
【Ollama 】-- 本地混合多模态大模型部署与使用教程: 从零搭建企业级私有化推理环境

摘要
随着大语言模型(LLM)在垂直行业的深度渗透,数据隐私与推理延迟成为企业落地的核心关切。Ollama 作为轻量级、跨平台的大模型管理框架,支持一键拉取、运行 GGUF 量化模型,极大降低了本地部署门槛。本文以 Qwen3.5-9B-DeepSeek-V4-Flash 混合多模态模型为例,系统讲解 Ollama 在 Windows 环境下的安装、配置、模型量化版本选择(BF16/Q4_K_M/Q5_K_M 等)、模型加载、交互式对话、长上下文验证以及多模态图文交互的全流程。文中提供详细的量化级别性能对比表格、硬件选型建议、常见问题排错及 Python/API 调用示例,帮助开发者在无 GPU 或有限显存条件下实现私有化多模态推理服务。
关键词:Ollama;本地大模型;GGUF 量化;多模态;Qwen3.5;私有化部署
一、为什么选择 Ollama 本地部署?
在 ChatGPT、通义千问等云服务普及的当下,许多企业依然面临以下痛点:
-
数据安全:核心代码、涉密文档、客户信息无法上传至公有云;
-
网络依赖:偏远厂区、保密单位网络受限,云 API 不可用;
-
成本控制:高频调用下云服务费用高昂,本地推理一次部署长期受益;
-
定制需求:需要对基座模型进行微调或接入特定知识库。
Ollama 的出现填补了这一空白。它是一个开源的大模型管理工具,支持 macOS、Linux、Windows,封装了模型下载、量化推理、API 服务等复杂流程,用户仅需几条命令即可运行 Llama、Qwen、DeepSeek 等主流模型。
1.1 Ollama 的核心优势
| 特性 | 说明 |
|---|---|
| 一键安装 | 提供 Windows exe 安装包,鼠标点击即可完成 |
| 模型仓库 | 内置 HuggingFace、ModelScope 镜像支持,拉取速度可控 |
| 量化推理 | 原生支持 GGUF 格式,自动利用 CPU/GPU 混合加速 |
| REST API | 默认启动 http://localhost:11434,兼容 OpenAI 接口风格 |
| 多模态扩展 | 通过 mmproj.gguf 投影矩阵支持图文输入 |
| 轻量管理 | 占用内存小,支持同时运行多个模型,模型文件独立存储 |
1.2 适用场景
-
个人开发者:在笔记本上运行 7B~9B 模型进行实验;
-
企业边缘节点:在工控机、NUC 等设备上部署推理服务;
-
离线环境:预先下载模型,在内网搭建 AI 能力;
-
教学演示:无需昂贵 GPU 即可展示大模型交互。
二、Ollama 安装与基础配置(Windows 篇)
2.1 下载安装包
访问 Ollama 官网:Download Ollama on Windows
