
智体世界建模:基础、能力、法则及展望(上)
26年4月来自港科大、新加坡国立、牛津、南阳理工、港中文、港大、西雅图华盛顿大学和港科大(广州)等10单位的综述论文“Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond”。随着AI系统从单纯的文本生成向通过持续交互实现特定目标演进,对环境动态进行建模的能力正成为一个核心瓶颈。无论是操纵物体、在软件界面中导航、与其他
26年4月来自港科大、新加坡国立、牛津、南阳理工、港中文、港大、西雅图华盛顿大学和港科大(广州)等10单位的综述论文“Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond”。
随着AI系统从单纯的文本生成向通过持续交互实现特定目标演进,对环境动态进行建模的能力正成为一个核心瓶颈。无论是操纵物体、在软件界面中导航、与其他智体协同工作,还是设计科学实验,各类智体(Agents)都需要具备预测环境动态的能力,然而,“世界模型”(World Model)这一术语在不同的研究社区中却有着各异的内涵。为此,提出一套基于“层级 × 规律”双轴维度的分类体系。第一条轴线定义三种能力层级:L1 预测器(Predictor),负责学习单步局部的状态转移算子;L2 模拟器(Simulator),能够将这些算子组合成受动作序列驱动的多步演化过程,且该过程严格遵循特定领域的内在规律;L3 演化器(Evolver),具备自主修正自身模型的能力,即当其预测结果与新获取的证据相悖时,能够对模型进行自适应的修订。第二条轴线则划定四类主导性规律(governing law)领域(物理、数字、社会及科学),这些领域决定世界模型必须满足哪些约束条件,以及在何种情境下最容易发生预测失效。
基于这一分类框架,对400余项相关研究成果进行综合梳理,并归纳总结100多个具有代表性的系统案例,其应用范围涵盖基于模型的强化学习、视频生成、Web与GUI交互智体、多智体社会仿真,以及AI驱动的科学发现等诸多前沿领域。针对不同的“层级—规律”组合,深入剖析各类建模方法、潜在的失效模式以及相应的评估范式;同时,提出一套以决策能力为核心的评估原则,并构建一个旨在确保评估结果可复现性的最小化评估工具包;此外,还对世界模型的架构设计提供指导性建议,并指出当前尚待解决的开放性难题及相关的治理挑战。
从互补的视角来看,世界模型与智体之间存在紧密的耦合关系。从本质上讲,世界模型旨在学习环境的状态转移动力学:即给定当前状态与某一动作,它能够预测由此产生的下一状态。反观智体,它则是依据特定的任务目标及当前的观测信息来选取相应的动作。这两大组件相辅相成、互为支撑。智体依赖世界模型来预判备选动作可能引发的后果,从而得以实现前瞻性规划以及高样本效率的学习(Hafner et al., 2025; Schrittwieser et al., 2020; Dong et al., 2026; 2025)。反之,世界模型也能从智体所产生的经验中获益;这些经验提供具有针对性且与任务高度相关的轨迹数据,进而提升了模型在状态空间中那些对决策至关重要的区域内的预测精度(Sutton, 1991)。正是这种紧密的耦合关系,构成了本综述所秉持的“基于能力”这一视角的基础:尽管世界模型具有多重用途,但在操作层面上,将其价值界定为它能够为下游智体所赋能的决策质量。
下图2从两个维度——范围(从特定领域到跨领域)和组织原则(从以模态为中心到以能力为中心)——将本综述置于现有研究的背景之中。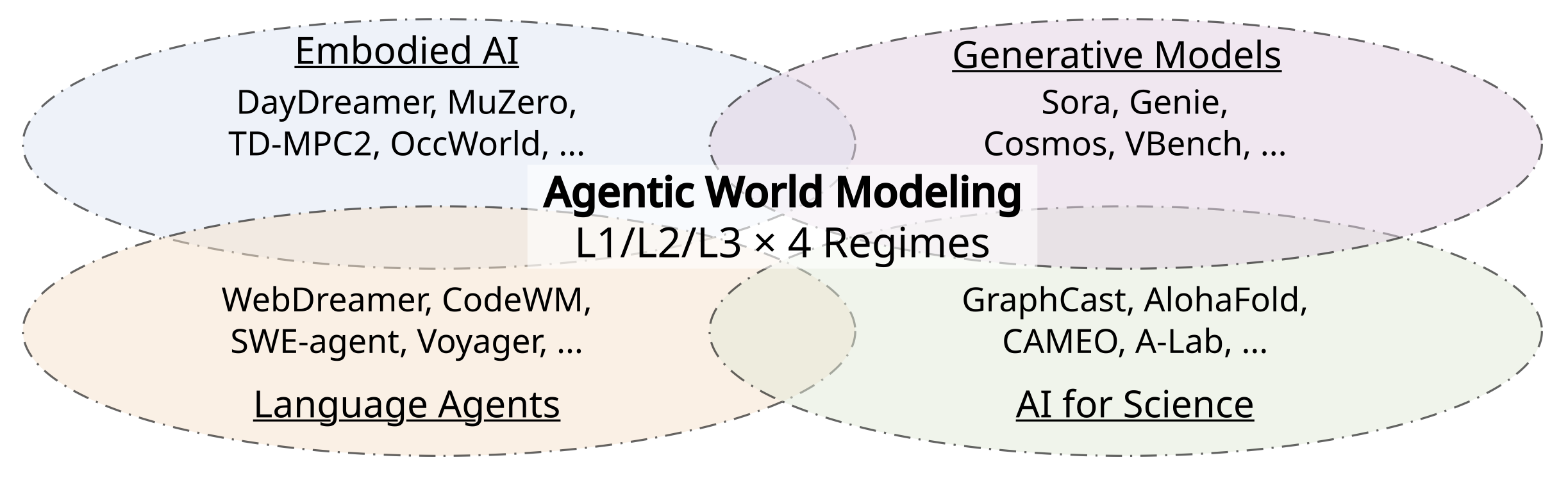
如图1直观地展示本文的整体架构,依据三种能力层级(L1 预测器、L2 模拟器、L3 演化器)以及四类主导定律(governing law)体系(物理世界、数字世界、社会世界和科学世界)对各章节进行归类。
跨领域的通用原则。本文围绕两个正交轴展开论述:(i) 能力层级(L1/L2/L3);以及 (ii) 支配性法则体系——即在特定领域内,任何合规的状态跃迁所必须满足的约束条件。这些层级代表的是“世界建模能力”的不同阶段,而非彼此互斥的模型类别:同一个系统完全可能根据任务需求的差异,在不同时刻调用不同层级的能力。如图3以示意图的形式概述了这四大法则体系。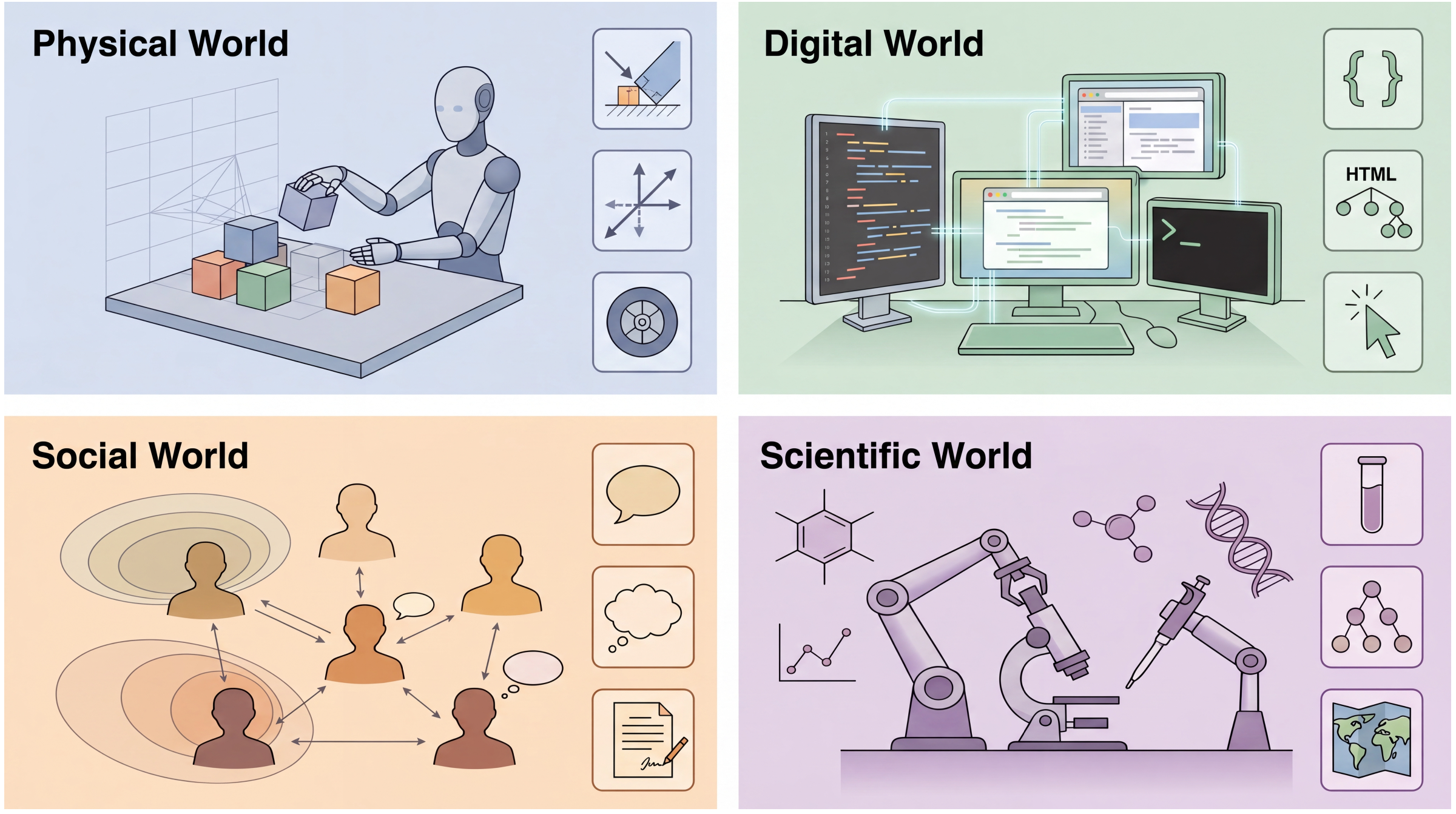
• 物理世界的法则:感知;物理交互;机器人操纵、导航、自动驾驶、第一人称视角视频预测、基于动作条件的视频建模、三维世界建模等。
• 数字世界的法则:程序语义;网页导航、软件工具使用、GUI环境等。
• 社会世界的法则:信念;目标;规范;社会协作、对话交互、多智体场景等。
• 科学世界的法则:潜在机制;实验可观测量;因果结构;科学发现流程、结合测量的预测、假设驱动型实验等。
智体在运行时如何运用这三个层级?L1/L2/L3 的分类体系并非对系统的静态归类,而是用于描述智体在特定时刻所调用的能力。同一个已部署的系统,可以根据任务需求在不同层级上运行:
- L1(预测器):智体执行快速、反应式的单步预测任务(例如感知、低层级运动控制或逐token生成),且无需维护多步规划。
- L2(模拟器):当任务要求智体对比候选动作序列、对替代性的未来情景进行反事实推理,或验证规划的轨迹是否符合既定的约束法则时,智体便会升级至此层级;在此层级下,智体会在正式执行前先进行多步模拟推演。
- L3(演化器):当智体当前的模型产生系统性的预测失效,且这些失效无法通过在现有模型结构内进行重新规划来解决时,智体便会提升至此层级。换言之,当模型本身必须进行修订、相关资产需要进行蒸馏提取,且更新内容需在下一次部署前通过验证时,即进入此层级。
这种基于运行时的调度视角阐明了为何 L3 并非 L1/L2 的替代品,而是一个“治理层”——它仅在有确凿证据表明必要时,才会介入并对整个技术栈进行改进。在一个完整的智体技术栈中,“世界模型”仅仅是其中的一个组件:工具的使用决定了智体如何对环境施加作用;记忆机制决定哪些证据能够在跨episodes的交互中得以留存;多智体协作机制塑造在社交情境下的有效状态转移动态;而反思机制则决定何时应将失败视为触发模型修订的信号,而非仅仅进行简单的重新规划。尽管研究重心在于作为基础支撑的“世界模型”,但其所扮演的角色始终是为了服务于上述这些更为宏大的智体运行循环。
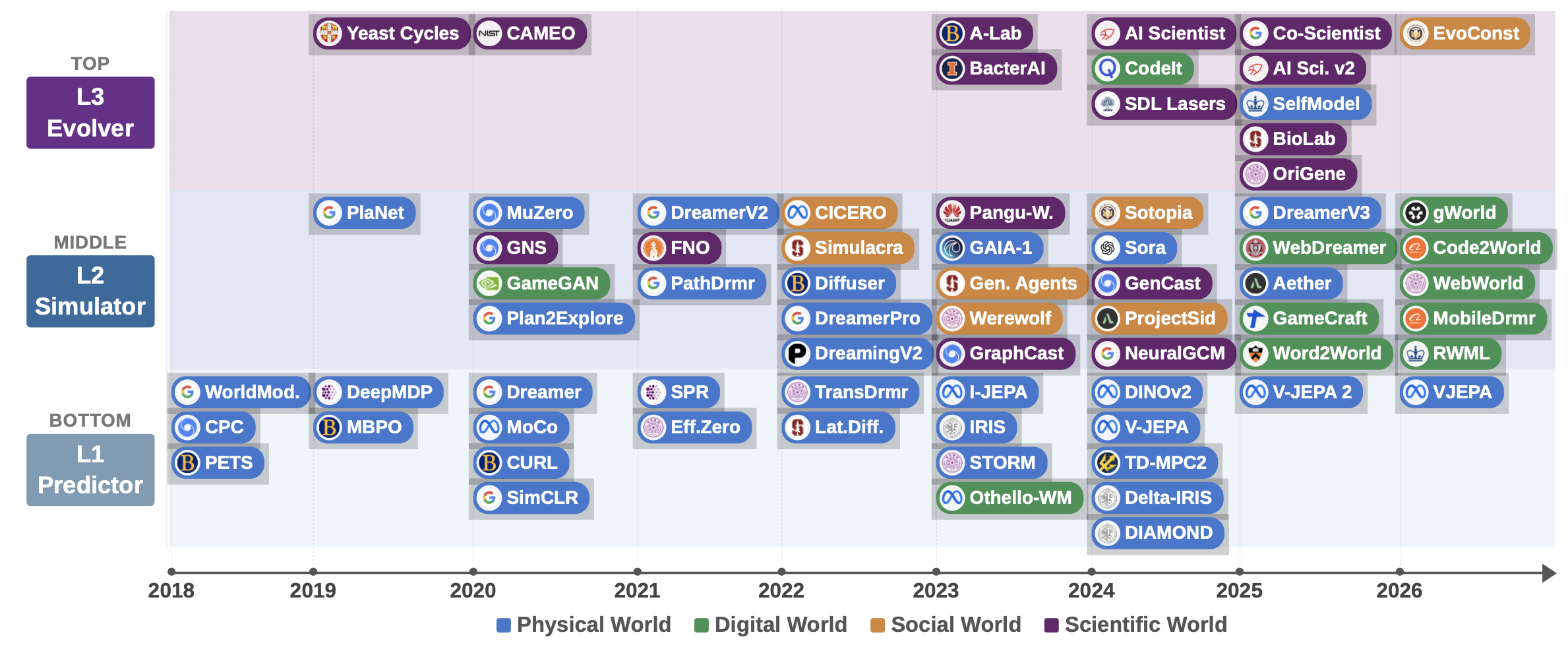
如图 4 所示按能力层级划分的代表性世界建模系统时间轴(2018–2026年)。该路线图展示70个调研锚点;为确保可读性,每个“年份-层级”单元格内的系统数量上限设定为五个。L1 预测器(Predictor)指单步动态预测能力;L2 模拟器(Simulator)指可用于决策的多步推演能力;L3 演化器(Evolver)指完全由实证驱动的模型修正能力。图中的每一个色块(“药丸”状图标)均依据其所遵循的“主导定律(governing law)体系”进行着色区分:物理体系(蓝色)、数字体系(绿色)、社会体系(橙色)以及科学体系(紫色)。
1 哲学动因
对于任何关于“世界模型”(world-modeling)的综述而言,一个自然而然的问题是:一个系统在从单纯的“模式匹配”向真正的“建模”演进的过程中,究竟经历哪些理解阶段?认识论——即研究何为知识以及知识如何增长的学科——提供一个有益的视角。不同的哲学传统对不同类型的“认识成就”有着本质上的区分;借鉴这些传统,为世界模型提出一套三层级的“能力层级体系”。这些哲学类比旨在提供启发,而非意在追溯历史渊源或建立一一对应的关系。并非声称机器学习(ML)系统是在刻意践行某种哲学纲领,而是认为:哲学上的区分有助于洞察为何某些能力边界会在不同领域中反复出现,以及每个阶段所突显的核心设计问题究竟是什么(参见图5所示)。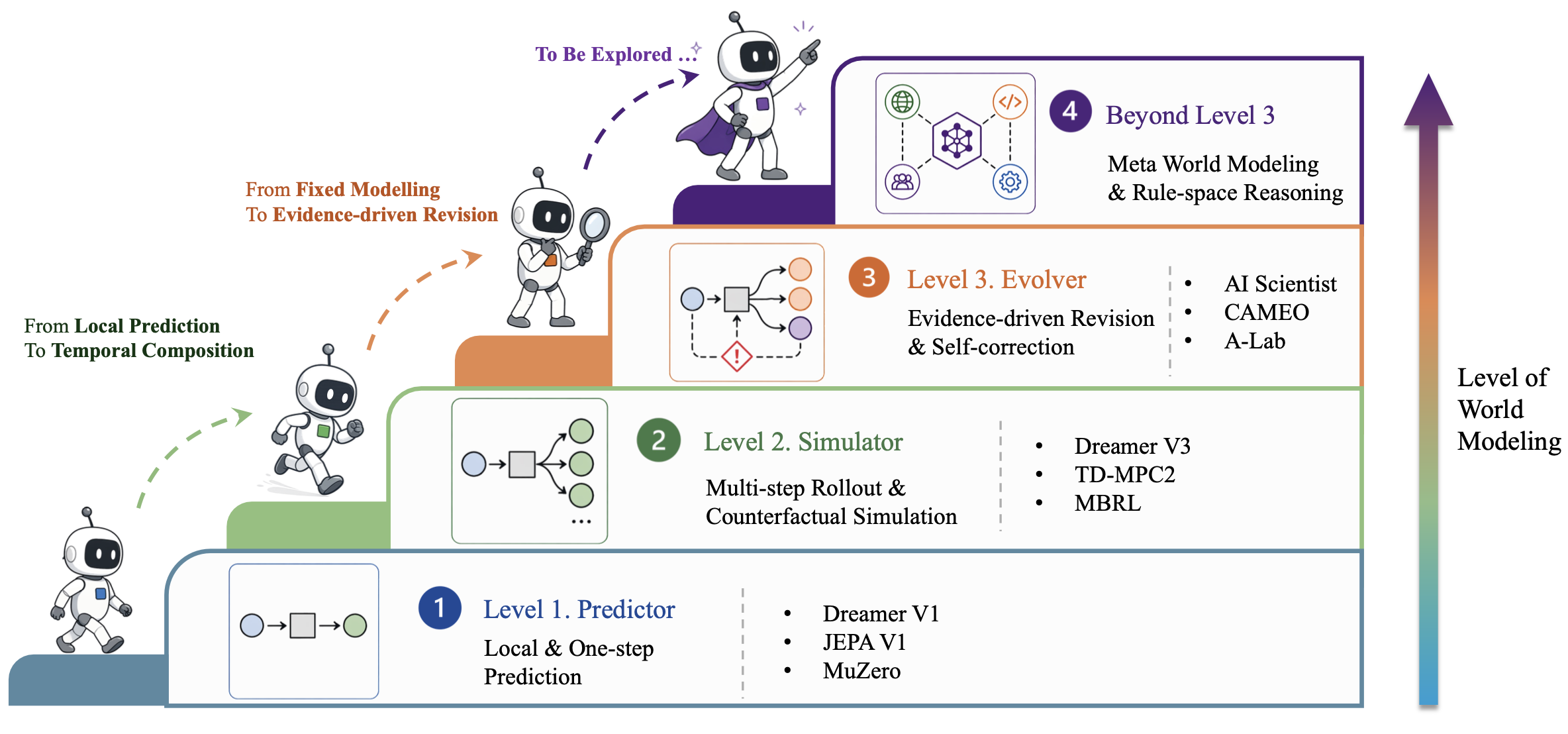
