
论文精读·Does Context Matter? CONTEXTUALJUDGEBENCH for Evaluating LLM-based Judges in Contextual Settin
摘要: 研究提出ContextualJudgeBench基准,系统评估大模型在“有上下文输入”任务中的评审能力。该基准包含2000对覆盖拒答性、忠实性等4类标准的样本,通过人工标注与LLM扰动构建。研究发现,现有评审模型在上下文评估中表现有限(最优模型准确率仅55.3%),并存在位置偏差与推理缺陷。创新性提出分层评估框架(拒答→忠实性→完整性→简洁性),揭示了模型在复杂上下文任务中的评估挑战,为未
研究背景
当前的“LLM-as-judge”(让大模型作为评审者)范式,被广泛用于评估其他模型的输出,因为它便捷、廉价且快速。然而:
- 现有评测主要集中在非上下文任务(如指令跟随、一般问答);
- 而实际应用(如RAG 检索增强生成、长文档摘要)越来越多依赖外部上下文;
- 在这些情境下,模型输出的质量不仅取决于语言能力,还取决于是否忠实于提供的上下文(faithfulness)。
因此,如何客观评估模型在“有上下文输入”的任务中的表现,成为一个关键但未解决的问题。
研究动机
作者指出,“上下文评估”具有三大挑战:
- 上下文理解复杂:评审者需要先读懂冗长、领域特定的上下文;
- 评估标准不统一:例如一个回答可能更“完整”,但不一定更“忠实”;
- 缺乏评测基准:目前没有系统性基准可测试LLM在上下文评估场景下的判断质量。
为填补这一空白,研究者希望建立一个能系统衡量“评审模型”上下文理解与评估能力的基准。
研究方法
论文提出了一个新的评测基准:
→ ContextualJudgeBench
-
含有 2000 对真实世界灵感的响应对(response pairs);
-
覆盖 8 个评测子集(splits),对应四类评估标准:
- Refusal(拒答有效性):能否判断回答是否应拒答;
- Faithfulness(忠实性):输出是否与上下文一致;
- Completeness(完整性):是否覆盖所有关键信息;
- Conciseness(简洁性):是否避免冗余。
-
每个样本包含用户输入、上下文和两个模型回答,评审模型需选出更优答案。
-
数据构建采用双重策略:
- 利用人工标注数据;
- 通过**LLM自动扰动生成(perturbation)**不良答案来形成对比样本。
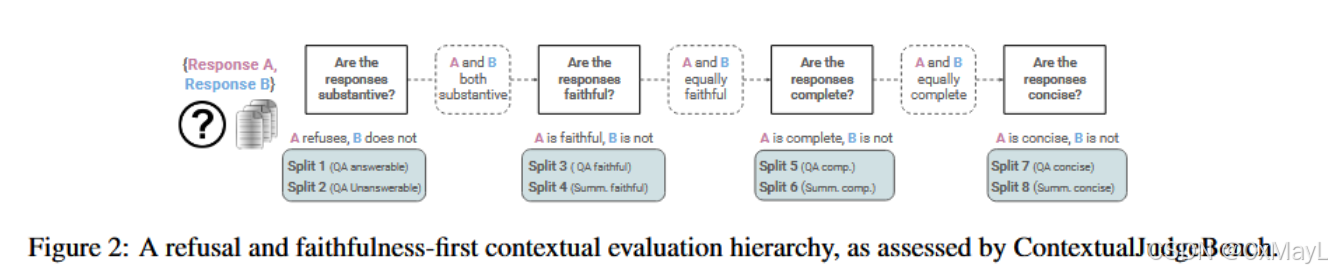
此外,论文提出了一个分层评估层次(conditional evaluation hierarchy):
- 拒答有效性 → 忠实性 → 完整性 → 简洁性
- 只有当前一层标准相等时,才进入下一层评估。这一体系确保评估过程符合人类逻辑与真实应用顺序。
主要创新点
-
首次系统研究LLM评审者在“有上下文”任务中的评估能力
以往评测多集中于指令类或单轮任务,本研究首次构建了可量化的上下文评估基准。 -
提出“条件分层评估层次”框架
明确从拒答、忠实性、完整性到简洁性的优先级顺序,提供了结构化的评估流程。 -
构建高质量基准数据集 ContextualJudgeBench
- 覆盖RAG问答与摘要两大真实任务;
- 融合人工标注与模型生成扰动;
- 上下文长度涵盖短至几百词到长达上万词。
-
系统评测多种评审模型与通用模型(共20个)
- 发现即使是最强的OpenAI o1模型,仅达 55.3% 一致准确率;
- 表明“上下文评估”仍是极具挑战性的未解问题。
-
揭示评审偏差与推理缺陷
- 许多评审模型给出“正确结果”,但理由错误;
- 模型存在对长答案偏好(length bias)和具体回答偏好(concreteness bias);
- 提高计算量或自一致推理并不能显著改善表现。
CONTEXTUAL JUDGE BENCH
- 作者采用了成对比较回答的思路,构建成对数据,而不是逐点评估。
- 简单来说就是构建4个SPLIT,每个SPLIT有两个分支,一般包括上下文任务:QA和Summarzation(摘要)。
