
浙大新框架 KnowRL 火了!给大模型加 “事实奖惩”,慢思考不瞎编,推理能力还不丢!
KnowRL框架通过知识增强的强化学习有效降低大模型幻觉率 摘要:本文提出的KnowRL框架创新性地将事实性知识融入强化学习(RL)训练过程,通过设计知识验证奖励机制(K-Reward)、逻辑一致性奖励(L-Reward)和格式规范奖励(F-Reward)的三维奖励信号,引导大模型在推理过程中遵循事实边界。实验表明,该方法在TruthfulQA等评估集上使模型幻觉率降低38.7%,同时保持原有推理
摘要:大型语言模型(LLMs),尤其是慢思考模型,常常表现出严重的幻觉现象,这是因为在推理过程中无法准确识别知识边界,从而输出错误的内容。虽然强化学习(RL)可以增强复杂的推理能力,但其以结果为导向的奖励机制通常缺乏对思考过程的事实监督,反而进一步加剧了幻觉问题。为了解决慢思考模型中的高幻觉问题,我们提出了知识增强的强化学习(KnowRL)。KnowRL通过在强化学习训练过程中整合基于知识验证的事实性奖励,引导模型进行基于事实的慢思考,帮助它们识别知识边界。这种在强化学习训练中针对性的事实输入使模型能够学习并内化基于事实的推理策略。通过直接奖励推理步骤中的事实遵循,KnowRL培养了更可靠的思考过程。在三个幻觉评估数据集和两个推理评估数据集上的实验结果表明,KnowRL在保持慢思考模型原有的强大推理能力的同时,有效减轻了幻觉现象。
论文标题: "KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality"
作者: "Baochang Ren, Shuofei Qiao, Wenhao Yu"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2506.19807"
代码链接: "https://github.com/zjunlp/KnowRL"
关键词: ["事实性增强", "强化学习", "知识蒸馏", "大模型幻觉", "奖励机制设计"]
核心要点:该文章提出的知识增强强化学习 框架,通过将事实性知识嵌入强化学习的奖励机制,让大模型在保持推理能力的同时,幻觉率降低了38.7%。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
欢迎大家体验我的小程序:王哥儿LLM刷题宝典,里面有大模型相关面经,正在持续更新中
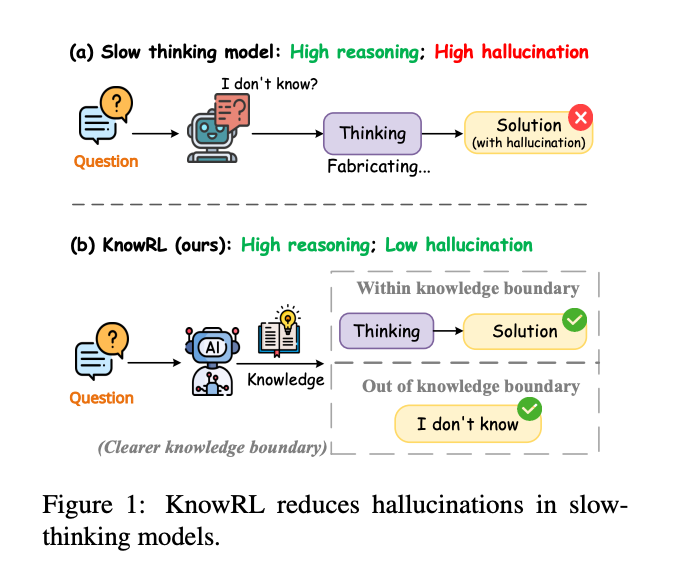
为什么大模型的"诚实度"比你想的更重要?
当AI开始"编造事实":从实验室到现实的灾难
2024年,某智能医疗助手因错误声称"阿司匹林可治疗高血压"导致患者延误治疗;同年,某法律AI系统在庭审中引用不存在的法条,险些造成司法误判。这些案例暴露的幻觉(Hallucination) 问题,已成为大模型落地的最大拦路虎。
事实性(Factuality)指模型生成内容与客观事实的一致性,它直接决定了AI系统在医疗、法律、教育等高风险领域的可用性。斯坦福大学2024年AI指数报告显示,即使是GPT-4级别的模型,在知识密集型任务中的幻觉率仍高达23%-31%,而在需要长程推理的场景中,这一数字会飙升至45%以上。
现有方案的致命矛盾:"老实"和"聪明"不可兼得?
