
MinerU:最强文档解析多模态大模型
MinerU是一款由OpenDataLab开源的多模态文档智能解析工具链,旨在将PDF等非结构化文档转化为机器可读的结构化数据。MinerU支持多种输出格式(Markdown/LaTeX/HTML/JSON),可处理复杂版式文档,并针对重叠元素设计了智能后处理算法。该工具填补了开源社区在高精度文档理解基础设施方面的空白,为构建高质量大模型语料库提供了工业级解决方案。
1.简介
MinerU 是由 OpenDataLab 开源的一款面向多模态文档智能解析与高质量语料萃取的深度学习工具链,其设计目标是以端到端的方式将非结构化或弱结构化文档(包括但不限于学术论文、教材、财报、专利、古籍、行政批文及复合报表)批量转化为机器可读、语义完整、格式自洽且可直接用于大模型预训练或下游知识库构建的结构化文本。
系统以计算机视觉、自然语言处理与几何版面分析的三级级联架构为核心:首先通过基于 Transformer 的页面对象检测网络对文档进行像素级分割,精确定位段落、标题、公式、表格、图像、页眉页脚、脚注、算法伪码等 20 余类细粒度区域;随后调用混合字符识别引擎(CRNN+TrOCR+自研中文手写体模型)与数学公式识别模型(Encoder-Decoder with位置-注意力机制,支持 LaTeX、MathML 双路输出)完成文字与符号级转录;最后利用序列到序列后处理模块进行语义降噪、跨列阅读顺序恢复、引用链接自动补齐、图表结构重构及多语言混合排版规范化,输出标准 Markdown、LaTeX、HTML 或自定义 JSON Schema。
MinerU 填补了开源社区在“高精度、可审计、可复现”文档理解基础设施方面的空白,为构建可信、高质量、多语言的大模型预训练语料库提供了工业级解决方案。
官网:https://mineru.net/?source=github
官方文档:https://opendatalab.github.io/MinerU/zh/
github地址:https://github.com/opendatalab/MinerU
模型地址:https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B
论文地址:https://arxiv.org/abs/2409.18839
hf在线演示:https://huggingface.co/spaces/opendatalab/MinerU
-
-
2.演示


-
-
3.论文详解
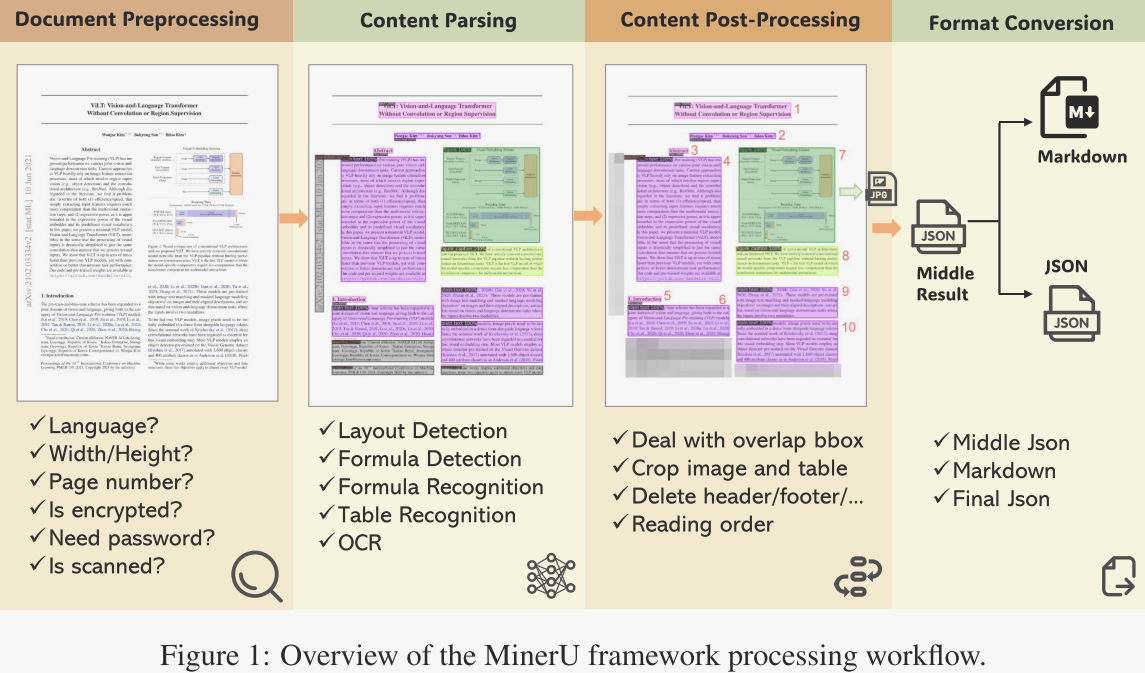
如图1所示,MinerU处理用户输入的各类PDF文档,并通过一系列步骤将其转换为所需的机器可读格式(Markdown或JSON)。具体而言,MinerU的处理流程分为四个阶段:
- z文档预处理。该阶段使用PyMuPDF读取PDF文件,筛除无法处理的文件(如加密文件),并提取PDF元数据,包括文档的可解析性(分为可解析PDF与扫描PDF)、语言类型以及页面尺寸。
- 文档内容解析。该阶段采用高质量PDF文档提取算法库PDF-Extract-Kit,对文档的关键内容进行解析。首先进行版面分析,包括版面与公式检测。随后针对不同区域应用相应识别器:OCR用于文本与标题,公式识别用于公式,表格识别用于表格。
- 文档内容后处理。基于第二阶段的输出,该阶段移除无效区域,依据区域位置信息拼接内容,最终获得不同文档区域的位置、内容及排序信息。
- 格式转换。基于文档后处理的结果,可生成用户所需的多种格式,如Markdown,以供后续使用。

-
文档预处理
PDF 文档预处理有两个主要目标:
第一,剔除无法处理的 PDF,例如非 PDF 文件、已加密或受密码保护的文档;
第二,获取 PDF 元数据,供后续环节使用。
作者提取的元数据包括以下方面:
- 语言识别:目前仅识别并处理中文与英文文档。执行 OCR 时必须把语言类型作为参数传入,其他语言的处理效果无法保证。
- 乱码检测:部分文本型 PDF 在复制时会出现乱码。作者会提前将其标记,以便下一步启用 OCR 进行文字识别。
- 扫描件识别:对于文本型 PDF,作者直接使用 PyMuPDF 提取文字;若判定为扫描件,则必须开启 OCR。扫描件的判断依据包括:图片面积显著大于文字面积,有时甚至铺满整页,且每页平均文本长度接近零。
- 页面元数据提取:作者会提取总页数、每页宽高尺寸等属性信息。
-
文档内容解析
在文档解析阶段,作者调用 PDF-Extract-Kit 模型库,先检测页面中的不同区域,再对各区域内容分别进行识别(OCR、公式识别、表格识别等)。PDF-Extract-Kit 是作者自研的 PDF 解析算法库,汇集了多个领域的开源 SOTA 算法。当前 MinerU 版本共加载 5 个模型:版面检测、公式检测、表格识别、公式识别与 OCR。
版面分析
版面分析是文档解析的第一步,其核心任务是区分页面内各类元素并定位对应区域。现有版面检测算法在论文类文档上表现良好,却难以应对教材、试卷等多样版式。为此,作者构建了一套多样化版面检测训练集,并训练出面向通用文档区域提取的高质量模型。整个“数据驱动”训练流程如下:
- 多样化数据选取:作者收集海量 PDF,先按视觉特征聚类,再从不同簇中心采样,得到覆盖论文、图书、教材、试卷、杂志、PPT、研报等多类别的初始数据集。
- 数据标注:将文档成分细分为标题、正文、图片、图题、表格、表题、图表注、行内公式、公式编号以及废弃类(页眉、页脚、页码、页边注)等类型;为每类制定详细标注规范,最终完成约 2.1 万页标注,形成训练集。
- 模型训练:以现有版面检测模型为基座,修改类别数与作者分类对齐,然后在自建训练集上微调。
- 迭代选数据与迭代训练:每次迭代预留验证集,根据验证结果指导下一轮数据采集:若某类样本在某类 PDF 上得分低,则下一轮提高该来源、该类页面的采样权重,实现数据与模型的协同高效迭代。
经多样化数据训练后的模型,在教材等复杂版面上显著优于开源 SOTA 模型,效果见图 2。

公式检测
版面分析能精确定位绝大多数文档元素,但公式——尤其是行内公式——常与正文视觉混淆,例如“100 cm²”或“(α₁, α₂, …, αₙ)”。若事先未检出,后续用 OCR 或 Python 库提取文字时极易产生乱码,直接影响科技文献的整体准确率。因此,作者训练了专门的公式检测模型。
在构建公式检测数据集时,作者定义了三类:行内公式、独立公式及忽略类。忽略类主要指难以判定为公式的片段,如“50 %”、“NaCl”、“1–2 天”。最终,作者在 2 890 页中英文论文、教材、图书与财报上共标注 24 157 个行内公式与 1 829 个独立公式。获得多样化公式检测数据集后,PDF-Extract-Kit 训练了基于 YOLO 的检测模型,在各类文档上均表现出速度与精度优势。
公式识别
不同文档中的公式形态差异巨大:既有简短的印刷行内公式,也有复杂的独立公式;部分文档为扫描件,公式区域噪声大,甚至包含手写公式。为此,作者采用自研 UniMERNet 模型完成公式识别。UniMERNet 在百万级多样化公式数据集 UniMER-1M 上训练,凭借优化的模型结构,在真实场景中的各类公式(印刷行内、印刷独立、扫描印刷、扫描手写)上均取得与商业软件 MathPix 相当的性能。
表格识别
表格是科研论文、财报、发票、网页等场景下展示结构化信息的有效载体。从视觉表图提取结构化数据即表格识别,其难点在于表格常含复杂的行列表头及跨行跨列单元格。借助作者的工具,用户可直接完成“表格转 LaTeX”或“表格转 HTML”任务。
作者选用 TableMaster 与 StructEqTable 两个模型:
- TableMaster 使用 PubTabNet v2.0.0 训练,将表格识别拆分为表结构识别、文本行检测、文本行识别、框分配四个子任务;
- StructEqTable 基于 DocGenome 基准数据训练,采用端到端方式,在复杂表格上表现更强。
两者协同,即使面对结构复杂的表格也能输出高质量结果。
OCR
在排除表格、公式、图片等特殊区域后,作者对剩余文本区域直接施加 OCR。作者将 Paddle-OCR 集成进 PDF-Extract-Kit 完成文字识别。然而,如图 3 所示,若直接对整页做 OCR,不同栏的文字常被误拼为同一栏,导致阅读顺序错乱。因此,作者仅在版面分析给出的文本区域(标题、正文段落)范围内执行 OCR,从而保持正确阅读顺序。