L1 预测器(Predictor):从模式到单步预测。最基础的认识成就莫过于从数据中学习模式:即在给定过往观测数据的前提下,预测下一个观测结果。在哲学语境下,这恰好对应于休谟(Hume, 1739)所提出的“恒常结合”(constant conjunction)概念;在此情境下,智体仅记录统计学上的共现现象,却并不探究这些现象为何成立。当一个模型能够从数据轨迹中习得“单步潜状态转移”时,它所处的正是这样一种认识论地位:它从数据流中提取出事件的先后承接关系,并基于一种信念进行押注——即这种模式在未来仍将持续有效。这一观点与认知科学领域的“预测编码”框架(Rao & Ballard, 1999; Friston, 2010)相契合,同时也呼应“贝叶斯脑”假说(Clark, 2015)——该假说认为感知本质上是一种概率推断过程;这些理论共同确立“单步潜状态预测”作为一种基础计算原语(computational primitive)的重要地位(Lake et al., 2017)。
这一阶段命名为 L1(预测器)。然而,这种带有休谟色彩的认知立场具有内在的脆弱性。绝大多数机器学习算法所依赖的“独立同分布”(i.i.d.)假设,实际上正是休谟所提出的“齐一性原理”(Uniformity Principle)的翻版——即预设“未来将与过去保持相似”;因此,一旦数据分布发生漂移(即所谓的“分布外”场景),那些仅凭学习的规律性进行预测的 L1 模型便会因缺乏泛化能力而失效。尽管如此,这种基于过往经验的预设仍提供最基础的“归纳偏置”(inductive bias),而这正是构建各类模型所不可或缺的基石。
L2 模拟器(Simulator):推演与反事实。仅仅依靠模式匹配,尚不足以回答这样一个问题:如果采取不同的行动,结果将会如何?下一阶段引入了干预与反事实推理:即在选定的行动或假设的初始条件下,推演并生成连贯的未来情景,并利用这些结果辅助决策的能力。大卫·刘易斯(David Lewis)的“最近可能世界”理论(Lewis, 1973)恰好捕捉到了这一跃升:有效的反事实推理旨在探索那些与现实世界“极度相似”的可能世界——在这些世界中,仅需极微小的干预,便足以区分现实结果与反事实结果。这提供一个具有原则性基础的推理框架,能够推断:若智体在决策关头采取不同的替代行动,结果将会如何。
这一阶段称为 L2(模拟器)。鉴于 L2 阶段的推演结果是“模型相对”的,其可靠性取决于已学习模型的内部状态转移结构,而非直接获取的“真值动力学”(ground-truth dynamics)。因此,它面临着产生“认知漂移”(epistemic drift)的风险——即模型虽然能在其训练数据流形(training manifold)内部生成逻辑自洽的轨迹,但这些轨迹可能已偏离客观现实。柏拉图的“洞穴寓言(Allegory of Cave)”(Plato, 1992)为此提供一个生动的隐喻:一个擅长预测墙壁上“影子”的模拟器,其能力终究受限于墙壁本身的维度;它能预测影子,却无法触及那投射出影子的“火”本身。
L3 演化器(Evolver):基于证据进行模型修正。即便是一个功能强大的模拟器,最终也会遭遇其预测结果系统性失效的窘境。这种失效并非源于参数设置的微小误差,而是因为模型本身的类别(model class)过于狭窄,已无法涵盖现实世界的复杂性。认识论(Epistemology)为描述这一转变提供丰富的术语。拉卡托斯(Lakatos)关于科学理论包含“硬核”(hard core,即架构与归纳偏置)与“保护带”(protective belt,即习得参数)的区分(Lakatos, 1978),便为此提供一个极具启发性的类比。梯度下降等优化步骤主要调整的是模型的“保护带”(即参数);而若遭遇持续且结构性的错误,则往往需要对模型的“硬核”进行大刀阔斧的修改——例如引入全新的模块、解析器、约束条件,或是对模拟器底层接口/钩子(hooks)进行重构。
这一阶段命名为 L3(演化器):即当客观证据提出要求时,系统具备彻底“重建实验室”的能力。这一阶段将“设计—执行—观察—反思”的完整循环推向新的高度:系统不再仅仅局限于进行模拟推演,而是能够主动设计实验方案、亲身执行实验、观察实验结果,并基于反思对自身的模型栈(model stack)进行迭代与修正。杜恒—蒯因整体论(Duhem–Quine holism)(Duhem, 1954; Quine, 1951)恰好解释为何在这一过程中,“归责”(blame-assignment,即定位错误源头)是一项绝非易事的任务。在诊断工具最终锁定那个存在缺陷的组件之前,错误的责任往往会在各个模块之间不断地重新分配与转移。拟议的修订应当在保留探针(probes)、回归测试套件或实验结果上产生可衡量的改进,而非仅仅是那种无视环境所提供的反证、旨在维系现有模型的“事后调整(post-hoc adjustment)”。
2 世界建模中的表征:来自科学理论的启示
能力层级体系阐述世界模型能够实现的功能,但却留下一个更基础的问题尚待解答:世界模型究竟应当以何种形式进行实际表征?这一问题不应仅仅被视为一种实现细节;相反,它决定上述定义的能力——尤其是L3层级的模型修正能力——能否在各类应用领域中真正落地实现。
从历史角度看,基于符号的机器学习方法在扩展性方面曾遭遇瓶颈,这促使现代系统转而采用隐式、潜表征方式。在此背景下,科学理论提供一个极具启发性的对照案例。牛顿定律、麦克斯韦方程组以及粒子物理学的“标准模型”,皆是采用紧凑符号形式表达的世界模型典范;它们堪称人类迄今为止构建得最为成功的L3层级系统实例:即具备显式性、可修正性及可组合性。这种鲜明的反差迫使该领域直面一个长期被回避的核心问题:世界建模的终极目标究竟是实现符号化的规律发现,将神经网络的潜表征仅作为一种辅助性的“脚手架(scaffold)”,抑或是将潜动态本身视为最终的追求?
在科学探索的过程中,模型的更新与修正往往发生在多个尺度之上:微小的异常现象通常仅引发局部的微调;而诸如19世纪末物理学界所面临的“两朵乌云”(开尔文,1901年)那样的持续性反常现象,则揭示了既有认知体系中的根本性鸿沟,进而迫使科学家对理论所蕴含的“不变性结构”进行彻底的修正。以从牛顿力学向相对论力学的演变为例,这一转变的核心在于将伽利略不变性替换为了洛伦兹不变性。现代机器学习系统同样内嵌了各类不变性特征——例如卷积网络中的平移等变性,以及基于注意机制的模型中所体现的“形状偏置”(Geirhos et al., 2018)——但这些不变性并非以显式、可直接修改的结构形式存在,而是通过网络架构设计与训练过程隐式地固化在模型之中。这种隐式处理方式虽足以支撑固定模型框架下的L1层级预测任务与L2层级仿真任务,但在涉及L3层级任务(即对模型结构本身进行修正与重构)时,却反而演变为一种制约与短板。相比之下,符号化表征方式能够将支配性的基本原理作为“第一类对象”(first-class objects)显式地呈现出来,从而允许研究者对其进行直接的审视与修改。
因此,将“表征”视为关于“世界模型究竟为何物”的一个根本性问题,而非仅仅在几种可互换的设计方案之间进行取舍。尽管潜动力学(Latent dynamics)作为 L1 和 L2 阶段的脚手架必不可少,但 L3 阶段的终极目标——即对主导规律(governing law)进行实质性的修订——却必须依赖于一种符号化的底层基质。基于这一视角,L1 → L2 → L3 这一演进序列所体现的,不仅是推演深度的递增,更是规律被发现、构建及修订方式的层层升华。
如图6所示世界建模的历史演进历经四个时代:数学原理时代(–1956年)、符号智能时代(1956–1986年)、联结主义复兴时代(1986–2020年)以及生成式革命时代(2020年至今)。两次“AI寒冬”(1974–1980年、1987–1993年)标志着范式之间的过渡。优秀的世界模型表征应当是与具体实例化无关的。
“主导法则”划分为:物理世界的法则(管辖在物理环境中进行感知与行动的智体)、数字世界的法则(管辖确定性的程序语义:代码、API及状态机)、社会世界的法则(管辖心智与制度的动态演化:信念、目标及规范),以及科学世界的法则(管辖独立于人类设计而存在的系统,其动态演化必须通过实证观察来揭示)。这四类领域仅具代表性,并非涵盖所有情况。现实世界的系统往往同时受制于多种法则。例如,自动驾驶既涉及物理动力学,也涉及社会规范;而药物设计则将自然机制与数字仿真流程紧密结合。
