
GitHub 上最牛逼的 OCR 开源项目,5 万人点赞。
如果你对编程感兴趣,想要学习python、人工智能、Java、前端,这里给大家分享一份编程全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!1️⃣零基础入门① 学习路线对于从来没有接触过编程的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。② 路线对应学习视频还有很多适合0基础入门的学习视频,有
在大模型刷屏的今天,似乎无论什么任务都可以 all in 大模型,但这真的是最好的解决方案吗?
当大模型致力于卷精度、拼参数量时,其实有一个能决定AI理解能力的关键任务往往被忽视了,那就是 OCR(文字识别与文档解析)。OCR能力对于AI来说其实非常重要,往小说,它决定了输入的非结构化信息的质量;往大说,它是AI理解人类信息的“眼睛”,它的好坏直接决定了AI的天花板有多高。
截止到目前,开源的OCR模型呈现出百家齐放的态势,但如果非要从其中选出一个真正最能打的、口碑最好的,我首推OCR界的“六边形战士”:PaddleOCR。
不只是我这么说,我问了Deepseek,它也是如此说道:

那么,PaddleOCR 作为小模型,凭什么能在大模型时代继续封神?
01
PaddleOCR 历史简述
作为一路跟随 PaddleOCR 成长的开发者,我觉得它这几年迭代非常迅猛,从一开始主打超轻量模型,到后来效果和速度双管齐下,社区生态也越来越火,多数OCR项目都得背靠PaddleOCR吃饭,基本成为了OCR界的“扛把子”。
其实在2020年那会儿,PaddleOCR开源就一鸣惊人,刚开源就放出了一个轻量OCR模型,直接冲上了GitHub Trending日榜第一,后来还干到了Papers with code trending榜第一。
包括我在内的很多开发者都惊了,这么小的模型效果居然真的能打。接下来就是差不多2021年或者2022年前后,PaddleOCR重磅推出了PP-OCRv2,效果、速度双重大幅提升,并且总模型大小仍然轻量,服务器和移动端都能轻松部署。再到之后的PP-OCRv3和v4,都不断刷新着OCR的精度和效率。
