
大模型技术深入浅出--hugging face的transformers对于Transformer架构的实现
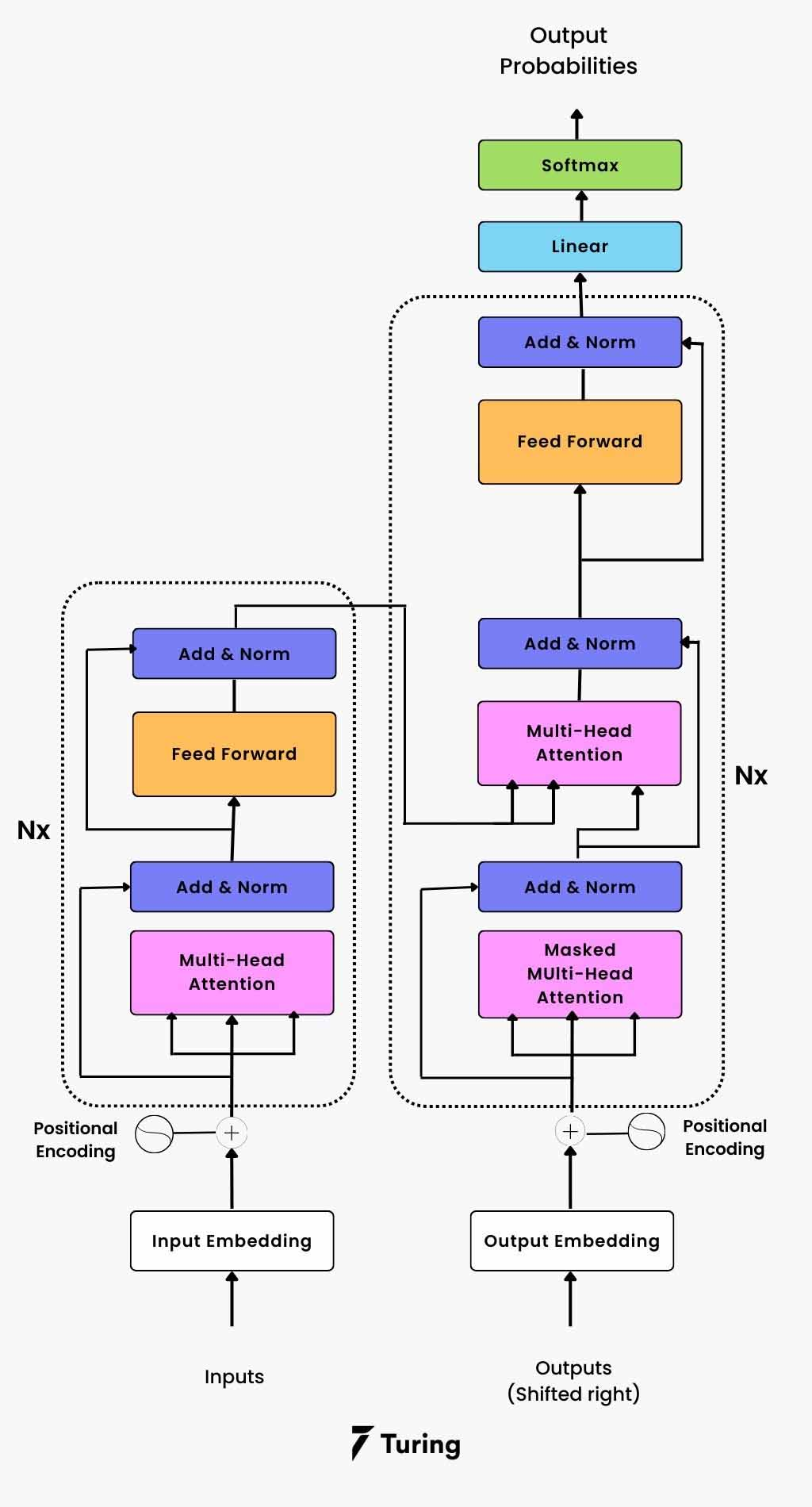
右侧为经典Transformer架构,数据流向如下:输入序列首先通过转换为向量表示加入以保留序列中的位置信息向量流经编码器的N个层解码器接收移位的输出序列的和解码器处理编码器的输出并生成预测最后通过层和转换为概率分布。
|
右侧为经典Transformer架构,数据流向如下:
|
 |
本文将结合hugging face的transformers项目对于Transformer架构的实现,来加深对Transform的理解:
Self-Attention 机制
Self-Attention 是 Transformer 的核心组件,实现了序列内部元素之间的关联建模。
核心实现 (基于 BERT)
class BertSelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None, is_causal=False, layer_idx=None):
super().__init__()
# 检查隐藏层大小是否能被注意力头数整除
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.config = config
self.num_attention_heads = config.num_attention_heads # 注意力头数
self.attention_head_size = int(config.hidden_size / config.num_attention_heads) # 每个头的维度
self.all_head_size = self.num_attention_heads * self.attention_head_size # 总维度
self.scaling = self.attention_head_size**-0.5 # 缩放因子 1/√d_k
# Q、K、V 线性变换层
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = position_embedding_type or "absolute"
def forward(self, hidden_states, attention_mask=None, head_mask=None, **kwargs):
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.attention_head_size)
# 生成 Q、K、V 矩阵
# [batch_size, seq_len, hidden_size] -> [batch_size, num_heads, seq_len, head_size]
query_layer = self.query(hidden_states).view(*hidden_shape).transpose(1, 2)
key_layer = self.key(hidden_states).view(*hidden_shape).transpose(1, 2)
value_layer = self.value(hidden_states).view(*hidden_shape).transpose(1, 2)
# 调用注意力计算函数
attn_output, attn_weights = eager_attention_forward(
self, query_layer, key_layer, value_layer, attention_mask,
dropout=0.0 if not self.training else self.dropout.p,
scaling=self.scaling, head_mask=head_mask, **kwargs
)