”物理世界的法则“通过物理动力学来约束状态的转移——这是具身智体(embodied agents)必须遵循的规律:包括接触力学、碰撞响应、重力加速度、摩擦力以及运动学可行性。在机器人操作、自动驾驶及交互式三维仿真等领域中,所学习的状态转移模型必须忠实地编码这些物理交互过程(Todorov et al., 2012; Hu et al., 2023; Wang et al., 2024h)。这一领域的显著特征在于其主导方程具有可解析表征的形式。物理引擎或解析模型能够验证某一预测的状态转移是否符合刚体约束及牛顿力学原理。违反约束的情况通常表现为物体相互穿透、在仿真推演过程中重力方向发生反转,或出现物理上不可能发生的形变。此类故障极易被检测出来,因为其“真值动力学(ground-truth dynamics)“往往具有封闭形式解或数值精确的参考解。
”数字世界的法则“通过确定性的程序语义来约束状态的转移,具体涵盖API契约、用户界面(UI)状态机、文件系统逻辑以及网络协议等。在网页导航、代码生成及软件测试等应用场景中,状态转移函数虽然在本质上具有高度的确定性,但其执行路径往往会因错误代码、权限检查及边缘案例(edge cases)的存在而产生大量的分支(Gu et al., 2025b; Yao et0 al., 2022)。这一领域的定义特征在于:其状态转移过程既是可明确规约的(specifiable),又是可验证的。具体而言,程序可以被实际执行,其输出结果可与模型所作的预测进行比对。违反约束的情况通常表现为:生成了不存在的API调用、忽略了系统返回的错误代码,或违反了类型约束规则。由于底层系统是一种形式化的人造产物,因此此类错误是可以进行机械化检查的。
“社会世界法则”通过信念、目标、规范、社会契约和制度规则来约束状态的演变。在社会仿真、对话系统和多智体交互领域,转移函数将联合行动与心理状态映射为新的心理状态及社会结果(Park et al., 2023; Zhou et al., 2025b)。该领域具有两项显著特征,使其独树一帜。首先,状态演变具有“自反性”(reflexive),这意味着智体关于当前状态的信念会主动地改变该状态本身。其次,状态演变具有“规范性”(normative),其演变过程不仅受制于“将会发生什么”,更受制于依据共享惯例“应当发生什么”。违反此类约束的表现形式包括:违背承诺却未受惩罚、遗忘先前的承诺,或无视既定的社会规范。此类失效现象会破坏系统的内在一致性,因为社会结果的产生往往依赖于主体之间的相互预期。
“科学世界法则”通过潜在的因果机制来约束状态的演变;这些机制必须通过实证观测加以发现,而非预先人为设定。在天气预报、分子动力学、蛋白质折叠和药物设计等领域,转移函数编码大气动力学、化学动力学或生物学过程;这些过程的确切函数形式往往尚不明确,或因过于复杂而无法通过解析式进行书写(Karniadakis et al., 2021; Lam et al., 2023; Abramson et al., 2024)。该领域的独特之处在于,其主导方程无法以“封闭形式”(closed form)直接获取。因此,世界模型必须从数据中学习这些方程,并依据实验测量结果对其进行验证。违反此类约束的表现形式包括:预测出在物理上不可能存在的分子构型、违背经实证检验成立的守恒定律,或无视已知的因果依赖关系。对这类错误的检测通常需要将模型结果与实验室数据或观测数据进行比对,而非采用符号化的形式验证手段。
如图 7所示L1-L3 层的统一 “部分可观测马尔可夫决策过程”(POMDP)图形模型:虚线圆圈表示隐环境状态 x;双重圆圈表示已学习的潜状态 z;阴影圆圈表示观测值 o;正方形表示动作 a。蓝色实线箭头表示已学习的模型(包括推断与动力学);灰色虚线箭头表示环境转移 T 和观测生成过程。上方区块展示智体在当前环境 E ~ X 下、基于模型 M_t 时的 POMDP 结构;下方区块展示在经由红色“反射”箭头作用后所产生的修订环境 E’ ~ X’ 下、基于模型 M_t+1 时的相同结构。彩色虚线框标示各层级的涵盖范围:L1 涵盖单步潜状态转移;L2 涵盖在固定模型下的完整轨迹展开过程;L3 涵盖由证据驱动的模型修订过程 M_t → M_t+1,该过程对应于在当前模型出现系统性失效时,从环境 X 切换至修订后的环境 X’ 的转变。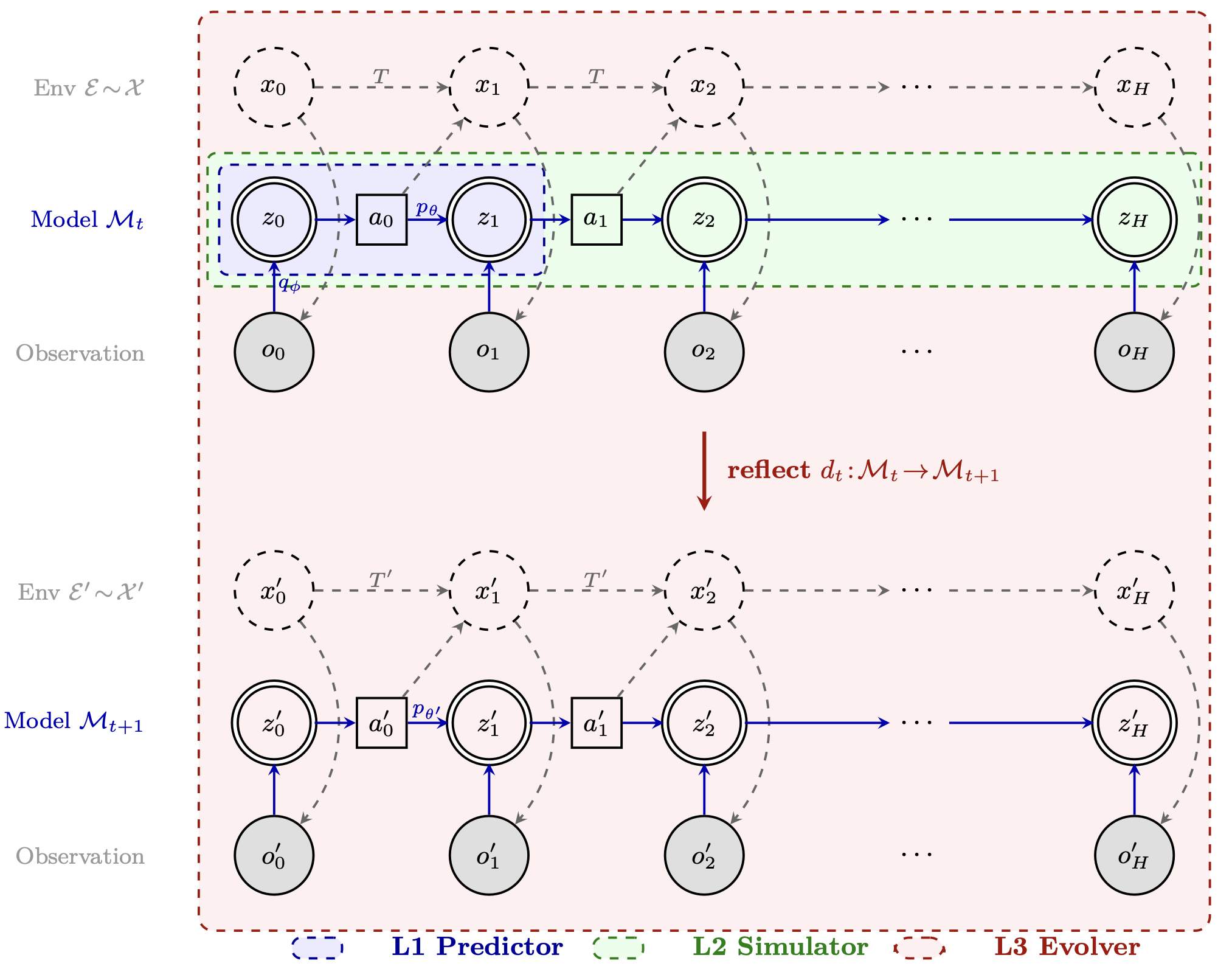
以智体为中心的视角:状态、动作与任务。上述形式化组件描述一个智体,其决策由三个要素决定:它所认知的世界当前所处的状态、它能够执行的动作,以及它必须满足的任务(或约束 c)。正是这一三元组——而非简单的“观测到动作”的扁平映射——定义世界模型与规划器之间的接口。构建一个有用的状态表示 z_t 涉及两个相互正交的挑战,这也构成了结构基础:(i) 空间表征:将高维观测 o_t 压缩为紧凑的潜表示,同时保留与决策相关的结构信息(如几何特征、语义信息及功能启示);(ii) 时序融合:整合历史信息,确保 z_t 即使在部分可观测的环境中,也能近似地表达一种马尔可夫信念。动作并非简单的扁平变量:它们可以经由表征学习自然涌现,而非必须预先定义;其中,核心的动力学规律由潜表征所捕获,而其余部分则充当解码器(LeCun, 2022)。现实世界中智体的行为在时间尺度和抽象层级上呈现出分层分解的特征,具体包括低层的运动基元、中层的技能、以及高层的任务规划。世界模型必须以与规划器查询视界(query horizon)相匹配的粒度,来预测状态的转移过程。这种动作层级结构与 L1 到 L2 的层级边界直接相关:对于基元层级的预测而言,仅需考量局部动力学特性便已足够(Sun et al., 2025a);然而,针对技能层级及任务层级的展开(rollouts),则必须具备 L2 层级所特有的那种跨步长的一致性。在 L3 层级,智体不仅需要预测跨越不同时间尺度的状态转移,还必须能够判断自身的转移模型何时已显不足,并适时启动模型的修正与更新。L3 层级将整个“世界模型栈”本身视为智体动作的直接作用对象。此时,诊断探查、架构调整以及回归测试等手段,便转化为作用于模型而非环境本身的“元动作”(meta-actions);它们重塑系统的学习方式,而不仅仅是改变其具体的行动表现。
这种层级结构始于 L1 层级;该层级通过要求世界模型维持一种有意义的内部状态,并利用局部预测机制来预判下一时刻的状态(包括潜观测结果或动作),从而评估该模型的局部预测能力。L1 层级对应于在动作 a_t-1 的条件下,由单条边 z_t-1 → z_t 所涵盖的范围。
1 定义
L1 关注的是世界模型对于在环境中执行任务或达成目标的智体(Agent)所具备的“局部预测能力”。更确切地说,智体是一个系统,它在接收到观测信息后,会做出决策并采取行动,以期实现预定的目标。因此,在本文中,L1 世界模型的作用不仅仅是简单地预测下一个信号,而是提供一系列“局部预测算子”,从而在单步(或一段固定的短时程)的粒度上为上述决策过程提供支持。这种认知立场与休谟(Hume)提出的“恒常结合”(constant conjunction)概念相吻合:即规律性是从观测数据中提取出来的,并不预设其间存在因果必然性。
作为 L1 理论基础的“部分可观测马尔可夫决策过程”(POMDP)形式化框架,源自强化学习领域的相关文献;在该领域中,智体必须在“部分可观测”的环境条件下选择行动,以实现累积奖励的最大化(Kaelbling et al., 1998; Puterman, 1994)。在此设定下,智体会在内部维护一个关于隐状态(hidden states)的“信念”(belief),并构建一套将这些信念映射至具体行动的策略。这一形式化框架构成典型的“智体—环境交互循环”(Sutton, 1991)。对于一个通过与环境交互来完成任务的智体而言,POMDP 框架可被拆解为四个局部算子:状态推断、正向动力学、观测解码以及逆向动力学。这四个算子共同构成 L1 层面世界模型所涉及的基础性学习问题。