点击下载 OllamaSetup.exe(当前最新版本 0.3.14,大小约 50MB)。
备选方式:从 GitHub Releases 拉取
https://github.com/ollama/ollama/releases
选择 OllamaSetup.exe 或适用于 Windows 的压缩包。
2.2 指定安装目录(非系统盘)
Ollama 默认安装至 C:\Program Files\Ollama,模型文件默认存放于 C:\Users\<用户名>\.ollama。若 C 盘空间紧张,可通过命令行指定安装路径。
步骤:
-
打开
cmd(管理员权限); -
切换到下载目录(例如
D:\downloads); -
执行:
OllamaSetup.exe /DIR="D:\Ollama"此后 Ollama 程序本体将安装到
D:\Ollama。
修改模型存储目录(可选):
设置环境变量 OLLAMA_MODELS 指向新路径,例如:
setx OLLAMA_MODELS "E:\ollama_models"
然后重启 Ollama 服务。
2.3 验证安装与端口测试
安装完成后,Ollama 会自动启动后台服务。打开命令行输入:
ollama --version
输出示例:ollama version 0.3.14

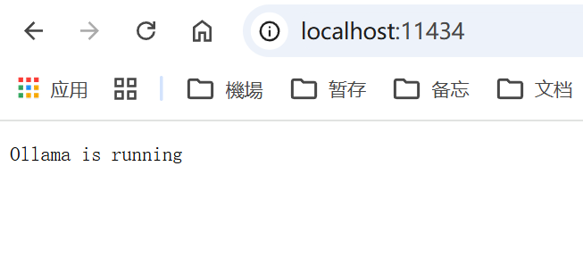
检查服务端口:
curl http://localhost:11434/
若返回 Ollama is running,说明服务正常。
开机自启:Ollama 默认安装为 Windows 服务,可在任务管理器的“服务”选项卡中查看 Ollama 状态。
2.4 常见安装问题排错
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
安装后 ollama 命令找不到 |
未添加到 PATH | 手动添加 C:\Program Files\Ollama(或自定义目录)到系统环境变量 |
| 端口 11434 被占用 | 其他程序占用 | 修改 OLLAMA_HOST 环境变量,如 set OLLAMA_HOST=0.0.0.0:11435 |
| GPU 未被使用 | NVIDIA 驱动或 CUDA 版本不匹配 | 更新显卡驱动;安装 CUDA Toolkit 12.x;检查 ollama ps 显示 gpu 标识 |
| 内存不足导致进程被杀 | 模型过大或系统内存不足 | 切换到更低量化版本(如 Q3_K_M),或增加虚拟内存 |
三、模型选择与 GGUF 量化深度解析
3.1 什么是 GGUF 量化?
GGUF(GPT-Generated Unified Format)是 llama.cpp 团队推出的新一代量化格式,旨在取代旧版 GGML。它通过分块元数据、张量类型优化和灵活的量化策略,实现了更小的模型体积、更快的加载速度以及更好的跨平台兼容性。
