
大模型微调完全指南:从理论到实践的问答合集
本文系统介绍了大模型微调全流程,包括预训练与微调的区别、模型选择、数据处理、参数调整和效果评估。重点强调数据质量优先,推荐LoRA技术降低算力成本,提出混合训练策略防止"灾难性遗忘"。从基础知识到实战技巧,为开发者和研究人员提供全面的大模型微调技术指南,助力高效定制专业领域AI模型。
本文系统介绍了大模型微调全流程,包括预训练与微调的区别、模型选择、数据处理、参数调整和效果评估。重点强调数据质量优先,推荐LoRA技术降低算力成本,提出混合训练策略防止"灾难性遗忘"。从基础知识到实战技巧,为开发者和研究人员提供全面的大模型微调技术指南,助力高效定制专业领域AI模型。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
Q1
Q:我想让一个AI学会某个新本领(比如看病、写法律文书),是该先教它基础知识,还是直接教它具体操作?
A: 这就像培养一位医生。你不能直接让一个刚毕业的医学生去开刀,得先让他学好解剖、生理、病理这些"基础医学知识"(这对应"预训练")。等他有了扎实的底子,再带他去临床实习,看他怎么诊断、开药、跟病人沟通(这对应"微调/SFT")。
- 预训练 (Pre-training): 是在海量的互联网文本(书籍、网页、文章)上,让模型学习语言的规律、世界的基本常识。这个阶段就像大学四年的通识教育,目标是成为一个"博学"的人。
- 微调 (Fine-tuning/SFT): 是在特定领域的高质量数据集上(比如10万份病历对话、1000个法律咨询问答),让模型学习如何在这个特定场景下"说话"和"思考"。这个阶段就像医学院的临床实习,目标是成为一个"专才"。
所以,如果你想让模型真正掌握一个领域,最好的方法是"两者结合":
1.第一步(打基础): 先用领域内的专业文档(如医学教材、法律条文、技术手册)进行"二次预训练"。这能让模型"闻到"这个领域的味道,熟悉专业术语和行文风格。
2.第二步(练技能): 再用高质量的问答对(如"患者说头痛,医生怎么问?“、“合同里这条款是什么意思?”)进行"指令微调(SFT)”。这教会模型如何在该领域内进行有效的对话和任务执行。
小贴士: 如果你手头只有少量的问答数据(比如不到1万条),那直接做SFT也行,相当于让一个聪明但没经验的实习生直接上手,效果可能也不错。但如果数据量巨大,那就一定要先做二次预训练,否则模型会像一个只会背答案的书呆子,缺乏真正的理解。
Q2
Q:做完预训练和微调,我的模型需要多少"脑力"(显存)才能跑起来?
A: 训练大模型就像开一艘超级油轮,需要巨大的动力(显存)。想象一下,一个70亿参数的模型,其内部的"神经连接"数量堪比一个小型城市的人口。
-
全参数微调 (Full Fine-tuning): 这是最"暴力"的方式,你需要更新模型里的每一个参数。对于一个7B(70亿)的模型,官方推荐配置是"4张A100 40G显卡",总共160G显存。这就像要给整艘油轮的所有零件都换新,成本极高。
-
为什么这么贵? 因为不仅要存模型本身,还要存:
- 梯度: 每次计算后,模型想知道每个参数"错"在哪,需要记下来(占内存最大头)。
- 优化器状态: 优化器(如AdamW)为了更聪明地调整参数,会记录历史信息,这也占很大空间。
- 中间激活值: 计算过程中产生的临时数据。
省钱妙招: 别急着全参数微调!现在流行用 LoRA 技术。这就像给你的油轮加装了一个小小的、可拆卸的"辅助推进器"(LoRA模块)。你只需要训练这个小推进器,而不用动油轮本身的引擎(主模型参数冻结)。这样,一台普通的3090显卡(24G)就能搞定7B模型的微调,效率提升百倍!
Q3
Q:微调时,我应该选一个"聊天型"模型(Chat)还是"基础型"模型(Base)当起点?