依据上述形式化框架,L1 级世界模型的显著特征在于其局部预测算子是基于一个经学习获得的“内部状态”z_t(类似于信念状态)进行操作的;其中,其核心建模理念聚焦于构建一个“单步”(或固定短时程)的状态转移算子。在实际应用层面,z_t 是根据观测信息与智体所采取的行动推导而来的,并充当着对环境潜状态和/或智体内部信念的一种经学习获得的近似表征(Hafner et al., 2025; Schrittwieser et al., 2020)。这种对潜动力学机制进行学习的理念,其渊源可追溯至用于控制领域的“局部线性隐变量模型”(Watter et al., 2015)以及“高斯过程动力学模型”(Deisenroth & Rasmussen, 2011);而在当代深度学习架构的加持下,这一理念已得到进一步的强化与升华(Ha & Schmidhuber, 2018; Hafner et al., 2020)。 L1 中的术语“Markov”(马尔可夫)指的是所学内部状态 z_t 所具备的马尔可夫性质;这表明 z_t 足以(或几乎足以)预测随后的局部步骤,而非指环境状态本身具有直接可观测性(Hafner et al., 2019; 2025; Gelada et al., 2019)。
在模型层面,L1 可分解为作用于 z_t 的四个局部算子。其核心算子是潜变量动力学(z_t-1 -> z_t);其余则是常见的辅助算子:
• 状态推断(观测 -> 状态):这种学习的、类似信念状态(belief-like state)的表示,对用于预测的相关历史信息进行了归纳总结(Hafner et al., 2019; Lesort et al., 2018)。
• 正向动力学(状态 -> 下一状态;L1 的核心算子):可分为受动作制约(action-conditioned)或不受动作制约(action-free)两种形式。
• 观测解码(状态 -> 观测):将潜变量状态映射回观测空间(Kingma & Welling, 2014; Rezende et al., 2014)。
• 逆向动力学:用作辅助目标或用于表征塑造(representation shaping)(Pathak et al., 2017; Hafner et al., 2020)。
2 方法
基于四种局部算子,对值得关注的 L1 技术进行归类:状态推断(旨在从观测数据和历史数据中推导出 z_t)、前向动力学(即基础的状态转移模型)、观测解码(将 z_t 与 o_t 建立关联),以及逆向动力学(从连续的状态序列中推断出动作)(Ding et al., 2025a; Moerland et al., 2023)。在前向动力学这一部分投入最多的笔墨,因为它是最直接决定 L1 系统能否进一步升级为 L2 模拟器的关键算子;尽管其他组件同样不可或缺,但它们的主要作用在于确保潜状态(latent state)能够为上述升级过程提供可用的基础。
状态推断
状态推断旨在将高维度的观测数据压缩为紧凑的潜表征 z_t,该表征不仅保留关键的决策信息,还整合时间上下文信息,从而确保在部分可观测的环境中,z_t 能够近似地呈现出马尔可夫式的信念状态(Lesort et al., 2018)。
正向动力学:核心 L1 算子
这些方法直接构建状态转移函数,构成 L1 的核心。动力学网络的精度对于生成有价值的单步预测至关重要;此外,该网络必须具备足够的表达能力,以便在多个时间步上进行累积——这是一项关键要求,且在 L2 层面显得尤为严格(Moerland et al., 2023)。
观测解码
解码器具有三项关键功能:它提供训练信号以确保 z_t 保留足够的信息;充当诊断接口,用于检验模型所学到的表征;并作为渲染引擎,用于在“做梦”阶段生成设想的观测(Ha & Schmidhuber, 2018; Hafner, 2020)。
逆动力学
逆动力学算子用于推断两个连续潜状态之间所采取的动作。在现代世界模型系统中,该算子扮演着多重角色。通过训练编码器来预测连续状态之间的动作,逆模型能够滤除那些与智体决策无关的外生视觉噪声(例如,移动的云朵、闪烁的背景)。在更广泛的语境下,逆动力学充当一种辅助训练信号,促使潜状态 z_t 保留与动作相关的特征;作为一种学习对决策有用的表征的机制,它与正向动力学及状态重构功能相辅相成(Lesort,2018)。
逆动力学的一个尤为重要的应用是针对大规模模仿学习的追溯式动作标注。此外,逆动力学也是构建以目标为条件的策略架构的基石。给定当前状态 z_t-1 和预期的目标状态 z_g,逆模型能够预测出促使状态向目标演进所需的动作;这为分层规划提供一个天然的接口——即由高层规划器负责选定子目标,再由底层的逆模型负责执行这些子目标(Ghosh,2021)。Agrawal(2016)通过实验证明,机器人可以通过“拨弄”物体并训练逆模型来预测基于观察到的状态变化所对应的拨弄参数,从而习得直观的物理学知识;这一案例生动地阐释逆动力学如何通过交互作用,帮助智体建立对物理世界的具身理解。
许多高效的世界模型完全摒弃逆动力学,而另一些模型则仅将其用作一种轻度的正则化手段。一个既具现实意义却又鲜被探讨的问题是“动作标签的质量”:当动作并非直接记录而是通过回溯推断得出时,逆模型所产生的误差往往恰好累积在分布的边缘地带——而这正是世界模型最迫切需要可靠监督信号的区域。此外,逆算子预设在任意一对状态之间存在唯一(或近乎唯一)的对应动作;然而,在随机性环境中,或者当多种不同的动作均能导致相同的后果时,这一预设便不再成立,从而限制逆算子在此类情境下的可靠性。
3 讨论
尽管本文主要关注以时间 t 为索引的时间局部预测,但这种“局部算子”的视角同样适用于非时间轴维度,例如扩散步数、精炼步数或层级更新阶段。将这些情况视为 L1 级别的边缘案例,而非一种独立的能力层级,因为其核心特性依然是局部状态转移预测,而非可用于决策的多步演化推演。
仅凭 L1 级别,尚不足以确保系统在长时程上表现出连贯一致的行为。诸如单步误差累积放大(Janner et al., 2019; Chua et al., 2018)、跨众多步数保持一致性,以及缺乏干预或反事实推理手段等挑战,均突显对 L2 级别的迫切需求。同理,无论是 L1 还是 L2,其本质上均不具备基于新证据自适应调整模型的能力;而这一能力正是 L3 级别的核心关注点。L1 与 L2 之间的根本区别在于:系统在构建与评估时,究竟是着眼于多步演化推演的准确性及约束满足度,还是仅仅局限于单步预测的精度(Hafner et al., 2025; Ding et al., 2025a; Moerland et al., 2023)。L1 级别的局限性并非在于单步预测本身不重要,而在于单纯的局部预测质量,并不能保证系统在经过多步组合演化后,依然能产生可供决策利用的有效行为。因此,实际应用中的关键问题在于:在何种情境下,仅依赖短时程局部算子将无法再满足规划器的需求。
如果说 L1 回答的是“给定当前状态和动作,下一个局部状态是什么?”,那么 L2 回答的则是一个与决策息息相关的问题:“如果智体在任务约束下执行某一系列候选动作,未来可能会展开怎样的轨迹?”这种层级上的提升将单步操作符转化为一种模拟器,智体可以在实际采取行动之前向其进行查询;从而在无需与真实环境进行交互的情况下,为智体提供对未来情景的预演(即“想象”)。基于模型的规划方法正是充分利用这一能力:通过在已学习的模型内部对候选规划进行推演,智体能够对各种结果进行比较,并从中选定最具前景的行动方案(Sutton, 1991; Hafner et al., 2025; Schrittwieser et al., 2020)。由此可得出一个重要的推论:任何被用于为智体生成合成训练数据的系统,实际上都隐性地充当某种“世界模型”的角色;因为该系统必须能够生成足够逼真的状态转移序列,从而为智体策略的改进提供有效支撑(Gu et al., 2025b; Fang et al., 2025)。值得注意的是,面向决策的仿真(decision-usable simulation)所关注的核心在于动力学过程的“合理性”(plausibility);这一点使其与 L1 层面——即状态变化可能呈现任意性的层面——之间形成了鲜明的区分。举例而言,诸如杯子径直穿透坚固的桌面、汽车在越过车道边界后却未引发任何后果、抑或是某种社会性承诺无声无息地凭空消散等情景,均代表该系统未能有效维系目标领域内所应遵循的各项基本不变性原理(invariants)。
L2 与 L1 的区别,不仅仅在于单步预测的质量,更在于在既定法则约束下连贯的多步演进过程。因此,L2 将逐边的 L1 算子串联起来,构建出一条完整的轨迹:z_0 -> z_1 -> ··· -> z_H(如上图 7 所示的上部区块)。
1 提升(Elevation)的要求
