
一文理清 AI 模型、大模型与开源模型:概念、差异及应用指南
一文理清 AI 模型、大模型与开源模型:概念、差异及应用指南
在人工智能技术飞速发展的当下,“AI 模型”“大模型”“开源模型” 等术语频繁出现,却常让人混淆。尤其对于高校教师而言,清晰区分这些概念不仅是自身学习的基础,更是开展教学、指导科研的关键。本文将从概念解析、核心差异、应用场景三个维度,系统梳理相关知识,并结合教育领域实践需求补充实用建议,助力更深入地理解 AI 技术体系。
一、核心概念详解:从基础模型到开源体系
1 AI模型、AI大模型、开源模型的概念提示词(Prompt):我是一位高校老教师,学习人工智能过程中,请问AI大模型的概念等知识,帮助我们更好理解AI大模型。谢谢!
DeepSeek(深度探索):您好!作为高校教师,您对人工智能大模型的学习和理解非常有意义。以下我将以系统、简明的方式为您梳理AI大模型的核心概念、技术特点、应用场景及学习建议,帮助您更好地掌握这一领域。


1. AI模型
(1)定义: 指通过算法和数据训练出的、能完成特定任务的模型,涵盖从简单的统计模型到中等复杂度的深度学习模型。例如线性回归、决策树、支持向量机(SVM)、卷积神经网络(CNN)等。
(2)特点:
规模较小:参数量通常在百万级以下,训练数据量相对有限。
专用性强:针对单一任务设计(如图像分类、文本分类)。
资源需求低:可在普通计算资源(如CPU或单个GPU)上训练和部署。
可解释性:部分传统模型(如决策树)结构透明,易于理解。
(3)典型应用:
简单预测任务(如房价预测)。
特定领域的小规模任务(如手写数字识别)。
2.AI大模型的概念
(1)AI大模型的定义
AI大模型(Large AI Models)是参数规模巨大(通常达数十亿甚至万亿级)、基于海量数据训练的深度学习模型,能够完成复杂任务(如文本生成、图像合成、跨模态推理等)。
其核心特点包括:
参数规模大:参数数量远超传统模型,例如GPT-3有1750亿参数。
通用性强:通过预训练学习广泛的知识,适应多领域任务(如ChatGPT的对话、编程、翻译)。
自监督学习:无需人工标注数据,通过预测文本中的掩码词或生成下一句进行训练。
(2)AI大模型的发展历程
①早期模型(2017年前):以RNN、CNN为主,参数规模小(百万级),任务专用(如情感分析)。
②Transformer革命(2017年):Google提出Transformer架构,通过自注意力机制解决长距离依赖问题,成为大模型基石。
③预训练时代(2018年后):
BERT(2018):双向Transformer,通过掩码语言模型理解上下文。
GPT系列(2018-2020):OpenAI的生成式预训练模型(GPT-1/2/3),逐步扩大参数规模。
多模态模型(2021年后):如CLIP(图文匹配)、DALL·E(文生图)、GPT-4(多模态输入)。
④人工智能的终局:通用人工智能(AGI)
通用人工智能AGI是“Artificial General Intelligence”的缩写,是指具备与人类相当或超越人类的综合智能系统,能够像人类一样在多领域进行感知、推理、学习、决策和创造,并适应复杂动态环境。与专用人工智能(如ChatGPT、图像识别工具)不同,AGI的关键在于跨领域通用性,其智能不局限于单一任务,而是通过自主学习和泛化能力解决未知问题。 例如,人类可以同时处理数学题、驾驶汽车、创作诗歌,而当前AI仅能完成特定任务。AGI的终极目标是实现这种综合能力的统一
这里引用OpenAI提出的五级标准,来判断AGI的实现程度:
第一级:聊天机器人(如ChatGPT)。仅具备对话能力,无法主动推理或执行复杂任务。
