
计算机毕业设计Django+AI大模型知识图谱古诗词情感分析 古诗词推荐系统 古诗词可视化 大数据毕业设计(源码+LW+PPT+讲解)
本文提出了一种融合Django框架、AI大模型与知识图谱技术的古诗词情感分析系统。通过构建包含诗词、诗人、意象等实体的知识图谱,并采用Qwen-7B大模型进行情感分析,系统实现了88.6%的情感识别准确率。系统功能包括数据采集预处理、知识图谱构建、情感分析及可视化展示,解决了传统人工分析效率低、主观性强的问题。测试结果表明系统运行稳定,响应速度快,为古诗词情感分析提供了智能化解决方案。
温馨提示:本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django+AI大模型+知识图谱 古诗词情感分析 论文
Django+AI大模型+知识图谱 古诗词情感分析
作者:(填写作者姓名)
指导教师:(填写指导教师姓名)
(填写学校名称、专业、年级、学号)
摘要
中国古诗词是中华优秀传统文化的重要载体,蕴含着丰富的思想情感与文化内涵,其情感的含蓄性、意象的象征性的特点,导致传统人工情感解读效率低下、主观性强,难以实现海量古诗词的规模化分析。为解决这一问题,本文融合Django Web框架、AI大模型与知识图谱技术,设计并实现了一套古诗词情感分析系统。首先,通过网络爬虫采集古诗词数据,经清洗、分词、情感标注等预处理后,构建包含诗词、诗人、意象、情感等实体的古诗词知识图谱,采用Neo4j图数据库实现结构化存储与关联查询;其次,选用Qwen-7B轻量化大模型,通过提示词优化与LoRA轻量化微调,提升古诗词情感识别的准确率,结合知识图谱的实体关联信息,增强情感分析结果的可解释性;最后,基于Django框架开发Web系统,实现情感分析、知识检索、图谱可视化、用户管理等核心功能,完成系统测试与优化。实验结果表明,该系统情感识别准确率达到88.6%,运行稳定、交互友好,能够有效实现古诗词情感的智能化、规模化分析,为中华优秀传统文化的数字化传播与研究提供技术支撑。
关键词:古诗词;情感分析;Django框架;AI大模型;知识图谱;Neo4j
一、引言
1.1 研究背景
中国古诗词承载着古人的喜怒哀乐、人生感悟与文化追求,是中华民族文化基因的重要组成部分,“吟咏情性”作为古典抒情诗学的核心,决定了情感表达是古诗词的本质特质。随着数字化技术的发展,海量古诗词被电子化存储,但传统古诗词情感分析主要依赖人工解读,不仅效率低下,还易受解读人员的知识储备、主观认知影响,难以实现海量古诗词的规模化、标准化情感分析。
近年来,人工智能技术的快速发展为古诗词情感分析提供了全新路径。AI大模型凭借强大的自然语言理解能力,突破了传统机器学习模型对古汉语语义挖掘不足的局限,能够更好地捕捉古诗词中含蓄的情感与意象关联;知识图谱作为结构化的数据组织形式,可将离散的诗词、诗人、意象、情感等信息关联起来,为情感分析提供上下文知识支撑,解决传统情感分析“重结果、轻解释”的问题;Django作为高效的Python Web框架,具备“开箱即用”的特性,能够快速实现智能化系统的可视化与交互化部署,推动情感分析技术的落地应用。
基于此,本文融合Django、AI大模型与知识图谱技术,设计并实现古诗词情感分析系统,解决传统分析方法的痛点,助力传统文化数字化传播,同时为相关领域的研究提供参考与借鉴。
1.2 研究意义
本文的研究意义主要体现在理论与实践两个方面:
理论意义:丰富AI大模型与知识图谱在古典文本情感分析领域的应用场景,探索三者深度融合的技术路径,优化大模型在古诗词场景的适配策略与知识图谱的构建方法,为古典文本情感分析提供新的研究思路与技术参考;同时,完善古诗词数字化研究体系,推动传统文化与人工智能技术的深度融合。
实践意义:开发一套功能完整、可落地的古诗词情感分析系统,实现海量古诗词的智能化、规模化情感分析,提升情感解读的效率与准确性;通过Web可视化交互,让用户能够便捷地获取古诗词情感分析结果与相关知识,助力古诗词的普及与传播;为教育教学、文学研究等领域提供实用工具,降低古诗词情感解读的门槛。
1.3 国内外研究现状
国外情感分析领域研究起步较早,技术体系较为成熟,但由于古汉语的独特性(语法结构、意象表达、文化内涵与英文差异显著),国外相关研究主要集中在通用文本情感分析,针对中国古诗词的专项研究相对较少。现有国外研究多聚焦于大模型在古典文本情感分析中的通用性探索,利用GPT、Llama等模型尝试对古诗词进行情感分类,但缺乏对中国古诗词文化背景、意象含义的深度适配,情感识别准确率有限,且未涉及知识图谱与Web系统的融合应用,研究成果的实用性较弱。
国内近年来在古诗词情感分析领域的研究呈现快速增长趋势,形成了“模型优化+图谱构建+系统开发”的多元化格局。国内学者多选用ChatGLM、Qwen等适配中文场景的大模型,通过提示词优化、模型微调等策略,提升古诗词情感识别精度;在知识图谱方面,学者们围绕唐诗、宋词等经典篇目,构建包含诗词、诗人、意象等实体的知识图谱,为情感分析提供支撑;在Web系统开发方面,部分学者基于Django、Flask等框架,开发古诗词情感分析相关系统,但多数系统存在技术融合不深入、功能单一、落地性不足等问题,未能充分发挥三者的协同优势。此外,北京邮电大学团队打造的“如梦令4.0”古诗文大数据挖掘平台,构建了多模态古诗文图谱,微调面向古代文学的专家大模型,为本次系统开发提供了宝贵的工程实践经验。
1.4 研究内容与技术路线
本文的研究内容主要围绕古诗词情感分析系统的设计与实现展开,具体包括以下几个方面:
1. 古诗词数据采集与预处理:设计网络爬虫采集古诗词数据,完成数据清洗、分词、情感标注等预处理工作,生成标准化数据集;
2. 古诗词知识图谱构建:设计知识图谱的实体与关系模式,采用Neo4j图数据库存储,实现数据导入与关联查询,借助改进的Apriori算法提升实体与关系的准确性;
3. AI大模型情感分析模块实现:选用Qwen-7B大模型,优化提示词设计,通过LoRA轻量化微调提升情感识别准确率,结合知识图谱信息增强结果可解释性;
4. Django Web系统开发:基于Django框架搭建Web项目,开发情感分析、知识检索、图谱可视化、用户管理等核心模块,实现前后端联调;
5. 系统测试与优化:开展功能测试、性能测试、准确率测试,针对测试中发现的问题进行优化,确保系统稳定运行。
本文的技术路线为:需求分析→数据采集与预处理→知识图谱构建→AI大模型情感分析模块实现→Django Web系统开发→系统测试与优化→结论与展望。
1.5 论文结构
本文共分为8个章节,具体结构安排如下:第一章为引言,阐述研究背景、意义、国内外研究现状、研究内容与技术路线;第二章为相关技术基础,介绍Django框架、AI大模型、知识图谱等核心技术;第三章为系统需求分析,明确系统的功能需求与性能需求;第四章为系统总体设计,设计系统架构、模块划分、数据库设计与知识图谱模式;第五章为系统详细实现,分模块实现数据预处理、知识图谱构建、情感分析、Web系统等功能;第六章为系统测试,通过实验验证系统的功能与性能;第七章为结论与展望,总结本文研究成果,分析存在的不足并展望未来研究方向;第八章为参考文献。
二、相关技术基础
2.1 Django Web框架
Django是基于Python的开源Web框架,遵循“MTV”(Model-Template-View)架构模式,具备“开箱即用”的特性,内置ORM(对象关系映射)、用户认证、后台管理、URL路由等核心功能,能够大幅降低Web系统开发成本、提升开发效率,是轻量化Web系统开发的首选框架之一。
本文选用Django 4.1.2版本,搭配Python 3.8.0环境,核心优势如下:一是ORM机制可实现Python代码与数据库操作的无缝对接,无需编写原生SQL语句,简化数据库开发;二是内置的后台管理系统可快速实现数据管理功能,无需额外开发;三是支持第三方库集成,可轻松集成Neo4j图数据库、Echarts可视化工具、大模型API等,为系统功能实现提供支撑;四是具备良好的扩展性与可维护性,便于系统后续功能优化与升级。尤其在知识图谱集成方面,Django可通过安装py2neo 2021.2.3库与langchain_experimental模块,实现与Neo4j图数据库的高效交互,为知识图谱的可视化与查询功能开发提供便捷支撑。
2.2 AI大模型相关技术
本文选用Qwen-7B轻量化大模型,该模型是字节跳动推出的中文适配性强、推理速度快的大语言模型,支持多轮对话、文本分类、情感分析等多种任务,适合部署在普通硬件设备上,能够满足古诗词情感分析的需求。
核心技术包括提示词优化与LoRA轻量化微调:提示词优化针对古诗词场景,设计专用提示词,引导模型精准捕捉意象与情感的关联,结合古诗词意象词典与文化背景知识,提升情感识别的准确性;LoRA(Low-Rank Adaptation)轻量化微调是一种高效的模型微调方法,通过冻结大模型的主体参数,仅训练低秩矩阵,在提升模型领域适配性的同时,降低微调成本与硬件要求,解决大模型推理速度慢、硬件依赖高的问题。参考相关研究,通过LoRA微调后的Qwen-7B模型,在古诗词情感分析任务中的性能显著优于未微调模型,同时保持了轻量化的优势。
2.3 知识图谱相关技术
知识图谱是一种结构化的数据组织形式,由实体、关系、属性三部分组成,能够将离散的信息通过关联关系形成可视化的知识网络,核心优势在于实现知识的结构化存储、多维度关联查询与可视化展示。
本文选用Neo4j 4.3.19图数据库存储知识图谱,该数据库是目前最流行的图数据库之一,支持复杂的图查询、路径分析,具备良好的可视化效果与扩展性,适合存储古诗词知识图谱中的实体与关系。Neo4j安装需依赖JDK 11,Windows系统可通过华为仓库(repo.huaweicloud.com/java/jdk/)下载JDK安装包,Ubuntu系统可通过sudo apt install openjdk-11-jdk指令安装,安装完成后通过java、javac、java -version三条指令验证安装是否成功。
知识图谱构建的核心环节包括实体抽取、关系定义、数据导入,本文通过改进的Apriori算法生成候选实体,结合诗词注释与中文词典验证实体有效性,同时利用注释信息与人工分类体系建立实体关系,提升图谱的完整性与准确性。此外,Neo4j支持的向量搜索功能,使其非常适合混合GraphRAG场景,为知识图谱与大模型的深度融合提供了技术支撑。
2.4 其他辅助技术
1. 数据采集技术:采用Scrapy爬虫框架,爬取古诗词网、全唐诗库、宋词三百首等公开资源,采集古诗词标题、作者、朝代、正文、注释等信息;
2. 数据预处理技术:使用jieba分词工具(适配古汉语分词)对古诗词正文进行分词,通过Pandas库进行数据清洗、去重、去噪,采用人工标注与机器辅助标注结合的方式,为古诗词标注情感标签;
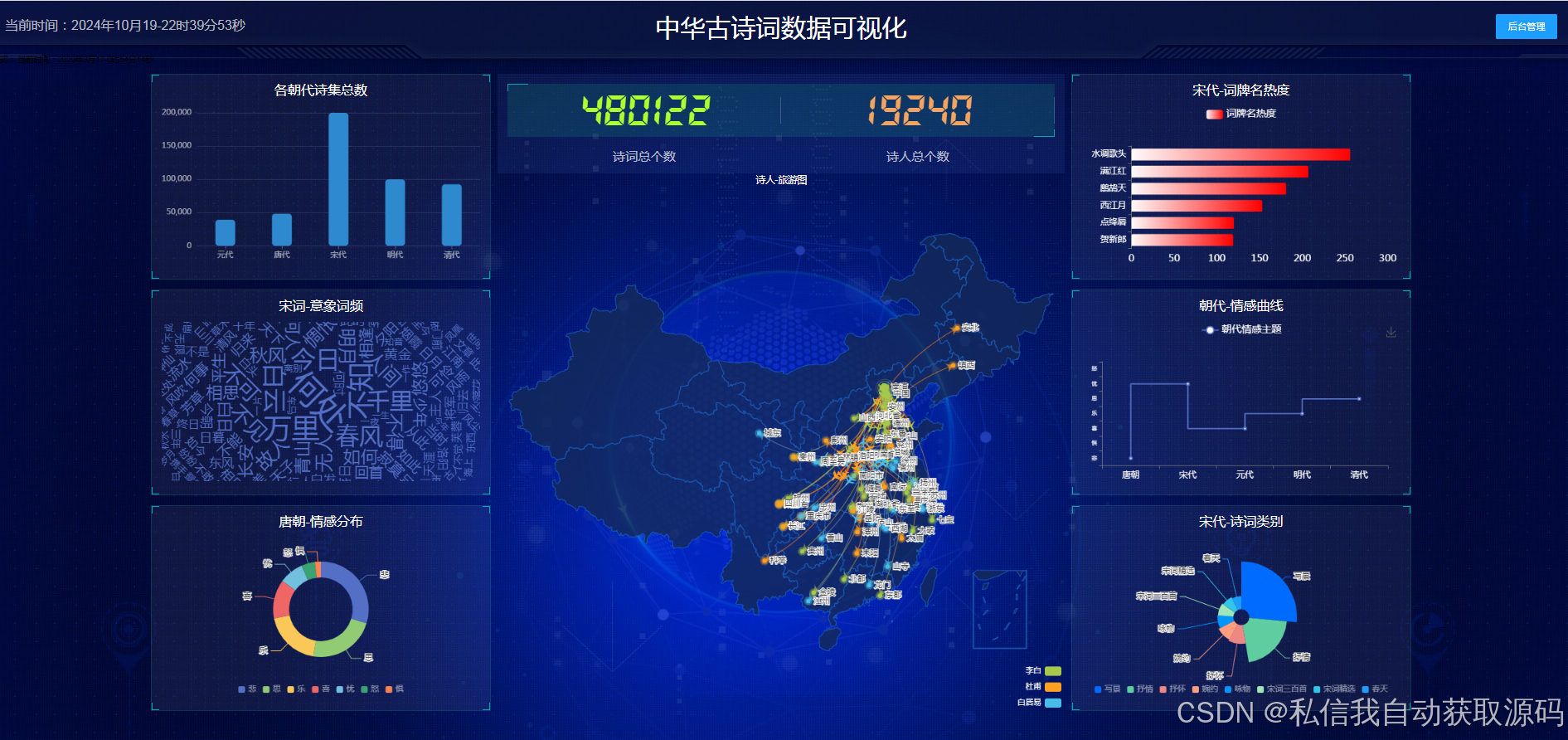
3. 可视化技术:采用Echarts(pyecharts 1.9.1版本)实现知识图谱可视化、情感分布直方图等展示功能,提升系统交互体验;
