
计算机毕业设计Python知识图谱中华古诗词可视化 古诗词情感分析 古诗词智能问答系统 AI大模型自动写诗 大数据毕业设计(源码+LW文档+PPT+讲解)
计算机毕业设计Python知识图谱中华古诗词可视化 古诗词情感分析 古诗词智能问答系统 AI大模型自动写诗 大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python知识图谱中华古诗词可视化与古诗词情感分析
摘要:本文聚焦于利用Python技术构建中华古诗词知识图谱并实现可视化,同时开展古诗词情感分析研究。通过整合网络爬虫、自然语言处理、图数据库及可视化库等技术,构建了包含诗人、诗作、朝代等实体的知识图谱,并采用多种深度学习模型进行情感分类。实验结果表明,系统在知识图谱构建与情感分析方面均取得较好效果,为古诗词的数字化传承、学术研究及教育应用提供了有力支持。
关键词:Python;知识图谱;古诗词可视化;情感分析
一、引言
中华古诗词作为中华民族的文化瑰宝,蕴含着丰富的历史、文化、情感与美学价值。从《诗经》《楚辞》到唐诗宋词元曲,不同时代的作品反映了当时的社会风貌、人文精神与诗人的内心世界。然而,随着时代变迁,古诗词的传承与理解面临一定挑战,普通读者难以全面、深入地领略其魅力。传统阅读与学习方式在信息爆炸时代面临诸多局限,难以充分挖掘古诗词的深层价值。