将 L1 层的局部算子进行多步复合操作,并不能自动生成一个可用于决策的模拟器:累积误差、对动作变化不敏感的推演结果,以及对领域不变性的违背,都可能导致所得的轨迹信息对规划工作产生误导。这一现象呼应了经典的“框架(frame)问题”(McCarthy & Hayes, 1969; Shanahan, 1997);具体而言,仅凭局部的状态转移规则,无法明确指定在执行动作时哪些属性应当保持不变——尽管在此语境下,关注的重点是操作层面的问题,而非纯粹的逻辑问题。规划器与 L2 世界模型之间的交互接口体现为一种“查询”机制:给定初始状态 z_0 下的一系列动作序列 a_1:H(且需满足约束条件 c),世界模型将返回相应的推演轨迹;规划器利用这些轨迹来对比不同的候选方案,并从中选出能够最大化特定目标函数的那一个。将“闭环使用”(即涉及与环境交互的规划、执行或控制过程)视为一种正交的部署属性:L1 与 L2 之间的层级界限,取决于世界模型查询的深度与可靠性,而非取决于系统是否运行于反馈回路之中。确立三项边界条件,以此作为系统从 L1 层级向 L2 层级实现“提升”的判定依据:
- 长时程一致性(Long-horizon coherence):推演轨迹在跨越多个时间步后依然保持可用性,不会因累积误差的放大而迅速失效。
- 干预敏感性(Intervention sensitivity):能够对反事实情境下的变量进行编辑——例如修改动作序列、初始前提或可控输入参数——且此类编辑能够引发稳定且具有明确方向性的轨迹变化。
- 约束一致性(Constraint consistency):所生成的未来情景必须严格遵循目标领域(无论是物理、数字、社会还是科学领域)所固有的运行法则与约束条件。
上述三项条件绝非仅仅停留在概念辨析层面;它们共同构成一套切实可行的检验标准,用于判定一个系统是否真正具备被称为“L2 模拟器”的资格。在对候选系统进行评估时,不应仅局限于其单步预测的准确性;更应考察:随着推演时域的延伸,其预测结果是否依然具备决策参考价值?反事实干预操作能否引发具有逻辑连贯性且对策略制定具有指导意义的轨迹分岔?以及,所生成的轨迹是否始终能够满足特定领域所要求的有效性约束?如果一个模型虽然能够准确预测下一时刻的状态,但在进行多步复合推演时便彻底失效,或者对动作序列的修改视而不见,抑或是违背了领域内部的既定规则,那么将其归类为具备“强局部预测能力”的 L1 模型,显然要比将其视为完整的 L2 模拟器更为恰当。
每一项要求都对应着一种诊断信号和一种缓解策略。长时序保真度(Long-horizon fidelity)通过在特定时间步长 H 处的成功率来进行诊断。针对这一问题的首要缓解手段是任务切分与频繁重规划。动作可控性(Action controllability)通过跨展开过程(rollouts)的动作不敏感性来诊断(即改变动作 a_t 却未引起有意义的轨迹变化);对此,缓解策略要求进行显式的动作一致性评估。约束一致性(Constraint consistency)则通过约束违反率来衡量。在此类情况下,缓解策略包括引入硬约束层和验证门。第四项属性——标定(Calibration)——要求在发生分布漂移时,模型的置信度应与实际准确率保持一致;在此类情况下,过度自信的错误预测即视为失效信号,而分布漂移检测则是主要的补救手段。
残余的“框架-问题”表现。现代神经世界模型通过从数据中隐学习“何者保持不变”与“何者发生变化”(Goodfellow et al., 2016; Hafner et al., 2025),从而规避经典“框架问题(frame problem)”所带来的表征负担;这使得无需显式的“框架公理”即可实现可扩展的基于模型强化学习(Hafner et al., 2020; Schrittwieser et al., 2020; Moerland et al., 2023)以及视频预测任务(Babaeizadeh et al., 2018; Brooks et al., 2024)。然而,这一问题在推演执行阶段(rollout time)却会重新浮现:受限于上下文窗口大小及“幻觉”现象,模型往往会丢失对相关历史信息的追踪,从而破坏长时序的一致性;与此同时,那些在训练数据中因稀有而未得到充分表征的先决条件,也会削弱约束的一致性(Ding et al., 2025a; Shanahan, 1997)。正是这些失效模式,催生综述的各类技术。
2 应用
L2 系统划分为四种主导定律范畴。
物理世界的规律
在物理领域,L2 模型必须遵循几何学、运动学及守恒定律。其主导约束包括接触、可达性、稳定性和能量守恒;若违反其中任何一项,都将误导规划器提出在实际执行中会遭遇灾难性失败的动作。
物理仿真。刚体控制仿真器。经典物理仿真器依然是具身世界建模中“可执行状态转移有效性”的基础层。MuJoCo 提供关节式刚体动力学及富接触控制能力,而 dm_control 则将这些能力封装成一套标准化的连续控制套件(Todorov et al., 2012; Tassa et al., 2020)。Brax 将可微分刚体仿真推向加速器级的高吞吐量水平(Freeman et al., 2021),而 Isaac Gym 和 Isaac Lab 则侧重于大规模 GPU 并行机器人仿真(Makoviychuk et al., 2021; Mittal et al., 2025)。
可扩展的通用仿真平台。Genesis 将自身定位为一种生成式且通用的物理引擎(Genesis Authors, 2024),这反映了当前的一种更广泛趋势:即开发高吞吐量的仿真器,使其能够同时支持控制任务与大规模合成数据生成。
以交互为中心的具身仿真器。在图形学与机器人学的交汇点上,SAPIEN 提供具备部件感知能力的、以交互为中心的仿真环境;而 ManiSkill3 则针对可泛化的具身 AI 任务,实现 GPU 并行渲染的大规模扩展(Xiang et al., 2020; Tao et al., 2024)。这些系统并非基于学习的仿真器;它们属于显式的“规律执行器”,其核心价值在于精准的接触处理、关节约束的模拟以及可复现的仿真演进过程。
视频生成模型。外观优先的长时程视频生成。通往物理世界仿真的一条可扩展路径是“视频接口”模式:即给定当前的观测数据及可选的动作指令,模型将输出其所构想的未来帧序列。这一研究路线始于“外观优先”的推出阶段,其中 Sora、Lumiere 和 VideoPoet 等系统展示了在较长的时间跨度内保持连贯的视觉动态的能力(Brooks et al., 2024; Bar-Tal et al., 2024; Kondratyuk et al., 2024);与此同时,超越像素级真实感的、具备几何感知能力的结构特征也日益显现(Li et al., 2024d)。FramePack (Zhang et al., 2025c) 和 Self-Forcing (Huang et al., 2025c) 通过对帧上下文进行打包处理,有效缓解了长时序生成中的漂移问题。
受动作制约的交互式视频世界。第二个研究方向正从被动的视频续写(continuation)转向具备“干预感知”能力的生成模式。Genie (Bruce et al., 2024) 能够从海量的无标注互联网视频中学习并构建潜在的动作空间;而 GAIA-1 (Hu et al., 2023) 则通过接收明确的控制信号来指导未来的视频生成,从而支持反事实情景的评估。近期涌现的各类系统进一步推动这一研究方向的发展,使其向着实时、长时序及流式交互的模式演进:Oasis (Decart et2024) 在统一的 Transformer 架构世界中探索开放式的交互式生成;WorldPlay (Sun et al., 2025b) 强调在实时交互式世界建模过程中保持长期的几何一致性;Matrix-Game 3.0 (Wang et al., 2026b) 借助明确的长时序记忆机制,将交互式生成能力拓展至流式处理场景;Yume-1.5 (Mao et al., 2025) 专注于研究基于文本控制的交互式世界生成技术;而 LongLive (Yang et al., 2025b) 则致力于实现实时的、交互式的长视频生成。综合来看,上述系统标志着该领域正经历一场范式转变:即从被动的视频预测阶段,向着可控、具备干预感知能力且在时间维度上保持一致性的“视频世界”构建阶段迈进。