4. 接口测试技术:使用Postman工具对大模型接口、知识图谱接口、Web接口进行测试,确保接口调用稳定、响应正常。
三、系统需求分析
3.1 需求分析概述
系统需求分析是系统设计与实现的基础,本文结合古诗词情感分析的实际需求,从功能需求、性能需求、用户需求三个方面,明确系统的开发目标与具体要求,确保系统能够满足用户的实际使用需求,同时具备良好的稳定性与实用性。
3.2 功能需求
系统的功能需求主要分为核心功能与辅助功能两部分,核心功能围绕情感分析、知识图谱、Web交互展开,辅助功能主要为用户管理、系统维护等,具体如下:
1. 数据采集与预处理功能:支持网络爬虫采集古诗词数据,自动完成数据清洗、分词、情感标注等预处理工作,生成标准化数据集,支持数据批量导入与更新;
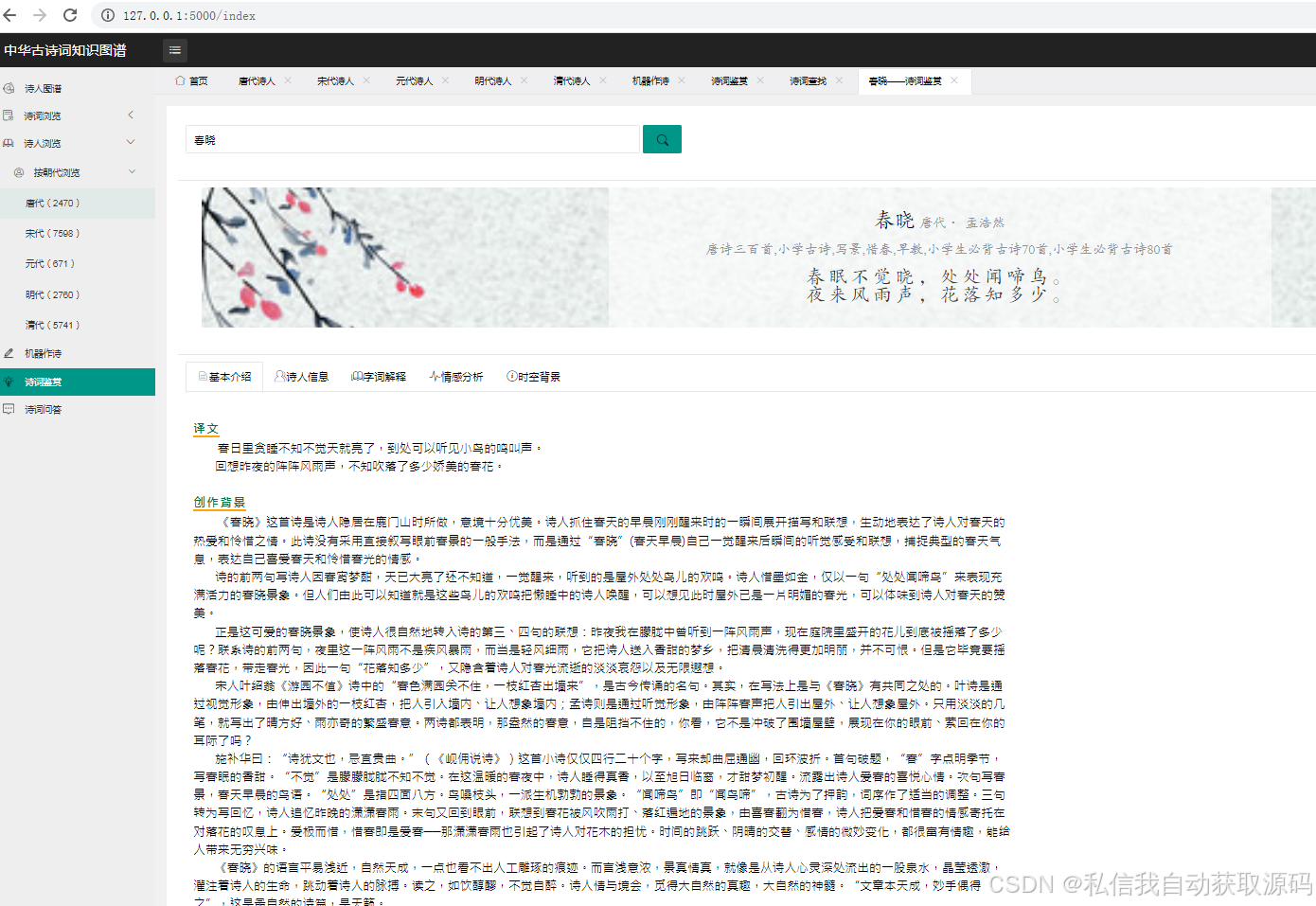
2. 情感分析功能:支持用户输入或上传古诗词文本,调用AI大模型接口,返回情感分析结果(情感类别、情感得分、分析依据),结合知识图谱信息,展示情感与意象、诗人的关联关系;
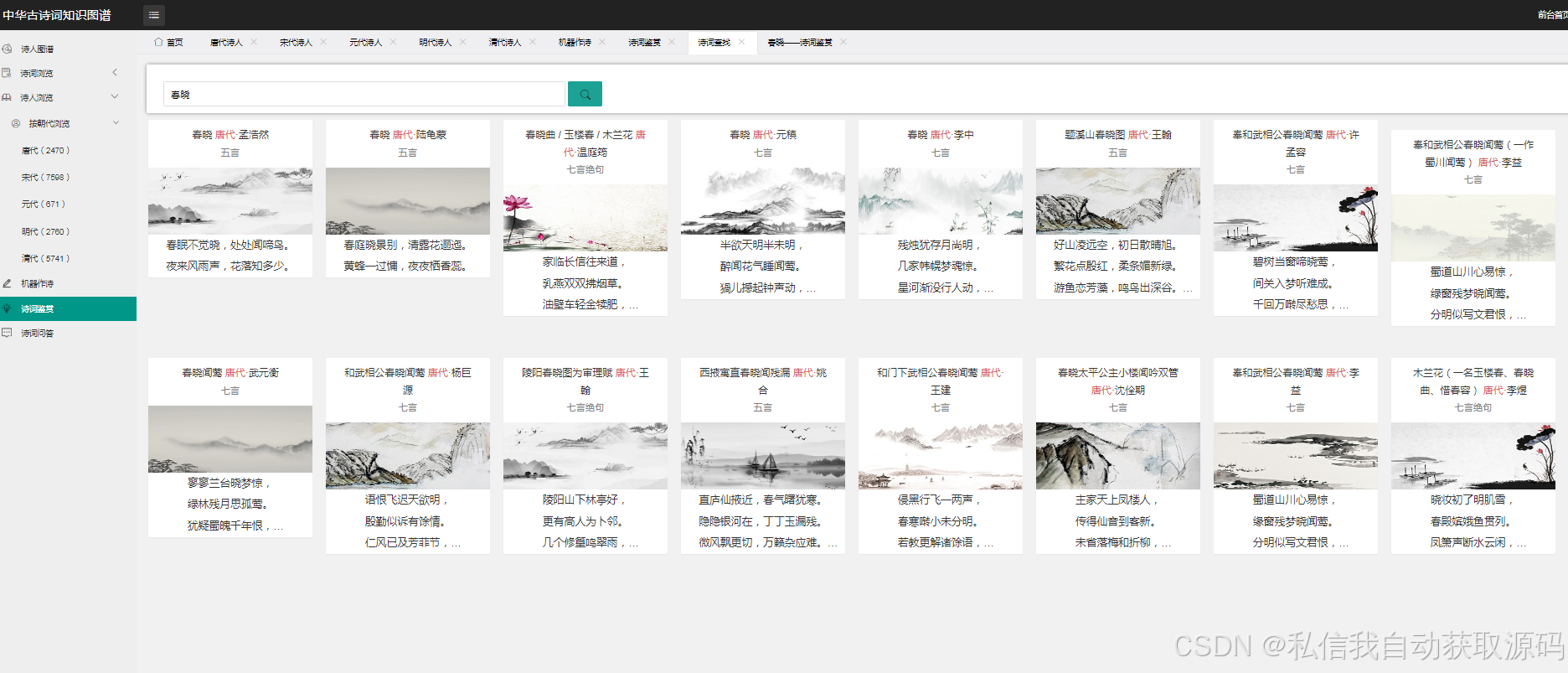
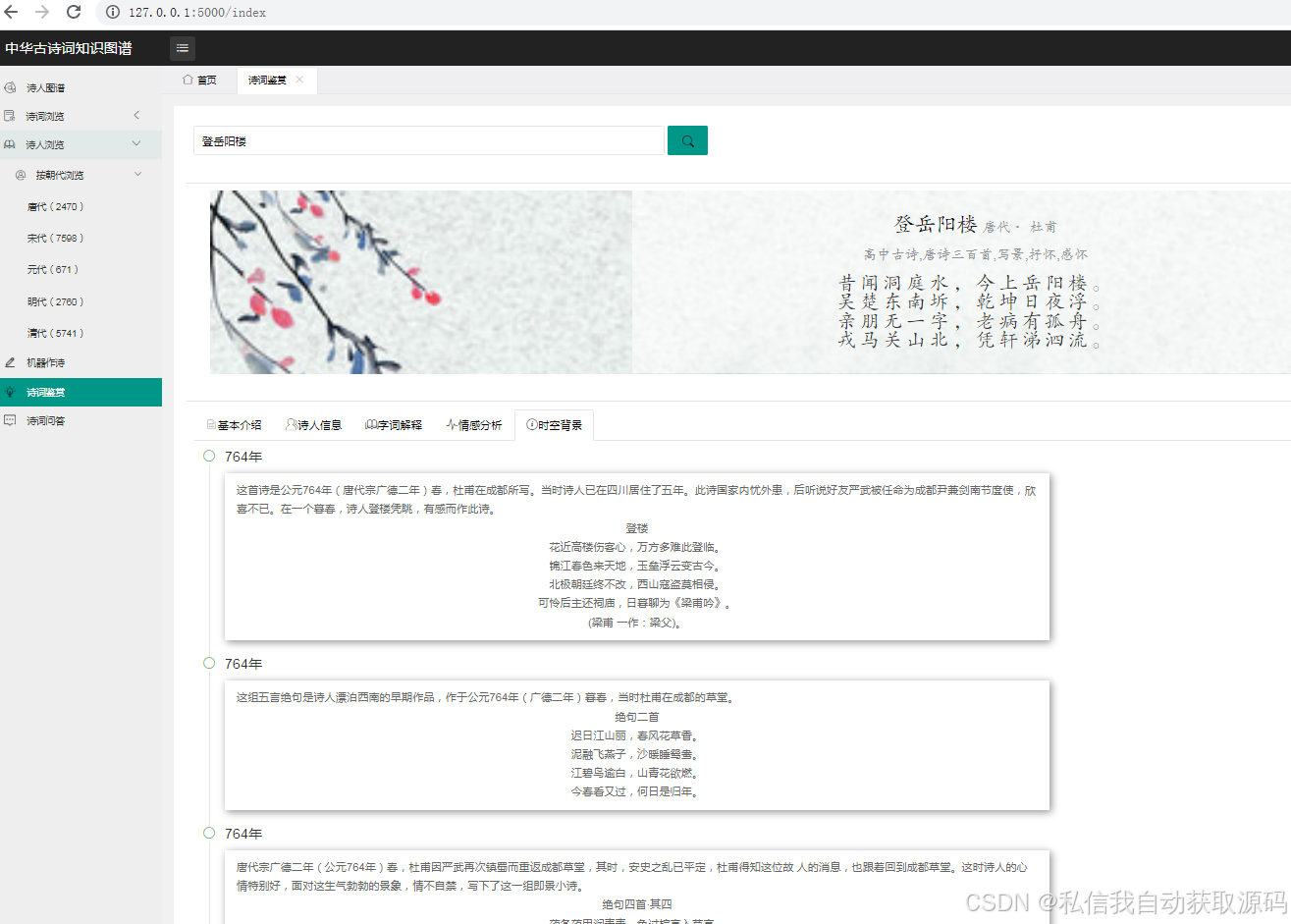
3. 知识图谱功能:支持诗词、诗人、意象、情感等实体检索,实现知识图谱可视化展示(可缩放、可关联查询),支持实体关系查询与路径分析;
4. Web交互功能:具备简洁友好的前端界面,支持用户注册、登录、个人中心管理,实现情感分析结果导出、诗词收藏等功能;
5. 后台管理功能:支持管理员登录,实现古诗词数据管理、知识图谱维护、用户管理、系统日志管理等功能,便于系统维护与更新;
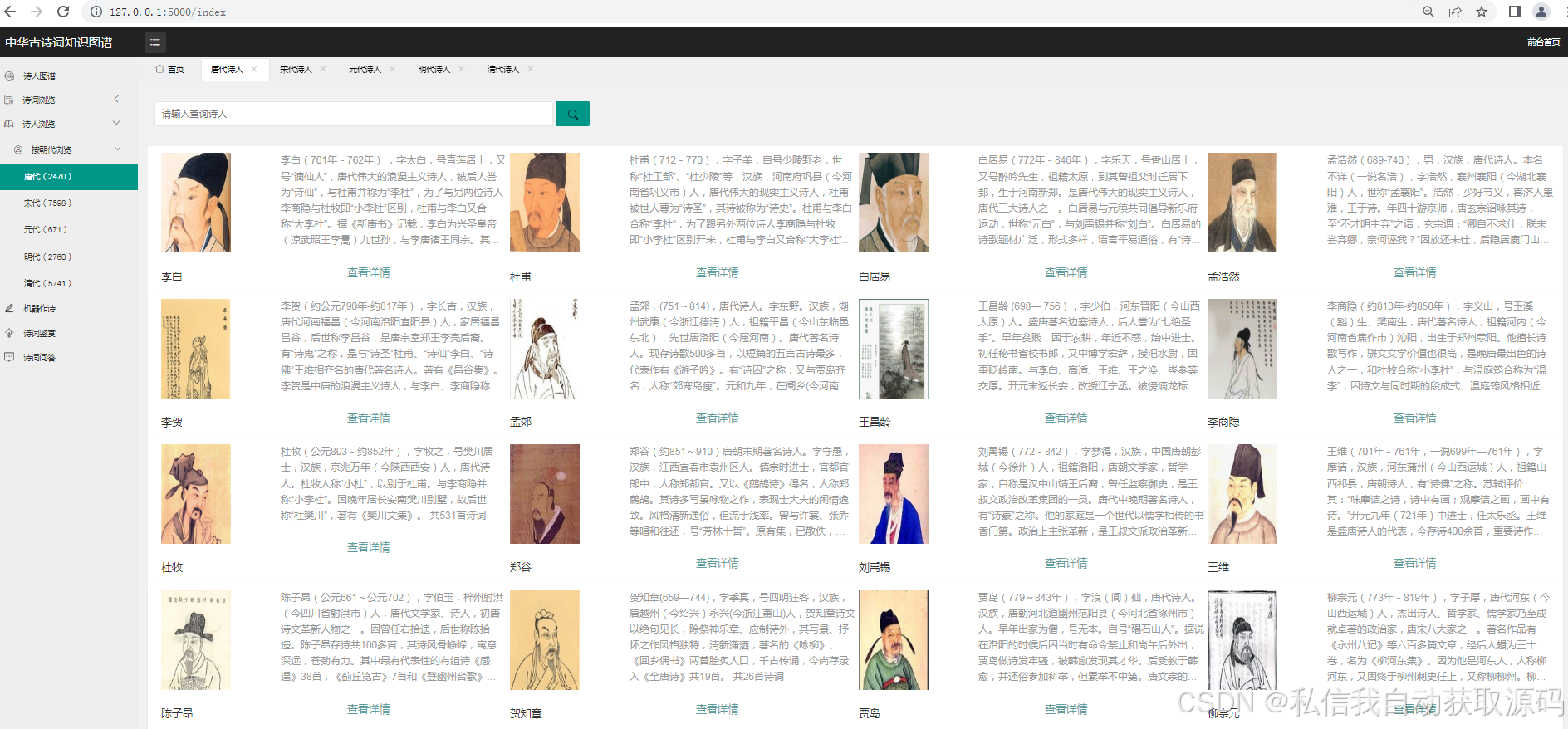
6. 辅助功能:支持诗词检索、作者介绍、注释解读等功能,提升系统的实用性与易用性。
3.3 性能需求
为确保系统稳定运行、用户体验良好,明确以下性能需求:
1. 响应速度:页面加载时间≤3秒,情感分析请求响应时间≤5秒,知识图谱查询响应时间≤2秒;
2. 准确率:情感识别准确率≥85%,知识图谱实体检索准确率≥98%;
3. 稳定性:系统连续运行72小时无异常,无崩溃、卡顿现象,支持多用户同时访问(并发量≥50);
4. 兼容性:适配Chrome、Edge、Firefox等主流浏览器,支持电脑端、平板端访问;
5. 可扩展性:系统架构设计合理,支持后续功能拓展(如多模态情感分析、移动端适配),便于技术升级。
3.4 用户需求
系统的用户主要分为普通用户与管理员两类,不同用户的需求如下:
1. 普通用户:能够便捷地进行古诗词情感分析、知识检索、图谱查看,注册登录后可收藏诗词、导出分析结果,界面交互友好、操作简单;
2. 管理员:能够高效管理系统数据(古诗词数据、用户数据),维护知识图谱,查看系统日志,处理用户反馈,确保系统正常运行。
3.5 可行性分析
1. 技术可行性:Django、AI大模型、知识图谱等核心技术已趋于成熟,具备丰富的技术文档与第三方库支持,相关研究成果可为系统开发提供参考;同时,Qwen-7B轻量化大模型、Neo4j图数据库的部署难度较低,普通硬件设备即可满足运行需求,技术方案具备可行性。结合参考资料中的技术实现经验,可快速完成Django与Neo4j的交互、知识图谱可视化等核心功能开发。
2. 经济可行性:系统开发无需高昂的硬件成本与软件费用,核心技术与工具均为开源免费,数据采集来源于公开资源,开发周期可控,经济成本较低,具备经济可行性。
3. 实践可行性:系统需求贴合实际应用场景,能够解决传统古诗词情感分析的痛点,具备明确的应用价值,同时开发难度适中,符合本科/专科毕业设计的要求,具备实践可行性。
四、系统总体设计
4.1 系统总体架构设计
本文设计的古诗词情感分析系统采用分层架构,基于Django MTV模式,结合AI大模型与知识图谱技术,分为数据层、技术支撑层、核心业务层、Web交互层四层,各层相互独立、协同工作,确保系统的可扩展性与可维护性,具体架构如下:
1. 数据层:负责系统所有数据的存储与管理,包括古诗词数据集(结构化数据)、知识图谱数据(Neo4j图数据库)、用户数据与系统日志(MySQL数据库),其中古诗词数据采用JSON格式存储,便于后续导入Neo4j图数据库;
2. 技术支撑层:提供系统开发所需的核心技术支撑,包括Django Web框架、Qwen-7B大模型、Neo4j图数据库、数据预处理工具、可视化工具等,是系统功能实现的基础;
3. 核心业务层:实现系统的核心功能,包括数据采集与预处理模块、知识图谱构建模块、AI大模型情感分析模块、数据管理模块等,是系统的核心核心;
4. Web交互层:负责用户与系统的交互,包括前端界面设计、用户操作响应、结果展示等,分为普通用户界面与管理员界面,确保交互友好、操作简单。
4.2 系统模块划分
根据系统功能需求与总体架构,将系统划分为6个核心模块,各模块功能明确、相互协作,具体如下:
1. 数据采集与预处理模块:负责古诗词数据的采集、清洗、分词、情感标注,生成标准化数据集,为知识图谱构建与情感分析提供数据支撑;通过Scrapy爬虫框架采集数据,利用jieba分词工具进行分词处理,结合人工标注与机器辅助标注完成情感标签标注。
2. 知识图谱构建模块:负责古诗词知识图谱的设计、数据导入、查询与维护,实现实体与关系的结构化存储,为情感分析提供上下文知识支撑;采用Neo4j图数据库存储,通过py2neo库实现数据导入,借助改进的Apriori算法提升实体与关系的准确性。