现代信息技术的飞速发展,为古诗词的数字化处理与传承提供了新的机遇。Python凭借其强大的数据处理、自然语言处理和可视化能力,为古诗词的数字化处理与深度分析提供了新路径。通过构建古诗词知识图谱并进行可视化展示,可以直观地呈现古诗词中的人物、地点、事件等实体及其关系,帮助用户快速梳理知识脉络;同时,开展古诗词情感分析,有助于深入理解诗人所表达的情感,促进中华文化的传承与发展。
二、研究现状
目前,在古诗词研究领域,已有不少学者开展了相关工作。在知识图谱构建方面,部分研究利用自然语言处理技术从古诗词文本中提取实体和关系,构建知识图谱,但存在实体识别准确率不高、关系抽取不全面等问题。例如,一些研究仅采用基于规则的方法进行实体识别,对于古诗词中复杂的语言结构和多样的表达方式难以准确处理。
在情感分析方面,传统方法多基于情感词典进行匹配,但古诗词的情感表达具有含蓄、委婉的特点,情感词典难以覆盖所有情感词汇和表达方式,导致情感分析的准确率较低。近年来,随着深度学习技术的发展,一些研究开始采用深度学习模型进行古诗词情感分析,但模型的泛化能力仍有待提高,在不同类型古诗词上的表现存在差异。
三、系统设计与技术实现
3.1 系统架构
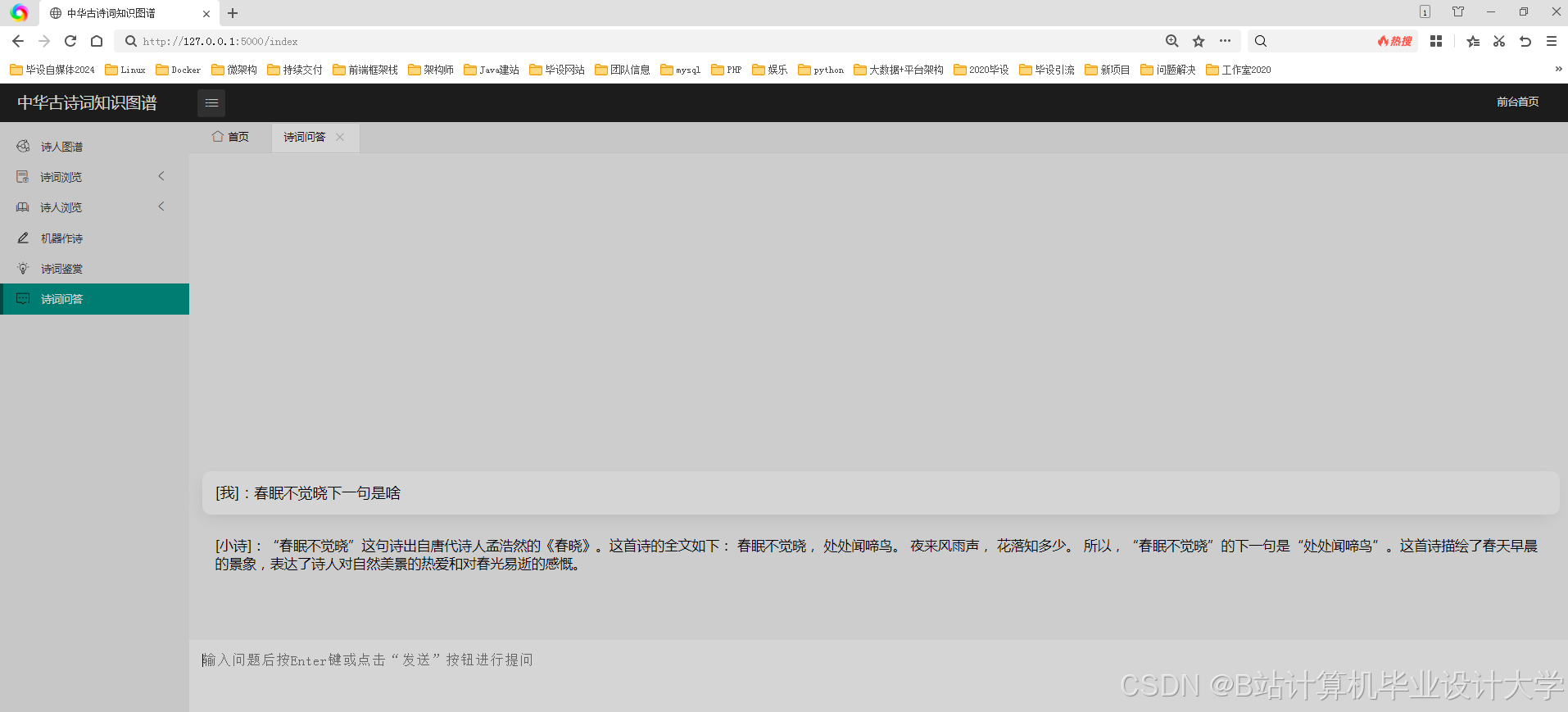
本系统主要由数据采集与预处理、知识图谱构建、可视化展示和情感分析四个核心模块构成。数据采集与预处理模块负责从多种渠道收集古诗词数据,并对原始数据进行清洗、转换和标注;知识图谱构建模块运用自然语言处理和图数据库技术,从预处理后的数据中提取实体和关系,构建知识图谱;可视化展示模块借助可视化库将构建好的知识图谱以直观的图形界面展示出来;情感分析模块采用深度学习模型对古诗词进行情感分类。
