
【AI大模型应用系统开发特训笔记】第05讲:AI大模型端侧部署实战
目录
1.3.1 奠基期(2017-2019):架构革命与双峰并立
1.3.2 爆发期(2020-2022):规模定律与ChatGPT横空出世
1.3.3 成熟与竞争期(2023-2025):多模并起与推理突破
2.7.1 智能体(Agent):从“回答问题”到“自主执行”
第五章:个人部署实战 — 基于 Ollama 本地运行 DeepSeek
5.1.2 排查“nvidia-smi: command not found”错误
5.2.2 第二步:安装 Ollama 并拉取 DeepSeek 模型
5.6 Windows + WSL2 环境下 NVIDIA 显卡支持
第六章:企业级生产环境部署方案 — 基于 vLLM 和 Docker / Kubernetes
6.3 第二步:单机生产部署 - Docker Compose 方案
6.3.5 Nginx 配置:TLS + API Key 认证 + 限流 + 并发管控
6.4 第三步:多机集群生产部署 - Kubernetes 方案
6.4.5 Ingress 配置:TLS + 限流 + 并发管控
6.6.2 K8s 环境日志方案(Filebeat + Elasticsearch)
第一章 AI大模型简介与发展历程
1.1 什么是AI大模型?
大语言模型(Large Language Model, LLM) 是一种通过海量文本数据训练的超大规模深度学习模型。其本质是一种基于神经网络的语言概率模型——给定前文,预测下一个Token(词元)出现的概率分布。底层架构依赖于2017年提出的 Transformer神经网络,这是一组由自注意力机制驱动的新型网络结构,由编码器和解码器组成,能够从大规模文本中提取深层语义并理解词与词、短语与短语之间的关系。
通俗地说,大语言模型就像一个“超级阅读者”:它通过阅读整个互联网级别的文本—网页、书籍、论文、代码—学会了语言的统计规律和推理模式。当你向它提问时,它不是在检索数据库,而是根据学到的“语言知识”,逐字逐句地预测出最合理的回答。
大模型的核心能力可以从六个维度来理解:
|
能力维度 |
核心表现 |
通俗理解 |
|---|---|---|
|
上下文理解 |
基于Transformer注意力机制,实现长距离依赖建模和复杂语义推理 |
像阅读高手,能同时记住整篇文档的前后逻辑,精准把握每一段的含义 |
|
常识与知识 |
从海量训练数据(网页、书籍、论文)中压缩存储大量世界知识和常识 |
像博览群书的人,脑中储存了各领域的背景信息 |
|
逻辑推理 |
推演因果关系、解决数学问题、分析多层次矛盾 |
像侦探,能根据线索推出未知结论;近年的推理模型更可展示完整解题步骤 |
|
生成与表达 |
以流畅、连贯的风格生成文本,支持写作、翻译、总结、改写等任务 |
像文字高手,可按需求创作不同风格的内容 |
|
多模态交互 |
现代LLM已突破纯文本限制,通过集成视觉编码器(如CLIP架构)实现图文跨模态理解 |
如 |
|
Agent自主执行 |
自主规划多步骤任务,如搜索网页、运行代码、调用API、管理文件等 |
像一位数字员工,可以独立完成一整套工作流程 |
概念辨析:大语言模型(LLM)是大模型中最具代表性的分支,除此之外,大模型还包括视觉大模型、多模态大模型等。日常语境中的“AI大模型”,大多数情况下指向的是以Transformer为基础架构、经过海量数据预训练的大语言模型。--> 统称【基础模型】
1.2 为什么大模型如此重要?
大模型的出现,标志着人工智能从“专用工具”向“通用能力”的范式转变。在ChatGPT出现之前,AI更多是小模型时代的“单打独斗”——手写识别、语音助手等场景下用一个小模型解决一个具体问题,每个新任务都需要从零开始收集数据、训练模型。而大模型凭借三方面的突破,彻底改变了这一局面:
突破一:一次训练,全场景复用
与以往每个新任务都需要收集数据、重新训练的“专用模型”不同,大模型凭借其庞大的参数量和预训练数据,具备了极强的泛化能力和涌现能力——即模型规模突破一定阈值后,会出现小模型不具备的复杂能力(如思维链推理、上下文学习)。这一现象俗称“大力出奇迹”,也正是“大”模型区别于“小”模型的根本特征所在。
突破二:自然语言即界面
用户不再需要编写代码或操作复杂软件来下达指令,而是可以直接用自然语言与模型交互,获得符合预期的回应。这极大降低了AI应用的开发门槛,催生了从个人开发者到企业组织广泛参与的应用生态。
突破三:长期的技术积累
大模型并非凭空出现——从2017年Transformer架构奠基,到BERT/GPT确立预训练范式,再到GPT-3展示少样本、零样本学习能力,直到ChatGPT引爆大众认知,背后有着长达数年的技术演进和工程优化历程。
2022年11月30日,OpenAI正式推出ChatGPT。这不是一场精心策划的产品发布会,而是一条简短的推特公告。但仅仅5天后,ChatGPT的用户数就突破100万;两个月后,月活用户突破1亿。英伟达CEO黄仁勋将这一刻称为AI的“iPhone时刻” — 一个由实验室技术走向亿级消费市场、改变整个人类与技术互动关系的转折点。
同年,国内也拉开了“百模大战”的序幕。据统计,截至2024年4月底,国内共推出了305个大模型,覆盖语言理解、图像识别等多个领域。AI大模型在全球范围内开始从实验室走向产业。
1.3 大模型的发展历程
1.3.1 奠基期(2017-2019):架构革命与双峰并立
大模型时代的原点可以追溯到2017年。这一年,Google团队在《Attention Is All You Need》论文中首次提出了Transformer架构,其核心创新—自注意力机制—彻底颠覆了传统序列建模方式。通过Q(Query)、K(Key)、V(Value)矩阵计算,模型可以同时关注输入序列中所有位置的信息,实现并行化的全局依赖捕捉。
通俗理解Transformer与自注意力:可以把自注意力想象成阅读一段文字时大脑的工作机制——当你读到“他”这个字,大脑会自动回顾上下文去判断“他”指的是谁(张三?李四?)。
Transformer让模型也能做到这一点:每个词都会“关注”句子中的其他所有词,计算出“与谁最相关”,从而精准理解语境。这套架构使得模型的参数量可以突破十亿级门槛,是后续所有大模型的技术基石。
2018年,Google发布了BERT(Bidirectional Encoder Representations from Transformers),通过掩码语言模型(MLM)和下一句预测(NSP)两大任务,在GLUE基准测试中以80.5%的准确率超越人类水平,推动NLP进入“预训练 + 微调”时代。
同年,OpenAI发布了GPT-1,这是首个生成式预训练Transformer模型,参数量仅1.17亿,训练数据来自BookCorpus(约4.5GB)。GPT-1开创性地证明了:一个模型用无标注文本训练后,可以微调适配各种下游任务——在2018年,这本身就是一个突破性的里程碑。
2019年,OpenAI扩充至15亿参数,推出了GPT-2。它展示了惊人的零样本学习能力(无需专门训练即可完成新任务),其文本生成质量甚至让OpenAI一度担心被滥用于制造虚假信息而推迟发布完整模型。
1.3.2 爆发期(2020-2022):规模定律与ChatGPT横空出世
2020年,OpenAI推出了当时最大的语言模型——GPT-3,参数量高达1750亿。GPT-3展示了强大的上下文学习能力,仅通过少量示例就能完成翻译、写作、代码生成等复杂任务,并将“LLM”这一术语带入大众视野。
2022年11月30日,OpenAI正式推出ChatGPT——基于GPT-3.5并通过监督微调(SFT)和基于人类反馈的强化学习(RLHF)进行对话优化。仅仅5天用户突破100万,两个月后月活用户达到1亿,成为史上增长最快的消费级应用。这一事件被称为AI的“iPhone时刻”,标志着大模型从前沿实验室技术正式进入大众市场。
1.3.3 成熟与竞争期(2023-2025):多模并起与推理突破
2023年3月,OpenAI发布GPT-4。GPT-4在模拟律师考试中进入前10%,在多项标准化考试中接近人类顶尖水平,标志着大模型在专业领域的可靠性和推理能力上实现了质的飞跃。
2023-2025年间,多模态大模型成为主流方向。GPT-4o集成了文本、图像、音频的端到端处理能力,Claude和Gemini相继实现百万Token级上下文窗口,模型的应用边界被大幅拓宽。
这三年间,大模型领域形成了“海外三大巨头+中国百模大战”的激烈竞争格局(详见1.5节)。以Llama为代表的开源模型全面崛起,以DeepSeek-R1和OpenAI o1为代表的推理模型(Reasoning Model) 取得突破,赋予LLM接近人类“系统2思维”的深度推理能力,标志着AI向模拟人类思维模式迈出了重要一步。
1.3.4 最新进展与前沿趋势(截至2026年5月)
2025-2026年,大模型发展进入超快迭代期。OpenAI在18个月内发布的模型数量超过此前3年的总和,GPT-5系列持续迭代至GPT-5.4(2026年3月),GPT-5.5于4月24日正式发布,5月5日又推出GPT-5.5 Instant,定位为“面向真实工作的全新智能形态”,代表了从基础模型到可用智能体助手的重大转变。
DeepSeek在2024年底至2026年间完成了从V3到R1再到V4的三级跳。其中2025年1月发布的R1推理模型引爆全球市场关注,其“高性价比+开源权重”的策略深刻冲击了业界格局。2026年4月24日,DeepSeek V4正式发布,总参数达1.6万亿,激活参数490亿,标配100万Token超长上下文,并首次与华为昇腾芯片完成深度适配,在推理端实现了重要的国产化突破。
Meta则在2026年4月宣布Muse Spark作为Llama家族的继承者,标志着大模型代际更迭正在加速。此外,阿里、腾讯、字节跳动等国内厂商持续迭代旗下模型,国产大模型阵营已形成包括DeepSeek、通义千问Qwen、智谱GLM、腾讯混元、字节豆包、MiniMax在内的多元化竞争格局。
1.4 大模型发展的关键里程碑时间线
|
时间 |
事件 |
简要说明 |
|---|---|---|
|
2017年6月 |
Google发布Transformer |
通过自注意力机制彻底革新NLP技术,成为所有LLM的架构基础 |
|
2018年6月 |
OpenAI发布GPT-1 |
首个生成式预训练Transformer模型,1.17亿参数 |
|
2018年10月 |
Google发布BERT |
革命性双向编码器模型,在GLUE基准上以80.5%超越人类表现 |
|
2019年2月 |
OpenAI发布GPT-2 |
15亿参数,展示强大零样本生成能力,因安全顾虑推迟完整发布 |
|
2019年3月 |
百度发布ERNIE 1.0 |
国内最早的预训练模型探索,为后续文心一言奠定基础 |
|
2020年6月 |
OpenAI发布GPT-3 |
1750亿参数,引入上下文学习,奠定LLM商业化的能力基础 |
|
2021年1月 |
OpenAI发布DALL·E |
首个基于Transformer的文本到图像生成模型,开创AI绘画先河 |
|
2021年4月 |
华为发布盘古大模型 |
聚焦行业场景,定位“不作诗只做事” |
|
2022年4月 |
Google发布PaLM |
5400亿参数,采用创新的Pathways训练方法 |
|
2022年11月 |
OpenAI发布ChatGPT |
基于GPT-3.5通过RLHF对齐优化,5天破百万用户,引爆全球AI热潮 |
|
2023年3月16日 |
百度发布“文心一言” |
打响国内“百模大战”第一枪,标志着国内大模型竞赛正式开启 |
|
2023年3月 |
OpenAI发布GPT-4 |
多模态能力重大突破,在律师考试中进入前10% |
|
2023年4月11日 |
阿里发布“通义千问” |
阿里版GPT,支持多轮对话、代码编程、文案创作 |
|
2023年7月7日 |
华为发布盘古大模型3.0 |
深耕政务、金融、制造、煤矿等价值场景 |
|
2023年7月 |
Meta发布Llama 2 |
开源可商用,包含7B/13B/70B版本,引爆企业私有化部署浪潮 |
|
2023年9月 |
腾讯混元/科大讯飞星火陆续备案上线 |
国内首批备案的大模型,标志着合规化进程加速 |
|
2024年4月 |
Meta发布Llama 3 |
8B/70B/405B多版本,训练数据15万亿Token,8B版性能超Llama 2 70B |
|
2024年5月 |
OpenAI发布GPT-4o |
端到端多模态,实时音频与视觉处理 |
|
2024年12月 |
DeepSeek发布V3 |
671B MoE架构,训练成本仅为同类产品的1/10,引发全球关注 |
|
2025年1月 |
DeepSeek发布R1 |
开源推理模型,低成本+高性能震撼全球市场 |
|
2025年4月 |
Meta发布Llama 4 |
全面转向MoE架构,原生多模态,Scout模型支持1000万Token上下文 |
|
2025年8月 |
OpenAI发布GPT-5 |
多模态理解新高度,Agent能力实质性突破 |
|
2026年2月 |
科大讯飞发布星火X2 |
基于全国产算力训练,单台国产昇腾服务器部署 |
|
2026年2月 |
智谱GLM-5/字节豆包2.0发布 |
国内模型矩阵进一步扩充 |
|
2026年3月 |
OpenAI发布GPT-5.4 |
整合推理、编程和Agent工作流的统一前沿模型 |
|
2026年4月 |
OpenAI发布GPT-5.5 |
定位为“面向真实工作的全新智能形态”,长任务执行能力 |
|
2026年4月 |
DeepSeek发布V4 |
1.6T总参数,标配1M上下文,与华为昇腾深度适配 |
|
2026年4月 |
Meta宣布Muse Spark |
Llama家族代际更新,细节待公布 |
|
2026年5月 |
OpenAI发布GPT-5.5 Instant |
ChatGPT免费默认模型,幻觉错误减少52.5% |
|
2026年5月 |
阿里发布Qwen3.8-27B |
270亿参数稠密多模态模型,Agentic Coding能力突出 |
|
2026年5月 |
Google Gemini 2.5 Pro (06-05) |
上下文窗口扩展至百万Token级,“Deep Think”模式达到IMO金牌水平 |
1.5 大模型发展的趋势特征与关键洞察
纵览大模型短短八年的发展历程,可以提炼出以下核心趋势:
趋势一:规模定律与效率革命的博弈。从GPT-1的1.17亿参数到GPT-4的数万亿参数,再到DeepSeek V4的1.6万亿MoE,模型参数量经历了数十万倍的增长。但单纯的“堆参数”已不是唯一路径——量化压缩、MoE稀疏激活、动态路由等技术使大模型在保持能力的同时大幅降低部署成本。
趋势二:从文本到多模态的感知融合。2018年的模型只能处理纯文本;2023年的GPT-4实现了图文混合理解;2024年的GPT-4o和Gemini进一步整合了视觉、音频和语音能力;2025年的Llama 4实现了原生多模态涵盖文本、图像、音频和视频。大模型正从单一模态走向全感知融合。
趋势三:从“生成模型”到“推理模型”再到“Agent”的智能跃迁。早期的GPT专注于文本生成;2025年DeepSeek-R1和OpenAI o1的推理模型实现了深度思考能力的突破;2026年的GPT-5.5被定位为“面向真实工作的全新智能形态”,具备自主规划、工具调用、跨工具协作等Agent核心能力。这意味着大模型正在从信息工具进化为行动系统——不仅能回答问题,还能自主执行任务。
趋势四:开源与闭源的生态分化与融合。OpenAI、Anthropic坚持闭源迭代,Meta的Llama系列和DeepSeek则构建了开源生态的标杆。DeepSeek R1的开源发布直接挑战了传统AI行业规范,证明了开源模型可以与顶尖闭源模型正面竞争。
趋势五:国产模型的崛起之路。从2023年初的“百模大战”仓促应战,到2025年DeepSeek R1以“高性价比+开源”震撼全球市场,再到2026年DeepSeek V4实现国产化算力深度适配。三年间,中国大模型完成了从追赶者到竞争者的角色转变。
趋势六:长上下文成为“新标配”。2023年模型的上下文窗口仅为2K-8K Token;2025-2026年,百万Token级别上下文窗口已在主流模型中普及——Llama 4 Scout甚至支持1000万Token的超长上下文。这意味着模型可以一次性处理整本长篇著作,应用场景从短问答拓展到深度文档分析和跨文档综合推理。
1.6 发展趋势与产业影响
截至2026年5月,AI大模型已从单点技术突破走向生态化、产业化、国产化的全方位竞争。
在技术层面,大模型的核心竞争维度正在从“谁更强”转向“谁能更稳定、更便宜地大规模交付”。DeepSeek V4延续其“效率路线”,通过Pro和Flash两版本分别对标高端推理场景和高频调用场景,表明了头部厂商对成本与能力双重维度的精细化运营。
在产业层面,大模型正在从“聊天工具”进化为“数字员工”。无论是GPT-5.5的长任务执行、Sonnet 4.6的Agent理想基座定位,还是DeepSeek V4在Agentic Coding上的开源领先,均表明Agent能力是2026年大模型竞争的第一焦点——模型的价值正从“答得好不好”转向“能不能自主把事情做成”。
在生态层面,开源与闭源模型之间的能力差距正在持续缩小。Llama 4完善了开源生态建设,DeepSeek V4与Qwen3.8等国内模型在智能体编程和推理评测中甚至超越部分同级别的商用模型。企业在模型选型时,成本效益、数据安全和国产化部署等非技术因素正占据越来越重要的决策权重。
在应用层面,无论选择云端API还是私有化部署,大模型本地部署的门槛正被持续压降。预量化模型(GGUF格式)使7B模型在一张消费级显卡上即可流畅运行,为大模型的普及化应用扫清了障碍。
对于即将投入大模型应用开发的从业者来说,理解这些技术演进脉络和当前竞争格局,不仅有助于把握行业趋势,更能为后续的技术选型、成本评估和架构设计提供坚实的知识基础。
第二章:AI大模型的应用场景
2.1 从“通用聊天”到“千行百业”:应用格局全景
当前,人工智能应用已覆盖钢铁、有色金属、电力、通信等重点行业,逐渐深入到产品研发、质量检测、客户服务等重点环节。2025年,广东人工智能核心产业规模已突破3000亿元,在制造、教育、医疗、文旅等领域累计发布3个批次共计78类应用场景清单。同年,广东省集中发布了覆盖AI+科技、制造、政务、民生、农业、医疗、教育、金融、出海等十余个行业的23个典型案例,系统勾勒出人工智能赋能千行百业的生动图景。麦肯锡2025年AI全球调查报告显示,全球已有88%的企业在至少一个业务职能中使用AI,但真正实现企业级规模化落地的仅占约三分之一。大模型应用正在从“概念验证”走向“规模化落地”。
经过大量落地实践的验证,可以归纳出AI在不同行业应用的三个共性规律:一是从高频重复场景切入,客服应答、文档处理、质量检测、数据分析等场景投入产出比高、验证周期短;二是数据质量决定AI上限,数字化程度高、历史数据积累充足的企业往往能在AI应用中更快获得回报;三是组织变革是成功的关键变量,AI高绩效企业中超过三分之一的高层管理者亲自主导AI项目并主动在日常工作中使用AI工具。
本章将从AI大模型的核心能力维度与典型行业落地两大视角出发,系统梳理大模型在2025-2026年的应用全景。具体而言,2.2节从文本生成、对话交互、多模态理解、代码生成等通用能力维度出发,阐述这些能力如何转化为具体的应用场景;2.3-2.6节分别深入制造、金融、医疗、教育四大重点行业,解析大模型在各行业的典型落地案例;2.7节聚焦Agent(智能体)、RAG(检索增强生成)、端侧推理三大关键应用架构,梳理其技术特点与行业应用价值;最后2.8节提供场景选择与落地的实用框架。
2.2 按核心能力划分的通用应用场景
大模型的应用场景,首先可以从其核心能力维度来理解。当前,主流大模型在文本生成与理解、对话交互、多模态理解与生成、代码生成、知识推理与决策、数据与搜索增强等方面展现出强大的通用能力,这些能力构成了各行业场景应用的底层基础。
2.2.1 文本生成与理解
文本生成与理解是大模型最基础、最成熟的能力,也是覆盖场景最广泛的维度。主要包括:
-
文档与报告生成:自动撰写商业报告、会议纪要、新闻稿件、法律文书等结构化文档。在金融领域,大模型可自动解析财报、新闻与研报,生成多维度投资观点与风险提示,辅助分析师效率提升40%以上。
-
内容创作与辅助:包括文案撰写、创意策划、翻译润色、社交媒体内容生成等。在文教传媒领域,AI已深度渗透到内容生产的全流程。
-
摘要与信息提取:从长文档中自动提取关键信息、生成摘要,广泛应用于法务审查、学术文献综述等场景。某基金公司的大模型投研系统,将单只股票的研究时间从72小时缩短至8小时。
2.2.2 对话交互与智能客服
对话交互能力使大模型成为智能客服的核心引擎,这是当前大模型在企业中落地最广泛、投入产出比最高的场景之一。
-
智能客服:基于RAG(检索增强生成)技术,大模型可基于企业知识库提供精准的问答服务。RAG通过“检索-增强-生成”三阶段解决大模型知识时效性问题:检索层构建向量数据库存储结构化与非结构化文档;增强层采用BM25+语义混合检索确保高相关度内容召回;生成层结合检索上下文与LLM生成精准回答。某金融企业实践表明,RAG使大模型在专业领域的回答准确率从58%提升至89%。
-
多轮对话与业务办理:结合Function Calling(函数调用)技术,大模型不仅能回答问题,还能调用外部API完成订单查询、退换货处理等实际操作。太平保险等机构部署大模型坐席后,客户满意度提升25%,人力成本显著优化。
2.2.3 多模态理解与生成