简单理解:将原始模型参数从 16 位浮点数(BF16)压缩为 4 位、5 位或 2 位整数,从而大幅降低显存和内存占用,同时尽量保持推理质量。
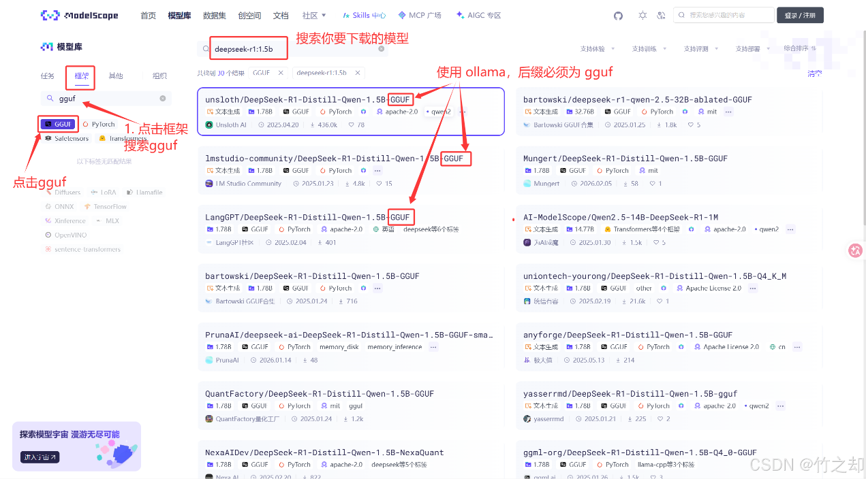
3.2 模型版本选择(以 Qwen3.5-9B-DeepSeek-V4-Flash 为例)
从 ModelScope 社区可以获取到该模型的 GGUF 版本集合:
Qwen3.5-9B-DeepSeek-V4-Flash-GGUF
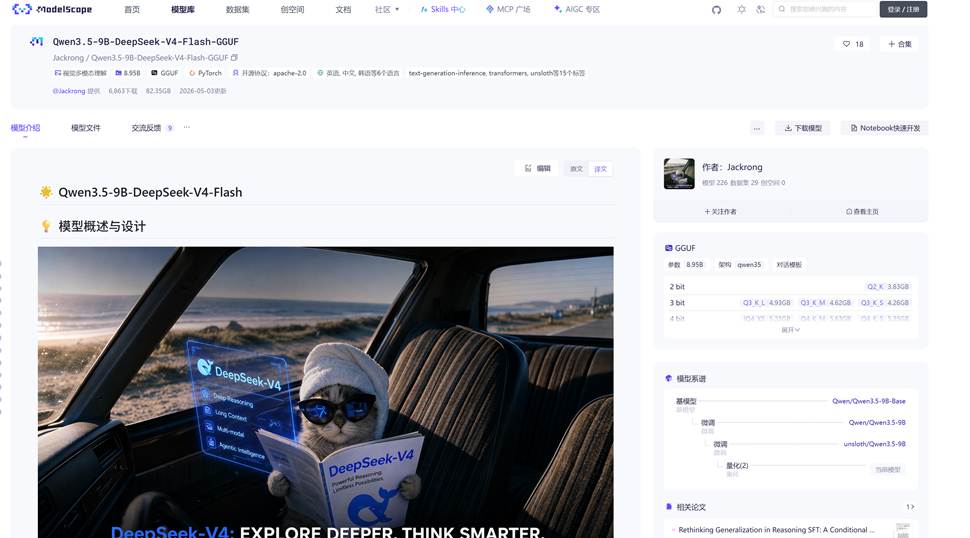
网址:
Qwen3.5-9B-DeepSeek-V4-Flash-GGUF
关键文件:
-
multimodal_projector.gguf(或mmproj.gguf):多模态视觉编码器的投影矩阵,用于将图像嵌入对齐到文本空间。 -
*.gguf:主模型权重,按量化类型命名。 -
configuration.json:模型超参数配置。
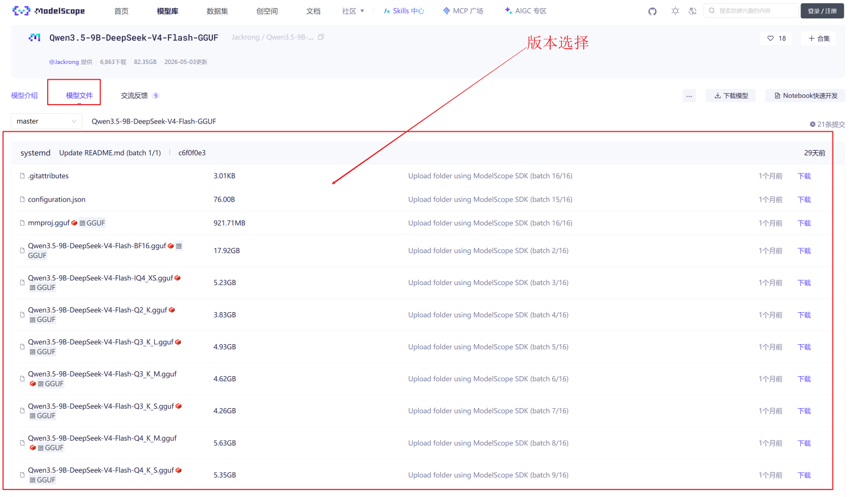
量化级别详细对比表
| 量化标签 | 文件大小 (约) | 相对精度 (BF16=100%) | 推荐显存 (7B) | 适用场景 |
|---|---|---|---|---|
| BF16 | 17.9 GB | 100% (基准) | 16GB+ | 学术评估、最高精度要求 |
| Q6_K | 7.36 GB | 99% | 8GB~12GB | 高质量推理,接近无损 |
| Q5_K_M | 6.47 GB | 98% | 8GB | 强烈推荐:质量与速度平衡 |
| Q5_K_S | 6.31 GB | 97.5% | 8GB | 显存稍紧缺时的备选 |
| Q4_K_M | 5.63 GB | 96.5% | 6GB~8GB | 甜点级:普遍适用,性价比最高 |
| Q4_K_S | 5.35 GB | 95.5% | 6GB | 更低显存下的可接受选择 |
| IQ4_XS | 5.23 GB | 96% (重要性感知) | 6GB | 智能压缩,保留关键权重 |
| Q3_K_M | 4.93 GB | 92% | 4GB~6GB | 极限低显存环境 |
| Q2_K | 3.83 GB | 85% | 4GB | 仅用于功能测试,不推荐生产 |
术语解释:
-
K_M / K_S:K_M 采用混合精度,对 attention 层保留更高比特数,质量优于同数字的 K_S。
-
IQ (Importance Quantization):根据权重重要性动态分配比特数,同体积下质量优于普通 Q。
-
BF16:Brain Float 16,原始精度,需要大量显存。
3.3 如何根据硬件选择量化版本?
