
LangGraph构建AI智能体:太阳能板节能计算实战项目
本文详细介绍如何使用LangGraph构建AI智能体的实战教程。LangGraph作为LangChain的扩展,支持有状态、多角色和可循环计算。通过太阳能板节能计算案例,文章展示了从定义工具、状态管理到构建工作流的完整流程,帮助开发者创建能执行复杂任务、维护状态并动态适应新信息的AI智能体。
本文详细介绍如何使用LangGraph构建AI智能体的实战教程。LangGraph作为LangChain的扩展,支持有状态、多角色和可循环计算。通过太阳能板节能计算案例,文章展示了从定义工具、状态管理到构建工作流的完整流程,帮助开发者创建能执行复杂任务、维护状态并动态适应新信息的AI智能体。
前言
在 AI 领域,检索增强生成(RAG) 系统已成为处理简单查询、生成上下文相关回答的常见工具。然而,随着对更复杂 AI 应用的需求增长,我们需要超越仅“检索+生成”的能力。于是出现了 AI 智能体(Agents)——它们能执行复杂的多步任务、在多轮交互中维护状态,并能动态适应新信息。
LangGraph 是 LangChain 的强力扩展,专为帮助开发者构建这类高级 AI 智能体而设计。它支持有状态(stateful)、多角色(multi-actor)、**可循环计算(cyclic computation)**的应用,让智能体在执行中不断“感知—决策—行动—反思—再行动”。
本文将介绍 LangGraph 如何改变 AI 开发方式,并通过一个太阳能板节能计算示例,手把手展示如何构建你自己的 AI 智能体。你将看到 LangGraph 的特性如何让系统更智能、更可适应、更贴近真实场景。
什么是 LangGraph?
LangGraph 是构建在 LangChain 之上的高级库,用于为大模型应用引入循环计算能力。
•在 LangChain 中,你通常构建有向无环图(DAG)来描述线性流程;•LangGraph 则更进一步:它支持循环(cycles),这对实现复杂、类似智能体的行为至关重要——模型可以在流程中反复迭代,根据不断变化的条件动态决定下一步动作。
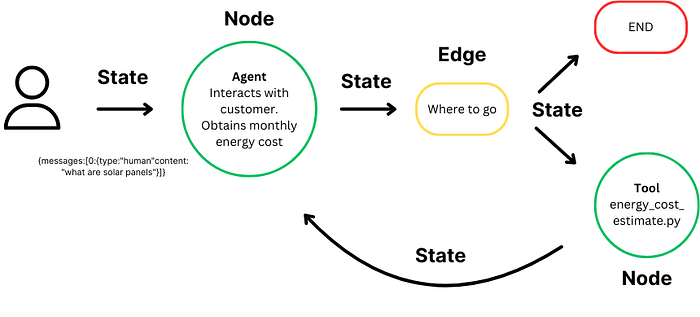
LangGraph 的节点、状态与边
LangGraph 的核心概念:有状态图(Stateful Graph)
•State(状态)
表示在计算推进过程中被持续维护与更新的上下文/记忆。
它确保每一步都能访问之前步骤的相关信息,从而基于累计数据进行动态决策。•Nodes(节点)
工作流的基本构件,代表某个计算步骤或函数。
每个节点执行特定任务,如处理输入、做出决策、调用外部系统等;
节点可自定义,以满足多种操作需求。•Edges(边)
连接节点、定义计算从一步到下一步的流向; 支持条件逻辑,可根据当前状态改变执行路径;
负责数据与控制在节点间的传递,从而实现复杂的多步流程。
为什么选择 LangGraph?
LangGraph 通过对图结构、状态与协调的无缝管理,重塑了 AI 应用的开发方式:
•自动状态管理:在多轮交互中保留上下文,让 AI 能对变化的输入做出更聪明的响应;•精简的智能体协调:保障精确执行与高效信息交换,开发者可以把精力放在设计创新工作流上;•极高的灵活性:支持打造定制化、高性能应用;•可扩展与容错:即便在企业级场景下,也能保持系统稳健与可靠。
接下来你将学到什么?
