
SGLang大模型推理框架:一文读懂如何解决冗余计算与结构化输出问题(建议收藏)
SGLang是专为复杂生成任务设计的大模型推理框架,通过RadixAttention实现跨请求细粒度KV Cache复用,并引入压缩有限状态机支持结构化输出约束。相比传统框架,SGLang在AI Agent、RAG等场景下显著降低冗余计算,提升推理吞吐量和响应速度,同时保证输出符合正则表达式、JSON Schema等格式要求。
简介
SGLang是专为复杂生成任务设计的大模型推理框架,通过RadixAttention实现跨请求细粒度KV Cache复用,并引入压缩有限状态机支持结构化输出约束。相比传统框架,SGLang在AI Agent、RAG等场景下显著降低冗余计算,提升推理吞吐量和响应速度,同时保证输出符合正则表达式、JSON Schema等格式要求。
在构建 AI Agent 时,你可能遇到这样的烦恼:每次调用工具时,哪怕大部分上下文相同,只要有细微差别,框架仍需重新计算。vLLM 虽支持跨请求复用 KV Cache,但只能按页(通常 16 个 token)共享,对于无法复用的部分仍需重复计算。
一、SGLang 产生的背景
vLLM 通过PagedAttention、连续批处理(Continuous Batching)以及Prefix Sharing,显著提升了长上下文和高并发请求的推理吞吐量。对于普通对话场景,其效率已经非常高。然而,在一些复杂应用场景下,大模型推理仍面临严重挑战:
1. AI Agent:多轮工具调用不仅要求高效推理,还需要结构化输出,对模型输出进行严格约束,例如正则表达式(Regular Expression)或 JSON Schema。vLLM 只能按页共享 KV Cache,对于复杂工具调用场景仍存在冗余计算和输出约束不足的问题。
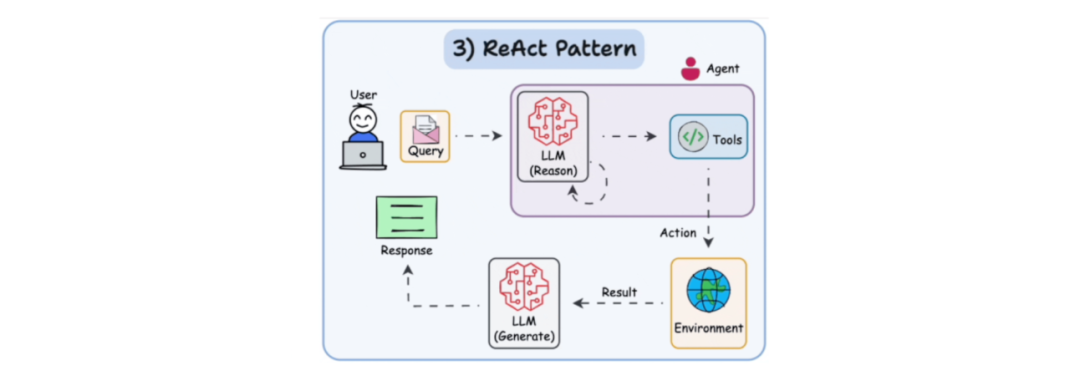
2. RAG(检索增强生成):当多个文档片段组合成大模型上下文时,不同请求的共享部分有限,重复计算不可避免。
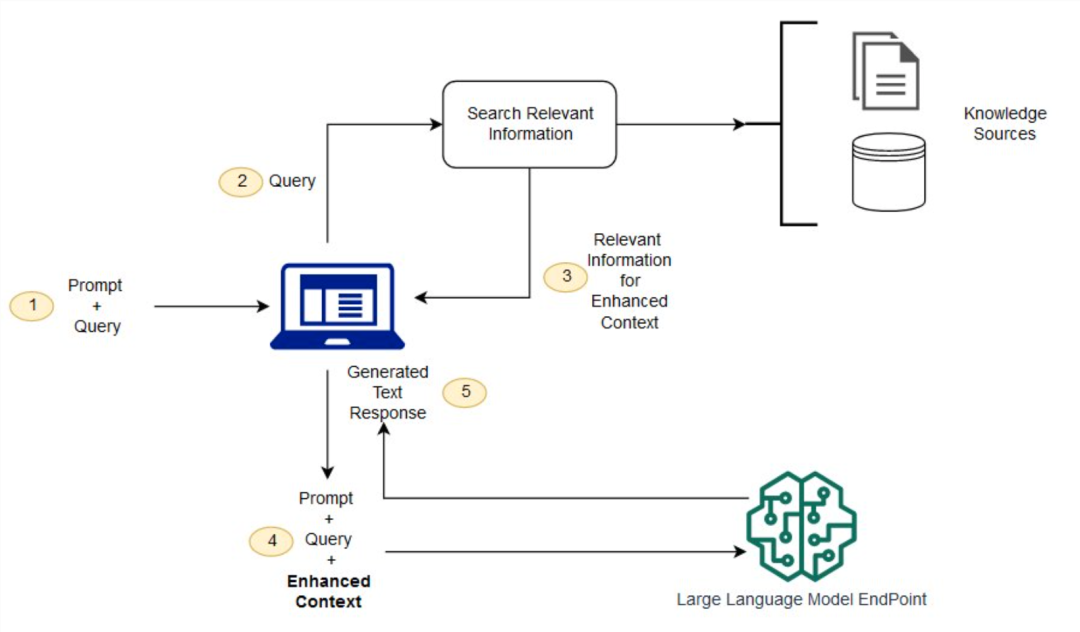
3. Self consistency:生成多条候选答案时,前缀大部分相同,但页粒度共享无法覆盖全部,仍会产生冗余计算。
