
【论文阅读05】-基于知识图谱与大语言模型的航空装配故障诊断联合方法
:一种经过海量文本数据训练的人工智能系统,能够理解和生成人类语言,类似一个非常博学的"文字预测器",可以根据输入的问题或提示生成连贯的回答。。
📌 研究背景与问题
- 研究背景:航空装配系统复杂度高,传统故障诊断依赖人工查询手册,效率低下;
- 问题陈述:多维信息(组件、工艺、工具等)形成复杂系统,需要智能故障定位解决方案技术;
- 挑战:LLMs缺乏事实知识捕获能力,KGs缺乏创造性和用户体验。
能否将KG的准确性与LLM的智能性相结合,取长补短,构建一个既可靠又易用的航空装配故障诊断专家系统?
📌 研究目标
提出一种KG与LLM的联合知识增强模型,实现航空装配领域高效、高精度的智能故障定位与解决方案生成。
🧠 所用方法
一、整体框架设计
-
核心思想: 一个两阶段联合框架。
-
阶段一(模型增强): 将领域知识(KG子图)通过前缀调优技术嵌入LLM,让模型“学好专业知识”。
-
阶段二(检索增强): 在推理时,通过子图生成-检索模型从用户问题中动态检索相关知识子图,作为提示输入给LLM,让模型“用对专业知识”
-
联合知识增强框架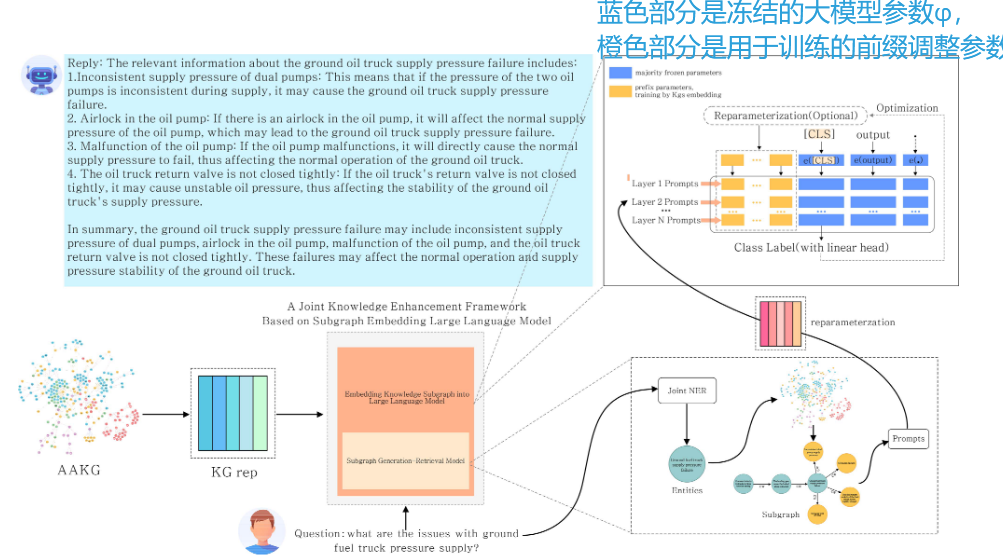
二、创新点一:知识增强的模型微调方法
方法: KG嵌入LLM的前缀调优。
-
从AAKG知识图谱中提取与特定故障相关的“2步关系子图”(包含实体直接和间接关系及属性)。
-
将子图转化为文本序列,作为连续提示前缀与原始问题一起输入LLM。
-
训练策略:训练时只优化代表前缀的少量参数,冻结LLM绝大部分参数,高效且避免灾难性遗忘。
优势: 使LLM内部化领域知识,成为一个领域专家,同时训练效率高。
三、创新点二:动态检索增强的推理机制
方法: 子图生成-检索模型。
命名实体识别(NER)技术:
- 使用命名实体识别技术从用户自然语言问题中提取关键实体(如部件名、故障现象)。
-
用这些实体去图数据库(如Neo4j)中查询,生成一个相关的、简洁的知识子图。
-
将该子图与用户问题组合成增强提示,输入给已经过微调的LLM。
优势: 支持知识融合和检索增强,提升专业领域知识的准确性。
🧪 实验设计
一、实验设置
-
数据集: 自建航空装配故障定位语料库AA550,包含200个真实工业故障案例,并通过添加噪声(错别字、语序颠倒)构建了总计1655条问题,模拟真实环境。
-
对比模型:
-
未调优的ChatGLM-6B
-
ERNIE-3.5
-
仅使用子图嵌入的GLM模型
-
本文提出的联合增强模型
-
-
评估指标: 准确率、精确度、召回率、F1值。
二、主要实验结果
-
准确性对比:
-
本文模型: 98.5% (在200个案例中正确诊断197个)
-
子图嵌入GLM: 93%
-
ChatGLM: 41.5%
-
ERNIE: 45%
-
-
结论: 本文提出的联合模型在故障诊断准确率上显著优于其他基线模型,证明了方法的有效性。
三、系统性能与应用验证
-
效率: 平均响应时间<1.1秒,字符生成速度达10.92字符/秒。
-
工业价值: 诊断耗时仅为人工审查的6.5%,效率提升巨大。
-
案例展示: 通过一个具体故障案例(如“XX部件安装不到位”),展示系统如何通过检索子图、融合知识,最终生成准确解决方案的全过程,体现其可解释性。
✅ 研究结论
-
本研究成功开发了一个KG与LLM深度融合的航空装配故障诊断联合框架。
-
通过知识增强(前缀调优) 和检索增强(子图检索) 双重机制,有效解决了LLM在专业领域知识不足和不可信的问题。
-
实验证明,该框架不仅实现了接近98.5%的超高诊断准确率,还具备了高效率、高可解释性的优点,满足工业应用需求。
📈 研究意义
本文的研究意义在于提出了一种融合知识图谱与大语言模型的联合知识增强框架,为解决航空装配等复杂工业场景中的智能故障诊断问题提供了创新性解决方案。该方法通过将知识图谱的结构化专业知识以子图形式嵌入大语言模型的前缀调优过程,显著提升了模型在专业领域的知识推理准确性和可靠性,同时保留了大语言模型的自然语言交互优势。