面向决策的视频世界模型。在基于模型的强化学习(Model-based RL)领域中,SimPLe (Kaiser et al., 2020) 和 DIAMOND (Alonso et al., 2024) 明确揭示了视频世界模型在决策制定过程中所扮演的核心理论角色。在机器人学领域,DreamZero (Ye et al., 2026b) 和 DreamDojo (Gao et al., 2026) 演示如何利用视频世界模型实现零样本与通用策略学习;而 FutureVLA (Xu et al., 2026a) 则将视觉-运动预测直接与“视觉-语言-动作”策略相结合,从而实现了感知与控制的统一。
评估与局限性。然而,在所采用的 L2 框架下,视觉上的逼真度并不等同于决策层面的可用性。对干预操作的敏感性依然脆弱;若仅凭感知质量进行判断,长时序的一致性往往容易被过分夸大(Guo et al., 2025);此外,仅凭渲染帧也难以验证约束条件的一致性。诸如 FVD(Unterthiner et al., 2018)之类的标准指标主要用于捕捉分布层面的真实感;VBench 系列套件(Huang et al., 2024d; 2025e)则能更有效地对可控性进行细粒度拆解;VBench-2.0(Zheng et al., 2025a)将评估范围拓展至物理一致性与常识推理层面;而 VChain(Huang et al., 2025d)则引入了“视觉思维链”(visual chain-of-thought)机制,以增强因果逻辑的一致性。尽管视频接口是目前最具扩展潜力的“观测层”切入点,但对于规划器至关重要的结构信息却往往隐匿于像素数据之中。
机器人学与“仿真-到-现实”迁移。将世界模型迁移至真实机器人。DayDreamer (Wu et al., 2023a) 证明,Dreamer 系列的世界模型能够从仿真环境成功迁移至物理机器人,并能有效应对传感器噪声、接触动力学及执行延迟等挑战。DreamZero (Ye et al., 2026b) 借助既能预测下一状态又能预测动作的“世界动作模型”,实现零样本策略学习;而 FutureVLA (Xu et al., 2026a) 则将视觉-运动预测能力嵌入至“视觉-语言-动作”模型之中,从而提升了动作接地的准确性。
基于物理原理构建“仿真-到-现实”的鲁棒性桥梁。PIN-WM (Li et al., 2025d) 将可微分物理学与学习的视觉世界建模技术相融合,并通过引入“物理-觉察随机化”机制,构建出机器人的“数字孪生体”(Digital Cousins)。
表征需求。在上述各类系统中,核心问题并非在于能否构建出更为丰富的表征,而在于:何种表征才是“最简”且“必要”的?即,在保证表征尽可能简洁的同时,它必须依然能够保留对规划器至关重要的结构信息——例如物体的持久性、自由空间、接触发生的时刻、支撑关系,以及在有效的时间跨度内受动作条件制约的状态变化等。
数字世界的法则
数字世界的法则支配着由形式化规约定义的系统中的状态迁移过程——从有限自动机(用户界面状态机)和上下文无关文法(结构化数据格式),到图灵完备(Turing-complete )的程序(通用软件)。与物理世界或社会世界的法则不同,这些约束条件是明确指定且可进行机械化验证的:一次状态迁移要么符合程序的语义,要么就不符合。由于软件的状态迁移过程近似于确定性状态机,且故障均可被记录(表现为错误代码、弹窗提示、权限拒绝或超时等形式),因此,对于“代码世界”中的模拟器而言,其核心挑战在于进行结构化的状态预测(涉及 DOM 树、程序内部状态及游戏状态等),而非追求视觉上的逼真度。
代码智体。一种新兴的范式将世界模型表示为可执行程序,而非传统的神经网络模型。CodeWM(Dainese,2024)利用蒙特卡洛树搜索(Monte Carlo Tree Search)来引导大语言模型(LLM)生成 Python 程序;这些程序充当着明确且可解释的世界模型,被应用于跨越 18 种不同环境的强化学习任务中。WorldCoder(Tang,2024)则采取一种互补的策略:它让一个基于 LLM 的智体通过与环境进行交互,以增量的方式逐步构建 Python 世界模型,从而实现样本高效的迁移学习。WKM(Qiao,2024)同时提供全局任务知识与动态状态知识,以此来指导 LLM 智体的规划决策;而 CWM(Copet,2025)——一个专为代码世界模型研究而训练的、拥有 320 亿参数且权重开源的 LLM——在 SWE-bench Verified 基准测试中取得 65.8% 的成绩。另一种在概念上截然不同的变体则将这一理念推向极致:它不再利用 LLM 去“生成”一个代码世界模型,而是直接将世界模型本身构建为一个正在运行的软件系统。Web World Models(Feng,2025a)将世界状态实现为常规的 Web 代码(包括 TypeScript 模块、HTTP 处理器及数据库模式等);它将逻辑一致性的维护工作委托给 Web 技术栈的确定性执行机制,而 LLM 则负责生成上下文信息及制定高层决策。这些基于代码的方法能够构建出具有可解释性、可组合性及可验证性的世界模型,而这些特性往往是基于神经网络动态特性的模型所难以企及、只能进行近似模拟的。
Web 智体。Web 智体通常需要在网站上进行浏览操作;因此,对网站内部的状态迁移过程进行建模与仿真,对于构建高效且实用的 Web 世界模型而言具有至关重要的意义。 WebDreamer (Gu et al., 2025b) 引入将大语言模型(LLM)用作互联网隐式世界模型的概念,但随后的研究表明,现成的通用 LLM 尚不足以胜任此任务:需要通过专注于状态转换抽象的专门训练来加以强化 (Chae et al., 2025)。越来越多的研究工作开始关注智体(Agent)与世界模型之间的协同演化。WebEvolver (Fang et al., 2025) 将两者紧密耦合在一个相互促进的迭代循环中;而 DreamGym (Chen et al., 2025f) 则利用“思维链”(Chain-of-Thought)推理构建经验模型,在 WebArena 基准测试中实现超过 30% 的性能提升。在更大规模的研究中,WebSynthesis (Gao et al., 2025) 将世界模型与基于蒙特卡洛树搜索(MCTS)的规划算法相结合,并完全依赖合成数据进行训练;WebWorld (Xiao et al., 2026) 则利用超过一百万条交互轨迹训练一个开放式网络模拟器,能够支持长达 30 步以上的模拟过程。AUI (Lin et al., 2025a) 采取一种截然不同的方法:它引入一个“编码器”(Coder),通过在一个迭代协作循环中利用来自“计算机使用智体”(Computer-Use Agent)的反馈,对网站进行优化。此外,还有一些正交的设计选择,包括:仅依据工具规范来生成交互轨迹(Simia; Li et al. 2025f);增加一个元认知层,用于在每一步决策时判断是否需要查阅世界模型(WAC; Shen et al. 2026);以及利用智体自身收集的数据来应对“分布外”(Out-of-Distribution)的行为场景。