3.2 数据采集与预处理
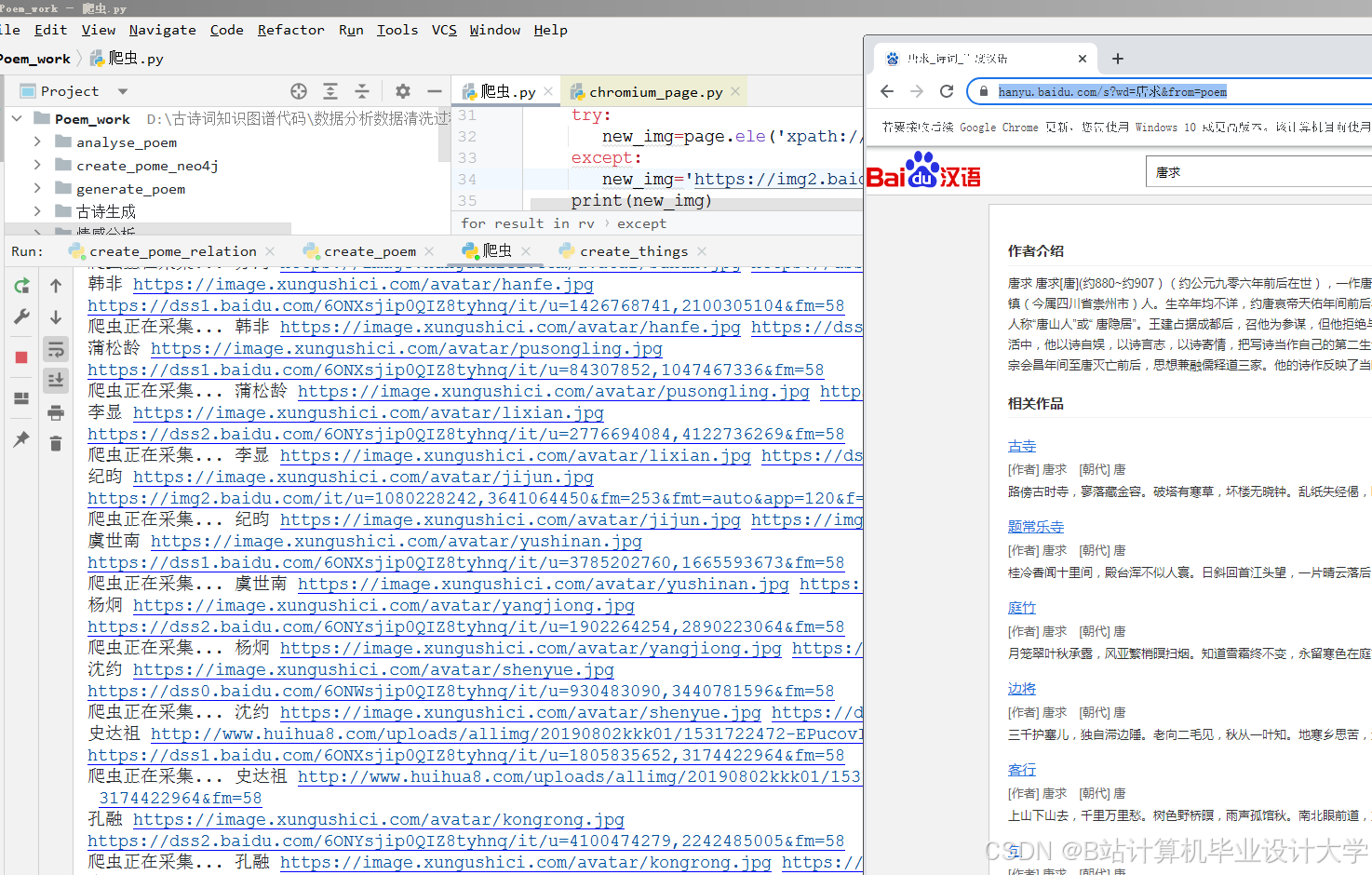
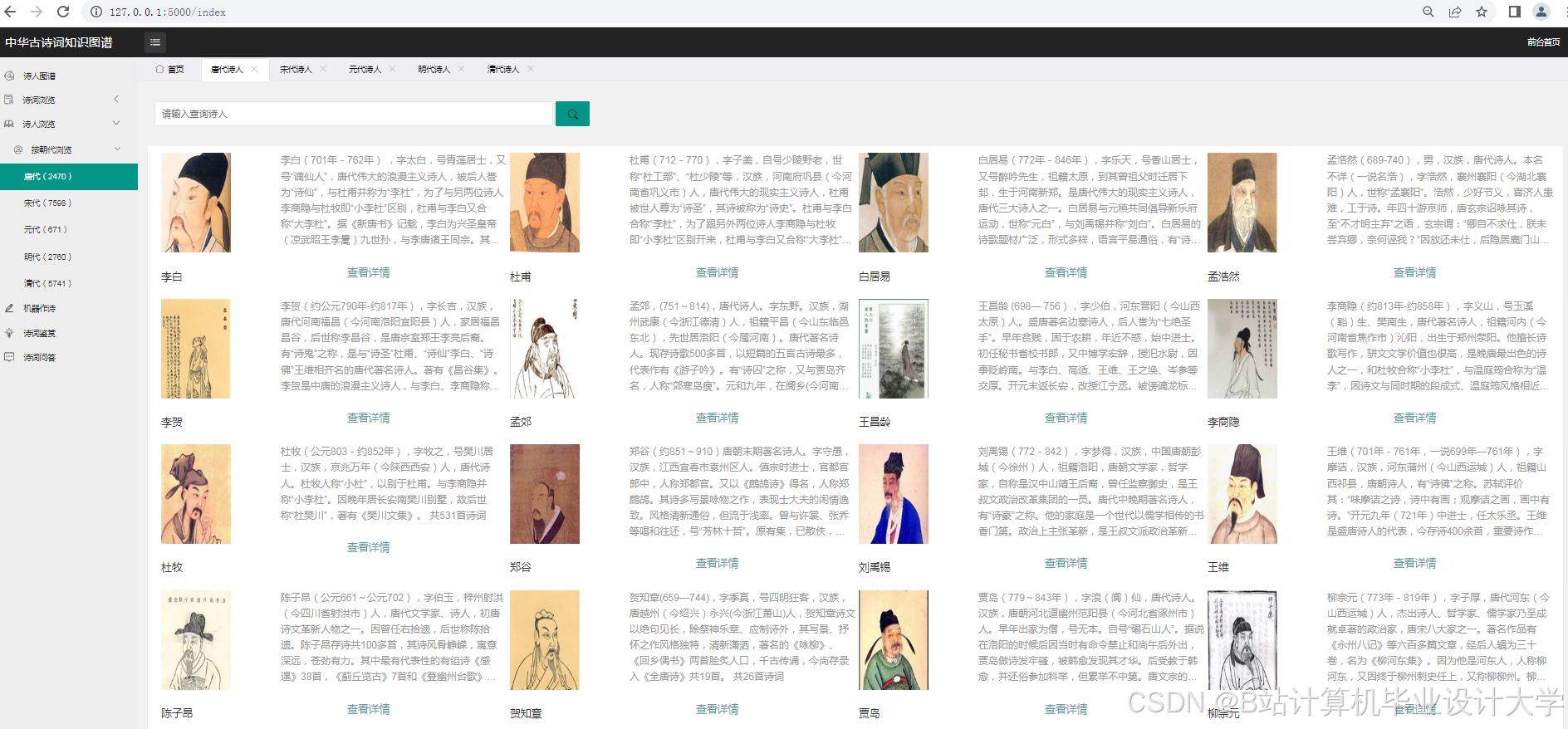
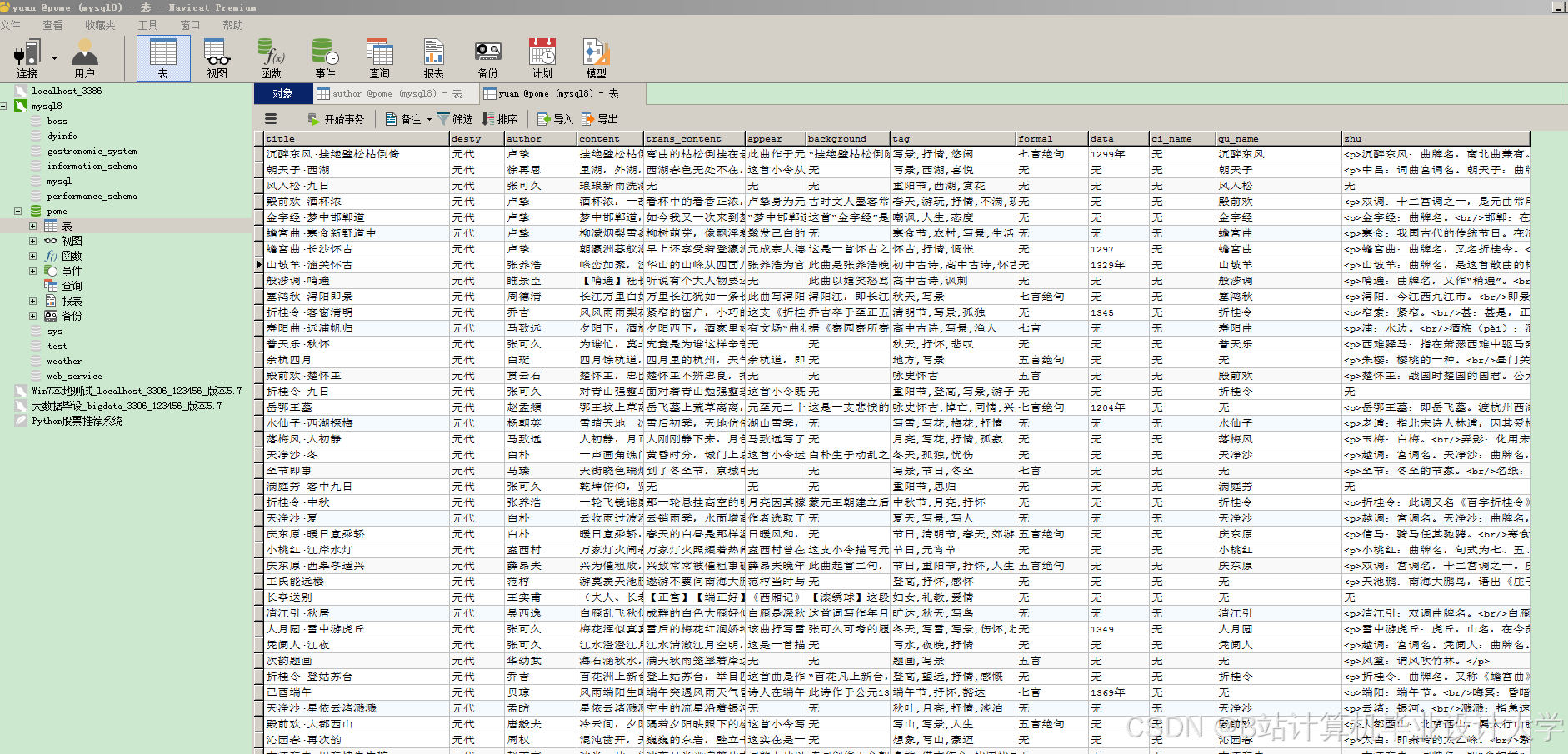
- 数据采集:可从权威诗词典籍、专业诗词网站等渠道广泛收集古诗词数据,涵盖诗词原文、作者信息、创作背景、注释赏析等。利用Python的requests库爬取网页数据,通过分析网页结构,使用BeautifulSoup或lxml库解析HTML,提取所需信息。例如,在爬取某诗词网站时,先定位包含诗词列表的HTML标签,然后遍历每个诗词项,提取诗词原文、作者、朝代等关键信息。部分诗词数据平台提供API接口,可通过requests库按照接口规范发送请求,获取结构化的诗词数据。
- 数据清洗:去除采集到的数据中的HTML标签、特殊字符、重复内容等噪声。使用正则表达式(re模块)进行模式匹配与替换,确保数据格式统一。例如,将诗词文本中的换行符、空格等进行规范化处理。
- 分词与词性标注:采用jieba分词库对诗词文本进行分词,并结合自定义词典和停用词表,去除无意义的停用词。同时,使用jieba.posseg模块进行词性标注,为后续的实体识别和关系抽取提供基础。