A: 这取决于你有多少"弹药"(数据)和"预算"(算力)。
- 选"聊天型"模型 (Chat Model, 如 ChatGLM, Llama-Chat):
- 优点: 它已经接受过大量对话数据的微调,天生就知道怎么跟人聊天,语气自然,能理解"你好"、"谢谢"这种日常用语。它就像一个已经通过了"人际交往课"的毕业生。
- 适合: “你只有几千到一万条高质量的领域对话数据”。你想快速让它变成一个专业的"客服"或"顾问",而不是一个冷冰冰的数据库。这时候用Chat模型,能事半功倍,避免"把模型弄傻"。
- 选"基础型"模型 (Base Model, 如 LLaMA, Qwen-Base):
- 优点: 它没有被任何特定对话格式"污染",像一张白纸,拥有最强的通用语言理解和生成能力。它就像一个天赋异禀但还没上过社会课的天才少年。
- 适合: “你有十万甚至百万条高质量的领域数据”,并且你打算从头开始,构建一个全新的、完全属于你自己的领域专家。你有足够的资源和时间,想让它既懂专业,又保持强大的通用性。
关键提醒: 如果你只用极少量的领域数据去微调一个Base模型,它可能会因为"学得太少"而忘记自己原本的本事,变得"傻乎乎"的。所以,数据少就选Chat,数据多且想追求极致,就选Base。
Q4
Q:微调用的数据,怎么造出来才靠谱?
A: 数据的质量,直接决定了你能飞多高。垃圾数据进去,垃圾模型出来。造数据就像做饭,食材不好,再好的厨艺也没用。
- 核心原则:质量 > 数量。1000条精心设计的优质问答,远胜于10万条乱七八糟的网络爬虫数据。
- 结构要清晰:
- 输入 (Input): 清晰的问题或指令。比如:“请根据以下病历摘要,给出初步诊断建议。”
- 输出 (Output): 精准、专业、符合人类期望的答案。比如:“根据患者的持续性胸痛、心电图ST段抬高表现,高度怀疑急性心肌梗死,建议立即进行冠脉造影检查。”
- 格式统一: 所有样本必须遵循同一个模板,模型才能学到规律。就像所有菜谱都要有"食材"、“步骤”、"火候"一样。
- 多样化与平衡:
- 不要只收集"简单问题"的答案。要覆盖各种难度、不同角度、甚至错误的反例(用于教会模型识别错误)。
- 如果你有多个子任务(如诊断、开药、解释),确保每个任务的数据量差不多,别让一个任务"压倒"了其他任务。
- 去污除杂:
- 删除重复、无意义的词(“嗯”、“啊”、“那个…”)。
- 去掉敏感、不安全或明显错误的信息。
- 如果是对话,可以适当"压缩"冗长的历史,保留最关键的信息,避免"显存爆炸"。
比喻: 构建微调数据集,就像是为你的AI助手建立一个"专业百科+案例库"。每一条数据都是一个精心挑选的案例,供它学习和模仿。
Q5
Q:我的模型微调后,怎么感觉它"变傻了"?原来那些常识它都不会了!
A: 这就是著名的"灾难性遗忘"!
- 为什么会发生?
- 数据偏差太大: 你用的微调数据全是"专业术语",模型以为这是唯一正确的语言,把之前学的日常用语、常识全都当成了"噪音"给扔了。
- 学习太猛: 学习率设置太高,或者微调的数据量相对预训练数据来说太小,导致模型"用力过猛",把原有的知识结构彻底覆盖了。
- 怎么解决?
- 混合训练 (Mix & Match): 在你的领域数据中,“掺入一定比例的通用数据”(比如10%-20%的通用问答、百科知识)。这就像让学游泳的音乐家每天还练一小时钢琴,维持肌肉记忆。通常,“领域数据 : 通用数据 = 1:5 到 1:10” 是个不错的起点。
- 降低学习率: 不要用很大的学习率(比如 > 2e-5)。用一个小一点的学习率,让模型"温柔地"调整。
- 使用LoRA: LoRA只修改一小部分参数,对原有权重影响小,能有效缓解遗忘。
关键点: SFT不是为了"灌输"知识,而是为了"激发"和"引导"模型已有的潜力。它的目标是让模型学会"如何回答问题",而不是"知道所有答案"。
Q6
Q:微调的时候,模型到底在学什么?它和预训练有什么本质区别?