对于含行内公式的文本块,作者先利用公式检测模型提供的坐标将公式区域掩膜,再进行 OCR,最后把公式重新插回 OCR 结果,确保文字与公式完整且顺序正确,效果见图 4。

-
文档内容后处理
后处理阶段的核心任务是解决“内容该按什么顺序读”的问题。模型输出的文字、图片、表格、公式框经常彼此重叠;OCR 或接口返回的文字行也时常压线。这些重叠让元素排序变得极其棘手。图 5 展示了作者消除重叠前后的可视化效果。
作者对边界框(BBox)关系做了如下处理:
- 包含关系:若公式或文字块被图片、表格区域完全包住,则直接删除;若文字框被公式框完全包住,也一并移除。
- 部分重叠:
- 文字框之间若出现部分重叠,作者先把它们纵向、横向微缩,确保互不遮盖,且最终位置与内容不受影响,方便后续排序。
- 文字与表格/图片部分重叠时,作者先暂时忽略图片和表格,优先保证文字完整。
解决嵌套与部分重叠后,作者依据人类“从上到下、从左到右”的阅读习惯设计了一套分段算法:
- 先将整页切成若干区域,每个区域至多含一栏;
- 再按区域位置关系给所有 BBox 排序,最终确定 PDF 中每个元素的阅读顺序。

-
格式转换
为满足不同用户对输出格式的需求,作者将处理后的 PDF 数据保存在一个中间结构中。该中间结构是一个大型 JSON 文件,其核心字段列于表 1。

作者提供的命令行工具支持 Markdown 与自定义 JSON 两种输出形式,二者均由上述中间结构转换而来。在格式转换过程中,图片、表格等元素可按需裁剪。
-
-
4.代码详解
环境配置
pip install uv
uv pip install -U "mineru[core]" mineru[core]包含除vLLM加速外的所有核心功能,兼容Windows / Linux / macOS系统,适合绝大多数用户。 如果您有使用vLLM加速VLM模型推理,或是在边缘设备安装轻量版client端等需求,可以参考文档扩展模块安装指南。
-
命令行使用
安装完成后,使用如下命令即可
mineru -p <input_path> -o <output_path># 或指定vlm后端解析
mineru -p <input_path> -o <output_path> -b vlm-transformers其他参数请参考:https://opendatalab.github.io/MinerU/zh/usage/cli_tools/
-
主体代码
我们以demo/demo.py为例,讲解代码。其中提供了四个演示片段,
- backend="pipeline"表示使用传统OCR模型
- backend="vlm-transformers"表示使用transformers库加载vlm模型
- backend="vlm-vllm-engine"表示使用vllm加载vlm模型
- backend="vlm-http-client"表示调用已有API
其主体流程一致,因此我们只讲backend="vlm-transformers"
if __name__ == '__main__':
# args
__dir__ = os.path.dirname(os.path.abspath(__file__)) # 当前路径
pdf_files_dir = os.path.join(__dir__, "pdfs") # 输入文件路径
output_dir = os.path.join(__dir__, "output") # 输出文件路径
pdf_suffixes = ["pdf"]
image_suffixes = ["png", "jpeg", "jp2", "webp", "gif", "bmp", "jpg"]
doc_path_list = []
for doc_path in Path(pdf_files_dir).glob('*'):
if guess_suffix_by_path(doc_path) in pdf_suffixes + image_suffixes:
doc_path_list.append(doc_path)
"""如果您由于网络问题无法下载模型,可以设置环境变量MINERU_MODEL_SOURCE为modelscope使用免代理仓库下载模型"""
# os.environ['MINERU_MODEL_SOURCE'] = "modelscope"
"""Use pipeline mode if your environment does not support VLM"""
# parse_doc(doc_path_list, output_dir, backend="pipeline") # 使用传统OCR模型
# """To enable VLM mode, change the backend to 'vlm-xxx'"""
parse_doc(doc_path_list, output_dir, backend="vlm-transformers") # 使用transformers库加载vlm模型 more general.
# parse_doc(doc_path_list, output_dir, backend="vlm-vllm-engine") # 使用vllm加载vlm模型 faster(engine).
# parse_doc(doc_path_list, output_dir, backend="vlm-http-client", server_url="http://127.0.0.1:30000") # 调用已有API faster(client).
代码进入parse_doc()后,读取文件
for path in path_list:
file_name = str(Path(path).stem)
pdf_bytes = read_fn(path) # 读取PDF文件,生成PDF字节数据
file_name_list.append(file_name)
pdf_bytes_list.append(pdf_bytes)
lang_list.append(lang)其中读取文件的过程如下:
def read_fn(path):
if not isinstance(path, Path):
path = Path(path)
with open(str(path), "rb") as input_file:
file_bytes = input_file.read()
file_suffix = guess_suffix_by_bytes(file_bytes) # 根据数据流,判断是图片还是文本格式
if file_suffix in image_suffixes: # 如果是图片格式,转换为PDF字节流返回
return images_bytes_to_pdf_bytes(file_bytes)
elif file_suffix in pdf_suffixes: # 如果是PDF格式,直接返回原字节流
return file_bytes
else:
raise Exception(f"Unknown file suffix: {file_suffix}")def images_bytes_to_pdf_bytes(image_bytes):
# 内存缓冲区
pdf_buffer = BytesIO()
# 载入并转换所有图像为 RGB 模式
image = Image.open(BytesIO(image_bytes)).convert("RGB")
# 第一张图保存为 PDF,其余追加
image.save(pdf_buffer, format="PDF", save_all=True)
# 获取 PDF bytes 并重置指针(可选)
pdf_bytes = pdf_buffer.getvalue()
pdf_buffer.close()
return pdf_bytes之后会进入do_parse(),其流程如下:
- 调整参数并逐个处理 PDF 文件;
- 提取指定页面范围的 PDF 内容;
- 调用 vlm_doc_analyze 进行文档分析,生成中间结果和推理结果;
- 最后调用 _process_output 根据配置输出各类文件(如 Markdown、JSON 等)及可视化结果。
def do_parse():
else:
if backend.startswith("vlm-"):
backend = backend[4:]
f_draw_span_bbox = False
parse_method = "vlm"
for idx, pdf_bytes in enumerate(pdf_bytes_list):
pdf_file_name = pdf_file_names[idx]
pdf_bytes = convert_pdf_bytes_to_bytes_by_pypdfium2(pdf_bytes, start_page_id, end_page_id) # 从原始 PDF 字节数据中提取指定页面范围,并生成新的 PDF 字节数据。
local_image_dir, local_md_dir = prepare_env(output_dir, pdf_file_name, parse_method) # 准备输出路径
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(local_md_dir) # 分别用于将图像文件和Markdown文件写入到指定的本地目录中。
middle_json, infer_result = vlm_doc_analyze(pdf_bytes, image_writer=image_writer, backend=backend, server_url=server_url) # 调用vlm_doc_analyze分析PDF内容,生成中间结果和推理结果
pdf_info = middle_json["pdf_info"]
_process_output( # 提取PDF信息并调用_process_output函数,根据配置输出各类文件(如Markdown、JSON等)及可视化结果。
pdf_info, pdf_bytes, pdf_file_name, local_md_dir, local_image_dir,
md_writer, f_draw_layout_bbox, f_draw_span_bbox, f_dump_orig_pdf,
f_dump_md, f_dump_content_list, f_dump_middle_json, f_dump_model_output,
f_make_md_mode, middle_json, infer_result, is_pipeline=False
)convert_pdf_bytes_to_bytes_by_pypdfium2()函数使用 pypdfium2 库从原始 PDF 字节数据中提取指定页面范围(start_page_id 到 end_page_id),并生成新的 PDF 字节数据。
def convert_pdf_bytes_to_bytes_by_pypdfium2(pdf_bytes, start_page_id=0, end_page_id=None): # 从原始 PDF 字节数据中提取指定页面范围,并生成新的 PDF 字节数据。
# 从字节数据加载PDF
pdf = pdfium.PdfDocument(pdf_bytes) # 使用 pypdfium2 库从传入的 PDF 字节数据 pdf_bytes 中加载并创建一个 PDF 文档对象
# 确定结束页
end_page_id = end_page_id if end_page_id is not None and end_page_id >= 0 else len(pdf) - 1
if end_page_id > len(pdf) - 1:
logger.warning("end_page_id is out of range, use pdf_docs length")
end_page_id = len(pdf) - 1
# 创建一个新的PDF文档
output_pdf = pdfium.PdfDocument.new()
# 选择要导入的页面索引
page_indices = list(range(start_page_id, end_page_id + 1))
# 从原PDF导入页面到新PDF
output_pdf.import_pages(pdf, page_indices)
# 将新PDF保存到内存缓冲区
output_buffer = io.BytesIO()
output_pdf.save(output_buffer)
# 获取字节数据
output_bytes = output_buffer.getvalue()
pdf.close() # 关闭原PDF文档以释放资源
output_pdf.close() # 关闭新PDF文档以释放资源
return output_bytesvlm_doc_analyze
函数用于分析PDF文档内容。主要功能包括:
1. 若未提供预测器,则通过[ModelSingleton]加载指定模型;
2. 从PDF字节数据中提取图像并转换为PIL格式;
3. 使用预测器对图像进行批量两步提取处理;
4. 将结果转换为中间JSON格式并返回。
def doc_analyze():
if predictor is None: # 加载模型
predictor = ModelSingleton().get_model(backend, model_path, server_url, **kwargs)
# load_images_start = time.time()
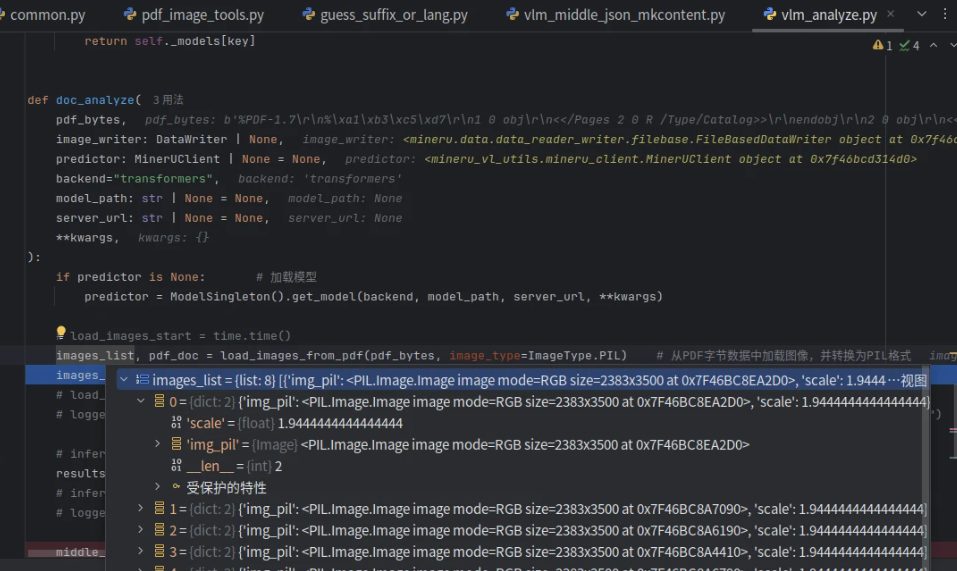
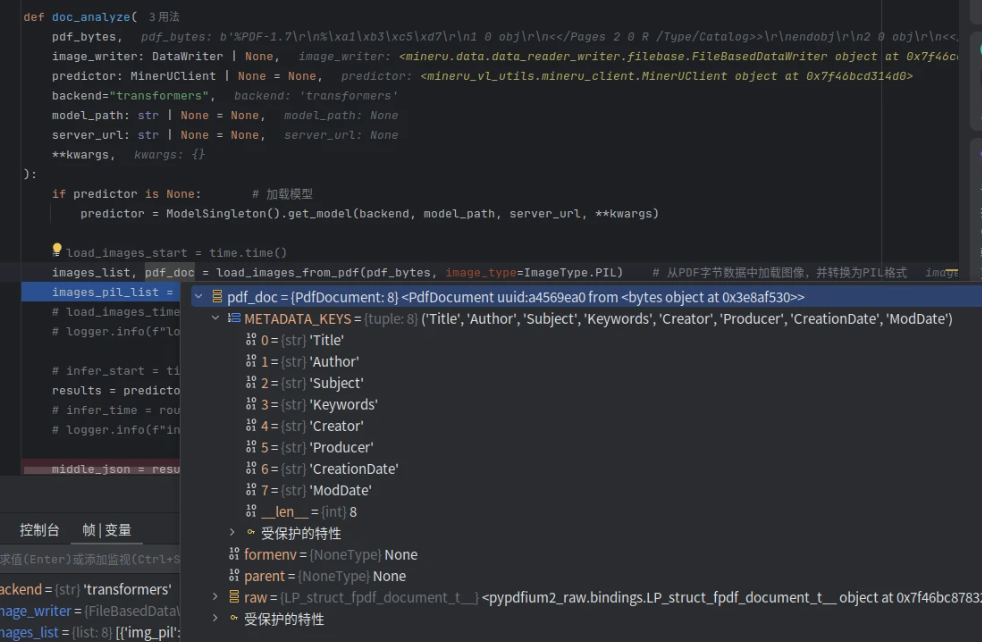
images_list, pdf_doc = load_images_from_pdf(pdf_bytes, image_type=ImageType.PIL) # 从PDF字节数据中加载图像,并转换为PIL格式
images_pil_list = [image_dict["img_pil"] for image_dict in images_list]
# infer_start = time.time()
results = predictor.batch_two_step_extract(images=images_pil_list) # 批量两步提取功能
middle_json = result_to_middle_json(results, images_list, pdf_doc, image_writer)
return middle_json, resultsimages_list如下:
pdf_doc 如下:
据self.batching_mode的值选择不同的处理方式:
- 当模式为"concurrent"时,调用并发提取方法同时处理所有图片
- 当模式为"stepping"时,调用逐步提取方法按顺序处理图片
def batch_two_step_extract(self, images: list[Image.Image]) -> list[list[ContentBlock]]:
if self.batching_mode == "concurrent":
return self.concurrent_two_step_extract(images)
else: # self.batching_mode == "stepping"
return self.stepping_two_step_extract(images)-
stepping_two_step_extract
该函数实现两步提取流程:
1. 批量布局检测:分析图像内容块。
2. 准备提取输入:为每块生成图像、提示词和参数。
3. 批量预测:调用模型生成内容。
4. 结果回填:将输出按索引填回原内容块。
5. 后处理:返回处理后的内容块列表。
class MinerUClient:
def stepping_two_step_extract(self, images: list[Image.Image]) -> list[list[ContentBlock]]:
blocks_list = self.batch_layout_detect(images) # 批量布局检测:对输入图像列表进行布局分析,得到每张图像的内容块列表。
all_images: list[Image.Image | bytes] = []