•如何用 LangGraph 搭建有状态、可循环的智能体流程;•如何让智能体分步规划—执行—评估—再规划;•以“太阳能板节能计算”为例,如何将 LangGraph 的特性落地,构建智能、可适应且可生产的 AI 系统。
分步指南
在了解了 LangGraph 的核心概念与优势之后,下面通过一个可落地的实战示例来动手实现:
我们将构建一个用于根据用户输入计算太阳能板潜在节能收益的 AI 智能体。该智能体可作为光伏销售网站上的潜在客户收集(lead generation)工具,与访客交互、给出个性化节省估算。通过收集诸如每月电费等关键数据,智能体既能帮助用户理解光伏的经济价值,也能为销售团队筛选高意向线索。此示例将展示 LangGraph 如何打造智能、动态的系统,实现复杂任务自动化并创造业务价值。
第 1 步:导入必要库
首先,导入项目所需的 Python 库与模块。这些依赖为我们使用 LangChain、LangGraph 以及 AWS 服务构建 AI 助手打下基础。
from langchain_core.tools import tool
from langchain_community.tools.tavily_search importTavilySearchResults
from langchain_core.prompts importChatPromptTemplate
from langchain_core.runnables importRunnable
from langchain_aws importChatBedrock
import boto3
from typing importAnnotated
from typing_extensions importTypedDict
from langgraph.graph.message importAnyMessage, add_messages
from langchain_core.messages importToolMessage
from langchain_core.runnables importRunnableLambda
from langgraph.prebuilt importToolNode
from langgraph.prebuilt import tools_condition
第 2 步:定义太阳能节省计算工具
接下来,我们定义一个工具(tool),用于根据用户提供的 月度电费 来估算使用太阳能后可能带来的节省。
这个工具将被智能体调用,以实现 数据驱动的交互。
from langchain_core.tools import tool
@tool
def compute_savings(monthly_cost:float)->float:
"""
根据用户的月电费计算切换到太阳能后的潜在节省情况。
参数:
monthly_cost (float):用户当前的月电费(单位:美元)
返回:
dict:包含以下估算信息:
-'number_of_panels':所需太阳能板数量
-'installation_cost':预计安装成本
-'net_savings_10_years':扣除安装成本后,10年净节省
"""
def calculate_solar_savings(monthly_cost):
# === 假设参数(可根据实际情况调整) ===
cost_per_kWh =0.28# 每度电费用(美元/kWh)
cost_per_watt =1.50# 每瓦太阳能安装费用(美元/W)
sunlight_hours_per_day =3.5# 平均每日有效日照时长
panel_wattage =350# 单块太阳能板功率(瓦)
system_lifetime_years =10# 系统寿命周期(年)
# === 计算过程 ===
# 每月耗电量(千瓦时)
monthly_consumption_kWh = monthly_cost / cost_per_kWh
# 每日所需发电量(kWh)
daily_energy_production = monthly_consumption_kWh /30
# 系统总装机容量(kW)
system_size_kW = daily_energy_production / sunlight_hours_per_day
# 需要的太阳能板数量 & 安装成本
number_of_panels = system_size_kW *1000/ panel_wattage
installation_cost = system_size_kW *1000* cost_per_watt
# 年节省与十年净节省
annual_savings = monthly_cost *12
total_savings_10_years = annual_savings * system_lifetime_years
net_savings = total_savings_10_years - installation_cost
return{
"number_of_panels": round(number_of_panels),
"installation_cost": round(installation_cost,2),
"net_savings_10_years": round(net_savings,2)
}
# 返回估算结果
return calculate_solar_savings(monthly_cost)
这段函数会处理用户的月度电费并返回一份太阳能系统收益的详细估算,包括:所需面板数量、安装成本以及 10 年期净节省。为简化演示,计算里使用了若干默认假设(如平均电价、平均日照时长)。在更高级的版本里,可以从用户处收集这些参数,从而更贴合其具体情况地给出个性化估算。