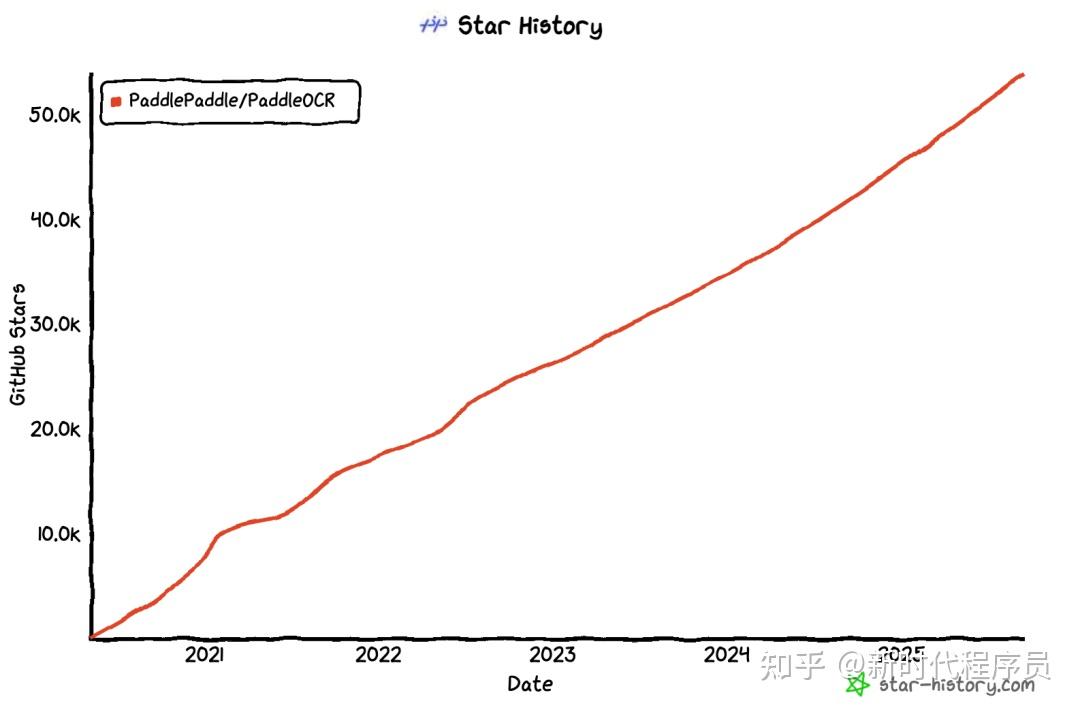
从2020年开源至今,PaddleOCR一路高歌猛进,GitHub Star数一路飙升,先后突破了10k、20k、30k,一直到达今天惊人的 55k+ star,从一个高效的OCR工具,一步步成长为一个覆盖多种场景、支持多语言、模型轻量且性能强劲的开源项目,背后是团队持续的创新和社区的大力支持。
作为开发者,我们很乐意看到这样的项目,它确实帮我们解决了不少实际问题。
02
PaddleOCR 3.x 重磅升级
自2025年以来,PaddleOCR 历经三次重大版本迭代,持续推动多语种OCR技术的创新发展。从 PP-OCRv5、PP-StructureV3 以及 PP-ChatOCRv4开始,实现了对42种语言的准确识别,大幅强化部署能力并引入 MCP 服务器支持,为下游应用高效集成 PaddleOCR 核心能力提供了坚实基础。
此外,PaddleOCR升级了各种部署能力,除了支持高性能推理外,也支持用户将模型通过一行命令部署为一个工业级API,也支持MCP server等和大模型做交互的部署方式。一路走来,PaddleOCR 始终屹立于多语种文本识别技术的最前沿,已被公认为业界领先的开源 OCR 系统,集成于 MinerU、Umi-OCR、RAGFlow 等多个知名项目中,奠定了其在 OCR 领域的领导地位。即便是与 TextIn 等商业 OCR 产品相比,PaddleOCR 也展现出卓越的性能与竞争力,充分体现了雄厚的技术实力与广泛的开源影响力。
PP-OCRv5 多语种识别:语种覆盖广,识别精度高
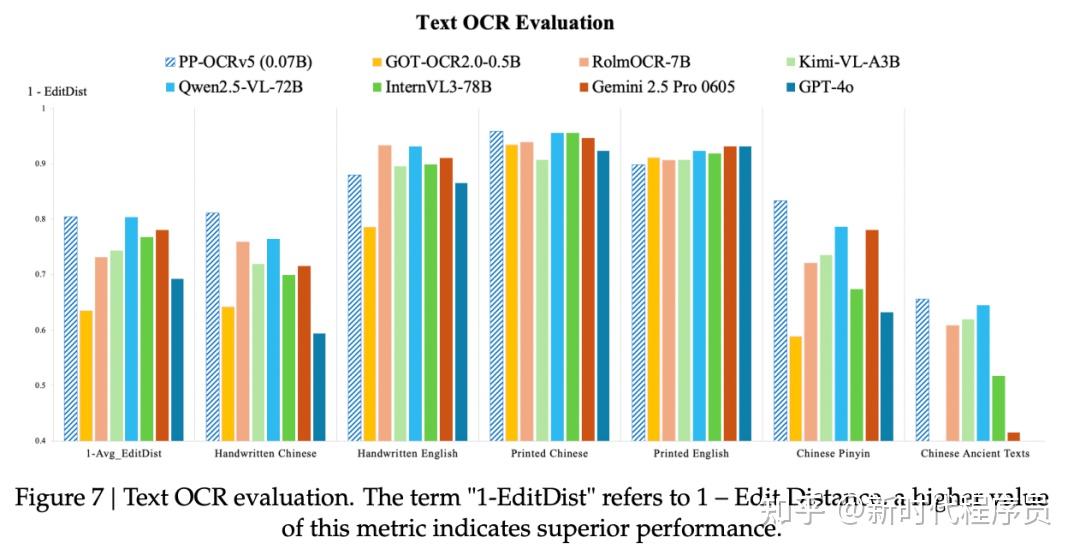
PP-OCRv5 现已全面支持 42 种语言识别,较上一代模型实现了跨越式升级。其识别场景广泛覆盖印刷体、手写体、通用文本、拼音、古籍、生僻字等多个高难度领域,并在识别精度上实现全方位显著提升,重新定义了多语种OCR的技术标杆。
指标不输大模型
识别语种全面覆盖
中文 ↓

