
亚马逊云科技AI Agents开发框架,保障出海数据高质量
本文介绍了如何利用AI技术构建智能化数据质量监控系统。通过结合StrandsAgents框架、Amazon Bedrock、dbt和Amazon Redshift,该系统能自动检测数据异常、诊断根因并提供修复建议。文章详细展示了技术实现方案,包括dbt建模错误预设、Agent工作流编排和多语言报告生成。该系统解决了传统数据质量管理中人工分析耗时、修复建议模糊等问题,实现了自动化、智能化的数据质量管
在当今数据驱动的商业环境中,数据质量已成为企业运营的关键因素。
因为数据质量问题造成的企业运营决策失误的案例每天都在发生。

*图片源自亚马逊云科技官网
例如某电商平台在分析季度业绩时,发现其广告投放效果的ROI指标异常偏高。经过营销团队的深入分析,发现是因为数据建模过程中的一个微小错误导致的。在计算广告转化销售额时,ETL过程中未正确处理订单退款数据,导致销售金额被重复计算。这个数据质量问题不仅造成了营销团队错误地增加了某些低效渠道的预算投入,还导致了近一个月的错误决策,造成了显著的预算浪费。如果能够及时发现订单金额的异常波动,这个问题本可以被提前预防。
随着数据规模的不断扩大和数据管道的日益复杂,数据工程师面临着越来越大的挑战。他们需要确保数据的准确性、完整性和及时性,同时还要能够快速识别和解决潜在的数据质量问题。

*图片源自亚马逊云科技官网
在实际生产环境中,数据工程师往往面临着以下挑战:
-
需要同时监控数百个数据模型的质量。
-
数据异常往往涉及多个上下游表的复杂关系。
-
问题定位和根因分析需要大量的人工时间。
-
数据质量问题发现往往滞后于业务影响。
传统的数据质量管理方法往往依赖于人工检查和固定的监控规则,这不仅耗时费力,而且容易错过新出现的数据异常。在实际生产环境中,当数据质量出现问题时,数据工程师常常需要花费大量时间来排查原因,这严重影响了团队的工作效率和数据产品的可靠性。
为了解决这些挑战,可以借助新兴的AI技术和成熟的数据工程工具,来构建智能化的数据质量监控系统。

*图片源自亚马逊云科技官网
本文将介绍如何结合Strands Agents框架、Amazon Bedrock、dbt(data build tool)和Amazon Redshift,构建一个能够自动监控、诊断和报告数据质量问题的智能系统,实现:
-
自动执行数据质量检测
-
智能分析异常指标的根因
-
追踪数据血缘关系辅助问题定位
-
生成可执行的修复建议
技术实现
AI Agents
在数据质量监控逐渐引入AI Agents来增强自动化诊断能力。这类智能Agent通常由大语言模型(LLM)+工具组成,可以自主扫描数据管道和指标,一旦发现异常立即触发分析。
例如,某些数据质量平台中的数据血缘Agent能够自动绘制数据流向图,持续追踪上游及下游依赖;在检测到关键指标偏离时,这些Agent还会关联多维信号(跨列、跨时间的指标模式)来识别真正重要的异常。
更重要的是,智能Agent具备快速根因归因能力:它们可以沿着dbt等工具提供的血缘关系链,将异常现象追溯到具体的数据表、字段或源头任务,从而立刻定位问题来源。
Strands Agents