第 3 步:状态管理与错误处理
稳健的 AI 系统离不开有效的状态管理与错误处理。下面定义两个实用工具:
•handle_tool_error:在工具执行出错时,生成与具体 tool call 关联的错误消息;•create_tool_node_with_fallback:创建带兜底回退能力的工具节点,出错时自动调用错误处理逻辑。
from langchain_core.messages importToolMessage
from langchain_core.runnables importRunnableLambda
from langgraph.prebuilt importToolNode
def handle_tool_error(state)-> dict:
"""
在工具执行过程中处理错误。
参数:
state (dict):智能体当前状态,包含消息历史与 tool call 信息。
返回:
dict:包含针对每个出错 tool 的错误消息(ToolMessage)的字典。
"""
# 从状态中取出异常
error = state.get("error")
# 取出最后一条消息中的 tool_calls(LangChain/LangGraph 产生)
tool_calls = state["messages"][-1].tool_calls
# 针对每一个 tool call,生成一条带有错误详情的 ToolMessage,并与其 id 关联
return{
"messages":[
ToolMessage(
content=f"Error: {repr(error)}\n please fix your mistakes.",
tool_call_id=tc["id"],
)
for tc in tool_calls
]
}
def create_tool_node_with_fallback(tools: list)-> dict:
"""
创建带回退(fallback)机制的Tool节点。
参数:
tools (list):需要挂载到该节点的工具列表。
返回:
dict:带错误兜底的工具节点;一旦发生异常,将调用 handle_tool_error。
"""
returnToolNode(tools).with_fallbacks(
[RunnableLambda(handle_tool_error)],# 用 RunnableLambda 包装错误处理函数
exception_key="error"# 指定捕获异常的键
)
这些函数可确保在工具执行过程中一旦出现错误,系统能优雅降级并向用户提供有用的反馈。
第 4 步:定义 State(状态)与 Assistant 类
在这一步,我们将定义智能体如何管理会话状态(对话的持续上下文),并保证其能正确响应用户输入与工具输出。
为此,先用 Python 的 TypedDict 来定义状态结构 State——它描述在 LangGraph 中节点之间传递的消息格式。状态中会保存整段对话的消息列表,其中既包括用户输入,也包括智能体回复和工具输出。
from typing importAnnotated
from typing_extensions importTypedDict
from langgraph.graph.message importAnyMessage, add_messages
classState(TypedDict):
# 一个“可累积”的消息列表:
# - AnyMessage:统一抽象,兼容人类消息、AI 消息、工具消息(ToolMessage)等
# - add_messages:LangGraph 的 reducer,用于将新消息追加到状态中
messages:Annotated[list[AnyMessage], add_messages]
在有了 State 之后,我们需要定义一个 Assistant 类 来驱动智能体的运行。
这个类的职责是:
•执行智能体的主循环;•调用工具(如 compute_savings);•管理对话流转(处理用户输入与工具结果);•兜底错误与无效输出(re-prompt 用户或请求澄清)。
核心逻辑基于一个 Runnable(可运行单元),它定义了调用 LLM 和工具的具体流程。
from langchain_core.runnables importRunnable
classAssistant:
def __init__(self, runnable:Runnable):
"""
初始化Assistant。
参数:
runnable (Runnable):定义 LLM 与工具交互流程的Runnable对象。
"""
self.runnable = runnable
def __call__(self, state:State):
"""
执行智能体主循环,确保最终返回有效输出。
参数:
state (State):当前智能体状态,包含消息与上下文。
返回:
dict:更新后的状态(包含新消息)。
"""
whileTrue:
# 运行当前流程
result =self.runnable.invoke(state)
# 检查工具是否未返回有效输出
ifnot result.tool_calls and(
not result.content
or isinstance(result.content, list)
andnot result.content[0].get("text")
):
# 请求用户澄清或重试
messages = state["messages"]+[("user","Respond with a real output.")]
