
小白轻松入门RAG:检索增强生成技术全面解析,1.3万字深度学习!
本文详解RAG(检索增强生成)技术,通过结合模型参数记忆与外部知识库,解决大模型知识更新和幻觉问题。文章重点解析RAG的Retriever模块,包括BERT架构的Query Encoder和MIPS算法的高效检索机制,展示如何利用密集向量表达提升检索效果。零基础视角下,深入浅出地剖析RAG从概念到实现的全过程,适合小白和程序员系统学习大模型技术。
简介
本文详解RAG(检索增强生成)技术,通过结合模型参数记忆与外部知识库,解决大模型知识更新和幻觉问题。文章重点解析RAG的Retriever模块,包括BERT架构的Query Encoder和MIPS算法的高效检索机制,展示如何利用密集向量表达提升检索效果。零基础视角下,深入浅出地剖析RAG从概念到实现的全过程,适合小白和程序员系统学习大模型技术。
一、 RAG神奇的风评
看完了Transformer之后,我想要介绍的就是这篇最先提出RAG框架的论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks。
有一个特别有意思的现象是:RAG(检索增强型生成)处于这样一种矛盾中——基础的、教科书式的RAG(Naive RAG)是一个优雅且通用的构想,但在真实、复杂的企业环境中,它往往因为过于“天真”而效果不佳。
这种矛盾感恰恰揭示了 RAG 技术从一个简洁的学术概念到一个可靠的生产级系统之间巨大的鸿沟。这也是“朴素RAG”进化成为“高级RAG”的动力。
本篇文章想要介绍的是一个最简单的“朴素RAG”到底是什么?这个极为**“朴素的基础”是后续学习更加高级的“系统”的垫脚石。**
“RAG”的朴素构想,也可以看作是“上下文工程”的一部分。因为,RAG要做的就是从“人为选定的知识库中挑选材料,给到下游模型生成”。这个“挑选材料”的过程,何尝不是要选择一种合适的“上下文”呢?
本篇文章展现的是我从一个零基础邪修的角度看待问题的思路,对于遇到的专业名词做很多絮絮叨叨的解释,因为那也是我学习时候的困惑。写着写着又变得太太…太长了。
只有把关于RAG的Generator和训练方式介绍放到下一篇文章,本文主要介绍RAG的Retriever模块,包含以下内容:
- RAG在解决的问题以及RAG的结构
- 传统的稀疏检索和现代的密集检索
- Query Encoder:BERT
- MIPS:从Query到知识库文章
本篇文章1.3w字,阅读时间比较长,感觉兴趣的朋友可以点个收藏或者关注呀~
二、RAG在解决什么问题?
我们知道LLMs其实体现出一种暴力美学。
我们先凭借自己的信仰,相信世界上存在着这么一个函数,能够解决我们的问题。我们设计这个函数的形状,然后给这个函数海量的“训练题”,让这个函数从一道又一道“训练题”里面自己找到自己的参数。
训练完成之后,我们称海量“训练题”里所含的知识都被固化在了函数的“参数”里面。我们问模型一个问题,模型会依据自己已有的**“参数记忆(parametric memory)”**来吐出回答。
但是在训练结束之后,模型的参数就被“冻结”了。也就是说,模型的内含“记忆”被固化了,因此**“新产生的信息”模型是没有办法接收的**。
最简单的例子就是在LLMs接入网络之前,它会回答自己已有的知识是截止到某个日期之前的——在此之后的事情:比如漂亮国总统换啦,XX体育赛事有新团队夺冠啦……它都无法回答,要么就是自信胡编乱造。
要想更新模型的“参数记忆”,就需要再次收集到新的信息,然后重新进行训练。
用脚趾头想也知道这种办法是很麻烦的:新的信息数据量可能就很少;模型训练一次要耗费相当的时间和算力(虽然也有一些部分参数微调的办法);模型更新参数之后还要再次重新部署上线,给工程上也带来新的成本。
所以学者们第一个想要解决的问题就是:有什么办法可以快速方便的更新模型的知识?