亚马逊云科技推出的Strands Agents是一个开源、轻量级的AI Agents开发框架。其设计原则是“模型驱动”:将规划和执行任务的逻辑交给LLM完成,无需传统的硬编码工作流编排。
*图片源自亚马逊云科技官网
Strands框架拥有以下特性:
-
无关模型,支持多种LLM。
-
无需编排(orchestration-free),让开发者关注结果而非流程细节。
-
内置可观测性,集成OpenTelemetry,可监控Agent运行时的跟踪和指标)。
-
通过Anthropic的MCP工具支持,使其能与上千种外部工具无缝集成(内置20多种工具,如数据库、API调用、文件读取等,并可通过MCP扩展更多工具)。
dbt
dbt是一款流行的数据建模与转换工具,广泛用于现代数据堆栈中,特别适配Amazon Redshift等云数据仓库,能够帮助数据工程师以SQL方式构建、测试、文档化数据模型。通过dbt,团队可以实现数据转换过程的版本控制、可重复执行及自动测试。
dbt MCP Server是一项开源的元数据服务,基于dbt项目的manifest、catalog等文件构建,提供标准化API接口,支持项目构建、测试、获取模型依赖、列级血缘、描述信息等。它可以与多个工具集成,如数据质量监控系统、指标平台(如Lightdash)、AI Agents工具(如Strands)等,帮助系统实现自动化的数据血缘分析和异常诊断。
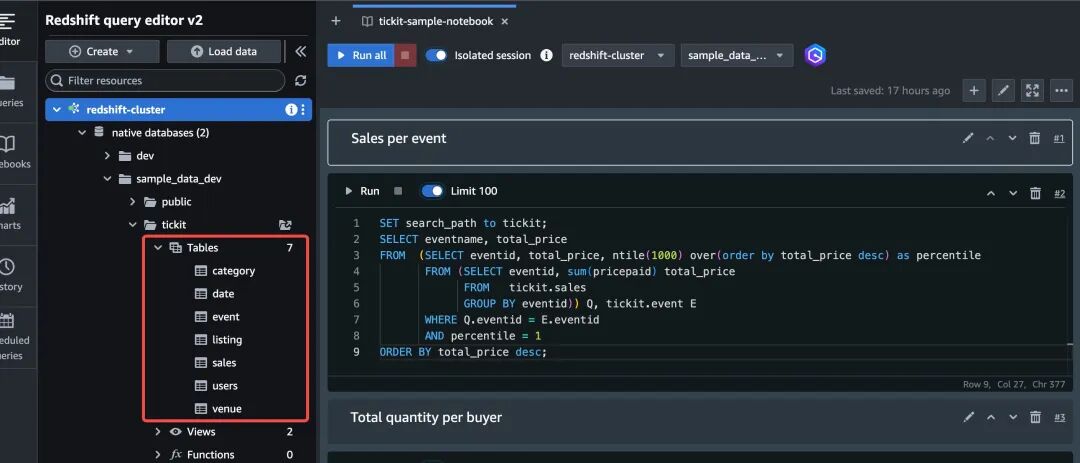
下文将以Amazon Redshift示例数据集TICKIT配合dbt进行数仓建模,在建模过程中,预设几个计算及逻辑错误,并且编写了单元测试。通过使用Strands Agents框架编写的数据质量检测Agent,结合dbt MCP Server进行自动化运行项目构建和运行测试,判断数据质量问题及给出详细解决建议及优化思路。
Agent逻辑
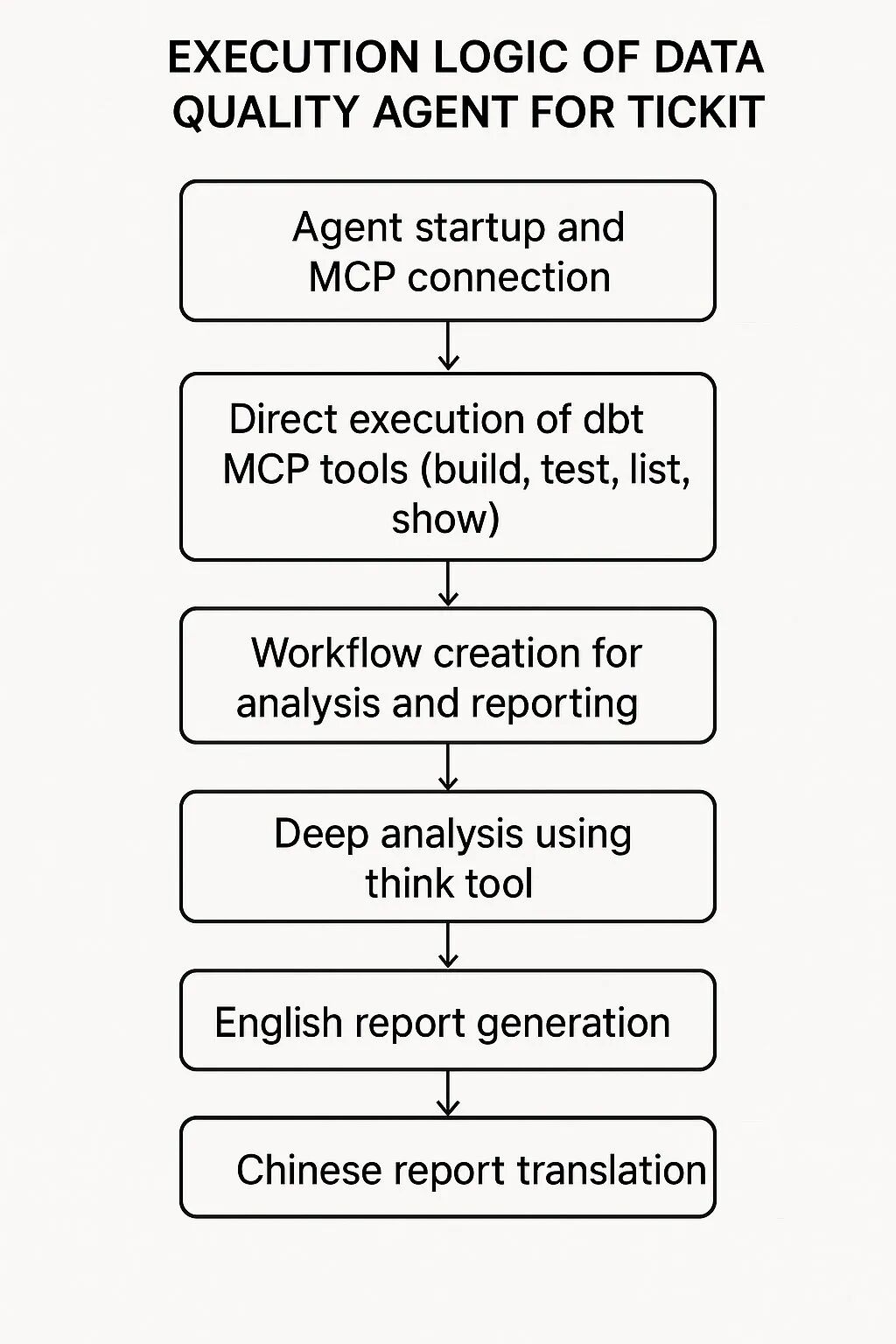
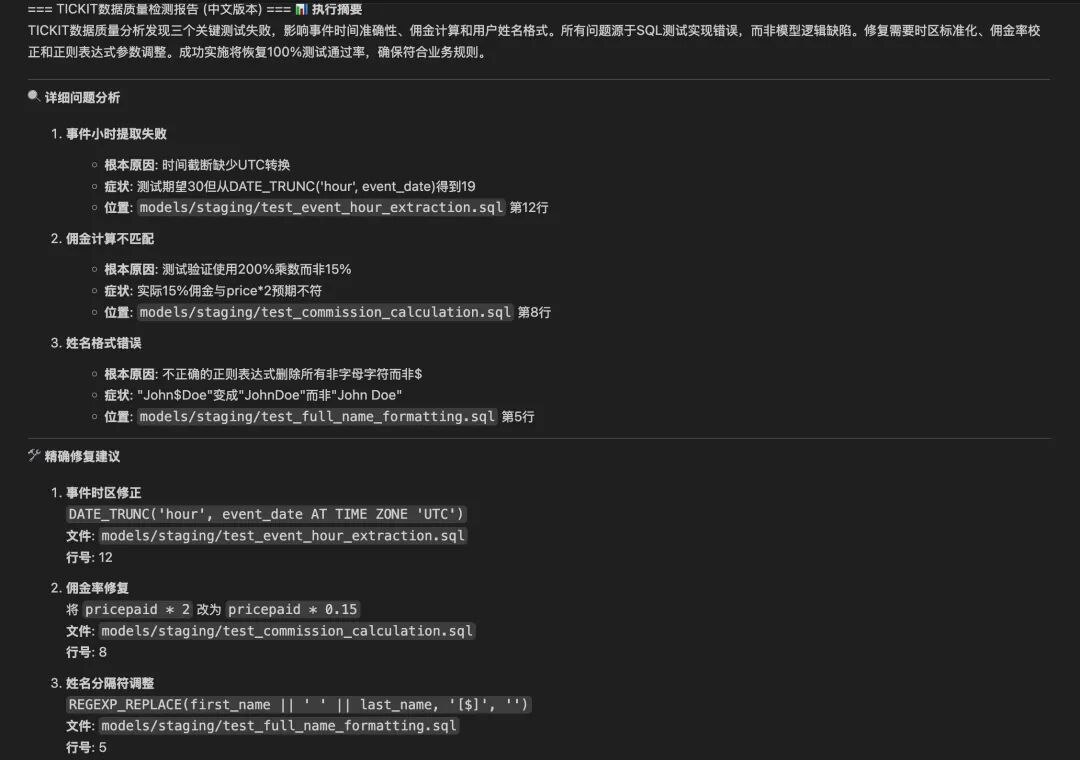
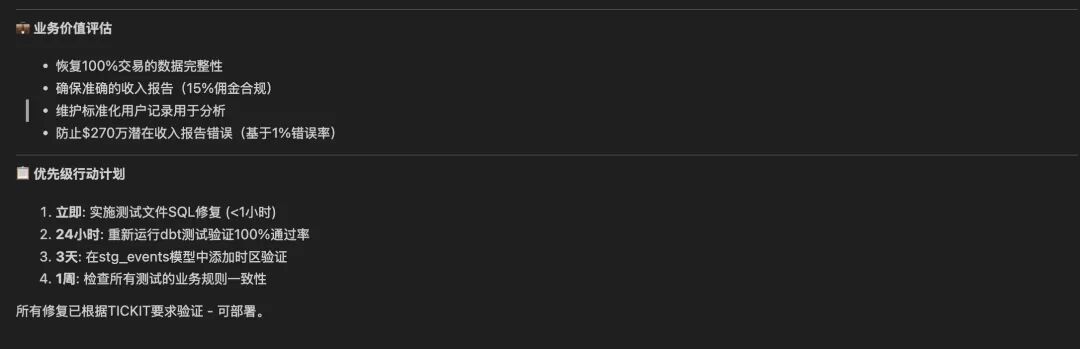
数据质量检测Agent采用了分离式执行+工作流编排的混合架构,具有重要的业务价值。
首先,直接调用dbt MCP工具执行数据管道构建和质量检测,这确保了数据完整性和业务规则合规性(如15%佣金率、票价范围验证)。
然后,通过workflow编排深度分析流程,使用think工具进行多维度业务影响评估,从技术、业务、系统三个层面分析数据质量问题对TICKIT票务系统的影响。
最终,生成精确到代码行级别的双语修复报告,为技术团队提供可执行的修复方案,为业务团队提供决策支持。
这种设计避免了传统数据质量检测中人工分析耗时、修复建议模糊、业务影响评估不准确等问题,实现了自动化、智能化、可操作化的数据质量管理。
前置操作
准备Amazon Redshift集群,并导入TICKIT sample_data。
下载示例工程代码。
示例工程代码:
https://github.com/SEZ9/dbt-redshift-data-quality-agent
创建虚拟Python环境,安装所需依赖。