多模态大模型能够同时处理文本、图像、音频、视频等多种数据类型,实现跨模态的理解与生成。2025年,多模态大模型不再满足于“看懂”世界,而是通过视觉-语言-动作(VLA)的深度融合,实现从感知到决策的闭环。
-
视觉识别与质检:在工业制造场景中,大模型可实时识别产品缺陷、零件型号,自动调整检测策略。美的顺德灯塔工厂的AI视觉检测系统,通过AI眼镜辅助工人实现市场问题、首检历史数据的易错点提醒,首检效率由原来的15分钟缩短至30秒。思谋科技依托全球首个工业多模态大模型IndustryGPT,研发出面向精密制造的智能检测机器人,可对复杂材料、曲面及微米级组件进行高精度自动化质量检测。
-
文档理解与解析:多模态模型可直接“阅读”扫描件、PDF、表格等复杂格式文档,自动提取关键字段和结构化信息,广泛用于金融票据识别、合同审查等场景。
-
视频分析:对监控视频、会议录像进行智能分析,提取关键事件和异常行为。商汤方舟平台已深入城市安全、交通、制造、无人机巡逻、具身智能等十余类关键场景,服务海内外近200个城市。
2.2.4 代码生成与软件开发
代码生成是AI大模型增长最快的应用领域之一。大模型可以辅助完成代码补全、Bug修复、代码审查、测试用例生成、技术文档编写等软件开发全流程任务。以通义千问Qwen3.8-27B为代表的新一代模型在Agentic Coding(智能体辅助编程)场景表现突出,大幅提升了开发者生产力。
2.2.5 知识推理与决策支持
大模型能够从海量数据中提取规律、进行逻辑推理并生成决策建议,包括:
-
投研分析与金融决策:大模型自动解析研报、财报及行业数据,生成包含投资逻辑链的分析报告。结合图神经网络(GNN)与大模型,某支付平台通过动态关联用户行为、设备指纹及社交关系,将欺诈交易拦截率提升至99.9%。
-
医疗辅助决策:基于患者病历、影像数据和医学知识库,大模型可辅助医生制定个性化治疗方案。三六三医院通过整合电子病历等临床数据与用药知识库,将DeepSeek模型融入门诊和住院医生工作站,每天有100多名医生在使用该模型进行辅助诊疗。
-
供应链与物流优化:结合运筹学算法与大模型的推理能力,实现库存预测、路径优化和动态调度。
2.2.6 数据与搜索增强(RAG与联网搜索)
RAG(检索增强生成)是目前企业级应用中最核心的架构模式之一。它通过将大模型与外部知识库(向量数据库、搜索引擎)连接,使模型能够基于最新的、私有的数据生成精准回答。RAG不仅是技术组件,更是一种应用架构范式——企业通过RAG将内部知识资产与大模型的推理能力深度融合,构建起安全可控的智能问答系统。具体架构细节将在2.7.2节展开。
各能力维度的典型应用场景速查:
|
能力维度 |
典型应用场景 |
代表行业 |
|---|---|---|
|
文本生成与理解 |
报告撰写、内容创作、翻译、摘要生成 |
金融、传媒、法律 |
|
对话交互 |
智能客服、语音助手、多轮业务办理 |
全行业 |
|
多模态理解 |
视觉质检、文档识别、视频分析 |
制造、安防、医疗 |
|
代码生成 |
智能编程助手、自动化测试、代码审查 |
软件开发 |
|
知识推理与决策 |
投研分析、医疗诊断、供应链优化 |
金融、医疗、物流 |
|
数据与搜索增强 |
企业知识库问答、合规审查、联网信息检索 |
全行业 |
2.3 制造业:从“自动化”到“智能化”的深度变革
制造业是AI大模型落地的核心战场。当前,AI在制造业的应用已从单点设备检测,升级为覆盖排产、质检、工艺、运维等全流程的“工厂大脑”。以下通过四个维度的典型案例来具体展示。
2.3.1 智能排产与柔性制造
制造业面临的核心挑战之一是“个性化需求”与“规模化生产”之间的矛盾——如何在保持生产效率的同时满足日益增长的定制化订单需求。
-
嘉立创“AI+柔性制造”:针对电子制造海量离散订单“交付慢、成本高”的痛点,嘉立创构建了涵盖智能选型、AI预审、智能排产及供应链预测的“AI+柔性制造”全链路系统。该系统融合多种AI算法破解个性化与规模化生产冲突,日均处理超4万份PCB订单,拼板效率提升百倍以上。该方案已累计服务全球超820万名用户,覆盖AI、新能源、航空航天、机器人等领域及超千所高校和科研机构。
-
酷特智能C2M平台:酷特智能以C2M产业互联网平台为核心,自主研发数据驱动的柔性智造体系,实现“一人一版、7天交付”的大规模个性化定制。核心能力已为50+行业、200+企业提供智能制造升级方案。
2.3.2 智能质检与缺陷检测
质量检测是制造环节中人力消耗最大、对精度要求最高的场景之一,也是AI视觉大模型最先突破的领域。
-
美的智能体工厂:美的洗衣机荆州工厂获得世界纪录认证机构WRCA“世界卓越的首个多场景覆盖的智能体工厂”认证。该工厂14个智能体覆盖了38个核心生产业务场景,以“工厂大脑”进行协同。在质检场景中,工人只需对实物进行拍照,工厂大脑即可自动获取研发系统图纸并进行比对,首检效率由原来的15分钟缩短至30秒。整体实践结果显示,智能体工厂平均提效80%以上,其中排产响应速度提升90%。
-
思谋科技工业质检机器人:依托自研的全球首个工业多模态大模型IndustryGPT,思谋科技研发了面向精密制造的智能检测机器人,广泛应用于消费电子、新能源电池及精密制造领域,可对复杂材料、曲面及微米级组件进行高精度自动化质量检测,并支持跨多条生产线的灵活部署。
-
兴澄特钢AI智能工厂:以“数据驱动、AI赋能”为建设理念,搭建工业互联网平台和智能管控中心,通过100余个垂直模型实现高炉炼铁可视透明化,炉温异常时间减少84.8%,产品检验不合格率下降47.3%,协同效率提升20%、产线产量增长11.5%。
2.3.3 设备预测性维护
设备意外停机是制造业最昂贵的成本之一。AI大模型通过实时分析振动、温度、工况等多维传感器数据,能够提前识别潜在故障并生成维修建议。
-
三一重工液压系统故障诊断:三一重工入选“2025中国AI+应用Top50”的工程机械液压系统AI故障诊断系统,通过深度学习模型对液压系统的运行数据进行实时分析,提前预测故障并推荐维修方案。
-
中车株机“斫轮·匠枢”大模型:依托“斫轮”大模型迭代训练,针对智能排产、调度调优、工艺优化、质量检测等制造核心场景定制训练,可实现生产前“沙盘推演”、过程中“随机应变”、结束后“复盘总结”,同时可化身AI计划员、工艺员、质检员,24小时实时监测生产状态。
2.3.4 工艺优化与知识传承
在流程工业和精密制造领域,工艺参数的优化和老师傅经验的传承是长期难题。
-
宝武钢铁高炉大模型:中国宝武联合华为,以AI大模型破解炼铁高炉这一工业“黑箱”难题。通过AI对高炉内部温度、气流等无法直接测量的关键参数进行实时建模与优化,单座高炉年创效超千万元。
-
张宣科技本地化部署DeepSeek:开发近零碳排放产线质量判定系统等6个数字化模型,实现对生产全过程的质量追溯。目前在线模型使用率同比提升了8%。
-
天智工业大模型:汇聚大规模高质量工业知识库,整合4700余个机理模型、200多项专家算法、110多款智能体开发工具,在家电、能源、石化、机械装备等9大行业落地45个高价值场景。
制造业各环节AI应用速查:
|
制造环节 |
核心能力 |
AI应用方式 |
代表案例 |
|---|---|---|---|
|
研发设计 |
工艺特征识别、知识库检索 |
自动识别三维数模特征,智能生成工艺路线 |
美的工艺设计智能体 |
|
生产排产 |
强化学习、运筹优化 |
动态插单响应、多目标排产优化 |
嘉立创智能排产、美的排产智能体 |
|
质量检测 |
视觉识别、多模态大模型 |
自动缺陷识别、AI辅助首检 |
美的智能体工厂、思谋质检机器人 |
|
设备运维 |
时序预测、异常检测 |
预测性维护、故障归因分析 |
三一重工、中车“斫轮·匠枢” |
|
工艺优化 |
工业机理+大模型 |
参数优化、知识传承 |
宝武高炉大模型、天智工业大模型 |
2.4 金融行业:从“外围辅助”到“核心决策”
金融业是AI大模型应用最活跃、场景覆盖最全面的行业之一。2025年,金融大模型已从概念验证进入规模化落地的深水区,应用从客服、文档等外围场景逐渐向风控、投研等核心领域渗透。
2.4.1 智能投研与分析
智能投研是金融大模型最具技术含量的应用方向,需要模型具备多源信息整合、逻辑推理和结构化输出的综合能力。
-
腾讯云金融AI:腾讯云携手上海证券交易所、深圳证券交易所、中国银行、工商银行、中金公司、太平保险集团等头部金融机构,成功将AI大模型应用于超过100个真实业务场景。在中金公司等机构,大模型可自动解析财报、新闻与研报,生成多维度投资观点与风险提示,辅助分析师效率提升40%以上。同时与上交所合作探索“AI+资本市场监管”,与中金公司共建“智能投研平台”,推动技术从“单点工具”向“系统能力”演进。
-
基金公司投研系统:某基金公司的大模型投研系统,通过自动解析研报、财报及行业数据,生成投资逻辑链,将单只股票的研究时间从72小时缩短至8小时。
2.4.2 智能风控与反欺诈
金融风控的核心挑战是“精准识别、快速响应”。大模型结合图神经网络(GNN)技术,正在重新定义风控的效率天花板。
-
银行实时反欺诈:工行、中行等银行利用AI实时监测交易行为,识别异常模式,反欺诈响应速度提升至秒级。某支付平台通过动态关联用户行为、设备指纹及社交关系,将欺诈交易拦截率提升至99.9%。
-
信贷风险评估:整合企业财报、税务数据及社交行为,大模型预测违约率的AUC值达0.92。某金融机构应用后,坏账率下降37%。
2.4.3 智能客服与营销
金融领域的客服场景对专业性、准确性和合规性要求极高,大模型结合RAG技术正成为标准解决方案。
-
保险智能客服:太平保险等机构部署大模型坐席,支持复杂保单解读与个性化推荐,客户满意度提升25%,人力成本显著优化。
-
私人银行财富管理:基于用户风险偏好、生命周期及市场动态,提供个性化资产配置建议。某私人银行的大模型财富顾问,客户留存率提升40%。
2.4.4 合规与监管科技
-
AI辅助监管:沪深交易所试点AI辅助监管科技(RegTech),自动比对信息披露文件,识别潜在违规线索。某金融科技公司部署合规审查系统后,合规审查效率提升6倍。
金融行业各应用场景速查:
|
场景 |
核心能力 |
典型效果 |
|---|---|---|
|
智能投研 |
多源信息融合、逻辑推理 |
研究时间从72小时缩短至8小时 |
|
智能风控 |
实时异常检测、图神经网络 |
欺诈拦截率达99.9% |
|
智能客服 |
RAG + 多轮对话 |
客户满意度提升25% |
|
信贷审批 |
多维度信用评估 |
审批时效从2天缩短至10分钟 |
|
合规审查 |
自动文档比对 |
审查效率提升6倍 |
2.5 医疗健康:从辅助诊断到全流程智能化
医疗行业的核心痛点在于优质医疗资源的极度稀缺与日益增长的健康需求之间的结构性矛盾。2025年截至5月,国内已发布133个医疗大模型,远超2024年全年的94个和2023年的61个。医疗服务是大模型应用最集中的领域,提及频次占比达53%,其中临床专病辅助决策、预问诊、病历辅助生成、医学影像辅助诊断为四大核心场景。
2.5.1 医学影像智能诊断
AI影像诊断是医疗AI最成熟的落地场景之一。大模型通过解析CT/MRI影像数据,结合电子病历构建三维疾病模型。例如在肺癌筛查中,模型可识别0.5mm级微小结节,准确率达98.7%,较传统方法提升42%。
-
“粤医智影”系统:广东省卫健委和中国联通联合构建了涵盖多类影像识别、智能阅片、报告生成的“AI+影像诊断”全链路系统。该系统覆盖7类影像检查,2秒即可生成诊断报告,准确率达98%,每小时阅片量抵150名医生全天工作量,已于2025年7月全面推广,接入2146家公立医疗机构实现全省基层全覆盖。
2.5.2 临床辅助决策
-
三六三医院DeepSeek本地化部署:通过整合电子病历等临床数据与用药知识库,实现DeepSeek模型本地化部署,并将其融入门诊和住院医生工作站,每天有100多名医生在使用该模型进行辅助诊疗。模型以对话式交互方式为医生提供科学、精准的用药推荐,且不连接外网,最大限度防止患者信息泄露。
-
“医颅大模型”:基于DeepSeek-R1(70B参数)大模型开展医疗迁移学习,在20亿级医学文本预训练基础上,针对16种高发癌种微调。嵌入含2200种诊断规则、210种疾病转化路径的知识图谱,融合NCCN指南与本地200名专科医生经验。
2.5.3 药物研发
AI药物研发正在从“辅助工具”升级为“核心引擎”。大模型结合图神经网络与强化学习,可在72小时内完成传统需要6个月的新药分子设计。清华大学与水木分子联合发布的BioMedGPT-R1模型,在USMLE考试中正确率达67.1%,逼近人类专家水平,助力缩短研发周期。
医疗行业各应用场景速查:
|
场景 |
核心能力 |
典型效果 |
|---|---|---|
|
影像诊断 |
视觉识别 + 医学知识推理 |
肺癌筛查准确率98.7%,2秒生成诊断报告 |
|
辅助诊疗 |
病历解析 + 医学知识检索 |
每天100+医生使用,显著提升诊疗效率 |
|
药物研发 |
分子结构预测 + 强化学习 |
72小时完成传统6个月的分子设计 |
|
健康管理 |
可穿戴数据 + 风险预测 |
疾病控制率提升28% |
2.6 教育行业:从“千人一面”到“因材施教”
教育领域的大模型应用正在改变传统的教学与学习方式。AI打破传统教学“千人一面”“单向灌输”的局限,带来个性化教学、互动课堂、精准评估、资源创新四大黄金应用场景。
2.6.1 个性化学习与自适应教学
-
“AI龙老师”:深圳首个教育AI品牌,一年完成197.2万份作业的学情智能采集与批改,打造7万册“一生一案”个性化学习手册。2025年引入华为盘古大模型,构建全国领先的“AI+教育”先锋城区。教师批改时间从日均90分钟降至20分钟以内,教研与个性化辅导的时间占比从30%跃升至55%。
2.6.2 智能作文批改与人机协作
-
高中议论文批改系统:基于DeepSeek-R1/V3模型与RAG检索增强技术,专门探索高中议论文的人机协作批改与个性化学习指导路径。其核心思路是搭建结构化知识库,涵盖审题指导、素材资源、逻辑谬误库等内容,经向量化处理后存入向量库,同时设计三级提示链辅助教师批改。
-
“AI超拟人老师”:小猿AI学习机T4的“AI超拟人老师”3.0功能,依托自研猿力大模型,融合多模态感知技术、可视化推理技术与动态知识图谱技术,实现了覆盖“听、看、思、答”全链路的类真人老师辅导模式。在整个讲解过程中,学生可以随时插话追问,AI老师能立即响应并基于实时笔迹指出错误。
教育行业各应用场景速查:
|
场景 |
核心能力 |
典型效果 |
|---|---|---|
|
个性化学习 |
学情数据分析 + 自适应推荐 |
7万册个性化手册,因材施教 |
|
智能批改 |
语义理解 + 多维度评分 |
批改效率提升80%,教师教研时间占比翻倍 |
|
虚拟教师 |
多模态感知 + 可视化推理 |
1对1全天候辅导,实时响应插话追问 |
2.7 三大关键应用架构:Agent、RAG与端侧推理
在众多具体的行业应用场景背后,有三类技术架构正在成为大模型企业级落地的核心范式:Agent(智能体)、RAG(检索增强生成)和端侧推理。理解这三种架构的特点和适用场景,是进行技术选型和方案设计的基础。
2.7.1 智能体(Agent):从“回答问题”到“自主执行”
AI Agent(智能体)是2025年企业级AI应用中增长最快的范式。不同于传统RPA(机器人流程自动化)或基础聊天机器人,企业级AI Agent具备三大核心特征:自主决策能力、跨系统协同能力和持续进化机制。
在企业办公领域,钉钉于2025年推出了全球首个为AI打造的工作智能操作系统AgentOS,其核心理念是调度“智能体”——那些能自主理解任务、调用工具、执行操作并持续学习的AI代理。钉钉已推出超过20款AI新品,覆盖订单处理、质检、排产等制造业核心场景。IBM也发布了通用型企业级智能体(IBM CUGA),能够跨多个业务场景执行复杂任务。壹沓科技打造的“小沓AI Agent数字员工平台”则专注于供应链领域,已成功赋能近2000家企业客户,推动企业运营向更智能、更高效的方向演进。
在制造、金融、医疗三大核心领域,Agent的应用成效尤为显著:
-
制造业:某制造业企业部署的采购Agent可自动分析库存数据、供应商报价及历史交付记录,生成最优采购方案。美的工厂通过14个智能体覆盖38个核心生产场景,平均提效80%以上。
-
金融业:某银行信贷审批Agent通过API对接征信系统、企业工商数据库及内部风控模型,将审批时效从72小时压缩至15分钟。
-
医疗健康:某三甲医院AI Agent对罕见病诊断准确率达89%,应用于辅助诊断、药物研发及患者管理。
2.7.2 检索增强生成(RAG):企业知识库的智能引擎
RAG是当前企业级AI应用中落地最广泛的技术架构之一。从技术原理看,RAG通过“检索-增强-生成”三阶段解决大模型的知识时效性与私有化问题:检索层构建向量数据库存储知识;增强层通过混合检索确保高相关度内容召回;生成层结合检索上下文与LLM生成精准回答。
RAG在实际应用中已覆盖多个领域:
-
智能客服:通过RAG技术实现基于企业内部知识库的精准问答,客服效率可提升3倍。
-
企业知识管理:打破传统知识库的功能局限,提供知识全生命周期管理、全域搜索、AI问答、智能推荐等服务,让企业知识资产真正“活”起来。
-
数据库运维:RAG技术应用于数据库运维场景,通过知识库构建、精准问答实现与自动化运维流程结合,提升故障处理效率与准确性。
-
文档问答:企业可通过RAG为员工提供个性化的信息服务,解答各种工作相关问题,提高工作效率和员工满意度。
2.7.3 端侧推理:离线、低延迟与数据安全
端侧推理是AI大模型从云端走向终端的必然趋势。通过模型量化、剪枝、蒸馏等压缩技术,将大模型部署到手机、汽车、机器人等边缘设备上,实现离线可用、毫秒级响应和数据完全本地的推理。
端侧大模型的核心优势在于:低延迟(毫秒级,远优于云端的秒级响应)、离线可用(无需网络连接)、保护隐私(数据完全本地处理,不出设备)。这使其在智能座舱、工业质检、安防摄像头、个人手机助手等场景中具有不可替代的价值。以自动驾驶为例,多模态大模型可在车端实时识别交通标志、预测路况风险、生成变道策略,最终输出油门/刹车指令,实现从感知到决策的完整端侧闭环。
2.8 行业应用总结与场景选择框架
综合本章所述的各行业实践,不同行业对AI大模型的需求本质差异显著:医疗行业的核心是“准确性与合规性”,制造业的核心是“效能与质量”,金融行业的核心是“效率与风控”,教育行业的核心是“个性化与普惠化”。不同行业的“第一性原理”不同,AI的切入点自然也不同。
2.8.1 各行业应用汇总
|
行业 |
核心需求 |
典型应用场景 |
代表案例 |
|---|---|---|---|
|
制造业 |
降本、提质、增效 |
智能质检、预测性维护、工艺优化、柔性排产 |
美的智能体工厂、嘉立创柔性制造、兴澄特钢智能工厂 |
|
金融 |
效率提升、风险可控、合规安全 |
智能投研、实时反欺诈、信贷审批、合规审查 |
腾讯云金融AI百场景落地、中金投研系统 |
|
医疗 |
准确性、安全性、合规性 |
影像诊断、辅助诊疗、药物研发、健康管理 |
“粤医智影”系统、三六三医院DeepSeek部署、“医颅大模型” |
|
教育 |
个性化、普惠化、赋能教师 |
自适应学习、智能批改、虚拟教师 |
深圳“AI龙老师”、小猿“AI超拟人老师” |
|
企业服务 |
提效、降本、知识管理 |
智能客服、RAG知识库、文档自动化 |
FastGPT RAG智能问答、AI Agent数字员工 |
2.8.2 场景选择框架:企业如何找到“第一场景”
对于计划落地AI大模型的企业,建议采用“影响度-可行性”双维度评估模型来选择切入场景:
(1)高影响度+高可行性的场景(优先切入):如智能客服、文档处理、质量检测等。这类场景数据基础好、业务价值清晰、技术方案成熟,投入产出比高,验证周期短。
(2)高影响度+低可行性的场景(长期布局):如战略决策支持、全自动药物研发等。这类场景虽然价值巨大,但技术难度高、风险大,需要长期投入。
(3)低影响度+高可行性的场景(快速验证):如内部知识库问答、会议纪要生成等。这类场景风险低,适合团队积累AI落地经验。
企业在选择切入场景时,建议优先考虑三个标准:一是该场景已有可参考的成功案例(降低不确定性);二是企业在此场景已有充足的数据积累(降低数据准备成本);三是该场景的业务价值可以被量化衡量(便于评估ROI)。
2.8.3 落地建议
对于AI应用开发工程师而言,理解应用场景的最终目的是能够在实际项目中将业务需求转化为技术方案。建议在学习和实践中重点关注以下几点:
(1)以业务痛点而非技术热点驱动:选择场景时首先问“这个场景解决了什么业务问题”,而非“这个技术很新我要用它”。
(2)从RAG起步,向Agent进阶:对于大多数企业而言,基于RAG的智能问答是门槛最低、见效最快的AI落地方式;随着业务复杂度提升和团队经验积累,再逐步引入Agent实现更复杂的自主决策。
(3)重视数据基础建设:无论选择哪个行业、哪种架构,数据质量始终是决定AI应用效果上限的关键变量。在项目启动前,务必评估企业是否已具备足够的、高质量的业务数据。
(4)关注合规与安全:尤其在金融、医疗等强监管行业,数据安全、模型可解释性和合规审计是AI落地的硬性前提,不能等上线后再补救。
企业普遍应用的AI落地节奏通常是“从RAG起步(知识库问答、智能客服),向Agent进阶(自主决策、跨系统协同),同时评估端侧部署需求(低延迟、离线场景)”。掌握这些关键架构的应用特点与适用场景,是进行企业级AI方案设计和技术选型的核心能力。
第三章 大模型本地部署方案:从个人实验到企业级生产环境
3.1 引言
在第一章中,我们系统梳理了截至2026年5月全球主流AI大模型的技术版图。无论选择哪款模型,下一步的核心问题都是:如何将它部署到实际环境中,让它真正跑起来?