A: 想象两个不同的考试:
- 预训练: 考的是"完形填空"。给你一句话:“今天天气真______”,让你猜下一个字是什么。模型的任务是预测每一个词的概率,它学的是语言的统计规律和上下文关联。损失函数计算的是"整个句子"的预测误差。
- 指令微调 (SFT): 考的是"问答题"。题目是:“描述计算机主板的功能?”,你希望模型写出:“计算机主板是计算机中的主要电路板,是系统的支撑。” 模型的任务是:“看到问题,生成一个完美的答案”。而且,在计算损失时,“只看答案部分是否正确”,问题部分的预测误差会被忽略。
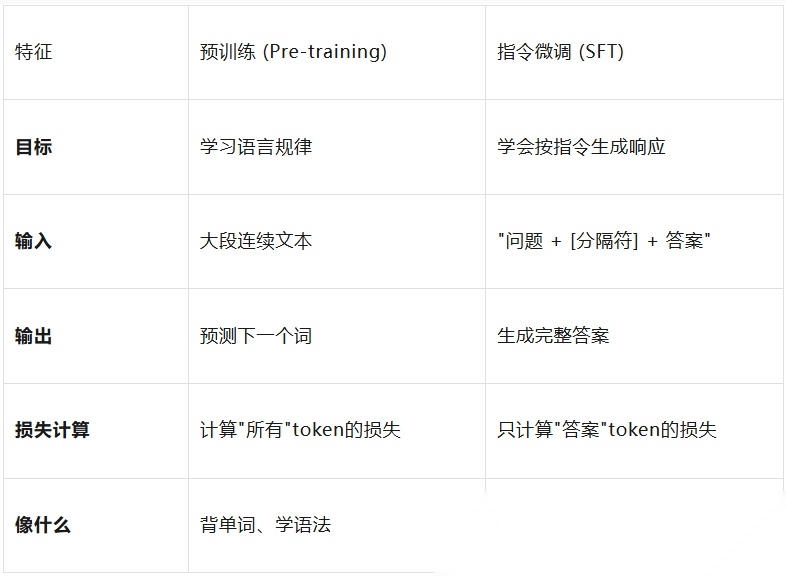
总结: SFT是在教模型"“听话”“和”“表达”“。它利用人类提供的高质量问答对,告诉模型:“当你看到这样的问题,就应该这样回答。” 这让模型从"一个会猜词的机器"变成了"一个能完成任务的智能体”。
Q7
Q:训练时,batch size(一次处理多少数据)该怎么设?太小或太大会怎样?
A: Batch Size 就像你一次上课的学生人数。
- Batch Size 太小 (比如每次只教1个学生):
- 问题: 教学方向不稳定,波动太大。今天讲得好,明天可能就偏了。就像一个人在风浪中划船,船身晃得厉害。
- 原因: 每次更新参数基于的"梯度"(教学反馈)噪声太大,不够代表全体学生的平均水平。
- Batch Size 太大 (比如一次教1000个学生):
- 问题: 效率低下,浪费资源。老师费劲巴拉地备课,但每个学生的个性化反馈几乎得不到。而且,计算资源消耗巨大,可能直接"爆显存"。
- 原因: 梯度非常精确,但收敛速度慢,需要更多的计算步骤才能达到最佳效果,总耗时未必减少。
- 理想情况: 找到一个"黄金平衡点"。通常,“批量越大,可以配合更大的学习率”。但超过某个临界点后,收益就会急剧下降。你可以先用一个中等大小(如64或128)试试,然后根据显存和训练速度慢慢调整。
小技巧: 如果你发现数据量增大就OOM(显存不足),不要慌!用"梯度累积"。你设定batch_size=128,但实际一次只加载32条数据,计算完梯度不更新,攒够4次(32*4=128)再一次性更新。这就像把4个小班的作业批改完,再统一讲评。
Q8
Q:训练过程中,loss(损失值)突然"跳崖"或"飙升",怎么回事?
A: Loss突刺就像你家的温度计突然从25°C飙到50°C,然后又回落,非常诡异。
- 为什么会出现? 核心罪魁祸首是"Adam优化器"的"副作用"。
- Adam优化器像一个聪明的管家,它会根据过去梯度的变化趋势来调整"前进的步伐"。但在大模型里,如果"浅层网络"(离输入近的部分)长时间没更新(比如因为梯度太小),而深层网络(离输出近的部分)一直在动,它们之间的"默契"就被打破了。
- 当某次更新,浅层网络突然"醒过来"并剧烈变动时,它和深层网络的状态严重脱节,整个系统瞬间陷入混乱,导致loss暴涨。
- 怎么解决?
- 减小**
epsilon** (ε)": Adam中的一个小常数,控制稳定性。把它调小一点,能让优化器更敏感,减少震荡。 - 减小浅层梯度: 有一种方法是,直接把浅层网络的梯度乘以一个小于1的系数(比如0.1),让它"轻一点"地动。这就像给最活跃的那几个学生戴了个"静音耳机",让他们别太吵。
- 更换数据批次: 如果发现某个批次的数据特别"脏",导致loss突刺,就跳过它,换一批干净的数据继续。
- 降低学习率: 这是最简单的办法,但治标不治本。
- 避免FP16精度溢出: 使用混合精度训练时,如果数值缩放(upscale)设置太小,可能导致梯度下溢(变成0),加剧了"浅层不更新"的问题。适当提高upscale值。
记住: 有时候loss突刺后,模型自己能"恢复"回来;但有时,它就再也回不去了,训练彻底失败。所以,一定要做好"断点保存",一旦发现loss异常,立刻回滚到之前的稳定版本。
Q9
Q:怎么判断我的微调模型是不是真的变强了?
