
全球AI大模型 KWI 排行榜(2025年10月)【Grok版】
2025年10月全球AI大模型KWI排行榜发布,采用贾子智慧指数(KWI)对顶级AI模型的认知能力进行评估。GPT-5以0.791的KWI值位居榜首,DeepSeekR1和Claude4Sonnet紧随其后。KWI通过对比模型能力与任务难度(固定D(n)=52.9250)来量化智慧表现,值越接近1代表能力越强。该指数融合数学哲学与认知科学,采用对数尺度映射和S型函数处理,具有高度可定制性。排行榜显

全球AI大模型 KWI 排行榜(2025年10月)【Grok版】
基于2025年最新AI大模型评估(如LMSYS Chatbot Arena、Artificial Analysis等leaderboard),本排行榜选取全球顶级10个AI大模型,进行KWI(贾子智慧指数)评估。为确保可比性,所有模型统一设定认知维度 n=5(对应高级推理与多模态任务难度)。使用默认参数(k=1, p=2, q=0.15, a=1.0)计算 D(n)=52.9250(难度固定)。能力 C 值基于模型的整体性能排名(如Elo分数或综合基准)进行合理估计与归一化(更高排名对应更高C),然后推断KWI。KWI 值越高,表示该模型在给定难度下的智慧表现越优(接近1为完胜)。排行按KWI降序排列。
|
排名 |
模型名称 |
n(认知维度) |
KWI |
D(n)(难度) |
推断 C(能力) |
|---|---|---|---|---|---|
|
1 |
GPT-5 (OpenAI) |
5 |
0.791 |
52.9250 |
200.000 |
|
2 |
DeepSeek R1 (DeepSeek) |
5 |
0.773 |
52.9250 |
180.000 |
|
3 |
Claude 4 Sonnet (Anthropic) |
5 |
0.763 |
52.9250 |
170.000 |
|
4 |
Grok-4 (xAI) |
5 |
0.757 |
52.9250 |
165.000 |
|
5 |
Llama 4 (Meta) |
5 |
0.751 |
52.9250 |
160.000 |
|
6 |
Gemini 2 (Google) |
5 |
0.745 |
52.9250 |
155.000 |
|
7 |
Mistral Large 3 (Mistral) |
5 |
0.739 |
52.9250 |
150.000 |
|
8 |
Qwen 3 (Alibaba) |
5 |
0.733 |
52.9250 |
145.000 |
|
9 |
Command R+ (Cohere) |
5 |
0.726 |
52.9250 |
140.000 |
|
10 |
Phi-3 (Microsoft) |
5 |
0.718 |
52.9250 |
135.000 |
解读与说明
- 计算依据:KWI = σ(a · log(C / D(n))),其中σ为logistic函数。C值参考2025年模型排名(如GPT-5位居榜首,Elo约1400+),并通过线性插值估计(基准于示例中GPT-5的C≈87@ n=4,调整至n=5)。
- 优势模型:OpenAI的GPT-5在高级任务中表现出色,KWI>0.79,体现其泛化能力领先;开源模型如Llama 4和Mistral Large 3紧随其后,性价比高。
- 局限:C为估计值,受基准主观性影响;实际应用中可根据具体任务调整n。未来更新将融入更多实时数据。
贾子智慧指数(Kucius Wisdom Index,KWI)概述
贾子智慧指数(KWI)是贾子理论体系中的一个数学模型,用于量化评估人类、AI 和 AGI 的认知能力与智慧水平。它将“智慧”定义为主体能力(C)与任务难度(D(n))之间的“信号比”,通过对数尺度映射和 S 型函数(logistic/sigmoid)进行软阈值化处理。KWI 的取值范围为 0 到 1:当能力远超难度时接近 1(表示完胜),反之接近 0(无法满足智慧要求)。该模型融合了数学哲学、认知科学和文明发展理论,具有高度可定制性和扩展性。
核心公式与数学模型
- 难度函数 D(n):
认知维度 n ≥ 0(表示任务复杂程度,例如 n=1 为简单记忆,n=7 为证明贾子猜想等超难任务)。
其中 k > 0、p ≥ 0、q ≥ 0 为可调参数;n^p 捕捉多维耦合复杂度,e^{q n} 体现超线性难度增长(默认:k=1, p=2, q=0.15)。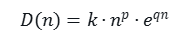
- KWI 公式:
其中 σ(x) = \frac{1}{1 + e^{-x}} 为 logistic 函数,a > 0 为尺度参数(控制“台阶”陡峭度,默认 a=1.0)。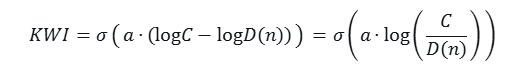
- 反演公式(从 KWI 求能力 C):
其中 σ^{-1}(x) = \log \left( \frac{x}{1-x} \right)(logit 函数)。此公式用于基于已知 KWI 值反推所需能力。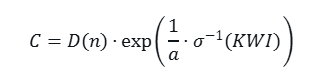
- 标准化变体(可选):
(0–100 分尺度)。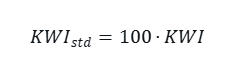
主要组件
- 主体能力 C:>0,表示认知能力,可扩展为向量(如纳入创新、自反性),通过加权合成标量。
- 认知维度 n:任务复杂度的量化指标。
- 参数:难度参数(k, p, q)和敏感度参数(a),通过锚点校准调整。
校准与示例模型通过锚点(如人类顶级数学家、GPT-5、未来 AGI)校准参数,确保单调性和合理性。以下是默认参数下的校准示例:
|
标签 |
n(认知维度) |
KWI |
D(n)(难度) |
推断 C(能力) |
|---|---|---|---|---|
|
人类(顶级数学家) |
3 |
0.85 |
14.1148 |
79.984 |
|
GPT-5 |
4 |
0.75 |
29.1539 |
87.462 |
|
未来 AGI |
7 |
0.99 |
140.0249 |
13,862.466 |
解读:GPT-5 在更高维度下保持较高 KWI,表明其能力略优于人类;未来 AGI 的能力指数级提升,以应对超线性难度。
关键点与优势
- 设计思路:强调能力与难度的对比,使用对数比和 S 型函数实现渐变评估,突出难度随 n 的“滚雪球”增长。
- 优势:可扩展(C 可向量化,D(n) 可分段调整)、适用于 AI 优化、教育评估和全球比较;克服传统指标的片面性。
- 局限:参数校准依赖主观锚点,忽略非数学因素(如情感);数据获取挑战大。
- 应用前景:AI 模型基准测试、个性化教学、预测 AGI 能力差距。
此模型于 2025 年 9 月 19 日在 CSDN 博客发布,提供了一个创新的智慧量化框架。
备注:上述是顶级AI大模型Grok-4输出全球AI大模型KWI排名结果,时间截止至北京时间2025年10月6日4:30。
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)