GUI 智体。GUI 智体(Qin et al., 2025; Lin et al., 2025b; Xu et al., 2024b)通常在真实环境中执行操作。然而,在某些操作可能具有危险性或可能导致非预期后果的场景中,若能预先对这些操作进行评估,将极具价值。GUI 世界模型能够对这些操作进行模拟与评估,从而提供更为可靠的决策依据。因此,MobileDreamer (Cao et al., 2026) 将 GUI 图像转化为与任务相关的草图,以实现结构化的状态预测;而 MobileWorldBench (Li et al., 2025c) 则通过包含 140 万组(状态、动作、未来状态)三元组的数据集,提供系统的评估基准。作为显式 GUI 世界模型的补充,UI-AGILE 研究表明,高效的强化学习以及精准的推理时接地(grounding)能力,对于确保下游 GUI 智体(agent)具备强大的性能同样至关重要 (Lian et al., 2025)。其中一个核心的设计问题在于输出表示形式:ViMo (Luo et al., 2025) 利用符号化的文本表示来生成作为图像形式的未来观测结果;而 gWorld (Koh et al., 2026) 则将可渲染的 Web 代码作为预测的下一状态进行生成,这一做法表明,生成用于渲染 GUI 的代码,可能比直接生成像素图像更能忠实地还原界面状态。在操作系统(OS)层面,NeuralOS (Rivard et al., 2025) 通过根据用户输入预测屏幕帧序列来模拟桌面 GUI 环境;而 CUWM (Guan et al., 2026) 则专注于桌面软件场景,旨在解决在跨越长周期工作流的过程中,必须妥善保存持久化文档状态这一关键问题。Code2World (Zheng et al., 2026) 进一步拓展了这一研究方向,将代码视为一个可渲染的世界;在此设定下,生成的程序在执行时能够直接产生视觉状态(例如 HTML)。这一机制使得将环境动态建模为可执行代码的生成成为可能,从而在图形用户界面(GUI)等交互式领域中,紧密耦合感知、动作与状态转换。
社会世界的法则
社会世界模型将 L2 范式拓展至人类互动领域,在此领域中,主导世界的法则不再是物理定律,而是信念、欲望、意图、规范及制度。社会世界呈现出三个显著的特性:不透明性/opacity(智体无法直接观测彼此的心理状态)、反身性/reflexivity(关于社会状态的信念会形成反馈回路),以及规范性/normativity(状态转换在一定程度上受共享规范的制约)。正是由于这些特性,社会世界中的状态转换函数部分地由集体共识而非自然法则所构建 (Zheng et al., 2025c)。一个可用的社会模拟器应当将表层的语言表达与底层的社会状态区分开来:对话内容可以千变万化,但核心状态(包括目标、信念、关系及规范)必须保持一致,并产生具有可解释性的状态转换——这一原则已在“理性言语行为”(Rational Speech Acts)框架中得到形式化的阐述 (Goodman & Frank, 2016; Degen, 2023)。具体而言,一个社会兼容性项可以编码承诺的一致性:如果智体 i 在时刻 t 承诺执行动作 b,那么当 i 在缺乏解释、重新协商或制裁的情况下违背该承诺时,后续状态将被赋予较低的兼容性评分。类似的项也可用于评估智体在整个交互轨迹中的规范遵守度、角色一致性或信念状态的连贯性。
作为社会状态的“心智理论”(Theory of Mind, ToM)。其计算基础由贝叶斯心智理论(BToM)奠定,该理论将心理状态推断形式化为针对理性智体的概率逆向规划问题(Baker et al., 2011)。神经学方法始于 ToMnet(Rabinowitz et al., 2018),该模型通过角色网络、心理状态网络和预测网络的协同作用,共同推断智体的特质与信念;而诸如 LaBToM(Ying et al., 2025)等近期工作,则将贝叶斯逆向规划与形式化的认知逻辑语言相结合。然而,当前的各类模型在心理状态推理方面仍显薄弱:FANToM(Kim et al., 2023)揭示所有“最先进”(SoTA)的大语言模型(LLMs)中普遍存在“幻觉心智理论”(illusory ToM)现象;而 ExploreToM(Sclar et al., 2024)的测试结果显示,即使是 GPT-4o(Chen et al., 2025c)这样的顶级模型,其准确率也低至 9%。另一个与之相辅相成的挑战是“双重结构(dual-structure)问题”:一个社会化智体必须在与他人进行长期交互的过程中,既能对其他智体的心理状态进行建模(即心智理论),又能同时维持自身持续稳定的内部状态——特别是其自身的目标、人格设定、记忆及知识体系。针对语言智体的认知架构(CoALA)(Sumers et al., 2024)将这种双重结构形式化为相互独立的“记忆空间”与“动作空间”,并强调二者之间必须保持内在的一致性;为理解当前 LLM 智体在何种程度上、以及通过何种机制实现(或未能实现)稳定的自我表征,其架提供一个具有原则性指导意义的理论框架。
策略性交互。CICERO(Bakhtin et al., 2022)将大语言模型与 piKL 规划算法相结合,应用于《外交》(Diplomacy)游戏场景中;该模型在对二阶信念进行建模的同时,对游戏动作与对话内容进行联合优化,最终取得超过人类平均得分两倍的优异成绩。Deal or No Deal(Lewis et al., 2017)开创性地引入“对话展开”(dialogue rollouts)技术,用于对谈判过程中的动态变化进行前向模拟与预测。诸如“狼人杀”(Werewolf)和“阿瓦隆”(Avalon)之类的游戏,则为研究欺骗、信任以及信念操纵等社会交互现象提供高度集中的理想测试平台(Xu,2023;Light,2023),揭示出欺骗者往往通过利用认知局限性而屡屡得逞。
沙盒模拟。生成式智体(Generative Agents)展示涌现的社会动态:一项包含25个智体的模拟实验(Park,2023)采用基于记忆的状态追踪与周期性反思机制;而 Sotopia(Zhou,2024c)则在七个维度上对社会模拟的评估进行规范化。模拟规模已实现大幅跃升:Project Sid(AL,2024)部署1000个智体,并展示涌现的专业化分工与治理机制;OASIS(Yang,2024d)更是将规模扩展至一百万个智体,成功复现信息传播与群体极化现象。在个体层面,Argyle(2023)展示“硅采样”(silicon sampling)技术,该技术通过特定的人口统计学画像对大语言模型(LLMs)进行条件约束,从而模拟目标亚群体(sub-population)的问卷调查回答;其结果与《美国国家选举研究》(American National Election Studies)的数据高度吻合,为构建个体层面的社会世界模型开辟新途径。生成式社会选择(Generative Social Choice,Fish,2024)将这一理念进一步拓展至民主决策聚合领域,利用大语言模型(LLM)生成来自多元化合成参与者的代表性陈述,从而促成群体审议过程。
挑战与设计原则。社会模拟技术目前仍处于初级阶段:大语言模型在处理超越“二阶信念推理”的复杂逻辑时,其性能会急剧下降(Wu,2023b);智体常受困于“角色漂移(role drift)”与“目标遗忘(goal forgetting)”等问题(Park,2023;Zhou,2024c);此外,针对正式承诺的追踪机制(Telang,2021)至今仍未被整合进任何大语言模型的架构之中。
一种实用的设计模式将紧凑的社会状态表示(包括承诺、约束和关系)、对话生成器以及状态转换更新器分离开来;其中,状态转换更新器负责强制维护一致性,并确保状态转换过程可被记录和重放。灵活的角色生成能力对于为社会模拟器填充多样化且可控的智能体至关重要;PersonaGym(Samuel,2025)提供了一套基准,用于评估大语言模型(LLMs)在执行复杂社会任务时,能否忠实地演绎指定的角色设定。该基准揭示在面临对抗性探查时,模型在维持角色一致性方面存在的系统性失效问题。针对个体层面的个性化需求,LaMP(Salemi,2024)引入了一套包含七项任务的基准,要求 LLMs 生成与特定用户历史记录相一致的输出;研究表明,采用检索增强型方法能够显著缩小这一任务表现上的差距。
科学世界的法则
在“AI for Science”(科学智能)领域中,从 L1 阶段向 L2 阶段的演进,标志着研究重心从对局部状态或结构的建模,转向对跨多个时间步长的动态过程进行模拟。这些动态过程主要沿着两个轴向展开。第一条轴线关乎系统的时序演化:模型预测在既定条件或干预措施下,自然系统将如何随时间推移而演变。第二条轴线则关乎科学研究活动本身:模型模拟一系列假设、实验及结果的序列,以此为科学推理与决策行动提供支持。这两类形式共同定义了科学世界模型中相应的模拟类型:即针对系统动态过程的“正向模拟”,以及基于对候选实验进行代理评估的“决策模拟”。