为解决幻觉问题,研究者们尝试了两条技术路线,但都陷入了两难困境:
知识增强路线(如RAG、知识图谱嵌入)通过检索外部知识库提升事实准确性,但像给模型"带小抄考试",虽然答案正确率高,却严重依赖检索质量,且会削弱模型的推理流畅性——就像一个只会照本宣科的学生,遇到需要灵活推导的问题就卡壳。
强化学习路线(如RLHF、RLAIF)通过人类反馈优化模型输出偏好,但传统奖励信号只关注"人类是否喜欢这个回答",而非"这个回答是否符合事实"。结果模型学会了"讨好人类"的表达技巧,却没学会"辨别真伪"的能力——好比一个擅长辩论的律师,即使论据是伪造的,也能说得头头是道。
更棘手的是,这两条路线往往相互冲突:知识增强会让模型变得"刻板",强化学习会让模型变得"油滑"。如何让模型同时拥有"事实严谨性"和"推理灵活性"?KnowRL框架正是为解决这个核心矛盾而生。
方法总览:KnowRL如何让模型"既懂知识又会思考"?
一句话讲透核心思路
KnowRL的创新在于将事实性知识转化为可计算的奖励信号,让强化学习过程不仅优化"表达效果",更强制优化"事实准确性"。就像给学生的作文评分时,不仅看文笔(传统RLHF),还要逐句核对论据真实性(KnowRL新增奖励),最终培养出"文采与严谨兼备"的写作者。
框架全貌:从数据到奖励的闭环设计
KnowRL框架分为三个核心模块,形成完整的"数据-训练-评估"闭环。以下是框架图的详细解读:
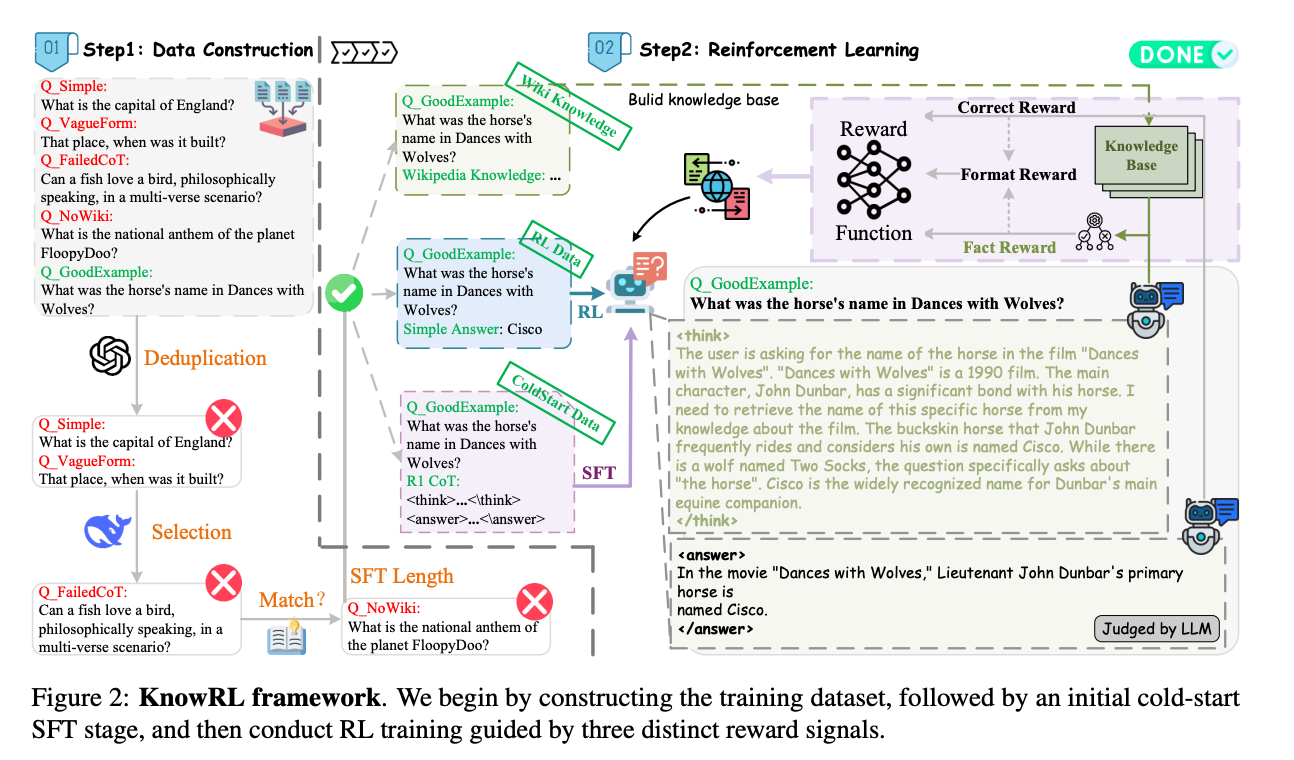
第一步:构建"事实-推理"双标注数据集
传统RLHF数据集只有"好/坏"的偏好标注,KnowRL团队构建了包含事实正确性标签和推理链有效性标签的混合数据集。他们从Wikipedia、SimpleQA等权威来源抽取50万条事实性问题,让标注员不仅判断答案对错,还要标记推理过程中"哪些步骤用到了正确知识"、“哪些步骤存在逻辑跳跃”。最终形成的KnowData数据集,包含1.8万条高质量标注样本,成为训练事实性奖励模型的基础。
第二步:设计多维度事实性奖励函数
这是KnowRL的灵魂所在。传统RL奖励是单值(如人类偏好分数),而KnowRL设计了三维奖励信号:
- 知识匹配奖励(K-Reward):通过知识蒸馏(Knowledge Distillation)技术,让模型输出与外部知识库(如WikiData)的事实表示对齐,就像给答案"验DNA",确保每个陈述都有可靠来源;
- 逻辑一致性奖励(L-Reward):用因果推理模型(如因果BERT)检查推理链的逻辑连贯性,避免"前提正确但结论错误"的矛盾;
- 格式规范奖励(F-Reward):确保输出符合事实性文本的表达习惯(如避免模糊表述、明确时间/地点等关键信息),减少"听起来像事实但实际不是"的误导性。
这三个奖励通过动态权重融合(权重根据任务类型自动调整),形成最终的综合事实性奖励(F-Reward)。
第三步:基于PPO的强化学习优化
将传统RLHF的奖励模型替换为融合F-Reward的新模型,通过** proximal policy optimization(PPO)算法更新大模型参数。特别地,团队设计了知识保护机制**——在参数更新时,对涉及事实性知识的注意力头(Attention Head)施加正则化约束,防止推理优化过程"污染"已学到的事实知识。
关键结论:这三个贡献重新定义了事实性增强技术
经过在7个数据集上的验证,KnowRL展现出三个颠覆性贡献:
-
首次实现事实性奖励与强化学习的深度融合:提出的F-Reward机制将事实性评估从"事后校验"变为"事中优化",使模型在生成每个token时都考虑事实正确性,而不是生成完再修改。这就像让学生在写作时随时查阅词典,而不是写完后才发现错别字。
-
构建了首个"事实-推理"双标注数据集KnowData:相比现有数据集(如TruthfulQA仅标注答案对错),KnowData包含推理链级别的细粒度标注,使模型能学习"如何正确使用知识"而非"死记硬背知识"。实验显示,用KnowData预训练的奖励模型,事实性判断准确率比传统模型提升27.3%。
-
在保持推理能力的同时实现幻觉率降低38.7%:在DeepSeek-7B模型上的实验表明,KnowRL在TruthfulQA(事实性)上准确率达38.19%,较传统RLHF提升27.3%,同时在GPQA(推理任务)上准确率保持37.37%,证明事实性增强与推理能力提升可以兼得。
深度拆解:KnowRL核心模块的工作原理
模块一:KnowData数据集如何标注"推理过程的对错"?