# 重塑输出形状
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
return attn_output, attn_weights关于Dropout
在经典的 Transformer 架构图中,为了保持图的简洁性,Dropout 层通常不会单独画出来,但它是结构中不可或缺的一部分。
在标准的 Transformer 论文和实现中,Dropout 主要作用于以下两个关键环节,作为正则化手段:
1. 嵌入层和位置编码之后(Embedding & Positional Encoding Output)
-
作用位置: 在 Input Embedding(输入嵌入)和 Positional Encoding(位置编码)相加之后,作为编码器和解码器堆栈的真正输入之前。
-
目的: 对词向量及其位置信息进行随机置零,防止模型过度依赖输入序列的特定位置或特定词向量,从而增强模型的鲁棒性。
2. 每个子层的输出之后(Sublayer Output)
Dropout 应用在每个子层(Sublayer)的输出进入 Add & Norm 环节之前,具体来说是:
A. 在注意力机制之后
-
作用位置: 在 Multi-Head Attention(多头注意力)或 Masked Multi-Head Attention(掩码多头注意力)的输出,与原始输入相加(Add)进行残差连接之前。
-
在代码中的体现: 这对应于您之前代码中,对 注意力权重(Attention Probabilities)进行 Dropout,这是 Transformer 中最关键的 Dropout 之一。
B. 在前馈网络之后
-
作用位置: 在 Feed Forward(前馈网络,或称位置感知前馈网络)的输出,与前一个子层的输出相加(Add)进行残差连接之前。
-
目的: 防止前馈网络中的神经元产生过度共适应性,确保每个神经元学习到的特征更加独立有效。
Dropout 是一种在神经网络训练中非常重要的正则化(Regularization)技术,它主要用于防止模型过拟合(Overfitting)。
在您提供的 BertSelfAttention 代码中,Dropout 应用于注意力权重(Attention Probabilities),即 Softmax 之后的输出。
Dropout 的工作原理非常直观:
-
随机“关闭”神经元:在每一次训练的迭代中,Dropout 会以一个预先设定的概率 p(在 BERT 中通常是
config.attention_probs_dropout_prob)随机地将网络中的一部分神经元的输出设置为零。 -
不参与前向和反向传播:这些被“关闭”的神经元在本次迭代中不参与前向传播的计算,也不参与反向传播的权重更新。
注意力计算核心函数
def eager_attention_forward(
module, query, key, value, attention_mask, scaling=None, dropout=0.0, head_mask=None, **kwargs
):
"""
实现标准的缩放点积注意力机制
Attention(Q,K,V) = softmax(QK^T/√d_k)V
"""
if scaling is None:
scaling = query.size(-1) ** -0.5 # 1/√d_k
# 计算注意力分数: Q @ K^T
# [batch_size, num_heads, seq_len_q, head_size] @ [batch_size, num_heads, head_size, seq_len_k]
# -> [batch_size, num_heads, seq_len_q, seq_len_k]
attn_weights = torch.matmul(query, key.transpose(2, 3))
# 处理相对位置编码(如果使用)
if module.position_embedding_type in ["relative_key", "relative_key_query"]:
# 计算相对位置偏置并添加到注意力分数中
# 这里省略具体实现细节...
pass
# 应用缩放因子
attn_weights = attn_weights * scaling
# 应用注意力掩码(防止看到未来信息或padding)
if attention_mask is not None and attention_mask.ndim == 4:
attention_mask = attention_mask[:, :, :, : key.shape[-2]]
attn_weights = attn_weights + attention_mask # 加法掩码(-inf表示屏蔽)
# Softmax 归一化
attn_weights = nn.functional.softmax(attn_weights.float(), dim=-1).type_as(attn_weights)
# 应用 dropout
attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
# 应用头部掩码(用于头部剪枝)
if head_mask is not None:
attn_weights = attn_weights * head_mask
# 计算最终输出: Attention_weights @ V
# [batch_size, num_heads, seq_len_q, seq_len_k] @ [batch_size, num_heads, seq_len_k, head_size]
# -> [batch_size, num_heads, seq_len_q, head_size]
attn_output = torch.matmul(attn_weights, value)
# 调整维度顺序: [batch_size, seq_len_q, num_heads, head_size]
attn_output = attn_output.transpose(1, 2).contiguous()
return attn_output, attn_weightsMulti-head Attention
Multi-head Attention 通过并行运行多个注意力头来捕获不同类型的依赖关系。
实现原理
class BertAttention(nn.Module):
"""
完整的多头注意力模块,包含自注意力计算和输出投影
"""
def __init__(self, config, position_embedding_type=None, is_causal=False,
layer_idx=None, is_cross_attention=False):
super().__init__()
self.is_cross_attention = is_cross_attention
# 选择注意力类型(自注意力或交叉注意力)
attention_class = BertCrossAttention if is_cross_attention else BertSelfAttention
self.self = attention_class(
config, position_embedding_type=position_embedding_type,
is_causal=is_causal, layer_idx=layer_idx
)
# 输出投影和残差连接
self.output = BertSelfOutput(config)
self.pruned_heads = set()
def forward(self, hidden_states, attention_mask=None, head_mask=None,
encoder_hidden_states=None, **kwargs):
# 计算注意力
attention_output, attn_weights = self.self(
hidden_states, encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask, head_mask=head_mask, **kwargs
)
# 应用输出投影和残差连接
attention_output = self.output(attention_output, hidden_states)
return attention_output, attn_weights
class BertSelfOutput(nn.Module):
"""
注意力输出层:线性投影 + Dropout + 残差连接 + LayerNorm
"""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size) # 输出投影
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps) # 层归一化
self.dropout = nn.Dropout(config.hidden_dropout_prob) # Dropout
def forward(self, hidden_states, input_tensor):
# 线性投影
hidden_states = self.dense(hidden_states)
# Dropout
hidden_states = self.dropout(hidden_states)
# 残差连接 + LayerNorm (Post-LN)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_statesAdd & Norm 层
Add & Norm 是 Transformer 中的关键组件,实现残差连接和层归一化。
残差连接 (Residual Connection)
LayerNorm 实现 (T5 风格)
class T5LayerNorm(nn.Module):
"""
T5 风格的 LayerNorm:只进行缩放,不进行平移
也称为 Root Mean Square Layer Normalization (RMSNorm)
"""
def __init__(self, hidden_size, eps=1e-6):
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size)) # 缩放参数
self.variance_epsilon = eps
def forward(self, hidden_states):
# 计算方差(不减去均值)
# 使用 fp32 精度进行计算以提高数值稳定性
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
# 归一化:x / √(variance + ε)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
# 转换回原始精度
if self.weight.dtype in [torch.float16, torch.bfloat16]:
hidden_states = hidden_states.to(self.weight.dtype)
# 应用缩放参数
return self.weight * hidden_statesBERT 风格的 LayerNorm
# BERT 使用标准的 LayerNorm
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