这就是本章要回答的问题。大模型的本地部署,并非简单“下载一个软件,双击安装”就能完成。它涉及硬件选型、量化策略、推理框架、多卡调度、安全加固等一系列技术决策。个人开发者在一张RTX 4090上跑通7B模型,与企业级团队在8卡H100集群上部署服务,其技术路径和成本结构截然不同。
本章从个人和企业两个视角切入,系统讲解大模型本地部署的完整技术栈、硬件选型、部署工具对比和实战操作,并为不同预算和技术水平的用户提供切实可行的方案。
3.2 部署框架全景图:四大主流方案速览
在深入具体部署流程之前,首先建立对主流部署工具的全局认知。当前(截至2026年5月),大模型本地部署领域形成了四大主流框架,分别面向不同的使用场景和技术需求:
|
框架 |
定位 |
一句话总结 |
代表用户 |
|---|---|---|---|
|
Ollama |
本地快速体验 |
“模型应用商店”,一行命令下载并运行模型 |
个人开发者、AI爱好者 |
|
llama.cpp |
极致硬件优化 |
纯C++高性能引擎,能在树莓派上跑7B模型 |
低配设备、边缘计算 |
|
vLLM |
企业级高并发服务 |
PagedAttention + 连续批处理,吞吐量提升可达24倍 |
企业API服务、生产环境 |
|
LM Studio |
图形化模型管理 |
桌面端GUI,像安装软件一样部署模型 |
非技术背景用户 |
3.2.1 框架核心定位对比
这四大框架并非竞争关系,而是各自专注于大模型部署生命周期的不同阶段:
-
Ollama 解决“好不好上手”的问题:它将模型下载、环境配置、量化加载全部封装在一条命令中,让开发者在几分钟内即可在本地运行大模型。但它不是为
高并发设计的——当并发请求量上升时,Ollama的性能会急剧下降。 -
llama.cpp 解决“能不能跑”的问题:当硬件条件极端受限时(老旧笔记本、工控机、甚至树莓派),llama.cpp通过AVX2/NEON指令集加速、内存映射优化等技术,将大模型的硬件门槛降到最低。
-
vLLM 解决“能跑多少”的问题:当需要为上百个用户同时提供推理服务时,vLLM的PagedAttention技术能减少78%的显存碎片,连续批处理将GPU利用率提升至90%以上,是生产环境的事实标准。
-
LM Studio 解决“要不要学命令行”的问题:为不熟悉终端的用户提供图形化操作界面,支持模型下载、参数配置、聊天测试全流程可视化操作。
3.2.2 技术特性与硬件需求一览
|
对比维度 |
Ollama |
llama.cpp |
vLLM |
LM Studio |
|---|---|---|---|---|
|
开发语言 |
Go |
C++ |
Python |
Electron(JS) |
|
核心优势 |
开箱即用、模型市场 |
CPU极致优化、内存占用低 |
高并发、PagedAttention |
图形界面、零命令行 |
|
量化支持 |
GGUF(Q4_K_M等) |
GGUF全系列 |
AWQ、GPTQ、FP8 |
GGUF |
|
并发能力 |
单请求为主 |
低并发 |
极高(支持256+并发) |
单请求为主 |
|
API兼容 |
OpenAI兼容 |
OpenAI兼容 |
OpenAI兼容 |
OpenAI兼容 |
|
GPU加速 |
支持(自动检测) |
CUDA/OpenCL |
深度GPU优化 |
支持 |
|
适用模型规模 |
7B–70B(量化后) |
7B–70B(量化后) |
7B–671B(多卡并行) |
7B–70B(量化后) |
|
最低硬件要求 |
8GB内存 |
4GB内存 |
16GB显存(单卡) |
8GB内存 |
在性能表现上,基准测试显示llama.cpp在低配设备上的推理速度比Ollama快约10%至20%,具有更好的性能和可配置性;而vLLM凭借PagedAttention内存管理、连续批处理等核心技术,在GPU服务器上的吞吐量相比传统HuggingFace方案最高可提升24倍。
3.3 核心部署工具详解
3.3.1 Ollama:个人开发者的“模型应用商店”
Ollama是当前个人本地部署大模型最便捷的入口,所有主流操作系统均已支持(Linux、macOS、Windows)。
安装(一行命令):
# Linux/macOS
curl -fsSL https://ollama.com/install.sh | sh
# Windows(需WSL2)
# 在WSL2的Ubuntu终端中执行同上命令核心操作:
# 下载模型(自动处理量化版本)
ollama pull qwen2.5:7b # 7B模型,约4GB
ollama pull deepseek-r1:14b # 14B模型,约9GB
ollama pull llama3.1:70b # 70B量化版,约40GB
# 运行交互式对话
ollama run qwen2.5:7b
# 查看已下载模型
ollama list
# 删除模型
ollama rm qwen2.5:7bOllama内置模型市场,支持一键获取Llama、Mistral、Qwen、DeepSeek等200+预量化模型。通过GGUF量化格式,70B模型在量化后仅需约8GB内存即可运行。需要注意的是,Ollama默认只监听本地127.0.0.1,仅能本机访问。
问题:什么是预量化模型?
预量化模型,指的是模型发布方在训练完成后,已经提前对模型权重进行了量化压缩(如将FP16精度压缩为INT4),并以量化后的文件格式(通常是GGUF格式)直接提供给用户下载使用。这就像厂家把一整本厚重的百科全书压缩成口袋书之后再出售——你下载的不是几百GB的原始全精度模型,而是一个已经过压缩、体积小得多的“即开即用”版本,无需自己准备校准数据集、运行量化脚本。Ollama模型库中的
qwen2.5:7b、deepseek-r1:14b等,实际上就是官方维护的预量化版本,用户执行ollama pull时下载的就是这类模型,省去了繁琐的量化操作,让本地部署的门槛大幅降低。
3.3.2 llama.cpp:低配设备的“性能救星”
llama.cpp是专为资源受限设备设计的C++高性能推理引擎,其核心优势在于极致的CPU优化。
# 克隆并编译
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make -j4
# 下载GGUF格式的量化模型
# 从HuggingFace下载.gguf文件到models/目录
# CPU推理
./llama-cli -m models/qwen2.5-7b-q4_k_m.gguf -p "请解释什么是人工智能" -n 256
# GPU加速推理(CUDA)
./llama-cli -m models/qwen2.5-7b-q4_k_m.gguf -p "你好" -n 256 -ngl 999典型硬件适配:树莓派5(8GB)可运行Mistral-7B-Q4;x86旧笔记本可运行Qwen-14B-Q4_K;支持GTX 1060等老旧显卡运行13B级模型。内存占用降低至原始模型的1/4,7B模型仅需4GB内存。llama.cpp同样默认只监听127.0.0.1。
3.3.3 vLLM:企业级高并发推理引擎
vLLM是企业生产环境部署大模型的首选方案,通过两大核心技术实现性能质变:
PagedAttention:借鉴操作系统虚拟内存分页思想,将KV Cache切分为固定大小的块,按需分配而非预分配整块连续显存,减少约78%的显存碎片。
Continuous Batching:动态调度请求,任一请求完成后立即释放资源并接纳新请求,消除传统批处理中的“气泡效应”,GPU利用率提升至90%以上。
# 安装
pip install vllm
# 启动OpenAI兼容的推理服务(单卡)
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--dtype float16 \
--max-model-len 4096
# 多卡并行部署(4卡)
python -m vllm.entrypoints.openai.api_server \
--model deepseek-ai/DeepSeek-V3 \
--tensor-parallel-size 4 \
--host 0.0.0.0 \
--port 8000关键参数速查:
|
参数 |
说明 |
建议值 |
|---|---|---|
|
|
张量并行使用的GPU数量 |
等于实际GPU卡数 |
|
|
GPU显存使用比例 |
0.85–0.95 |
|
|
最大上下文长度 |
根据模型能力和显存调整 |
|
|
最大并发序列数 |
根据显存调整(128–256) |
|
|
推理精度 |
|
vLLM通过FastAPI提供OpenAI兼容的REST接口,启动后即可使用标准OpenAI SDK调用本地模型:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed" # 本地服务无需密钥
)
response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct",
messages=[{"role": "user", "content": "请解释什么是PagedAttention"}],
temperature=0.7,
max_tokens=512
)vLLM默认监听0.0.0.0,这意味着它可以被同一网络内的其他设备访问,适合部署在企业内部网络中。但在无防火墙的生产环境中使用时,建议配合Nginx反向代理添加身份认证和TLS加密。
3.4 硬件选型指南
3.4.1 核心原则:显存先于算力
在大模型推理部署中,硬件选型的首要考量不是GPU的计算速度(FLOPS),而是显存容量(VRAM)。推理任务的计算量相对固定,但若显存不足以容纳模型权重和KV Cache,模型根本无法启动。
显存需求估算公式:
基础显存需求(GB) = (模型参数量(B) × 每参数字节数 × 开销系数) + KV Cache开销
以FP16精度、7B模型为例:
模型权重:7B × 2字节 = 14GB
推理开销:约2GB
KV Cache(4K上下文):约4GB
总计:约20GB → 需至少24GB显存的显卡其中“开销系数”通常取1.2,用于涵盖推理框架自身的内存占用和临时缓冲。
问题:如何查看电脑的显存?