中文繁体↓

英文↓

法语↓

西班牙语↓

葡萄牙语↓

德文↓

日文↓

韩语↓

俄文↓

泰文↓

希腊文↓

南非荷兰文↓

意大利文↓

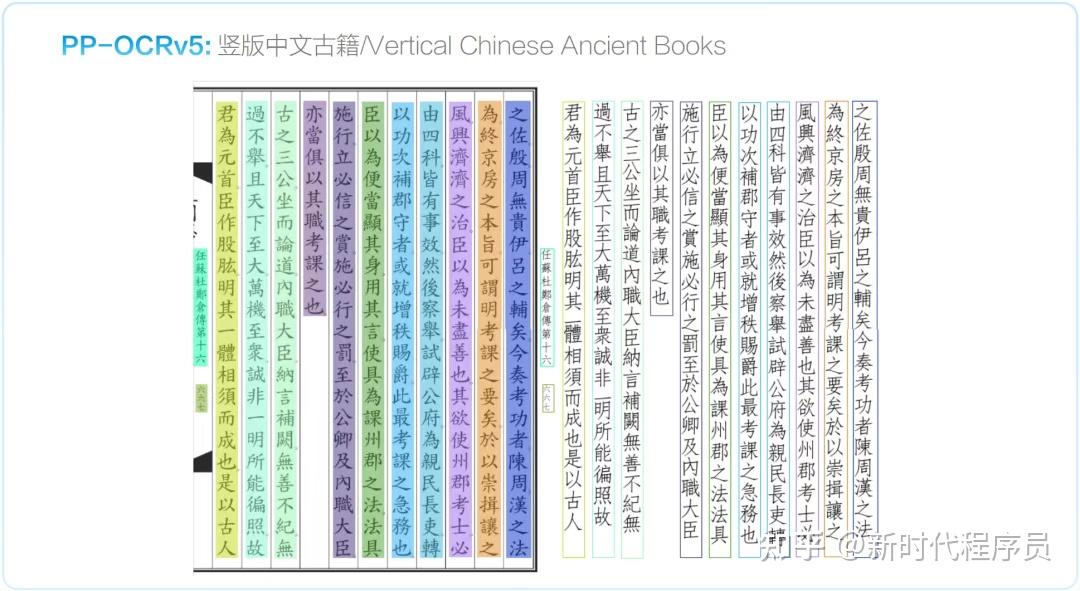
识别边界大幅延伸







PP-StructureV3 智能文档解析:结构精准还原,理解深入语义
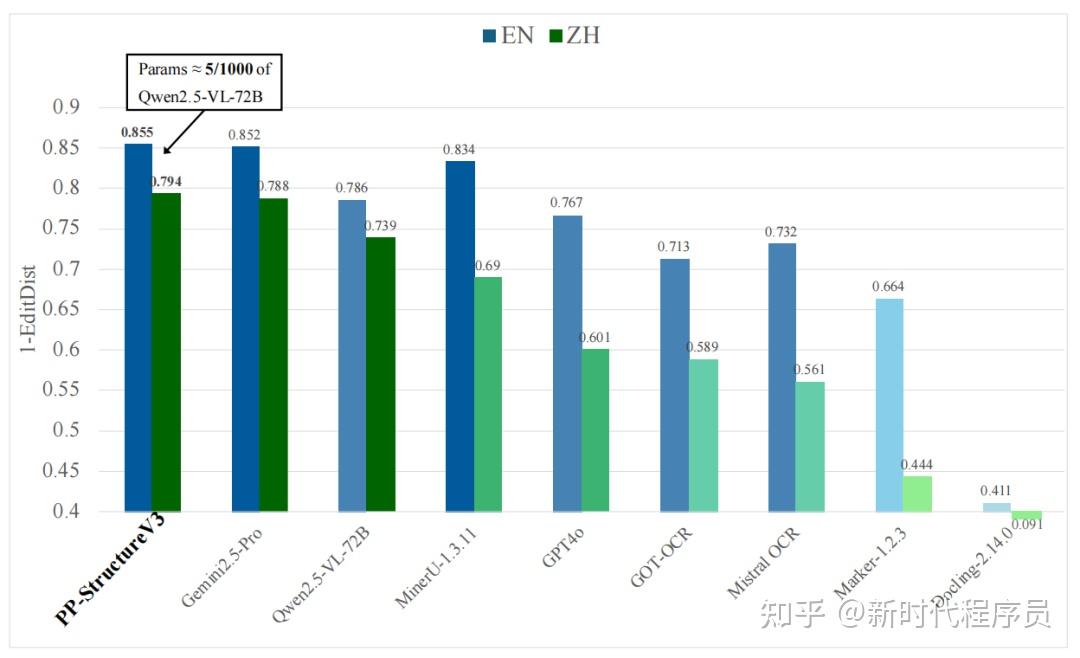