3.3 知识图谱构建
- 实体识别:采用基于规则与机器学习相结合的方法。基于规则的方法根据古诗词的特点和语言规律,定义一系列规则来识别实体。例如,通过“朝代 + 人名”的模式识别诗人实体,通过“诗名 + 诗体”的模式识别诗作实体。基于机器学习的方法使用预处理后的标注数据集,训练机器学习模型进行实体识别。可以选择支持向量机(SVM)、决策树、条件随机场(CRF)等算法。以CRF为例,利用sklearn_crfsuite库实现模型的训练和预测,将分词和词性标注结果作为特征,提高实体识别的准确性。近年来,深度学习在自然语言处理领域取得了显著成果,也可以使用循环神经网络(RNN)、长短期记忆网络(LSTM)、双向长短期记忆网络(BiLSTM)等模型进行实体识别。例如,使用PyTorch或TensorFlow框架构建BiLSTM - CRF模型,通过大量的标注数据进行训练,自动学习文本中的特征,进一步提高实体识别的性能。
- 关系抽取:基于规则的方法根据诗词的语法结构和语义信息,定义规则来抽取实体之间的关系。例如,通过“诗人 + 创作 + 诗作”的句式抽取“诗人 - 作品”关系。基于机器学习的方法将关系抽取看作一个分类问题,使用标注数据集训练分类模型。可以选择支持向量机、随机森林等算法。以支持向量机为例,将实体对及其上下文信息作为特征,训练模型判断实体对之间是否存在特定关系。基于深度学习的方法利用深度学习模型学习文本中的语义表示,进行关系抽取。