# 标准 LayerNorm 公式:
# LayerNorm(x) = γ * (x - μ) / √(σ² + ε) + β
# 其中 μ 是均值,σ² 是方差,γ 和 β 是可学习参数Feed Forward 网络
Feed Forward Network (FFN) 是 Transformer 中的位置无关的全连接网络。
标准 FFN 实现 (T5)
class T5DenseActDense(nn.Module):
"""
标准的 FFN:Linear -> Activation -> Dropout -> Linear
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
"""
def __init__(self, config):
super().__init__()
# 第一个线性层:d_model -> d_ff (通常 d_ff = 4 * d_model)
self.wi = nn.Linear(config.d_model, config.d_ff, bias=False)
# 第二个线性层:d_ff -> d_model
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
self.dropout = nn.Dropout(config.dropout_rate)
self.act = ACT2FN[config.dense_act_fn] # 激活函数 (ReLU, GELU等)
def forward(self, hidden_states):
# 第一个线性变换
hidden_states = self.wi(hidden_states)
# 激活函数
hidden_states = self.act(hidden_states)
# Dropout
hidden_states = self.dropout(hidden_states)
# 处理数据类型转换(用于混合精度训练)
if (isinstance(self.wo.weight, torch.Tensor) and
hidden_states.dtype != self.wo.weight.dtype and
self.wo.weight.dtype != torch.int8):
hidden_states = hidden_states.to(self.wo.weight.dtype)
# 第二个线性变换
hidden_states = self.wo(hidden_states)
return hidden_states门控 FFN 实现 (T5 Gated)
class T5DenseGatedActDense(nn.Module):
"""
门控 FFN:使用门控机制的 Feed Forward Network
常用于 T5、PaLM 等模型中,提供更强的表达能力
"""
def __init__(self, config):
super().__init__()
# 两个并行的线性层
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False) # 门控分支
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False) # 线性分支
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False) # 输出投影
self.dropout = nn.Dropout(config.dropout_rate)
self.act = ACT2FN[config.dense_act_fn] # 通常使用 GELU
def forward(self, hidden_states):
# 门控分支:应用激活函数
hidden_gelu = self.act(self.wi_0(hidden_states))
# 线性分支:不应用激活函数
hidden_linear = self.wi_1(hidden_states)
# 门控机制:元素级别相乘
hidden_states = hidden_gelu * hidden_linear
# Dropout
hidden_states = self.dropout(hidden_states)
# 数据类型处理(用于量化和混合精度)
if (isinstance(self.wo.weight, torch.Tensor) and
hidden_states.dtype != self.wo.weight.dtype and
self.wo.weight.dtype != torch.int8):
hidden_states = hidden_states.to(self.wo.weight.dtype)
# 输出投影
hidden_states = self.wo(hidden_states)
return hidden_states完整的 FFN 层 (带残差连接)
class T5LayerFF(nn.Module):
"""
完整的 Feed Forward 层,包含 LayerNorm、FFN 和残差连接
"""
def __init__(self, config):
super().__init__()
# 选择 FFN 类型
if config.is_gated_act:
self.DenseReluDense = T5DenseGatedActDense(config)
else:
self.DenseReluDense = T5DenseActDense(config)
# LayerNorm 和 Dropout
self.layer_norm = T5LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.dropout = nn.Dropout(config.dropout_rate)
def forward(self, hidden_states):
# Pre-LayerNorm:先归一化再进入 FFN
forwarded_states = self.layer_norm(hidden_states)
# FFN 计算
forwarded_states = self.DenseReluDense(forwarded_states)
# 残差连接:原始输入 + FFN输出
hidden_states = hidden_states + self.dropout(forwarded_states)
return hidden_statesBERT 风格的 FFN
class BertIntermediate(nn.Module):
"""BERT 的中间层(FFN 的第一部分)"""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
self.intermediate_act_fn = ACT2FN[config.hidden_act] # 通常是 GELU
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
class BertOutput(nn.Module):
"""BERT 的输出层(FFN 的第二部分 + 残差连接)"""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
# 第二个线性变换
hidden_states = self.dense(hidden_states)
# Dropout
hidden_states = self.dropout(hidden_states)
# 残差连接 + LayerNorm
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_statesEncoder 架构