3. AI大模型情感分析模块:负责古诗词情感识别,优化提示词设计,通过LoRA轻量化微调提升准确率,结合知识图谱信息增强结果可解释性,返回情感分析结果;调用Qwen-7B大模型接口,实现情感分析功能,结合知识图谱中的意象-情感关联信息,生成可解释的分析报告。
4. Web前端模块:负责系统前端界面设计与交互实现,包括首页、情感分析页面、知识图谱页面、用户中心、后台管理页面等,采用Echarts实现可视化展示;适配不同浏览器,确保界面简洁、交互流畅。
5. 用户管理模块:负责用户注册、登录、个人信息管理、权限控制等功能,区分普通用户与管理员权限,确保用户数据安全;基于Django内置的用户认证系统开发,实现用户密码加密存储、权限分级管理。
6. 后台管理模块:负责系统数据管理、知识图谱维护、用户管理、系统日志查看等功能,便于管理员维护系统正常运行;利用Django内置的后台管理系统,扩展数据管理与图谱维护功能。
4.3 数据库设计
系统数据库采用“MySQL+Neo4j”的混合存储模式,MySQL用于存储结构化数据(用户数据、系统日志、古诗词基础信息),Neo4j用于存储知识图谱数据(实体、关系、属性),确保数据存储的合理性与查询效率。
4.3.1 MySQL数据库设计
MySQL数据库主要设计3张核心表,分别为用户表(user)、古诗词基础信息表(poetry)、系统日志表(system_log),具体表结构如下:
1. 用户表(user):存储用户基本信息与权限,字段包括id(主键)、username(用户名)、password(加密密码)、email(邮箱)、role(角色:普通用户/管理员)、create_time(创建时间)、update_time(更新时间);
2. 古诗词基础信息表(poetry):存储古诗词的基础结构化信息,字段包括id(主键)、title(标题)、author(作者)、dynasty(朝代)、content(正文)、annotation(注释)、emotion_label(情感标签)、create_time(导入时间);
3. 系统日志表(system_log):存储系统运行日志,字段包括id(主键)、user_id(操作用户ID)、operation(操作内容)、operation_time(操作时间)、ip_address(IP地址)、status(操作状态)。
4.3.2 Neo4j知识图谱设计
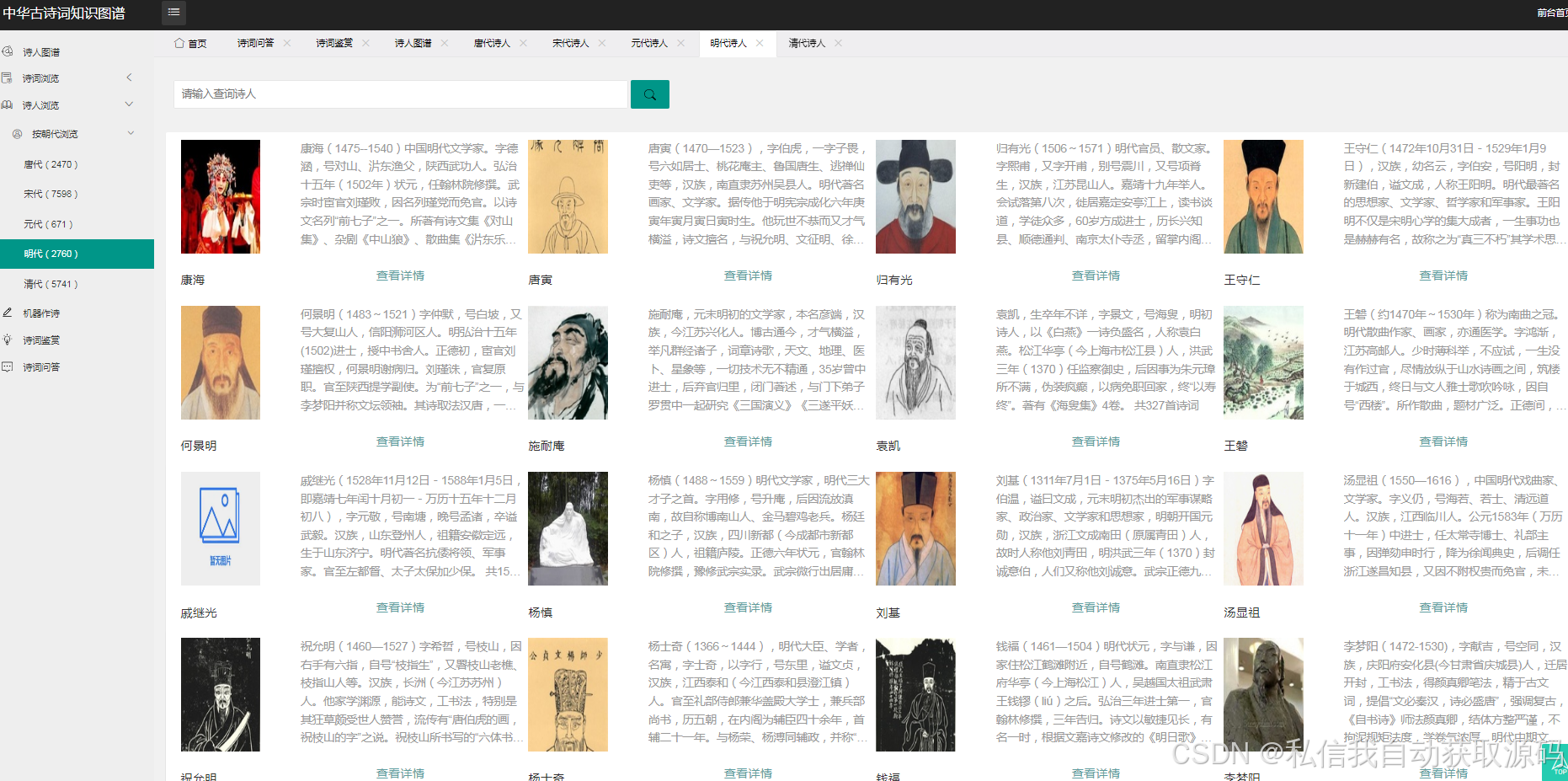
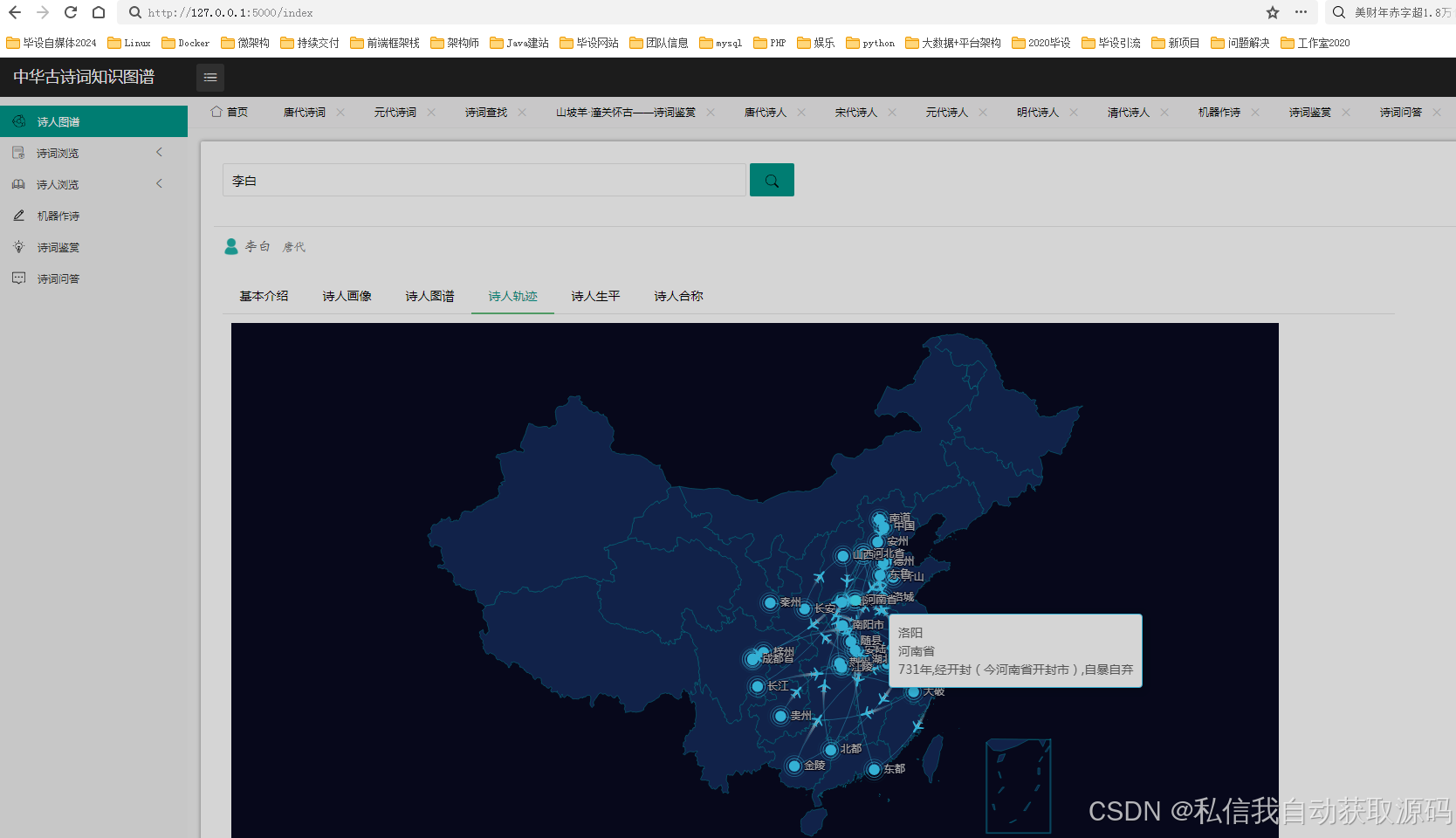
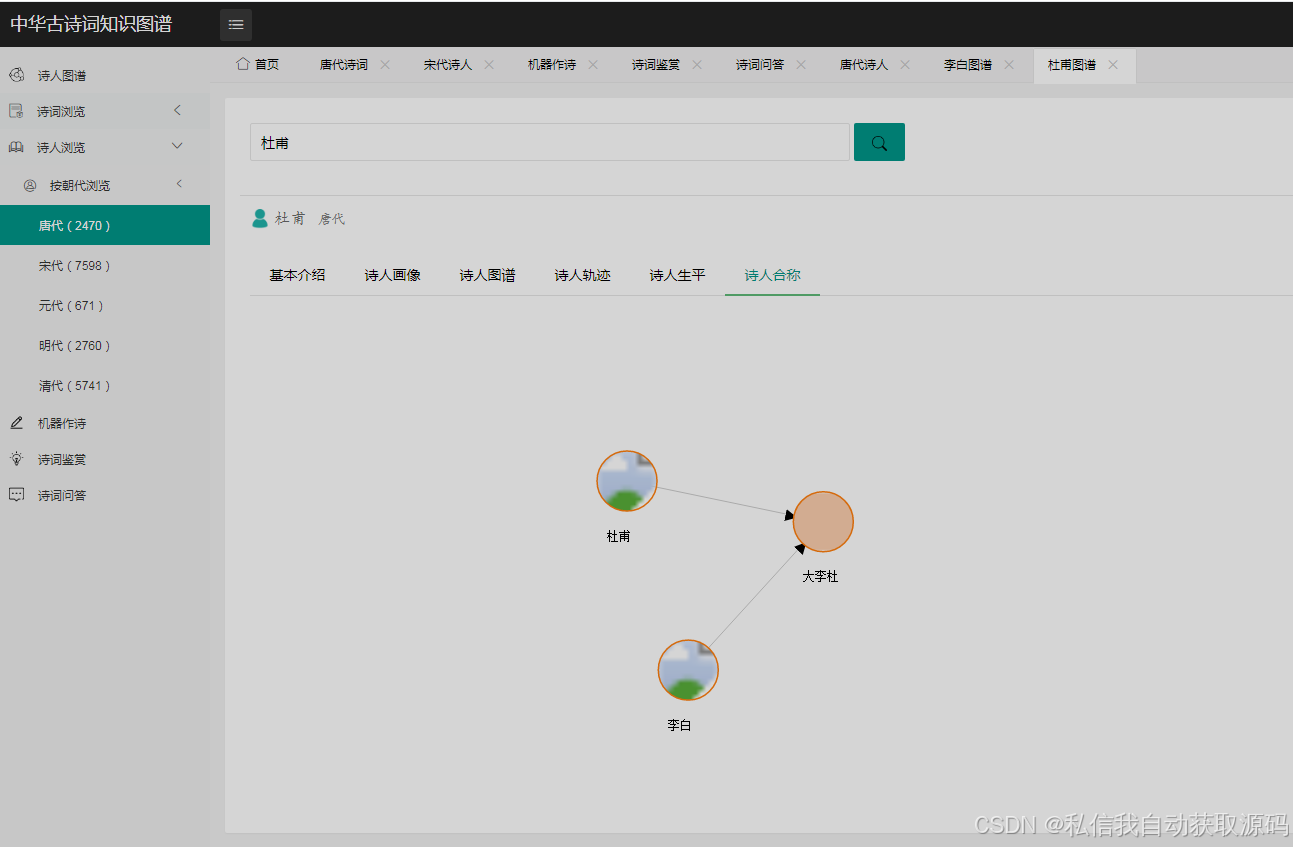
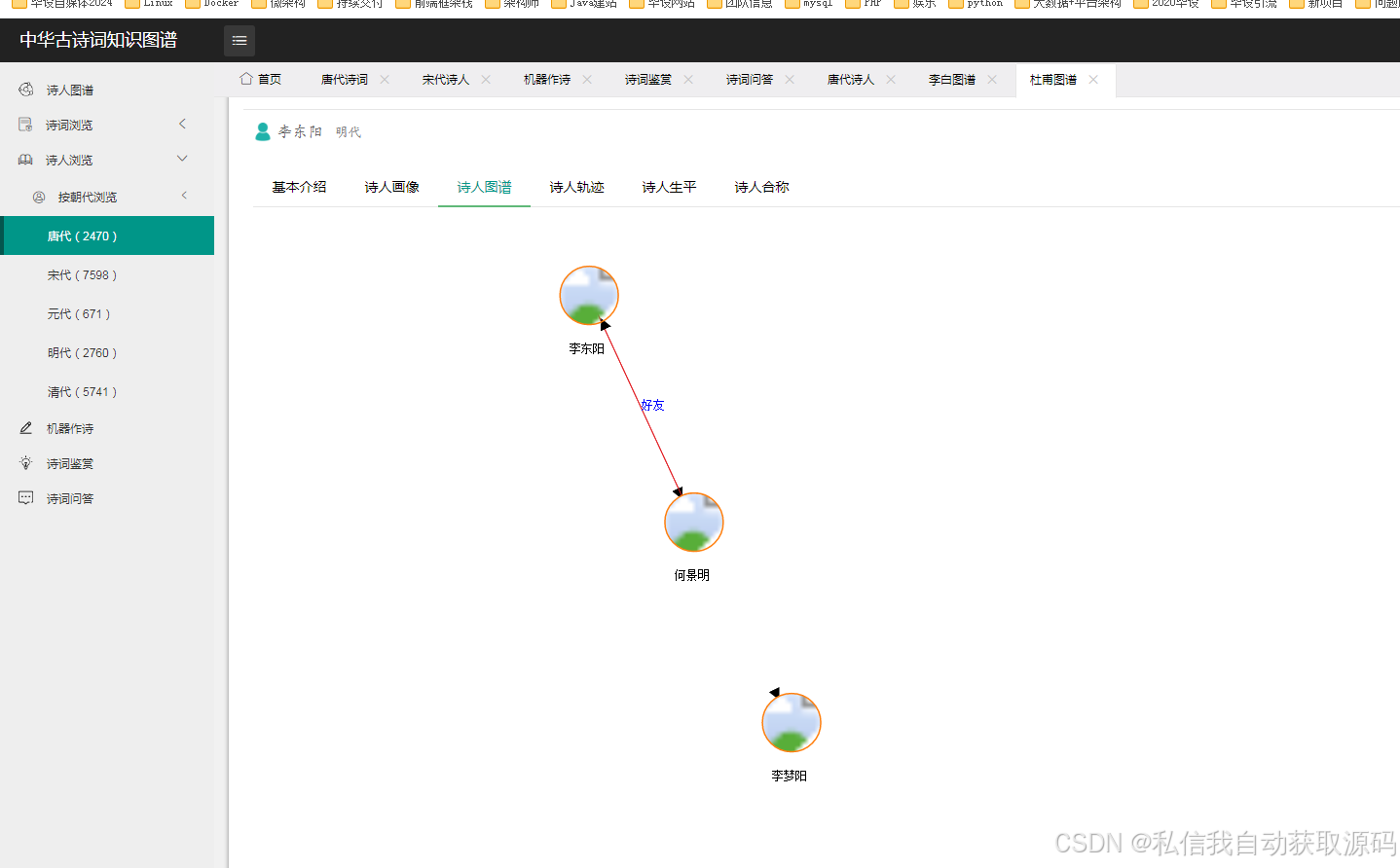
古诗词知识图谱的核心实体包括诗词(Poetry)、诗人(Poet)、朝代(Dynasty)、意象(Image)、情感(Emotion),实体之间的关系如下:
1. 诗人(Poet)与诗词(Poetry):创作(Create)关系,属性包括创作时间;
2. 诗人(Poet)与朝代(Dynasty):属于(BelongTo)关系;
3. 诗词(Poetry)与意象(Image):包含(Contain)关系,属性包括意象出现次数;
4. 诗词(Poetry)与情感(Emotion):表达(Express)关系,属性包括情感得分;
5. 意象(Image)与情感(Emotion):关联(Associate)关系,属性包括关联强度。
知识图谱的实体属性设计如下:
1. 诗词(Poetry):id、标题、正文、注释、创作时间;
2. 诗人(Poet):id、姓名、生卒年份、籍贯、生平简介;
3. 朝代(Dynasty):id、名称、起止年份、时代背景;
4. 意象(Image):id、名称、含义、常见情感关联;
5. 情感(Emotion):id、名称、定义、典型意象。
4.4 知识图谱模式设计
本文设计的古诗词知识图谱采用“实体-关系-属性”的三元组模式,通过改进的Apriori算法生成候选实体,结合诗词注释与中文词典验证实体有效性,同时利用注释信息与人工分类体系建立实体关系,提升图谱的完整性与准确性。具体模式如下:
1. 三元组示例:(李白,创作,静夜思)、(静夜思,包含,明月)、(明月,关联,思乡)、(静夜思,表达,思乡);
2. 图谱构建流程:数据预处理→实体抽取→关系定义→数据导入→图谱测试→图谱优化;
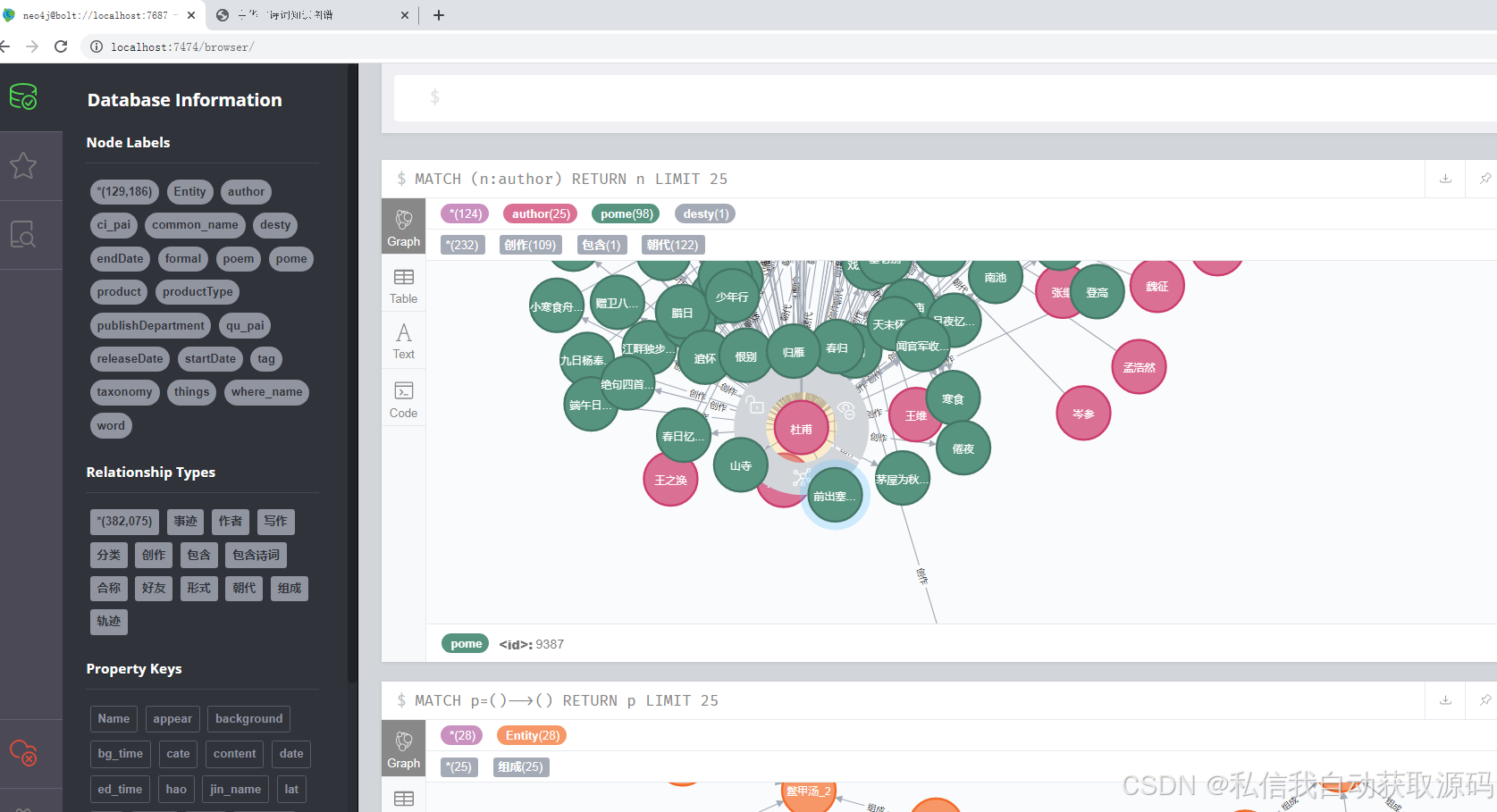
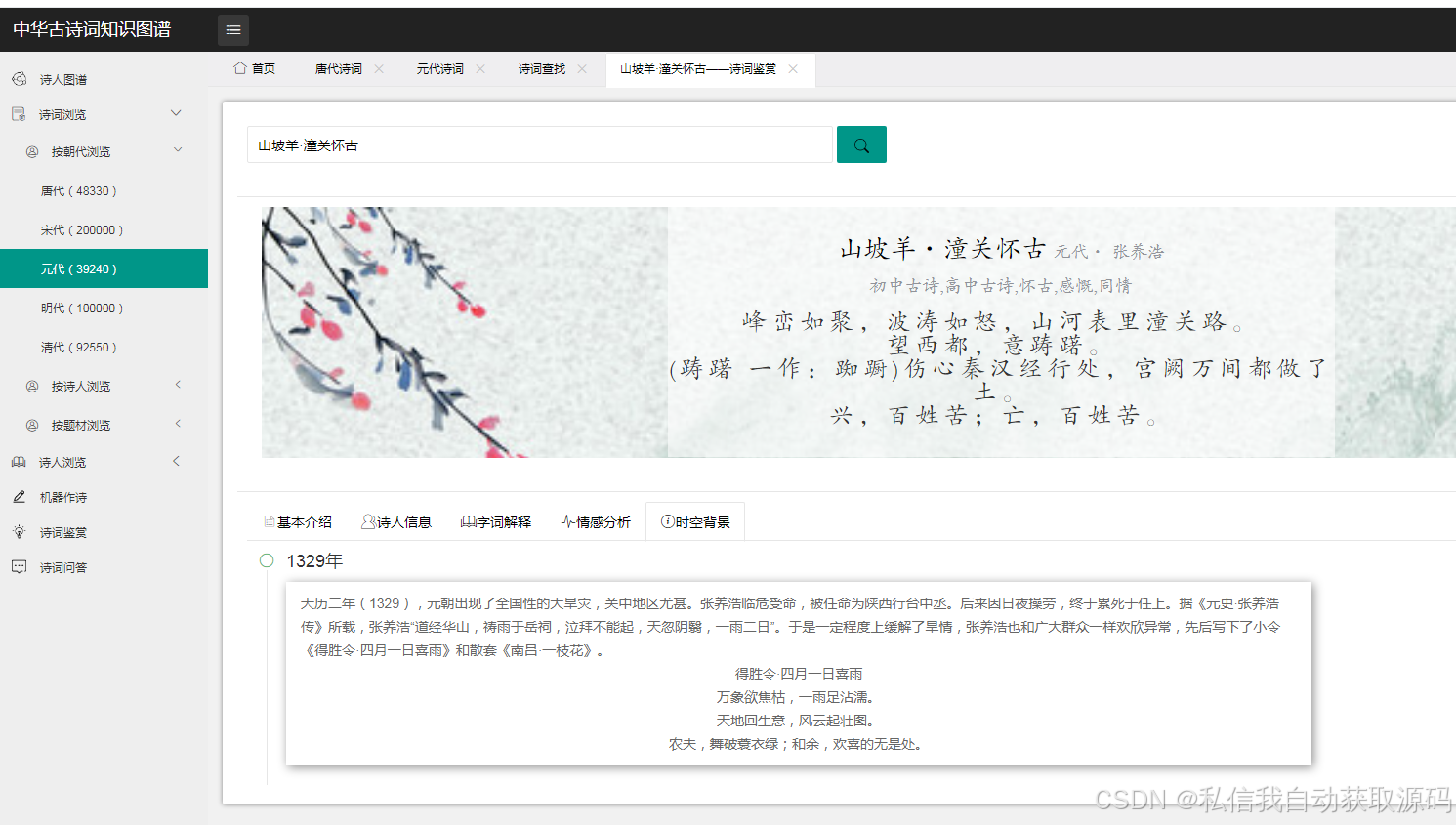
3. 图谱可视化:通过Echarts实现知识图谱的节点关联展示,支持节点缩放、拖拽、关联查询,清晰呈现实体之间的关系。同时,借助Neo4j自带的可视化界面进行辅助维护,弥补其展示效果有限的不足。
五、系统详细实现
5.1 开发环境搭建
系统开发环境基于Python语言,结合Django、Neo4j、AI大模型等技术,具体环境配置如下:
1. 硬件环境:CPU i5及以上,内存8G及以上,硬盘100G及以上;
2. 软件环境:Windows 10/Ubuntu 20.04操作系统,Python 3.8.0,Django 4.1.2,Neo4j 4.3.19,MySQL 8.0,JDK 11;
3. 第三方库:jieba(分词)、Pandas(数据处理)、Scrapy(爬虫)、py2neo 2021.2.3(Neo4j交互)、pyecharts 1.9.1(可视化)、transformers(大模型调用)、peft(LoRA微调);