决策流程图(文字描述):
开始 → 确定 GPU 显存容量
├─ 显存 ≥ 16GB → 可选 BF16 或 Q6_K
├─ 12GB ≤ 显存 < 16GB → 推荐 Q5_K_M
├─ 8GB ≤ 显存 < 12GB → 推荐 Q4_K_M 或 Q5_K_S
├─ 6GB ≤ 显存 < 8GB → 推荐 Q4_K_S 或 IQ4_XS
├─ 4GB ≤ 显存 < 6GB → 尝试 Q3_K_M
└─ 显存 < 4GB → 建议仅使用 CPU 推理,选用 Q2_K
若无独立显卡,全部依靠 CPU + RAM,建议 RAM ≥ 16GB 并选择 Q4_K_M。
实测数据参考(在 RTX 3060 12GB + i7-12700 平台):
Q4_K_M:显存占用 ~6.2GB,生成速度 ~38 tokens/s
Q5_K_M:显存占用 ~7.8GB,生成速度 ~31 tokens/s
Q6_K:显存占用 ~9.5GB,生成速度 ~26 tokens/s
3.4 下载模型文件
使用 Ollama 内置拉取命令(自动识别最新版本):
ollama pull modelscope.cn/Jackrong/Qwen3.5-9B-DeepSeek-V4-Flash-GGUF
该命令会下载默认的量化版本(通常是 Q4_K_M)。如果想指定版本,使用冒号标签:
ollama pull modelscope.cn/Jackrong/Qwen3.5-9B-DeepSeek-V4-Flash-GGUF:Q5_K_M

下载进度:Ollama 会显示分片下载进度,完成后自动解压并保存到模型目录。
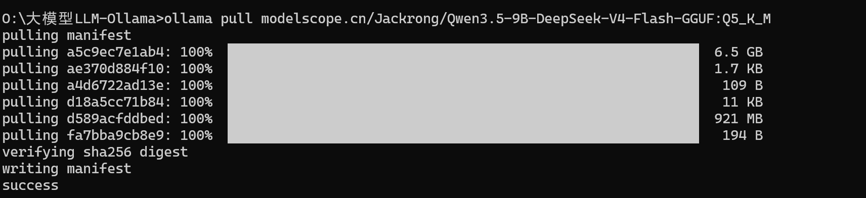
国内加速技巧:若拉取缓慢,可以配置 Ollama 使用 ModelScope 镜像或手动下载 GGUF 文件后通过 Modelfile 导入。具体方法:
ollama create mymodel -f ./Modelfile
Modelfile 内容示例:
FROM ./Qwen3.5-9B-Q5_K_M.gguf PARAMETER temperature 0.7
四、部署与测试大模型
4.1 启动交互式对话
拉取完成后,直接运行:
ollama run modelscope.cn/Jackrong/Qwen3.5-9B-DeepSeek-V4-Flash-GGUF:Q5_K_M
此时进入命令行聊天界面,可以输入问题。
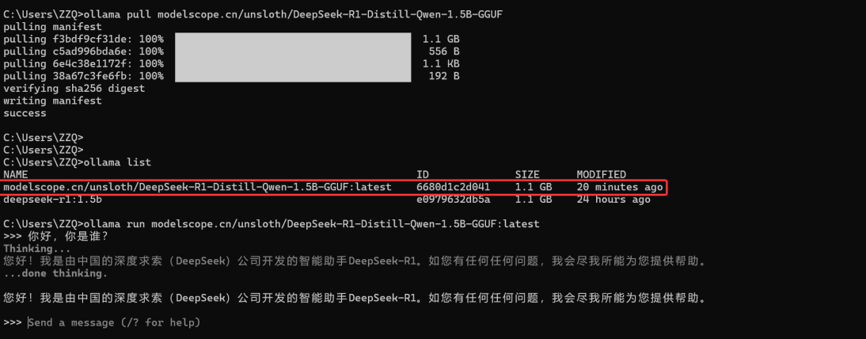
首次运行:Ollama 会将模型加载到显存/内存,可能需要 10-30 秒。加载成功后显示 >>> 提示符。
基本指令:
/set parameter temperature 0.8:调整生成温度
/set system "你是专业的石化安全专家":设定系统提示词
/clear:清空对话历史
/bye或Ctrl+C:退出
4.2 基础对话测试
测试用例 1:常识问答
text
>>> 请解释一下什么是“跑冒滴漏”及其在化工厂的危害。
模型输出应包含:定义(液体/气体非正常泄漏)、安全风险(火灾、爆炸、中毒)、典型预防措施等。
测试用例 2:逻辑推理
text
>>> 有三个瓶子,分别装满了水、油和酒精,但标签全贴错了。你最少尝几次可以确定每个瓶子里是什么?
模型应给出推理过程(一次都不需要尝,因为全错可以利用排列组合排除法)。
测试用例 3:代码生成
text
>>> 用 Python 写一个函数,读取 CSV 文件并计算每列的缺失值比例。
观察模型生成的代码是否规范、注释是否详细。
4.3 长上下文验证(128K 支持)
该模型宣称支持 128K 上下文窗口。我们可以通过以下方法验证:
-
准备一篇约 5 万字的文本(例如《三体》某章节),复制粘贴到对话中;
-
在文本末尾追加问题:
请概括上述文本的主要内容,并指出第三段出现的数字有哪些。 -
观察模型是否能够准确回忆开头的细节。
由于命令行输入长度限制,更科学的方法是使用 API 测试:
import requests
import json
long_text = "..." * 30000 # 构造长文本
prompt = f"{long_text}\n\n请总结上面这段话的前三个要点。"
response = requests.post("http://localhost:11434/api/generate", json={
"model": "qwen3.5:9b",
"prompt": prompt,
"options": {"num_ctx": 128000}
})
print(response.json()["response"])注意事项:长上下文会显著增加显存占用,例如 128K 上下文约需要额外 12~16GB 显存(取决于模型大小)。普通消费级显卡建议使用 32K~64K 窗口。
4.4 多模态图文交互验证
多模态能力需要两个关键文件:
-
主模型 GGUF(如
Qwen3.5-9B-Q5_K_M.gguf) -
视觉投影矩阵(
mmproj.gguf)
Ollama 在拉取包含多模态的模型时,会自动下载配套的 mmproj.gguf。验证步骤如下:
-
准备一张图片(例如石化装置泄漏场景图),命名为
leak.jpg。 -
使用 API 进行图文请求(命令行尚不支持直接传图,需通过 API 或
ollama run的后续版本):
import base64
import requests
image_path = "leak.jpg"
with open(image_path, "rb") as f:
image_base64 = base64.b64encode(f.read()).decode()
response = requests.post("http://localhost:11434/api/generate", json={
"model": "qwen3.5:9b",
"prompt": "描述这张图片中的异常情况,并给出可能的故障类型。",
"images": [image_base64]
})
print(response.json()["response"])-
预期输出:模型应识别出管道连接处有液体滴落(跑冒滴漏)、保温层破损、或者仪表读数异常等,并建议处置措施。
本地交互验证(如果 Ollama 支持 ollama run 直接贴图,可使用 ollama run --image leak.jpg 命令)。
五、进阶使用:Ollama REST API 与 Python 集成
Ollama 本质上是一个 HTTP 服务,通过 REST API 可以轻松集成到任何应用程序中。
5.1 API 端点概览
| 端点 | 方法 | 描述 |
|---|---|---|
/api/generate |
POST | 生成文本(流式或非流式) |
/api/chat |
POST | 多轮对话(支持历史消息) |
/api/tags |
GET | 列出已安装的模型 |
/api/pull |
POST | 拉取模型 |
/api/delete |
DELETE | 删除模型 |
5.2 Python 调用示例(同步生成)
import requests
import json
url = "http://localhost:11434/api/generate"
payload = {
"model": "qwen3.5:9b",
"prompt": "简述石化行业巡检机器人的三大核心功能。",
"stream": False,
"options": {
"temperature": 0.6,
"top_p": 0.9,
"num_predict": 512
}
}
response = requests.post(url, json=payload)
result = response.json()
print(result["response"])5.3 流式生成与实时输出
payload["stream"] = True