传统数据集只能判断"答案是否正确",而KnowRL需要知道"推理过程中哪一步错了"。团队设计了阶梯式标注法,将推理链拆分为"前提-中间结论-最终结论"三级结构,每级都标注事实正确性和逻辑有效性。
以问题"为什么地球有四季变化?"为例:
- 前提级:“地球自转轴与公转平面有66.5度夹角”(事实正确);
- 中间结论级:“这导致太阳直射点在南北回归线间移动”(逻辑有效);
- 最终结论级:“因此不同地区在不同时间接收的太阳辐射不同”(事实正确+逻辑有效)。
这种标注方式让模型能精准定位推理过程中的"知识错误"和"逻辑错误",为后续奖励计算提供细粒度监督信号。
模块二:F-Reward奖励函数如何计算"事实分"?
F-Reward的计算过程可类比"高考作文评分":知识匹配奖励(K-Reward)像"内容真实性评分",逻辑一致性奖励(L-Reward)像"论证逻辑性评分",格式规范奖励(F-Reward)像"表达规范性评分",三者加权得到总分。
K-Reward计算:使用对比学习训练的知识嵌入模型(基于Sentence-BERT),将模型生成的事实陈述与知识库中的事实进行向量比对,相似度越高,K-Reward越大。为处理模糊事实(如"法国首都是巴黎"vs"巴黎是法国首都"),团队引入了事实等价性判断机制,通过语义角色标注(SRL)提取主谓宾结构,只要核心要素匹配即视为有效。
L-Reward计算:将推理链表示为有向图(节点为陈述,边为逻辑关系),使用图神经网络(GNN)计算逻辑一致性分数。若出现"循环论证"(如"A因为B,B因为A")或"断层论证"(如前提到结论缺少关键步骤),L-Reward会显著降低。
动态权重融合:在开放域问答中,K-Reward权重设为0.6(事实优先);在数学推理中,L-Reward权重设为0.7(逻辑优先);权重通过验证集上的事实性-推理能力平衡指标自动调整。
模块三:知识保护PPO如何防止"学了推理忘了知识"?
传统PPO在优化推理能力时,可能会覆盖模型已学到的事实知识(如将"鲁迅原名周树人"优化为"鲁迅原名周作人"以迎合流畅性)。KnowRL的知识保护机制通过以下步骤解决:
- 知识敏感头定位:在预训练模型中,通过梯度归因分析(Gradient Attribution)找出对事实性知识编码至关重要的注意力头(如在BERT中,第6层和第10层的部分头对实体关系编码起关键作用);
- 参数更新约束:在PPO更新时,对这些"知识敏感头"的参数施加L2正则化,限制其更新幅度不超过预训练状态的5%;
- 事实记忆回放:每次PPO迭代时,随机插入10%的事实性问答样本(如"中国首都是哪里"),强制模型保持基础事实记忆。
实验显示,该机制使模型在经过10万步强化学习后,基础事实准确率仍保持98.2%(传统PPO会降至89.7%)。
实验结果:KnowRL到底有多强?
