
生物科学家代理-基于知识图谱与大模型的智能药物再利用框架!
BioScientist Agent是一个创新的端到端框架,整合生物医学知识图谱、变分图自编码器、强化学习和LLM多智能体系统,用于药物再利用和作用机制阐明。该框架系统性地识别新的药物适应症对及其作用机制,在多项指标上超越现有基准模型,提供可解释的因果关系报告,加速药物研发假设生成,降低实验成本。
简介
BioScientist Agent是一个创新的端到端框架,整合生物医学知识图谱、变分图自编码器、强化学习和LLM多智能体系统,用于药物再利用和作用机制阐明。该框架系统性地识别新的药物适应症对及其作用机制,在多项指标上超越现有基准模型,提供可解释的因果关系报告,加速药物研发假设生成,降低实验成本。

摘要
药物发现过程漫长、资源密集,且成功率不足90%,导致大多数疾病,尤其是罕见或被忽视的适应症,缺乏有效疗法。药物再利用提供了一个成本效益高的替代方案,然而,由于生物医学知识的规模和异质性,系统性地识别新的药物适应症对及其作用机制仍然受到阻碍。我们提出了一个名为生物科学家代理的端到端框架,它将十亿事实的生物医学知识图谱与以下几个部分统一:(i)用于表示学习和基于链接预测的药物再利用的变分图自编码器,(ii)遍历图谱以恢复生物学上可行的机制路径的强化学习模块,以及(iii)协调这些组件的大型语言模型(LLM)多智能体层,使其能够为药物疾病对推断目标途径,并自动生成一致的因果报告。在所有下游任务中,生物科学家代理在各项指标上均超越现有的最先进基准模型,并提供与文献一致的作用机制解释。其开放和模块化设计加速了假设生成,并减少了早期发现阶段的实验开销。
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何系统地识别新的药物适应症对和药物作用机制的合理解释。药物发现过程耗时长、成本高,且成功率不足90%,许多疾病尤其是罕见或未被重视的适应症缺乏有效治疗。药物再利用是一种成本效益高的替代方法,但现有的系统难以应对生物医学知识的规模和异质性。
- 研究难点:该问题的研究难点包括:生物医学知识的规模和异质性、缺乏透明的作用机制证据、以及需要加速假设生成和减少早期阶段的实验开销。
- 相关工作:该问题的研究相关工作包括BioKG、CKG和RTX-KG2等知识图谱的开发,这些图谱整合了广泛的生物医学数据库。此外,大型语言模型(LLMs)在信息检索和文本生成方面也显示出强大的能力。
研究方法
这篇论文提出了BioScientist Agent,一个端到端的框架,用于药物再利用和作用机制阐明。具体来说,
-
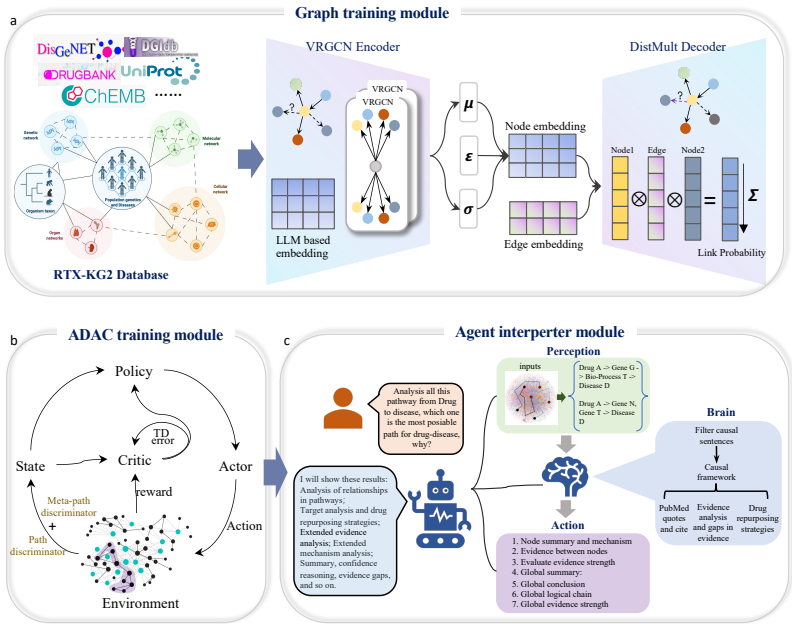
知识图谱预训练:首先,使用变分图自编码器(VGAE)对RTX-KG2进行预训练,以学习低维节点嵌入。VGAE的编码器使用两层关系图卷积网络(VRGCN),解码器使用DistMult方法进行链接预测。
-
对抗性演员-评论家(ADAC)强化学习算法:其次,设计了一个对抗性演员-评论家(ADAC)强化学习算法,用于发现生物学上合理的药物-靶点-疾病路径,并为每个预测提供可解释的作用机制。ADAC模型包括演员网络用于路径生成,评论家网络评估药物-疾病效果,以及元路径判别器和路径判别器来约束和评估中间节点类型和路径长度。
-
LLM驱动的多代理系统:最后,将上述模型整合到一个LLM驱动的多代理系统中,支持四种实际工作流程:(i)疾病到药物搜索或药物到疾病搜索,(ii)路径阐明,(iii)自动生成因果报告。LLM多代理系统包括感知、大脑和行动组件,分别负责从ADAC模块获取路径信息、分析这些路径以及生成最终的研究报告。
实验设计
-