最简单的办法就是像我们人类一样随时带一个知识库外挂,这样只要更新模型可以接触到的外部知识库,模型就能够了解到最新的信息。这样还不需要重新训练模型,这样知识库外挂叫做模型的非参数记忆(non-parametric memory)。
LLMs还有一个毛病就是“自信地胡言乱语”,也就是我们所说的“幻觉”问题。从LLMs的原理来看,它们是在基于已有的token,输出下一个位置概率大的token,并不会真的去进行事实校验(除非一些刻意设计)。
于是学者们就想,能不能让模型的每次回答都结合一下知识库。就像是我们人类在回答问题之前去寻找和对比权威的外部信源一样,这样是不是就能够降低LLMs胡言乱语的概率?
基于此RAG结构被提了出来,它的全名是检索增强型生成(Retrieval-Augmented Generation),它是一个通用的框架,用来解决知识密集型问题(就是那些需要依赖外部知识库,不能纯靠理论推导就得出结论的问题)。
它是一个简洁且通用的方案,(在理想情况下)具有以下明显的优点:
- 缓解模型“幻觉” (Hallucination);
- 知识实时更新;
- 具有可解释性,方便溯源:当 RAG 系统给出答案时,它可以同时引用其参考的原始文档。
- 降低成本和个性化门槛:维护一个外部知识库的成本较低。企业可以轻松地将自己的私有数据(如内部 Wiki、技术手册)作为 RAG 的知识源,实现专属的智能问答。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

三、RAG的结构是什么?
那么RAG到底包含什么呢?**是怎么把外部的非参数知识和模型的参数知识结合在一起的呢?**从这篇RAG起源的文章“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”来一起看一看。
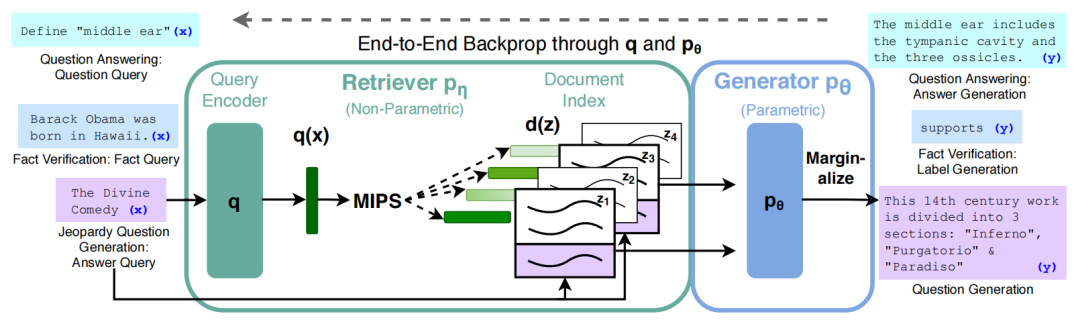
论文里面模型要完成一系列的问答任务。在Transformer相关的文章里面,我已经分析过,问答任务的本质就是“接收用户的输入(也就是Query),然后预测接下来的token是什么”。
接收的token和输出的token长度都是不确定的,所以这种任务也可以被归类为**seq2seq(sequnce to sequnce)**任务。
我们可以来大致模拟一些RAG框架需要完成的事情:
首先要做的是**“把用户的Query变成模型能够处理的形式”。这种时候一般都会设计一个“编码”模块**,用于处理用户的Query,这个模块叫做Query Encoder。
处理好了之后,当然是需要把**“用户输入的信息”和“已经有的知识库”进行检索匹配**,找出那些相关的信息给到下游模块进行生成。这个检索过程利用了训练好的模型生成的Document Index(文档索引)。
以上两块合并在一起叫做Retriever。
后面的模块综合“用户输入的信息”和“知识库里面相关信息”,进行预测,输出可能跟在这些信息后面的token,这个模块叫做Generator。
整个RAG架构就是由Retriever和Generator一起构成的。