例如,使用卷积神经网络(CNN)、图神经网络(GNN)等模型。以CNN为例,将实体对及其上下文文本转换为向量表示,通过卷积层、池化层等提取特征,最后通过全连接层进行关系分类。
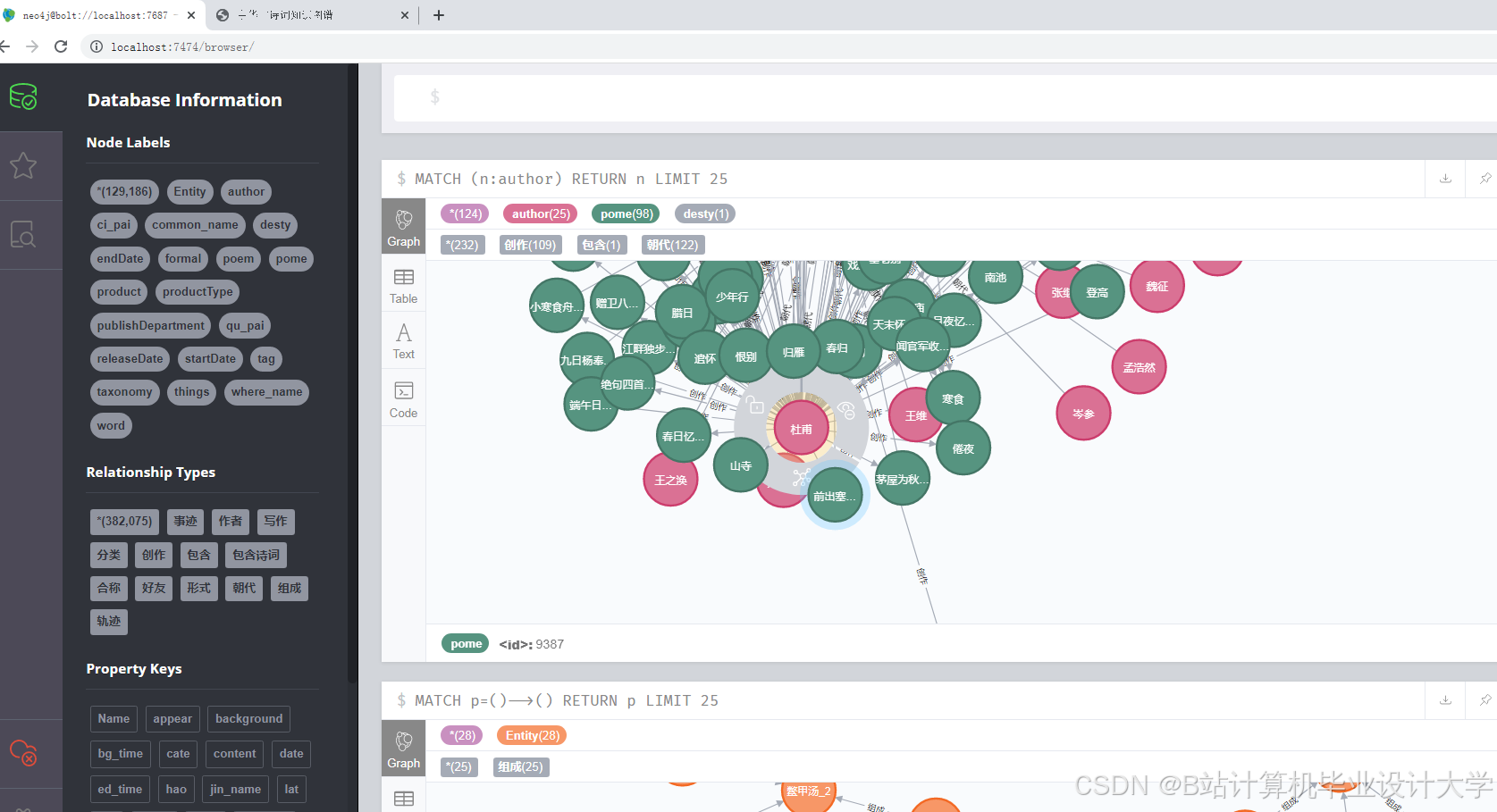
- 图谱存储:选择Neo4j图数据库进行知识图谱的存储。使用py2neo库作为Python与Neo4j的交互接口,通过定义节点和边的属性,将实体和关系数据导入到Neo4j数据库中。例如,定义诗人节点包含姓名、朝代、生平事迹等属性,诗作节点包含诗名、原文、创作时间等属性,“诗人 - 作品”关系包含创作时间等属性。
3.4 可视化展示
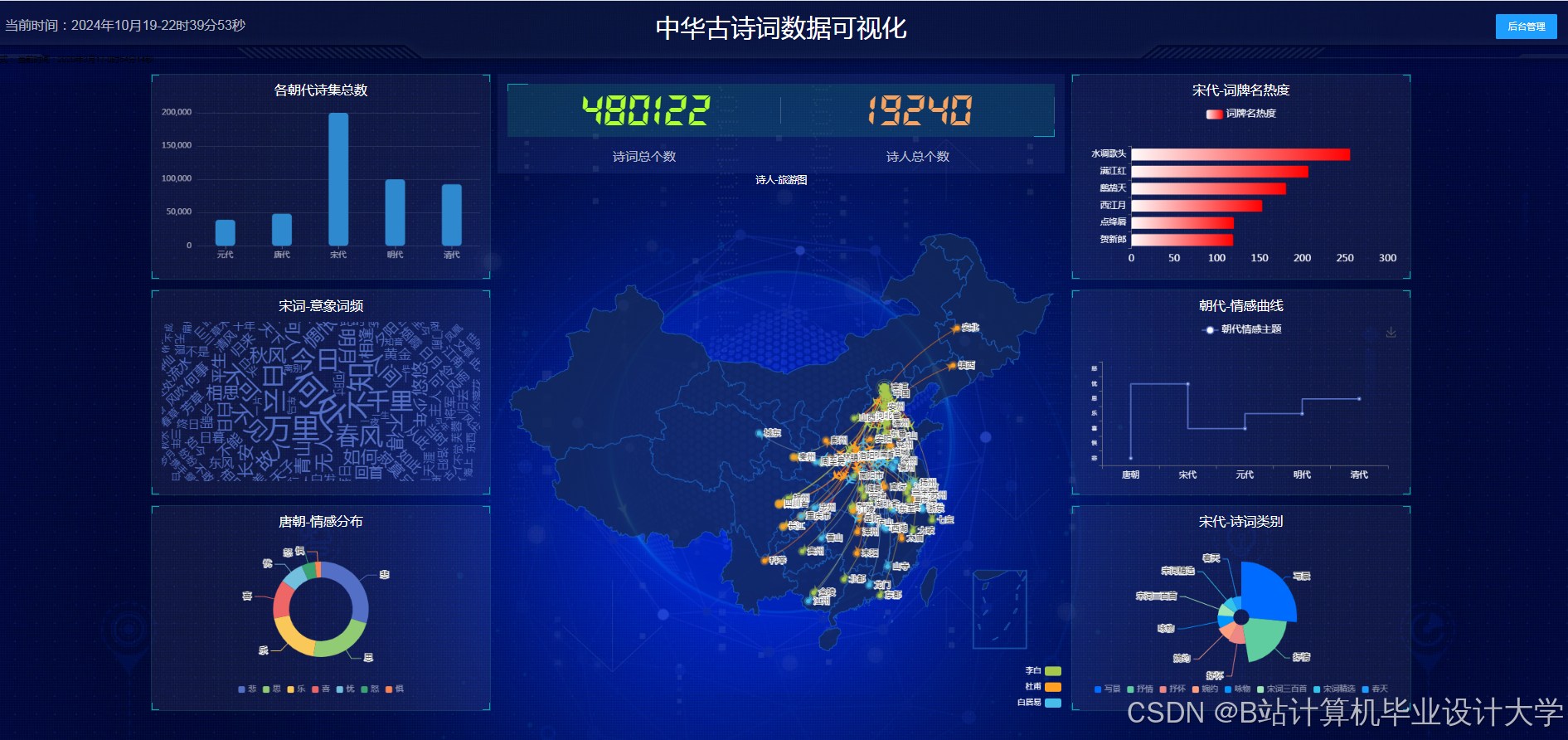
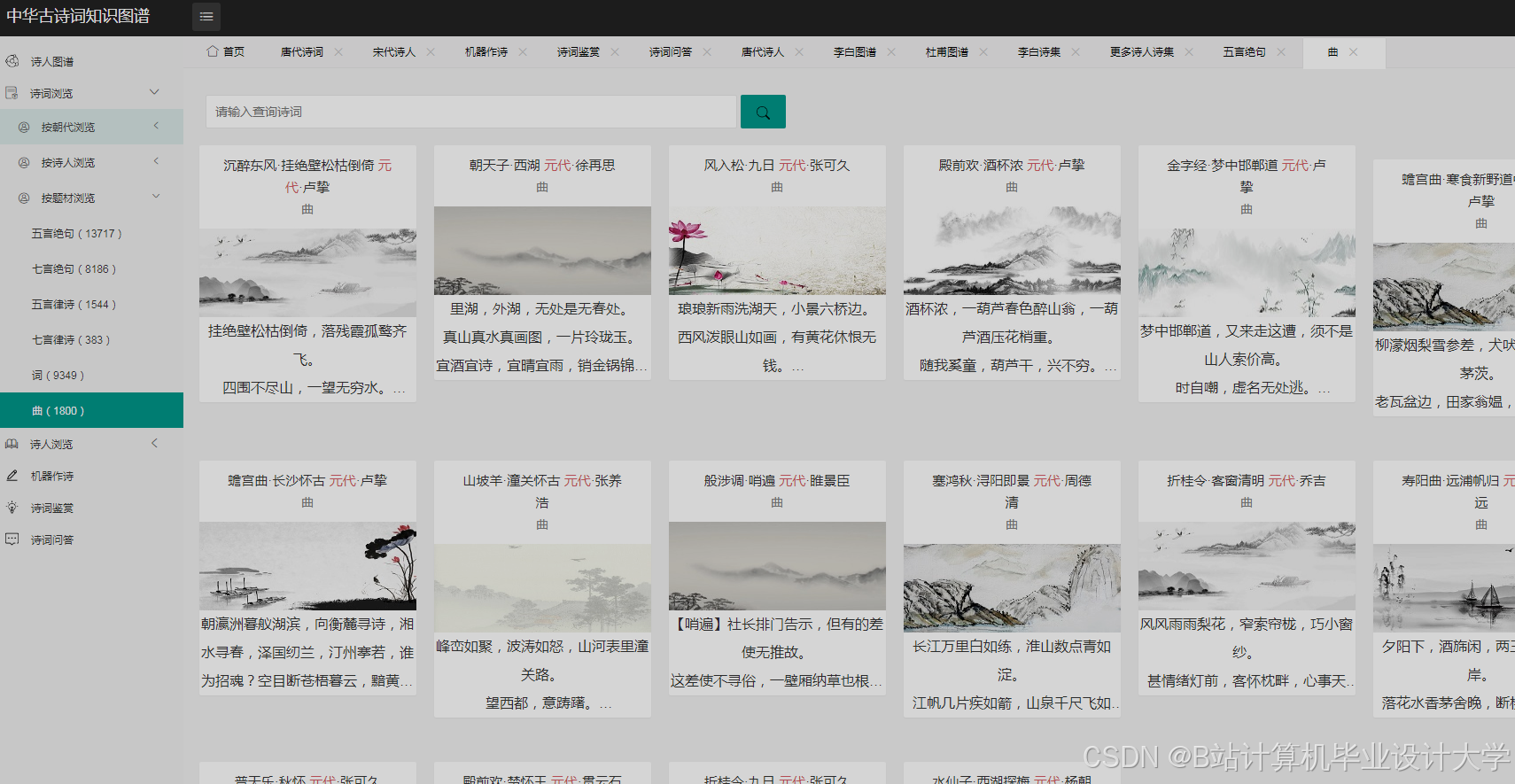
- 可视化库选择:使用D3.js和ECharts等可视化库进行知识图谱的可视化展示。D3.js基于数据驱动文档,能够创建高度定制化的可视化图表。ECharts提供了丰富的可视化图表类型和交互功能,支持将知识图谱与柱状图、折线图等结合展示。
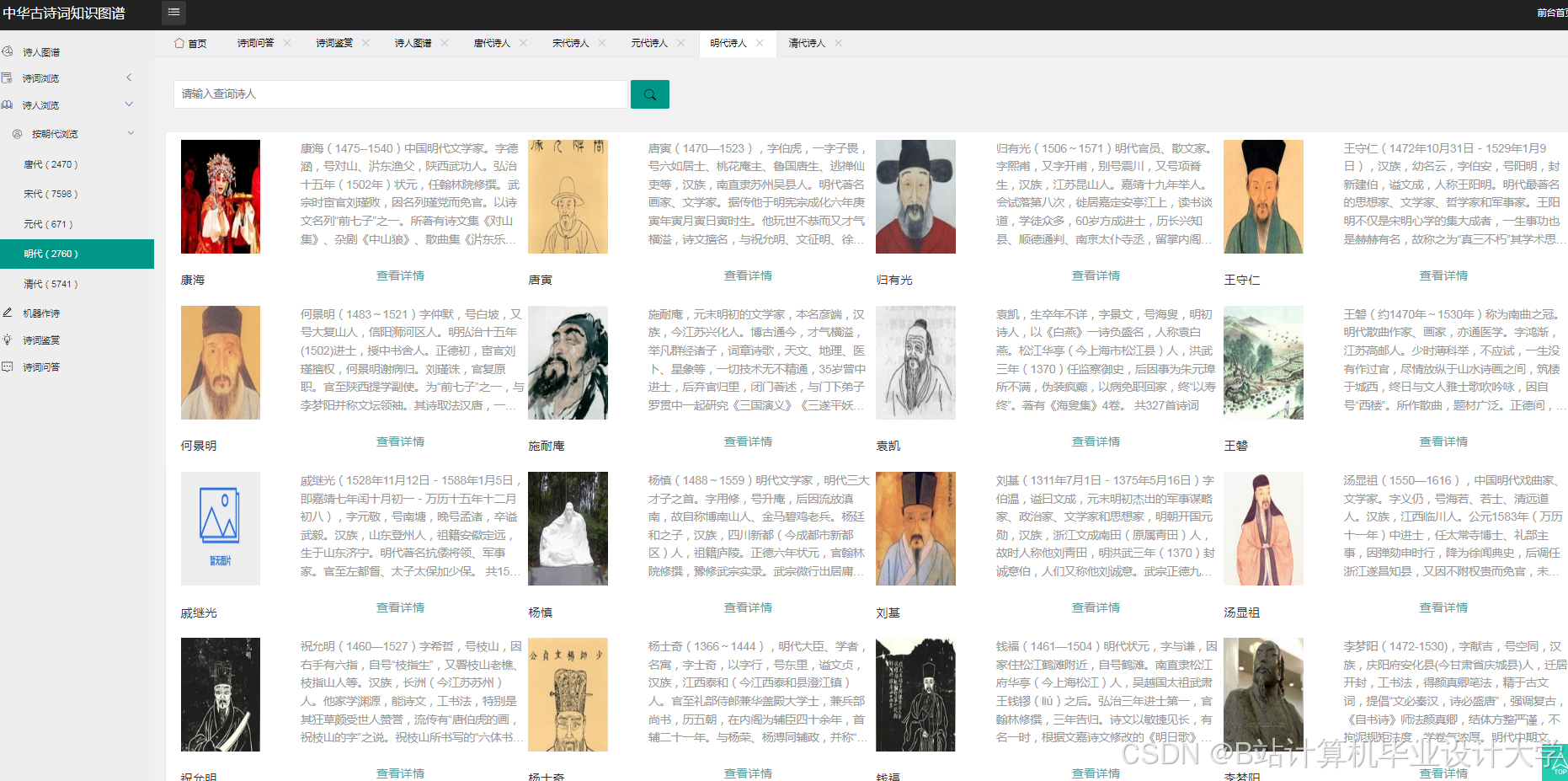
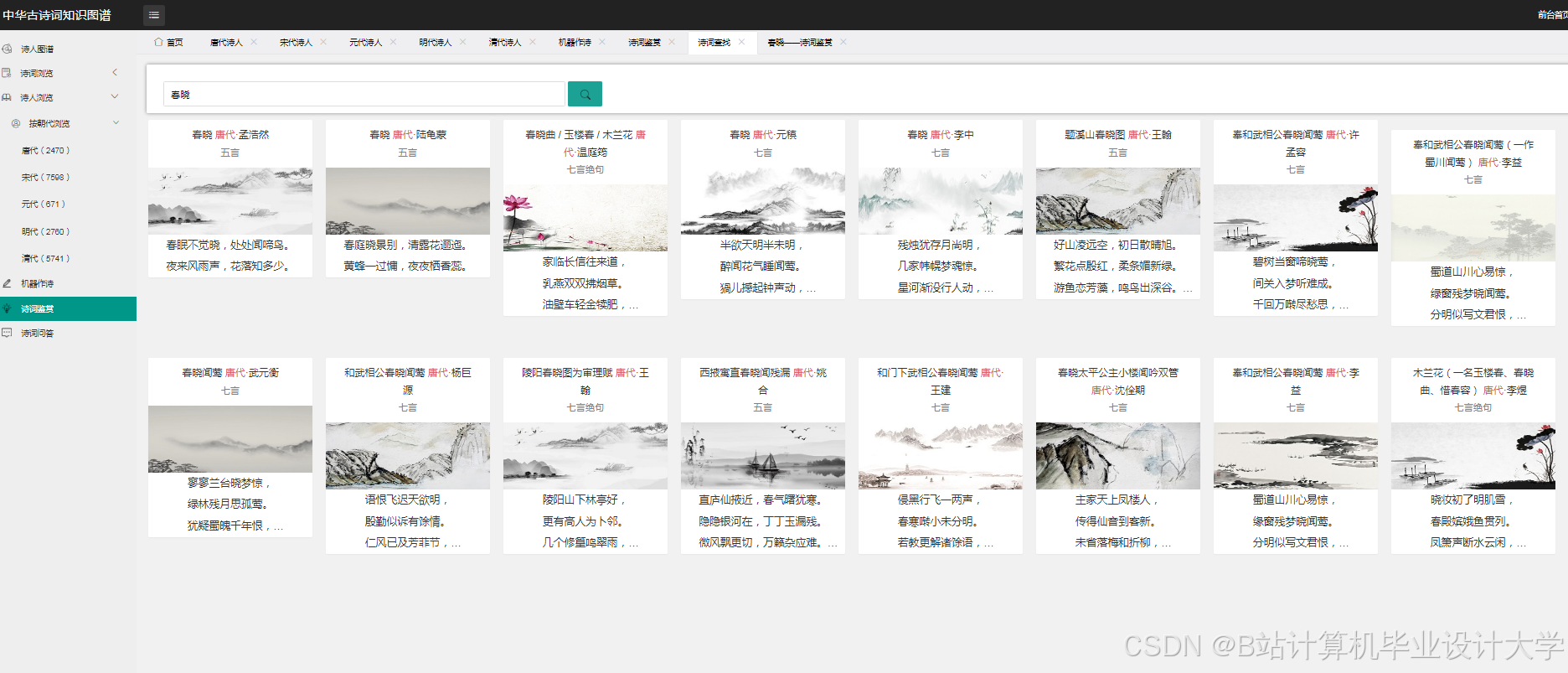
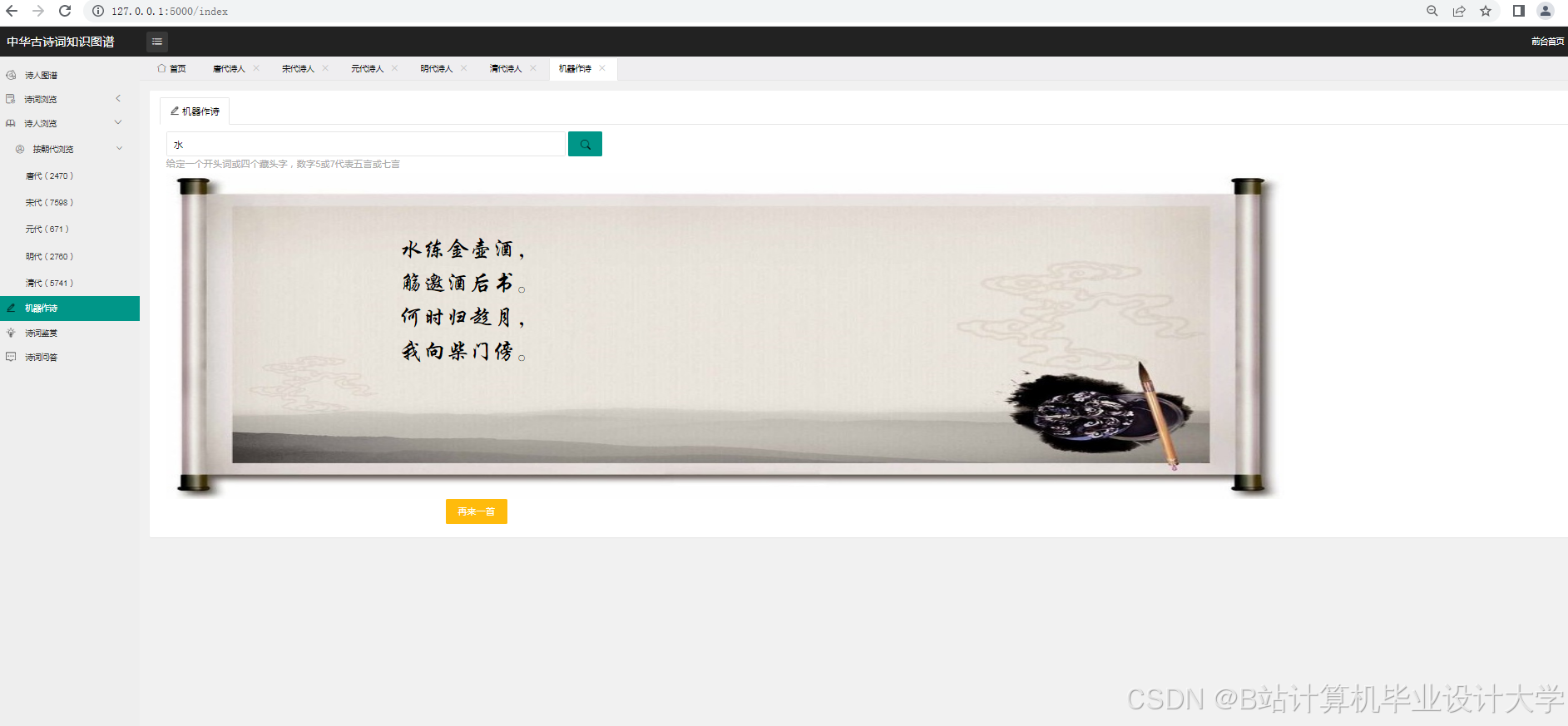
