
【2025具身智能大模型·系列17】阿里达摩院开源RynnVLA-001:视觉-语言-动作模型助力机器人智能操控
RynnVLA-001是阿里达摩院推出的一款视觉-语言-动作模型,旨在通过预训练大量第一人称视角的视频数据,学习人类操作技能,并将其隐式迁移到机器人手臂的操控中。该模型结合了视频生成技术和变分自编码器(VAE),能够生成连贯、平滑的动作序列,显著提升机器人在复杂任务中的成功率和指令遵循能力。它在工业自动化、服务机器人、物流与仓储、医疗保健等多个领域具有广泛的应用前景。
系列篇章💥
目录
前言
在人工智能与机器人技术快速发展的今天,如何让机器人更好地理解和执行人类指令,是研究者们关注的焦点之一。阿里达摩院开源的RynnVLA-001项目,正是在这一领域的一次重要探索。它通过结合视觉、语言和动作模型,为机器人操控提供了新的解决方案。本文将详细介绍该项目的背景、核心功能、技术原理、应用场景以及快速使用方法,帮助读者全面了解这一前沿技术。
一、项目概述
RynnVLA-001是阿里达摩院推出的一款视觉-语言-动作模型,旨在通过预训练大量第一人称视角的视频数据,学习人类操作技能,并将其隐式迁移到机器人手臂的操控中。该模型结合了视频生成技术和变分自编码器(VAE),能够生成连贯、平滑的动作序列,显著提升机器人在复杂任务中的成功率和指令遵循能力。它在工业自动化、服务机器人、物流与仓储、医疗保健等多个领域具有广泛的应用前景。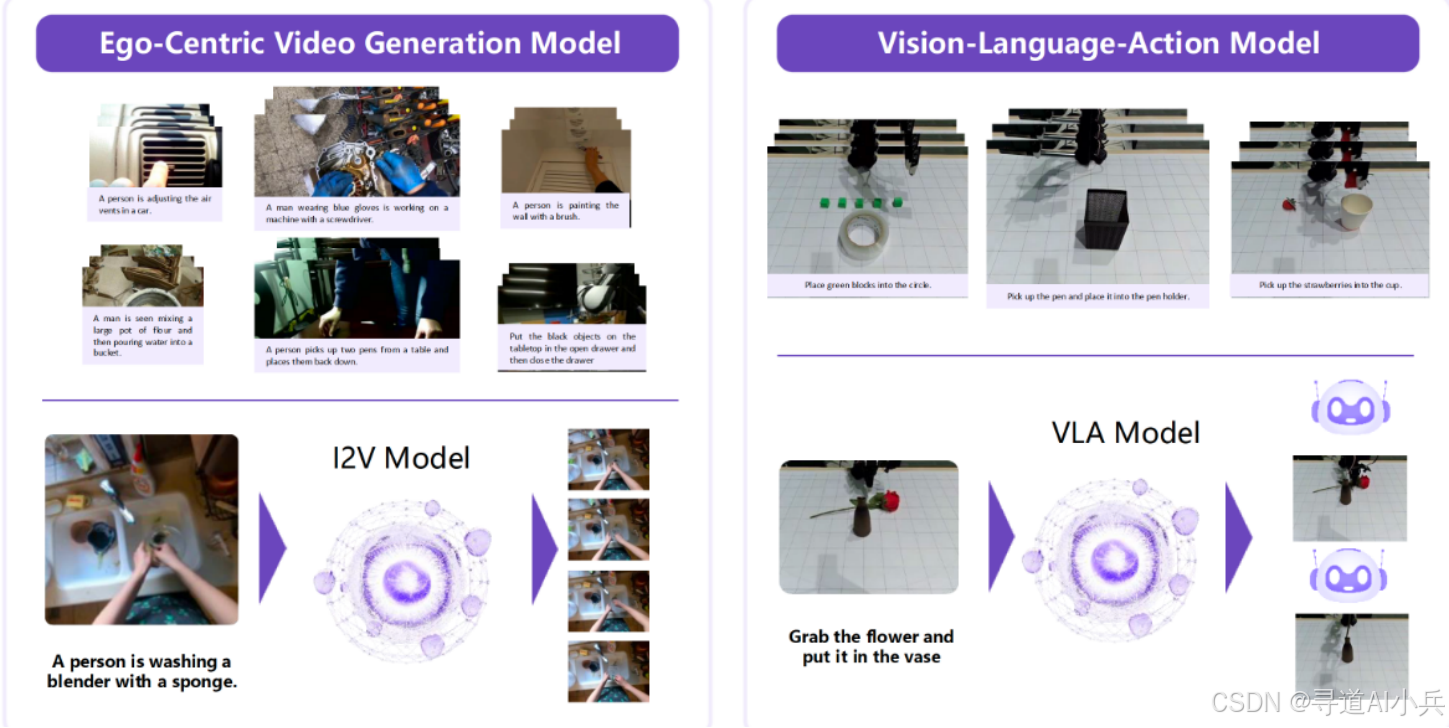
二、核心功能
(一)理解语言指令
RynnVLA-001能够接收自然语言指令,例如“将红色物体移动到蓝色盒子中”,并准确理解其含义。这一功能使得机器人能够根据人类的指令完成各种任务,极大地提高了人机交互的便利性和效率。
(二)生成动作序列
基于对语言指令和当前视觉环境的理解,RynnVLA-001能够生成连贯、平滑的动作序列,驱动机器人手臂完成任务。这一过程不仅考虑了任务的目标,还兼顾了动作的自然性和流畅性,使得机器人的操作更接近人类的自然操作。
(三)适应复杂场景
RynnVLA-001能够处理复杂的抓取和放置任务,以及长时域任务,显著提高了任务的成功率。它通过从第一人称视角的视频中学习,掌握了丰富的操作技能和物理动态知识,从而能够在复杂多变的环境中稳定运行。
(四)模仿人类操作
该模型通过预训练大量第一人称视角的视频数据,学习人类的操作模式和物理动态。因此,它生成的动作序列不仅高效,还具有较高的自然性和可接受性,使得机器人在执行任务时能够更好地模仿人类的行为。
三、技术原理
(一)第一阶段:第一人称视频生成模型
RynnVLA-001的第一阶段是基于大规模第一人称视角的视频数据训练一个视频生成模型。这些视频数据包含了丰富的手部操作场景,模型通过自回归Transformer架构,预测未来帧,模拟机器人操作的视觉推理过程。这一阶段的目标是让模型学习人类操作的视觉模式和物理动态,为后续的动作预测奠定基础。
(二)第二阶段:变分自编码器(VAE)压缩动作片段
在VLA模型中,预测动作片段(短序列动作)比预测单步动作更有优势。为了避免重复预测和提高计算效率,RynnVLA-001训练了一个轻量级的VAE,将每个机器人动作片段压缩为紧凑的嵌入向量。这样,模型只需要预测一个嵌入向量,然后通过VAE解码器将其还原为连贯的动作序列,从而提高了动作预测的平滑性和效率。
(三)第三阶段:视觉-语言-动作模型
在第三阶段,RynnVLA-001将预训练的视频生成模型微调为VLA模型,统一“下一帧预测”和“下一动作预测”。模型通过Transformer架构,结合视觉输入和语言指令,生成动作嵌入向量,驱动机器人执行任务。这一阶段的关键在于将视觉、语言和动作紧密结合,实现高效的指令理解和动作生成。
四、应用场景
(一)工业自动化
在工业生产中,RynnVLA-001可以驱动机器人完成复杂的装配和质量检测任务。通过接收自然语言指令,机器人能够准确执行任务,提高生产效率和产品质量,减少人工干预。
(二)服务机器人