- 第一个SPLIT只有QA,包括可以回答/不可以回答两种分支。
实验评估
作者指出,回答的先后顺序会影响模型的判断(即所谓“位置偏差 positional bias”,Wang et al., 2023)。
为消除这种干扰,他们采用一致性评估方案(consistency evaluation setup):
对每个样本评测两次:
Run 1:把正确答案设为 Response A;
Run 2:把正确答案设为 Response B。
每次都让评审模型判断“A 好”还是“B 好”。
这样就能检验:
模型是否稳定(两次给出同一判断);
模型是否真的选对(无论顺序怎样)。
非常好,这一节(论文第 4.1 节 Evaluation setup and baselines,约第 6 页)是整篇实验设计的“中枢”部分——作者在这里交代了他们如何评测评审模型(judge models)、采用哪些指标、测试哪些基线。下面我把这部分内容系统拆解,并结合上下文图表(表 1、表 2)详细讲清楚。
🧩 一、研究目的回顾
在前面 3 章中,作者构建了一个新的评测基准 ContextualJudgeBench:
共 2000 条样本对(A/B 回答),每个样本包含:
- 用户输入;
- 一段外部上下文(context);
- 两个回答(Response A、Response B),其中一个是“更优”(正例)。
这一节的目标就是说明:
他们是如何用不同评审模型(judges)来打分、并以何种指标衡量评审的正确性与一致性的。
⚙️ 二、评测设置(Evaluation setup)
双次评测(Run 1 和 Run 2)
作者指出,回答的先后顺序会影响模型的判断(即所谓“位置偏差 positional bias”,Wang et al., 2023)。
为消除这种干扰,他们采用一致性评估方案(consistency evaluation setup):
-
对每个样本评测两次:
- Run 1:把正确答案设为 Response A;
- Run 2:把正确答案设为 Response B。
-
每次都让评审模型判断“A 好”还是“B 好”。
这样就能检验:
- 模型是否稳定(两次给出同一判断);
- 模型是否真的选对(无论顺序怎样)。
五类指标(Metrics)
根据双次评测结果,作者定义了五个评价指标:
| 指标名称 | 含义 | 判定规则 |
|---|---|---|
| Consistent Accuracy(核心指标) | 模型两次都选对同一个正确答案。 | 两次都选对 = 1;否则 = 0。 随机猜的基线 = 25%。 |
| Run 1 Accuracy / Run 2 Accuracy | 单次测试正确率,不考虑一致性。 | Run 1 或 Run 2 单次命中正确答案。 |
| Optimistic Accuracy | “乐观上界”:两次只要有一次选对即可。 | 反映模型潜在最佳表现。 |
| Consistency | 模型两次判断结果是否一致(不论对错)。 | 仅测稳定性,不计正确与否。 |
📘 作者强调:“Consistent Accuracy”是主报告指标,因为它既要求选对又要求稳定,是最严格也最能反映评审可靠性的标准【第 6 页】。
控制顺序偏差(Positional bias)
为了系统分析偏差,他们规定:
- 在 Run 1 中,Response A 总是正例;
- 在 Run 2 中,Response B 总是正例;
- 之后还专门在附录 D.2 分析了这种偏差对性能的影响(例如,有的模型偏爱第一个回答)。
评测对象(Evaluation Models)
作者在表 2 中列出了共 20 个模型,分为两大类:
(一)LLM-as-Judge 模型 (11 个)
这些模型是专门训练成“评审员”的 LLMs,即它们本身经过微调(fine-tuning)以生成评判与解释。
| 模型 | 参数规模 | 特点 | 说明 |
|---|---|---|---|
| GLIDER (Deshpande et al., 2024) | 3.8B | 轻量型评估模型,可输出解释 | Context len 128K |