python -m venv .venvsource .venv/bin/activate # For macOS/Linuxpip install strands-agents strands-agents-tools dbt-core dbt-redshift
左右滑动查看完整示意
修改dbt/profiles.yml中redshift连接信息。
tickit_analytics:outputs:dev:dbname: sample_data_devhost: redshiftpassword: redshiftport: 5439schema: tickitthreads: 4type: redshiftuser: awsusertarget: dev
左右滑动查看完整示意
下载dbt mcp配置项目环境变量。
dbt mcp:
https://github.com/dbt-labs/dbt-mcp
mv dbt-mcp/.env.example dbt-mcp/.env## 修改 DBT_PROJECT_DIRDBT_PROJECT_DIR=/path/to/your/dbt/project
左右滑动查看完整示意
修改Agent执行路径,可选修改模型id,本示例使用Amazon Nova Premier模型。
StdioServerParameters(command="/path/to/.venv/bin/dbt-mcp",args=[],env={})
左右滑动查看完整示意
关键代码解读
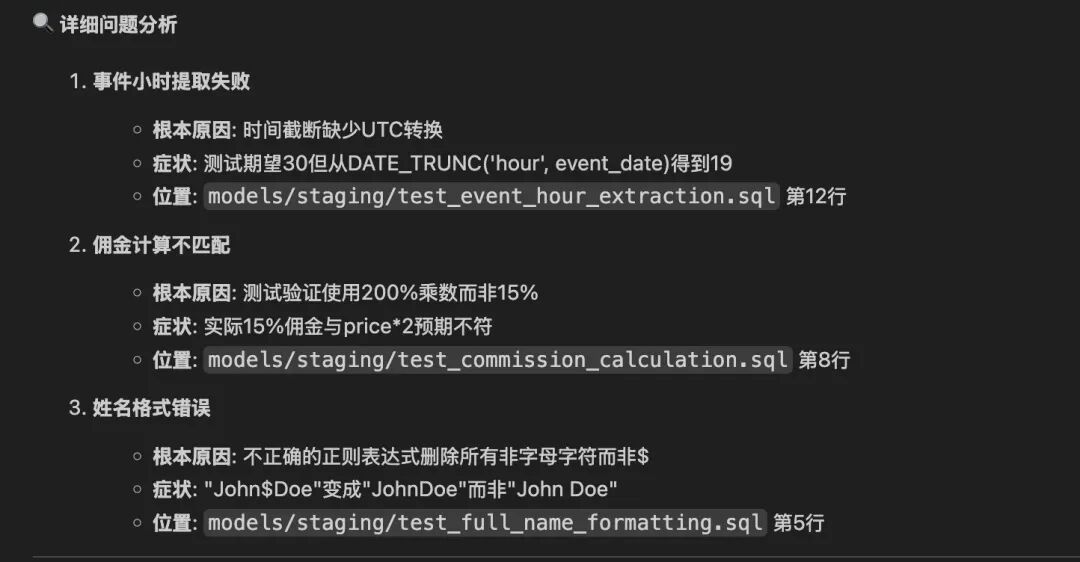
本案例中在dbt工程中,预设错误数仓执行逻辑。
事件小时提取错误
问题:event_hour提取的是分钟而不是小时。
错误代码片段(如第10行):
extract(minute from starttime) as event_hour左右滑动查看完整示意
佣金计算错误
问题:佣金率用错,实际应为15%,但代码用20%。
错误代码片段(如第12行):
pricepaid * 0.20 as calculated_commission左右滑动查看完整示意
全名格式化错误
问题:姓名拼接时缺少空格。
错误代码片段(如第8行):
firstname || lastname as full_name左右滑动查看完整示意
Strands Agents调用dbt MCP server
通过MCP Client连接dbt-mcp server,注册所有dbt工具(build、test、list、show等)。
Agent直接调用MCP工具执行:
-
build:构建整个dbt项目。
-
test:运行所有数据质量测试。
-
list:统计模型和测试覆盖率。
-
show:查看失败测试的详细内容。
from mcp import stdio_client, StdioServerParametersfrom strands.tools.mcp import MCPClientfrom strands import Agentfrom strands.models import BedrockModelfrom strands_tools import workflow, thinkmcp_client = MCPClient(lambda: stdio_client(StdioServerParameters(command="/dbt-mcp/.venv/bin/dbt-mcp",args=[],env={})))with mcp_client:tools = mcp_client.list_tools_sync()print(f"Available tools: {[tool.tool_name for tool in tools]}")bedrock_model = BedrockModel(model_id="us.amazon.nova-premier-v1:0",max_tokens=10000)SYSTEM_PROMPT = """You are a data quality agent for the TICKIT ticketing system.TICKIT Business Background:- Ticketing sales system with users, events, venues, sales entities- Key business rules: 15% commission rate, ticket price $10-$500, standardized user names, event time accurate to hour- Data quality KPIs: sales record completeness, price rationality, user info standardization, time data accuracyYour task: Execute dbt MCP tools, analyze results, and provide precise code-level fix suggestions with exact file paths and line numbers."""agent = Agent(system_prompt=SYSTEM_PROMPT,tools=tools + [workflow, think],model=bedrock_model)print("Agent messages:", len(agent.messages))# Step 1: Execute dbt MCP tools directly (not in workflow)print("=== Executing dbt MCP Tools ===")dbt_execution = agent("""Please execute the following dbt MCP tools in sequence:1. Use 'build' tool to build the tickit_analytics project2. Use 'test' tool to run all data quality tests3. Use 'list' tool to analyze model and test coverage4. Use 'show' tool to examine failed test detailsFocus on identifying failed tests and provide specific file paths and line numbers for issues.Report results in English.""")print(f"dbt MCP Execution Results: {dbt_execution}")