🔮 未来研究方向
-
技术层面: 探索更高效的子图采样策略、尝试更多先进的LLM作为基座模型。
-
应用层面: 将本框架扩展至航空维修、其他复杂装备制造等更多工业领域。
-
功能层面: 研究支持多模态输入(如图片、视频)的故障诊断,使系统能力更加全面。
📕专业名词
一、核心人工智能技术术语
LLM (Large Language Model) - 大语言模型
-
外行定义:一种经过海量文本数据训练的人工智能系统,能够理解和生成人类语言,类似一个非常博学的"文字预测器",可以根据输入的问题或提示生成连贯的回答。
KG (Knowledge Graph) - 知识图谱
-
外行定义:一种以图形方式组织知识的方法,将现实世界中的事物(实体)和它们之间的关系用节点和连线表示,就像一张巨大的"知识地图"。
AAKG (Aviation Assembly Knowledge Graph) - 航空装配知识图谱
-
外行定义:专门为航空装备制造领域构建的知识图谱,包含了飞机组装过程中涉及的所有部件、工艺、故障现象和解决方案等专业知识。
二、自然语言处理技术术语
NER (Named Entity Recognition) - 命名实体识别
-
外行定义:从文本中自动识别和提取特定类型实体的技术,比如从问题中找出人名、地名、机构名或本文中的故障部件名称等。
HMM (Hidden Markov Model) - 隐马尔可夫模型
-
外行定义:一种统计模型,用于处理序列数据,通过观察可见的信号来推测背后不可见的状态序列,常用于语音识别和文本标注。
CRF (Conditional Random Field) - 条件随机场
-
外行定义:一种更先进的序列标注模型,能够考虑整个句子的上下文信息来做出更准确的标注决策。
BiLSTM (Bidirectional Long Short-Term Memory) - 双向长短期记忆网络
-
外行定义:一种特殊的神经网络,能够同时从前后两个方向理解文本的上下文含义,更好地捕捉长距离的依赖关系。
三、模型训练与优化术语
Prefix-tuning - 前缀调优
-
外行定义:一种高效训练大模型的方法,只训练添加到输入前的一小段"提示词"参数,而不改动模型原有的权重,就像给模型一个专门的"使用说明书"。
Fine-tuning - 微调
-
外行定义:在预训练好的基础模型上,用特定领域的数据进行进一步训练,使模型适应特定任务的过程。
Adapter-tuning - 适配器调优
-
外行定义:一种参数高效的微调方法,在模型中插入小的可训练模块(适配器),而保持主干网络参数不变。
P-tuning v2
-
外行定义:前缀调优的改进版本,在模型的多个层都添加可训练的提示参数,效果更好。
四、评估指标术语
F1值 (F1-score)
-
外行定义:综合考量模型准确率和召回率的评价指标,数值越高说明模型整体性能越好,是准确率和召回率的"调和平均数"。
Precision - 精确度
-
外行定义:模型预测为正例的样本中,真正为正例的比例,衡量的是"宁缺毋滥"的程度。
Recall - 召回率
-
外行定义:所有真实的正例样本中,被模型正确预测出来的比例,衡量的是"网罗全面"的程度。
五、其他专业术语
Transformer架构
-
外行定义:当前大多数先进语言模型采用的底层技术架构,使用自注意力机制来处理序列数据。
Retrieval-augmentation - 检索增强
-
外行定义:让模型在回答问题前先从一个知识库中查找相关信息,然后基于这些信息生成回答,类似于"开卷考试"。
Stochastic Gradient Descent - 随机梯度下降
-
外行定义:一种优化算法,通过不断微调模型参数来最小化错误率,是模型"学习"的核心过程。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)