在Windows中,可以用一行命令查询显存。最准确的方法是使用 wmic。
(1)按下键盘上的 Win + R 键,输入 cmd 后按回车,打开命令提示符。
(2)复制并粘贴以下命令,按回车执行:
wmic path win32_videocontroller get caption,adapterram(3)查看输出:执行后会显示显卡名称和一串数字。这串数字的单位是字节(Bytes),你需要把它除以 1073741824 (即1024×1024×1024) 来得到我们常说的GB数值。
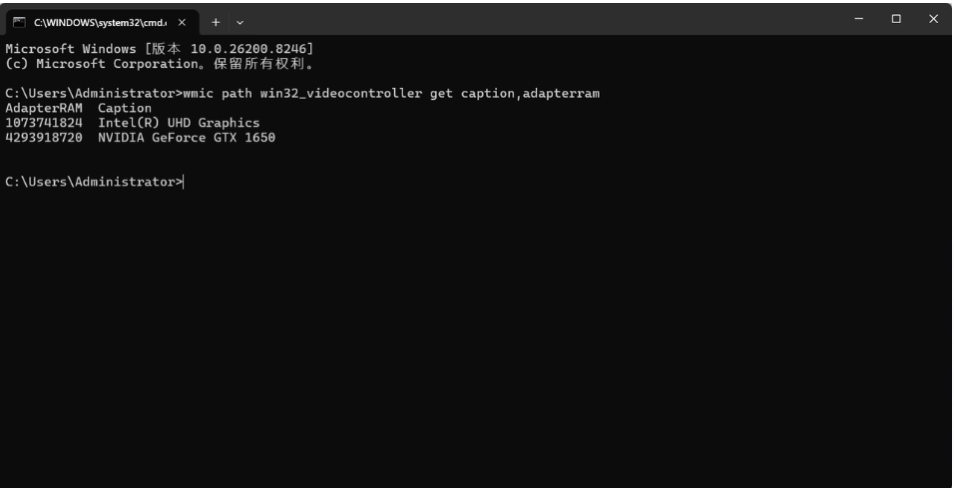
根据截图,AdapterRAM 的单位是字节(Bytes),换算结果如下:
-
Intel(R) UHD Graphics(核显):1,073,741,824 Bytes ≈ 1 GB
-
NVIDIA GeForce GTX 1650(独显):4,293,918,720 Bytes ≈ 4 GB
主力显卡是NVIDIA GTX 1650,物理显存为 4GB。这个容量在运行AI大模型时比较吃紧,只能尝试INT4/GGUF量化后的7B模型(约4-5GB),或模型体积更小的3B/1.5B模型。推理时建议关闭其他占用显存的程序以释放更多空间。
3.4.2 个人开发者硬件选型
|
使用场景 |
推荐GPU |
显存 |
可运行模型(量化后) |
参考成本 |
|---|---|---|---|---|
|
入门体验 |
RTX 4060 Ti 16GB |
16GB |
7B模型(Q4_K_M),8B模型 |
约¥3,000 |
|
主力开发 |
RTX 4090 24GB |
24GB |
7B–14B模型全场景,70B(Q4) |
约¥13,000 |
|
高性能开发 |
RTX 5090 32GB |
32GB |
7B–32B模型,70B(Q4_K_M) |
约¥24,000 |
RTX 4090作为消费级旗舰产品,其24GB显存足以支持7B–14B参数量化模型的流畅推理。采用INT4量化后,7B–13B参数模型仅需约10GB显存,单卡可处理2000–4000 Token上下文。
对于预算极有限的用户,最低配置建议为8GB内存+4GB显存,可运行Q4_K_M量化的7B模型(约4GB),推理速度约5–10 tokens/s。
3.4.3 企业级硬件选型
|
部署规模 |
推荐GPU |
总显存 |
可部署模型 |
参考成本 |
|---|---|---|---|---|
|
小型团队(<20人) |
2×RTX 4090 24GB |
48GB |
70B模型(8bit量化) |
约¥8万(整机) |
|
中型团队(20–100人) |
4×A100 80GB |
320GB |
70B–130B模型(全精度) |
约¥50–80万 |
|
大型团队(100+人) |
8×H100/H200 80GB |
640GB+ |
671B满血版模型 |
约¥200–500万 |
用户实测证明,双卡RTX 4090在8bit量化下可实现接近A100 40GB的性能表现,为中小型团队提供了高性价比的大模型本地化方案。在8卡H100集群上,671B满血版DeepSeek模型的持续吞吐可达约每秒380个Token。
对于金融、医疗、政务等对数据安全要求极高的行业,国产算力方案正日益成熟。华为昇腾Atlas 800I A2(64GB×8卡)已通过DeepSeek系列模型的完整适配认证,国产AI一体机支持“开箱即用”——出厂预装调试,通电即用,且数据完全不出域。这类一体机目前已成为众多国央企AI基础设施的首选方案。
3.4.4 模型规模与硬件配置对照总表
|
模型规模 |
典型模型 |
INT4量化后体积 |
最低GPU配置 |
推荐系统内存 |
单卡可运行 |
|---|---|---|---|---|---|
|
1.5B–3B |
Qwen2.5-1.5B |
1–2GB |
集成显卡/CPU |
8GB |
✅ |
|
7B–8B |
Qwen2.5-7B, Llama3-8B |
4–5GB |
RTX 3060 12GB |
16–32GB |
✅ |
|
13B–14B |
Qwen2.5-14B |
8–10GB |
RTX 4090 24GB |
32–64GB |
✅ |
|
32B–34B |
DeepSeek-R1-Distill-Qwen-32B |
18–20GB |
2×RTX 4090或A100 40GB |
64–128GB |
⚠️(需双卡) |
|
70B–72B |
Llama3-70B, Qwen2.5-72B |
35–40GB |
2×A100 80GB或4×RTX 4090 |
128GB+ |
❌(需多卡) |
|
236B |
DeepSeek-V3-Lite |
约60GB |
2×H100 80GB |
256GB+ |
❌ |
|
671B |
DeepSeek-V3, DeepSeek-R1 |
约170GB |
8×A100/H100 80GB |
512GB–1TB |
❌(需集群) |
第四章 企业级大模型部署成本方案与经济分析
4.1 引言
在第二章中,我们系统讲解了从个人开发者到企业团队的大模型本地部署技术栈和硬件选型。对于企业决策者而言,技术方案的可行性只是第一步——更核心的问题是:“这个方案到底要花多少钱?” 成本,是所有技术选型的最终仲裁者。
本章以200人使用团队、每人日均消耗1000万Token为基准案例进行全量成本测算。这意味着团队内部深度整合了AI工作流,不仅用于简单的对话问答,更承担着代码生成、长文档分析、多步推理、批量数据处理等高Token消耗任务。在这种量级下,不同部署方案的成本差异将以数十倍乃至数百倍计。
本章将对三大方案进行全量成本测算:
-
方案一:云端API调用方案(含海外商用API和国内高性价比API)
-
方案二:本地部署方案(海外NVIDIA GPU硬件)
-
方案三:国产算力硬件本地部署方案
所有数据均基于2026年4月至5月的市场价格,重点关注3年总拥有成本(TCO)。同时,本章还将提供成本优化策略与混合部署方案,帮助企业决策者在安全、性能和经济成本之间找到最优平衡点。
4.2 成本测算模型构建
在深入具体方案之前,首先建立统一的测算框架,确保各方案的可比性。
4.2.1 使用量估算假设
对于一个200人的技术团队,按照每人日均消耗1000万Token的使用强度,参数设定如下:
基础使用量:
|
参数项 |
参考值 |
说明 |
|---|---|---|
|
团队规模 |
200人 |
— |
|
每人日均Token消耗 |
1000万Token |
相当于约700万中文字符/人/天 |
|
团队日均总Token消耗 |
20亿Token |
200 × 1000万 |
|
日均输入Token |
约14亿Token |
按输入:输出≈7:3估算 |
|
日均输出Token |
约6亿Token |
按输入:输出≈7:3估算 |
|
年有效使用天数 |
250天 |
排除节假日 |
|
年总输入Token |
约3.5万亿Token |
14亿 × 250天 |
|
年总输出Token |
约1.5万亿Token |
6亿 × 250天 |
|
峰值并发请求 |
50–100 QPS |
上班时段集中 |
量级直观感受:20亿Token/天相当于每天处理约1.4亿中文字符(按中文每Token约0.7字估算)。
4.2.2 TCO计算模型
(1)云端方案的TCO计算公式:
3年TCO = API调用费 + 平台服务费 + 额外功能费 + 公网带宽费
其中:
API调用费 = 年输入Token量 × 输入价格 + 年输出Token量 × 输出价格
年输入Token量 = 日均输入Token × 250天
年输出Token量 = 日均输出Token × 250天(2)本地部署方案的TCO计算公式:
3年TCO = 硬件采购费 + 软件许可费 + 网络设备费 + 3年电费 + 3年运维人力费 + 3年IDC托管费
参数详解:
- 硬件采购费:包含GPU卡、服务器整机、网络设备及存储阵列的首次采购价格。
- 软件许可费:主要为开源推理框架(如vLLM),该项费用较低。
- 电费 = GPU总功耗(kW) × 24小时 × 365天 × 电费单价 × 负载系数(0.6–0.8)
- 运维人力费 = AI运维工程师薪资 × 人员数量
- IDC托管费:机房机位租赁、基础带宽与散热费用,按每月每机柜报价。4.3 API定价数据来源说明
本章测算使用的API价格均基于截至2026年4月至5月的公开API定价信息,具体如下:
GPT-5.5系列:GPT-5.5的API输入定价为$5/百万Token,输出定价为$30/百万Token;GPT-5.5 Pro输入$30/百万Token,输出$180/百万Token。
Claude系列:Claude Sonnet 4.6的API输入$3/百万Token、输出$15/百万Token。
Gemini系列:Gemini 2.5 Pro的API输入端约$1.25/百万Token、输出端约$2.50/百万Token。
DeepSeek V4系列(2026年4月最新降价后):V4-Flash输入缓存命中¥0.02/百万Token,未命中输入¥0.2/百万Token,输出¥2/百万Token;V4-Pro缓存未命中输入¥3/百万Token,输出¥6/百万Token。
4.4 方案一:云端API调用方案
方案描述:全部推理能力通过云端API获取,本地无需部署GPU硬件。年输入总量约3.5万亿Token,年输出总量约1.5万亿Token。
4.4.1 基础API费用测算
|
服务商 |
模型 |
输入价格 |
输出价格 |
年输入费 |
年输出费 |
年API费合计 |
|---|---|---|---|---|---|---|
|
OpenAI |
GPT-5.5 |
$5/百万Token |
$30/百万Token |
$1.75亿 |
$4.50亿 |
$6.25亿(≈¥45.6亿) |
|
OpenAI |
GPT-5.5 Pro |
$30/百万Token |
$180/百万Token |
$10.5亿 |
$27亿 |
$37.5亿(≈¥273.8亿) |
|
Anthropic |
Claude Sonnet 4.6 |
$3/百万Token |
$15/百万Token |
$1.05亿 |
$2.25亿 |
$3.3亿(≈¥24.1亿) |
|
|
Gemini 2.5 Pro |
$1.25/百万Token |
$2.50/百万Token |
$0.44亿 |
$0.375亿 |
$0.81亿(≈¥5.9亿) |
|
DeepSeek |
V4-Flash |
¥0.2/百万Token |
¥2/百万Token |
¥700万 |
¥3亿 |
约¥3.07亿 |
|
DeepSeek |
V4-Pro |
¥3/百万Token |
¥6/百万Token |
¥1.05亿 |
¥9亿 |
约¥10.05亿 |
数据来源说明:GPT-5.5 输入$5/百万Token、输出$30/百万Token;GPT-5.5 Pro 输入$30/百万Token、输出$180/百万Token;Claude Sonnet 4.6 输入$3/百万Token、输出$15/百万Token;DeepSeek V4-Flash 输入¥0.2/百万Token(缓存未命中)、输出¥2/百万Token;V4-Pro 输入¥3/百万Token(缓存未命中)、输出¥6/百万Token。年输入总量=日均14亿Token × 250天=3.5万亿Token/年;年输出总量=日均6亿Token × 250天=1.5万亿Token/年。
4.4.2 附加费用与3年TCO汇总
|
附加费用项 |
年费估算 |
说明 |
|---|---|---|
|
平台管理服务费 |
¥10–50万 |
API管理平台、监控系统 |
|
公网带宽费 |
¥12–24万 |
100M独享带宽 |
|
方案 |
年API费用 |
年附加费 |
3年TCO合计 |
|---|---|---|---|
|
OpenAI GPT-5.5 |
约¥45.6亿 |
约¥22–74万 |
约¥137亿 |
|
Anthropic Claude Sonnet 4.6 |
约¥24.1亿 |
约¥22–74万 |
约¥72亿 |
|
DeepSeek V4-Flash |
约¥3.07亿 |
约¥22–74万 |
约¥9.2亿 |
4.4.3 云端方案核心风险
云端方案的成本几乎100%集中在持续的API调用费上。日均调用量每增加1000万Token(即人均增加5万Token/天),年API费用将增加约5%–7%,这意味着使用量与成本呈高度线性关系,缺乏本地部署方案中的规模效应。
云端方案的安全与合规补充考量:虽然成本上具有明显优势(尤其是DeepSeek路线),但对于金融、医疗、政务等强监管行业需额外考量:
-
数据传输风险:推理数据经由公网传输,存在被截获的风险。建议使用TLS 1.3加密传输,并要求服务商提供私有网络接入能力(如VPC专线)。
-
日志留存合规:需签署数据处理协议(DPA),明确云服务商的日志留存期限和删除机制,并优先选择通过SOC 2、ISO 27001认证的服务商。
-
模型训练隔离:需在协议中明确约定“用户数据不用于模型训练”,确保数据不被用于改进云厂商的模型。
-
央国企信创场景:国产化部署是政策合规的刚性要求,云端方案通常不作为可选项。
4.5 方案二:海外GPU硬件本地部署方案
方案描述:采购搭载NVIDIA H100 GPU的服务器集群,在自有或托管数据中心完成全部模型推理。部署DeepSeek V4-Flash等模型,通过INT4/INT8量化降低单卡显存需求。
4.5.1 算力需求测算
要承载20亿Token/天的推理量,以INT4量化后的DeepSeek V4-Flash为基准(总参数约3000亿,INT4量化后约160GB),参考基准测试中H100在vLLM上的实际吞吐数据:Llama 3.3 70B(FP8)在vLLM上每卡可达约1,850 Token/秒,经过深度优化的102B级别模型单卡可达约9,000 Token/秒。对于INT4量化的V4-Flash(约280B级参数),保守估计单卡H100推理吞吐约3,000–5,000 Token/秒。按保守值3,000 Token/秒计算:
日均总Token = 20亿
有效推理时间 ≈ 20小时(考虑负载波动)
所需总吞吐率 ≈ 20亿 ÷ (20 × 3600) ≈ 27,778 Token/秒
单卡H100吞吐率 ≈ 3,000 Token/秒
所需H100卡数 ≈ 27,778 ÷ 3,000 ≈ 10张 → 取12张(含冗余设计)4.5.2 硬件配置规划
参考2026年4–5月国内GPU服务器市场行情:H100 80GB单卡市场价约18–22万元,整台8卡H100服务器含税价约52–65万元。按2台×8卡配置,含冗余设计的12卡方案测算如下:
|
配置项 |
型号/规格 |
数量 |
单价(万元) |
小计(万元) |
|---|---|---|---|---|
|
GPU |
NVIDIA H100 80GB SXM |
12张 |
18–22 |
约240 |
|
服务器整机 |
8卡H100兼容机 |
2台 |
55–65 |
约120 |
|
网络设备 |
100GbE交换机 |
2台 |
3–5 |
约8 |
|
存储设备 |
全闪存阵列 |
20TB |
0.3/TB |
约6 |
|
硬件采购总计 |
— |
— |
— |
约374 |
配置说明:表中采用2台×8卡服务器共16张H100,实际激活12张(含4张冗余备用),以确保在GPU卡故障时推理服务不中断。
4.5.3 年度运维费用
|
费用项 |
月费(万元) |
年费(万元) |
说明 |
|---|---|---|---|
|
IDC托管费 |
12–18 |
144–216 |
含机柜和基础带宽 |
|
电费 |
5–7 |
60–84 |
12卡H100,含散热和PUE,工业电价约0.8元/度 |
|
运维人力 |
10–15 |
120–180 |
4–5名AI运维工程师,人均年薪约35万 |
|
软件许可 |
— |
5–10 |
开源框架为主,少量商业许可 |
|
年度合计 |
— |
329–490 |
— |
电费说明:12张H100总功耗约8.4kW,加上散热(PUE约1.4)系统总功耗约11.8kW,年用电量=11.8kW × 24h × 365天≈10.3万kWh。按数据中心工业电价约0.7–1.0元/kWh,年电费约7.2–10.3万元。参考行业分析显示,电力成本约占数据中心运营成本的57%。