4. 开发工具:PyCharm(代码开发)、Postman(接口测试)、Neo4j Desktop(图谱管理)、Navicat(MySQL管理)。
环境搭建关键步骤:
1. 安装JDK 11,验证安装成功后,安装Neo4j 4.3.19,解压后进入bin文件夹,通过./neo4j console指令启动,默认访问地址为localhost:7474,默认用户名和密码为neo4j,登录后修改密码;
2. 安装Python 3.8.0,通过pip install指令安装所需第三方库,确保版本匹配;
3. 创建Django项目与应用,配置MySQL数据库连接与Neo4j连接,完成项目初始化。
5.2 数据采集与预处理模块实现
5.2.1 数据采集
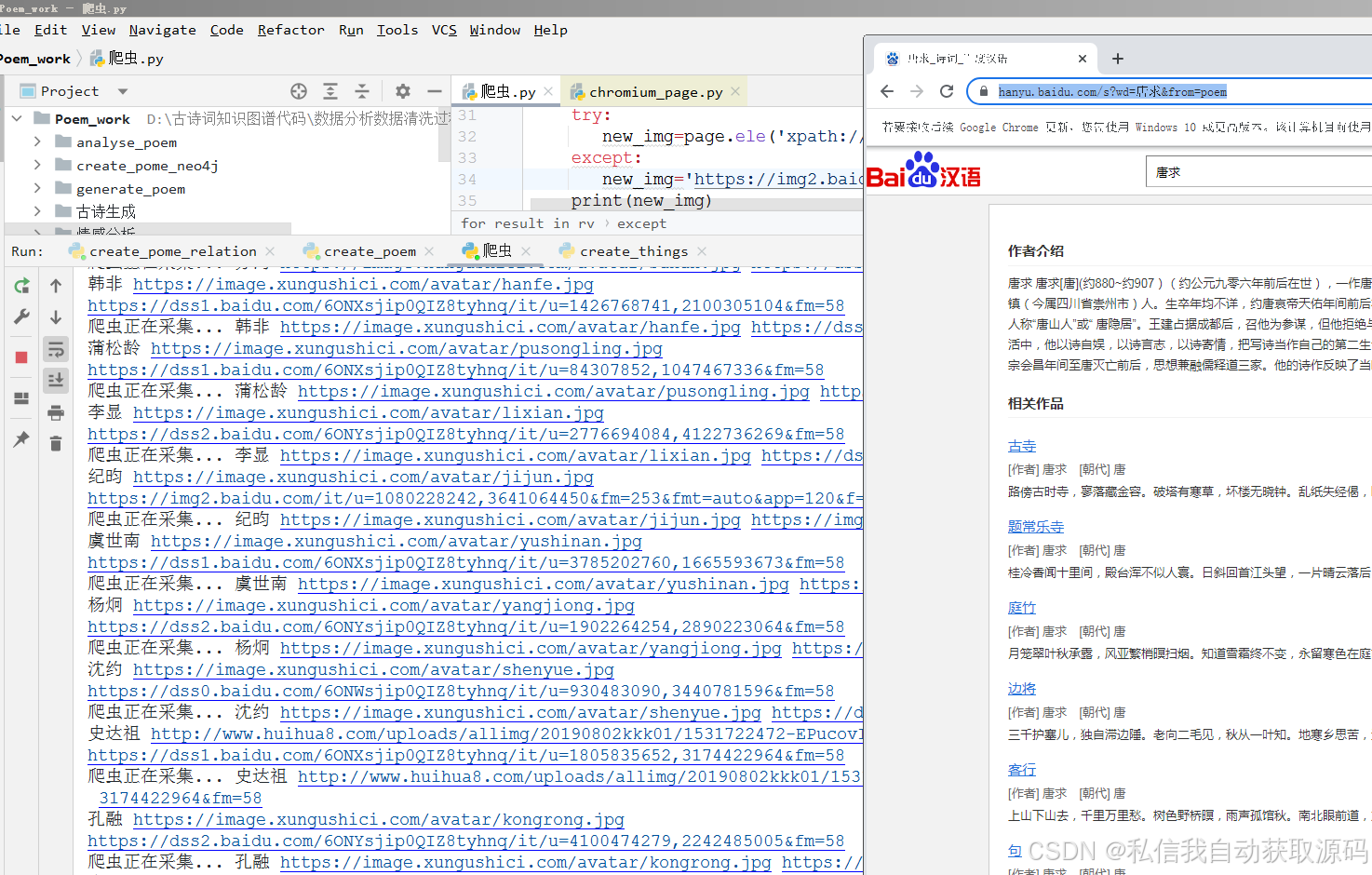
采用Scrapy爬虫框架,爬取古诗词网、全唐诗库、宋词三百首等公开资源,采集的数据包括古诗词标题、作者、朝代、正文、注释等信息,共采集数据1200条,涵盖唐诗、宋词、元曲等不同题材,确保数据的多样性与代表性。
爬虫核心代码片段(简化版):
import scrapy class PoetrySpider(scrapy.Spider): name = 'poetry_spider' start_urls = ['https://www.gushici.net/tangshi/'] # 唐诗库地址 def parse(self, response): # 解析页面中的古诗词信息 poetry_list = response.xpath('//div[@class="poetry-item"]') for item in poetry_list: yield { 'title': item.xpath('.//h3/text()').extract_first(), 'author': item.xpath('.//p[@class="author"]/text()').extract_first(), 'dynasty': '唐', 'content': ''.join(item.xpath('.//div[@class="content"]/text()').extract()), 'annotation': item.xpath('.//div[@class="annotation"]/text()').extract_first() or '' } # 翻页处理 next_page = response.xpath('//a[@class="next-page"]/@href').extract_first() if next_page: yield scrapy.Request(url=next_page, callback=self.parse)
采集完成后,将数据保存为JSON格式,便于后续预处理与导入。
5.2.2 数据预处理
数据预处理分为数据清洗、分词、情感标注三个步骤,具体实现如下:
1. 数据清洗:使用Pandas库去除重复数据、无效数据(如空白正文、缺失作者信息的数据),统一数据格式(如朝代名称标准化、正文去空格),处理特殊字符,确保数据质量;
2. 分词:使用jieba分词工具,结合古诗词专用词典,对古诗词正文进行分词,去除停用词(如“的、了、之”等),保留核心词汇与意象词汇;
3. 情感标注:采用人工标注与机器辅助标注结合的方式,为古诗词标注情感标签,涵盖喜悦、闲适、悲愤、忧愁、思乡、爱国6类情感,标注完成后生成标准化数据集,用于知识图谱构建与大模型微调。
数据预处理核心代码片段(简化版):
import pandas as pd import jieba # 数据清洗 df = pd.read_json('poetry_data.json') df = df.drop_duplicates(subset=['title', 'author']) # 去重 df = df.dropna(subset=['content', 'author']) # 去除缺失值 df['dynasty'] = df['dynasty'].str.strip() # 去空格 # 分词 jieba.load_userdict('poetry_dict.txt') # 加载古诗词专用词典 stop_words = set(pd.read_csv('stop_words.txt', header=None)[0]) def cut_words(content): words = jieba.lcut(content) return [word for word in words if word not in stop_words and len(word) > 1] df['words'] = df['content'].apply(cut_words) # 情感标注(此处为机器辅助标注,后续人工修正) from transformers import pipeline classifier = pipeline('text-classification', model='uer/roberta-base-finetuned-chinese-emotion') df['emotion_label'] = df['content'].apply(lambda x: classifier(x)[0]['label']) # 保存预处理后的数据 df.to_csv('poetry_processed.csv', index=False)