第二级:推理者(OpenAI自评接近但未达到)。能像博士学历人类一样解决跨领域问题,例如无需工具辅助完成科研级数学推导或法律案例分析。
第三级:代理者。代表用户长期行动,例如自主管理日程、协调多方资源完成项目。
第四级:创新者。辅助人类发明新技术,如设计新药分子结构或优化量子计算算法。
第五级:组织者。具备企业级管理能力,可独立运作公司或协调全球供应链。
目前主流观点认为,达到第三级(代理者)可视为初步实现AGI,而第五级则标志着超越人类组织能力的超级智能。
而关于通用人工智能(AGI)何时才能实现也存在着显著分歧:激进派如OpenAI内部文件预测可能在2028-2033年实现初级AGI(具备跨领域代理能力),而保守派如清华大学郑纬民院士认为,ChatGPT仅代表工程化改进,基础理论未突破,AGI至少需到2070年后。深度学习先驱Geoffrey Hinton也强调:“人类大脑的能耗效率是当前AI的十亿倍,硬件革命是AGI的前提”。这种差异源于对技术瓶颈的不同评估——当前大模型依赖海量数据与高能耗(GPT-4训练能耗约1.3×10²⁵焦耳),而人类智能具备小样本学习优势。
(3)大模型的核心技术
①Transformer架构:
自注意力机制(Self-Attention):计算输入序列中每个词与其他词的关系权重,捕捉长距离依赖。
位置编码(Positional Encoding):为模型提供序列位置信息。
多头注意力(Multi-Head Attention):并行多组注意力机制,增强模型表达能力。
②预训练与微调(Pre-training & Fine-tuning):
预训练:在大规模无标注数据上训练模型,学习通用特征(如GPT通过预测下一个词)。
微调:在特定任务的小规模标注数据上调整模型参数,适应具体场景(如医疗问答)。
③提示学习(Prompt Learning):
通过设计自然语言提示(如“请翻译为英文:___”),引导模型完成任务,减少对标注数据的依赖。
(4)大模型的典型应用
①自然语言处理(NLP):
文本生成:撰写文章、代码、诗歌(如ChatGPT)。
问答系统:开放域知识问答(如Perplexity AI)。
机器翻译:支持多语言互译(如Google Translate)。
②多模态任务:
文生图:根据文字生成图像(如MidJourney、Stable Diffusion)。
视频理解:分析视频内容并生成摘要。
③教育领域应用:
智能助教:自动批改作业、生成习题。
个性化学习:根据学生水平推荐学习材料。
科研辅助:文献摘要生成、实验设计建议。
(5)大模型的挑战与争议
①算力与资源消耗:
训练GPT-3需数千张GPU,耗电相当于数百家庭年用电量,引发碳足迹争议。
②数据偏见与伦理风险:
模型可能放大训练数据中的偏见(如性别、种族歧视)。
生成虚假信息(“幻觉”)可能导致误导。
③可解释性不足:
模型决策过程类似“黑箱”,难以追溯错误原因。
(6)高校教师的学习建议
①入门路径:
理论学习:阅读经典论文(如《Attention Is All You Need》)、学习在线课程(如吴恩达《深度学习专项课程》)。
实践工具:通过Hugging Face平台调用现成模型(如BERT、GPT-2),使用Colab免费GPU资源运行代码。
②教学结合:
案例教学:用大模型生成课堂案例(如自动写作文),与学生讨论其优缺点。
跨学科探索:在文科中分析AI生成文本的逻辑,在理工科中结合大模型解决数据处理问题。
③伦理教育:
引导学生批判性思考AI的伦理问题(如隐私、版权),设计相关研讨主题。
(7)扩展资源推荐
①书籍:《深度学习》(花书)、《自然语言处理实战:利用Python理解、分析和生成文本》。