PP-StructureV3 依托 PaddleOCR 强大的多模态解析能力——涵盖版面检测、文本识别、表格重构、公式提取、图表解析与智能页面排序——一举实现从复杂版式图像到清晰结构化 Markdown 的高精度转化,并在 OmniDocBench 数据集上表现优异,效果领先于现有的一众 pipeline 方案与多模态大模型方案。该能力显著加速高质量企业级知识库的构建进程,为大规模模型训练与应用提供坚实可靠的语料基础。
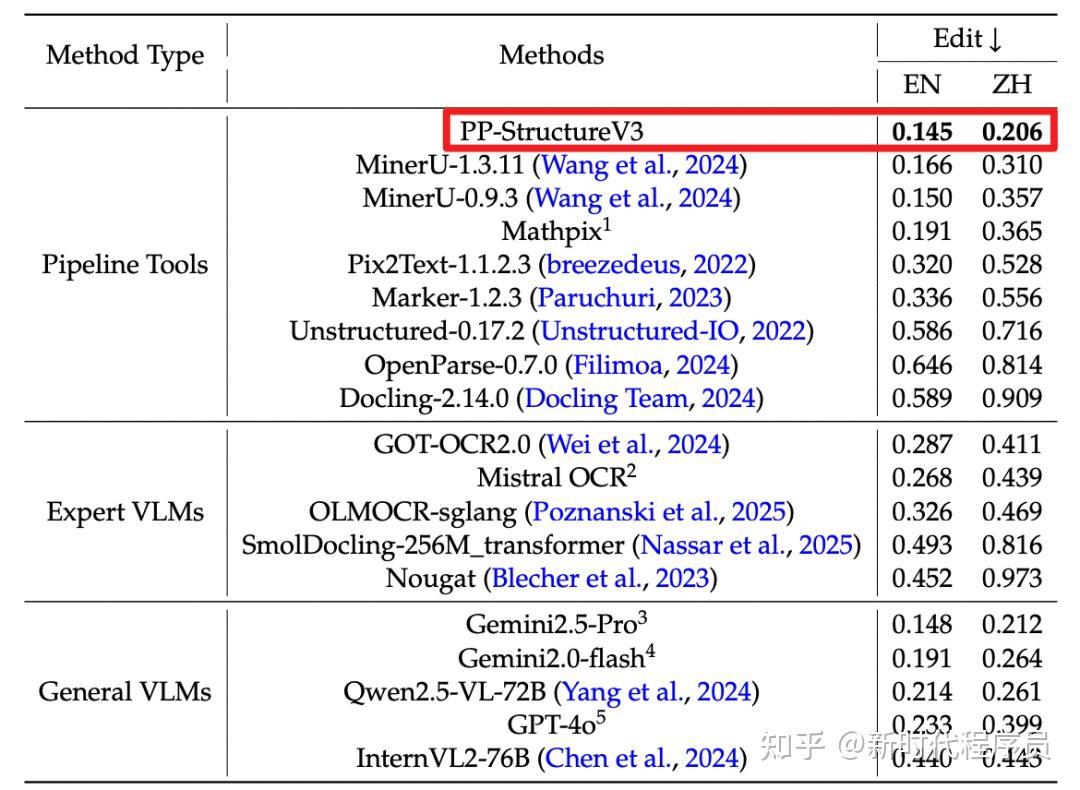
覆盖多种场景的文档解析
含公式低质扫描件 ↓

