
Tabular Learning 系列02
SERSAL架构是这样的,其实分为了四个板块。先把数据喂给LLM(Zero-Shot),LLM反馈一个概率值或者置信区间,这些概率值称之为noisy soft labels,让小模型从这些noisy soft labels进行学习、品质把控后再次把小模型反馈的标签回馈给大模型迭代微调;循环迭代,最终把测试数据放入学生模型,收获预测标签。1、小模型怎么从大模型给出的noisy soft labels
一天不炸,浑身发麻。不管咋游龙也得保证更新。今日分享SMALL MODELS ARE LLM KNOWLEDGE TRIGGERS FOR MEDICAL TABULAR PREDICTION-ICLR 2025 (我最崇拜的师兄)
我要围绕五个点来读顶会:
- 本文章拟解决什么问题?
- 文章做了什么工作来解决这些问题?
- 文章的详细架构、公式推导、设置本身是怎样的?与此联系紧密的基础知识有什么是你不懂的?
- 使用的数据集是怎么来的?文章实验是怎么设置的?
- 高屋建瓴地想,文章为啥子这样想,顶层设计是什么?它能为我带来什么启示?未来见到什么样的知识点,什么样的架构是与其紧密关联的?
本文章拟解决什么问题?
当下LLM还是火啊,大行其道。但是结构化数据由于数值特征多,模态鸿沟大,吃不到LLM这边的红利。我们想让结构化数据学习也享有类似的范式,吃到类似的红利。
文章做了什么工作来解决这些问题?
文章提出SERSAL框架。是一个self-prompting框架,同时搭配synergy learning(其实就是教师-学生框架)来以一种无监督的方式完成表格预测。
文章的详细架构、公式推导、设置本身是怎样的?与此紧密联系的基础知识有什么是你不懂的?
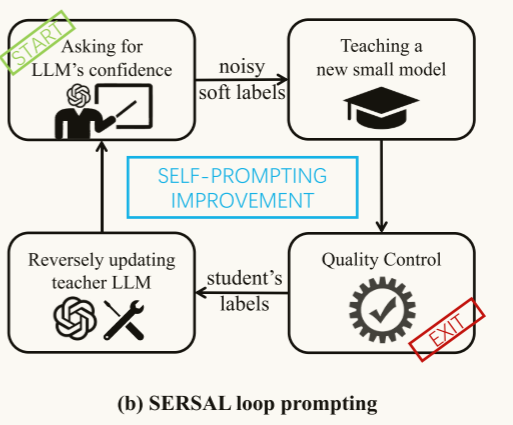
SERSAL架构是这样的,其实分为了四个板块。先把数据喂给LLM(Zero-Shot),LLM反馈一个概率值或者置信区间,这些概率值称之为noisy soft labels,让小模型从这些noisy soft labels进行学习、品质把控后再次把小模型反馈的标签回馈给大模型迭代微调;循环迭代,最终把测试数据放入学生模型,收获预测标签。
1、小模型怎么从大模型给出的noisy soft labels进行学习?
大模型给的标签噪声是很大的,所以这一步比较复杂,我们要从噪声中进行学习,即learning with noisy labels(LNL),是一种半监督学习方法。
首先要划分数据,把训练数据划分为3簇,一簇是干净的数据,一簇是噪声大的数据,还有一簇是用来早停的验证数据。
用来早停的验证数据必须特别纯净,文章中设置的是LLM预测概率大于0.9的就作为早停数据。因为说明LLM对这份数据非常有把握。
那么干净数据和噪声数据怎么来划分呢?依据“噪声大的数据难以使神经网络很快收敛”理论(在文章中有指明理论来源),我们收集所有样本的训练损失值,用GMM(高斯混合模型)对齐进行二分类聚类(干净和有噪声),最后根据后验概率来划分样本。
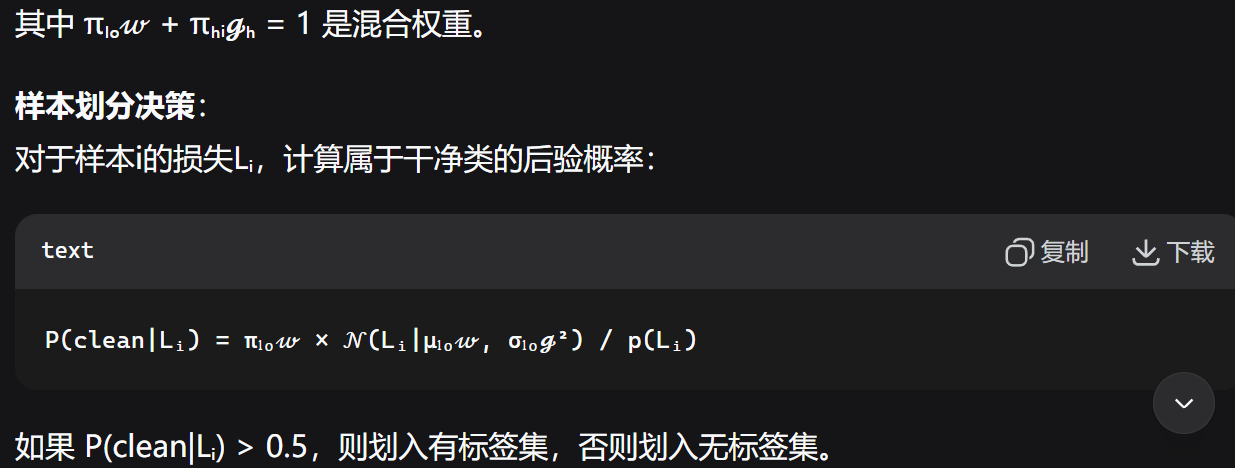
我理解的是先有P(X),也就是关于训练损失的概率分布;接着去反解或者模拟或者拟合出高斯混合模型的重要参数均值和方差,然后再去调查后验概率。如此法,可以把数据给进行划分。
第二步要开始训练模型了,干净的一簇直接喂给模型进行训练,不干净的一簇我们不做有监督学习了,做一些正则化。比如把不干净的一簇加一些噪声扰动,把扰动前后的预测损失差值作为“一致性损失”反向传播给神经网络。要同时训练一对模型,而非单一一个,因为两个模型划分数据的方式可能不同,对两模型的结果进行集成不容易“错误加深”。
最终的结果是狠狠的鞭笞小模型,小模型在验证集上进行早停。
2、什么时候把小模型给调明白呢?
3、回头微调大模型
再用小模型预测出来的数据,利用openai api 对大模型进行微调。