state ={**state,"messages": messages}
else:
# 一旦得到有效输出,就退出循环
break
# 返回包含新消息的最终状态
return{"messages": result}
这些配置对于维持对话流程并确保助手基于上下文做出恰当响应至关重要。
第 5 步:使用 AWS Bedrock 配置 LLM
本步骤我们为智能体接入 AWS Bedrock 上的 LLM(如 Anthropic Claude),作为语言能力引擎。
要调用 AWS 服务,你必须先正确配置 AWS 凭据,否则无法连接 Bedrock 并运行模型。
常见凭据配置方式包括:
•通过 AWS CLI 登录并写入本地凭据(aws configure)•设置环境变量:AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY、AWS_SESSION_TOKEN(可选)、AWS_DEFAULT_REGION•使用可被 AWS SDK 访问的 credentials 文件(通常位于 ~/.aws/credentials)
完成凭据与区域设置后,即可创建 Bedrock Runtime 客户端,并实例化 LangChain 的 ChatBedrock:
import boto3
from langchain_aws importChatBedrock
def get_bedrock_client(region):
return boto3.client("bedrock-runtime", region_name=region)
def create_bedrock_llm(client):
returnChatBedrock(
model_id='anthropic.claude-3-sonnet-20240229-v1:0',
client=client,
model_kwargs={'temperature':0},
region_name='us-east-1'
)
llm = create_bedrock_llm(get_bedrock_client(region='us-east-1'))
这一步的集成保证了助手能够有效理解并响应用户输入。
第 6 步:定义 Assistant 的工作流(Workflow)
在配置好 LLM 和 工具 之后,我们需要定义智能体的工作流。 工作流决定了智能体如何:
•与用户沟通;•何时收集所需信息(如月度电费);•何时调用工具(如 compute_savings);•如何将结果返回给用户。
核心部分是创建一个提示模板(Prompt Template),明确智能体的身份、对话目标与交互规则。
from langchain_core.prompts importChatPromptTemplate
primary_assistant_prompt =ChatPromptTemplate.from_messages(
[
(
"system",
'''You are a helpful customer support assistant for Solar Panels Belgium.
You should get the following information from them:
- monthly electricity cost
If you are not able to discern this info, ask them to clarify!Donot attempt to wildly guess.
After you are able to discern all the information, call the relevant tool.
''',
),
("placeholder","{messages}"),
]
)
•system 消息:作为智能体的“行为守则”,引导其向用户询问月度电费,若信息不明确就不要猜测,并持续追问直至收集到必要数据。•placeholder:用于动态注入对话历史,让助手能基于上下文持续对话,并让用户的上一轮输入影响下一步动作。
接下来,定义智能体交互中会用到的工具;主要工具是 compute_savings,它会基于用户的月度电费计算潜在节省。将工具列在清单里后,通过 llm.bind_tools() 绑定到助手工作流,使智能体在对话中按需触发工具,实现人与工具的无缝衔接。
# 定义助手在本阶段将使用的工具
part_1_tools =[
compute_savings
]
# 将工具绑定到助手工作流(Prompt → LLM(已绑定工具))
part_1_assistant_runnable = primary_assistant_prompt | llm.bind_tools(part_1_tools)