表格内公式 ↓

中文手写笔记 ↓

低质扫描竖排繁体中文文档 ↓

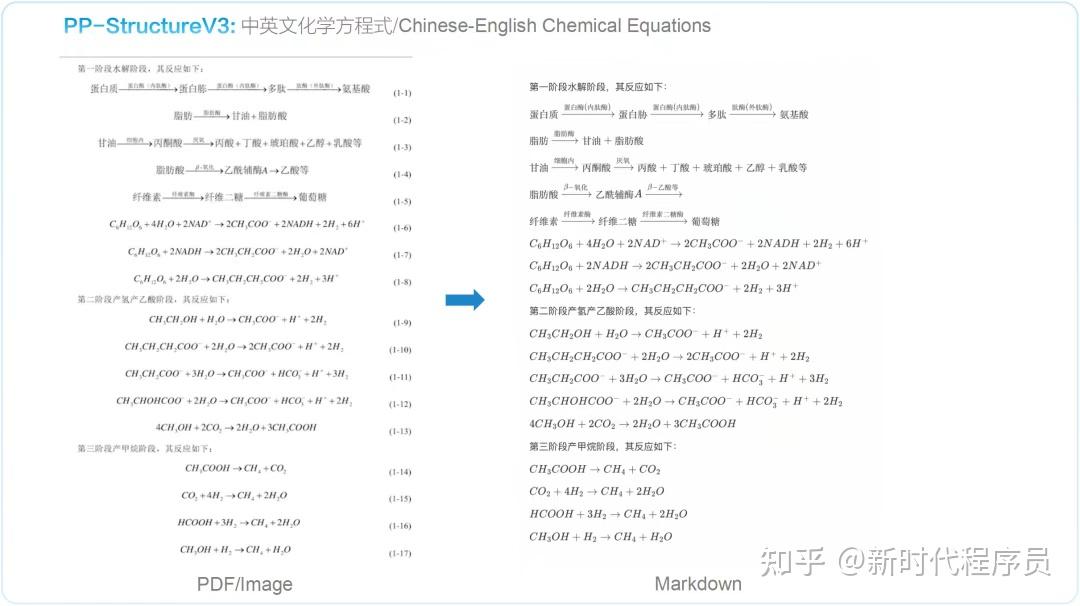
中英文化学方程式 ↓
繁体中文古籍 ↓

中学数学教辅材料 ↓

中文多栏文本 ↓

日文论文 ↓

复杂公式 ↓

中文公式 ↓

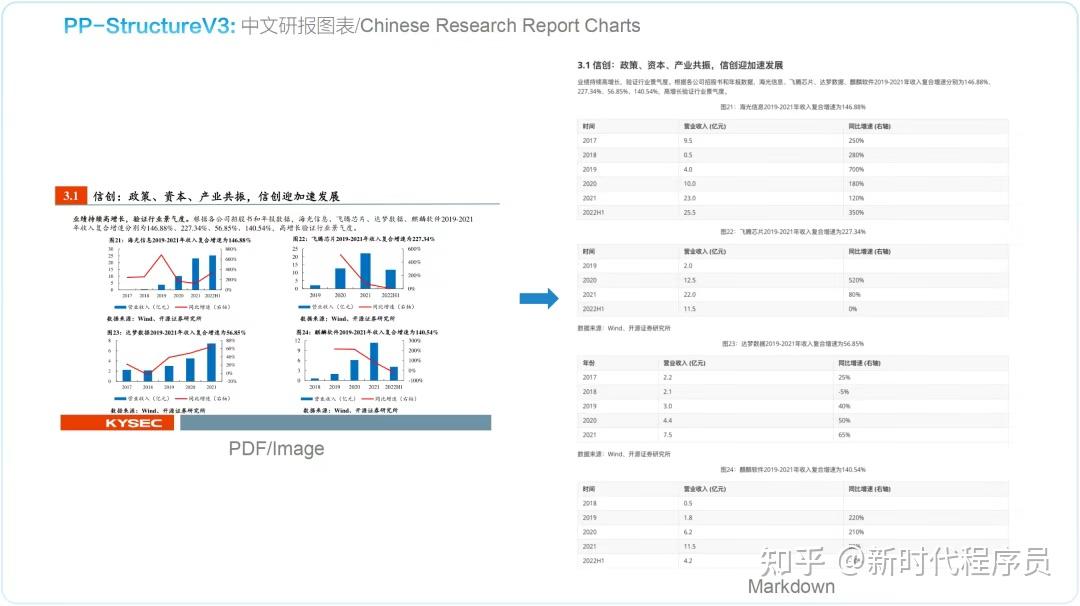
中文研报图表 ↓
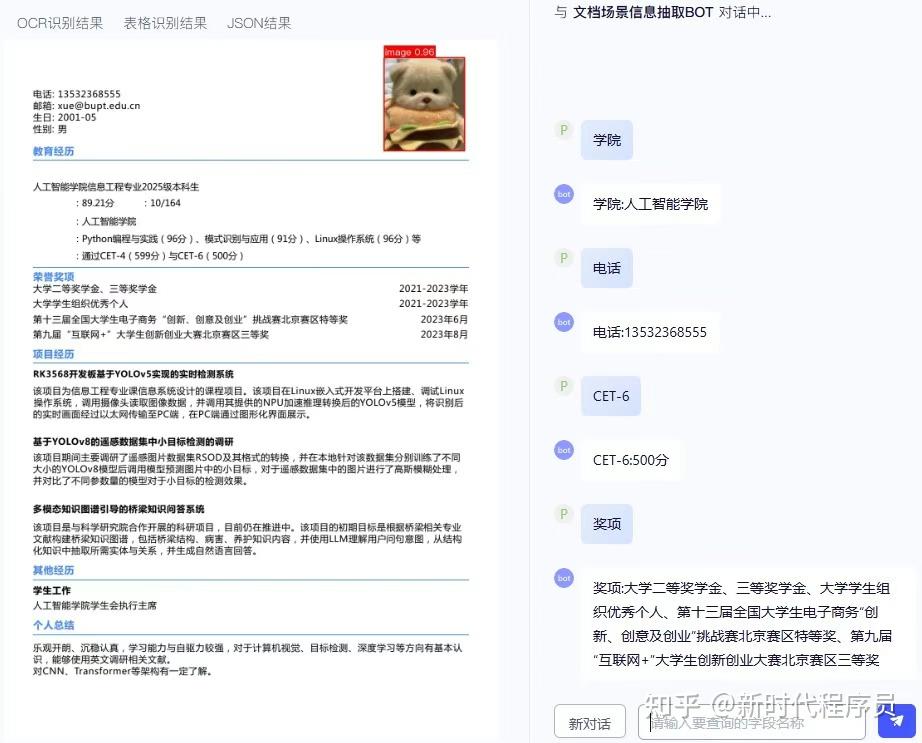
PP-ChatOCRv4 关键信息抽取:对话即抽取,一问即得
PP-ChatOCRv4 创新性地采用“大小模型协同”架构,深度融合 PaddleOCR 精准的文档识别能力、文心大模型4.5 的强大语义理解与 PP-DocBee2 多模态文档解析模型的深层结构感知,实现了面向复杂场景的高精度、端到端文档关键信息智能抽取。
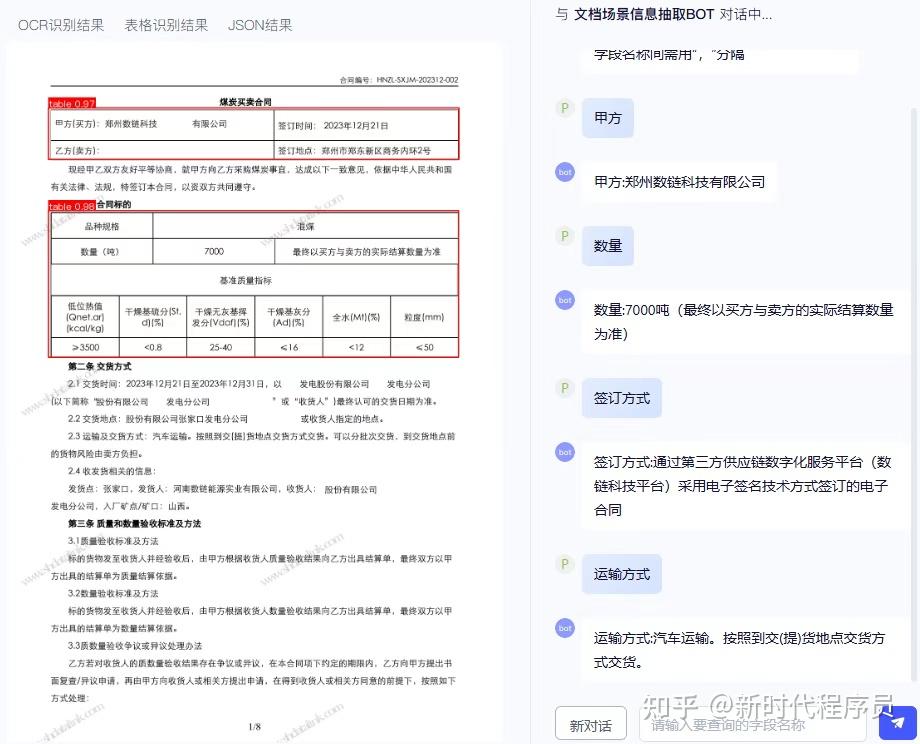