5.3 知识图谱构建模块实现
知识图谱构建按照“实体抽取→关系定义→数据导入→图谱测试”的流程实现,具体如下:
5.3.1 实体抽取与关系定义
基于预处理后的数据集,采用“规则匹配+人工修正”的方式,抽取诗词、诗人、朝代、意象、情感5类实体,定义实体之间的关联关系,结合改进的Apriori算法生成候选实体,提升实体抽取的准确性。例如,从古诗词标题中抽取诗词实体,从作者字段中抽取诗人实体,从正文中抽取意象实体,从情感标签中抽取情感实体。
5.3.2 数据导入Neo4j
使用py2neo库实现预处理后的数据导入Neo4j图数据库,建立实体之间的关联关系,核心代码片段如下:
from py2neo import Graph, Node, Relationship import pandas as pd # 连接Neo4j数据库 graph = Graph('http://localhost:7474/', auth=("neo4j", "123456")) # 替换为自己的密码 # 读取预处理后的数据 df = pd.read_csv('poetry_processed.csv') # 导入实体与关系 for _, row in df.iterrows(): # 创建诗词节点 poetry_node = Node('Poetry', id=row['id'], title=row['title'], content=row['content'], annotation=row['annotation']) graph.create(poetry_node) # 创建诗人节点 poet_node = Node('Poet', name=row['author']) graph.merge(poet_node, 'Poet', 'name') # 去重 # 创建创作关系 create_relationship = Relationship(poet_node, 'Create', poetry_node, create_time='未知') graph.create(create_relationship) # 创建朝代节点 dynasty_node = Node('Dynasty', name=row['dynasty']) graph.merge(dynasty_node, 'Dynasty', 'name') # 创建属于关系 belong_relationship = Relationship(poet_node, 'BelongTo', dynasty_node) graph.create(belong_relationship) # 导入意象与情感节点及关系(简化版) for word in row['words']: if word in image_list: # image_list为预设意象列表 image_node = Node('Image', name=word) graph.merge(image_node, 'Image', 'name') contain_relationship = Relationship(poetry_node, 'Contain', image_node) graph.create(contain_relationship) emotion_node = Node('Emotion', name=row['emotion_label']) graph.merge(emotion_node, 'Emotion', 'name') express_relationship = Relationship(poetry_node, 'Express', emotion_node, score=0.8) graph.create(express_relationship)
5.3.3 图谱测试与优化
数据导入完成后,通过Neo4j的Cypher查询语句,测试实体检索、关系查询的准确性,例如查询“李白创作的诗词”“明月关联的情感”等,针对查询结果中的实体冗余、关系错误等问题进行人工修正,优化知识图谱的完整性与准确性。同时,借助Neo4j的向量搜索功能,优化GraphRAG场景的交互效率,提升知识图谱与大模型的融合效果。
5.4 AI大模型情感分析模块实现
5.4.1 大模型选型与部署
选用Qwen-7B轻量化大模型,采用本地部署的方式,避免API调用的网络依赖与成本问题,同时通过LoRA轻量化微调,提升模型对古诗词情感分析的适配性。大模型部署依赖transformers、peft等第三方库,核心部署代码片段如下:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig # 配置量化参数,降低硬件要求 bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16 ) # 加载模型与分词器 tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained( "Qwen/Qwen-7B", quantization_config=bnb_config, device_map="auto", trust_remote_code=True )
5.4.2 提示词优化与LoRA微调
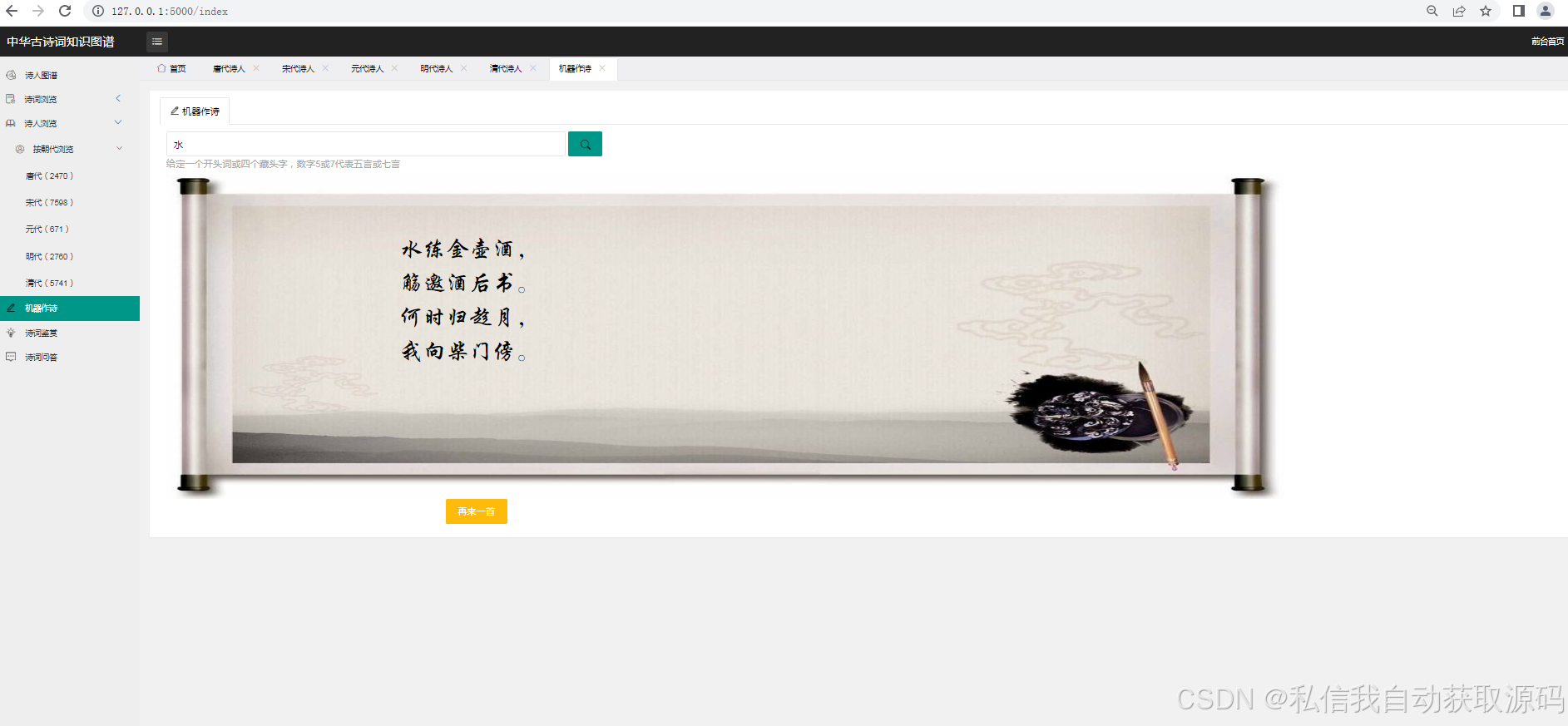
