.export、ONNX 要解决的问题。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)