Encoder 是 Transformer 的编码部分,用于处理输入序列并生成上下文表示。
BERT Encoder Layer
class BertLayer(GradientCheckpointingLayer):
"""
BERT 的单个 Encoder 层
结构:Self-Attention -> Add&Norm -> FFN -> Add&Norm
"""
def __init__(self, config, layer_idx=None):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
# 自注意力模块
self.attention = BertAttention(config, is_causal=config.is_decoder, layer_idx=layer_idx)
# 判断是否为解码器(支持交叉注意力)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
# 交叉注意力模块
self.crossattention = BertAttention(
config, position_embedding_type="absolute", is_causal=False,
layer_idx=layer_idx, is_cross_attention=True
)
# Feed Forward 网络
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
def forward(self, hidden_states, attention_mask=None, head_mask=None,
encoder_hidden_states=None, encoder_attention_mask=None, **kwargs):
# 1. 自注意力计算
self_attention_output, _ = self.attention(
hidden_states, attention_mask, head_mask, **kwargs
)
attention_output = self_attention_output
# 2. 交叉注意力计算(仅在解码器中)
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
)
cross_attention_output, _ = self.crossattention(
self_attention_output, None, head_mask, encoder_hidden_states,
encoder_attention_mask, **kwargs
)
attention_output = cross_attention_output
# 3. Feed Forward 网络(分块处理以节省内存)
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward,
self.seq_len_dim, attention_output
)
return layer_output
def feed_forward_chunk(self, attention_output):
"""FFN 的分块处理函数"""
# Intermediate layer (第一个线性层 + 激活)
intermediate_output = self.intermediate(attention_output)
# Output layer (第二个线性层 + 残差连接 + LayerNorm)
layer_output = self.output(intermediate_output, attention_output)
return layer_outputBERT Encoder
class BertEncoder(nn.Module):
"""
BERT 的完整 Encoder,由多个 BertLayer 堆叠而成
"""
def __init__(self, config):
super().__init__()
self.config = config
# 创建多层 Encoder Layer
self.layer = nn.ModuleList([
BertLayer(config, layer_idx=i) for i in range(config.num_hidden_layers)
])
def forward(self, hidden_states, attention_mask=None, head_mask=None,
encoder_hidden_states=None, encoder_attention_mask=None, **kwargs):
# 逐层处理
for i, layer_module in enumerate(self.layer):
# 获取当前层的头部掩码
layer_head_mask = head_mask[i] if head_mask is not None else None
# 通过当前层
hidden_states = layer_module(
hidden_states, attention_mask, layer_head_mask,
encoder_hidden_states, encoder_attention_mask=encoder_attention_mask,
**kwargs
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
)T5 Encoder (更现代的实现)
class T5Block(GradientCheckpointingLayer):
"""
T5 的 Transformer Block,可用作 Encoder 或 Decoder
"""
def __init__(self, config, has_relative_attention_bias=False, layer_idx=None):
super().__init__()
self.is_decoder = config.is_decoder
self.layer = nn.ModuleList()
# 1. 自注意力层
self.layer.append(
T5LayerSelfAttention(config, has_relative_attention_bias=has_relative_attention_bias,
layer_idx=layer_idx)
)
# 2. 交叉注意力层(仅在解码器中)
if self.is_decoder:
self.layer.append(T5LayerCrossAttention(config, layer_idx=layer_idx))
# 3. Feed Forward 层
self.layer.append(T5LayerFF(config))
def forward(self, hidden_states, attention_mask=None, position_bias=None,
encoder_hidden_states=None, encoder_attention_mask=None, **kwargs):
# 1. 自注意力
self_attention_outputs = self.layer[0](
hidden_states, attention_mask=attention_mask, position_bias=position_bias, **kwargs
)
hidden_states, position_bias = self_attention_outputs[:2]