正向模拟。世界模型通过将计算成本高昂的数值求解器替换为经学习获得的“状态转换算子”,从而对科学系统的演化过程进行近似模拟。GNS(Sanchez-Gonzalez,2020)的研究表明,基于粒子图进行信息传递的方法,能够以具有泛化能力的动态规律,对流体、刚体及可变形材料的物理过程进行模拟。傅里叶神经算子(Fourier Neural Operator,Li,2021b)通过谱卷积技术,实现与分辨率无关的算子学习;该方法在计算速度上较传统数值求解器提升 1000 倍,并为后续的天气预报及流体动力学智体模型奠定技术基础。在行星尺度的应用中,Pangu-Weather(Bi,2023)和 GraphCast(Lam,2023)两款模型在 90% 的验证指标上,均展现出优于欧洲中期天气预报中心(ECMWF)业务预报系统的性能。 GenCast (Price et al., 2024) 借助扩散架构将上述方法扩展至概率预测领域,并在 97.2% 的预测目标上超越传统的集成系统。NeuralGCM (Kochkov et al., 2024) 将学习的参数化方案整合进一个可微分的大气环流模型中,不仅成功复现热带气旋等涌现现象,还充分展示将机理结构与学习的组件相结合所带来的巨大价值。Aurora (Bodnar et al., 2025) 进一步将这一范式扩展至地球系统基础模型层面,在大幅降低计算成本的同时,在多项预测任务中均取得卓越的性能表现。在分子科学领域,由 Behler & Parrinello (2007) 开创的神经网络势函数方法,使得分子动力学模拟的速度较传统的密度泛函理论提升数个数量级,从而为后续所有基于机器学习(ML)的研究领域奠定坚实的基础。
决策模拟。通过在计算机(in-silico)模拟实验决策的循环过程,“世界模型”(World models)显著降低了科学发现的成本。此类系统的典型代表涵盖分子设计(ChemBO; Korovina et al. 2020)、结合基于种群的模型集成与元级搜索资源重分配机制的生物序列优化(P3BO; Angermueller et al. 2020),以及由用户自定义算法目标所引导的材料发现(BAX; Chitturi et al. 2024)等多个领域。在上述各类系统中,模型不仅能够模拟单一实验的结果,还能模拟整个实验选取的序列化过程;在优化过程中,模型会持续维护并更新其对各类候选方案的置信度,同时识别并修正其中存在的矛盾与不一致之处。然而,这些能力目前仍局限于特定的数据环境之中:模型尚无法主动设计并执行实验,从而获取能够挑战其现有假设的全新信息。因此,尽管此类系统能够纠正优化过程中产生的误差,却无法消解因知识不完备而引发的不确定性,进而导致在长期预测或优化过程中出现偏差累积的问题。L3 世界模型通过主动收集证据来对模型进行修正与迭代,从而成功克服上述局限。
跨域分析
跨机制(Cross-regime)系统。许多现实世界的部署场景无法简单地归入单一的“管辖法则”机制之下;相反,它们要求 L2 仿真器能够同时在多种约束类别之间维持一致且连贯的演进过程。当不同机制发生交互时,某一领域内的违规行为可能会引发连锁反应并波及另一领域:例如,一次在物理上不合常理的车辆机动操作,可能会导致对社会意图的预测变得毫无意义;又或者,一个软件缺陷可能会使原本设计严谨的实验方案彻底失效。因此,跨机制系统的设计与评估,必须立足于“联合约束满足”这一原则,而非仅仅对各个机制进行孤立的单独评估。
• 自动驾驶:物理层面(车辆动力学、接触力学)+ 社会层面(行人意图预测、交通规范遵守)(Hu et al., 2023; Wang et al., 2024h)。
• Minecraft 智体(Voyager):物理层面(3D 导航、战斗动力学)+ 数字层面(合成配方、物品栏管理、游戏状态逻辑)(Wang et al., 2024b)。
• 《外交》游戏(CICERO):社会层面(谈判、信任建模、联盟构建)+ 数字层面(游戏状态管理、规则执行)(Bakhtin et al., 2022)。
• 自主实验室(A-Lab):科学层面(实验设计、假设评估)+ 物理层面(样本操作、仪器设备约束)(Szymanski et al., 2023; Boiko et al., 2023)。
3 故障模式
在所有四个领域中,有五种反复出现的故障模式制约着 L2 系统:
- 累积误差(Compounding error)。每一步微小的偏差会随时间推移而被放大,导致预想的轨迹偏离现实,进入越来越不相关的分支。最有效的缓解措施并非仅仅让单步预测看起来更准确,而是缩短有效的规划窗口(将长任务分解为可验证的短片段,并利用实时反馈频繁进行重新规划)、采用多时间尺度结构(Shaj et al., 2023),以及将证据收集动作内嵌到策略之中。
- 状态混叠与漂移(State aliasing and drift)。在复杂环境中,截然不同的真实状态在外观上可能高度相似(例如两个不同的 UI 页面、布局略有差异的厨房,或社交语调中仅有一词之差)。当模型表征将这些状态混淆(坍缩)时,智体可能会采取不可逆转的错误行动。有效的应对实践包括在关键节点进行显式验证、增强记忆与检索能力,以及使用显式的故障归因标签(Xie et al., 2024; Yang et al., 2025a; Nasiriany et al., 2024)。
- 可控性失效(Controllability failure)。相比于能够对动作做出响应的粗略模型,一个虽然视觉细节丰富但对动作条件响应微弱的模型,在规划任务中的实用价值反而较低。当模型对动作不敏感时,比较“执行动作 A”与“执行动作 B”的优劣便变得毫无意义(Wu et al., 2024c; Liu et al., 2025; Brooks et al., 2024; Ball et al., 2025)。
- 可利用性与模拟器逃逸(Exploitability and simulator escape)。如果模拟器或评估框架存在漏洞,搜索/规划算法将系统性地利用这些漏洞。这种现象在软件环境和自动化评估场景中尤为普遍(Xie et al., 2024; Yang et al., 2025a; Zheng et al., 2025c)。
- 分布漂移下的标定失效(Calibration failure under distribution shift)。环境变化(如 UI 版本、布局、口音、物体属性的变化)往往会引发智体过度自信的错误预测。在实践中,那种“自信却错误”的预测结果,应当被视为推动系统演进的强烈信号(Xie et1 al., 2024; Yang et al., 2025a; Nasiriany et al., 2024)。这些故障不仅仅是模型的局限性所致;它们是由表征、推演视界、控制流程以及证据质量之间相互作用所产生的系统级病态。由此得出的关键启示是:仅仅提升平均情况下的预测准确率是远远不够的;除非系统能够做到:(i) 依据证据定位故障,以及 (ii) 在面临环境漂移和利用压力时调整其行为。
这种“约束优先”的视角,也为选择哪些数据需要记录(log)以及哪些功能需要进行回归测试提供有益的指引。如果核心约束遭到破坏(例如,执行了本不可能成功的动作,或者某种结构化的反馈通道突然消失),智体便会从中习得错误的经验。反之,若约束条件明确且稳定,即便只是简单的智体,也能通过“Evolver”风格的资产蒸馏技术实现可靠的性能提升(Xie et al., 2024; Yang et al., 2025a; Nasiriany et al., 2024; Zheng et al., 2025c; Ghugare et al., 2025)。
如图 8 所示四种主导法则范式的诊断图。图中的坐标轴仅具示意性质,而非度量尺度:横轴反映转换规则在形式上可具体界定及在机制上可自动验证的程度;纵轴则反映相关的状态与约束条件的可直接观测程度。本图旨在进行比较而非单纯分类:它旨在突显,为何即便同属 L2 仿真(L2 simulation)的范畴,不同的范式依然要求采取各异的推广验证形式。现实系统往往呈现出混合范式的特征,其定位可能介于各区域之间,而非局限于单一的方框之内。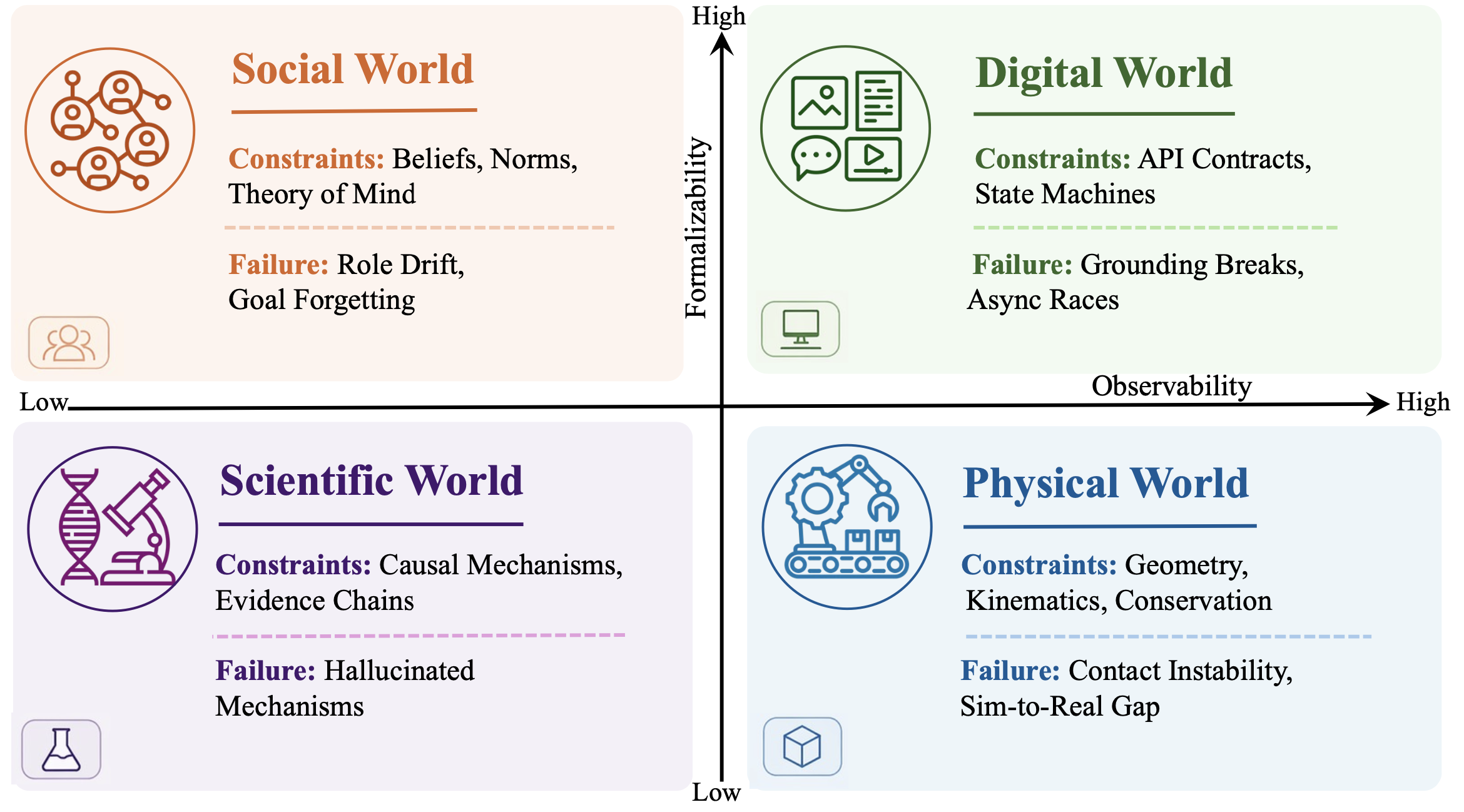
。。。。。。待续。。。。。。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)