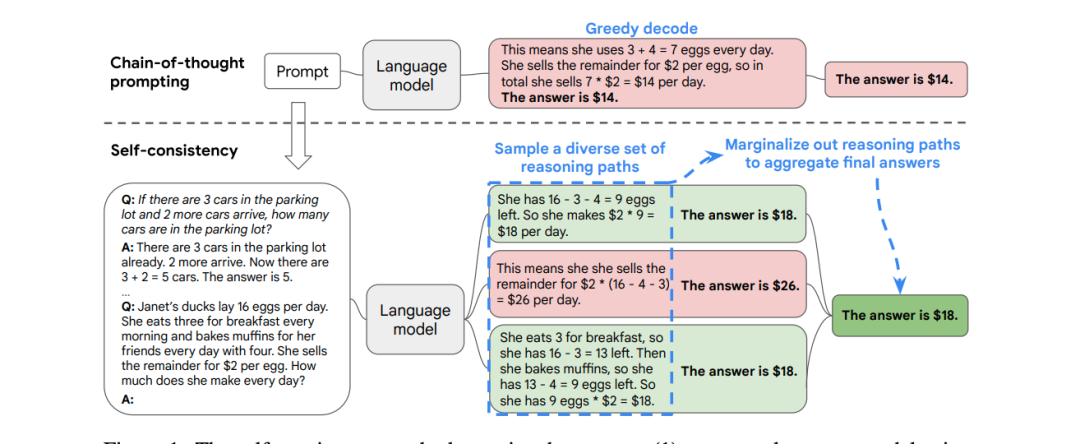
此外,其他复杂场景也面临类似问题。总的来说:
vLLM 提升了推理速度,但在复杂应用场景下仍存在冗余计算、KV Cache 复用不足 以及结构化输出约束不足 的问题。
SGLang 正是为解决这些挑战而诞生的。
二、SGLang 介绍
SGLang 是一个专为复杂生成任务而设计的大模型推理框架,它不仅关注算子级别的高性能优化,也重视 上下文(context) 的结构化管理 与 KV Cache 复用。
SGLang 将 上下文(context) 抽象为 压缩有限状态机(Compressed FSM),将整个任务拆解为可复用的节点,通过 RadixAttention 构建前缀树,实现跨请求的高效 KV Cache 复用。这种方式使得复杂场景下的大模型推理——如Agent 多次工具调用、RAG(检索增强生成)、以及 Self consistency 多样化生成——都能显著减少冗余计算。
SGLang 原生支持 结构化输出约束,保证大模型的输出结果符合正则(regex)、Json Schema 等的约束要求。
总的来说,SGLang 通过理解上下文的结构,复用KV Cache 并约束输出,使大模型在多轮对话、RAG 或 Agent 场景下既快速又稳定。
Radix Attention
RadixAttention 是 SGLang 的核心技术之一,用于解决 复杂任务中 KV Cache 复用效率低的问题。vLLM 的 PagedAttention 已经能高效管理 KV Cache,可以避免显存碎片。但它并不能做到跨请求的 token 级前缀复用。SGLang 使用 RadixAttention 解决 了这个问题。
RadixAttention 实现思路:
- 把多个请求的 token 序列,组织成 Radix Tree(基数树)。
- 前缀部分只保存一份 KV Cache。
- 不同请求在后续 token 上分叉时,只在各自的分支节点里存储新 token 对应的 KV。
用一个简单的例子,看下 RaddixAttention 是如何共享前缀的:
请求 A:
System: You are a helpful assistant.