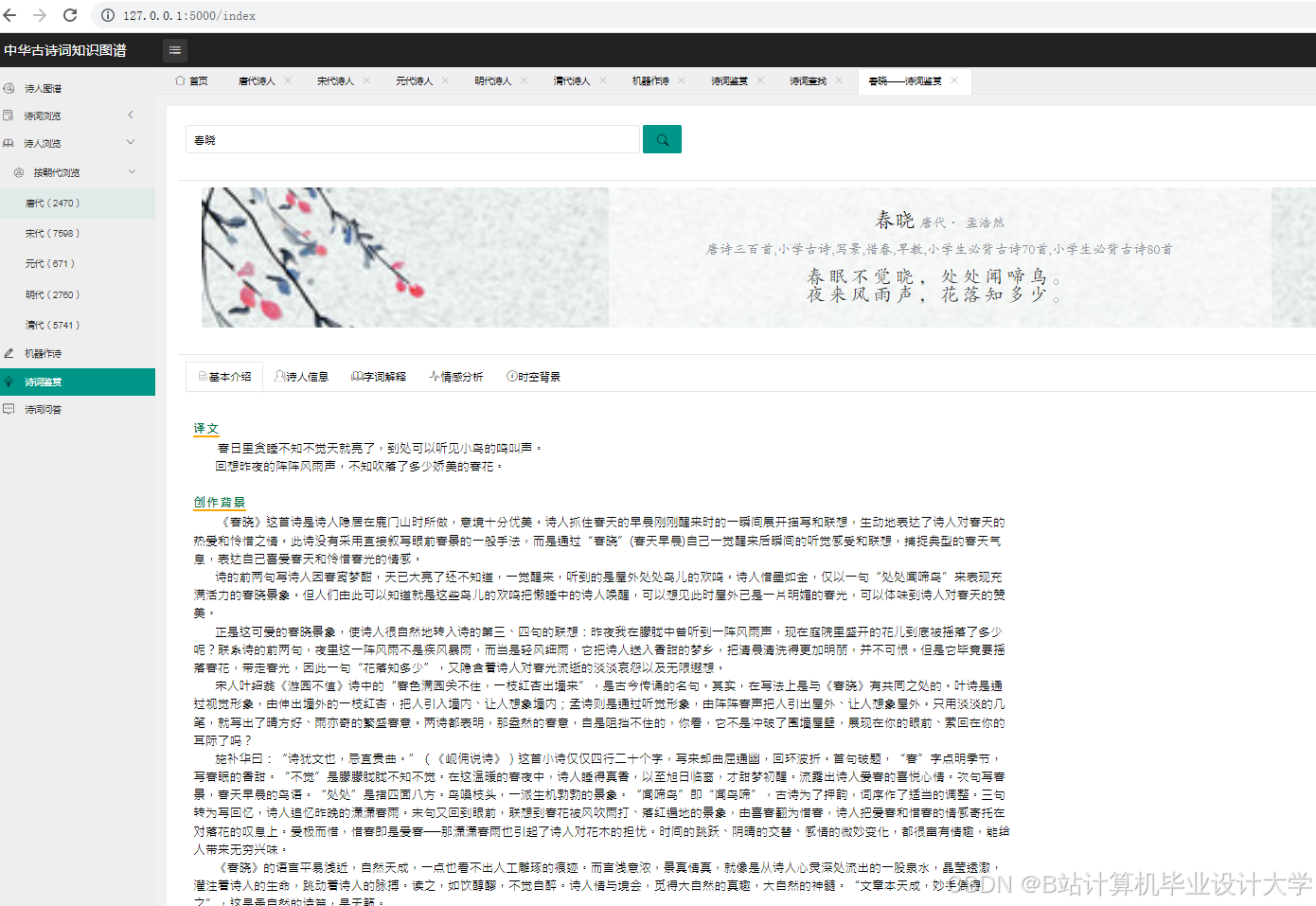
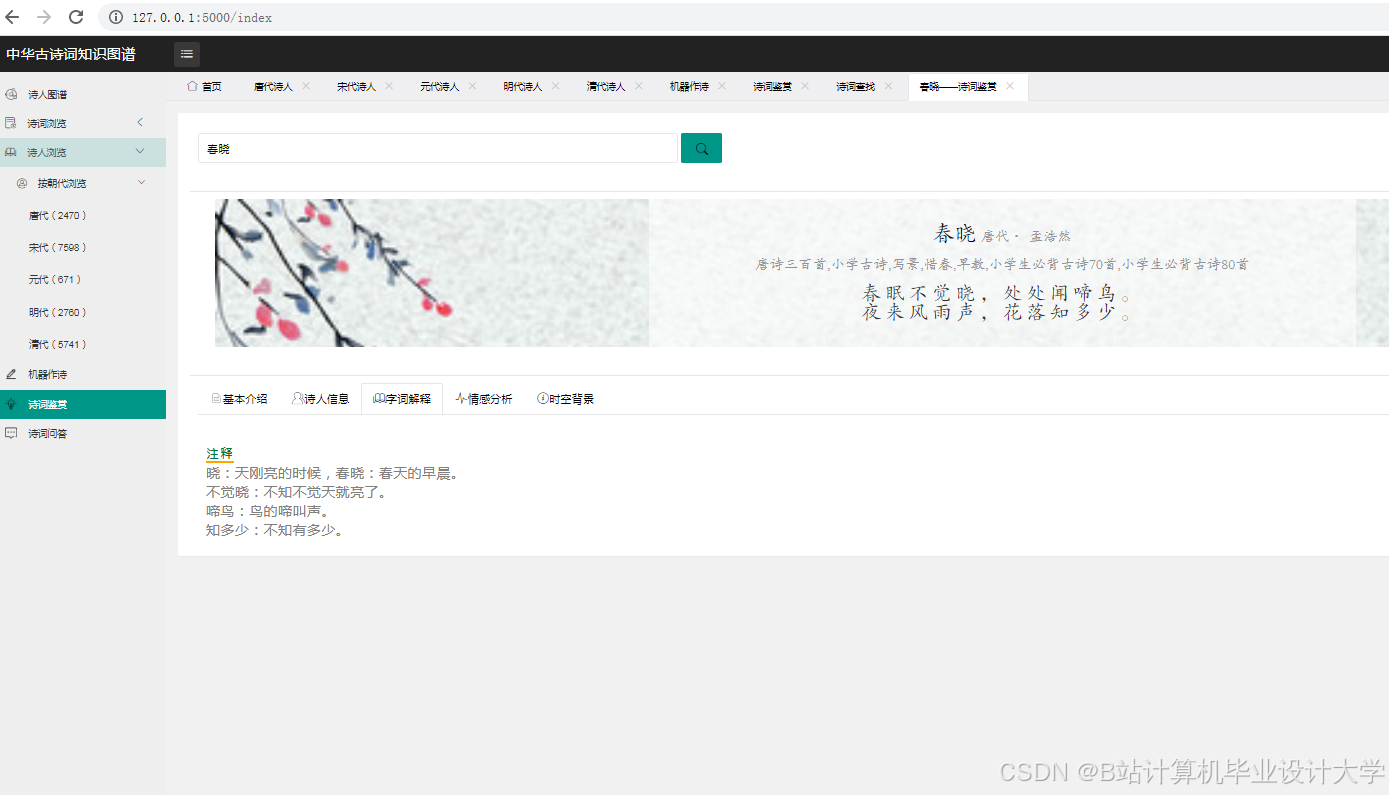
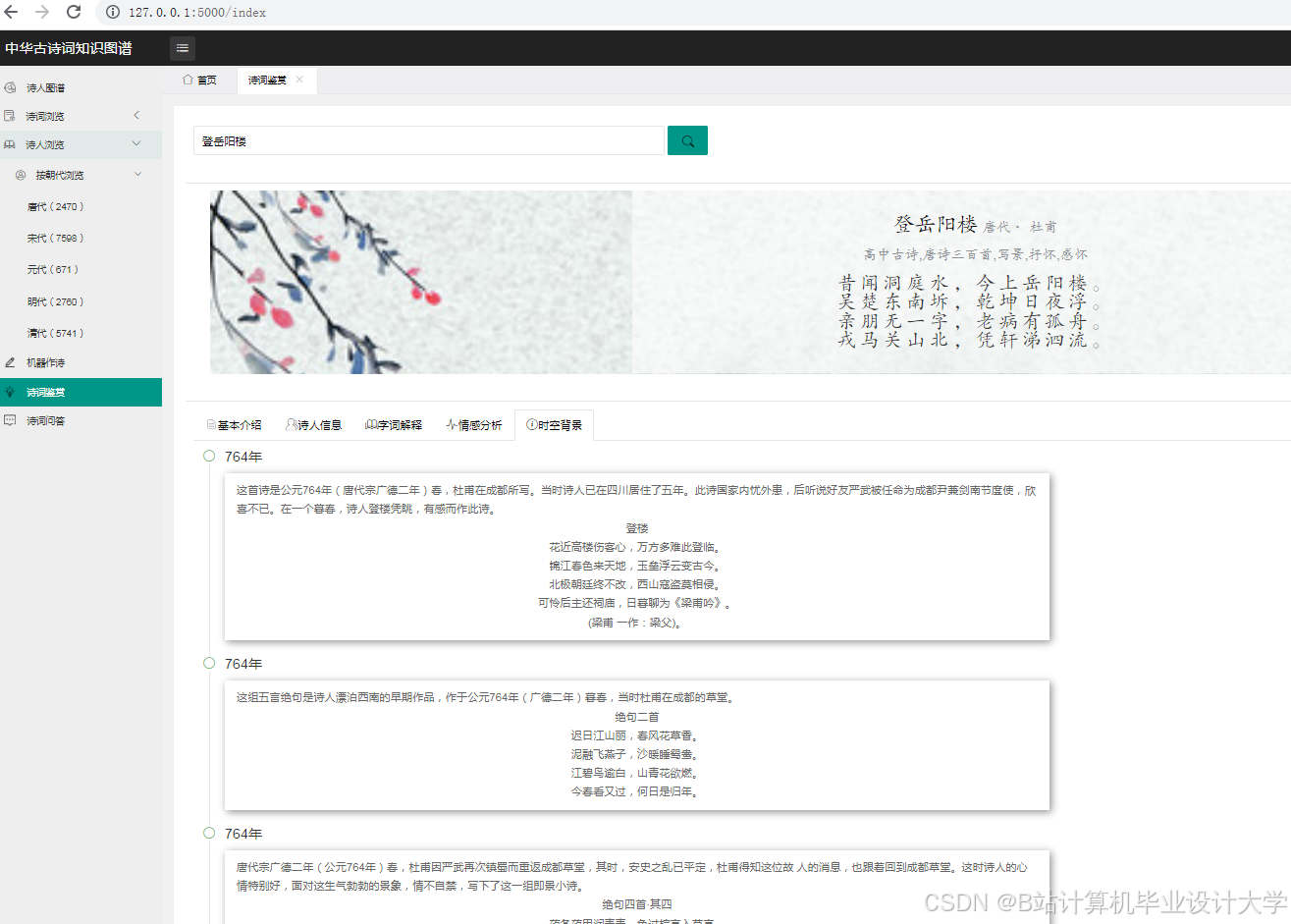
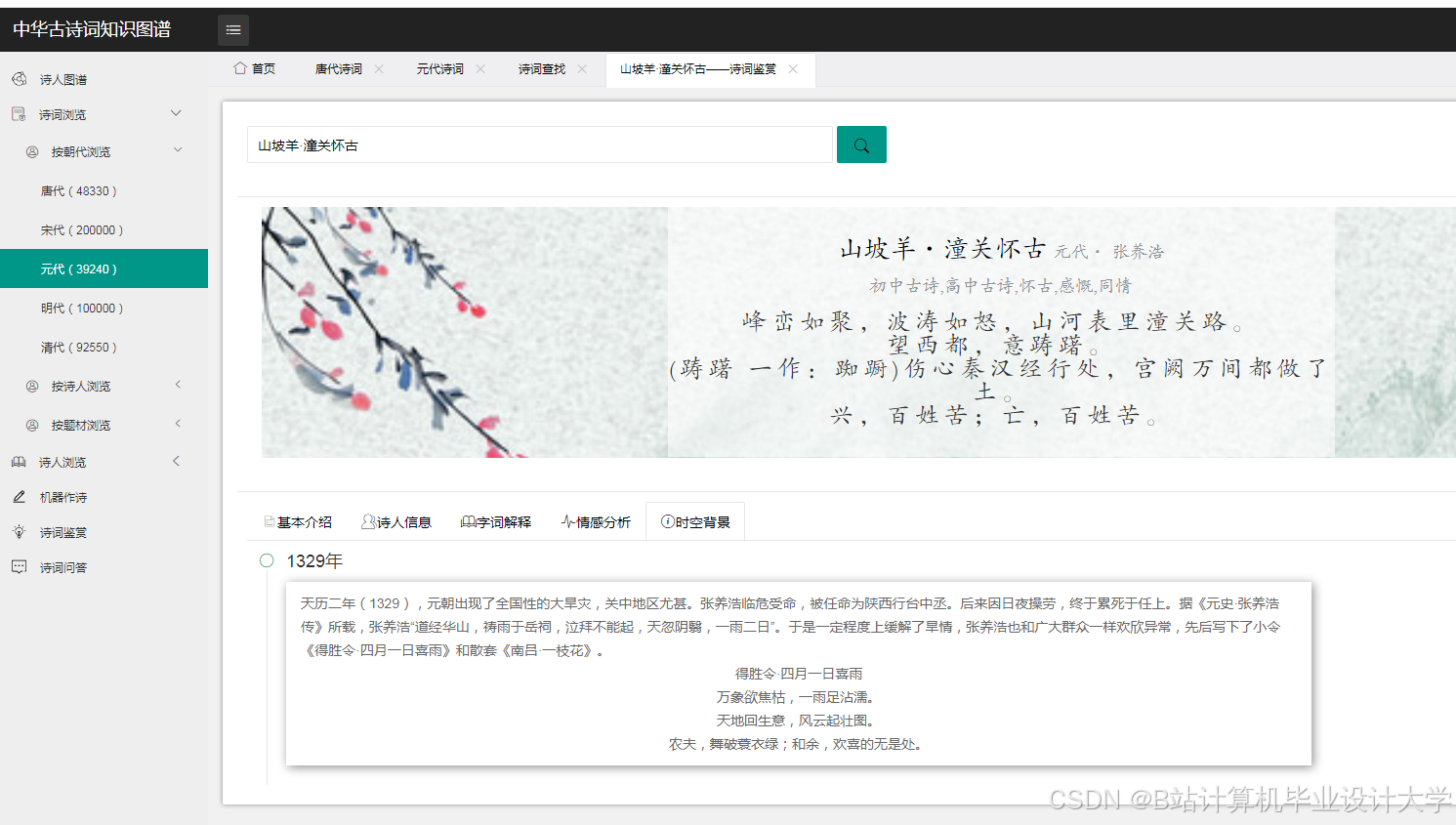
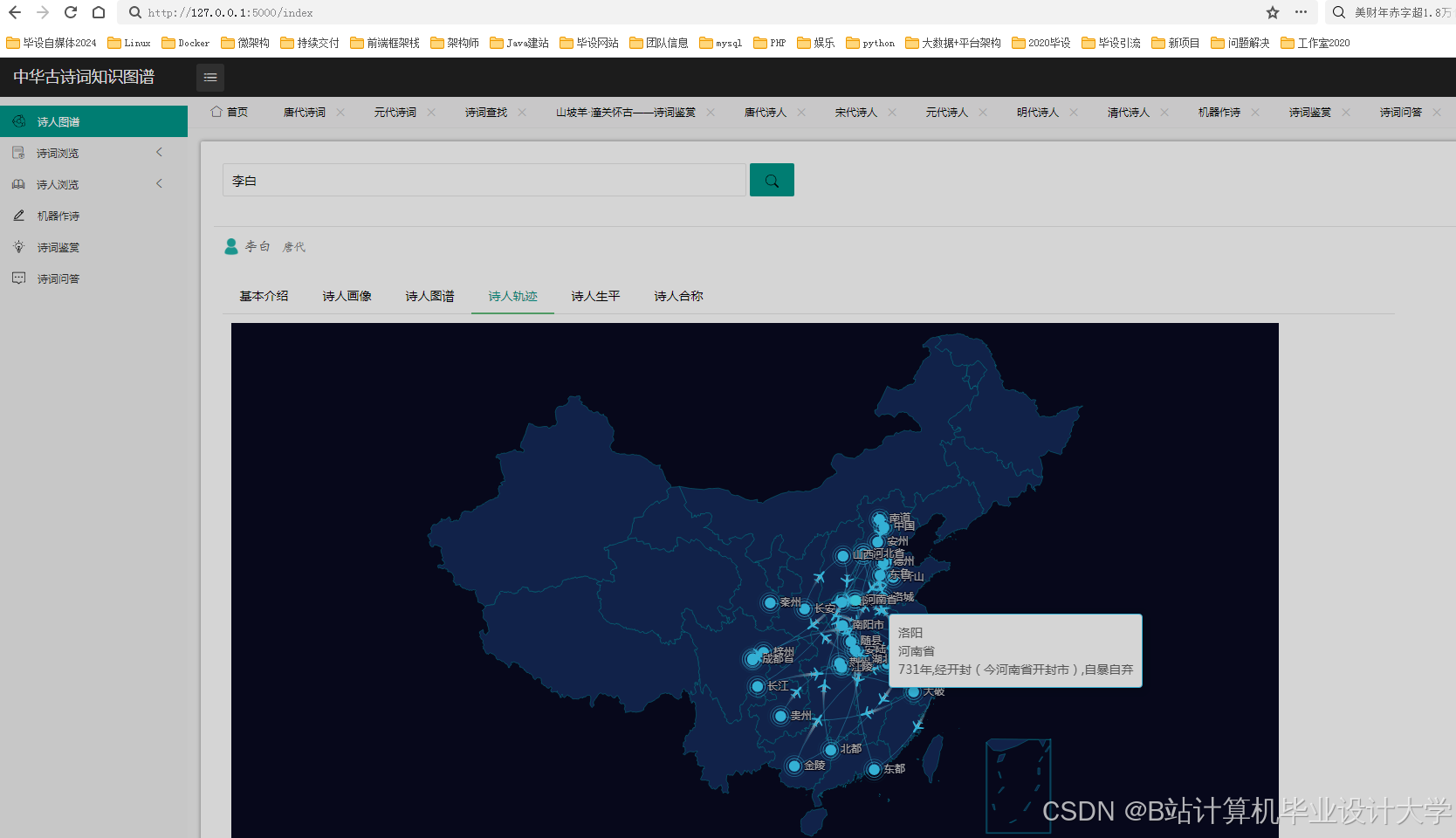
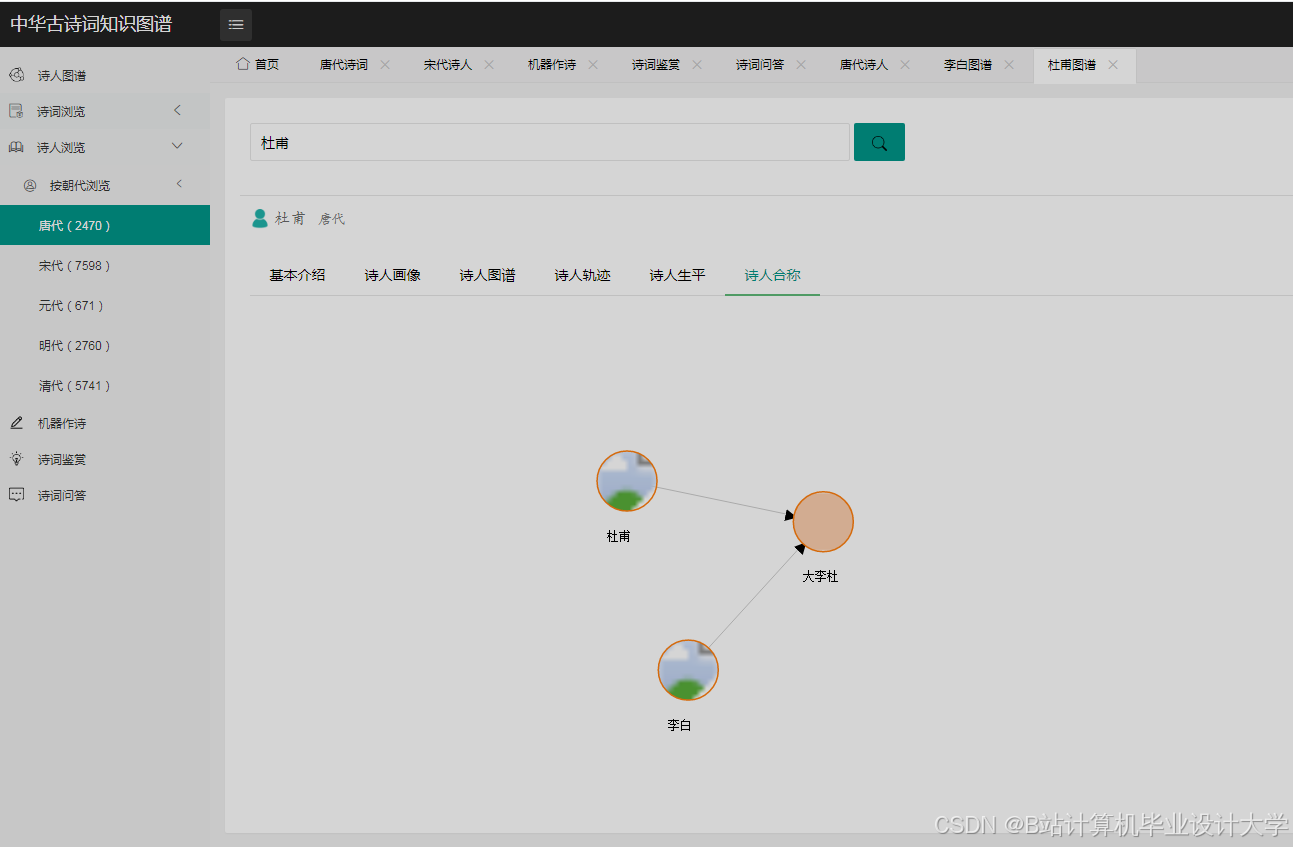
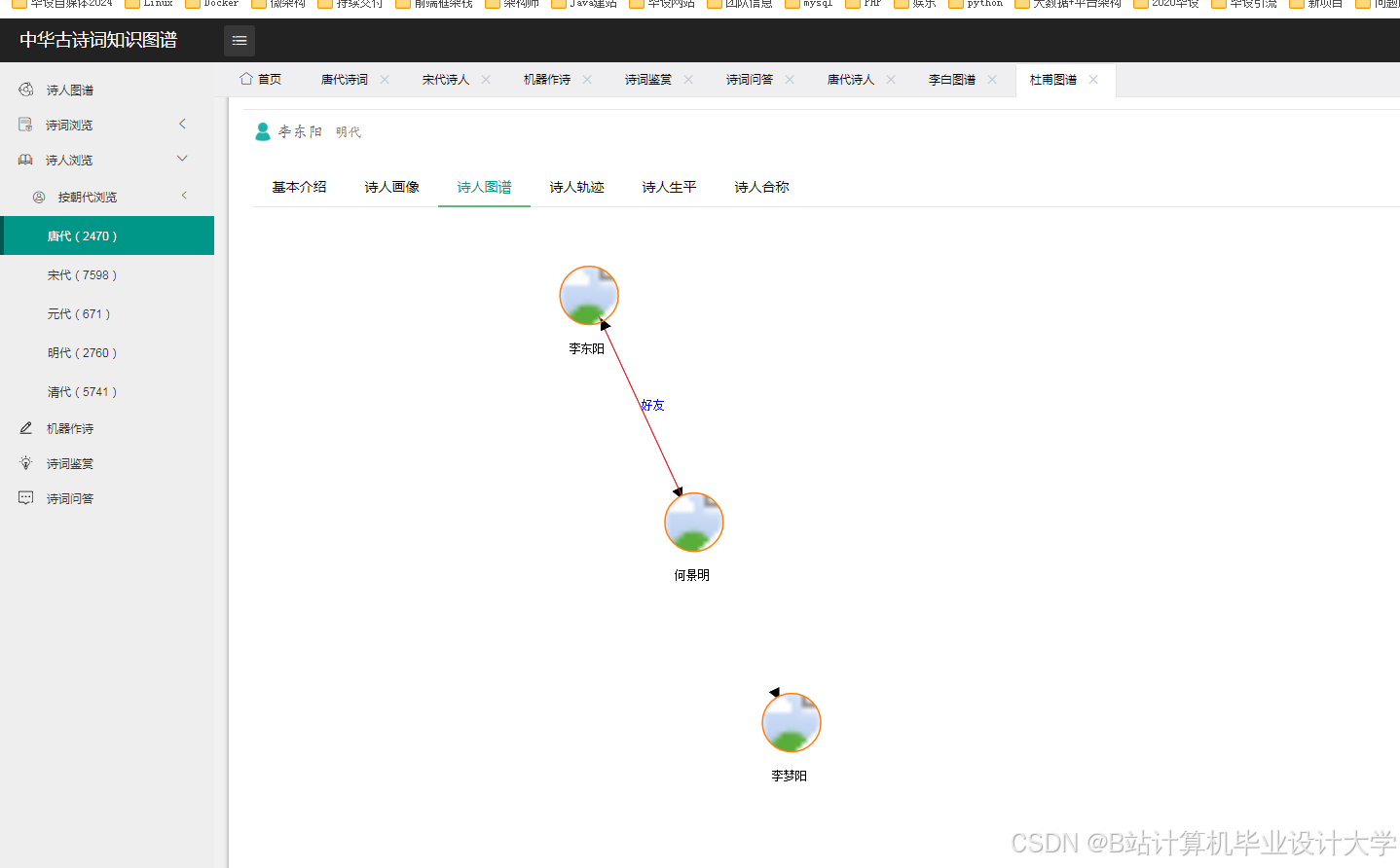
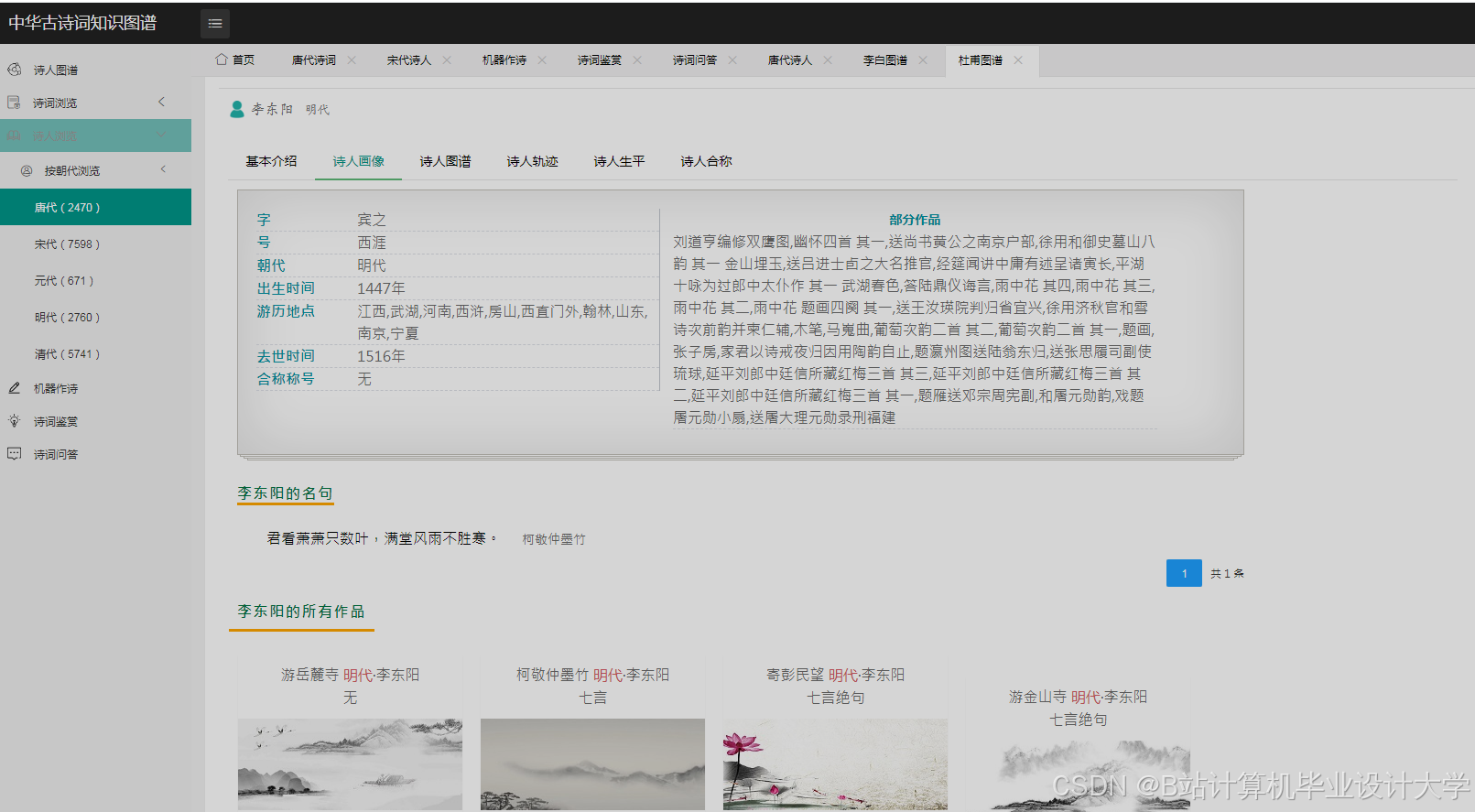
- 可视化设计:设计可视化的布局和样式,如采用力导向布局展示实体间的关系,设置不同的颜色、形状和大小来区分实体类型和关系强度。通过调用可视化库的API,实现图形的绘制和交互功能,如点击节点显示详细信息、缩放和拖动图形等。例如,在D3.js中,通过定义节点和边的样式、布局算法,将知识图谱中的节点和边以图形化的方式展示出来。用户可以通过鼠标悬停查看节点和边的详细信息,如点击诗人节点,弹出该诗人的简介、代表作品列表;点击诗作节点,展示诗词原文、创作背景、情感分析结果等。
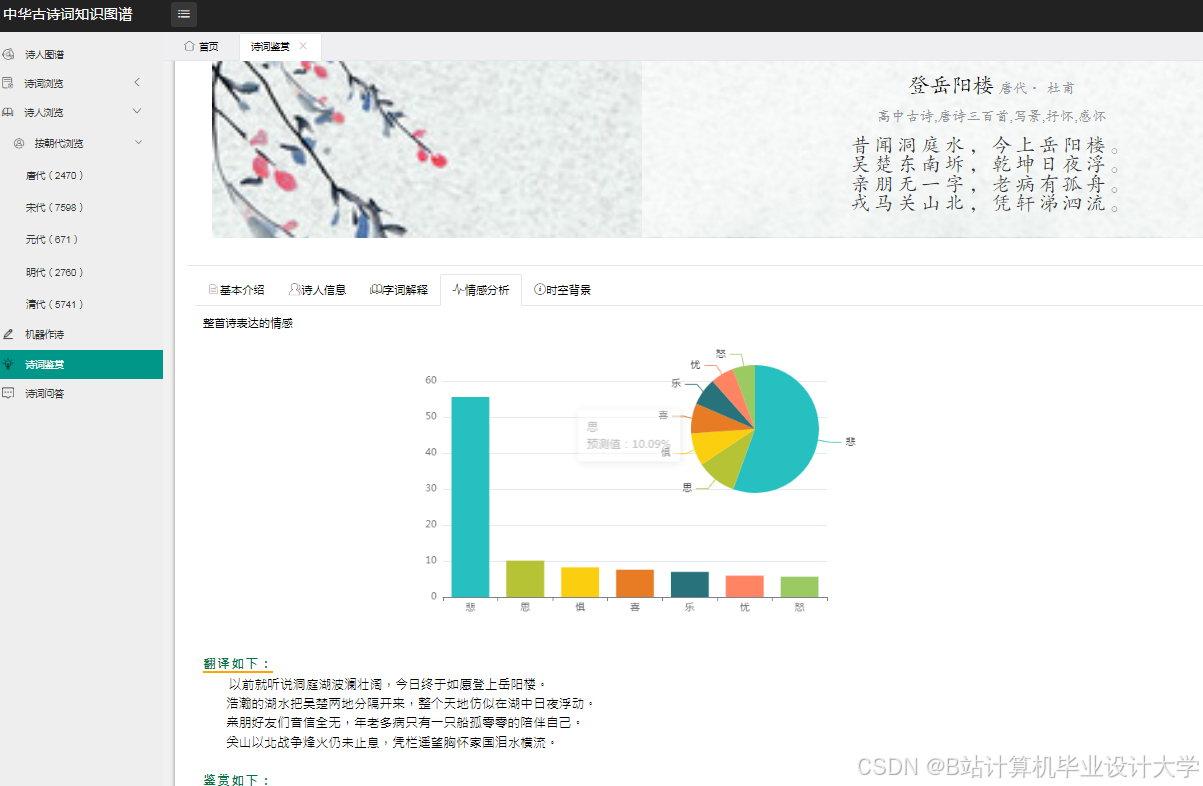
3.5 情感分析