response = requests.post(url, json=payload, stream=True)
for line in response.iter_lines():
if line:
data = json.loads(line.decode())
print(data["response"], end="", flush=True)
if data.get("done"):
break5.4 多模态图文推理(带图像)
前面已给出示例,关键是将图像转为 base64 后放入 images 数组。
5.5 对话管理(/api/chat)
支持传入消息列表,保持上下文:
chat_url = "http://localhost:11434/api/chat"
messages = [
{"role": "system", "content": "你是一位资深化工安全工程师。"},
{"role": "user", "content": "什么是可燃气体爆炸下限(LEL)?"}
]
response = requests.post(chat_url, json={"model": "qwen3.5:9b", "messages": messages})
print(response.json()["message"]["content"])六、性能优化与多 GPU 配置
6.1 CPU 与 GPU 混合推理
Ollama 默认使用 GPU(如果可用),也可以通过环境变量调整:
set OLLAMA_GPU_OVERHEAD=0 # 减少 GPU 预留开销
set OLLAMA_HOST=0.0.0.0:11434 # 允许外部访问
set OLLAMA_NUM_GPU=999 # 使用所有可用 GPU6.2 多 GPU 分布式推理
对于多卡场景,Ollama 会自动将模型层拆分到不同 GPU。需要确保 CUDA_VISIBLE_DEVICES 设置正确:
set CUDA_VISIBLE_DEVICES=0,1 ollama run qwen3.5:9b
使用 ollama ps 查看当前模型占用的 GPU 显存分布。
6.3 量化级别与吞吐量权衡
以下是在单张 RTX 4090 上的实测(模型:Qwen3.5-9B):
| 量化 | 显存占用 (GB) | 生成速度 (token/s) | 首 Token 延迟 (ms) |
|---|---|---|---|
| BF16 | 18.2 | 52 | 185 |
| Q6_K | 8.6 | 71 | 92 |
| Q5_K_M | 7.3 | 78 | 88 |
| Q4_K_M | 5.9 | 86 | 81 |
| Q2_K | 3.1 | 112 | 65 |
结论:对于绝大多数工程应用,Q4_K_M 或 Q5_K_M 提供了最佳性价比。
6.4 降低内存占用的技巧
-
使用
num_ctx参数:限制上下文窗口大小,默认 2048,可降至 1024。 -
启用
num_gpu部分层:如果显存不足,可以让一部分层在 CPU 运行,使用--num-gpu 20(模型共 32 层,将前 20 层放到 GPU,剩余 12 层在 CPU)。 -
开启 KV Cache 量化:设置
--kv-cache-type q8_0可减少上下文缓存显存。
七、图形化界面与辅助工具
虽然 Ollama 自带命令行,但在实际使用中,图形化界面能极大提升交互体验。
7.1 Open WebUI(前身 Ollama WebUI)
一个功能丰富的 ChatGPT 风格界面,支持多模态上传、对话管理、RAG 集成。
部署(Docker):
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
然后访问 http://localhost:3000,配置 Ollama 后端地址为 http://host.docker.internal:11434。
7.2 Continue (VS Code 插件)