②论文:GPT-3论文《Language Models are Few-Shot Learners》、BERT论文《BERT: Pre-training of Deep Bidirectional Transformers》。
③实践平台:Hugging Face(模型库)、Kaggle(数据集和竞赛)、OpenAI Playground(体验GPT模型)。
3.开源模型的概念
(1)开源模型概念
开源是“众人拾柴”的技术民主化实验,闭源是“重兵突进”的商业深水区探索,二者如同燃油车与电动车——路径不同,但共同驱动AI向更普惠、更强大的方向进化。
在大语言模型发展的发展过程中,开源模型与闭源模型的技术路线之争一直存在。
什么是开源模型? 开源模型是指由开源社区或组织开发、维护和共享的大型软件模型。 这些模型的源代码是公开的,所有人都可以查看、修改和分发。
开源模型就像公开菜谱的连锁餐厅,不仅提供成品菜品(模型功能),还开放食材清单(训练数据)、烹饪步骤(模型架构)和火候参数(训练代码),允许任何人复刻或改进 。
典型案例如Meta的Llama,全球开发者可下载完整代码,用自有数据微调出方言翻译、医疗问答等分支模型 。又比如DeepSeek-33B,开源中英双语模型,同时还允许企业植入内部知识库(如阿里云将其改造成金融风控工具)。
(2)开源模型类型
那到底什么程度才算是开源?业内所说的开源实则也有三种,不可一概而论:
①代码开放(Open Source)。这是最彻底的一种开放。将软件或者算法完全开放,源代码可查,如Python和Linux将每一行代码置于阳光下,允许自由查看、修改与再创造,这种全透明模式催生了安卓系统等突破性技术。
②数据开放(Open Data)。即将数据集(如文本、图像、结构化数据)公开。这种开放构建了AI训练的公共资源池,如同开源燃料,推动计算机视觉等领域跨越式发展。
③权重开放(Open Weights)。指开放公开训练好的模型参数(weights),可以理解即为允许他人直接部署或微调模型,而无需从头训练。这种开放开启了AI普惠新阶段,DeepSeek的开源便是属于此类。使用者无需知晓训练细节即可部署或微调,**在保护核心算法机密性的同时,**让普通开发者也能调用前沿AI能力。
二、AI模型、AI大模型的区别与联系
AI模型与AI大模型是人工智能领域的两个重要概念,它们在规模、能力和应用场景上有显著区别。以下是两者的概念解析及主要差异:
(1)AI模型(通用AI模型)
①定义:AI模型指通过算法和数据训练出的、能完成特定任务的模型,涵盖从简单的统计模型到中等复杂度的深度学习模型。例如线性回归、决策树、支持向量机(SVM)、卷积神经网络(CNN)等。
②特点:
规模较小:参数量通常在百万级以下,训练数据量相对有限。
专用性强:针对单一任务设计(如图像分类、文本分类)。
资源需求低:可在普通计算资源(如CPU或单个GPU)上训练和部署。
可解释性:部分传统模型(如决策树)结构透明,易于理解。
③典型应用:
简单预测任务(如房价预测)。
特定领域的小规模任务(如手写数字识别)。
(2)AI大模型(Large AI Models)
①定义:AI大模型指参数量极大(通常达十亿甚至万亿级别)、基于深度学习架构(如Transformer)训练的模型。典型代表包括GPT-4、PaLM、BERT等。
②特点:
超大规模:参数量在十亿(1B+)到万亿(1T+)级别,需海量数据训练。
通用性强:通过预训练学习广泛的知识,可迁移到多种下游任务(如文本生成、翻译、代码编写)。
复杂架构:采用多层神经网络(如Transformer的注意力机制),支持并行计算。
高资源消耗:依赖大规模分布式计算集群(如数千GPU/TPU)和巨额能源。
③典型应用:
自然语言处理(对话系统、内容生成)。