数据集怎么来的?实验怎么设置的?
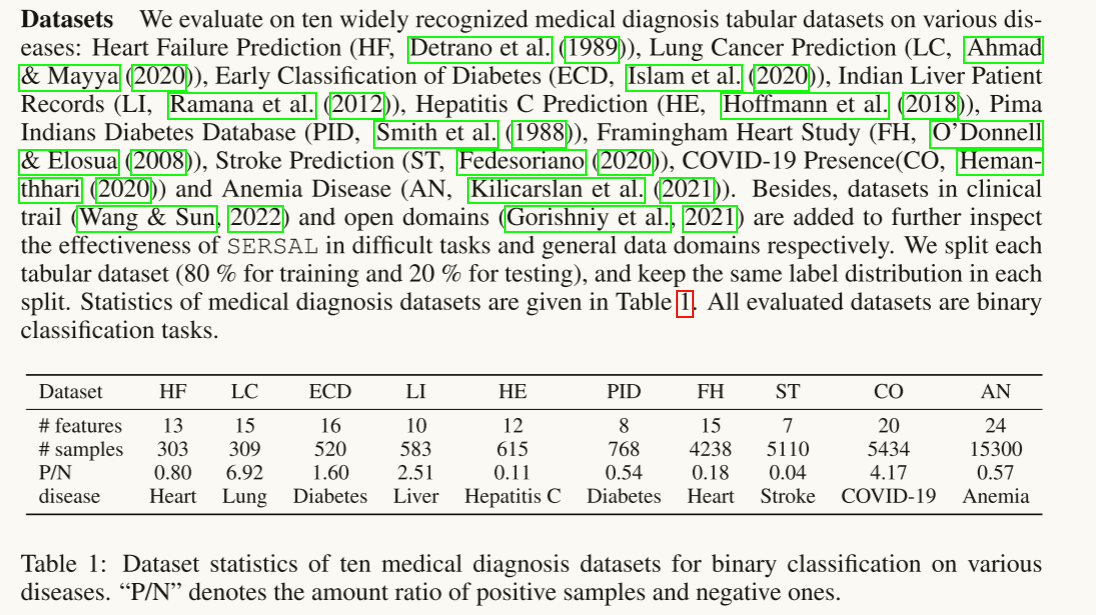

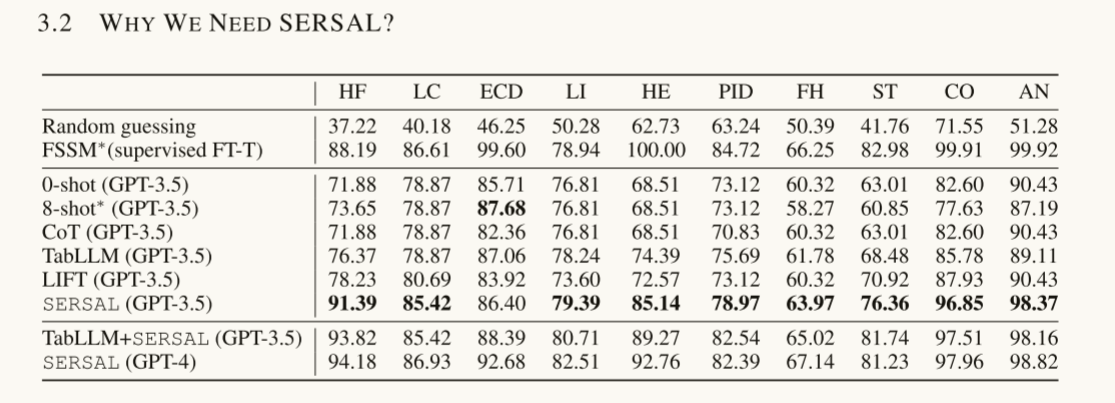
高屋建瓴地想,文章为啥子这样想,顶层设计是什么?它能为我带来什么启示?未来见到什么样的知识点,什么样的架构是与其紧密关联的?
回头看,师兄不愧是师兄,想法太权威太中意了。大模型是有幻觉的,输出的是有噪音的,但是先验知识是摆在那的,如何“去伪存真”,如何“取其精华,弃其糟粕”把先验知识纳入小模型学习呢?
其实是把大模型噪声剔除,精华留给小模型,小模型猛学,越学越猛,同时反逼着大模型每次给我输出点精华,是一个正反馈。
所以整个流程下来,实现了比较权威的无监督学习,至少跟其他的Prompt策略比起来,遥遥领先。
这种先验知识-机器学习的结合让我狠狠向往,想到了周志华老师汇报的“反绎学习”,想到了读任侃的几篇工作论文,以后看到这些知识点往这儿联想,这篇工作真的很出彩很棒,也是我想往的工作。

更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)