在家庭或餐饮服务中,RynnVLA-001能够让机器人根据自然语言指令完成日常服务任务,如整理物品、送餐等。这不仅提高了服务效率,还增强了用户体验。
(三)物流与仓储
在物流仓库中,RynnVLA-001可以指导机器人完成货物分拣和搬运任务。通过优化库存管理流程,提高物流效率,降低人力成本。
(四)医疗保健
在医疗领域,RynnVLA-001可以辅助手术操作或康复训练。通过精确的动作控制和指令理解,提高医疗服务的精准度和效率,为患者提供更好的治疗体验。
(五)人机协作
在人机协作场景中,RynnVLA-001能够使机器人更好地理解人类指令,实现自然流畅的人机互动。这不仅提高了工作效率,还增强了人机之间的信任和协作。
五、快速使用
(一)环境准备
在开始使用RynnVLA-001之前,需要确保已经安装了必要的依赖包。可以通过以下命令安装:
pip install torch==2.2.0 torchvision==0.17.0 --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
pip install flash-attn==2.5.8
(二)下载预训练模型
下载Chameleon模型和RynnVLA-001-7B-Base预训练模型,并将它们放置在pretrained_models目录下。目录结构如下:
pretrained_models
├── Chameleon
│ ├── original_tokenizers
│ │ ├── text_tokenizer.json
│ │ ├── vqgan.ckpt
│ │ └── vqgan.yaml
│ ├── config.json
│ └── ...
└── RynnVLA-001-7B-Base
(三)数据准备
如果使用自己的LeRobot数据,需要将其转换为hdf5格式。可以使用以下脚本进行转换:
python misc/lerobot_data_convert.py --dataset_dir path-to-raw-lerobot-data --task_name dataset-name --save_dir path-to-save-hdf5-files
转换完成后,需要将数据的统计信息和路径保存到一个json文件中。可以使用以下脚本生成json文件:
cd misc/merge_data
python misc/data_process_with_configs.py -c misc/merge_data/config.yaml
(四)训练
在训练阶段,需要调整./configs/actionvae/actionvae_lerobot.yml和./configs/lerobot/lerobot_exp.yml中的路径为本地路径。训练脚本如下:
# Stage 2
bash scripts/actionvae/action_vae.sh
# Stage 3
bash scripts/lerobot/lerobot.sh
(五)推理
在推理阶段,可以使用inference_lerobot.py脚本进行推理。如果遇到错误,可以尝试升级transformers版本到4.46.3。
六、结语
RynnVLA-001作为阿里达摩院开源的视觉-语言-动作模型,通过预训练大量第一人称视角的视频数据,实现了高效的指令理解和动作生成。它在多个领域具有广泛的应用前景,为机器人操控提供了新的思路和方法。希望本文能够帮助读者全面了解RynnVLA-001项目,并在实际应用中发挥其价值。
项目地址
- 项目官网:https://huggingface.co/blog/Alibaba-DAMO-Academy/rynnvla-001
- GitHub仓库:https://github.com/alibaba-damo-academy/RynnVLA-001
- HuggingFace模型库:https://huggingface.co/Alibaba-DAMO-Academy/RynnVLA-001-7B-Base

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)