attention_outputs = self_attention_outputs[2:] # 保存注意力权重
# 数值稳定性处理(防止 fp16 溢出)
if hidden_states.dtype == torch.float16:
clamp_value = torch.where(
torch.isinf(hidden_states).any(),
torch.finfo(hidden_states.dtype).max - 1000,
torch.finfo(hidden_states.dtype).max,
)
hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
# 2. 交叉注意力(仅在解码器中)
do_cross_attention = self.is_decoder and encoder_hidden_states is not None
if do_cross_attention:
cross_attention_outputs = self.layer[1](
hidden_states, key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask, **kwargs
)
hidden_states = cross_attention_outputs[0]
attention_outputs = attention_outputs + cross_attention_outputs[1:]
# 3. Feed Forward
hidden_states = self.layer[-1](hidden_states)
return (hidden_states,) + attention_outputs
class T5Stack(T5PreTrainedModel):
"""
T5 的 Encoder/Decoder Stack
"""
def __init__(self, config, embed_tokens=None):
super().__init__(config)
self.embed_tokens = embed_tokens
self.is_decoder = config.is_decoder
# 创建多个 T5Block
self.block = nn.ModuleList([
T5Block(config, has_relative_attention_bias=bool(i == 0), layer_idx=i)
for i in range(config.num_layers)
])
# 最终的 LayerNorm
self.final_layer_norm = T5LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.dropout = nn.Dropout(config.dropout_rate)
self.post_init()Decoder 架构
Decoder 是 Transformer 的解码部分,用于生成输出序列。与 Encoder 的主要区别是增加了交叉注意力和因果掩码。
T5 Decoder Layer
class T5LayerCrossAttention(nn.Module):
"""
T5 的交叉注意力层:Decoder 对 Encoder 输出的注意力
"""
def __init__(self, config, layer_idx=None):
super().__init__()
# 交叉注意力(不使用相对位置偏置)
self.EncDecAttention = T5Attention(config, has_relative_attention_bias=False, layer_idx=layer_idx)
self.layer_norm = T5LayerNorm(config.d_model, eps=config.layer_norm_epsilon)
self.dropout = nn.Dropout(config.dropout_rate)
def forward(self, hidden_states, key_value_states, attention_mask=None, **kwargs):
"""
Args:
hidden_states: Decoder 的隐藏状态 (Query)
key_value_states: Encoder 的输出 (Key & Value)
attention_mask: Encoder 的注意力掩码
"""
# Pre-LayerNorm
normed_hidden_states = self.layer_norm(hidden_states)
# 交叉注意力计算
attention_output = self.EncDecAttention(
normed_hidden_states, # Query 来自 Decoder
mask=attention_mask,
key_value_states=key_value_states, # Key & Value 来自 Encoder
**kwargs
)
# 残差连接
layer_output = hidden_states + self.dropout(attention_output[0])
outputs = (layer_output,) + attention_output[1:]
return outputs因果掩码 (Causal Mask)
def create_causal_mask(seq_length, device, dtype):
"""
创建因果掩码,防止 Decoder 看到未来的信息
Returns:
mask: 下三角矩阵,上三角部分为 -inf
例如 seq_length=4:
[[ 0, -inf, -inf, -inf],
[ 0, 0, -inf, -inf],
[ 0, 0, 0, -inf],
[ 0, 0, 0, 0]]
"""
mask = torch.full((seq_length, seq_length), float('-inf'), device=device, dtype=dtype)
mask = torch.triu(mask, diagonal=1) # 上三角矩阵(不包括对角线)
return mask
# 在注意力计算中应用因果掩码
def apply_causal_mask(attention_scores, seq_length):
"""
将因果掩码应用到注意力分数上
"""
causal_mask = create_causal_mask(seq_length, attention_scores.device, attention_scores.dtype)
# 广播到 [batch_size, num_heads, seq_length, seq_length]
causal_mask = causal_mask.unsqueeze(0).unsqueeze(0)
attention_scores = attention_scores + causal_mask
return attention_scores完整的 Decoder Block
# T5 Decoder Block 已在上面的 T5Block 中实现
# 当 config.is_decoder=True 时,T5Block 自动包含:
# 1. 自注意力层(带因果掩码)
# 2. 交叉注意力层
# 3. Feed Forward 层
# 关键区别在于 forward 函数中的处理:
def forward(self, hidden_states, attention_mask=None, encoder_hidden_states=None, **kwargs):