第 7 步:构建图结构
本步骤使用 LangGraph 搭建智能体的状态图,控制助手如何处理用户输入、何时触发工具、以及各阶段之间的流转。
图中包含用于核心动作的节点(nodes),以及决定节点间走向的边(edges)。
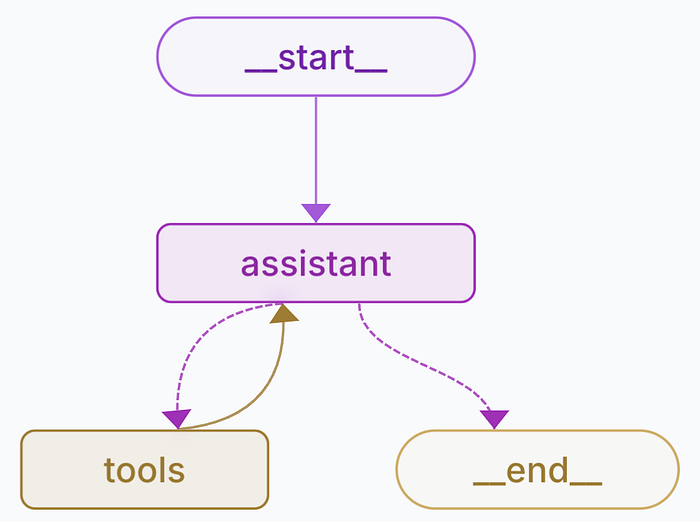
用于计算太阳能节省的 AI 智能体流程图
在 LangGraph 中,每个 节点 代表一个操作步骤(如与用户交互或执行工具)。本示例定义两个关键节点:
•Assistant 节点:管理对话流程,向用户询问月度电费并处理响应;•Tool 节点:执行工具(如 compute_savings)来计算节省结果。
from langgraph.graph importStateGraph
builder =StateGraph(State)
# 1) 助手节点:驱动对话与决策(是否需要调用工具等)
builder.add_node("assistant",Assistant(part_1_assistant_runnable))
# 2) 工具节点:实际执行 compute_savings,并带有错误兜底
builder.add_node("tools", create_tool_node_with_fallback(part_1_tools))
边用于定义节点之间的流向。在本例中:
•助手(assistant)先发起对话;•当收集到所需输入后,转入工具节点;•工具执行完成后,返回助手节点继续对话或收尾。
builder.add_edge(START,"assistant")# 从起点进入 assistant
builder.add_conditional_edges("assistant", tools_condition)# 收到必要输入后转入 tools
builder.add_edge("tools","assistant")# 工具执行结束后回到 assistant
为确保对话在多步交互中能记住上下文,我们使用 MemorySaver 持久化图的会话状态(State):
from langgraph.checkpoint.memory importMemorySaver
memory =MemorySaver()
graph = builder.compile(checkpointer=memory)
第 8 步:运行助手
最后,通过初始化图工作流并开始对话来运行助手。
# import shutil
import uuid
# 构造一个示例对话,模拟用户与助手的交互
tutorial_questions =[
'hey',
'can you calculate my energy saving',
"my montly cost is $100, what will i save"
]
thread_id = str(uuid.uuid4())
config ={
"configurable":{
"thread_id": thread_id,
}
}
_printed =set()
for question in tutorial_questions:
events = graph.stream(
{"messages":("user", question)}, config, stream_mode="values"
)
foreventin events:
_print_event(event, _printed)
结论
通过以上步骤,你已经成功构建了一个基于 LangGraph 的 AI 助手,它能够根据用户输入计算太阳能板节能效益。
本教程展示了 LangGraph 在管理复杂的多步骤流程中的强大能力,并突出了如何结合先进的 AI 工具来高效解决现实问题。
无论是开发用于 客户支持、能源管理 还是其他应用场景的 AI 智能体,LangGraph 都提供了你所需的:
•灵活性(Flexibility):可定制复杂工作流;•可扩展性(Scalability):支持从小规模实验到企业级部署;•稳健性(Robustness):保证系统在长时运行与多轮交互中的可靠表现。
👉 借助 LangGraph,你可以更快地将 AI 创意转化为实用的智能系统,并让它们在真实世界中创造价值。
https://medium.com/@lorevanoudenhove/how-to-build-ai-agents-with-langgraph-a-step-by-step-guide-5d84d9c7e832
大模型未来如何发展?普通人能从中受益吗?
在科技日新月异的今天,大模型已经展现出了令人瞩目的能力,从编写代码到医疗诊断,再到自动驾驶,它们的应用领域日益广泛。那么,未来大模型将如何发展?普通人又能从中获得哪些益处呢?