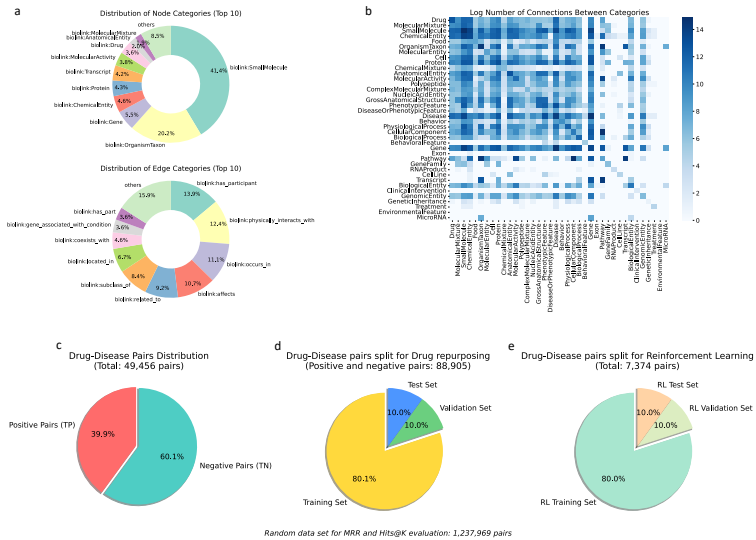
数据集:使用RTX-KG2作为基础知识图谱,版本为v2.9.2,包含6,381,804个节点和40,989,410条边。从MyChemData、SemMedDB Data、NDF-RT Data和RepoDB Data四个数据库中获取真实的药物-疾病关系数据,包括19,755个已知有效的治疗关系和29,701个无效关系,总计49,456个标注的药物-疾病关系。
-
训练集划分:在知识图谱预训练后,将训练集划分为71,180对用于训练,8,857对用于验证,8,868对用于测试。此外,还有一个包含1,237,969对的随机负样本集,用于MRR和Hits@K评估。
-
强化学习训练集:包括5,898个专家演示的药物-疾病对,738对用于验证,738对用于测试。基于分类的药物-疾病对,生成了约1.88百万的四跳推理路径,其中1.51百万在训练集中,190万在验证和测试集中。
结果与分析
-
药物再利用任务:在药物再利用任务中,BioScientist Agent在使用VGAE的模型上展示了优越的性能,准确率和F1分数分别提高了约3.3%到3.7%。关键指标如MRR、Hit@1和Hit@3分别提高了约36.32%、52.76%和42.34%。
-
作用机制路径预测任务:在作用机制路径预测任务中,BioScientist Agent在使用预训练节点特征的模型上也展示了增强的性能,MRR、Hit@1和Hit@10分别提高了约11.01%、15.25%和5.18%。
-
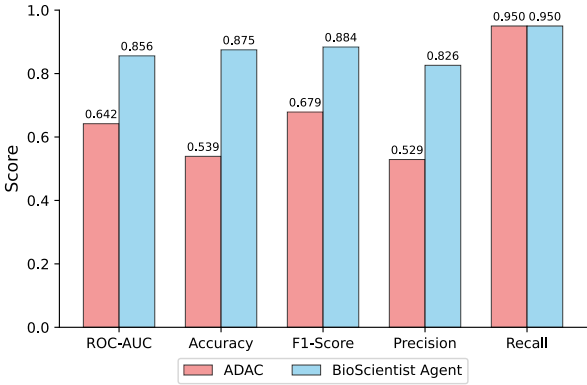
因果路径解释:通过集成LLM基础的因果代理,BioScientist Agent能够评估提出的药物-疾病关系和相应的作用机制。在40个选定的路径上,20个科学测试为正路径和20个随机选择的负路径,Agent的ROC AUC为0.8562,准确率为0.8750,F1-score为0.8837,精确率为0.8261,召回率为0.9500。
总体结论
这篇论文提出的BioScientist Agent框架通过结合知识图谱、强化学习和大型语言模型,提供了一个可扩展且可解释的药物再利用和作用机制阐明平台。该框架加速了药物再利用假设的生成和验证,并加深了对作用机制的理解。尽管存在一些局限性,如需要从头开始训练模型以关联新节点与现有节点,但该框架展示了在生物医学知识密集型任务中的巨大潜力。
论文评价
优点与创新
- 全面的知识图谱整合:论文整合了RTX-KG2(v2.9.2),包含638万节点和4100万边,涵盖了广泛的生物医学知识,显著提升了模型发现新药-疾病关系和探索药物作用机制的能力。
- 变分图自编码器(VGAE):训练了一个VGAE,在药物-疾病链接预测基准测试中达到了最先进的性能。
- 对抗性演员-评论家(ADAC)强化学习算法:设计了一种对抗性演员-评论家强化学习算法,能够发现生物学上合理的药物-靶点-疾病路径,并为每个预测提供可解释的作用机制。
- 多智能体系统:集成了一个由大型语言模型(LLM)驱动的多智能体系统,支持四种实用工作流程:疾病到药物的搜索或药物到疾病的搜索、路径阐明和自动化因果报告生成。
- 可扩展和可解释的框架:提供了一个可扩展和可解释的框架,加速了药物再利用假设的生成和验证,同时加深了对作用机制的理解。
- 文献驱动的因果分析:通过LLM和多智能体系统,能够评估提出的药物-疾病关系及其相应的作用机制,并通过文献代理系统进行解释和实验验证。
不足与反思
- 计算资源限制:由于计算约束,之前的研究很少涉及在大规模知识图谱上进行训练。本研究虽然整合了大量数据,但仍需进一步优化以应对大规模数据处理的需求。