运维人力说明:AI运维工程师平均月薪约1.3–2.5万/月,算力硬件运维专家约2–3万/月。按4–5人团队(含GPU运维、网络运维、系统运维轮班),综合年薪含福利社保约35万/人年。
4.5.4 海外硬件方案3年TCO汇总
|
TCO构成 |
费用(万元) |
备注 |
|---|---|---|
|
首年硬件投入 |
约374 |
一次性采购 |
|
年度运维费用 × 3 |
约987–1,470 |
按中位数约410万/年×3年 |
|
3年TCO总计 |
约1,361–1,844 |
— |
4.6 方案三:国产算力硬件本地部署方案
方案描述:采用华为昇腾Atlas 800I A2服务器,符合信创合规要求。单台8卡Atlas服务器可承载约3000亿参数模型的日常推理,根据公开招标数据,Atlas 800I A2服务器单价约57.5–98.3万元,8卡整机配置约180万元。单卡昇腾910B成本约为H200的38%,推理延迟较H200仅高15%。
4.6.1 硬件配置规划
为承载20亿Token/天的推理量,参考单卡昇腾910B推理吞吐约H100的60%–70%性能水平,需约20张昇腾910B卡,按2台Atlas服务器(每台8卡)共16张卡测算,预留20%–25%冗余量。
|
配置项 |
推荐型号 |
数量 |
单价(万元) |
小计(万元) |
|---|---|---|---|---|
|
AI服务器 |
Atlas 800I A2(8卡) |
2台 |
150–180 |
约330 |
|
网络设备 |
华为交换机 |
2台 |
1.5–3 |
约4.5 |
|
存储设备 |
全闪存阵列 |
20TB |
0.3/TB |
约6 |
|
AI开发平台 |
ModelMate/Ascend SDK |
1 |
0(免费) |
0 |
|
硬件总计 |
— |
— |
— |
约340.5 |
4.6.2 年度维保电费
国产方案的电费较高原因:昇腾910B/C单卡功耗(约600W)高于同级NVIDIA产品,16卡整机功耗约10kW,加上散热(PUE约1.5)系统总功耗约15kW。参考西部数据中心0.3–0.4元/kWh的低成本绿电优势:
|
费用项 |
年费(万元) |
说明 |
|---|---|---|
|
硬件维保 |
20–35 |
原厂7×24小时上门 |
|
电费 |
50–95 |
16卡整机约15kW系统功耗(含PUE 1.5散热),年用电约13万度 |
|
运维人力 |
105–175 |
3–5名AI运维工程师 |
|
年度合计 |
约175–305 |
— |
4.6.3 国产硬件方案3年TCO汇总
|
TCO构成 |
费用(万元) |
备注 |
|---|---|---|
|
首年硬件投入 |
约340.5 |
一次性采购 |
|
年度运维费用 × 3 |
约525–915 |
按中位数约240万/年×3年 |
|
3年TCO总计 |
约865–1,255 |
— |
4.7 三大方案成本对比总结
4.7.1 3年总拥有成本对比
|
对比维度 |
云端API方案 |
海外硬件方案 |
国产硬件方案 |
|---|---|---|---|
|
一次性硬件投入 |
¥0 |
约374万元 |
约340.5万元 |
|
年度API费用 |
约¥3亿–45亿(依模型而异) |
¥0 |
¥0 |
|
年度运维费用 |
约22–74万 |
约329–490万 |
约175–305万 |
|
3年TCO |
约¥9.2亿–137亿 |
约¥1,361–1,844万 |
约¥865–1,255万 |
|
日均成本(3年摊销) |
约¥123万–1,827万/天 |
约¥1.8–2.5万/天 |
约¥1.2–1.7万/天 |
4.7.2 云端API方案年成本速查表
|
服务商 |
模型 |
年API费(¥) |
日均成本 |
|---|---|---|---|
|
OpenAI |
GPT-5.5 |
约¥45.6亿 |
约¥1,825万 |
|
Anthropic |
Claude Sonnet 4.6 |
约¥24.1亿 |
约¥964万 |
|
|
Gemini 2.5 Pro |
约¥5.9亿 |
约¥236万 |
|
DeepSeek |
V4-Pro |
约¥10.05亿 |
约¥402万 |
|
DeepSeek |
V4-Flash |
约¥3.07亿 |
约¥123万 |
4.7.3 核心结论
在200人团队、每人日均1000万Token的极高使用量下:
(1)从纯成本角度出发:尽管DeepSeek V4-Flash已将API价格压至极低水平(输出¥2/百万Token),但在20亿Token/天的量级下,云端API方案的年费用仍超过¥3亿。而自建本地服务器(无论是海外H100方案还是国产昇腾方案)的3年总成本仅为¥865万–1,844万元,远优于任何云端方案。
(2)海外 vs 国产硬件的选择:国产昇腾方案在3年TCO上较海外H100方案低约25%–40%,主要得益于昇腾910B单卡成本仅为H200的38%带来的采购价格优势和国产维保体系的成熟。
(3)云端方案适用边界的明确化:在当前量级(20亿Token/天)下,云端方案的年费用达到数亿至数十亿元级别,对于绝大多数企业而言在财务上不具有可行性。云端方案的优势区间应定位在:日调用量较低(<5000万Token/天)、团队规模较小、或业务波动大的场景。
(4)数据安全与信创合规是本地部署的核心驱动:对于金融、医疗、政务等国央企,数据不出域是刚性合规要求。国产昇腾方案是目前唯一同时满足“数据本地化+信创合规”要求的生产环境方案。
4.8 混合部署策略:精打细算企业的最佳实践
4.8.1 策略核心思想
将复杂的Agent推理、长文档处理等高消耗任务路由至本地部署模型处理,同时通过云端API作为弹性补充——在业务高峰期(如季度报告生成、新模型上线评测)临时租用云端算力,避免本地硬件为短期峰值需求而过度配置。
4.8.2 任务分层路由设计
|
任务分层 |
日均Token占比 |
路由目标 |
日均费用 |
|---|---|---|---|
|
复杂Agent推理与代码生成 |
20%(约4亿Token) |
本地部署集群 |
已含在硬件运维费中 |
|
高频FAQ与文档问答 |
60%(约12亿Token) |
本地部署集群 |
已含在硬件运维费中 |
|
弹性峰值补充 |
20%(约4亿Token) |
云端API(DeepSeek V4-Flash) |
约¥6,000/天 |
弹性峰值场景示例:某金融企业每月末需对数千份财报进行批量分析,此时本地GPU利用率会突然飙升至100%以上,触发排队。通过将溢出流量自动路由至云端API,可在不增加硬件投入的前提下确保业务SLA。
4.8.3 混合方案3年TCO评估
|
方案构成 |
3年费用(万元) |
说明 |
|---|---|---|
|
本地硬件(国产昇腾方案) |
约865–1,255 |
含硬件+3年运维 |
|
云端弹性流量(20%) |
约450 |
¥6,000/天 × 250天 × 3年 |
|
运维人力边际增加 |
0 |
本地团队复用,无需额外人员 |
|
混合方案3年TCO |
约1,315–1,705 |
— |
策略价值:混合方案比纯海外硬件方案节省约10%–30%,比纯国产方案增加了合理的弹性扩充空间,适合业务量存在周期性波动的企业。
4.9 投资回报周期测算
测算逻辑:将本地部署方案与同等性能水平的云端API方案进行对比,分析前期硬件投资需要多长时间才能通过节省API费用来收回。
以海外硬件方案 vs. Anthropic Claude Sonnet 4.6 API方案为对比基准:
|
对比项 |
本地部署(海外H100) |
纯云端方案(Claude Sonnet 4.6) |
|---|---|---|
|
一次性硬件投入 |
¥374万 |
¥0 |
|
年度运维/API费用 |
¥329–490万/年 |
约¥24.1亿/年 |
回本分析:
-
本地部署方案3年总成本约¥1,361–1,844万,云端方案3年总成本约¥72亿。
-
即使仅考虑首年的对比,本地方案约¥703–864万(硬件¥374万+运维¥329–490万)也远低于云端方案一年的API费用约¥24.1亿。
-
在当前量级下,本地方案的经济优势极其显著,几乎无需考虑“回本周期”的概念——仅第一年的费用差就足以覆盖全部硬件投资。
4.10 成本优化六策
策略一:量化精度压缩
将模型从FP16精度压缩至INT4或INT8。实测验证INT4量化可将模型体积压缩至原来的1/4,推理延迟降至原来的1/3到1/4,且精度损失通常低于1%。
策略二:KV Cache复用
固定system prompt作为全局前缀,避免每次请求重复缓存相同内容。在客服、知识问答等高重复场景中可减少约30%–50%的KV Cache开销,显著提升批处理能力。
策略三:负载均衡与弹性伸缩
根据业务负载动态调整GPU工作卡数:低负载时段仅保持50%–60%的GPU在线,高峰时段全部激活。该方法可将电力消耗降低20%–30%。
策略四:异步流水线
将LLM调用、RAG检索、工具执行等任务拆分为独立的异步流水线,消除同步等待瓶颈。根据行业实测数据,端到端延迟可降低40%–60%,同等硬件下承载更多并发。
策略五:云端训练 + 本地推理的分层模式
仅在需要大规模训练的短时间内租用云端GPU(按需付费),日常推理使用本地已部署的模型。适合需要定期微调模型的企业。
策略六:选择低电价区域部署
国内西部数据中心提供0.3–0.4元/度的低成本绿电,较东部工业电价低50%以上。对于年用电量超过10万度的GPU集群,选择西部部署每年可节省电费约¥5–10万。
4.11 综合选型建议与决策矩阵
|
决策场景 |
推荐方案 |
理由 |
|---|---|---|
|
极高使用量(>10亿Token/天) |
自建海外或国产硬件方案 |
云端API费用过高,自建方案TCO更低,且数据安全可控 |
|
信创合规(央国企) |
自建国产昇腾方案 |
满足信创目录要求,可申请国产化采购补贴 |
|
数据安全优先(金融/医疗) |
自建国产或海外硬件方案 |
数据100%本地闭环,满足等保和合规要求 |
|
业务周期性波动 |
混合方案(国产硬件+云端弹性) |
本地处理基础流量,云端补足业务峰值 |
|
预算极紧 |
云端API方案(DeepSeek V4-Flash) |
年API费约¥3亿(此为当前量级下极限情况) |
4.12 总结
大模型部署的成本评估需要综合考虑使用量级、安全合规、运维能力和企业战略等多个维度。对于200人团队、每人日均消耗1000万Token的极高使用量场景:
(1)核心发现:在当前量级下,云端API方案的年费用高达数亿至数十亿元人民币,即便使用最具性价比的DeepSeek V4-Flash,年API费也超过¥3亿。与此形成鲜明对比的是,自建本地服务器方案(无论是海外H100方案还是国产昇腾方案)的3年总成本仅为¥865万–1,844万元,经济优势极其显著。
(2)国产 vs 海外硬件:国产昇腾方案(3年TCO约¥865–1,255万)较海外H100方案(3年TCO约¥1,361–1,844万)低约25%–40%,同时满足信创合规要求,是数据敏感行业和央国企的首选路径。
(3)混合部署策略适用于业务量存在周期性波动的企业 — 本地硬件承载基础流量,云端API作为弹性补充,实现成本与灵活性的最优平衡。通过量化压缩、KV Cache复用、异步流水线等六项优化策略,还可在现有硬件基础上进一步降低20%–40%的推理成本。
关键决策的一句话总结:高频调用看本地,低频弹性走云端,数据敏感选国产,混合部署最均衡。
第五章:个人部署实战 — 基于 Ollama 本地运行 DeepSeek
本地快速体验大模型,最便捷的方式是使用 Ollama。它是一个命令行工具,相当于一个“模型应用商店”,可以一键下载并运行各种开源大模型。
核心操作流程:

5.1 检查电脑配置
要评估你的电脑能否部署AI大模型,可以先用下面的一行命令,一次性查看CPU、内存、存储和显存这几个关键信息。
5.1.1 一行命令:查看CPU、内存、存储和显存
把下面的命令复制、粘贴到 命令提示符(cmd) 或 PowerShell 里,然后按回车:
echo. & wmic cpu get name,numberofcores,numberoflogicalprocessors & echo. & wmic computersystem get totalphysicalmemory & echo. & wmic diskdrive get model,size /format:list && for /f "tokens=*" %i in ('wmic path win32_videocontroller where "AdapterRAM is not null" get adapterram /format:value ^| find "="') do set %i && echo AdapterRAM=%AdapterRAM% MB运行上面的命令后,输出如下内容:
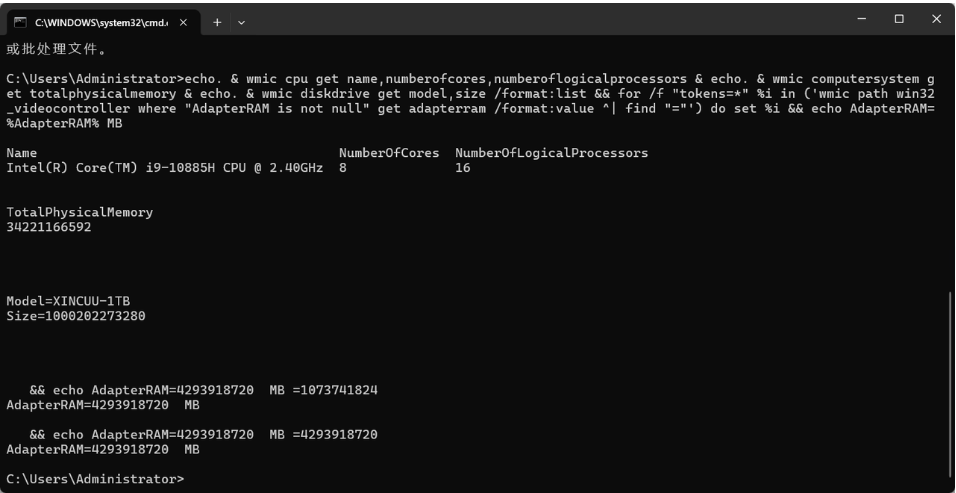
命令拆解与输出解读:
-
CPU信息:
wmic cpu get name,numberofcores...-
Name: CPU 具体型号 -
NumberOfCores: 物理核心数 -
NumberOfLogicalProcessors: 逻辑处理器数(超线程数量)
-
-
内存信息:
wmic computersystem get totalphysicalmemory-
TotalPhysicalMemory: 系统物理内存总容量(单位是 Bytes,需要除以 1024³ 换算成 GB)
-
-
存储信息:
wmic diskdrive get model,size-
Model: 磁盘型号 -
Size: 硬盘总容量(单位:Bytes)
-
-
显存信息:
wmic path win32_VideoController...-
AdapterRAM: 显卡显存容量(单位是 MB)
-
⚠️ 注意:
如果显卡是集成显卡(显存从内存中划分),这条命令可能会显示一个较小的值或运行出错。对于集成显卡,通常查看系统内存即可。
如果你的配置比较好,可能有多块显卡,这个命令会显示全部。
总而言之,最简单的方法就是根据你显存的大小,选择对应参数量级的 4-bit 量化模型,然后用
Ollama run之类的命令一键跑起来。实践出真知,这些工具帮你跳过了很多繁琐的配置步骤,非常值得一试。
在你的硬件环境下:
-
CPU:i9-10885H,8核16线程,性能充足,可以承担纯 CPU 推理。
-
内存:32GB,对于运行
1.5B和7B量化模型绰绰有余。 -
显卡:GTX 1650,拥有 4GB 独立显存,可以提供额外的 GPU 加速能力,显著提升推理速度。
-
操作系统:Windows,需要借助 WSL2 (Windows Subsystem for Linux) 来搭建 Linux 环境,这是目前 Windows 下进行 AI 开发的最佳实践。
5.1.2 排查“nvidia-smi: command not found”错误
如果在运行 nvidia-smi 时提示找不到命令,通常是因为:没有 NVIDIA 显卡;或驱动未正确安装。你可以按下面的步骤操作:
(1)检查显卡型号:按 Win + X 键,选择“设备管理器”,展开“显示适配器”就能看到。如果列表里没有 NVIDIA 的显卡,就不用继续了。
(2)安装/更新驱动:若有 NVIDIA 显卡,去其官方网站下载安装最新的驱动。
(3)配置环境变量:如果驱动已装好但命令仍无效,可以手动把 C:\Program Files\NVIDIA Corporation\NVSMI 这个路径添加到系统的 PATH 环境变量里。
5.1.3 AI部署建议(基于你的配置)
快速选择表
|
你的显存 (VRAM) |
可以运行参数量级 |
模型推荐实例 (4-bit量化) |
建议系统内存 (RAM) |
|---|---|---|---|
|
8GB |
7B~8B |
Llama 3 8B, Qwen2.5 7B |
≥ 16GB |
|
12GB |
13B~14B |
Qwen2.5 14B, Phi-3 Medium 14B |
≥ 32GB |
|
16GB |
14B~20B |
Gemma 2 27B (需部分 offload), 更流畅运行 13B 模型 |
≥ 32GB |
|
24GB |
32B~34B |
Yi-34B, Qwen2.5 32B |
≥ 64GB |
不同模型的硬件要求详解
-
入门级:运行1B-3B的小型模型
-
硬件门槛:仅需约 8GB 系统内存,甚至可在部分集成显卡上运行。
-
适用场景:适合初次体验或对性能要求不高的简单任务。
-
推荐工具与模型:可使用 Ollama,选择