- 数据集选择:采用清华大学人工智能所提供的中文诗词情感分类公开测评数据库,该数据集根据古诗词自身特点进行整理,包含丰富的情感标注信息。
- 模型选择与训练:研究TextCNN(Text Convolutional Neural Networks)、LSTM(Long Short-Term Memory)和Attention机制等多种深度学习模型,并使用多种不同结合的网络结构模型。通过实验证明,TextCNN、BiLSTM和Attention机制结合的模型在古诗词情感分类任务中表现较好。使用PyTorch或TensorFlow框架构建模型,将数据集划分为训练集、验证集和测试集,对模型进行训练和调优。
- 模型评估:使用准确率、召回率、F1值等指标对模型进行评估。根据评估结果,对模型进行优化,如调整模型参数、增加训练数据等,以提高模型的性能。
四、实验与结果分析
4.1 实验环境
硬件环境为Intel Xeon Platinum 8380处理器,256GB内存,NVIDIA A100 GPU;软件环境为Ubuntu 20.04操作系统,Python 3.8,Django 4.2,Neo4j 5.0,TensorFlow 2.6。
4.2 实验数据
从公开数据库和诗词网站采集了5000首古诗词数据,其中4000首用于训练,1000首用于测试。
4.3 实验结果
- 知识图谱构建:实体识别准确率达到90%以上,关系抽取准确率达到85%以上。通过基于规则与机器学习相结合的方法,有效提高了实体识别和关系抽取的准确性。