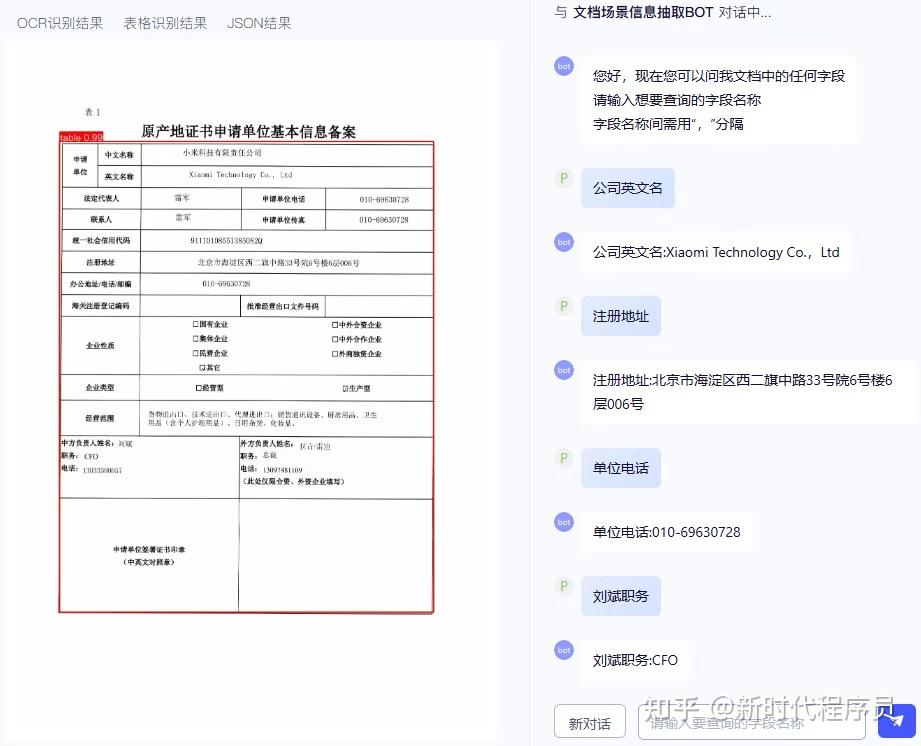
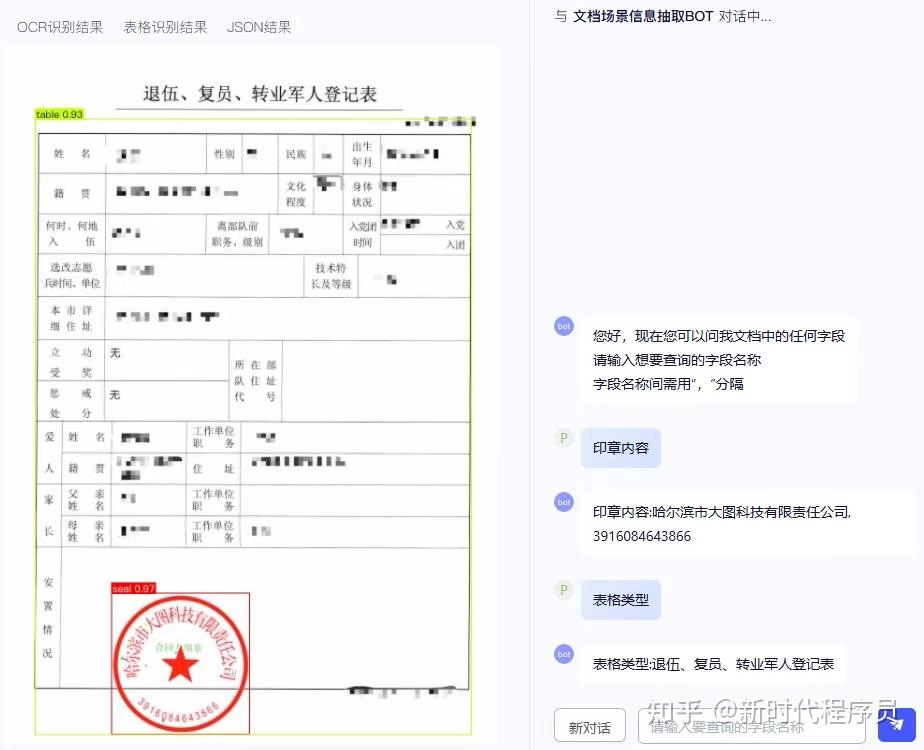
03
总结
作为五年来一路跟着PaddleOCR的开发者,今年这三个版本的迭代速度和技术突破确实让人印象深刻。每一次升级都直指我们开发中的实际痛点。来说说我认为的几个关键改进:
① 核心文字识别能力持续突破,精度与场景覆盖并重:PaddleOCR 的核心文字识别模型演进到PP-OCRv5这个版本, 精度大幅跃升,复杂场景的覆盖能力更强。
② 多语言支持从“有”到“优”,真正拥抱全球化:PaddleOCR 的多语言识别能力在这三个版本中不断迭代优化,支持的语种文字越来越多,正在全面拥抱全球化。
③ 部署与生态:开发者体验日趋完善:PaddleOCR 还是一如既往地重视部署效率和开发者体验,新增了对昆仑芯、昇腾等国产硬件的支持,引入 MCP 服务器功能,助力用户在工业产线系统、桌面应用等多种场景下高效集成和部署。