A: 不能光看训练loss低,那只是"抄作业"得分高。真正的考验是"期末考试"。
- 构建两套"考卷":
- 选择题/客观题评测集 (自动评测): 准备几百道标准化的领域问题,答案明确。用BLEU、ROUGE等指标自动打分。这就像期中考试,方便、快速,能筛选出明显不合格的模型。
- 开放题/人工评测集 (精筛): 准备几十个贴近真实应用场景的复杂问题。找领域专家(医生、律师、工程师)来人工评判模型的回答是否专业、准确、有用。这就像毕业答辩,虽然慢,但最真实,能发现自动评测发现不了的"细微差别"和"逻辑漏洞"。
关键: 自动评测是"初筛",人工评测是"终审"。两者缺一不可。一个模型可能在自动评测中拿高分,但回答却生硬、不切实际;反之,一个在人工评测中表现优秀的模型,才是真正有价值的。
Q10
Q:需要给模型"扩词表"吗?就是增加一些专业词汇。
A: 这就像给一个只会说普通话的翻译,增加一本《金融术语词典》。
- 好处: “显著提升解码效率”。模型遇到"ATP"、“胰岛素抵抗”、“违约风险"这些词时,不再需要把它拆成"A-T-P”、"胰-岛-素-抵-抗"这几个字去猜,可以直接当作一个整体单元处理。这会让生成速度更快,响应更流畅。
- 坏处: 对最终回答的"准确性"或"智力水平"提升"有限"。模型的核心能力在于理解和推理,不是靠认识多少个词。
- 结论: “有必要,但不是优先级最高的”。如果你的领域术语非常多(比如生物医学),强烈建议扩词表。如果只是少数几个词,可以先不扩,看看效果再说。
Q11
Q:训练中文大模型有什么特别的经验?
A: 中文有它独特的挑战和优势:
- 词表是关键: 中文不像英文那样天然有空格分隔。直接用英文的词表训练中文,效率极低。“第一步必须扩充中文词表”,加入常用成语、专业术语、网络用语等,让模型能"吃透"中文。
- 数据质量是王道: 中文互联网上的数据鱼龙混杂。“优先选择高质量数据”:权威网站、学术论文、新闻报道、经典文学作品。数据质量比单纯的数量重要十倍。
- 数据分布很重要: 单纯用英文数据训练的模型,对中文理解很差。“必须加入大量的纯中文数据”。即使你有英文数据,也要保证中文占比足够高。
- 指令微调数据要地道: 构建的问答对,要符合中文用户的表达习惯。不要生搬硬套英文的prompt格式。
终极建议: 模仿成功者的路线——先用海量中文文本做"二次预训练",再用高质量中文指令数据做"SFT"。最后,别忘了"RLHF"(用人类反馈再优化)这一关,这是让模型"情商"上线的关键一步
Q12
总结一下,微调大模型的最佳实践有哪些?
A: 来,一份超实用的"微调指南":
- 目标先行: 明确你要模型干什么?是问答?写作?分析?这决定你用什么数据和方法。
- 数据为王: 花80%精力在"构建高质量、多样化的微调数据集"上。宁缺毋滥。
- 善用LoRA: “除非你有充足的算力预算,否则一律首选LoRA”。省时、省钱、省显存,效果不打折。
- 混合训练防遗忘: "领域数据 + 通用数据"一起训,比例大概1:5~1:10。
- 选对基座: 数据少 → 选Chat模型;数据多、想追求极致 → 选Base模型。
- 调参有方: 学习率不宜过大(2e-5起步),使用AdamW优化器,梯度裁剪设为1.0。
- 监控异常: 密切关注loss变化,警惕"突刺"现象,及时回滚。
- 全面评估: 用"自动评测"和"人工评测"双保险,别被单一指标蒙蔽。
- 勤做备份: 训练过程漫长,定期保存checkpoint,防止前功尽弃。
- 别怕试错: 微调是门手艺活,多尝试,多总结,你的模型会越来越聪明!
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐

 11
11 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)