论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读
今天带来的是由微软Edward Hu等人完成并发表在ICLR 2022上的论文《LoRA: Low-Rank Adaptation of Large Language Models》,论文提出了大模型 tuning 框架 **LoRA** (**Lo**w-**R**ank **A**daptation)。
论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读
今天带来的是由微软Edward Hu等人完成并发表在ICLR 2022上的论文《LoRA: Low-Rank Adaptation of Large Language Models》,论文提出了大模型 tuning 框架 LoRA (Low-Rank Adaptation)。
论文地址:https://openreview.net/pdf?id=nZeVKeeFYf9
附录下载地址:https://openreview.net/attachment?id=nZeVKeeFYf9&name=supplementary_material
代码地址:https://github.com/microsoft/LoRA
Background
一些术语介绍:
· Intrinsic Dimension(本征维度):An objective function’s intrinsic dimensionality describes the minimum dimension needed to solve the optimization problem it defines to some precision level. 是指在pre-trained LLM中,对于下游的tuning工作,实际上不需要对模型所有参数都进行更新,在保证某种精度(如90%)的要求下,可以只更新一部分就可以了(可称为 d 90 d_{90} d90)。
few-shot learning:少样本学习。借助于少样本学习,大模型在特定下游任务的训练过程中,只需要少数的特定任务数据就可以发挥不错的性能。
Prompt Engineering:提示工程。这是 LLM 在 NLP 应用中的特有应用,类似于特征工程,是一种需要专家背景知识,通过组织input的格式,风格等内容,使得输入内容对LLM能够具备更好的促进作用。
Adaptation:适应。也就是大模型对特定下游任务的tuning,使其能够在下游任务中性能更好。
Introduciton
本文提出的主要出发点在于 大模型 的训练模式,即先通过对 大量的 task-independent 语料的预训练,然后再在特定任务上进行精调 fine-tuning,使得模型能够在特定的下游任务中展现较好的表现。
这里就出现一个问题,大模型无论是在存储还是计算上,都是很大的,需要很大的算力和存储。Fine-tuning所有参数就会很费时费力。举例来说,GPT-3 175B总共包含175 billion个参数,也就是1750亿个,fine-tuning所有层,所有Transformer中的Q K V 和 output 矩阵加上 bias,可想而知是一个很大的开销。如何解决这个问题构成本文的 Motivation。
当然已经有诸多此类问题的解决方案。例如,Adapter Layer,也就是在Transformer中插入了两层Adapter Layer 来适应下游任务,只更新Adapter Layer 中的参数,原来的Transformer中的参数 不进行更新。这类模型的问题在于,Adapter Layer 和原来的大模型参数是从输入到输出上下夹在一起的(类似于汉堡),参数计算时必须从输入到输出一层一层进行。那么模型在推理的时候,就必然涉及到等上一层计算完才可以计算下一层,那么就带来了模型的延迟,影响模型体验。
作者提出了低秩矩阵乘法作为任意矩阵 W W W的 特定增量 Δ W \Delta W ΔW,通过只更新 Δ W \Delta W ΔW 的方式减小模型开销的同时,保住模型性能。
是的,模型就是这么“简单”,但是一方面模型的切入点非常犀利;另一方面模型性能不错且带来了巨大的 tuning 节省,让贫穷的学生党探索大模型时能够更自如一些;同时,本文的实验部分也非常充分(附录中),在不同benchmark中的表现都能够佐证LoRA模型的有效性。