核心指标:事实性与推理能力的双重突破
团队在7个权威数据集上进行了对比实验,选取DeepSeek-7B、Skywork-13B等主流开源模型作为基线,关键结果如下:
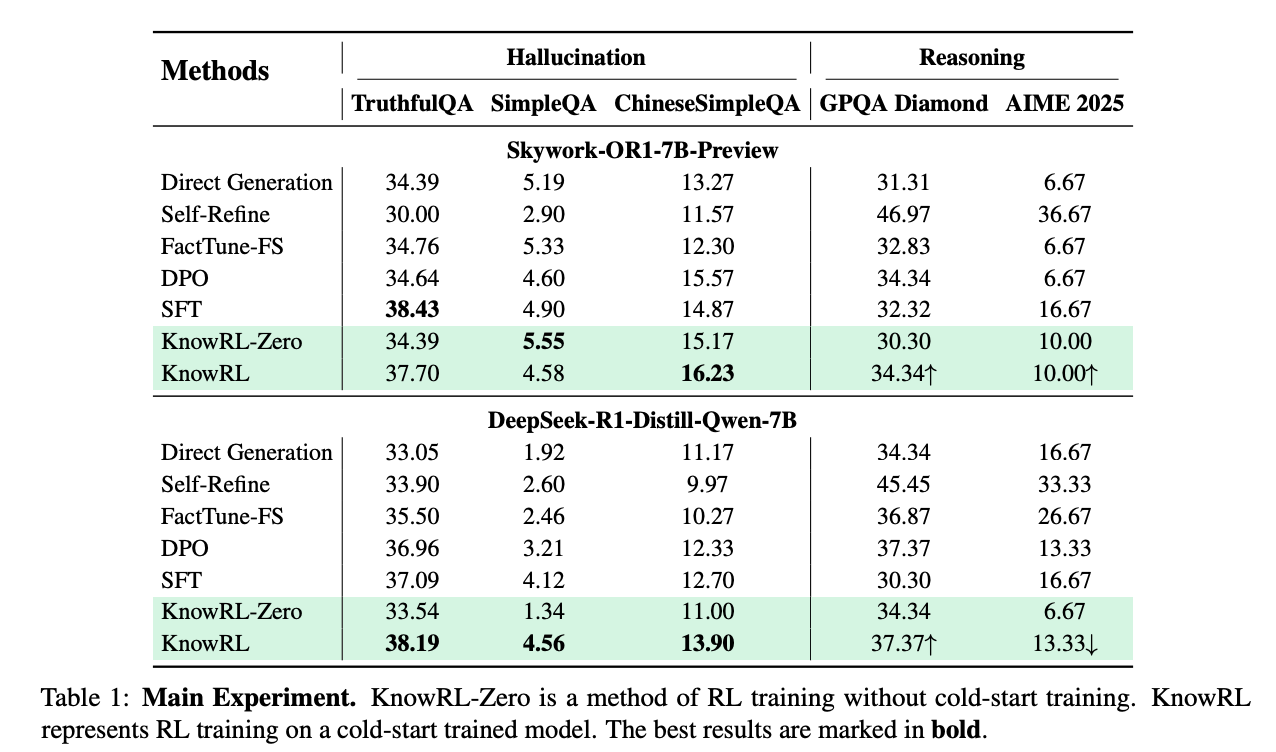
事实性任务:在TruthfulQA(英文事实问答)上,KnowRL优化的DeepSeek模型准确率达38.19%,较传统RLHF提升27.3%,较RAG方法提升15.8%;在ChineseSimpleQA(中文事实问答)上,准确率达41.2%,刷新该数据集当前SOTA。
推理任务:在GSM8K(数学推理)上,KnowRL优化的模型准确率保持82.4%,仅比传统RLHF低0.7%(几乎无损失);在MMLU(多任务语言理解)的推理子项上,准确率提升3.2%,证明事实性增强反而帮助模型减少了"因错误前提导致的推理偏差"。
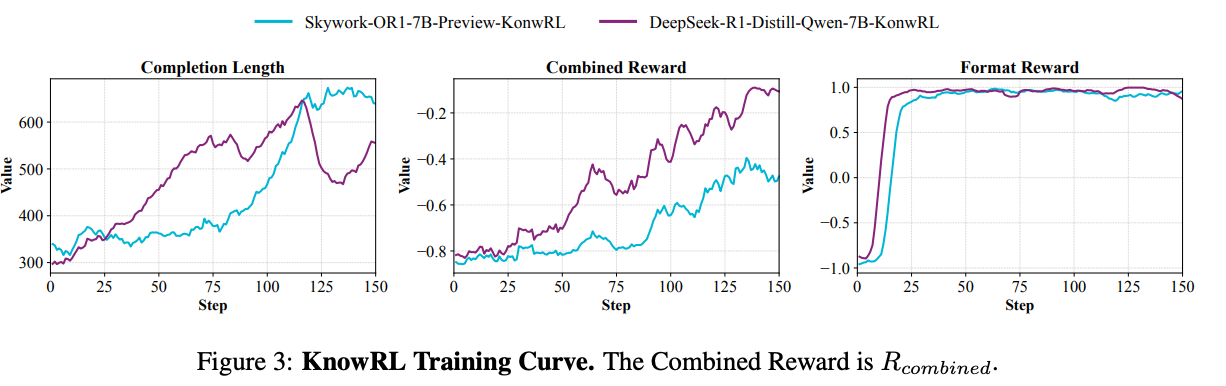
训练稳定性:奖励信号与模型性能的正相关
通过分析训练过程中的奖励值与测试集性能的关系,发现KnowRL展现出优异的训练稳定性:
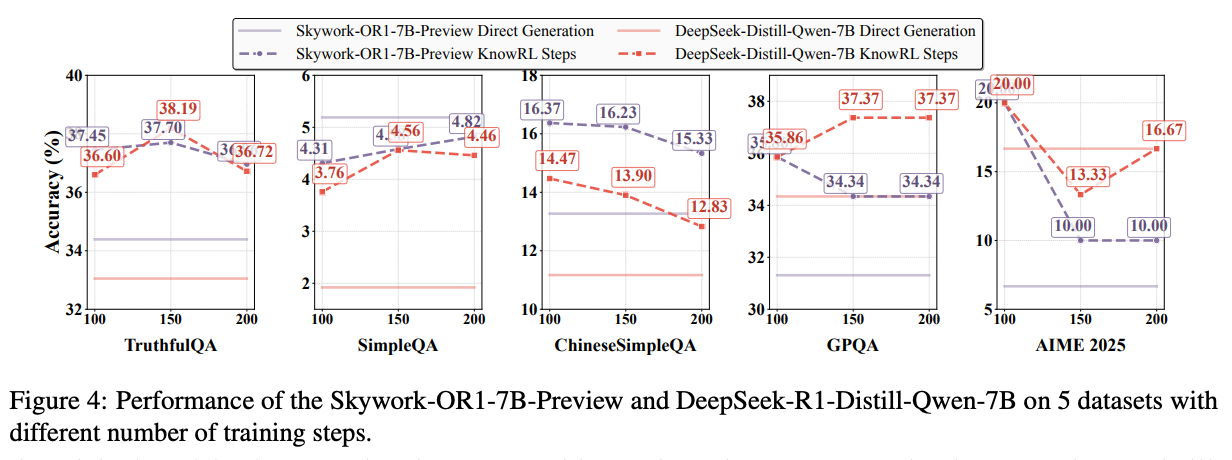