请求 B:
System: You are a helpful assistant.
请求 A 和 请求 B 可以共享前缀:
System: You are a helpful assistant.
请求 A 在自己的分支节点 存储 “nice to meet you!” 对应的 KV Cache 即可
请求 B 在自己的分支节点 存储 “can I help you?” 对应的 KV Cache 即可
下面是在原论文中展示的更具体的例子:
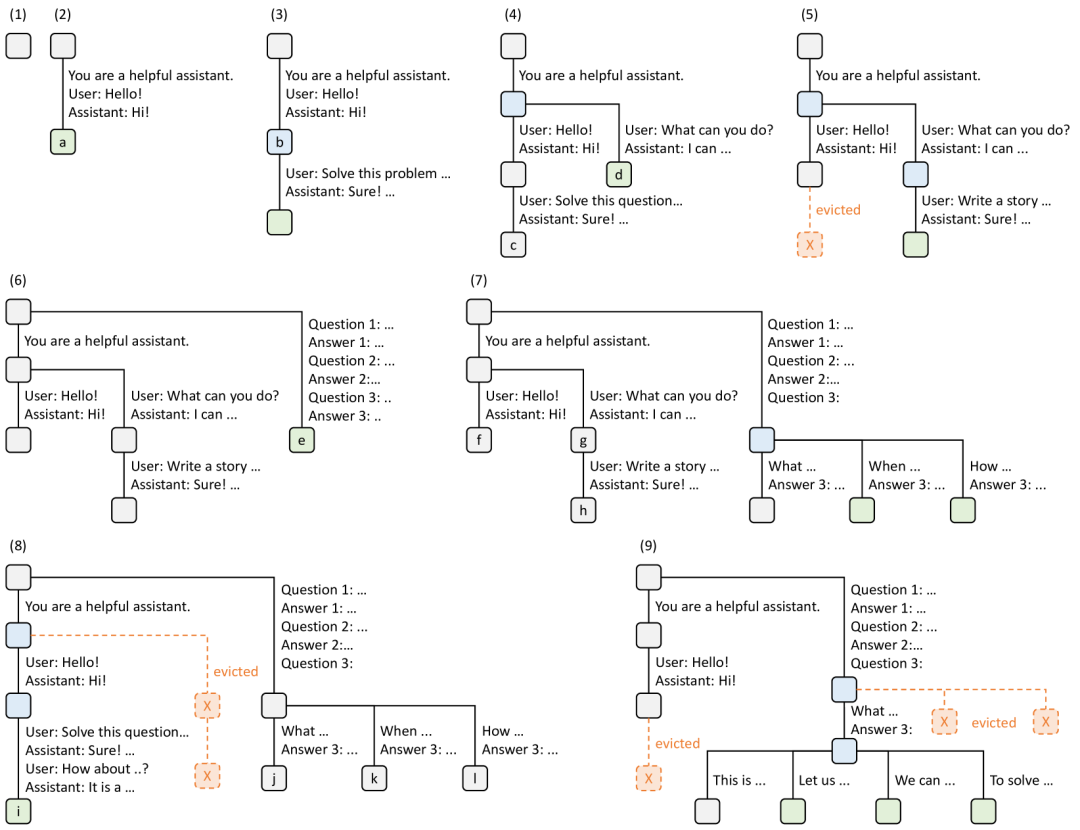
引用来源:《SGLang: Efficient Execution of Structured Language Model Programs》
这样做的优势是:
- 显存大幅节省:相同前缀的 KV Cache 不会重复存储。
- 吞吐量提升:多个请求批量推理时,不需要重新计算前缀。
- 更适合 RAG / Agent / Self consistency场景:这些场景里,前缀往往共享大量检索结果或系统提示。
三、压缩有限状态机
在传统的大模型推理中,解码过程往往是 逐 token 进行的:模型每次预测一个 token,再拼接到 context 里继续预测。这种方式虽然通用,但在**结构化输出(如JSON Schema、正则约束等)**场景下却存在一个主要的问题:
- 效率低:每个 token 都要经过一次完整的前向传播,即便约束已经确定了后续部分。
为此,SGLang 引入了 压缩有限状态机(Compressed FSM)。
1. 从约束生成状态机