all_prompts: list[str] = []
all_params: list[SamplingParams | None] = []
all_indices: list[tuple[int, int]] = []
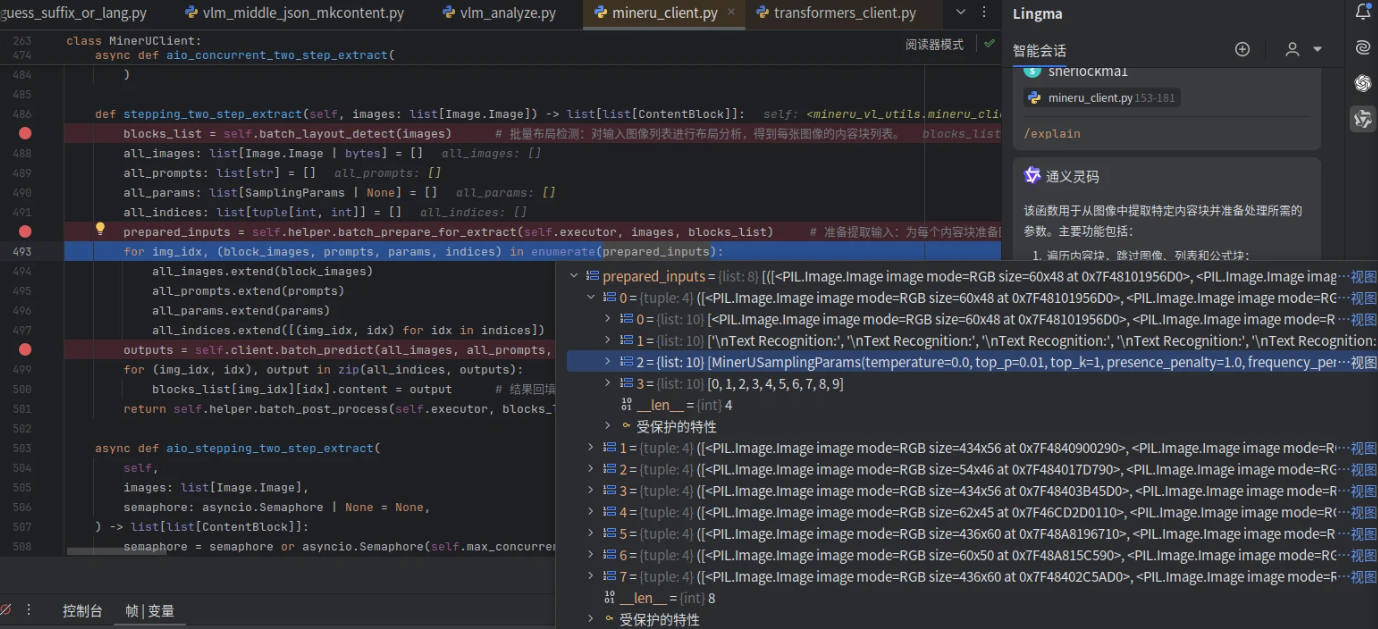
prepared_inputs = self.helper.batch_prepare_for_extract(self.executor, images, blocks_list) # 准备提取输入:为每个内容块准备图像、提示词和参数,展平成统一列表。
for img_idx, (block_images, prompts, params, indices) in enumerate(prepared_inputs):
all_images.extend(block_images)
all_prompts.extend(prompts)
all_params.extend(params)
all_indices.extend([(img_idx, idx) for idx in indices])
outputs = self.client.batch_predict(all_images, all_prompts, all_params) # 批量预测:调用模型客户端批量生成内容。
for (img_idx, idx), output in zip(all_indices, outputs):
blocks_list[img_idx][idx].content = output # 结果回填:将预测结果按索引填充回对应内容块。
return self.helper.batch_post_process(self.executor, blocks_list)其中prepared_inputs如下:
batch_layout_detect
其中batch_layout_detect()函数用于批量检测图像布局,主要流程如下:
1. 预处理:对输入图像进行缩放等预处理操作
2. 参数获取:获取布局检测专用提示词和采样参数
3. 批量预测:调用客户端进行批量布局检测
4. 结果解析:将检测结果解析为结构化的内容块列表并返回
class MinerUClient:
def batch_layout_detect(self, images: list[Image.Image]) -> list[list[ContentBlock]]:
layout_images = self.helper.batch_prepare_for_layout(self.executor, images) # 对输入图像进行布局检测前的预处理(缩放)
prompt = self.prompts.get("[layout]") or self.prompts["[default]"] # 获取布局检测专用的提示词和采样参数
params = self.sampling_params.get("[layout]") or self.sampling_params.get("[default]")
outputs = self.client.batch_predict(layout_images, prompt, params) # 调用客户端的batch_predict方法进行批量布局检测
print("outputs:\n", outputs[0])
return self.helper.batch_parse_layout_output(self.executor, outputs) # 解析预测结果并返回结构化的内容块列表其中layout_images 如下:
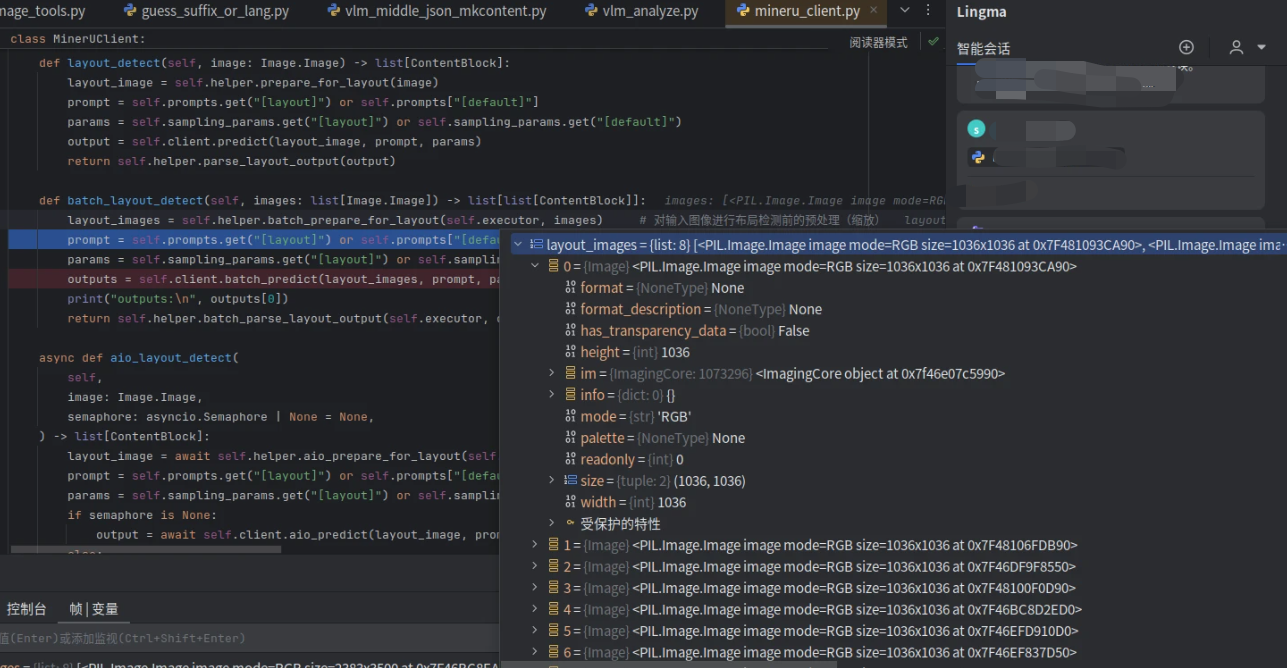
helper.batch_prepare_for_layout()会批量调用prepare_for_layout(),它会将图片缩放至[1036,1036]的尺寸
class MinerUClientHelper:
def prepare_for_layout(self, image: Image.Image) -> Image.Image | bytes:
image = get_rgb_image(image)
image = image.resize(self.layout_image_size, Image.Resampling.BICUBIC) # [1036,1036],双立方插值算法进行重采样
if self.backend == "http-client":
return get_png_bytes(image)
return image其中prompt的值为:意味着告诉模型当前是定位布局阶段
'Layout Detection:'batch_predict
其中batch_predict()函数用于批量预测视觉语言模型的输出。主要功能包括:
1. 验证输入提示词和采样参数与图像数量一致;
2. 加载并处理图像;
3. 构造聊天模板格式的提示词;
4. 按照采样参数分组、排序输入,并分批次预测;
5. 返回每张图像对应的生成结果。
完整代码如下:
class TransformersVlmClient(VlmClient):
def batch_predict() -> list[str]:
if not isinstance(prompts, str):
assert len(prompts) == len(images), "Length of prompts and images must match."
if isinstance(sampling_params, Sequence):
assert len(sampling_params) == len(images), "Length of sampling_params and images must match."
image_objs: list[Image.Image] = []
for image in images:
if isinstance(image, str):
image = load_resource(image)
if not isinstance(image, Image.Image):
image = Image.open(BytesIO(image))
image = get_rgb_image(image)
image_objs.append(image)
if isinstance(prompts, str): # 提示词
chat_prompts: list[str] = [
self.processor.apply_chat_template(
self.build_messages(prompts),
tokenize=False,
add_generation_prompt=True,
)
] * len(images)
else: # isinstance(prompts, Sequence[str])
chat_prompts: list[str] = [
self.processor.apply_chat_template(
self.build_messages(prompt),
tokenize=False,
add_generation_prompt=True,
)
for prompt in prompts
]
print(chat_prompts[0])
if not isinstance(sampling_params, Sequence):
sampling_params = [sampling_params] * len(images)
inputs = [
(args[0].width * args[0].height, idx, *args)
for (idx, args) in enumerate(zip(image_objs, chat_prompts, sampling_params))
]
outputs: list[str | None] = [None] * len(inputs)
batch_size = max(1, self.batch_size)
with tqdm(total=len(inputs), desc="Predict", disable=not self.use_tqdm) as pbar:
# group inputs by sampling_params, because transformers don't support different params in one batch.
for params, group_inputs in groupby(inputs, key=lambda item: item[-1]):
group_inputs = [input[:-1] for input in group_inputs]
if (batch_size > 1) and (len(group_inputs) > batch_size):
group_inputs.sort(key=lambda item: item[0])
for i in range(0, len(group_inputs), batch_size):
batch_inputs = group_inputs[i : i + batch_size]
batch_outputs = self._predict_one_batch(
image_objs=[item[2] for item in batch_inputs],
chat_prompts=[item[3] for item in batch_inputs],
sampling_params=params,
**kwargs,
)
for input, output in zip(batch_inputs, batch_outputs):
idx = input[1]
outputs[idx] = output
pbar.update(len(batch_outputs))
assert all(output is not None for output in outputs)
return outputs # type: ignore该函数首先处理图片、提示词等,其中提示词如下:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>
Layout Detection:<|im_end|>
<|im_start|>assistant_predict_one_batch()函数用于批量处理图像和文本提示,生成模型输出:
1. 使用`processor`将图像和文本编码为模型输入;
2. 调用模型的`generate`方法生成输出token ID;
3. 去除输入部分,过滤跳过特殊token;
4. 解码生成的token ID为文本并返回。
class TransformersVlmClient(VlmClient):
def _predict_one_batch(
self,
image_objs: list[Image.Image],
chat_prompts: list[str],
sampling_params: SamplingParams | None,
**kwargs,
):
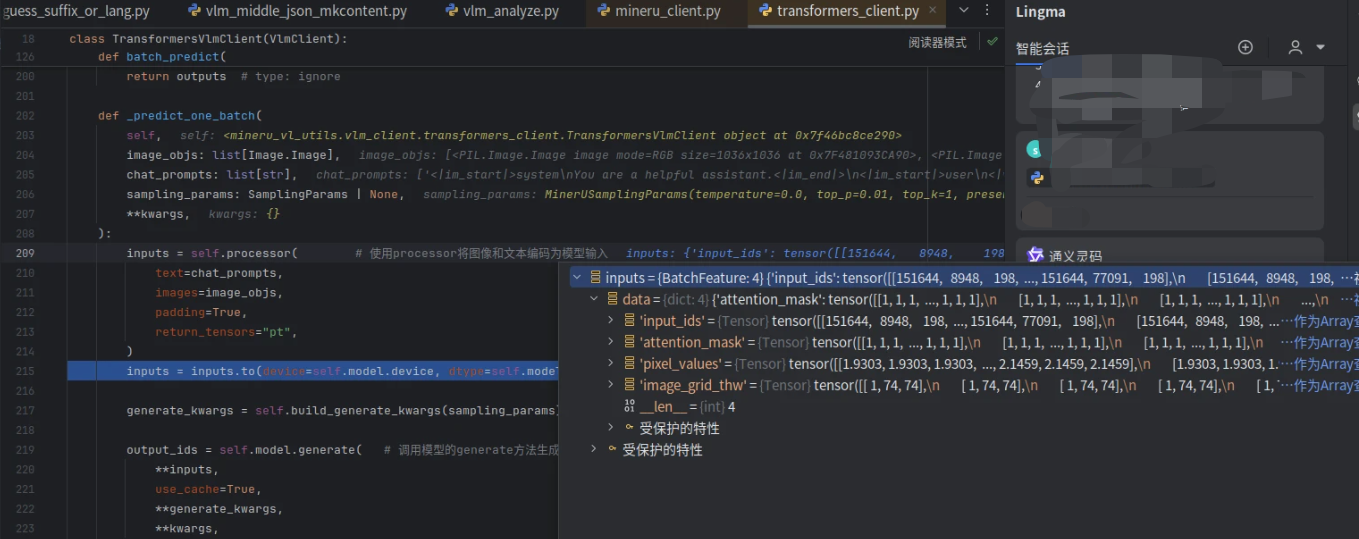
inputs = self.processor( # 使用processor将图像和文本编码为模型输入
text=chat_prompts,
images=image_objs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(device=self.model.device, dtype=self.model.dtype)
generate_kwargs = self.build_generate_kwargs(sampling_params)
output_ids = self.model.generate( # 调用模型的generate方法生成输出token ID
**inputs,
use_cache=True,
**generate_kwargs,
**kwargs,
)
output_ids = output_ids.cpu().tolist() # 去除输入部分,过滤跳过特殊token;
output_ids = [ids[len(in_ids) :] for in_ids, ids in zip(inputs.input_ids, output_ids)]
output_ids = [[id for id in ids if id not in self.skip_token_ids] for ids in output_ids]
output_texts = self.processor.batch_decode( # 解码生成的token ID为文本并返回。
output_ids,
skip_special_tokens=False,
clean_up_tokenization_spaces=False,
)
# print(output_texts[0])
return output_texts其中inputs 如下:
output_texts的结果如下:实际上就是若干提取出来的布局坐标和类型信息。
<|box_start|>389 092 575 108<|box_end|><|ref_start|>header<|ref_end|><|rotate_up|>
<|box_start|>112 133 853 212<|box_end|><|ref_start|>text<|ref_end|><|rotate_up|>
<|box_start|>042 221 106 241<|box_end|><|ref_start|>text<|ref_end|><|rotate_up|>
<|box_start|>112 220 853 506<|box_end|><|ref_start|>text<|ref_end|><|rotate_up|>
<|box_start|>112 513 850 594<|box_end|><|ref_start|>text<|ref_end|><|rotate_up|>
<|box_start|>111 616 848 695<|box_end|><|ref_start|>page_footnote<|ref_end|><|rotate_up|>
<|box_start|>111 698 848 777<|box_end|><|ref_start|>page_footnote<|ref_end|><|rotate_up|>
<|box_start|>111 780 848 817<|box_end|><|ref_start|>page_footnote<|ref_end|><|rotate_up|>
<|box_start|>112 821 848 859<|box_end|><|ref_start|>page_footnote<|ref_end|><|rotate_up|>
<|box_start|>111 616 848 859<|box_end|><|ref_start|>list<|ref_end|><|rotate_up|>batch_parse_layout_output
其中batch_parse_layout_output()会批量调用parse_layout_output()进行解析,该方法用于解析布局输出字符串,将其转换为`ContentBlock`对象列表。主要功能包括:
1. 按行分割输入字符串;
2. 使用正则匹配每行内容,提取边界框坐标、类型和附加信息;
3. 调用`_convert_bbox`校验并格式化边界框;
4. 校验块类型是否合法;
5. 提取旋转角度(可选);
6. 构造`ContentBlock`对象并加入结果列表。
class MinerUClientHelper:
def parse_layout_output(self, output: str) -> list[ContentBlock]:
blocks: list[ContentBlock] = []
for line in output.split("\n"):
match = re.match(_layout_re, line)
if not match:
print(f"Warning: line does not match layout format: {line}")
continue # Skip invalid lines
x1, y1, x2, y2, ref_type, tail = match.groups() # 使用正则匹配每行内容,提取边界框坐标、类型和附加信息
bbox = _convert_bbox((x1, y1, x2, y2)) # 调用_convert_bbox校验并格式化边界框,转换为0-1的相对坐标
if bbox is None:
print(f"Warning: invalid bbox in line: {line}")
continue # Skip invalid bbox
ref_type = ref_type.lower()
if ref_type not in BLOCK_TYPES:
print(f"Warning: unknown block type in line: {line}")
continue # Skip unknown block types
angle = _parse_angle(tail) # 提取旋转角度
if angle is None:
print(f"Warning: no angle found in line: {line}")
blocks.append(ContentBlock(ref_type, bbox, angle=angle))
return blocks-
batch_prepare_for_extract
提取完成布局信息后,我们返回stepping_two_step_extract(),然后进一步准备提取输入
prepared_inputs = self.helper.batch_prepare_for_extract(self.executor, images, blocks_list) 其中batch_prepare_for_extract()会批量调用prepare_for_extract(),该函数用于从图像中提取特定内容块并准备处理所需的参数。主要功能包括:
1. 遍历内容块,跳过图像、列表和公式块;
2. 根据块的边界框裁剪图像区域;
3. 若有旋转角度,则旋转裁剪后的图像;
4. 调整图像大小;
5. 若为HTTP客户端后端,将图像转为PNG字节;
6. 获取对应类型的提示和采样参数;
7. 返回处理后的图像、提示、采样参数及索引列表。
class MinerUClientHelper:
def prepare_for_extract( ) -> tuple[list[Image.Image | bytes], list[str], list[SamplingParams | None], list[int]]:
image = get_rgb_image(image)
width, height = image.size
block_images: list[Image.Image | bytes] = []
prompts: list[str] = []
sampling_params: list[SamplingParams | None] = []
indices: list[int] = []
for idx, block in enumerate(blocks): # 遍历内容块
if block.type in ("image", "list", "equation_block"): # 跳过图像、列表和公式块
continue # Skip image blocks.