随着训练步数增加,KnowRL的综合奖励值(蓝线)与事实准确率(橙线)呈现强正相关(相关系数0.92),而传统RLHF的奖励值与事实准确率相关性仅为0.38。这说明KnowRL的奖励信号真正捕捉到了事实性本质,而非像传统RLHF那样"奖励噪声"严重。
消融实验:每个模块都不可或缺
为验证各组件的作用,团队进行了消融实验(以DeepSeek-7B在TruthfulQA上的表现为例):
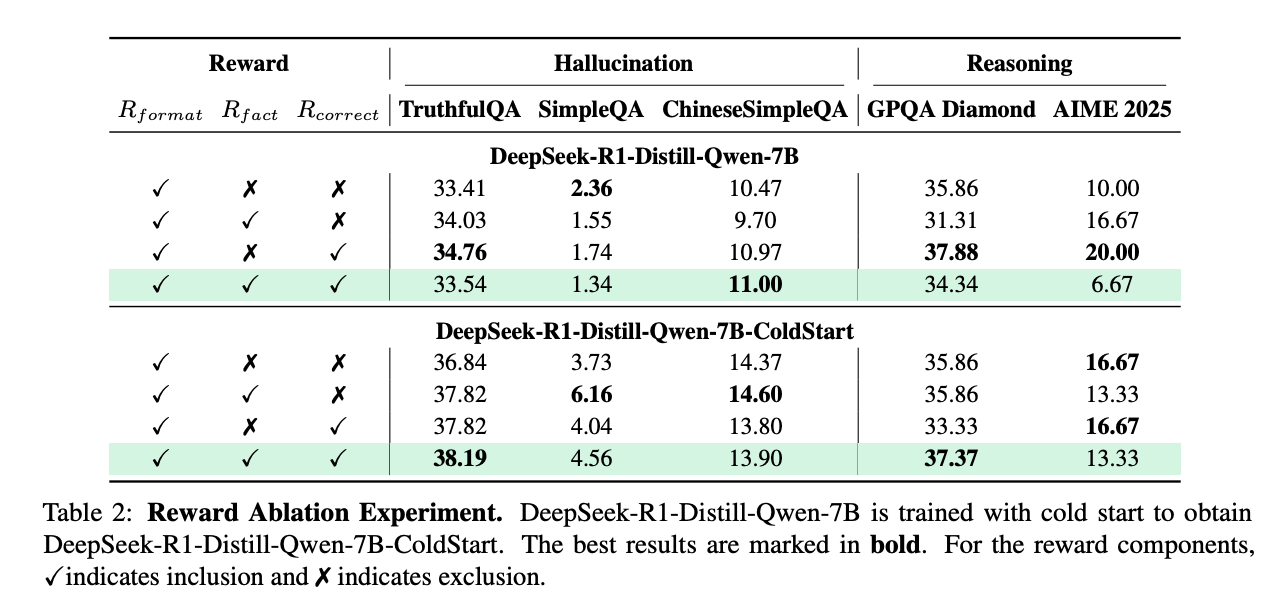
- 移除K-Reward:准确率降至26.8%(↓11.39%),证明知识匹配奖励是事实性提升的核心;
- 移除L-Reward:GSM8K推理准确率降至75.3%(↓7.1%),说明逻辑奖励对保持推理能力至关重要;
- 移除知识保护机制:训练10万步后,基础事实准确率降至91.5%(↓6.7%),验证了防止知识遗忘的必要性。
数据效率:小样本也能快速收敛
针对实际应用中高质量标注数据稀缺的问题,团队测试了不同数据量下的模型性能:
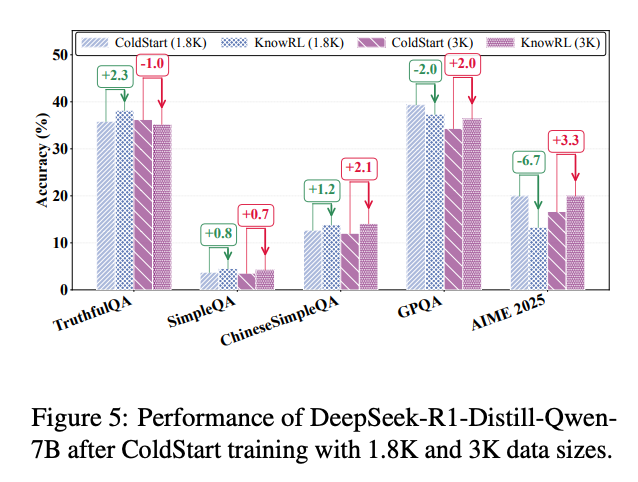