| Prometheus-2 (Kim et al., 2024) | 7B / 8×7B | 基于 Mistral,使用 GPT-4 蒸馏数据训练 | 生成解释 ✓ |
| OffsetBias (Park et al., 2024) | 8B | 关注偏差校正,不生成解释 | Context len 8K |
| Atla-Selene (Alexandru et al., 2025) | 8B | 通用评估模型,能解释 | Context len 128K |
| Skywork-Critic (Shiwen et al., 2024) | 8B / 70B | 对评审任务做 SFT 微调 | – |
| SFRJudge (Wang et al., 2024b) | 8B / 12B / 70B | 使用 Direct Preference Optimization 训练,能解释 | Context len 128K |
| ST-Eval (Wang et al., 2024c) | 70B | “Self-taught Evaluator”,可解释 | Context len 128K |
这些是主角类模型,作者主要想看看它们在上下文任务中的“判断力”如何。
(二)通用推理模型 / API 模型 (9 个)
这些并非专为评审训练,但具有强推理能力。作者把它们当作“Prompted judge”来比较。
| 模型 | 参数规模 / 来源 | 特点 |
|---|---|---|
| Llama-3.1 (8B & 70B)、Llama-3.3-70B | Meta 系列 | 通用 Instruct 模型 |
| GPT-4o / 4o-mini (Hurst et al., 2024) | OpenAI API | 多模态 GPT 系列 |
| GPT-o1 / o3-mini (Jaech et al., 2024) | OpenAI “reasoning models” | 推理优化版本 |
| DeepSeek-R1 / R1-Distill (Guo et al., 2025) | 中国研究团队 | 基于 RL 优化的推理模型 |
辅助基线(非生成型评估器)-不是LLM
为对照 generative judge 的表现,作者还加入两种“非生成式评估方法”:
-
RAGAS (Es et al., 2023)
- 是一个 pointwise (逐句) RAG 评估器,结合 embedding 与 prompted LLM。
- 能评测拒答、忠实、完整等维度。
-
MiniCheck (Tang et al., 2024)
- 是专门训练的幻觉检测器(hallucination detector)。
- 主要用于忠实性/拒答场景。
这些模型不生成解释,输出数值分数。作者把它们转成pairwise 比较(谁得分高谁赢)来和 LLM 评审模型对照【第 6 页】。
评测方式的统一
为了让不同模型公平可比:
-
对每个评审模型,保留其原始 prompt 模板(即开发者原来的输入格式),
但统一修改其中的评价规则,使其遵循本文提出的四层标准:Refusal → Faithfulness → Completeness → Conciseness
(详见论文 Sec. 3 和 附录 B.2。) -
对通用模型(如 GPT-4o 等)采用 greedy 采样,即无随机性生成输出;
这样结果可复现,也更能反映评估逻辑稳定性。
实验设计的关键点
- 所有评审都按 pairwise 方式进行(即 A vs B 选优),符合 ContextualJudgeBench 的设计;
- 一致性双运行机制确保可度量模型偏差;
- 统一上下文长度上限 128K tokens,保证所有模型能处理长文档;
- 统一指标体系,核心报告 Consistent Accuracy;
- 引入强通用模型和传统指标(RAGAS/MiniCheck)作基线,验证生成式评审器是否真的更优。
作者的评测目的
通过这样的设计,他们想回答三个核心问题:
- 📏 在复杂上下文任务中,现有评审模型的稳定性与准确性如何?