当用户要求输出必须满足某个格式(例如 正则约束),SGLang 会先生成一个普通的有限状态机(FSM):
-
每个状态节点表示输出的一个位置。
-
每条边表示可能的 token 序列。

2. 合并单一转移边形成压缩状态机
压缩状态机就是在普通状态机的基础上,把连续的、无分叉的边合并成一条长边。
单一转换边(Singular transition edge):
- 它的源节点(source node)只有一个后继节点;
- 该边上只允许一个字符或字符串。
压缩边(Compressed edge):
若一条边由若干条连续相邻的边 e0,e1,…,ek 压缩而成,并且其中的 e1,…,ek 都是单一转换边,则这条边称为压缩边。压缩边上的文本等于这些边文本的拼接,即 e0,e1,…,ek 的文本串联结果。
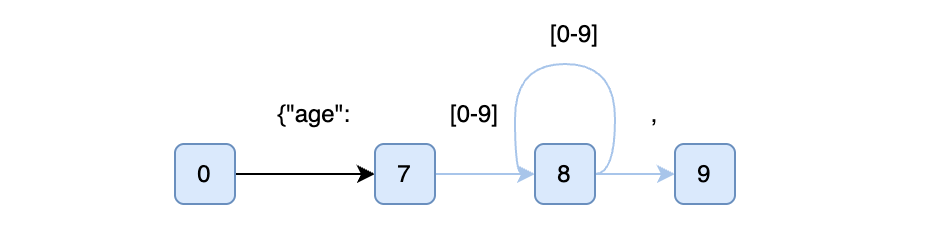
3. 解码时的跳跃前进
在推理过程中,模型预测出下一个 token 后,SGLang 会拿它去匹配压缩状态机的边,如果匹配成功,就可以直接跳跃到边的末尾,而不是逐 token 慢慢走。这样避免了重复调用模型,大大减少前向传播计算。边匹配成功有两种类型:
普通边(单字符/单 token 边)
- 如果预测出的 token 恰好匹配边上的文本,就可以直接沿边进入下一个节点。
- 不需要 retokenize,因为 tokenizer 分割和模型输出是一致的。
压缩边(长字符串边)
- 如果预测出的 token 的前缀匹配到压缩边上的文本,那么模型就进入“跳跃前进(jump forward)”模式。