多模态任务(图文生成、跨模态检索)。
复杂推理(代码生成、数学问题求解)。
(3)AI模型与AI大模型的核心区别
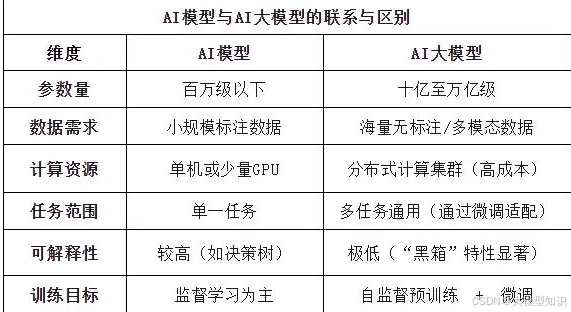
(4)优势与局限性
AI模型:
优势:轻量化、易部署、计算成本低。
局限:泛化能力弱,难以处理复杂任务。
AI大模型:
优势:强大的涌现能力(如逻辑推理)、零样本/少样本学习。
局限:训练成本高、存在偏见风险、依赖高质量数据。
(5)总结
AI模型是基础工具,适用于资源有限、任务明确的场景。
AI大模型是技术前沿,通过规模效应实现通用智能,但需权衡成本与伦理问题。
未来趋势可能是两者的结合:大模型提供底层能力,小模型针对具体场景优化(如模型压缩、蒸馏技术)。
三、AI大模型、生成式AI的区别与联系
大模型(Large Models)与生成式人工智能(Generative AI)是两个密切相关但存在区别的概念。以下是两者的定义、特点及区别分析:
1. 大模型(Large Models)
(1)定义:大模型指参数量极大(通常在十亿至万亿级别)、训练数据规模庞大的深度学习模型,例如GPT-4、PaLM、BERT等。其核心特点是规模驱动性能,通过增加模型参数和数据量提升泛化能力。
(2)关键特点
参数量庞大:模型结构复杂,参数可达千亿甚至万亿级别。
预训练+微调范式:先在大量无标注数据上预训练(如文本、图像),再针对具体任务微调。
多任务能力:能处理文本生成、翻译、问答、代码编写等多种任务。
高计算需求:训练依赖大规模算力(如GPU集群)和分布式技术。
(3)典型应用
自然语言处理(如ChatGPT、文心一言)
多模态任务(如CLIP、DALL·E)
复杂推理(如AlphaFold)
2. 生成式人工智能(Generative AI)
(1)定义
生成式人工智能是以创造新内容为核心目标的AI技术,能够生成文本、图像、音频、视频等。其核心技术包括生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion Models)和基于Transformer的大模型(如GPT)。
(2)关键特点
内容生成:核心目标是创造新数据(如写文章、画图、作曲)。
多样性技术:如GAN的对抗训练、扩散模型的逐步去噪。
多模态支持:可跨文本、图像、音频等模态生成内容。
可控性:通过提示词(Prompt)或条件控制生成结果。
(3)典型应用
文本生成(如ChatGPT、小说创作)
图像生成(如Midjourney、Stable Diffusion)
代码生成(如GitHub Copilot)
语音合成(如DeepMind的WaveNet)
3.AI大模型与生成式AI的区别
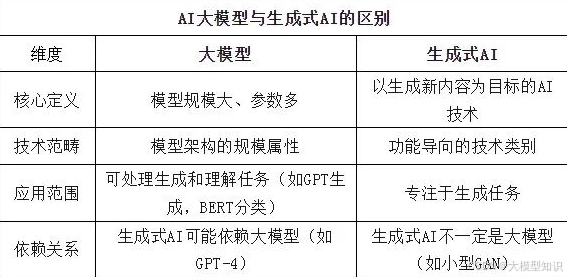
4.联系与交叉
大模型推动生成式AI发展:以GPT、PaLM为代表的大模型显著提升了生成内容的质量和多样性。
生成式AI是大模型的主要应用场景:大模型常被用于生成任务(如对话、创作),但也能处理理解任务(如分类、摘要)。
技术融合:生成式AI的工具(如扩散模型)可能结合大模型的规模优势(如Imagen结合T5模型)。
总结
大模型。强调模型的规模和架构,是技术实现的载体。
生成式AI。强调生成新内容的能力,是功能层面的定义。
交叉点:大模型(如GPT-4)是生成式AI的重要实现方式,但生成式AI也可通过小模型(如GAN)实现。
四、如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?

更多推荐
 19
19 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)