- 🔍 与通用推理 LLMs 或传统指标(RAGAS、MiniCheck)相比,这些微调过的评审模型是否真的更可靠?
- ⚖️ 模型大小、推理能力、是否生成解释,对评审质量有何影响?
后续 4.2 节的表 3 即基于这些设置汇报结果:最强 OpenAI o1 模型的 Consistent Accuracy 只有 55.3%,表明“上下文评估”仍是一个尚未解决的挑战。
✅ 总结一句话:
在 Evaluation Setup and Baselines 中,作者构建了一个严格、可复现的双次评审体系,定义了 5 个衡量指标,以 20 个评审/推理模型和 2 个非生成基线为对照,统一用 ContextualJudgeBench 来检验 “LLM 评审员” 在真实上下文场景下的判断力与稳定性。
探究其他问题
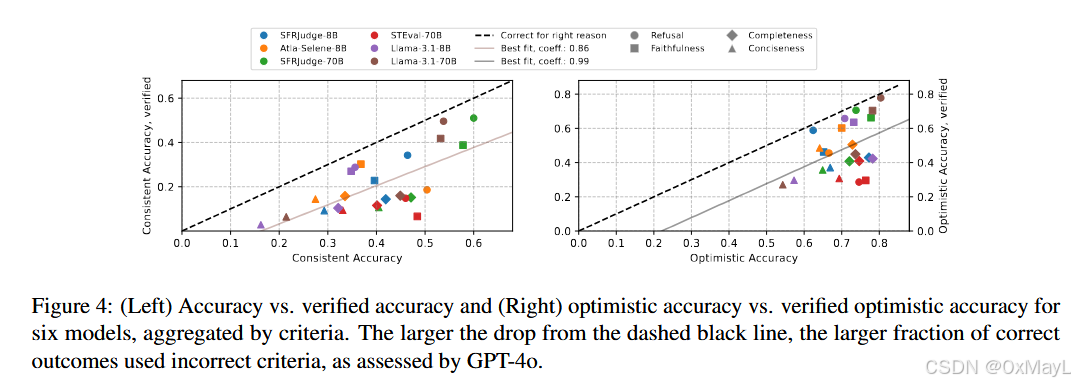
除了研究现有LLM judge在上下文任务情景下评估的可靠性,作者探究了以下问题:
LLM是否根据正确的准则来作出决策的?
- 作者使用GPT-4O来判定正确回答是否根据实现规定的评判标准,得到修正后的consistency accuracy
具体流程为:
- 模型的解释;
- 模型选出的答案;
- 当前任务所属的评估标准(如“faithfulness”、“completeness”等);
- 然后判断:
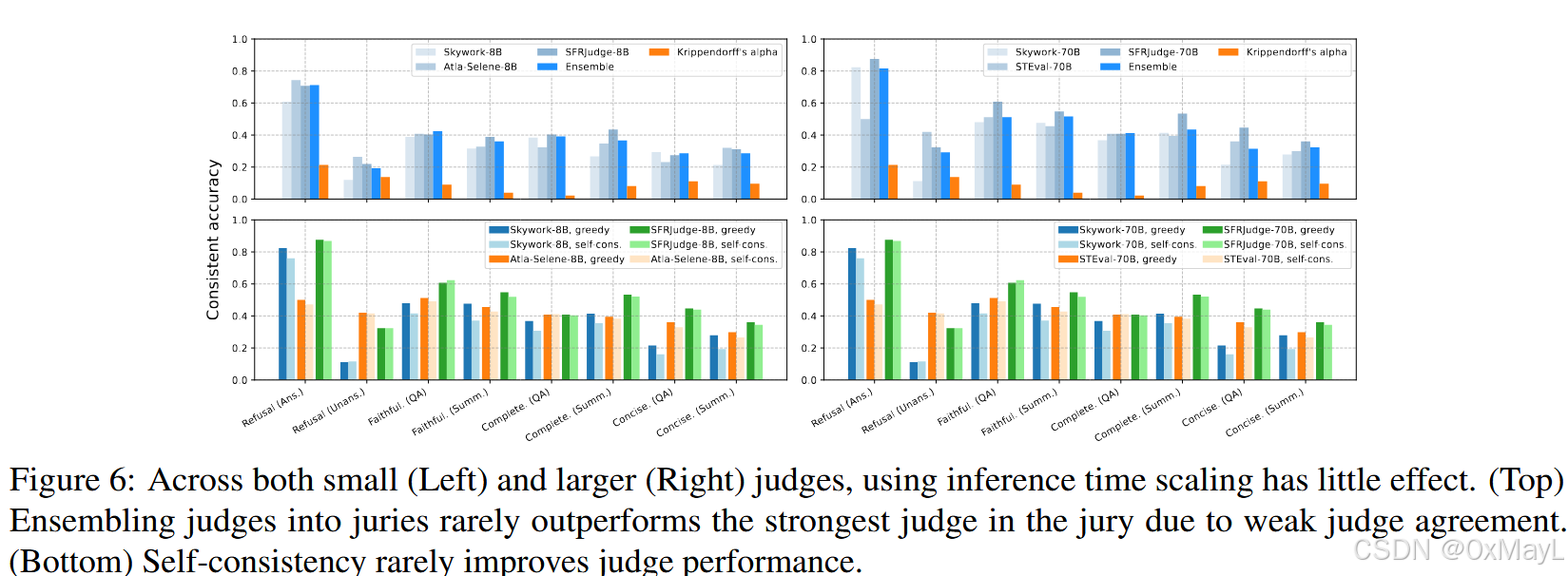
在评审任务中,增加推理时的计算量(如自一致、多模型集成等方法)能否提升 LLM 评审员的表现?
在第 4.2 – 4.3 节的实验中,作者发现:
- 即使是很强的模型(如 GPT-o1、DeepSeek-R1),在 ContextualJudgeBench 上的**一致准确率(Consistent Accuracy)**仍不高;
- 而且评审任务明显比普通文本生成更推理密集(reasoning-intensive)。
因此,他们提出问题:
❓是否可以通过增加推理阶段的计算量(inference-time scaling)——例如让模型多想几次、多评几遍、或多模型投票——来提升评审的准确性?
–
| 内容 | 概要 |
|---|---|
| 研究问题 | 扩大推理计算(多模型、多采样)能否让评审更准? |
| 方法 | (1) LLM-as-Jury:多评审多数投票; (2) Self-Consistency:同一模型多次采样投票。 |
| 结果 | 两种方法效果微弱,甚至不如单模型。 |
| 原因分析 | 评审模型间缺乏一致标准;系统性偏差(位置、长度)无法通过采样平均消除。 |
| 结论 | 推理时扩算(inference-time scaling)对上下文评审无显著帮助;改进需从训练与标准化入手,而非计算扩展。 |
上下文(context)越长、回答(response)越长,是否会让评审模型(LLM-as-judge)的判断变得更困难
在前文实验中,作者已经发现:
- 模型在 faithfulness(忠实性)、completeness(完整性) 等需要深度理解上下文的任务上表现明显下降;
- 同时,模型还受到**长度偏差(length bias)**影响——倾向于选择较长的回答。
因此他们进一步想验证:
当上下文本身很长、回答也很长时,这两种因素会不会**叠加(compound)**导致评审模型的准确率和一致性下降?