总的来看,从 3.0 到 3.2,PaddleOCR 的迭代清晰地展现了一条技术发展路径:从解决单一的“看得见”问题,演进到解决“看得懂”、“用得好”的复杂需求。它不仅是一个OCR工具,更正在成为一个强大的多语言文档理解与处理平台。
对于开发者而言,这意味着我们能更轻松、更高效地构建出能力更强、体验更优的应用,去应对全球化和数字化带来的各种挑战。PaddleOCR确实越来越卷,但这种“内卷”卷对了地方——卷技术,卷生态,最终受益的是我们开发者。
最后总结
如果你对编程感兴趣,想要学习python、人工智能、Java、前端,这里给大家分享一份编程全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
1️⃣零基础入门
① 学习路线
对于从来没有接触过编程的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
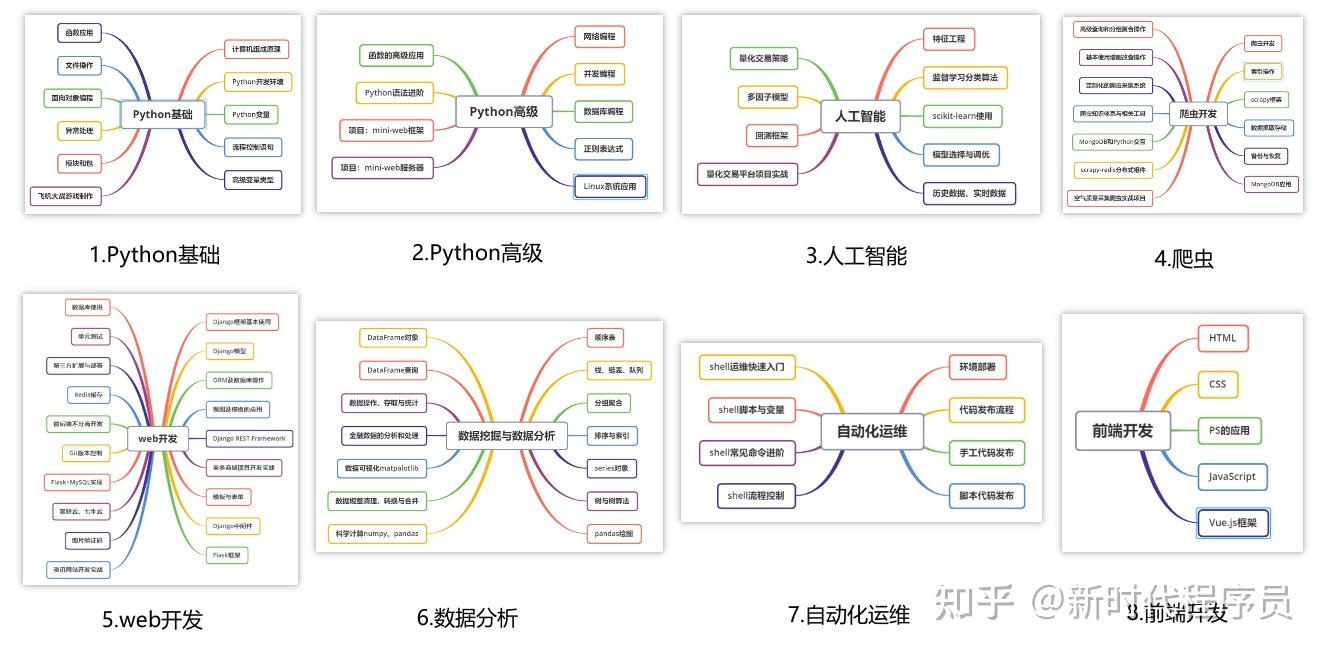
② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手编程~
2️⃣国内外书籍、文档
① 文档和书籍资料
3️⃣工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②编程实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!
③小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!
4️⃣大厂面试题
我们学会了编程之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
完整版获取方式:
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)