# 1. 自注意力(带因果掩码)
self_attention_outputs = self.layer[0](
hidden_states,
attention_mask=attention_mask, # 包含因果掩码
**kwargs
)
hidden_states = self_attention_outputs[0]
# 2. 交叉注意力(Decoder 对 Encoder 的注意力)
if encoder_hidden_states is not None:
cross_attention_outputs = self.layer[1](
hidden_states,
key_value_states=encoder_hidden_states, # 来自 Encoder
attention_mask=encoder_attention_mask, # Encoder 的掩码
**kwargs
)
hidden_states = cross_attention_outputs[0]
# 3. Feed Forward
hidden_states = self.layer[-1](hidden_states)
return hidden_states完整 Transformer 模型
T5 Encoder-Decoder 模型
class T5Model(T5PreTrainedModel):
"""
完整的 T5 Encoder-Decoder 模型
"""
def __init__(self, config: T5Config):
super().__init__(config)
self.shared = nn.Embedding(config.vocab_size, config.d_model) # 共享词嵌入
# Encoder 配置
encoder_config = copy.deepcopy(config)
encoder_config.is_decoder = False
encoder_config.use_cache = False
encoder_config.tie_encoder_decoder = False
self.encoder = T5Stack(encoder_config, self.shared)
# Decoder 配置
decoder_config = copy.deepcopy(config)
decoder_config.is_decoder = True
decoder_config.tie_encoder_decoder = False
decoder_config.num_layers = config.num_decoder_layers
self.decoder = T5Stack(decoder_config, self.shared)
self.post_init()
def forward(self, input_ids=None, attention_mask=None, decoder_input_ids=None,
decoder_attention_mask=None, **kwargs):
"""
Args:
input_ids: Encoder 输入 token ids
attention_mask: Encoder 注意力掩码
decoder_input_ids: Decoder 输入 token ids
decoder_attention_mask: Decoder 注意力掩码
"""
# 1. Encoder 前向传播
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
**kwargs
)
encoder_hidden_states = encoder_outputs[0]
# 2. Decoder 前向传播
decoder_outputs = self.decoder(
input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
encoder_hidden_states=encoder_hidden_states, # 交叉注意力的 Key & Value
encoder_attention_mask=attention_mask, # Encoder 掩码
**kwargs
)
return Seq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
encoder_last_hidden_state=encoder_hidden_states,
encoder_hidden_states=encoder_outputs.hidden_states,
decoder_hidden_states=decoder_outputs.hidden_states,
)
class T5ForConditionalGeneration(T5PreTrainedModel, GenerationMixin):
"""
T5 条件生成模型(带语言模型头)
"""
def __init__(self, config: T5Config):
super().__init__(config)
self.model_dim = config.d_model
# 共享词嵌入
self.shared = nn.Embedding(config.vocab_size, config.d_model)
# Encoder 和 Decoder
encoder_config = copy.deepcopy(config)
encoder_config.is_decoder = False
self.encoder = T5Stack(encoder_config, self.shared)
decoder_config = copy.deepcopy(config)
decoder_config.is_decoder = True
self.decoder = T5Stack(decoder_config, self.shared)
# 语言模型头(输出投影)
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
self.post_init()
def forward(self, input_ids=None, attention_mask=None, decoder_input_ids=None,
decoder_attention_mask=None, labels=None, **kwargs):
# 获取模型输出
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
**kwargs
)
# 计算 logits
sequence_output = outputs[0]
if self.config.tie_word_embeddings:
# 权重共享:lm_head 与 embedding 共享权重
sequence_output = sequence_output * (self.model_dim ** -0.5)
lm_logits = self.lm_head(sequence_output)
# 计算损失(如果提供了标签)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss(ignore_index=-100)
# 将 logits 和 labels 展平
loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
return Seq2SeqLMOutput(