tinyllama(1.1B)、phi(2.7B) 或qwen2.5:3b等模型。
-
-
进阶级:流畅运行7B-8B的主流模型
-
硬件门槛:这是目前个人部署的主流。一个 8B 模型量化后约 5GB 大小,因此拥有 8GB 或更多显存的游戏显卡即可流畅运行。同时,建议系统内存不低于 16GB。
-
适用场景:可以作为个人AI助手,胜任日常聊天、内容总结、代码补全等任务。
-
推荐模型:
llama3(8B)、qwen2.5(7B)、mistral(7B)。
-
-
发烧级:探索13B-14B的更强模型
-
硬件门槛:需要 12GB 显存,系统内存建议提高至 32GB。
-
适用场景:能处理更复杂的对话和中等程度的推理任务,模型的回答质量会有明显的提升。
-
推荐模型:
qwen2.5:14b、phi3:14b-medium。
-
-
专业级:挑战32B及以上的顶级模型
-
硬件门槛:这些顶尖模型的要求较高,推荐使用 24GB 显存的消费级旗舰显卡,例如 RTX 3090 或 RTX 4090,系统内存也最好能有 64GB 或以上。
-
适用场景:适用于对模型性能有严格要求的专业研究或高质量内容生成。
-
模型格式小提示:建议优先选择模型页面上带有
GGUF或GPTQ标识的版本。这是目前本地部署中最通用的两种量化格式。
5.2 个人本地AI大模型部署
5.2.1 第一步:安装 WSL2 并配置环境
(1)安装 WSL2:右键点击开始菜单,选择“Windows PowerShell (管理员)”。输入以下命令并回车:
wsl --install -d Ubuntu系统会自动下载并安装 Ubuntu。安装完成后,按提示重启电脑。
(2)初始化 Ubuntu:重启后,在开始菜单找到并打开“Ubuntu”。它会自动进行初始化配置,然后提示你设置一个 Linux 用户名和密码。请牢记这个密码,后续安装软件时会用到。注意:输入密码时屏幕不会有任何显示,这是正常的安全机制。
(3)更新系统软件包:在 Ubuntu 终端中,依次执行以下命令,确保系统处于最新状态:
sudo apt update && sudo apt upgrade -y5.2.2 第二步:安装 Ollama 并拉取 DeepSeek 模型
1、创建目标文件夹
打开终端,执行以下命令创建一个文件夹(例如 ~/ollama_deepseek)并进入:
# 创建文件夹
mkdir -p ~/ollama_deepseek
# 进入文件夹
cd ~/ollama_deepseek2、下载及安装 Ollama
curl -# -L -o ollama-linux-amd64.tar.zst https://cnb.cool/hex/ollama/-/releases/latest/download/ollama-linux-amd64.tar.zst输出如下内容即表示下载成功:
3、安装解压工具 zstd(如果尚未安装)
(在 ~/ollama_deepseek 目录中执行)
# 验证是否安装zstd
zstd --version
# 下载并安装 zstd
sudo apt update && sudo apt install zstd -y输出如下内容即表示下载安装成功:
4、解压文件
# 解压到当前目录(会得到 ollama-linux-amd64 二进制文件)
tar -I zstd -xvf ollama-linux-amd64.tar.zst
# 回到 ~/ollama_deepseek 目录
cd ~/ollama_deepseek
# 方法一:直接使用 bin/ollama(不复制)
./bin/ollama --version输出如下内容:
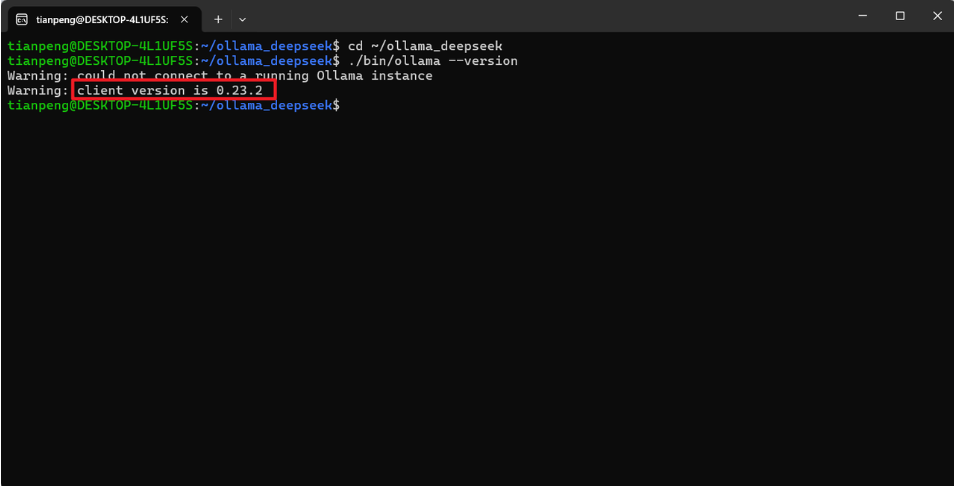
好的,你现在已经成功得到了 ollama 客户端(版本 0.23.2),接下来只需要启动服务即可运行模型。
5、设置必要的环境变量(每次新终端都需要,或写入 ~/.bashrc)
# 设置库文件路径(让 ollama 能找到 lib/ 里的 .so 文件)
export LD_LIBRARY_PATH="$HOME/ollama_deepseek/lib:$LD_LIBRARY_PATH"
# 创建模型存储目录
mkdir -p "$HOME/ollama_deepseek/models"
# 设置模型存储目录(可选,但建议指定到自己的文件夹)
export OLLAMA_MODELS="$HOME/ollama_deepseek/models"
# 创建模型目录
mkdir -p "$OLLAMA_MODELS"为了让这些环境变量永久生效,可以把上面两行 export 命令添加到 ~/.bashrc 文件中:
echo 'export LD_LIBRARY_PATH="$HOME/ollama_deepseek/lib:$LD_LIBRARY_PATH"' >> ~/.bashrc
echo 'export OLLAMA_MODELS="$HOME/ollama_deepseek/models"' >> ~/.bashrc
source ~/.bashrc6、启动 Ollama 服务(后台运行)
# 启动服务,并将日志输出到 ollama.log
./bin/ollama serve > ollama.log 2>&1 &-
执行后会返回一个进程号,例如
[1] 12345。 -
你可以用
jobs或ps aux | grep ollama确认服务是否在运行。
出现如下图的内容即表示服务成功启动:
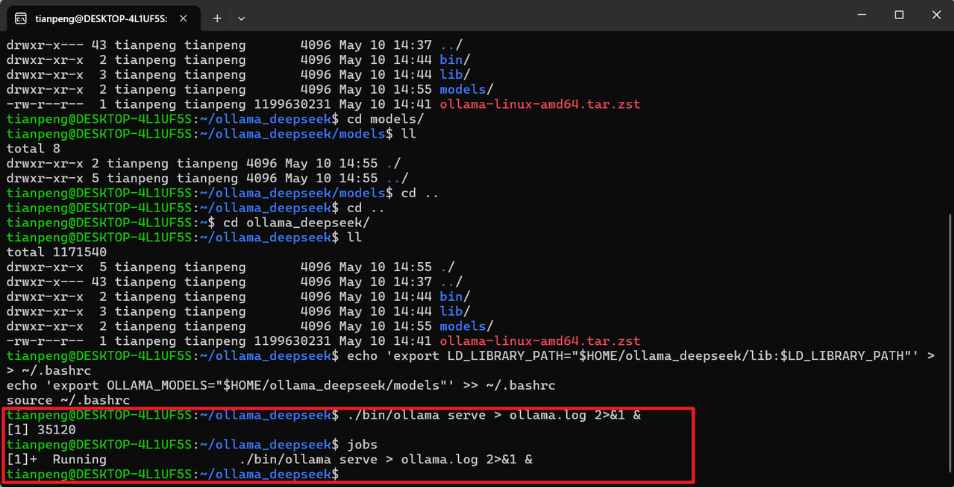
7、验证服务是否成功启动
# 再次查看版本,如果没有“could not connect”警告,说明服务正常
./bin/ollama --version如果仍然提示 Warning: could not connect,请检查 ollama.log 中的错误信息:
cat ollama.log常见错误及解决办法:
-
error while loading shared libraries→ 说明LD_LIBRARY_PATH没设对,重新执行步骤1。 -
bind: address already in use→ 说明端口被占用,可以pkill ollama后重新启动,或换端口(一般不必须)。
8、运行 DeepSeek 模型(以 deepseek-r1:7b 为例)
进入项目目录下,执行如下命令:
./bin/ollama run deepseek-r1:7b-
首次运行会自动下载模型文件(约 4-5 GB),下载过程会有进度条显示。
-
下载完成后自动进入对话界面,输入问题即可与模型对话。
-
输入
/bye退出对话。
如果一切顺利,你会看到模型下载进度并进入对话。
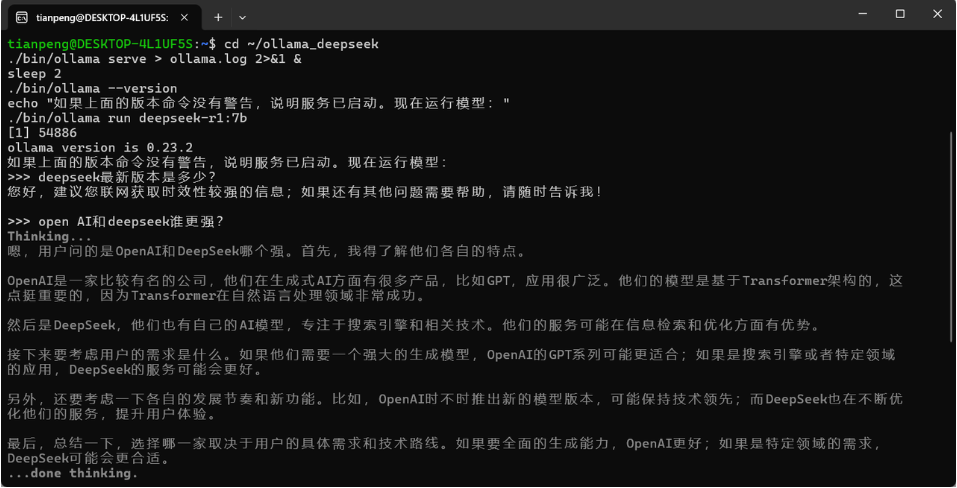
>>> 请用一句话介绍什么是人工智能?输出如下内容:
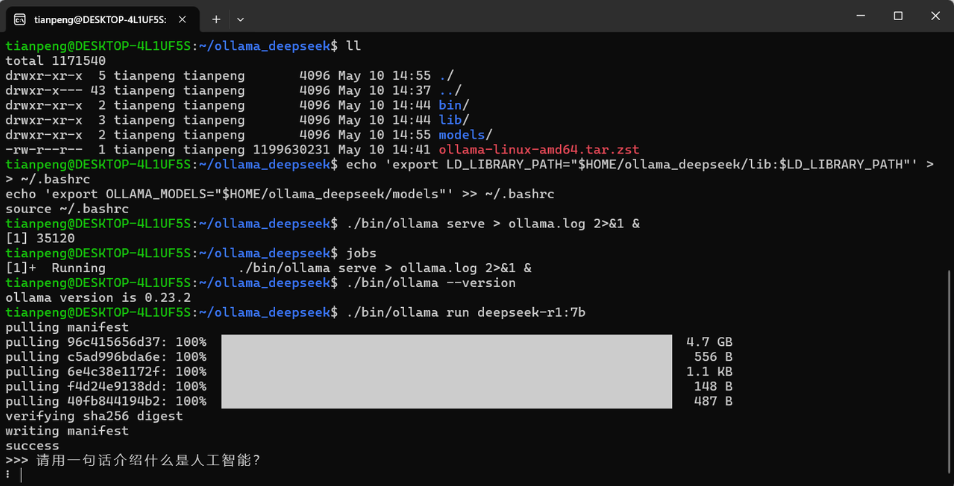
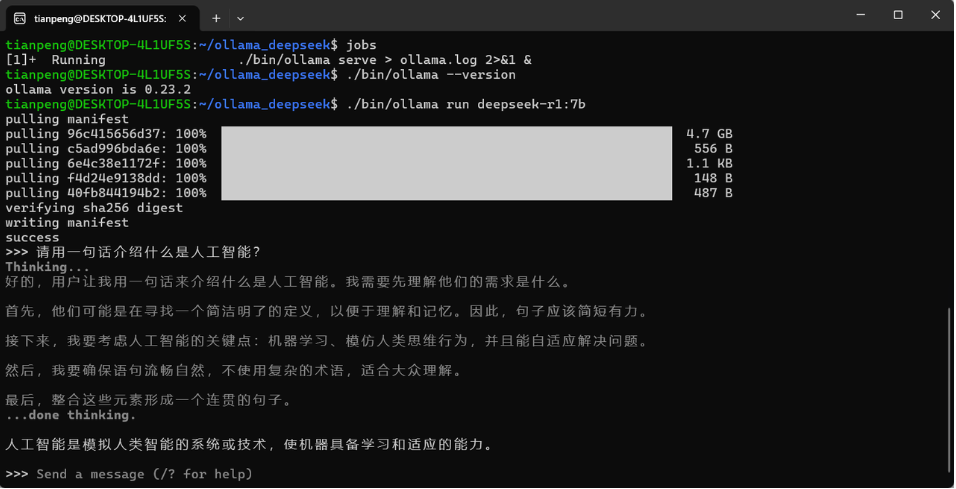
9、补充说明
-
如果模型下载很慢:可以设置代理,或者使用国内镜像(如 modelscope)手动下载模型文件。
-
停止 Ollama 服务:执行
pkill ollama。 -
重启服务:先
pkill ollama,再执行第6步的命令。
10、你现在可以直接执行以下命令用于启动 ollama 和 deepseek 大模型(一次性复制粘贴)
cd ~/ollama_deepseek
./bin/ollama serve > ollama.log 2>&1 &
sleep 2
./bin/ollama --version
echo "如果上面的版本命令没有警告,说明服务已启动。现在运行模型:"
./bin/ollama run deepseek-r1:7b执行上述命令后,输出如下内容:
按照你提供的 4.5 个人部署可选操作:配置 API 访问与监控 章节内容,结合你已经完成的 DeepSeek 环境(Ollama 位于 ~/ollama_deepseek/bin/ollama,尚未配置为 systemd 服务),以下是完整的适配处理步骤。
5.5 个人部署可选操作:配置 API 访问与监控
本操作基于你已经成功部署并能够手动运行
deepseek-r1:7b模型的前提。
5.5.1 修改配置监听全网(让 API 可被外部调用)
为了模拟企业环境中的网络访问,我们需要让 Ollama 监听所有网络接口。由于你的 Ollama 尚未作为系统服务运行,我们首先将其注册为 systemd 服务,然后修改配置。
步骤 1:创建 Ollama systemd 服务
# 使用 --force --full 创建完整的服务单元文件
sudo systemctl edit --force --full ollama.service在弹出的编辑器(如 nano)中粘贴以下内容(请将 User= 后的用户名改为你自己的,例如 tianpeng):
[Unit]
Description=Ollama AI Model Server
After=network.target
[Service]
Type=simple
User=tianpeng
Environment="LD_LIBRARY_PATH=/home/tianpeng/ollama_deepseek/lib"
Environment="OLLAMA_MODELS=/home/tianpeng/ollama_deepseek/models"
ExecStart=/home/tianpeng/ollama_deepseek/bin/ollama serve
Restart=on-failure
RestartSec=10
[Install]
WantedBy=multi-user.target保存退出(nano 中按 Ctrl+O,Enter,Ctrl+X)。
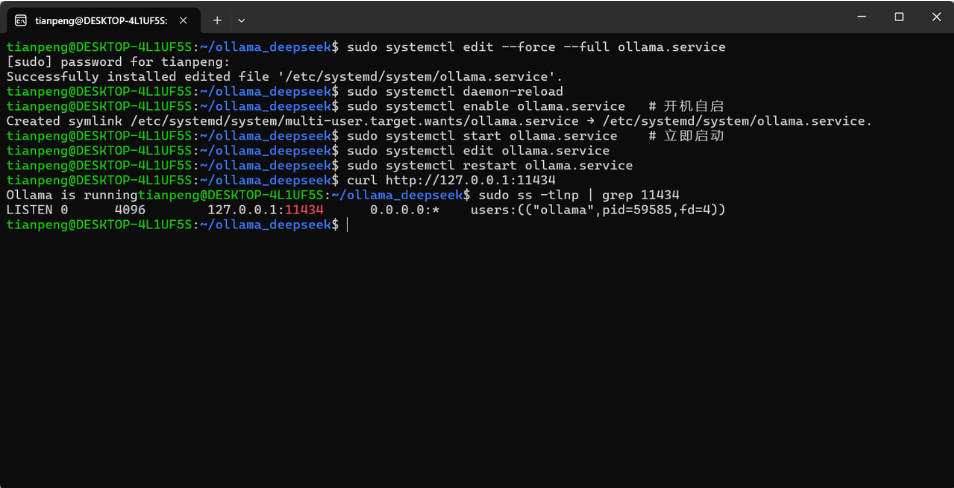
步骤 2:启动并启用服务
sudo systemctl daemon-reload
sudo systemctl enable ollama.service # 开机自启
sudo systemctl start ollama.service # 立即启动步骤 3:修改服务配置,让 Ollama 监听所有网络接口
sudo systemctl edit ollama.service在打开的覆盖配置文件中输入以下两行:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"保存退出后,重启服务:
sudo systemctl restart ollama.service步骤 4:验证服务是否已启动并监听全网
# 测试本地 API 是否响应
curl http://127.0.0.1:11434
# 查看监听端口(应显示 0.0.0.0:11434)
sudo ss -tlnp | grep 11434如果 curl 返回类似 Ollama is running 的消息,说明配置成功。现在 Ollama 已准备就绪,可以接受来自外部(其他机器)的 API 请求。
注意:如果你的电脑有防火墙,可能需要放行
11434端口。WSL 环境下通常无需额外配置。
5.5.2 通过 Python 脚本调用 API
新建一个 test_ollama_api.py 文件,用于测试本地的 DeepSeek 7B 模型。
(1)环境准备:安装 openai Python 库
# 安装 pip(如果尚未安装)
sudo apt install python3-pip -y
# 步骤 1:安装虚拟环境工具(如果尚未安装)
sudo apt update
sudo apt install python3-venv python3-full -y
# 步骤 2:在项目目录中创建虚拟环境
cd ~/ollama_deepseek/large_model_projec/test_ollama_deepseek_first
python3 -m venv venv
# 步骤 3:激活虚拟环境
source venv/bin/activate
# 步骤 4:在虚拟环境中安装 openai 库
pip install openai(2)编写测试脚本
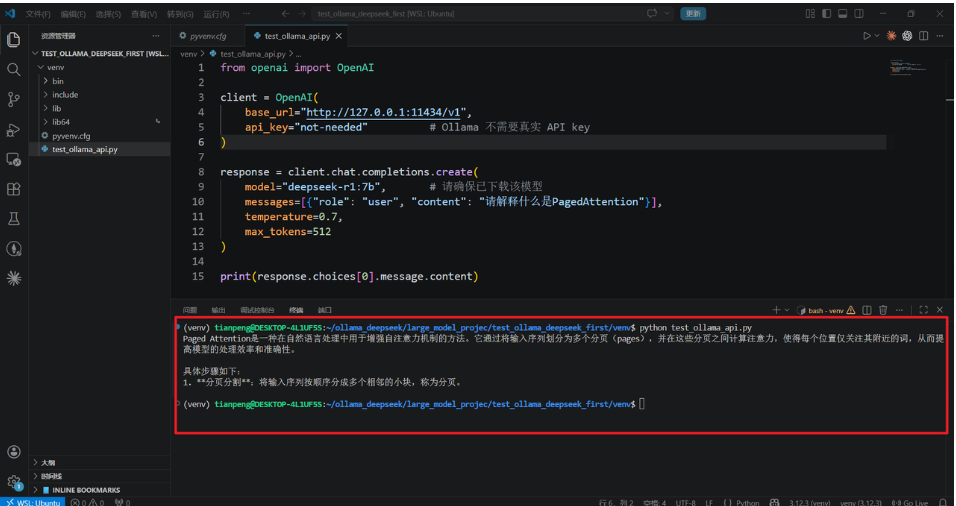
在任意目录(例如 ~/ollama_deepseek/)创建 test_ollama_api.py,内容如下:
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:11434/v1",
api_key="not-needed" # Ollama 不需要真实 API key
)
response = client.chat.completions.create(
model="deepseek-r1:7b", # 请确保已下载该模型
messages=[{"role": "user", "content": "请解释什么是PagedAttention"}],
temperature=0.7,
max_tokens=512
)
print(response.choices[0].message.content)运行脚本
python test_ollama_api.py如果一切正常,你会看到 DeepSeek 模型对“PagedAttention”的解释。如下图所示:
可能遇到的问题:
如果提示
ModuleNotFoundError: No module named 'openai',请检查pip3 install openai是否执行成功,或尝试python3 -m pip install openai --user。如果连接失败,确认 Ollama 服务正在运行:
sudo systemctl status ollama。如果模型未下载,Ollama 会自动拉取,但建议提前运行
ollama run deepseek-r1:7b完成下载。
(3)扩展:监控 API 访问(可选)
Ollama 本身不提供图形化监控面板,但你可以:
-
查看实时日志:
journalctl -u ollama.service -f -
统计 API 请求:通过分析日志
journalctl -u ollama.service --since today | grep "POST /api/generate"。
总结,你现在已经:
(1)将 Ollama 配置为 systemd 服务,实现开机自启和便捷管理。
(2)让 Ollama 监听全网接口,允许 API 远程调用。
(3)使用 Python 通过 OpenAI 兼容接口访问本地 DeepSeek 模型。
这些操作将本地模型无缝集成到你的 AI 应用开发流程中,你可以继续基于此搭建聊天机器人、API 网关等更高级的应用。
(4)监控 GPU 状态(可选):在 WSL2 的 Ubuntu 终端中,你可以使用 nvidia-smi 命令来查看 GPU 的运行状态。如果命令未找到,说明需要安装 NVIDIA 驱动,可参考下一节的步骤。
如果需要更专业的监控(如 Prometheus + Grafana),可以编写一个简单的 metrics 采集器,但这不是个人部署的必需项。
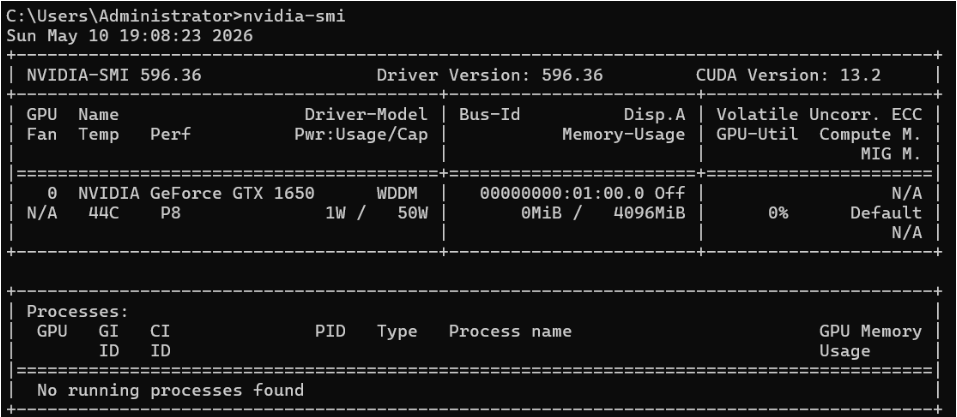
5.6 Windows + WSL2 环境下 NVIDIA 显卡支持
5.6.1 先确定Window系统中的驱动版本
在window命令行窗口执行如下命令,查看NVIDIA-SMI版本:
nvidia-smi输出如下的内容:
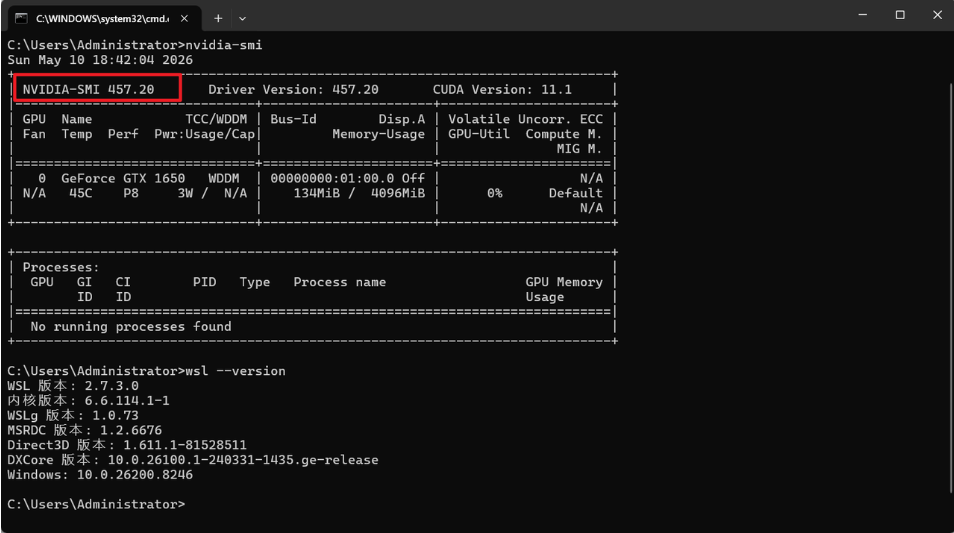
Windows NVIDIA 驱动版本是 457.20,这个版本太老了,不支持 WSL2 的 GPU 直通功能。
通过下面步骤来完成更新:
(1)访问 NVIDIA 官方驱动下载页面:https://www.nvidia.com/Download/index.aspx
(2)产品类型:选择 GeForce。
(3)产品系列(Product Series):这是最关键的一步,需要根据你的电脑类型选择:
-
如果你的显卡是笔记本版本:请务必选择
GeForce GTX 16 Series **(Notebooks)**。必须选择带“Notebooks”后缀的选项,否则驱动可能无法正常工作。 -
如果你的显卡是台式机版本:请选择
GeForce GTX 16 Series。
(4)产品家族(Product Family):在列表中会看到多个型号,请选择 GeForce GTX 1650。