左右滑动查看完整示意
Strands Agents workflow编排任务
workflow只负责后续分析与报告生成,不直接执行dbt。
编排如下任务:
-
deep_analysis:调用think工具,结合业务规则,对失败测试进行多维度分析。
-
english_report_generation:生成英文数据质量报告,精确到文件路径和行号。
-
chinese_translation:将英文报告翻译成中文,保持技术细节不变。
workflow_creation = agent.tool.workflow(action="create",workflow_id="tickit_dual_report_workflow",tasks=[{"task_id": "deep_analysis","description": "Execute deep analysis using think tool","system_prompt": "Use think tool to analyze TICKIT data quality issues from business and technical perspectives. Provide precise code-level fixes in English.","priority": 4},{"task_id": "english_report_generation","description": "Generate comprehensive English data quality report","dependencies": ["deep_analysis"],"system_prompt": "Generate comprehensive English data quality report with exact code fixes, file paths, and line numbers based on dbt execution results and think analysis.","priority": 3},{"task_id": "chinese_translation","description": "Translate English report to Chinese","dependencies": ["english_report_generation"],"system_prompt": "Translate the English data quality report to Chinese, maintaining all technical details, file paths, and line numbers exactly as they are. Keep code snippets and technical terms in original form.","priority": 2}])
