
基于雾计算和Q学习的公交信号优先控制策略研究【附代码】
📈 算法与建模领域的探索者 | 专注数据分析与智能模型设计✨ 擅长算法、建模、数据分析💡 matlab、python、仿真公交信号优先控制的核心在于通过动态调整信号配时方案,在保障社会车辆通行效率的同时,优先放行公交车辆。强化学习(RL)因其自适应决策能力成为该领域的研究热点,其技术框架包含以下关键要素:状态空间设计状态空间需综合反映交叉口的实时交通特征。典型设计包括:(智能体与环境交互示意图
·
📈 算法与建模领域的探索者 | 专注数据分析与智能模型设计
✨ 擅长算法、建模、数据分析
💡 matlab、python、仿真
✅ 具体问题可以私信或查看文章底部二维码
✅ 感恩科研路上每一位志同道合的伙伴!
(1)基于强化学习的公交信号优先控制核心技术
公交信号优先控制的核心在于通过动态调整信号配时方案,在保障社会车辆通行效率的同时,优先放行公交车辆。强化学习(RL)因其自适应决策能力成为该领域的研究热点,其技术框架包含以下关键要素:
状态空间设计
状态空间需综合反映交叉口的实时交通特征。典型设计包括:
- 公交特征参数:排队公交车数量、到站时间预测、载客量(如Priority Control of Intelligent Connected Dedited Bus Corridor中通过GPS获取车辆位置与乘客数据)
- 社会车辆指标:各车道排队长度、饱和度、历史延误数据(A Bus Signal Priority Control Method Based on Deep Reinforcement Learning采用车道级车辆计数)
- 信号状态:当前相位剩余时间、周期长度等。状态信息通常通过路侧单元(RSU)或车载设备采集,并传输至边缘计算节点处理。
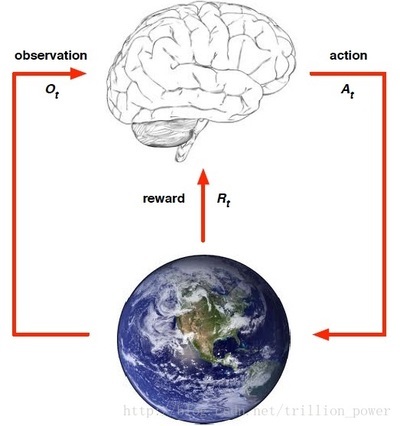
(智能体与环境交互示意图:展示观察、动作、奖励的循环逻辑)
动作空间定义
动作空间需平衡控制灵活性与工程可行性:
- 单交叉口控制:采用离散动作如绿灯延长(3-6秒)、相位切换或跳跃(Multi-Agent Reinforcement Learning for Cooperative Transit Signal Priority限制最大绿灯时间防止相位冲突)
- 多交叉口协同:通过相位差调整实现绿波协调(Coordinated Multi-Agent Reinforcement Learning Method提出联合优化信号偏移量与公交速度引导)
奖励函数构建
奖励函数需权衡公交优先与社会车辆影响:
- 公交效益指标:减少公交延误(如Transit Signal Priority Control with Deep Reinforcement Learning采用负延误作为奖励)
- 社会车辆惩罚项:限制排队长度增长、人均延误增幅(Adaptive Transit Signal Priority based on Deep Reinforcement Learning引入权重系数动态调整优先级)
- 稳定性约束:最小绿灯时间、行人过街安全时长等硬性条件(部分研究通过无效动作屏蔽机制实现)
(2)单交叉口与多交叉口协同优化方法
单交叉口控制策略
针对孤立交叉口,Q-learning及其衍生算法(如Double DQN)可有效处理离散动作空间:
- 事件驱动机制:当公交进入检测区域时触发决策(Integrating Transit Signal Priority into Multi-Agent Reinforcement Learning定义200米触发范围)
- 混合优先级策略:结合公交载客量与延误程度动态调整优先级(PDFBus Priority Procedure for Signalized Intersections提出25级优先级分类)
- 实时重规划:每5-10秒重新评估信号方案,适应交通流变化(部分研究采用LSTM网络预测短时交通状态)
(多智能体协同框架:展示局部观测与全局奖励的协调机制)
多交叉口协同优化
面向干线协调场景,多智能体强化学习(MARL)展现优势:
- 分布式决策架构:每个交叉口作为独立智能体,通过通信网络共享公交轨迹预测(eMARLIN-MM采用值分解网络实现联合训练)
- 分层控制逻辑:上层优化相位差,下层调整单点绿灯时长(CTVH方法引入虚拟队列平衡社会车辆影响)
- 跨模态协同:结合公交速度引导(如红绿灯建议速度)降低二次排队风险(Co-ST算法实现信号与车速联合控制)
import numpy as np
import tensorflow as tf
from collections import deque
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size # 包含公交数量、社会车辆数等
self.action_size = action_size # 绿灯延长/保持/切换
self.memory = deque(maxlen=2000)
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.model = self._build_model()
def _build_model(self):
model = tf.keras.Sequential([
tf.keras.layers.Dense(24, input_dim=self.state_size, activation='relu'),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(self.action_size, activation='linear')
])
model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(0.001))
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return np.random.choice(self.action_size)
act_values = self.model.predict(state, verbose=0)
return np.argmax(act_values[0])
def replay(self, batch_size):
minibatch = np.random.choice(len(self.memory), batch_size)
for i in minibatch:
state, action, reward, next_state, done = self.memory[i]
target = reward
if not done:
target = reward + self.gamma * np.amax(self.model.predict(next_state, verbose=0)[0])
target_f = self.model.predict(state, verbose=0)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
# 仿真环境交互示例
def run_simulation(env, agent, episodes):
for e in range(episodes):
state = env.reset()
state = np.reshape(state, [1, agent.state_size])
total_reward = 0
while True:
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, agent.state_size])
agent.remember(state, action, reward, next_state, done)
state = next_state
total_reward += reward
if done:
print(f"Episode: {e}, Reward: {total_reward}")
break
if len(agent.memory) > 32:
agent.replay(32)
如有问题,可以直接沟通
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇
更多推荐


 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)