- 并且需要对 历史生成的 token 序列(previous text)和压缩边上的字符串 做一次 retokenize,确保切分出来的 token 序列和 LLM 的原始分词(tokenization)规则一致。否则,可能出现模型生成的 token 序列和压缩边预期的 token 序列不一致的问题。
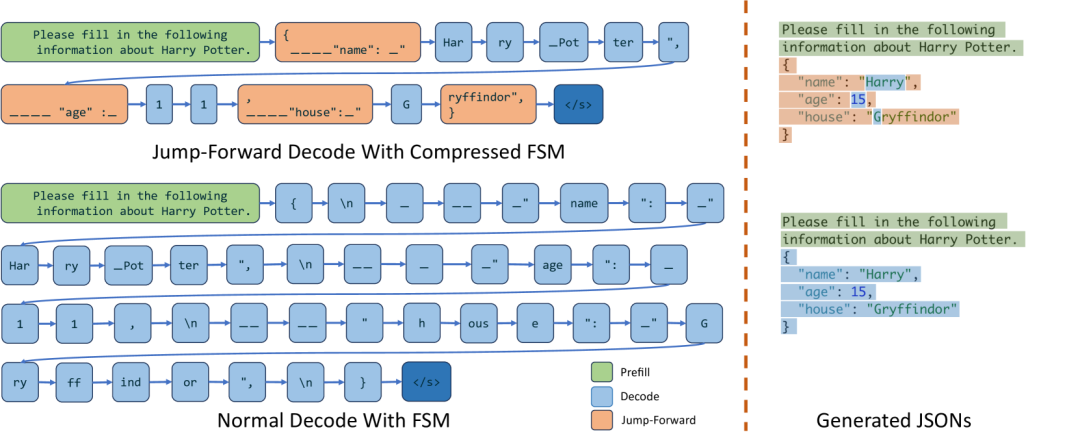
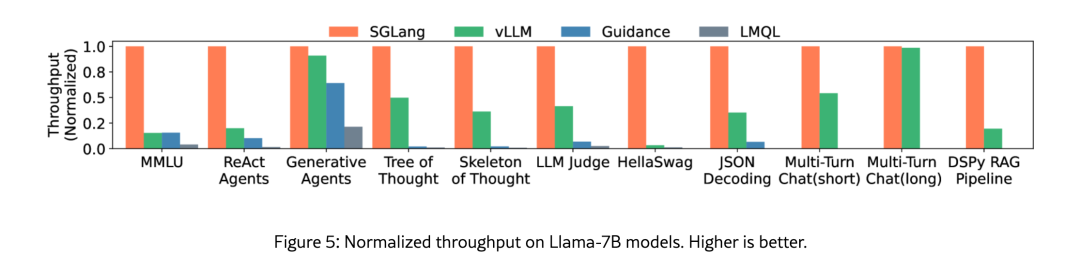
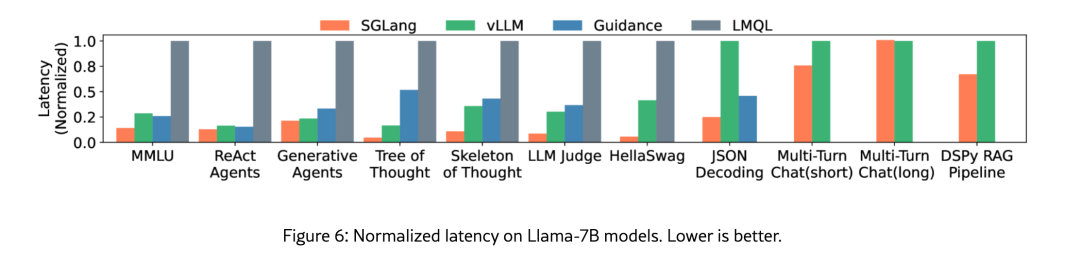
四、总结:SGLang 的优势
相较于传统推理框架,SGLang 的核心优势主要体现在:
- 更低延时:通过 RadixAttention 和 压缩状态机(Compressed FSM),避免了大量重复计算,尤其在 AI Agent、RAG、self-consistency 等复杂场景下,大幅降低了响应延时。
- 更高吞吐量:跨请求的细粒度前缀复用,以及对长边的“跳跃解码”,让显存利用率和推理吞吐量显著提升,支持更高并发的实时服务。
- 更强约束能力:借助压缩状态机与 retokenize 技术,SGLang 能在保证推理效率的同时,支持 正则表达式、JSON Schema 等多种结构化输出约束,非常适合 AI Agent 的工具调用场景。
五、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐
 6
6 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)