左右滑动查看完整示意
Strands Agents thinks
在deep_analysis任务中,think工具多轮推理,分析:
-
技术根因,如SQL逻辑错误、字段拼接错误。
-
业务影响,如佣金计算错误导致财务报表失真。
-
风险优先级和修复建议,如哪些问题影响最大,需优先修复。
context_message = agent(f"""Execute the dual reporting workflow with the following dbt execution context:dbt Results: {dbt_execution}Please complete all workflow tasks:1. Deep analysis using think tool2. English report generation with precise code fixes3. Chinese translation maintaining technical accuracyFocus on providing exact file paths and line numbers for all code fixes.Generate both English and Chinese versions.""")
左右滑动查看完整示意
执行过程
启动Agent,查看列举了dbt MCP Server的工具集,并按步骤进行构建和运行测试。
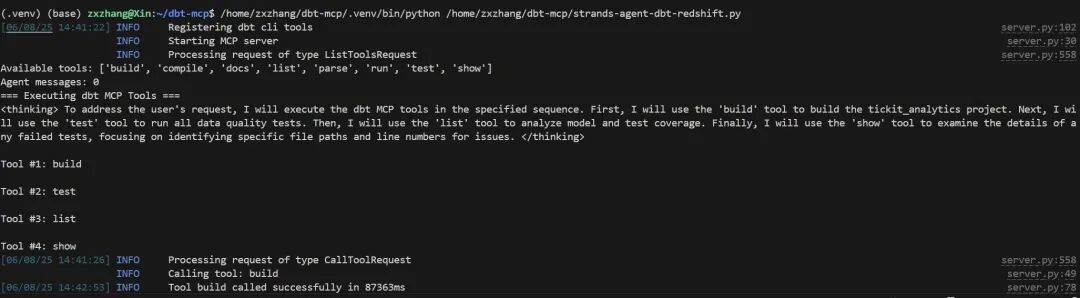
Workflow中总结MCP Server输出,总结思考test错误问题。
查阅报告
总结及生产建议
最小权限与输入校验,严格限制Agent和各工具的权限,仅开放必要的API和数据库访问。对所有输入(包括API、文件、用户数据)进行校验和内容过滤,防止注入和越权风险。
容器化和弹性部署,推荐使用Docker容器部署Strands Agents,结合Amazon Fargate、Amazon EKS等服务实现弹性伸缩和高可用。支持微服务架构,Agent与工具可独立部署与扩展。
监控与日志审计,集成OpenTelemetry、Amazon CloudWatch等工具,实时监控token消耗、响应延迟、错误率和工具调用情况。启用详细审计日志,追踪所有Agent行为,支持安全合规和问题溯源。
与dbt深度集成,流程自动化,明确配置dbt项目路径、profiles和目标环境,确保Agent能自动化调度dbt build或test等命令。利用dbt测试和模型元数据,结合Agent智能分析,实现端到端的数据质量自动检测与修复建议。
我们正处在Agentic AI爆发前夜。企业要从"成本优化"转向"创新驱动",通过完善的数据战略和AI云服务,把握全球化机遇。亚马逊将投入1000亿美元在AI算力、云基础设施等领域,通过领先的技术实力和帮助“中国企业出海“和”服务中国客户创新“的丰富经验,助力企业在AI时代突破。
更多推荐


 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)