Problem Statement
首先是问题形式化,对于fine-tuning,就是把预训练完成的所有参数checkpoint进行存储dump,在精调阶段,将所有参数初始化为dump出来的value,以此作为参数更新的起始点,完成模型优化。表示如下:
max
Φ
∑
(
x
,
y
)
∈
Z
∑
t
=
1
∣
y
∣
log
(
P
Φ
(
y
t
∣
x
,
y
<
t
)
)
(1)
\max _{\Phi} \sum_{(x, y) \in \mathcal{Z}} \sum_{t=1}^{|y|} \log \left(P_{\Phi}\left(y_{t} \mid x, y_{<t}\right)\right) \tag{1}
Φmax(x,y)∈Z∑t=1∑∣y∣log(PΦ(yt∣x,y<t))(1)
如上所示,通过对下游任务数据集
Z
\mathcal{Z}
Z 进行模型所有参数
Φ
\Phi
Φ 的更新。如果
Φ
{\Phi}
Φ 很大,那么fine-tuning 就会很麻烦。
对此,作者提出了只更新 task-specific 的 新引入的 少量的参数 Δ Φ = Δ Φ ( Θ ) \Delta \Phi = \Delta \Phi(\Theta) ΔΦ=ΔΦ(Θ),完成模型的tuning。这里 Θ \Theta Θ 是新参数,而且维度相比较于原LLM模型很小( ∣ Θ ∣ ≪ ∣ Φ 0 ∣ |\Theta| \ll |\Phi_{0}| ∣Θ∣≪∣Φ0∣。作者指出,LoRA能够将需要更新的参数数量缩小到万分之一的地步。
max Θ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( p Φ 0 + Δ Φ ( Θ ) ( y t ∣ x , y < t ) ) (2) \max _{\Theta} \sum_{(x, y) \in \mathcal{Z}} \sum_{t=1}^{|y|} \log \left(p_{\Phi_{0}+\Delta \Phi(\Theta)}\left(y_{t} \mid x, y_{<t}\right)\right) \tag{2} Θmax(x,y)∈Z∑t=1∑∣y∣log(pΦ0+ΔΦ(Θ)(yt∣x,y<t))(2)
Methodology
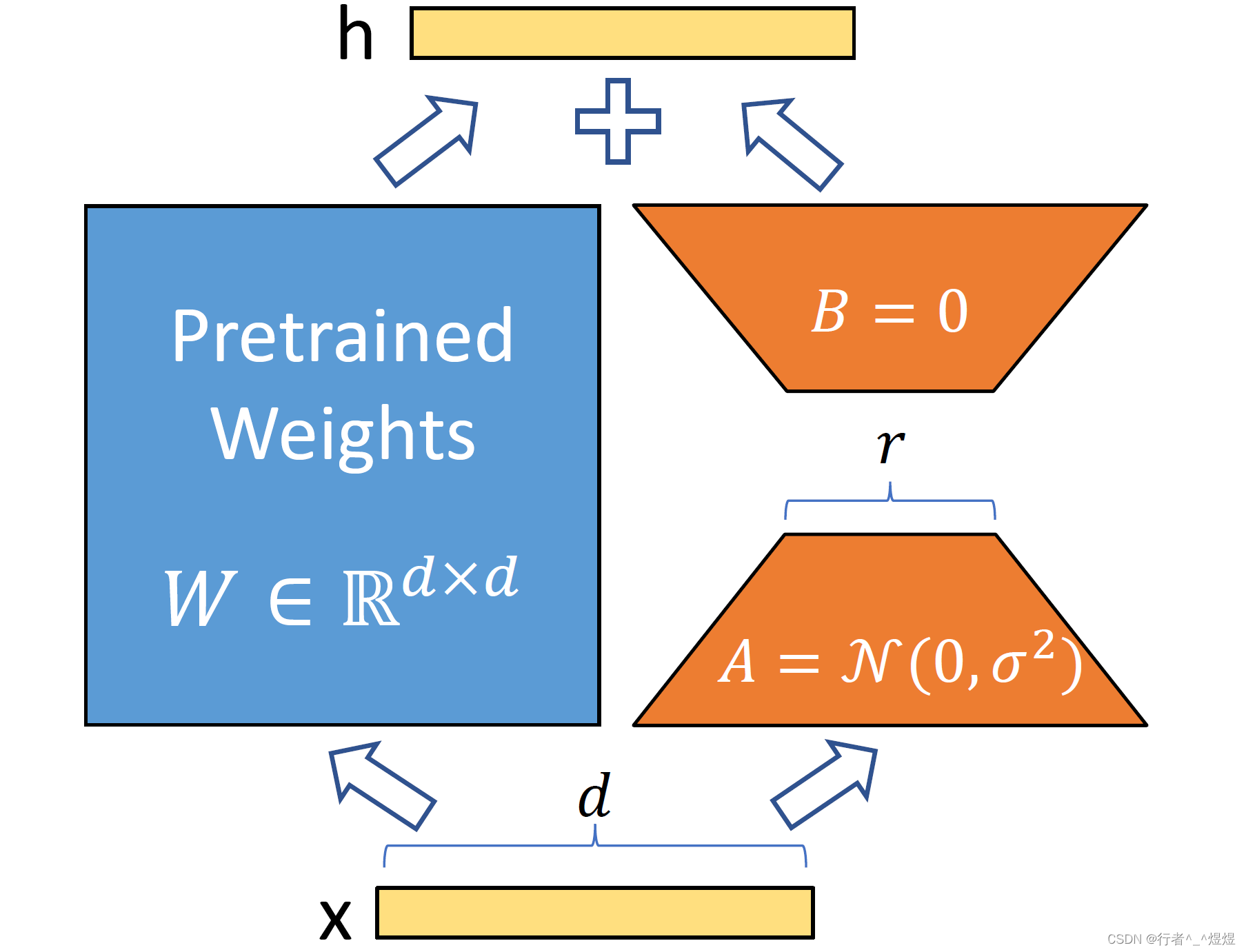
LoRA的具体设计实际上用两句话可以完成概括,(1)引入低秩矩阵进行 Δ W \Delta W ΔW 的计算;(2)选择哪些矩阵进行引入。
Δ W \Delta W ΔW 的选择
对于
Δ
W
\Delta W
ΔW 的计算,如下所示:
h
=
W
0
x
+
Δ
W
x
=
W
0
x
+
B
A
x
(3)
h=W_{0} x+\Delta W x=W_{0} x+B A x \tag{3}
h=W0x+ΔWx=W0x+BAx(3)
即,针对Transformer中的矩阵,加入一个
B
⋅
A
B \cdot A
B⋅A 的操作,其中,
B
B
B 和
A
A
A 共享的那个维度是
r
r
r,远小于 输入维度(
x
x
x 的维度)和 输出维度 (
h
h
h 的维度)。
W W W的选择
Transformer中的几个矩阵可以分为四类,这里分别表示为Q/K/V/O,分别对应到query/key/value/output。作者在附录中加入了对矩阵的选择(所有可训练参数总数18M, 18 M / 175 B ≈ 1 / 10 K 18M/175B \approx 1/10K 18M/175B≈1/10K),可以看到对QKVO所有矩阵都进行更新,性能最佳。但是在文中,作者普遍使用了只更新QV的方式,并说QV表现更好,这里不太明白。

总结
本文simple but effective,值得一看!

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)