
大模型技术演变-6生成式预训练开端Improving Language Understanding by Generative Pre-Training读后笔记
论文提出了一种革命性的两阶段训练框架,通过无监督预训练与有监督微调相结合,有效解决了NLP领域标注数据稀缺的难题。该模型采用Transformer解码器架构,在BookCorpus数据集上进行语言建模预训练,展现出强大的迁移学习能力。实验表明,在12个NLP任务中的9个取得当时最优性能,尤其在常识推理任务上实现8.9%的显著提升。
1 研究背景与动机
在自然语言处理(NLP)领域,大量未标注文本数据丰富,但用于特定任务(如文本蕴含、问答、语义相似性评估、文档分类等)的标注数据相对稀缺。这使得完全依赖监督学习的模型性能受到限制。尽管词嵌入(Word2Vec, GloVe)等技术能利用无标注数据提升单词级别的表示,但它们难以捕捉句子、段落或文档级别的语义信息。此前的许多研究方法存在两大挑战:首先,不确定何种优化目标能最有效地学习到有利于迁移的文本表示;其次,对于如何将学习到的表示有效迁移到下游任务,也缺乏共识。GPT-1论文针对这些问题,提出了一种半监督学习框架,通过生成式预训练(Generative Pre-Training)充分利用海量无标注文本,再通过微调(Fine-tuning)适配下游任务。
2 核心方法:两阶段训练
GPT-1的核心创新在于其两阶段训练流程(无监督预训练 + 有监督微调),这一范式对后续大模型发展产生了深远影响。
2.1 无监督预训练 (Unsupervised Pre-training)
在此阶段,模型利用大量无标注文本语料,通过语言建模目标进行训练。其目标是基于上文预测下一个单词(Token),最大化以下似然函数:
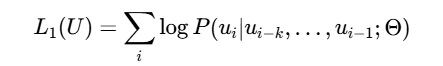
其中 U=u1,…,un表示未标注的文本序列,k是上下文窗口大小,Θ是模型参数。模型架构上,GPT-1采用了Transformer的Decoder部分(12层堆叠的Masked Multi-Self-Attention结构),摒弃了Encoder部分。这样设计是因为语言模型需根据上文预测下一个词,Decoder的单向注意力机制(Masked Self-Attention)天然契合这一需求,它能防止当前位置关注到后续信息。模型输入包括词嵌入(Token Embedding) 和 位置嵌入(Position Embedding),经过多层Transformer Decoder后,通过Softmax输出下一个词的概率分布。
2.2 有监督微调 (Supervised Fine-tuning)
预训练完成后,模型会针对特定的下游NLP任务进行有监督微调。论文的一个关键点是采用了任务感知的输入转换(Task-aware Input Transformation),将不同任务的结构化输入(如句子对、文档-问题-答案三元组)重新组织成单一连续的令牌序列,以便模型处理。微调时,使用带标签的数据集,通过最大化条件似然函数进行训练:
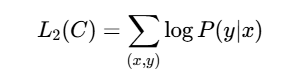
其中 C是带标签的数据集,x是输入序列,y是对应的标签。微调过程仅需最小化模型架构的改动,通常只需添加一个线性输出层,从而实现了高效的任务适配。
3 技术实现与模型细节
-
模型架构: 基于Transformer Decoder,包含12层,隐藏层维度为768,采用12个注意力头(Attention Head)。
-
预训练数据: 使用了BookCorpus数据集,约7000本未出版的书籍,总计约5GB的文本数据。
-
参数规模: GPT-1总参数量为1.17亿。
-
关键技巧: 在微调阶段,作者发现将预训练目标(语言建模)作为辅助损失引入微调过程有助于提升模型的泛化能力,并加速收敛。
4 实验结果与性能表现
论文在多种NLP任务上评估了GPT-1的性能,涵盖了:
-
自然语言推理(Natural Language Inference, NLI),如MultiNLI