- 可视化展示:采用力导向布局和圆形布局等多种布局方式,能够清晰展示古诗词知识图谱中实体间的关系。用户可以通过交互操作,如缩放、拖拽、查询等,深入了解古诗词的知识脉络。
- 情感分析:TextCNN、BiLSTM和Attention机制结合的模型在测试集上的准确率达到82%,F1值为0.81。与传统的基于情感词典的方法相比,深度学习模型能够更好地捕捉古诗词中含蓄、委婉的情感表达,提高了情感分析的准确性。
五、结论与展望
本文利用Python技术构建了中华古诗词知识图谱并实现可视化,同时开展了古诗词情感分析研究。通过整合多种技术,系统在知识图谱构建与情感分析方面均取得较好效果,为古诗词的数字化传承、学术研究及教育应用提供了有力支持。
未来研究可以进一步探索和改进深度学习模型的结构和算法,提高模型在古诗词领域的泛化能力和性能。例如,引入更多的语义关系和知识推理方法,丰富知识图谱的内容;结合多模态数据,如图片、音频等,进行更准确的情感判断;加强跨学科的合作与交流,推动古诗词研究的深入发展。通过不断优化和完善技术手段,Python在古诗词领域的应用将更加广泛,为传统文化的传承与创新贡献更大的力量。
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻
更多推荐
 8
8 0
0- 0



 已为社区贡献99条内容
已为社区贡献99条内容

所有评论(0)