(5)操作系统:根据你的实际系统,选择 Windows 10 64-bit。
(6)语言选择Chinese (Simplified)(简体中文)
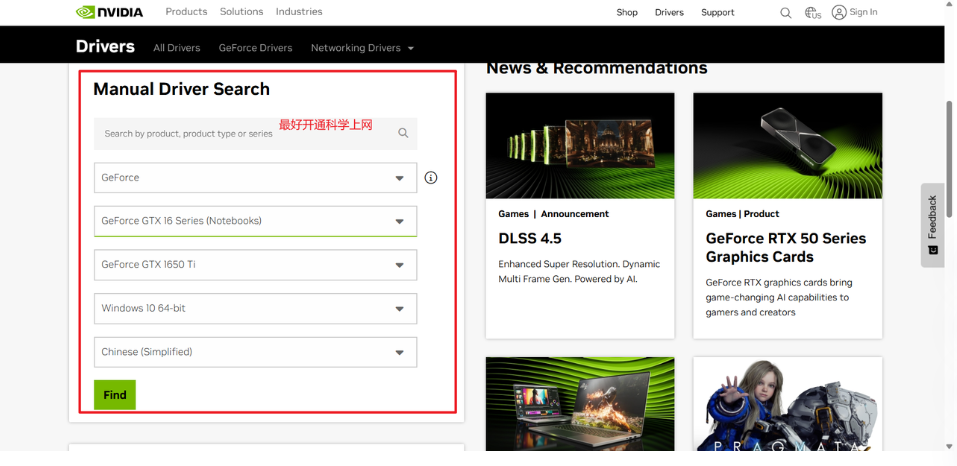
(7)下载类型(Download Type):这里建议选择 Game Ready Driver (GRD),它主要为游戏优化,性能更稳定。如果你主要进行视频剪辑、3D建模、AI开发等工作,可以选择 Studio Driver (SD)。
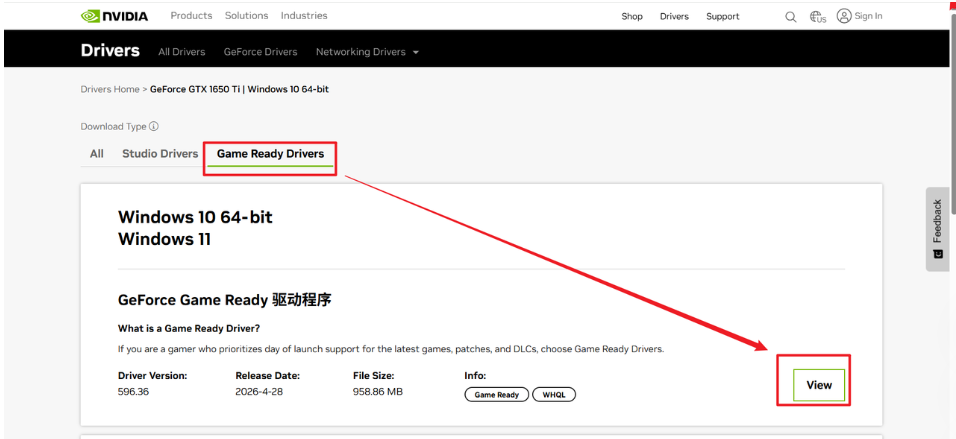
完成这些选择后,点击“开始搜索”,页面就会列出适合的驱动。为了确保能顺利开启 GPU 直通,建议选择 560.70 或更新的版本。选择后,点击“下载”即可。
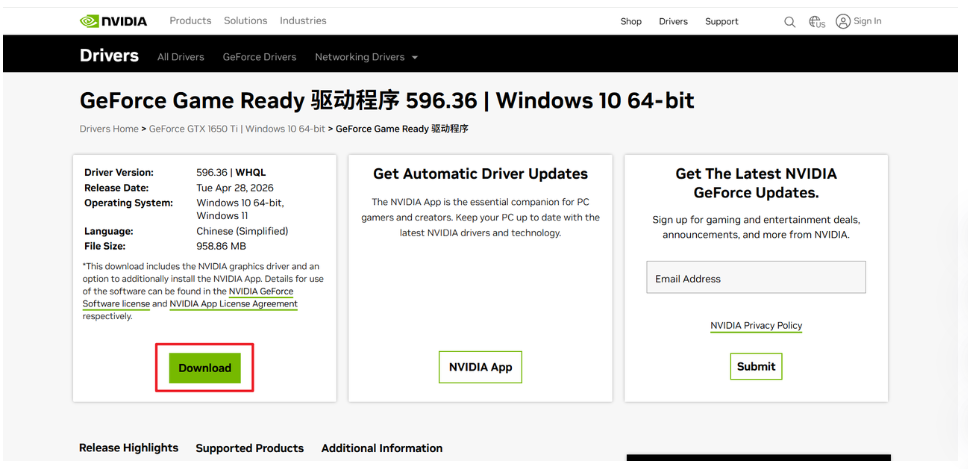
下载完以后双击安装包进行安装即可:
安装完成后再次验证版本。输入如下的命令:
nvidia-smi输出如下内容,即表示版本更新成功,下载为:596.36
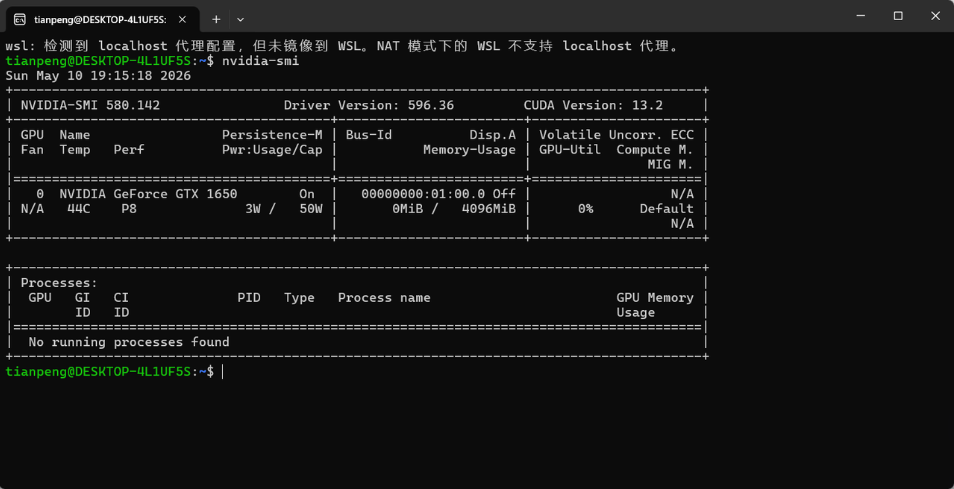
在WSL中输入如下的命令:
# 执行如下命令,如果显示 command not found,则执行下面两条命令后再来执行这条命令。
nvidia-smi
# 刷新软件包列表,让系统知道有哪些软件可用
sudo apt update
# 安装 NVIDIA 的命令行工具(如 nvidia-smi)到 WSL 内
sudo apt install nvidia-utils-550 -y输出如下内容,表示WSL能和window中的NVIDIA通信。
5.6.2 在WSL中配置NVIDIA驱动
为了让 Docker 或 WSL2 中的程序能充分利用你的 GTX 1650 显卡进行加速,需要安装 NVIDIA 官方提供的 CUDA 驱动。
步骤 1:下载密钥并保存到系统密钥目录
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg步骤 2:验证密钥文件是否创建成功
ls -l /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg你应该会看到类似 -rw-r--r-- 1 root root ... 的输出,证明文件已存在。
步骤3:清理并配置软件源
# 为了确保配置是干净的,先删除旧的源文件,再重新创建一个。(如果之前没有创建就不需要这步)
sudo rm -f /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 创建新的源文件,并指定我们刚才下载的密钥
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list命令解释:此命令的关键在于,通过 sed 动态修改了下载的.list文件内容,用 signed-by 参数指定了我们在第 1 步中放置的密钥文件
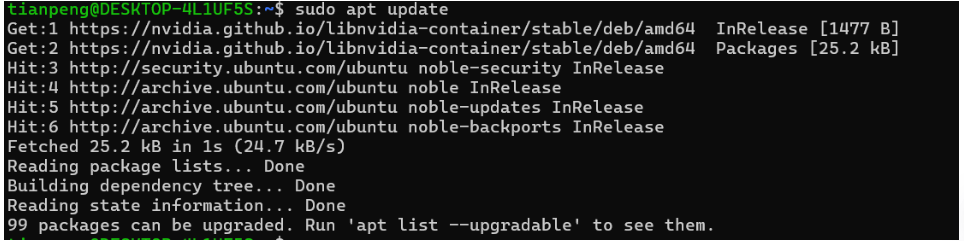
步骤4:重新更新软件源
sudo apt update运行成功后,输出如下内容:
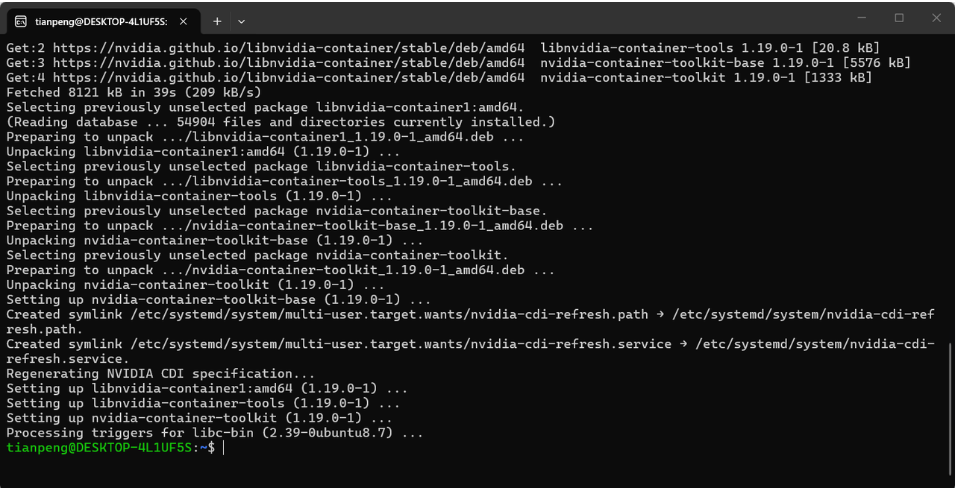
步骤 5:安装 nvidia-container-toolkit
sudo apt install -y nvidia-container-toolkit成功后输出如下内容:
步骤 6:配置 Docker 运行时
sudo nvidia-ctk runtime configure --runtime=docker输出如下内容即表示成功:

步骤 7:安装并启动 Docker 服务
# 使用阿里云的 Docker 安装脚本镜像
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
#
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
#
sudo apt update
#
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin为 Docker 配置国内的镜像加速器,就像给请求配一个“高速公路收费站”,让数据从更近、更通畅的国内节点走,是解决网络延迟最直接的办法。
(1)编辑 Docker 配置文件 /etc/docker/daemon.json: 你可以使用 nano 这个更方便的编辑器来修改文件。如果你还没有这个编辑器。
# 可以通过如下命令快速安装
sudo apt update && sudo apt install nano -y
sudo nano /etc/docker/daemon.json(2)设置第三方镜像源:
将现有内容全部替换或添加上下文中的 JSON 内容。这里是目前比较可靠的几个国内 Docker Hub 镜像源,你可以根据网络测试选择一个组合:
{
"registry-mirrors": [
"https://docker.1panel.live"
],
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
💡 推荐多个源组合:为了提高稳定性,可以考虑配置多个镜像源。除了
docker.1panel.live,你也可以在"registry-mirrors"这个列表里加上"https://docker.unsee.tech"或"https://docker.m.daocloud.io"作为备用。
(3)重启 Docker 服务: 保存文件(按 Ctrl+X,然后按 Y 确认,最后按 Enter 键返回命令行),然后执行:
# 启动 Docker 服务
sudo systemctl start docker
sudo systemctl enable docker
# 验证 Docker 是否安装成功
sudo docker run hello-world输出入下内容:
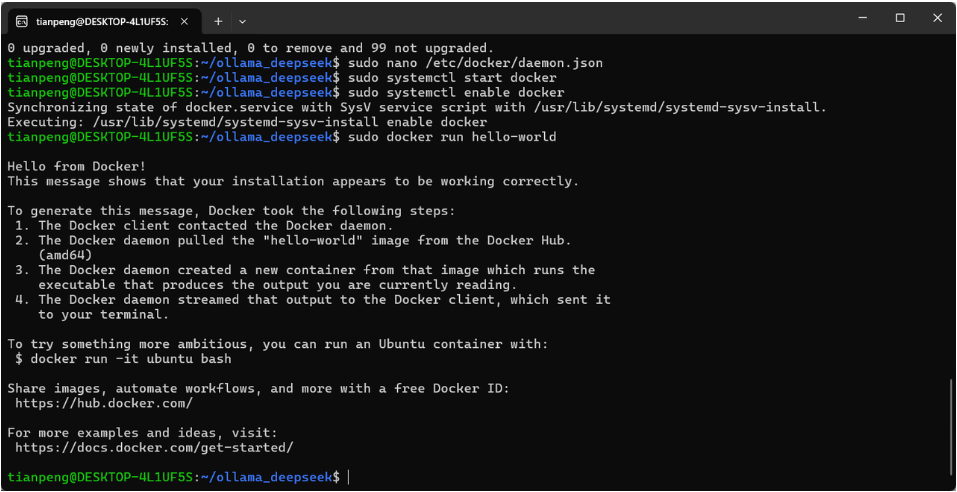
步骤 8:验证 GPU 是否可以被 Docker 识别
sudo docker run --rm --gpus all nvidia/cuda:12.1.0-runtime-ubuntu22.04 nvidia-smi如果成功,你会看到类似 nvidia-smi 的显卡信息输出:
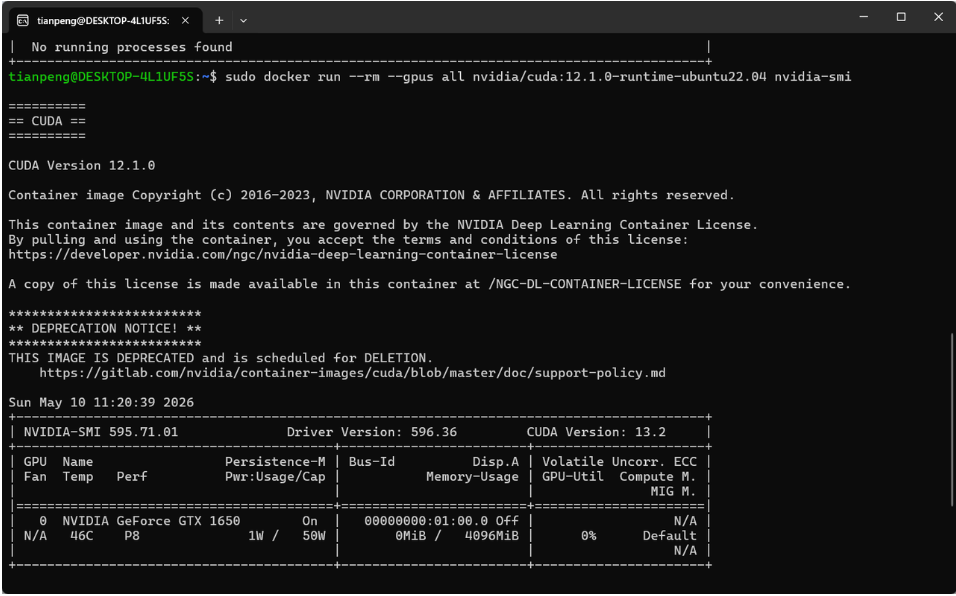
步骤九:验证 Ollama 能否调用 GPU:启动 Ollama 服务,运行 deepseek-r1:7b,用 nvidia-smi 观察显存占用。
在 Ollama 中运行 DeepSeek 模型
你已经通过独立安装(非 Docker)的方式部署了 Ollama,现在可以放心使用它来运行模型,GPU 会被自动调用。
进入 Ollama 目录并启动服务:
cd ~/ollama_deepseek
export LD_LIBRARY_PATH="$HOME/ollama_deepseek/lib:$LD_LIBRARY_PATH"
export OLLAMA_MODELS="$HOME/ollama_deepseek/models"
./bin/ollama serve > ollama.log 2>&1 &
运行 DeepSeek 7B 模型(首次会下载约 4.5GB):
./bin/ollama run deepseek-r1:7b可以在另一个终端用 watch -n 1 nvidia-smi 观察 GPU 显存占用,确认模型正在使用 GPU。
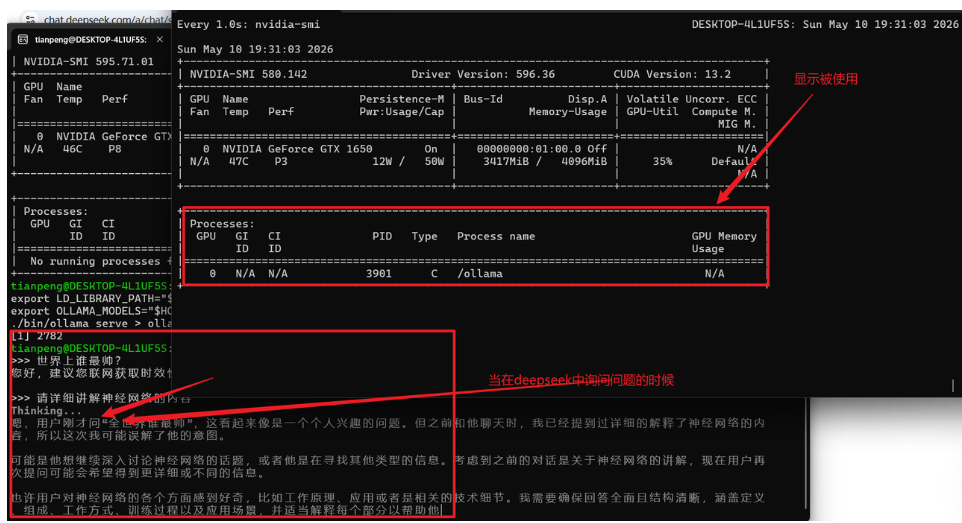
总结:通过以上步骤,你完成安装正确的版本。之后 Docker 将能够调用宿主机 GPU,为后续部署 vLLM 等需要 GPU 加速的 AI 服务做好准备。
第六章:企业级生产环境部署方案 — 基于 vLLM 和 Docker / Kubernetes
在企业级生产环境中,部署一个高性能、高可用的模型推理服务,除了核心的模型推理引擎本身,还需要一套完善的工程化基础设施来保障。这通常包括:CI/CD 模型拉取与校验流程、容器化部署编排、TLS 加密与 API 认证、并发限流与负载均衡、自动伸缩策略,以及全方位的监控与告警。本章将逐一详细介绍这些关键环节的具体落地细节与配置。
6.1 生产环境部署与个人环境的关键区别
|
维度 |
个人开发 |
企业生产环境 |
|---|---|---|
|
模型获取 |
手动下载、反复重试 |
CI/CD 自动拉取、内网模型仓库、文件完整性校验 |
|
环境管理 |
手动 pip install,虚拟环境 |
Docker/Kubernetes 声明式部署,环境完全一致 |
|
配置管理 |
命令行参数,手动调试 |
环境变量、ConfigMap、Secrets、配置中心(如 Vault) |
|
服务管理 |
前台进程,Ctrl+C 停止 |
systemd/Kubernetes 管理,自动重启,滚动更新 |
|
安全加固 |
基本本地访问 |
TLS 加密、API Key 认证、限流、网络策略隔离 |
|
高可用 |
无 |
多副本部署,负载均衡,自动故障转移 |
|
监控告警 |
nvidia-smi 手动查看 |
Prometheus + Grafana + Alertmanager,自动采集与告警 |
|
日志管理 |
终端输出,易丢失 |
持久化日志,集中采集至 ELK/Loki |
|
并发管控 |
单线程,无控制 |
HPA 自动伸缩、Ingress 限流、连接数限制 |
6.2 第一步:硬件与系统环境规划
6.2.1 硬件选型
|
模型规模 |
推荐 GPU |
显存需求 |
典型配置 |
|---|---|---|---|
|
1.5B~3B |
NVIDIA RTX 4090/A5000 |
8~12 GB |
1 卡,16 核 CPU,64 GB 内存 |
|
7B |
NVIDIA A10/A100 40GB |
28 GB (FP16) |
1 卡,16 核 CPU,64 GB 内存 |
|
14B |
NVIDIA A100 80GB |
56 GB (FP16) |
1~2 卡,32 核 CPU,128 GB 内存 |
|
32B/70B |
多卡 A100 80GB/H100 |
>120 GB |
2~8 卡,64 核 CPU,256 GB+ 内存 |
|
671B (满血版) |
8×H100/H200 80GB |
1.3 TB |
8 卡集群,分布式推理 |
本案例以 DeepSeek‑R1‑Distill‑Qwen‑14B 为例,选择 1×A100 80GB 服务器作为单节点部署,2×A100 80GB 作为 K8s 集群节点示例。
6.2.2 操作系统与驱动
-
OS:Ubuntu 22.04 LTS(服务器版,长期支持)
-
NVIDIA 驱动:535.xx 或更高,支持 CUDA 12.2+
-
容器运行时:Docker 24.0+ + nvidia-container-toolkit
-
Kubernetes 版本:v1.29+ (可选,用于多机集群)
-
网络:10 Gbps 内网,低延迟
6.3 第二步:单机生产部署 - Docker Compose 方案
适用于中小规模业务(<200 QPS),或作为多机方案的基础验证。
6.3.1 项目结构
/opt/vllm_production/
├── docker-compose.yml # 服务编排
├── .env # 全局环境变量
├── models/ # 模型存储 (只读挂载)
│ └── deepseek‑r1‑14b/
├── config/
│ ├── nginx/
│ │ └── default.conf # 反向代理配置
│ ├── prometheus/
│ │ └── prometheus.yml # 监控配置
│ └── alertmanager/
│ └── alertmanager.yml # 告警路由
├── scripts/
│ └── download_model.sh # 模型下载脚本(CI/CD调用)
└── logs/ # 容器日志挂载6.3.2 模型准备:自动化拉取与完整性校验
在生产环境中,模型文件不会通过手动下载获取,而是通过自动化脚本从制品库或镜像站同步,并在流水线中校验完整性。
scripts/download_model.sh(模型下载与校验脚本)
#!/bin/bash
# ============================================================
# 脚本: download_model.sh
# 用途: 从 HuggingFace 或私有模型仓库下载指定版本模型,并校验完整性
# 执行环境: CI/CD 流水线中由 GitHub Actions 或 GitLab CI 调用
# ============================================================
set -e
# ---------- 可配置参数 ----------
MODEL_NAME="deepseek-ai/DeepSeek-R1-Distill-Qwen-14B"
LOCAL_DIR="/opt/vllm_production/models/deepseek-r1-14b"
REVISION="main" # 可指定特定 commit hash 或 tag
HF_ENDPOINT="${HF_ENDPOINT:-https://hf-mirror.com}" # 国内加速镜像
export HF_ENDPOINT
# ---------- 函数:校验关键文件完整性 ----------
verify_model_files() {
local dir="$1"
# 检查 config.json(模型架构定义)
if [ ! -f "$dir/config.json" ]; then
echo "ERROR: config.json not found in $dir"
return 1
fi
# 检查 tokenizer 文件(分词器)
if [ ! -f "$dir/tokenizer.json" ] && [ ! -f "$dir/tokenizer.model" ]; then
echo "ERROR: tokenizer files not found"
return 1
fi
# 检查权重文件(至少有一个 .safetensors)
if ! find "$dir" -name "*.safetensors" | head -1 | grep -q .; then
echo "ERROR: no weight file (.safetensors) found"
return 1
fi
# 检查 config.json 是否为有效 JSON(vLLM 严格要求)
if ! python3 -c "import json; json.load(open('$dir/config.json'))" 2>/dev/null; then
echo "ERROR: config.json is not valid JSON"
return 1
fi
echo " Model verification PASSED"
return 0
}
# ---------- 主流程 ----------
echo "========== Model Download Pipeline =========="
echo "Model: $MODEL_NAME"
echo "Target: $LOCAL_DIR"
echo "Date: $(date)"
# 1. 下载模型(huggingface-cli 自动处理断点续传)
echo "[1/3] Downloading model..."
huggingface-cli download "$MODEL_NAME" --local-dir "$LOCAL_DIR" --revision "$REVISION"
# 2. 校验完整性
echo "[2/3] Verifying model files..."
if verify_model_files "$LOCAL_DIR"; then
echo " Model verification PASSED"
else
echo "FATAL: Model verification FAILED — aborting deployment"
exit 1
fi
# 3. 记录版本元信息(便于追溯)
echo "[3/3] Saving version metadata..."