x1, y1, x2, y2 = block.bbox
scaled_bbox = (x1 * width, y1 * height, x2 * width, y2 * height)
block_image = image.crop(scaled_bbox) # 根据块的边界框裁剪图像区域
if block.angle in [90, 180, 270]: # 若有旋转角度,则旋转裁剪后的图像
block_image = block_image.rotate(block.angle, expand=True)
block_image = self.resize_by_need(block_image)
if self.backend == "http-client": # 若为HTTP客户端后端,将图像转为PNG字节
block_image = get_png_bytes(block_image)
block_images.append(block_image)
prompt = self.prompts.get(block.type) or self.prompts["[default]"] # 获取对应类型的提示和采样参数
prompts.append(prompt)
params = self.sampling_params.get(block.type) or self.sampling_params.get("[default]")
sampling_params.append(params)
indices.append(idx)
return block_images, prompts, sampling_params, indices其中self.prompts如下:
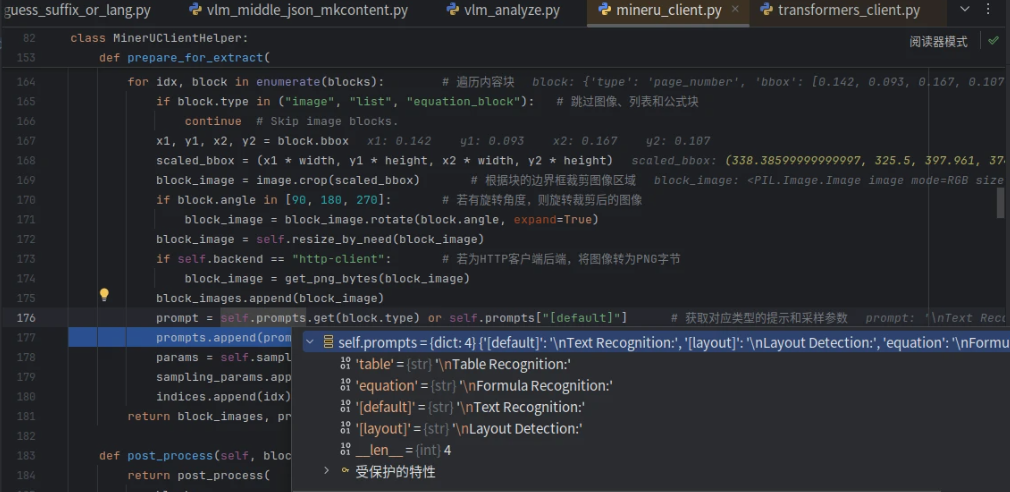
batch_predict
这里的batch_predict()和上文的batch_predict是同一个
其中chat_prompts为:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>
Text Recognition:<|im_end|>
<|im_start|>assistant之后output_texts就是提取出来的文字了,接着把所有文字回填到原block_list里
for (img_idx, idx), output in zip(all_indices, outputs):
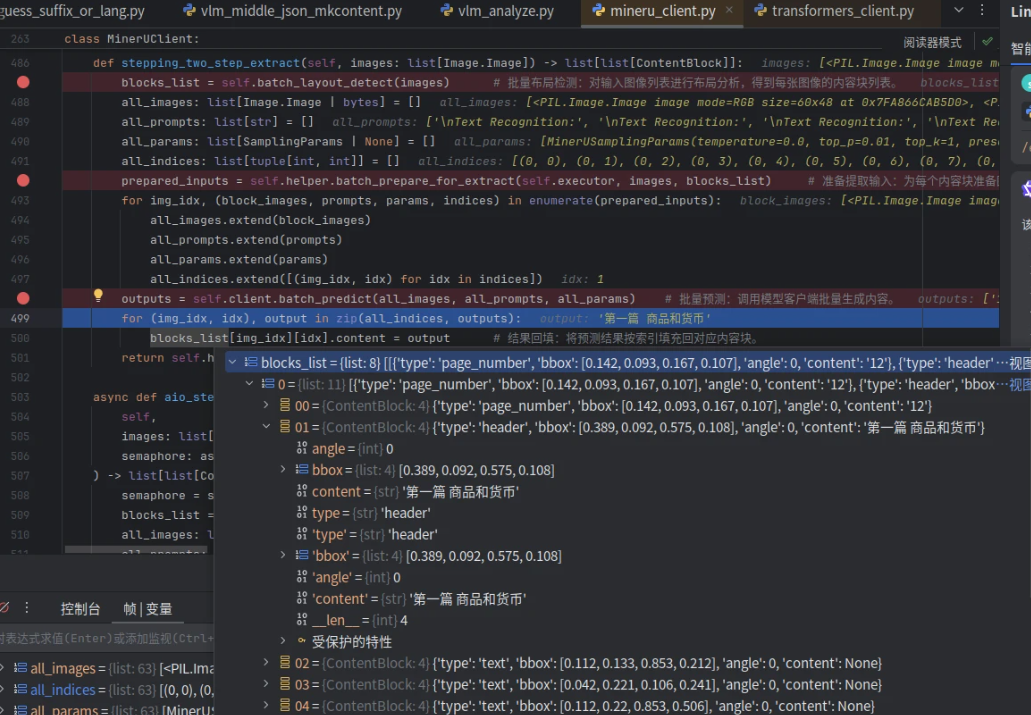
blocks_list[img_idx][idx].content = output # 结果回填:将预测结果按索引填充回对应内容块。blocks_list为:
batch_post_process
post_process()函数对内容块列表进行后处理:
1. 转换表格内容为HTML格式。
2. 处理公式内容,如修复和格式化。
3. 若启用,进一步处理公式块。
4. 为公式添加标准的LaTeX括号。
5. 根据参数过滤掉不需要的块类型(如列表、旁注等)。
最终返回处理后的块列表。
def post_process() -> list[ContentBlock]:
for block in blocks:
if block.type == "table" and block.content:
block.content = convert_otsl_to_html(block.content) # 转换表格内容为HTML格式。
if block.type == "equation" and block.content: # 处理公式内容,如修复和格式化。
block.content = _process_equation(block.content, debug=debug)
if handle_equation_block: # 若启用,进一步处理公式块。
blocks = do_handle_equation_block(blocks, debug=debug)
for block in blocks: # 为公式添加标准的LaTeX括号。
if block.type == "equation" and block.content:
block.content = _add_equation_brackets(block.content)
out_blocks: list[ContentBlock] = []
for block in blocks: # 根据参数过滤掉不需要的块类型(如列表、旁注等)。
if block.type == "equation_block": # drop equation_block anyway
continue
if abandon_list and block.type == "list":
continue
if abandon_paratext and block.type in PARATEXT_TYPES:
continue
out_blocks.append(block)
return out_blocks-
主体代码剩余部分
result_to_middle_json
处理完成之后,会回退到doc_analyze()进行中间结果保存:result_to_middle_json
middle_json = result_to_middle_json(results, images_list, pdf_doc, image_writer)该函数将模型输出的页面块信息转换为中间JSON格式。主要功能包括:
1. 遍历每页内容,调用[blocks_to_page_info]生成页面信息;
2. 若启用表格功能,则合并跨页表格;
3. 若标题优化模块可用,则使用LLM优化标题层级;
4. 最后关闭PDF文档并返回结果。
-
保存
返回do_parse(),然后调用_process_output()进行保存
_process_output( # 提取PDF信息并调用_process_output函数,根据配置输出各类文件(如Markdown、JSON等)及可视化结果。
pdf_info, pdf_bytes, pdf_file_name, local_md_dir, local_image_dir,
md_writer, f_draw_layout_bbox, f_draw_span_bbox, f_dump_orig_pdf,
f_dump_md, f_dump_content_list, f_dump_middle_json, f_dump_model_output,
f_make_md_mode, middle_json, infer_result, is_pipeline=False
)该函数根据传入的标志参数决定是否生成并保存不同的PDF处理结果文件,包括布局框图、原始PDF、Markdown文档等,并将它们写入指定目录。
def _process_output():
"""处理输出文件"""
if f_draw_layout_bbox: # 输出布局框的文件
draw_layout_bbox(pdf_info, pdf_bytes, local_md_dir, f"{pdf_file_name}_layout.pdf")
if f_draw_span_bbox:
draw_span_bbox(pdf_info, pdf_bytes, local_md_dir, f"{pdf_file_name}_span.pdf")
if f_dump_orig_pdf: # 输出原始PDF文件
md_writer.write(
f"{pdf_file_name}_origin.pdf",
pdf_bytes,
)
image_dir = str(os.path.basename(local_image_dir))
if f_dump_md: # 输出Markdown文件
make_func = pipeline_union_make if is_pipeline else vlm_union_make
md_content_str = make_func(pdf_info, f_make_md_mode, image_dir)
md_writer.write_string(
f"{pdf_file_name}.md",
md_content_str,
)
if f_dump_content_list:
make_func = pipeline_union_make if is_pipeline else vlm_union_make
content_list = make_func(pdf_info, MakeMode.CONTENT_LIST, image_dir)
md_writer.write_string(
f"{pdf_file_name}_content_list.json",
json.dumps(content_list, ensure_ascii=False, indent=4),
)
if f_dump_middle_json:
md_writer.write_string(
f"{pdf_file_name}_middle.json",
json.dumps(middle_json, ensure_ascii=False, indent=4),
)
if f_dump_model_output:
md_writer.write_string(
f"{pdf_file_name}_model.json",
json.dumps(model_output, ensure_ascii=False, indent=4),
)
logger.info(f"local output dir is {local_md_dir}")draw_layout_bbox
draw_layout_bbox()的代码功能是:
解析PDF页面信息,按类型提取各类区块(如表格、图像、代码、文本等)的边界框(bbox)。
为每类区块分配不同颜色和样式,调用 draw_bbox_without_number 或 draw_bbox_with_number 在PDF上绘制边界框。
生成带标注的新PDF,保存到指定路径(即后缀带_layout.pdf的文件)。
def draw_layout_bbox(pdf_info, pdf_bytes, out_path, filename):
dropped_bbox_list = []
tables_body_list, tables_caption_list, tables_footnote_list = [], [], []
imgs_body_list, imgs_caption_list, imgs_footnote_list = [], [], []
codes_body_list, codes_caption_list = [], []
titles_list = []
texts_list = []
interequations_list = []
lists_list = []
list_items_list = []
indexs_list = []
for page in pdf_info:
page_dropped_list = []
tables_body, tables_caption, tables_footnote = [], [], []
imgs_body, imgs_caption, imgs_footnote = [], [], []
codes_body, codes_caption = [], []
titles = []
texts = []
interequations = []
lists = []
list_items = []
indices = []
for dropped_bbox in page['discarded_blocks']:
page_dropped_list.append(dropped_bbox['bbox'])
dropped_bbox_list.append(page_dropped_list)
for block in page["para_blocks"]: # 按类型提取各类区块(如表格、图像、代码、文本等)的边界框(bbox)
bbox = block["bbox"]
if block["type"] == BlockType.TABLE:
for nested_block in block["blocks"]:
bbox = nested_block["bbox"]
if nested_block["type"] == BlockType.TABLE_BODY:
tables_body.append(bbox)
elif nested_block["type"] == BlockType.TABLE_CAPTION:
tables_caption.append(bbox)
elif nested_block["type"] == BlockType.TABLE_FOOTNOTE:
if nested_block.get(SplitFlag.CROSS_PAGE, False):
continue
tables_footnote.append(bbox)
elif block["type"] == BlockType.IMAGE:
for nested_block in block["blocks"]:
bbox = nested_block["bbox"]
if nested_block["type"] == BlockType.IMAGE_BODY:
imgs_body.append(bbox)
elif nested_block["type"] == BlockType.IMAGE_CAPTION:
imgs_caption.append(bbox)
elif nested_block["type"] == BlockType.IMAGE_FOOTNOTE:
imgs_footnote.append(bbox)
elif block["type"] == BlockType.CODE:
for nested_block in block["blocks"]:
if nested_block["type"] == BlockType.CODE_BODY:
bbox = nested_block["bbox"]
codes_body.append(bbox)
elif nested_block["type"] == BlockType.CODE_CAPTION:
bbox = nested_block["bbox"]
codes_caption.append(bbox)
elif block["type"] == BlockType.TITLE:
titles.append(bbox)
elif block["type"] in [BlockType.TEXT, BlockType.REF_TEXT]:
texts.append(bbox)
elif block["type"] == BlockType.INTERLINE_EQUATION:
interequations.append(bbox)
elif block["type"] == BlockType.LIST:
lists.append(bbox)
if "blocks" in block:
for sub_block in block["blocks"]:
list_items.append(sub_block["bbox"])
elif block["type"] == BlockType.INDEX:
indices.append(bbox)
tables_body_list.append(tables_body)
tables_caption_list.append(tables_caption)
tables_footnote_list.append(tables_footnote)
imgs_body_list.append(imgs_body)
imgs_caption_list.append(imgs_caption)
imgs_footnote_list.append(imgs_footnote)
titles_list.append(titles)
texts_list.append(texts)
interequations_list.append(interequations)
lists_list.append(lists)
list_items_list.append(list_items)
indexs_list.append(indices)
codes_body_list.append(codes_body)
codes_caption_list.append(codes_caption)
layout_bbox_list = []
table_type_order = {"table_caption": 1, "table_body": 2, "table_footnote": 3}
for page in pdf_info:
page_block_list = []
for block in page["para_blocks"]:
if block["type"] in [
BlockType.TEXT,
BlockType.REF_TEXT,
BlockType.TITLE,
BlockType.INTERLINE_EQUATION,
BlockType.LIST,
BlockType.INDEX,
]:
bbox = block["bbox"]
page_block_list.append(bbox)
elif block["type"] in [BlockType.IMAGE]:
for sub_block in block["blocks"]:
bbox = sub_block["bbox"]
page_block_list.append(bbox)
elif block["type"] in [BlockType.TABLE]:
sorted_blocks = sorted(block["blocks"], key=lambda x: table_type_order[x["type"]])
for sub_block in sorted_blocks:
if sub_block.get(SplitFlag.CROSS_PAGE, False):
continue
bbox = sub_block["bbox"]
page_block_list.append(bbox)
elif block["type"] in [BlockType.CODE]:
for sub_block in block["blocks"]:
bbox = sub_block["bbox"]
page_block_list.append(bbox)
layout_bbox_list.append(page_block_list)
pdf_bytes_io = BytesIO(pdf_bytes)
pdf_docs = PdfReader(pdf_bytes_io)
output_pdf = PdfWriter()
for i, page in enumerate(pdf_docs.pages):
# 获取原始页面尺寸
page_width, page_height = float(page.cropbox[2]), float(page.cropbox[3])
custom_page_size = (page_width, page_height)
packet = BytesIO()
# 使用原始PDF的尺寸创建canvas
c = canvas.Canvas(packet, pagesize=custom_page_size)
c = draw_bbox_without_number(i, codes_body_list, page, c, [102, 0, 204], True)
c = draw_bbox_without_number(i, codes_caption_list, page, c, [204, 153, 255], True)
c = draw_bbox_without_number(i, dropped_bbox_list, page, c, [158, 158, 158], True)
c = draw_bbox_without_number(i, tables_body_list, page, c, [204, 204, 0], True)
c = draw_bbox_without_number(i, tables_caption_list, page, c, [255, 255, 102], True)
c = draw_bbox_without_number(i, tables_footnote_list, page, c, [229, 255, 204], True)
c = draw_bbox_without_number(i, imgs_body_list, page, c, [153, 255, 51], True)
c = draw_bbox_without_number(i, imgs_caption_list, page, c, [102, 178, 255], True)
c = draw_bbox_without_number(i, imgs_footnote_list, page, c, [255, 178, 102], True)
c = draw_bbox_without_number(i, titles_list, page, c, [102, 102, 255], True)
c = draw_bbox_without_number(i, texts_list, page, c, [153, 0, 76], True)
c = draw_bbox_without_number(i, interequations_list, page, c, [0, 255, 0], True)
c = draw_bbox_without_number(i, lists_list, page, c, [40, 169, 92], True)
c = draw_bbox_without_number(i, list_items_list, page, c, [40, 169, 92], False)
c = draw_bbox_without_number(i, indexs_list, page, c, [40, 169, 92], True)
c = draw_bbox_with_number(i, layout_bbox_list, page, c, [255, 0, 0], False, draw_bbox=False)
c.save()
packet.seek(0)
overlay_pdf = PdfReader(packet)
# 添加检查确保overlay_pdf.pages不为空
if len(overlay_pdf.pages) > 0:
new_page = PageObject(pdf=None)
new_page.update(page)
page = new_page
page.merge_page(overlay_pdf.pages[0])
else:
# 记录日志并继续处理下一个页面
# logger.warning(f"layout.pdf: 第{i + 1}页未能生成有效的overlay PDF")
pass
output_pdf.add_page(page)
# 保存结果
with open(f"{out_path}/{filename}", "wb") as f:
output_pdf.write(f)其中draw_bbox_without_number为:
def draw_bbox_without_number(i, bbox_list, page, c, rgb_config, fill_config):
new_rgb = [float(color) / 255 for color in rgb_config] # 将RGB颜色值归一化到0-1之间
page_data = bbox_list[i]
for bbox in page_data:
rect = cal_canvas_rect(page, bbox) # cal_canvas_rect计算实际绘制坐标 Define the rectangle
if fill_config: # 决定绘制填充矩形(带透明度)或仅描边的边界框。 filled rectangle
c.setFillColorRGB(new_rgb[0], new_rgb[1], new_rgb[2], 0.3)
c.rect(rect[0], rect[1], rect[2], rect[3], stroke=0, fill=1)
else: # bounding box
c.setStrokeColorRGB(new_rgb[0], new_rgb[1], new_rgb[2])
c.rect(rect[0], rect[1], rect[2], rect[3], stroke=1, fill=0)
return c其输出的最终样式为:

union_make()函数 用于根据不同的 make_mode 将 PDF 页面信息转换为 Markdown 或内容列表格式。
- 若 make_mode 为 MM_MD 或 NLP_MD,调用 mk_blocks_to_markdown 生成 Markdown 文本。
- 若 make_mode 为 CONTENT_LIST,调用 make_blocks_to_content_list 生成结构化内容列表。
- 支持公式和表格的启用控制,最终返回对应格式的内容。
def union_make(pdf_info_dict: list,
make_mode: str,
img_buket_path: str = '',
):
formula_enable = get_formula_enable(os.getenv('MINERU_VLM_FORMULA_ENABLE', 'True').lower() == 'true')
table_enable = get_table_enable(os.getenv('MINERU_VLM_TABLE_ENABLE', 'True').lower() == 'true')
output_content = []
for page_info in pdf_info_dict: # 生成markdown文件
paras_of_layout = page_info.get('para_blocks')
paras_of_discarded = page_info.get('discarded_blocks')
page_idx = page_info.get('page_idx')
page_size = page_info.get('page_size')
if not paras_of_layout:
continue
if make_mode in [MakeMode.MM_MD, MakeMode.NLP_MD]:
page_markdown = mk_blocks_to_markdown(paras_of_layout, make_mode, formula_enable, table_enable, img_buket_path)
output_content.extend(page_markdown)
elif make_mode == MakeMode.CONTENT_LIST:
for para_block in paras_of_layout+paras_of_discarded:
para_content = make_blocks_to_content_list(para_block, img_buket_path, page_idx, page_size)
output_content.append(para_content)
if make_mode in [MakeMode.MM_MD, MakeMode.NLP_MD]:
return '\n\n'.join(output_content)
elif make_mode == MakeMode.CONTENT_LIST:
return output_content
return None返回结果示例:
史的事情。(3)为有用物的量找到社会尺度, 也是这样。商品的这些尺度之所以不同, 部分是由于被计量的物的性质不同, 部分是由于约定俗成。
14(I)
物的有用性使物成为使用价值。(4)但这种有用性不是飘忽不定的。它决定于商品体的属性,离开了商品体就不存在。因此,商品体本身,例如铁、小麦、金钢石等等,就是使用价值。赋予商品体以这种性质的,不是人为了取得它的有用性质所耗费的劳动的多少。在谈到使用价值时,总是指一定的量而言,如一打表,一米布,一吨铁等等。商品的使用价值为商品学和商业成规这种专门的知识提供材料。该函数用于将段落中的文本、行内公式和行间公式合并为一个字符串。根据公式是否启用,决定如何处理行间公式:启用时添加分隔符,禁用时尝试以图片形式插入。
def merge_para_with_text(para_block, formula_enable=True, img_buket_path=''):
para_text = ''
for line in para_block['lines']:
for j, span in enumerate(line['spans']):
span_type = span['type']
content = ''
if span_type == ContentType.TEXT:
content = span['content']
elif span_type == ContentType.INLINE_EQUATION:
content = f"{inline_left_delimiter}{span['content']}{inline_right_delimiter}"
elif span_type == ContentType.INTERLINE_EQUATION:
if formula_enable:
content = f"\n{display_left_delimiter}\n{span['content']}\n{display_right_delimiter}\n"
else:
if span.get('image_path', ''):
content = f""
# content = content.strip()
if content:
if span_type in [ContentType.TEXT, ContentType.INLINE_EQUATION]:
if j == len(line['spans']) - 1:
para_text += content
else:
para_text += f'{content} '
elif span_type == ContentType.INTERLINE_EQUATION:
para_text += content
return para_text
def mk_blocks_to_markdown(para_blocks, make_mode, formula_enable, table_enable, img_buket_path=''):
page_markdown = []
for para_block in para_blocks:
para_text = ''
para_type = para_block['type']
if para_type in [BlockType.TEXT, BlockType.INTERLINE_EQUATION, BlockType.PHONETIC, BlockType.REF_TEXT]:
para_text = merge_para_with_text(para_block, formula_enable=formula_enable, img_buket_path=img_buket_path)
elif para_type == BlockType.LIST:
for block in para_block['blocks']:
item_text = merge_para_with_text(block, formula_enable=formula_enable, img_buket_path=img_buket_path)
para_text += f"{item_text} \n"
elif para_type == BlockType.TITLE:
title_level = get_title_level(para_block)
para_text = f'{"#" * title_level} {merge_para_with_text(para_block)}'
elif para_type == BlockType.IMAGE:
if make_mode == MakeMode.NLP_MD: # 若模式为 NLP_MD,则跳过图片
continue
elif make_mode == MakeMode.MM_MD: # 若模式为 MM_MD,检测是否存在图片脚注
# 检测是否存在图片脚注
has_image_footnote = any(block['type'] == BlockType.IMAGE_FOOTNOTE for block in para_block['blocks'])
# 如果存在图片脚注,则将图片脚注拼接到图片正文后面
if has_image_footnote: # 如果有脚注,按 标题→图片→脚注 顺序拼接
for block in para_block['blocks']: # 1st.拼image_caption
if block['type'] == BlockType.IMAGE_CAPTION:
para_text += merge_para_with_text(block) + ' \n'
for block in para_block['blocks']: # 2nd.拼image_body
if block['type'] == BlockType.IMAGE_BODY:
for line in block['lines']:
for span in line['spans']:
if span['type'] == ContentType.IMAGE:
if span.get('image_path', ''):
para_text += f""
for block in para_block['blocks']: # 3rd.拼image_footnote
if block['type'] == BlockType.IMAGE_FOOTNOTE:
para_text += ' \n' + merge_para_with_text(block)
else: # 如果没有脚注,按 图片→标题 顺序拼接
for block in para_block['blocks']: # 1st.拼image_body
if block['type'] == BlockType.IMAGE_BODY:
for line in block['lines']:
for span in line['spans']:
if span['type'] == ContentType.IMAGE:
if span.get('image_path', ''):
para_text += f"" # 这段代码用于将图片路径拼接成Markdown格式的图片引用,格式为 ,其中 img_buket_path 是图片的基础路径,span['image_path'] 是具体图片文件的路径。
for block in para_block['blocks']: # 2nd.拼image_caption
if block['type'] == BlockType.IMAGE_CAPTION:
para_text += ' \n' + merge_para_with_text(block)
elif para_type == BlockType.TABLE:
if make_mode == MakeMode.NLP_MD:
continue
elif make_mode == MakeMode.MM_MD:
for block in para_block['blocks']: # 1st.拼table_caption
if block['type'] == BlockType.TABLE_CAPTION: # 拼接表格标题
para_text += merge_para_with_text(block) + ' \n'
for block in para_block['blocks']: # 2nd.拼table_body
if block['type'] == BlockType.TABLE_BODY: # 拼接表格主体
for line in block['lines']:
for span in line['spans']:
if span['type'] == ContentType.TABLE:
# if processed by table model
if table_enable:
if span.get('html', ''): # 若启用了表格模型(table_enable=True),优先使用 HTML 表格
para_text += f"\n{span['html']}\n"
elif span.get('image_path', ''):
para_text += f""
else:
if span.get('image_path', ''):
para_text += f""
for block in para_block['blocks']: # 3rd.拼table_footnote
if block['type'] == BlockType.TABLE_FOOTNOTE: # 拼接表格脚注
para_text += '\n' + merge_para_with_text(block) + ' '
elif para_type == BlockType.CODE:
sub_type = para_block["sub_type"]
for block in para_block['blocks']: # 1st.拼code_caption
if block['type'] == BlockType.CODE_CAPTION:
para_text += merge_para_with_text(block) + ' \n'
for block in para_block['blocks']: # 2nd.拼code_body
if block['type'] == BlockType.CODE_BODY:
if sub_type == BlockType.CODE:
guess_lang = para_block["guess_lang"]
para_text += f"```{guess_lang}\n{merge_para_with_text(block)}\n```"
elif sub_type == BlockType.ALGORITHM:
para_text += merge_para_with_text(block)
if para_text.strip() == '':
continue
else:
# page_markdown.append(para_text.strip() + ' ')
page_markdown.append(para_text.strip())
return page_markdown对于title,其para_text为md格式的标题,如:
'# TABLE: Table 1.'对于图片:这段代码用于将图片路径拼接成Markdown格式的图片引用,格式为 ``,其中 `img_buket_path` 是图片的基础路径,`span['image_path']` 是具体图片文件的路径。
para_text += f"" # 这段代码用于将图片路径拼接成Markdown格式的图片引用,格式为 ,其中 img_buket_path 是图片的基础路径,span['image_path'] 是具体图片文件的路径。
如:
''-
-
生成结果演示
目前来看,这个框架的提升空间还很大,但作为一个小模型,这样的表现能力确实不错!
-
-
5.总结
MinerU 是作者面向多端场景推出的全链路 PDF 解析工具,其目标是把任意版式的静态文档转化为机器可读、人类易用的结构化数据。作者首先用轻量预处理筛掉加密或损坏文件并提取语言、页数、页面尺寸等元数据;随后调用自研 PDF-Extract-Kit 模型库,在版面检测、公式检测、表格识别、公式识别与 OCR 五个方向级联推理,将文字、公式、表格、图片精准切块并识别。
为了应对真实版面中框体重叠、阅读顺序混乱等难题,作者设计了一套基于“包含-部分重叠-阅读顺序”原则的后处理算法,先清理嵌套与遮挡,再按“从上到下、从左到右”分段排序,确保栏序与行序符合人类阅读习惯。最终,作者把中间结果写入统一 JSON,并支持一键输出 Markdown 或自定义 JSON,图片与表格可随文裁剪,方便后续知识库构建、学术写作、数据挖掘等应用。
整个系统呈现了作者从数据标注、模型训练、工程优化到格式输出的完整闭环,验证了多样化数据工程与阅读顺序后处理在提升端到端解析精度中的关键作用,为复杂版式文档的可信自动化处理提供了可复制的实践范式。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)