- 节点和边的快速迭代:尽管BioScientist Agent可以快速迭代处理更新的数据库,但仍需从头开始重新训练以将新节点与现有节点关联起来,这一过程耗时且需要大量数据预处理和初始特征提取。
- 局部图表示能力:未来工作旨在建立快速整合新节点和边关系的机制,包括通过局部图表示能力和引入更多节点表示模型来增强其表示能力。
- 实验设计和验证:未来的研究将优化实验设计,包括在细胞系和动物模型中进行实验,以验证药物再利用策略的有效性,并探索组合疗法。
关键问题及回答
问题1:BioScientist Agent在药物再利用任务中具体使用了哪些评估指标?这些指标是如何定义和计算的?
在药物再利用任务中,BioScientist Agent使用了多个评估指标来衡量其性能,主要包括准确率(Accuracy)、F1分数(F1 Score)、平均倒数排名(Mean Reciprocal Rank, MRR)和Top-K命中率(Hit@K)。这些指标的定义和计算方法如下:
- 准确率(Accuracy):正确预测的数量除以总预测数量。
- F1分数(F1 Score):是准确率和召回率的调和平均值,综合考虑了假阳性和假阴性。
- 平均倒数排名(Mean Reciprocal Rank, MRR):对于每个真实药物-疾病对,将其在所有候选对中的排名取倒数后求平均值。MRR越高,表示模型排名越靠前。
- Top-K命中率(Hit@K):在所有候选对中,前K个结果中有多少个是真实药物-疾病对的百分比。
这些指标通过比较模型预测的排名与真实排名来评估模型的性能,特别适用于排序任务。
问题2:BioScientist Agent如何利用对抗性演员-评论家(ADAC)强化学习算法来发现生物学上合理的药物-靶点-疾病路径?
- 演员网络(Actor):负责生成可能的药物-靶点-疾病路径。演员网络根据当前状态生成动作,即下一个节点。
- 评论家网络(Critic):评估演员生成的路径的有效性,给出一个评分。评论家网络通过比较生成的路径与已知有效路径的相似度来评估路径的质量。
- 元路径判别器(Meta-path Discriminator):确保生成的路径符合特定的生物学元路径模式,例如“药物-基因-蛋白质-疾病”。
- 路径判别器(Path Discriminator):评估路径的中间节点是否合理,确保路径的连续性和生物学上的合理性。
通过这些组件,ADAC模型能够在训练过程中不断优化路径生成策略,最终生成生物学上合理的药物-靶点-疾病路径。
问题3:BioScientist Agent在解释药物-疾病关系的作用机制时,如何利用大型语言模型(LLM)和多代理系统?
- LLM多代理系统:包括感知、大脑和行动三个组件。
- 感知组件:从ADAC模块获取生成的路径信息。
- 大脑组件:使用LLM分析这些路径,首先通过代理系统筛选出相关的PubMed摘要,然后使用预定义的因果推理框架分析这些摘要,提取因果关系句子。
- 行动组件:生成最终的研究报告,包括实体摘要、机制、实体间关系分析、支持和矛盾证据分析、药物再利用策略和路径链式思维推理。
- 因果推理框架:通过查询PubMed摘要,找到与药物和疾病相关的句子,并使用LLM对这些句子进行分析,提取因果关系。LLM输出的引用和评分用于评估每条路径的证据强度和因果关系。
通过这种方式,BioScientist Agent能够生成详细的作用机制报告,提供透明且可验证的因果关系解释。
AI大模型学习和面试资源
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 22
22 0
0- 0



 已为社区贡献78条内容
已为社区贡献78条内容

所有评论(0)