在 VS Code 中安装 Continue 插件,设置 Ollama 作为本地补全/聊天模型,实现 AI 辅助编程。
7.3 纯前端调用 (JavaScript)
通过 fetch 调用 Ollama API,构建简单的聊天网页。
八、常见问题与排错手册
Q1: 拉取模型时提示 “404 Not Found”
-
原因:模型名称或标签写错,或者未在 ModelScope/HuggingFace 上公开。
-
解决:确认完整路径,例如
modelscope.cn/Jackrong/Qwen3.5-9B-DeepSeek-V4-Flash-GGUF:Q4_K_M。
Q2: 运行时显存不足(CUDA out of memory)
-
解决:更换更低量化版本(如从 Q5_K_M 降到 Q4_K_M);减小
num_ctx;使用--num-gpu部分层加速;增加系统虚拟内存。
Q3: 多模态图片输入无响应或识别错误
-
检查:是否下载了
mmproj.gguf且与主模型版本匹配;图片格式是否为 JPEG/PNG;是否在 API 请求中正确传递 base64 编码。
Q4: Windows 下 ollama 服务自动停止
-
排查:查看事件查看器 → Windows 日志 → 应用程序;检查是否有杀毒软件拦截;尝试以管理员权限运行
ollama serve。
Q5: 如何完全卸载 Ollama?
-
步骤:停止服务 → 删除安装目录 → 删除
%USERPROFILE%\.ollama→ 删除注册表项HKEY_LOCAL_MACHINE\SOFTWARE\Ollama。
九、总结与展望
本文详细记录了在 Windows 环境下使用 Ollama 部署 Qwen3.5 多模态大模型的完整流程,从安装、模型量化选择、交互测试到 API 集成,覆盖了个人开发者与企业边缘计算场景的核心需求。通过合理选择 GGUF 量化级别,即使仅拥有 8GB 显存的普通游戏显卡也能流畅运行 9B 级别的模型,推理质量接近原始 BF16 模型。
未来,随着 Ollama 对更多硬件(如 Intel Arc、AMD ROCm)的原生支持,以及量化技术(如 GPTQ、AWQ)的持续演进,本地大模型将真正成为每个工程师桌面上的标配工具。建议读者在实际项目中从 Q4_K_M 起步,逐步探索适合自身业务场景的精度与速度平衡点。
下一步学习路径:
-
尝试微调自己的 GGUF 模型(使用 llama.cpp 或 mlx);
-
结合 LangChain 构建本地 RAG 知识库;
-
部署多模型混合推理(Embedding + LLM)的智能体。
参考文献
[1] Ollama Official Documentation. https://github.com/ollama/ollama
[2] GGUF Specification. https://github.com/ggerganov/llama.cpp/blob/master/gguf-py/README.md
[3] ModelScope GGUF Repository. Qwen3.5-9B-DeepSeek-V4-Flash-GGUF
[4] Qwen Technical Report. [2309.16609] Qwen Technical Report
[5] TheBloke’s GGUF Guide. https://huggingface.co/TheBloke
附录:一键启动脚本(Windows 批处理)
batch
@echo off set OLLAMA_MODELS=D:\ollama_models set OLLAMA_HOST=0.0.0.0:11434 start /B ollama serve timeout /t 3 ollama run qwen3.5:9b-q5_k_m
将上述内容保存为 start_ollama.bat,双击即可启动服务并进入交互界面。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)