通用人工智能(AGI)的曙光:未来,我们可能会见证通用人工智能(AGI)的出现,这是一种能够像人类一样思考的超级模型。它们有可能帮助人类解决气候变化、癌症等全球性难题。这样的发展将极大地推动科技进步,改善人类生活。
个人专属大模型的崛起:想象一下,未来的某一天,每个人的手机里都可能拥有一个私人AI助手。这个助手了解你的喜好,记得你的日程,甚至能模仿你的语气写邮件、回微信。这样的个性化服务将使我们的生活变得更加便捷。
脑机接口与大模型的融合:脑机接口技术的发展,使得大模型与人类的思维直接连接成为可能。未来,你可能只需戴上头盔,心中想到写一篇工作总结”,大模型就能将文字直接投影到屏幕上,实现真正的心想事成。
大模型的多领域应用:大模型就像一个超级智能的多面手,在各个领域都展现出了巨大的潜力和价值。随着技术的不断发展,相信未来大模型还会给我们带来更多的惊喜。赶紧把这篇文章分享给身边的朋友,一起感受大模型的魅力吧!
那么,如何学习AI大模型?
在一线互联网企业工作十余年里,我指导过不少同行后辈,帮助他们得到了学习和成长。我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑。因此,我坚持整理和分享各种AI大模型资料,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频。
学习阶段包括:
1.大模型系统设计
从大模型系统设计入手,讲解大模型的主要方法。包括模型架构、训练过程、优化策略等,让读者对大模型有一个全面的认识。

2.大模型提示词工程
通过大模型提示词工程,从Prompts角度入手,更好发挥模型的作用。包括提示词的构造、优化、应用等,让读者学会如何更好地利用大模型。

3.大模型平台应用开发
借助阿里云PAI平台,构建电商领域虚拟试衣系统。从需求分析、方案设计、到具体实现,详细讲解如何利用大模型构建实际应用。

4.大模型知识库应用开发
以LangChain框架为例,构建物流行业咨询智能问答系统。包括知识库的构建、问答系统的设计、到实际应用,让读者了解如何利用大模型构建智能问答系统。
5.大模型微调开发
借助以大健康、新零售、新媒体领域,构建适合当前领域的大模型。包括微调的方法、技巧、到实际应用,让读者学会如何针对特定领域进行大模型的微调。


6.SD多模态大模型
以SD多模态大模型为主,搭建文生图小程序案例。从模型选择、到小程序的设计、到实际应用,让读者了解如何利用大模型构建多模态应用。
7.大模型平台应用与开发
通过星火大模型、文心大模型等成熟大模型,构建大模型行业应用。包括行业需求分析、方案设计、到实际应用,让读者了解如何利用大模型构建行业应用。


学成之后的收获👈
• 全栈工程实现能力:通过学习,你将掌握从前端到后端,从产品经理到设计,再到数据分析等一系列技能,实现全方位的技术提升。
• 解决实际项目需求:在大数据时代,企业和机构面临海量数据处理的需求。掌握大模型应用开发技能,将使你能够更准确地分析数据,更有效地做出决策,更好地应对各种实际项目挑战。
• AI应用开发实战技能:你将学习如何基于大模型和企业数据开发AI应用,包括理论掌握、GPU算力运用、硬件知识、LangChain开发框架应用,以及项目实战经验。此外,你还将学会如何进行Fine-tuning垂直训练大模型,包括数据准备、数据蒸馏和大模型部署等一站式技能。
• 提升编码能力:大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握将提升你的编码能力和分析能力,使你能够编写更高质量的代码。
学习资源📚
- AI大模型学习路线图:为你提供清晰的学习路径,助你系统地掌握AI大模型知识。
- 100套AI大模型商业化落地方案:学习如何将AI大模型技术应用于实际商业场景,实现技术的商业化价值。
- 100集大模型视频教程:通过视频教程,你将更直观地学习大模型的技术细节和应用方法。
- 200本大模型PDF书籍:丰富的书籍资源,供你深入阅读和研究,拓宽你的知识视野。
- LLM面试题合集:准备面试,了解大模型领域的常见问题,提升你的面试通过率。
- AI产品经理资源合集:为你提供AI产品经理的实用资源,帮助你更好地管理和推广AI产品。
👉获取方式: 😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】

更多推荐


 23
23 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)