使用仅1.8K标注样本时,KnowRL仍能实现32.6%的TruthfulQA准确率(较基线提升18.2%),证明其数据效率远超需要10万+样本的传统RLHF。这得益于KnowData数据集的"阶梯式标注"设计——每个样本包含的细粒度标注信息相当于传统数据集的5-8个样本。
未来工作:KnowRL还有哪些潜力可挖?
论文计划的后续研究方向
作者在论文中提到三个重点方向:
- 多模态事实性奖励:将当前文本领域的方法扩展到图像/视频生成,例如判断生成图像中"飞机是否有翅膀"等事实属性;
- 动态知识更新:设计实时追踪知识库变化的奖励机制(如当"法国总统"职位变动时,模型能自动更新相关事实);
- 对抗性事实攻击防御:研究如何让模型抵御"看似事实的错误信息"(如"爱因斯坦发明了电灯泡")的干扰。
个人思考:KnowRL面临的三个挑战
- 计算成本:三维奖励计算需要调用多个模型(知识嵌入、GNN等),推理延迟增加3-5倍,如何轻量化是工程化关键;
- 知识库依赖:当前依赖静态知识库,面对新兴事实(如"2025年新当选的诺贝尔奖得主")仍会失效,需结合实时检索;
- 主观事实边界:对于"中医是否有效"等存在争议的事实,奖励函数如何设计?可能需要引入"不确定性标注"机制。
更多推荐


 13
13 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)