作者基于 ContextualJudgeBench 中所有样本(共 2000 对),计算每个样本的:
- 上下文长度(context length);
- 回答平均长度(mean response length)。
然后:
1️⃣ 将样本按长度分桶(binning)——从短到长划分为多个区间;
2️⃣ 计算每组样本的:
- Consistent Accuracy(一致准确率)
- Consistency(判断一致性);
3️⃣ 对结果在六个表现较强的评审模型上取平均: - Llama-3.1-70B
- STEval-70B
- SFRJudge-70B
- GPT-4o
- DeepSeek-R1
- GPT-o1
结果可视化在 Figure 8(第 9 页),其中左图显示准确率变化,右图显示一致性变化。
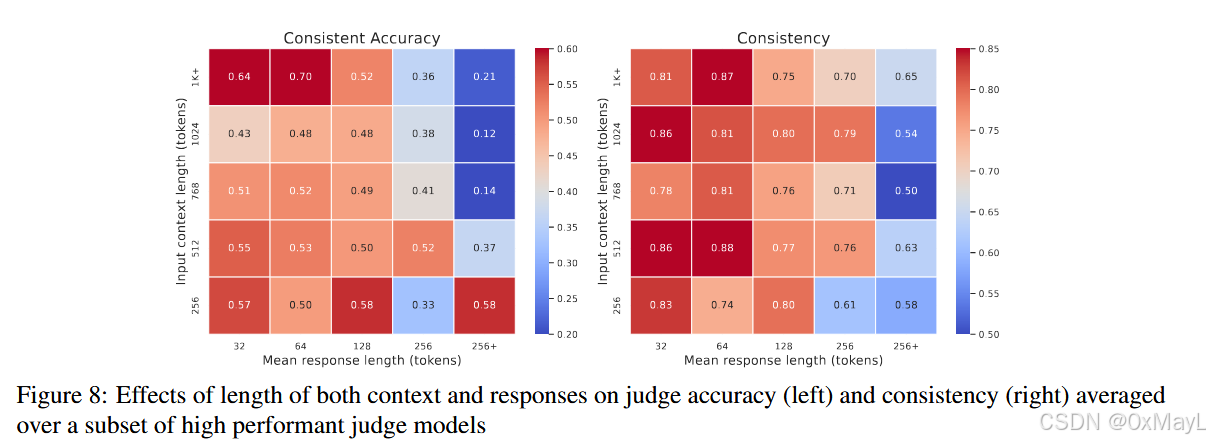
(1)长上下文 & 长回答 → 双重负效应
-
总体趋势:
- 当上下文和回答都变长时,模型的一致准确率显著下降;
- 判断的一致性(Consistency)也随之下降。
📉 举例趋势:
- 短上下文 + 短回答 → 准确率可接近 0.55–0.60
- 长上下文 + 长回答 → 准确率降至约 0.20–0.30
- 说明:模型越需要处理大量信息,它越容易出现理解偏差、标准混淆或记忆溢出。
(2)“回答长度”比“上下文长度”影响更大
-
当单独比较两种因素时:
- 上下文越长 → 模型理解和核对难度上升;
- 但回答越长 → 模型需要在更庞大文本中判断“哪句多余/不忠实”,更容易出错。
结论:回答长度是更主要的性能下降来源。
💬 作者认为这是因为评审任务的输入实际上包含三部分:
- 用户输入(问题);
- 上下文;
- 两个回答。
当回答过长时,模型在 prompt 窗口中必须“比对更多事实”,认知负担更高。
(3)短上下文 / 短回答 → 明显更稳定
-
在上下文较短(如 256 tokens 以下)或回答简短时:
- 模型的准确率与一致性都显著提升;
- 表明在“低信息量”环境中,评审模型能更清晰地聚焦标准(如忠实性、简洁性等)。
| 项目 | 内容摘要 |
|---|---|
| 研究问题 | 长上下文与长回答是否让评审更困难? |
| 方法 | 按上下文和回答长度分组,分析6个强评审模型在不同长度区间的准确率与一致性变化。 |
| 结果一 | 上下文和回答越长 → 准确率、一致性均显著下降。 |
| 结果二 | 回答长度影响更大于上下文长度。 |
| 结果三 | 短上下文 / 短回答样本中模型更稳定。 |
| 结论 | 上下文与回答长度具有叠加负效应(compound effect);当前评审模型对长文本理解仍显不足。 |
简而言之:
📉 评审模型的表现会随着上下文和回答长度同时增加而显著退化;尤其是长回答带来的复杂性,让模型更难保持一致、准确的判断。
这说明“上下文评审”不仅考验语言理解,还考验模型的记忆、聚焦与比较能力。
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)