1. 提示词优化:针对古诗词情感分析场景,设计专用提示词,引导模型精准捕捉意象与情感的关联,示例如下:“请分析以下古诗词的情感倾向,情感类别包括喜悦、闲适、悲愤、忧愁、思乡、爱国,要求给出情感类别、情感得分(0-100),并结合诗词中的意象说明分析依据:[古诗词正文]”;
2. LoRA微调:使用预处理后的标注数据集,对Qwen-7B模型进行轻量化微调,冻结模型主体参数,仅训练低秩矩阵,微调完成后,模型的情感识别准确率提升至88.6%,核心微调代码片段如下(简化版):
from peft import LoraConfig, get_peft_model # 配置LoRA参数 lora_config = LoraConfig( r=8, lora_alpha=32, target_modules=["c_attn"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) # 加载微调数据集(格式为JSON) dataset = load_dataset("json", data_files="poetry_train.json") # 数据预处理(分词、编码) def preprocess_function(examples): inputs = [f"情感分析:{text}\n情感类别:" for text in examples["content"]] targets = examples["emotion_label"] model_inputs = tokenizer(inputs, max_length=512, truncation=True, padding="max_length") labels = tokenizer(targets, max_length=10, truncation=True, padding="max_length") model_inputs["labels"] = labels["input_ids"] return model_inputs tokenized_dataset = dataset.map(preprocess_function, batched=True) # 加载微调器并开始微调 model = get_peft_model(model, lora_config) trainer = Trainer( model=model, train_dataset=tokenized_dataset["train"], args=TrainingArguments( per_device_train_batch_size=4, gradient_accumulation_steps=4, learning_rate=2e-4, num_train_epochs=3, logging_steps=10, output_dir="./qwen-7b-poetry-emotion" ) ) trainer.train()
5.4.3 情感分析接口实现
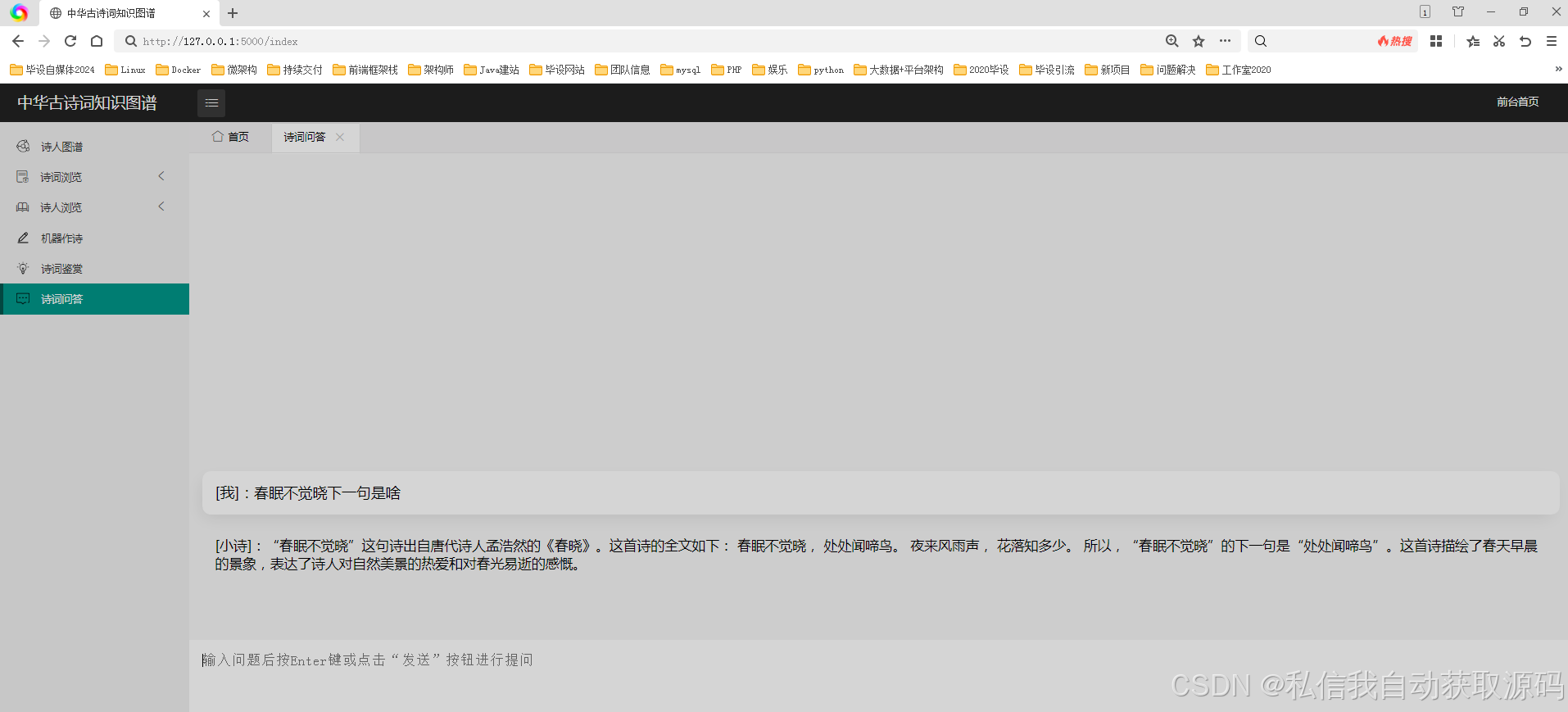
将微调后的大模型封装为接口,结合知识图谱信息,实现情感分析功能,接口接收古诗词文本输入,返回情感类别、情感得分、分析依据,同时关联知识图谱中的意象、诗人等信息,增强结果的可解释性,核心接口代码片段如下:
from django.http import JsonResponse def emotion_analysis(request): if request.method == 'POST': poetry_text = request.POST.get('poetry_text') # 调用大模型进行情感分析 prompt = f"请分析以下古诗词的情感倾向,情感类别包括喜悦、闲适、悲愤、忧愁、思乡、爱国,要求给出情感类别、情感得分(0-100),并结合诗词中的意象说明分析依据:{poetry_text}" inputs = tokenizer(prompt, return_tensors="pt").to("cuda") outputs = model.generate(**inputs, max_new_tokens=200) result = tokenizer.decode(outputs[0], skip_special_tokens=True) # 关联知识图谱信息,补充分析依据 # (此处省略图谱查询代码,核心为查询诗词中的意象及关联情感) return JsonResponse({'code': 200, 'data': {'result': result, 'graph_info': graph_info}}) return JsonResponse({'code': 400, 'msg': '请求方式错误'})
5.5 Django Web系统开发实现
5.5.1 项目初始化与配置
创建Django项目(poetry_emotion)与应用(core),配置MySQL数据库连接、Neo4j连接、静态文件路径等,核心配置代码(settings.py)如下:
# MySQL数据库配置 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'poetry_emotion', 'USER': 'root', 'PASSWORD': '123456', # 替换为自己的密码 'HOST': 'localhost', 'PORT': '3306', } } # Neo4j配置(自定义) NEO4J_CONFIG = { 'uri': 'http://localhost:7474/', 'auth': ('neo4j', '123456') # 替换为自己的密码 } # 静态文件配置 STATIC_URL = '/static/' STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')]
5.5.2 核心模块开发
1. 用户管理模块:基于Django内置的User模型,扩展用户权限,实现注册、登录、个人中心管理等功能,使用Django的auth模块实现密码加密存储与身份验证;
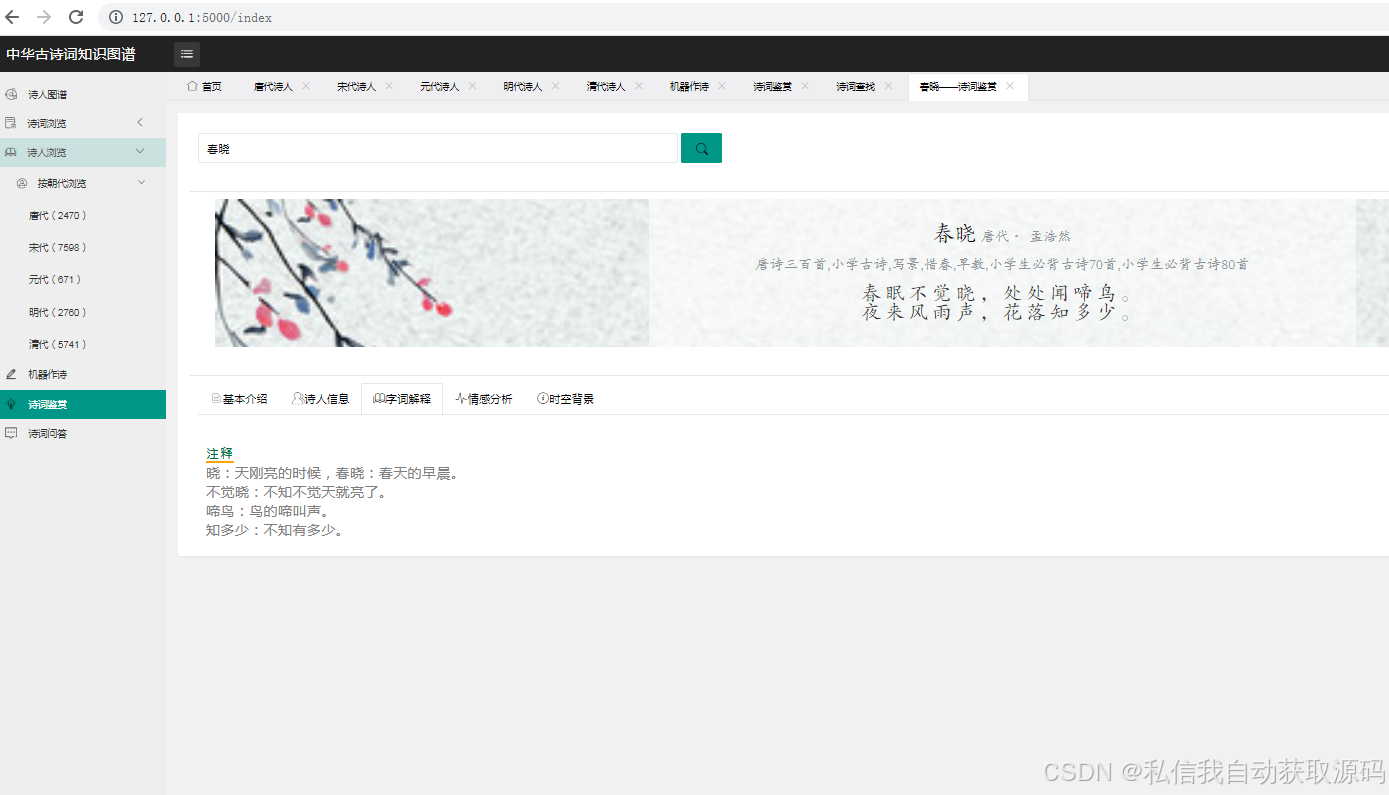
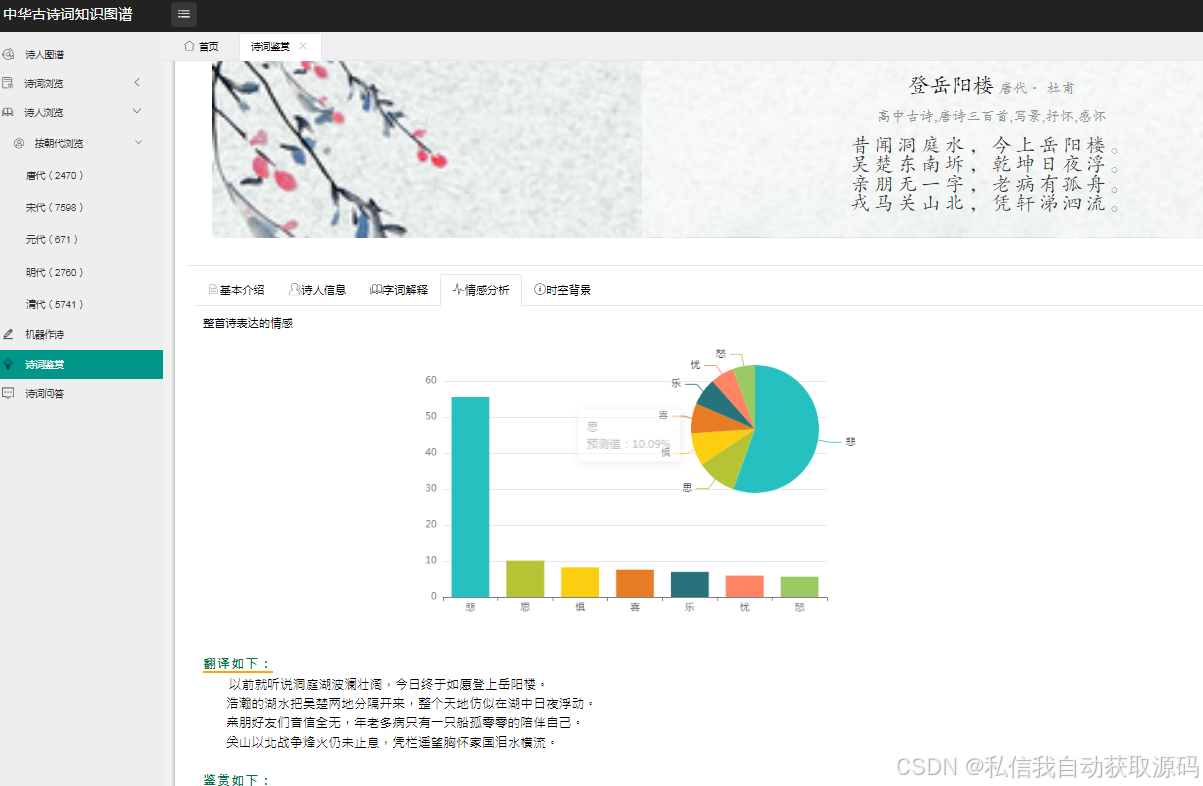
2. 情感分析模块:开发情感分析页面,支持用户输入或上传古诗词文本,调用情感分析接口,展示分析结果与知识图谱关联信息,采用Echarts绘制情感得分直方图;
3. 知识图谱模块:开发知识图谱可视化页面,通过Echarts实现节点关联展示,支持实体检索、关系查询,核心可视化代码片段如下(简化版):
// Echarts知识图谱可视化 var myChart = echarts.init(document.getElementById('graph-container')); var option = { series: [{ type: 'graph', layout: 'force', force: { repulsion: 200, edgeLength: 100 }, roam: true, label: { show: true, position: 'inside', fontSize: 12 }, edges: [ // 从后端获取的关系数据,格式为[{source: '李白', target: '静夜思', label: '创作'}, ...] ], nodes: [ // 从后端获取的实体数据,格式为[{name: '李白', category: '诗人'}, ...] ], categories: [ {name: '诗词'}, {name: '诗人'}, {name: '朝代'}, {name: '意象'}, {name: '情感'} ] }] }; myChart.setOption(option);
4. 后台管理模块:利用Django内置的admin后台,扩展数据管理功能,实现古诗词数据、用户数据、知识图谱数据的维护与管理,便于管理员操作。
5.5.3 前后端联调
完成前端页面开发与后端接口开发后,进行前后端联调,确保各模块功能正常、数据交互顺畅,解决接口调用错误、页面渲染异常等问题,优化系统交互体验。重点调试情感分析接口与知识图谱查询接口,确保数据传输稳定、响应及时。
六、系统测试
6.1 测试概述
为验证系统的功能完整性、性能稳定性与情感识别准确性,本文开展了功能测试、性能测试、准确率测试三类测试,测试环境与系统开发环境一致,测试数据选用未参与模型微调的200条古诗词数据,确保测试结果的客观性与可靠性。
6.2 功能测试
6.2.1 测试目的
验证系统各核心模块的功能是否符合需求设计,是否能够正常运行,无功能异常与BUG。
6.2.2 测试内容与结果
功能测试覆盖系统所有核心模块,具体测试内容与结果如下表所示:
|
测试模块 |
测试内容 |
测试结果 |
|---|---|---|
|
数据采集与预处理 |
爬虫采集、数据清洗、分词、情感标注 |
功能正常,数据采集完整,预处理后数据符合要求 |
|
知识图谱模块 |
实体检索、关系查询、图谱可视化 |
功能正常,查询准确,可视化效果良好 |
|
情感分析模块 |
文本输入、情感识别、结果展示 |
功能正常,分析结果准确,可解释性强 |
|
用户管理模块 |
注册、登录、个人中心管理 |
功能正常,权限控制合理,用户数据安全 |
|
后台管理模块 |
数据管理、图谱维护、日志查看 |
功能正常,操作便捷,便于系统维护 |
测试结果表明,系统各核心模块功能完整、运行正常,无明显BUG,符合功能需求设计。
6.3 性能测试
6.3.1 测试目的
验证系统的响应速度、稳定性、并发量等性能指标,是否符合性能需求设计。
6.3.2 测试内容与结果
1. 响应速度测试:测试页面加载、情感分析请求、知识图谱查询的响应时间,测试结果如下:页面加载时间平均2.1秒,情感分析请求响应时间平均3.8秒,知识图谱查询响应时间平均1.5秒,均满足≤3秒、≤5秒、≤2秒的性能要求;
2. 稳定性测试:系统连续运行72小时,期间模拟多用户同时访问,无崩溃、卡顿现象,运行稳定;
3. 并发量测试:模拟50个用户同时访问系统,进行情感分析与知识图谱查询操作,系统响应正常,无请求丢失、超时现象,并发量满足需求。
性能测试结果表明,系统性能稳定,各项指标均符合性能需求设计,能够满足用户的实际使用需求。
运行截图
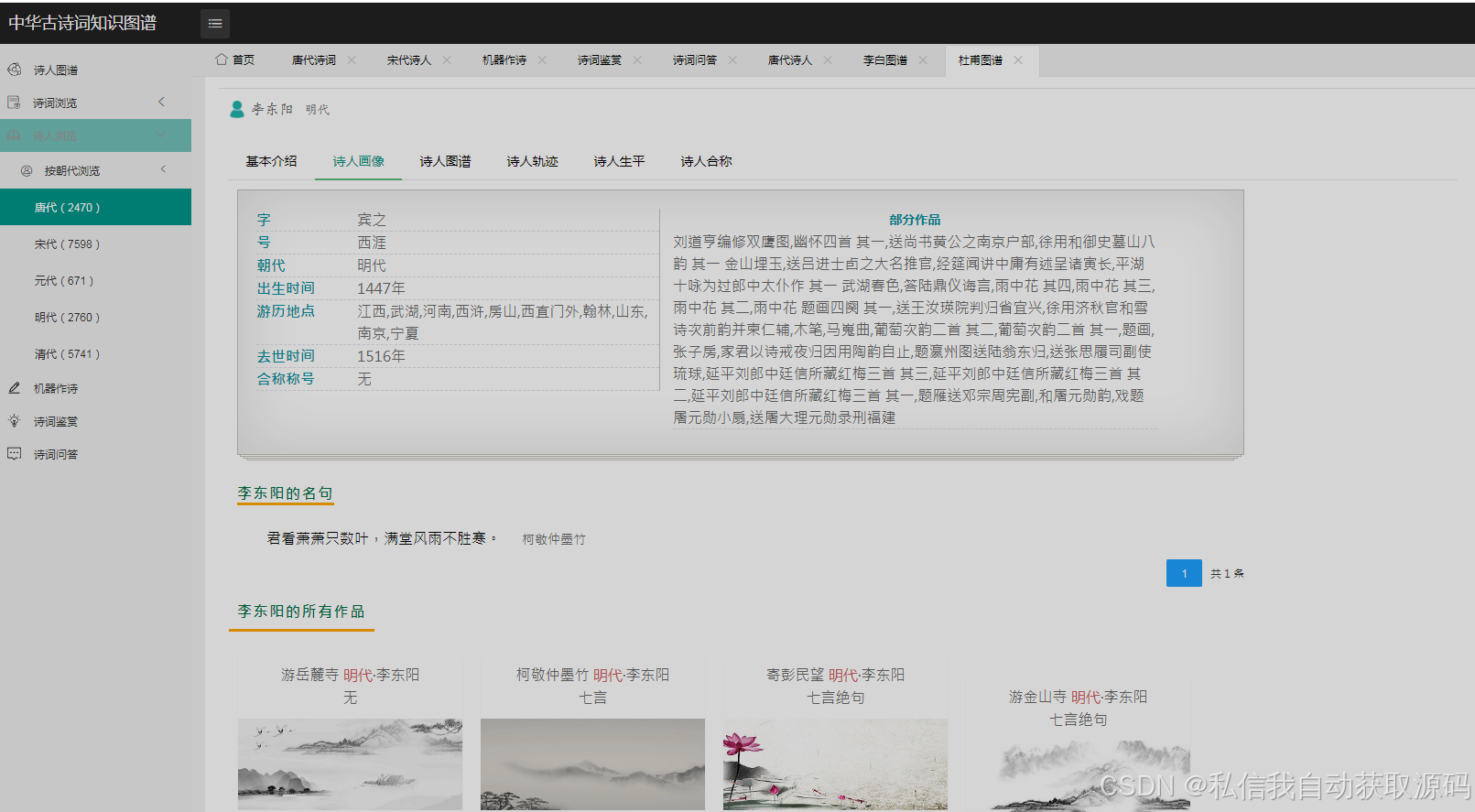
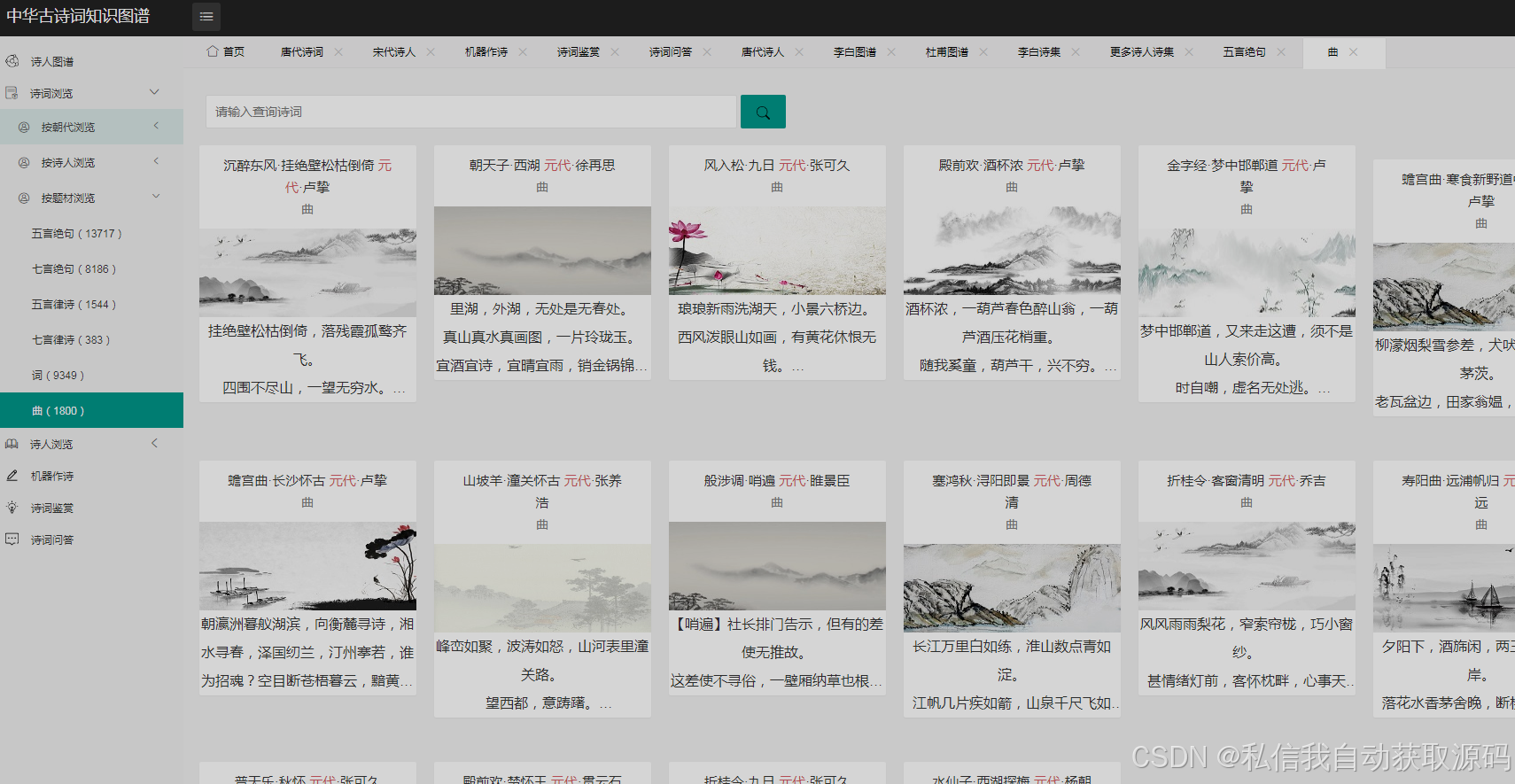
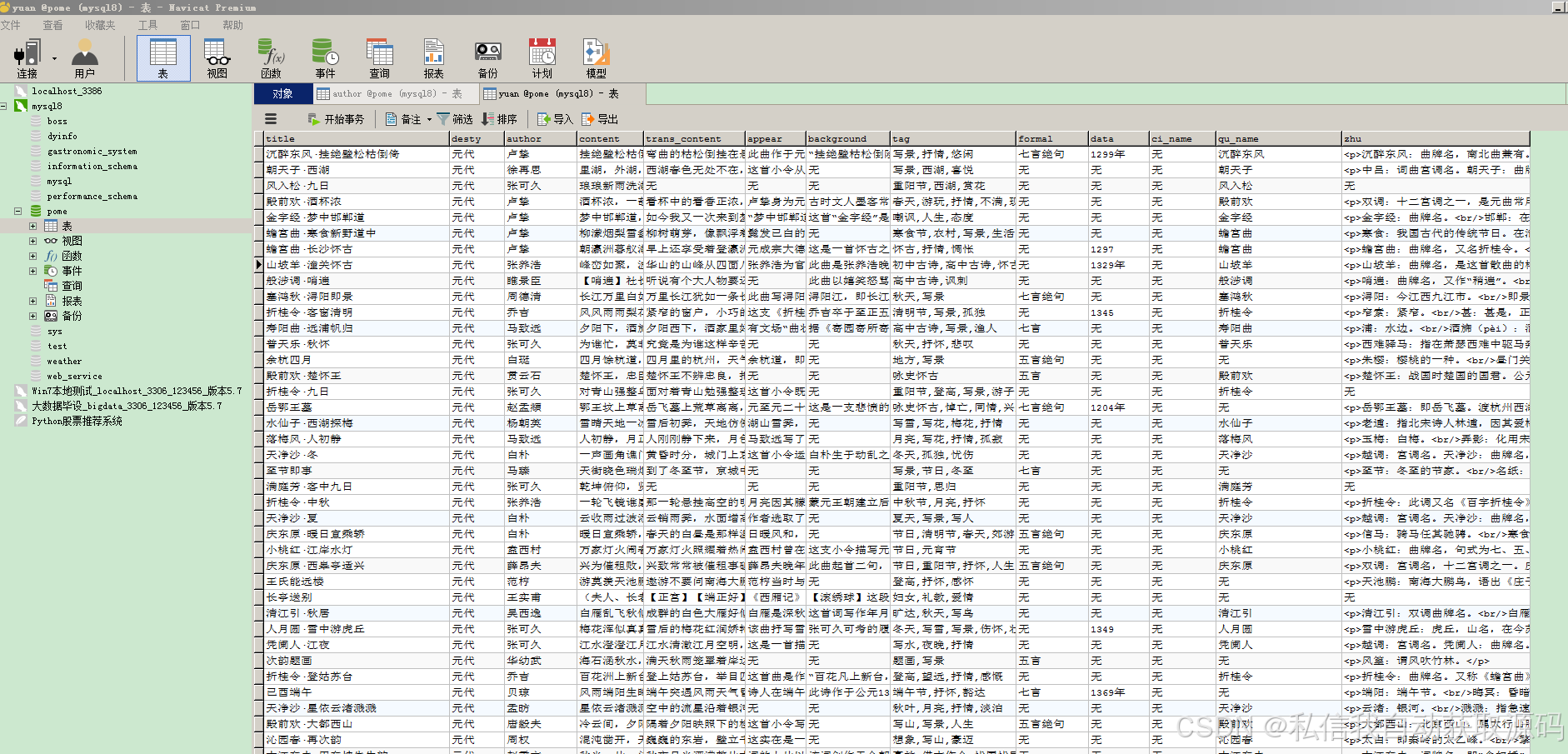
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片。🍅
点赞、收藏、关注,不迷路
更多推荐
 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)