{
echo "model_name=$MODEL_NAME"
echo "revision=$REVISION"
echo "download_date=$(date -Iseconds)"
echo "commit_hash=$(git -C $LOCAL_DIR log -1 --format='%H' 2>/dev/null || echo 'unknown')"
} > "$LOCAL_DIR/version.txt"
echo "========== Pipeline SUCCESS =========="为什么要做完整性校验? 模型文件可能因网络波动或存储故障而导致部分文件损坏或缺失。在企业中,一个损坏的配置文件(例如空文件)会导致 vLLM 无法启动,这在生产环境中是不可接受的。因此,CI/CD 流水线中必须对模型文件进行完整性校验,确保关键文件存在且有效。
6.3.3 Docker Compose 编排
# docker-compose.yml
version: '3.8'
services:
# ========== vLLM 推理服务 ==========
vllm:
image: vllm/vllm-openai:latest # 官方镜像,包含 CUDA 等依赖
container_name: vllm-inference
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
- HUGGING_FACE_HUB_TOKEN=${HF_TOKEN:-}
ports:
- "8000:8000"
volumes:
- ./models:/models:ro # 模型只读挂载,防止运行时意外修改
- ./logs:/var/log/vllm # 日志持久化到宿主机
command: >
--model /models/deepseek-r1-14b
--host 0.0.0.0
--port 8000
--dtype float16
--gpu-memory-utilization 0.90
--max-model-len 8192
--enable-prefix-caching
--api-key ${API_KEY}
restart: unless-stopped # 服务异常退出时自动重启
healthcheck: # 健康检查机制
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 30s
timeout: 10s
retries: 3
logging:
driver: "json-file"
options:
max-size: "100m" # 单个日志文件上限
max-file: "5" # 最多保留5个日志文件
networks:
- llm_net
# ========== Nginx 反向代理 + TLS ==========
nginx:
image: nginx:1.24-alpine
container_name: vllm-nginx
ports:
- "443:443"
volumes:
- ./config/nginx/default.conf:/etc/nginx/conf.d/default.conf:ro
- /etc/letsencrypt:/etc/letsencrypt:ro # TLS 证书
depends_on:
vllm:
condition: service_healthy # 等 vLLM 健康检查通过后再启动
restart: unless-stopped
networks:
- llm_net
# ========== Prometheus 监控 ==========
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./config/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports:
- "9090:9090"
restart: unless-stopped
networks:
- llm_net
# ========== Grafana 可视化 ==========
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_PASSWORD:-admin}
volumes:
- grafana-storage:/var/lib/grafana
restart: unless-stopped
networks:
- llm_net
networks:
llm_net:
driver: bridge
volumes:
grafana-storage:6.3.4 环境变量管理
# .env (仅示例,生产环境通过密钥管理服务如 HashiCorp Vault 注入)
API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
HF_TOKEN=hf_your_read_token_if_private_repos
GRAFANA_PASSWORD=YourStrongPass6.3.5 Nginx 配置:TLS + API Key 认证 + 限流 + 并发管控
# config/nginx/default.conf
# ============================================================
# 限流区域定义:
# api_limit: 每个客户端 IP 每秒最多 10 个请求
# burst=20: 允许突发 20 个请求排队处理(不丢弃)
# nodelay: 突发请求立即处理(不等待时间窗口)
# ============================================================
limit_req_zone $binary_remote_addr zone=api_limit:10m rate=10r/s;
# 并发连接数限制区域:每个 IP 最多 20 个并发连接
limit_conn_zone $binary_remote_addr zone=perip_conn:10m;
upstream vllm_backend {
server vllm:8000;
keepalive 64; # 保持 64 个长连接,减少 TCP 握手开销
}
server {
listen 443 ssl http2;
server_name llm-api.yourcompany.com;
ssl_certificate /etc/letsencrypt/live/llm-api.yourcompany.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/llm-api.yourcompany.com/privkey.pem;
ssl_protocols TLSv1.3;
location / {
# ------ API Key 认证 ------
# 只有携带正确 Bearer Token 的请求才能通过
if ($http_authorization != "Bearer ${API_KEY}") {
return 401 '{"error":"Unauthorized"}';
}
# ------ 限流控制 ------
limit_req zone=api_limit burst=20 nodelay;
# ------ 并发连接数限制 ------
limit_conn perip_conn 20;
# ------ 反向代理到 vLLM ------
proxy_pass http://vllm_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_read_timeout 120s;
}
location /health {
proxy_pass http://vllm_backend/health;
}
}6.4 第三步:多机集群生产部署 - Kubernetes 方案
当单节点无法满足并发吞吐量或需要高可用时,应采用 Kubernetes 集群进行部署。
6.4.1 集群要求
-
Kubernetes v1.29+
-
GPU 节点已安装 NVIDIA GPU Operator,或至少安装 nvidia-device-plugin
-
集群内至少 2 个 GPU 节点,每个节点有 A100 80GB 或其他目标 GPU
-
共享存储:支持 ReadWriteMany 的持久卷(如 NFS、CephFS、JuiceFS),用于存储模型文件
-
Ingress Controller (如 nginx-ingress)
-
Prometheus Operator(推荐)用于监控
-
cert-manager(用于自动管理 TLS 证书)
6.4.2 模型存储与共享(PV + PVC)
在多节点环境中,模型文件需要被所有 Pod 访问。以下提供两种方案。
方案 A(生产推荐):NFS 共享存储
# model-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: model-pv
spec:
capacity:
storage: 100Gi
accessModes:
- ReadOnlyMany # 多 Pod 只读挂载,防止运行时意外修改
persistentVolumeReclaimPolicy: Retain
nfs:
server: 192.168.1.100 # NFS 服务器地址
path: /export/models
---
# model-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: model-pvc
spec:
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 100Gi方案 B:hostPath(仅适合单节点测试)
apiVersion: v1
kind: PersistentVolume
metadata:
name: model-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadOnlyMany
hostPath:
path: /models6.4.3 vLLM Deployment
# vllm-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-deployment
labels:
app: vllm
spec:
replicas: 2 # 2 个推理副本,提高并发与可用性
selector:
matchLabels:
app: vllm
template:
metadata:
labels:
app: vllm
spec:
# Pod 反亲和性:尽量将 vLLM Pod 调度到不同 GPU 节点上,提高容错
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: vllm
topologyKey: kubernetes.io/hostname
containers:
- name: vllm
image: vllm/vllm-openai:latest
resources:
limits:
nvidia.com/gpu: 1 # 每个 Pod 分配 1 张 GPU
requests:
nvidia.com/gpu: 1
memory: "32Gi"
cpu: "8"
env:
- name: API_KEY
valueFrom:
secretKeyRef:
name: vllm-api-key
key: key
ports:
- containerPort: 8000
name: http
args:
- "--model"
- "/models/deepseek-r1-14b"
- "--host"
- "0.0.0.0"
- "--port"
- "8000"
- "--dtype"
- "float16"
- "--gpu-memory-utilization"
- "0.90"
- "--max-model-len"
- "8192"
- "--enable-prefix-caching"
volumeMounts:
- name: model-volume
mountPath: /models
readOnly: true
livenessProbe: # 存活探针:检测容器是否正常运行
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60 # 容器启动后 60 秒开始检测
periodSeconds: 30 # 每 30 秒检测一次
failureThreshold: 3 # 连续失败 3 次则重启容器
readinessProbe: # 就绪探针:检测容器是否准备好接收流量
httpGet:
path: /health
port: 8000
initialDelaySeconds: 30 # 容器启动后 30 秒开始检测
periodSeconds: 10 # 每 10 秒检测一次
failureThreshold: 3 # 连续失败 3 次则从 Service 中摘除
volumes:
- name: model-volume
persistentVolumeClaim:
claimName: model-pvc
nodeSelector:
accelerator: nvidia-tesla-a100
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule6.4.4 Service 暴露
# vllm-service.yaml
apiVersion: v1
kind: Service
metadata:
name: vllm-service
spec:
selector:
app: vllm
ports:
- port: 8000
targetPort: 8000
protocol: TCP
type: ClusterIP6.4.5 Ingress 配置:TLS + 限流 + 并发管控
# vllm-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: vllm-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-prod # 自动签发证书
nginx.ingress.kubernetes.io/limit-rps: "10" # 每秒请求限流
nginx.ingress.kubernetes.io/limit-connections: "50" # 并发连接数限制
nginx.ingress.kubernetes.io/limit-burst-multiplier: "2" # 突发倍数
spec:
ingressClassName: nginx
tls:
- hosts:
- llm-api.yourcompany.com
secretName: llm-api-tls
rules:
- host: llm-api.yourcompany.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: vllm-service
port:
number: 8000API Key 认证:可在 Ingress 层通过 Lua 脚本(nginx.ingress.kubernetes.io/configuration-snippet)校验 Authorization 头,或使用 APISIX/Kong 等专用 API 网关实现更精细的认证和鉴权。对于生产环境,推荐使用 API 网关统一管理密钥、限流和审计日志。
6.4.6 HPA 自动伸缩配置
HPA(Horizontal Pod Autoscaler)可根据 GPU 利用率或自定义指标自动调整 Pod 副本数量。
# vllm-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: vllm-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: vllm-deployment
minReplicas: 2 # 最少 2 个副本,保证基础高可用
maxReplicas: 6 # 最多 6 个副本,防止无限扩展
metrics:
# 指标一:CPU 利用率
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
# 指标二:GPU 利用率(来自 Prometheus 自定义指标)
- type: Pods
pods:
metric:
name: gpu_utilization
target:
type: AverageValue
averageValue: 80
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # 缩容稳定窗口:5 分钟内不触发缩容
policies:
- type: Percent
value: 50 # 每次最多缩容 50%
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 60 # 扩容稳定窗口:1 分钟内聚合指标
policies:
- type: Percent
value: 100 # 每次最多扩容 100%(即翻倍)
periodSeconds: 60关键说明:默认 Kubernetes HPA 不支持 GPU 指标,需要配合 Prometheus Adapter 或 KEDA 将 vLLM 暴露的 GPU 指标(如 vllm:gpu_cache_usage_perc)注册为 Kubernetes 自定义指标,HPA 才能基于 GPU 利用率进行自动伸缩。配置步骤如下:
-
安装
prometheus-adapter -
创建
CustomMetricsConfig,将 vLLM Prometheus 指标映射到 K8s 指标名 -
在 HPA 中引用映射后的指标名
6.5 第四步:监控与可观测性
6.5.1 Prometheus 监控指标配置
# config/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'vllm'
static_configs:
- targets: ['vllm:8000'] # vLLM 内置的 /metrics 端点
metrics_path: '/metrics'
- job_name: 'nginx'
static_configs:
- targets: ['nginx-exporter:9113'] # Nginx Prometheus ExportervLLM 内建暴露的 Prometheus 指标主要包括:
|
指标 |
含义 |
告警参考 |
|---|---|---|
|
|
首 Token 延迟 |
P99 > 10s 时触发告警 |
|
|
每 Token 生成时间 |
> 100ms 时需关注 |
|
|
等待队列长度 |
> 50 时说明并发压力过大 |
|
|
GPU KV 缓存使用率 |
> 90% 时触发告警 |
|
|
生成 Token 总数 |
用于成本核算 |
|
|
请求错误总数 |
> 2% 时触发严重告警 |
6.5.2 Grafana 仪表盘
在 Grafana 中导入 vLLM 社区提供的模板(Grafana Dashboard ID: 19960),可监控 GPU 内存、吞吐量、延迟分布和请求错误率。
6.5.3 告警规则
# config/prometheus/alert_rules.yml
groups:
- name: vllm-alerts
rules:
- alert: VLLMHighErrorRate
expr: rate(vllm:request_errors_total[5m]) > 0.02
for: 5m
labels:
severity: critical
annotations:
summary: "vLLM error rate exceeds 2%"
- alert: VLLMHighLatency
expr: histogram_quantile(0.99, rate(vllm:time_to_first_token_seconds_bucket[5m])) > 10
for: 5m
labels:
severity: warning
annotations:
summary: "P99 TTFT exceeds 10 seconds"
- alert: VLLMGPUMemoryHigh
expr: vllm:gpu_cache_usage_perc > 0.90
for: 5m
labels:
severity: warning
annotations:
summary: "GPU KV Cache usage above 90%"
- alert: VLLMQueueBacklog
expr: vllm:num_requests_waiting > 50
for: 3m
labels:
severity: warning
annotations:
summary: "Request queue backlog exceeds 50"6.6 第五步:日志管理与审计
6.6.1 日志收集架构
-
vLLM 容器日志输出到 stdout/stderr,由 Docker 或 K8s 采集
-
使用 Filebeat/Vector 采集至 Elasticsearch 或 Loki
-
关键审计日志字段:请求来源 IP、模型名称、输入/输出 Token 数、延迟
6.6.2 K8s 环境日志方案(Filebeat + Elasticsearch)
# filebeat-config.yaml
filebeat.inputs:
- type: container
paths:
- /var/log/containers/vllm-*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
# 提取关键字段
- dissect:
tokenizer: "%{timestamp} %{level} %{message}"
field: "message"
target_prefix: "vllm"
output.elasticsearch:
hosts: ["https://elasticsearch.logging.svc:9200"]
username: "elastic"
password: "${ES_PASSWORD}"
index: "vllm-logs-%{+yyyy.MM.dd}"6.7 第六步:性能调优与基准
6.7.1 单卡 14B 模型性能基线 (A100 80GB)
|
指标 |
预期值 |
说明 |
|---|---|---|
|
首 Token 延迟 (TTFT) |
~150 ms |
Prefill 阶段耗时 |
|
每 Token 延迟 (TPOT) |
~25 ms |
Decode 阶段耗时 |
|
吞吐量 (单流) |
40 tokens/s |
单个用户连续请求 |
|
并发吞吐量 (50 并发) |
约 800 tokens/s |
Continuous Batching 聚合吞吐 |
|
显存占用 |
~55 GB |
模型 28 GB + KV Cache 约 27 GB |
6.7.2 优化参数
|
参数 |
作用 |
调优建议 |
|
|
对长 prompt 分块处理 |
降低首 Token 延迟,对超长输入效果好 |
|
|
批次 token 数上限 |
增大可提升吞吐,但增加延迟,需根据 SLO 调优 |
|
|
同时处理序列数上限 |
显存不足时降低,避免 OOM |
|
|
复用重复前缀的 KV Cache |
对系统提示词固定的场景效果显著 |
6.8 第七步:CI/CD 部署流水线
企业应通过 CI/CD 自动构建、测试和部署模型服务,而非手动操作。
6.8.1 流水线阶段
-
模型拉取与校验:运行
download_model.sh,校验config.json、tokenizer 和权重文件完整性 -
构建测试:启动 vLLM 容器,发送标准查询,验证返回码为 200
-
性能冒烟测试:运行
vllm bench serve,确保吞吐量不低于基线值的 90% -
部署到环境:更新 K8s Deployment 或 Docker Compose 栈
-
健康检查:监控启动后 5 分钟内无异常,自动回滚条件为连续 3 次健康检查失败
6.8.2 GitHub Actions 工作流
# .github/workflows/deploy.yml
name: Deploy vLLM to Prod
on:
push:
branches: [main]
paths:
- 'models/**'
- 'docker-compose.yml'
- 'scripts/**'
jobs:
deploy:
runs-on: self-hosted
timeout-minutes: 30
steps:
- uses: actions/checkout@v4
# ========== 阶段 1: 模型拉取与校验 ==========
- name: Download and verify model
run: |
bash scripts/download_model.sh
# ========== 阶段 2: 构建测试 ==========
- name: Build and smoke test
run: |
docker compose up -d vllm
# 等待服务就绪(最多 120 秒)
for i in $(seq 1 24); do
if curl -s --fail http://localhost:8000/health > /dev/null 2>&1; then
echo "vLLM is ready"
break
fi
echo "Waiting for vLLM... ($i/24)"
sleep 5
done
# 发送标准查询
response=$(curl -s -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${API_KEY}" \
-d '{
"model": "deepseek-r1-14b",
"messages": [{"role": "user", "content": "Hi"}],
"max_tokens": 10
}')
if echo "$response" | grep -q "choices"; then
echo "Smoke test PASSED"
else
echo "Smoke test FAILED: $response"
exit 1
fi
# ========== 阶段 3: 性能冒烟测试 ==========
- name: Performance smoke test
run: |
vllm bench serve \
--model deepseek-r1-14b \
--endpoint /v1/chat/completions \
--num-prompts 50 \
--request-rate 5
# ========== 阶段 4: 部署 ==========
- name: Deploy to production
run: |
docker compose up -d --force-recreate
# ========== 阶段 5: 部署后健康检查 ==========
- name: Post-deploy health check
run: |
sleep 30
curl --fail http://localhost:8000/health
echo "Deployment verified"6.9 总结与检查清单
|
类别 |
检查项 |
说明 |
|---|---|---|
|
模型获取 |
自动化脚本 + 完整性校验 |
使用 |
|
容器化 |
官方 vLLM 镜像 + 只读卷挂载 |
环境一致性,防止运行时意外修改模型文件 |
|
安全 |
TLS 加密 + API Key + 限流 + 并发管控 |
Nginx/Ingress 反向代理,TLS 1.3,Bearer Token 认证 |
|
高可用 |
Deployment 多副本 + PodAntiAffinity + HPA |
自动扩缩,自动故障转移 |
|
监控 |
Prometheus 采集 + Grafana 可视化 + Alertmanager 告警 |
实时监控延迟、吞吐、显存、错误率 |
|
日志 |
Filebeat 集中采集至 ELK/Loki |
保留请求审计记录,满足合规要求 |
|
CI/CD |
GitHub Actions 自动化流水线 |
模型拉取 → 完整性校验 → 冒烟测试 → 部署 → 健康检查 |
通过本章的企业级方案,您可以在任何支持 Docker 或 Kubernetes 的集群上稳定运行大模型推理服务,从容应对生产环境的并发、安全和运维挑战。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)