-
问答(Question Answering),如RACE
-
语义相似性(Semantic Similarity)
-
文本分类(Text Classification)
-
常识推理(Commonsense Reasoning),如Story Cloze Test
在12个任务中的9个上,GPT-1取得了当时的最先进(State-of-the-Art)性能。具体提升包括:
-
在常识推理(Story Cloze Test)上实现了8.9%的绝对改进。
-
在问答(RACE)上实现了5.7%的绝对改进。
-
在文本蕴含(MultiNLI)上实现了1.5%的绝对改进。
-
在GLUE多任务基准上实现了5.5%的绝对改进。
下表概要展示了GPT-1在部分任务上的性能提升:
|
任务类型 |
数据集示例 |
性能提升 (绝对) |
意义 |
|---|---|---|---|
|
常识推理 |
Story Cloze |
+8.9% |
表明模型更好地理解了日常常识和叙事逻辑 |
|
问答 |
RACE |
+5.7% |
显示模型阅读理解能力的显著进步 |
|
自然语言推理(文本蕴含) |
MultiNLI |
+1.5% |
在复杂语义理解任务上展现优势 |
|
综合评估 |
GLUE Benchmark |
+5.5% |
证明了模型 across multiple tasks 的强大泛化能力 |
这些结果验证了生成式预训练结合判别式微调的有效性,表明其学习到的表示具有很强的迁移能力。
5 历史意义与影响
GPT-1论文的发布具有里程碑式的意义,它为NLP领域乃至整个AI发展方向带来了深远影响:
-
开创了生成式预训练范式: GPT-1首次成功验证了通过生成式语言模型预训练(自回归语言建模)学习通用文本表示,再通过微调适配下游任务的可行性。这为后续的GPT-2、GPT-3、ChatGPT等系列模型奠定了坚实的基础。
-
奠定了Transformer在NLP的主导地位: 虽然Transformer架构于2017年提出,但GPT-1是其在大规模预训练模型中的成功实践之一(与BERT几乎同期),证明了Transformer(尤其是Decoder)在捕获长程依赖和高效并行计算方面的巨大优势,促使它逐渐取代RNN、LSTM成为NLP的主流架构。
-
推动了半监督学习在NLP的应用: 论文证实了无监督预训练+有监督微调这一半监督学习路径在NLP领域的巨大潜力,提供了一种有效利用海量无标注数据的方案,缓解了对大量标注数据的依赖。
-
提出了灵活的任务适配方案: 其任务感知的输入转换方法,将不同NLP任务均转化为类似文本生成的序列形式,实现了模型架构的最小改动,为构建通用任务无关模型提供了重要思路。
-
启示了模型缩放的重要性: 虽然GPT-1的参数量“仅”为1.17亿,但其成功为后续研究指明了一个方向:扩大模型规模(参数量、数据量) 可能带来能力的显著提升。这直接引导了GPT-2(15亿)、GPT-3(1750亿)等更大规模模型的探索。
6 总结与思考
《Improving Language Understanding by Generative Pre-Training》这篇论文是NLP领域发展过程中的一个重要转折点。它不仅在技术上创新地结合了Transformer架构和两阶段训练模式,更在理念上推动了从为特定任务设计特定模型,向预训练大规模通用模型并微调的范式转变。
GPT-1的局限性也同样明显,例如其单向上下文建模(仅从左到右)在理解任务上可能不如同时期BERT的双向编码全面;其模型规模与后续模型相比也较小。然而,正是这些不足为后续研究留下了空间,并清晰地勾勒出了一条通过扩大模型规模、扩展数据、改进训练策略来提升模型能力的演进路线。
总体而言,GPT-1如同一颗种子,其提出的生成式预训练思想在此后几年迅速生长,最终开花结果,催生了如今丰富多彩的大语言模型生态,深刻地改变了人工智能的发展图景。
更多推荐
 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)