loss=loss,
logits=lm_logits,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
)HF的transformers中的模型结构
以Qwen3-14b模型为例,用transforms的model加载模型后输出结构如下
Qwen3AWQForCausalLM(
(model): Qwen3ForCausalLM(
(model): Qwen3Model(
(embed_tokens): Embedding(151936, 5120)
(layers): ModuleList(
(0-39): 40 x Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): Linear(in_features=5120, out_features=5120, bias=False)
(k_proj): Linear(in_features=5120, out_features=1024, bias=False)
(v_proj): Linear(in_features=5120, out_features=1024, bias=False)
(o_proj): Linear(in_features=5120, out_features=5120, bias=False)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
)
(mlp): Qwen3MLP(
(gate_proj): Linear(in_features=5120, out_features=17408, bias=False)
(up_proj): Linear(in_features=5120, out_features=17408, bias=False)
(down_proj): Linear(in_features=17408, out_features=5120, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((5120,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((5120,), eps=1e-06)
)
)
(norm): Qwen3RMSNorm((5120,), eps=1e-06)
(rotary_emb): Qwen3RotaryEmbedding()
)
(lm_head): Linear(in_features=5120, out_features=151936, bias=False)
)
)1. 输入层 (Input Layer)
-
(embed_tokens): Embedding(151936, 5120):-
对应 Transformer 的输入嵌入层 (Input Embedding)。
-
151936 是模型的词汇表大小 (Vocab Size),即模型能处理的词/token总数。
-
5120 是隐藏层维度 (Hidden Size),即每个 token 嵌入后的向量长度,也是整个模型内部数据流动的维度 Dmodel。
-
2. 位置编码 (Positional Encoding)
-
(rotary_emb): Qwen3RotaryEmbedding():-
Qwen3 使用 RoPE (Rotary Position Embedding) 来为序列中的 token 提供位置信息。
-
这取代了原始 Transformer 结构中的绝对位置编码,是一种更先进且常用于 LLMs 的相对位置编码方式。
-
3. 核心计算层 (Core Computation Layers)
-
(layers): ModuleList( (0-39): 40 x Qwen3DecoderLayer(...) ):-
这是模型的主体,包含40个连续堆叠的 Qwen3DecoderLayer。
-
这与原始 Transformer 多层堆叠的思想一致,每一层都会对输入信息进行一次更复杂的特征提取。
-
a. 解码器层 (Decoder Layer)
每个 Qwen3DecoderLayer 内部包含两个主要的子层,这是 Transformer Decoder 的典型结构:
-
自注意力机制 (Self-Attention Mechanism)
-
(self_attn): Qwen3Attention(...):对应 Transformer Decoder 中的遮盖自注意力 (Masked Self-Attention) 子层。这是 Transformer 的核心,允许模型在处理序列的每一步时,关注输入序列中的所有先前 token。-
(q_proj), (k_proj), (v_proj):分别用于计算 Query (查询)、Key (键)、Value (值) 向量。在 Qwen3 中,这三个投影的输出维度不同,表明它使用了分组查询注意力 (GQA, Grouped-Query Attention) 或 多查询注意力 (MQA, Multi-Query Attention) 的变体,其中 Key/Value 的维度 1024 小于 Query 的维度 5120,这能显著加速推理。 -
(o_proj):将注意力机制的输出重新投影回隐藏层维度 5120。 -
(q_norm), (k_norm):在 Qwen3 中,对 Query 和 Key 向量进行 RMSNorm (Root Mean Square Normalization),是一种预归一化 (Pre-Normalization) 的做法,有助于训练稳定。
-
-
-
前馈网络 (Feed-Forward Network, FFN)
-
(mlp): Qwen3MLP(...):对应 Transformer Decoder 中的前馈网络子层,用于对每个 token 的特征向量进行非线性变换。-
(gate_proj), (up_proj):输入维度 5120 扩展到 17408。Qwen3 使用 SwiGLU (Gated Linear Unit with Swish) 形式的 FFN(通过gate_proj和up_proj实现),这比原始 Transformer 的 FFN 更有效。 -
(down_proj):将维度从 17408 降回到 5120。 -
(act_fn): SiLU():激活函数 SiLU (Sigmoid Linear Unit),在 FFN 中引入非线性。
-
-
b. 归一化 (Normalization)
-
(input_layernorm), (post_attention_layernorm):-
对应 Transformer 结构中的层归一化 (Layer Normalization)。
-
Qwen3 使用 RMSNorm 而非经典的 LayerNorm,且通常采用预归一化 (Pre-LN) 结构(将 LayerNorm 放在注意力或 FFN 之前),有助于训练深层模型。
-
4. 输出层 (Output Layer)
-
(norm): Qwen3RMSNorm((5120,), eps=1e-06):-
位于所有 Decoder 层之后,对最终的隐藏状态进行归一化。
-
-
(lm_head): Linear(in_features=5120, out_features=151936, bias=False):-
对应 Transformer 的线性输出层。
-
将维度为 5120 的最终隐藏状态投影回词汇表大小 151936,得到每个词汇的对数几率 (logits),用于预测下一个 token。
-
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)