这里还要提一嘴的是,论文里构造了两个模型:一个模型叫做RAG-seq,一个模型叫做RAG-token。
RAG-seq模型**生成一次回答,**这次回答的每个token都是依据那一次检索找到的信息进行生成的。假如一个问题的答案有10个token,那么这10个token依据的检索资料都是相同的。
而RAG-token**模型在生成一次回答时,**一个问题的答案有10个token,这10个token可能是依据不同的检索资料生成的。
四、从检索匹配的传统解法说起
上文提到Retriever分为两块:首先要把用户的输入进行编码,然后再把用户输入和知识库进行匹配。
我们需要理解一下把**“用户的输入和知识库进行匹配”**这件事。这是一个非常古老的问题,但凡涉及知识管理都需要进行这个操作,更别说在有了互联网之后,我们一天使用无数次搜索引擎了。
用户的输入是千变万化的,不像是我们的习题册,题目和答案都是标准的,我们难以直接从知识库里面找到标准答案,很多时候我们做的就是从知识库里把跟用户输入“Top K相关”的文章给找出来,提供给用户。
既然要评价“Top K相关”,意味着我们必然要找到一个数值化的评价相关性的方法。
最开始的时候学者们采用一些简单而直观的相关性评分。比如用户搜索“苹果”,那么就数一数知识库里面每一篇文章**“苹果”出现的次数**,出现次数越多的文章,越有可能跟用户这个搜索词关系紧密。直接用**词频(Term Frequency,TF)**来作为相关性分数。
但是有的词语是通用词,比如“的”、“地”,这种词语高频率的出现在每一篇知识库的文章中,证明这个词语很**“普遍”。这个时候继续使用词语在文章中出现的频率来判断相关性就不是很恰当了,因为这个“普遍”的词语带来的“相关性价值”会很低**。
好在一个词语的“普遍性”是可以度量的,我们可以对它施加惩罚,以降低由这种“普遍”带来的“相关性评分”。
要怎么来度量普遍性呢?一个很简单的想法是,如果一个词语只出现在一篇文章中,那么这个词语肯定不普遍——只要比较一下“包含词语A的文章数量”和**“知识库总文档数量”就可以了,这个指标叫做“逆文档频率 (Inverse Document Frequency,IDF)”**,公式如下:

N 是整个知识库中的文档总数;df(t) 是包含词语 t 的文档数。一个词语越普遍,就会导致IDF越低。
现在我们有了词频和逆文档率,把它们乘在一起,就得到了TF-IDF相关性评分:

TF-IDF筛选出那些高频包含用户Query的文章,降低了普遍性词语对于筛选的影响。
但是这种表示方法也有问题:比如越长的文章,就越容易获得高评分;词频TF对于这个相关性评分的影响是线性的——假如用户查询词语是“苹果”,文章A中“苹果”出现了1万次,文章B中“苹果”出现了2万次,TF-IDF对于文章B的评价会超级偏高。而经验数据则显示“频次”到了一定程度之后,对相关性的影响不会增长那么快。
学者们为了弥补这些问题,创造了一个更加精细化的公式来计算文章与词语的相关性,叫做BM 25(Best Match 25)算法,简化版本的公式如下:
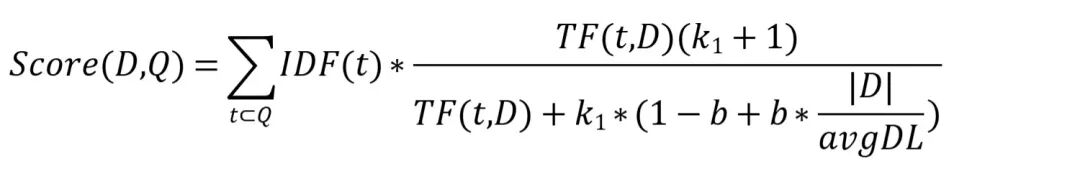
其中D表示文章,Q表示用户的Query,t表示用户Query里面的词汇,TF(t,D)表示词汇t在文章D中出现的频率,k_1和b是公式的参数,可以由人为设定。|D|表示文章D的长度,avgDL表示整个知识库文章的平均长度。
IDF(t)是逆文档率。这不过这个逆文档率是上面介绍的逆文档率的一个平滑优化版本,公式如下:
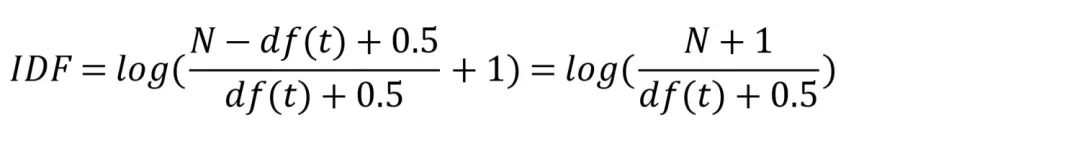
N 是整个知识库中的文档总数;df(t) 是包含词语 t 的文档数。这个逆文档率在分母上加上常数,是为了防止分母变成0;在分子上不加0.5而是加1,是为了防止df(t)为N导致整个逆文档率变成0。
整个用户Query与文章的相关性分数,是用户Query里面的每一个“词汇”的相关性评分相加得到的。
每个词汇的相关性得分,又是由每个词汇的逆文档率和后面一大坨指数相乘。
仔细看后面这个貌似有点复杂的指数,它是BM 25优于TF-IDF的关键。

首先它解决了相关性随着词频线性增长的问题。可以观察上面的公式,假如TF的值取到正无穷,整个后半部分的值也只会趋于k_1+1,这证明在词频越来越高之后,词频对于相关性的影响就下降了。k_1作为人为的选择的超参数,可以用来调节词频对于相关性得分的影响。通常取值在 1.2 到 2.0 之间。
同时BM 25还把**“文档长度”纳入考量**。后面指数的分母上有|D|/avgDL,这是被度量的文档长度除以知识库平均文档长度,可以看成一种归一化操作。
被度量的文档长度|D|越大,这个分母就越大,相关性得分就越小,反之相关性得分就越大。b可以人为选择来控制对于“文档长度”的惩罚力度,b越大惩罚力度就越大。通常取值为 0.75。
BM 25是TF-IDF的一个优化算法,它计算简单且在关键词匹配上非常有效,至今仍是许多搜索引擎(如 Elasticsearch, Lucene)中默认或核心的排序算法之一。但是它仍然有其局限性:
- 第一,BM 25执行的是严格匹配,也就是无法识别近义词,比如“计算机”和“PC”它就没办法匹配起来。
- 第二,BM 25是一种词袋模型(bag of words,顾名思义把词语全部放在一个大袋子里)。也就是不管用户Query中词汇的顺序,也没有办法理解上下文,所以“猫吃鼠”和“鼠吃猫”是无法区分的。
- 第三,BM 25的准确性严重依赖用户Query中词汇的切分。
BM 25是传统的检索匹配一个经典的算法。我们可以把这种算法看成一种“稀疏表达下(Sparse Representations)的检索”。
为什么这样说呢?因为其实我们可以把这种传统的检索匹配也看成向量表达下的检索,实质上在电脑上运行的检索一定是转化为数值去进行的。只不过这种向量表达比较直观且原始。
它们的工作方式可以被想象成这样:
首先,构建一个巨大的“字典”:系统会扫描所有文档,创建一个包含所有不重复词语的巨大词汇表(Vocabulary)。这个词汇表可能包含几万甚至几十万个词。
其次,用“稀疏向量”代表文本:每一篇文档或每一个查询,都可以被表示成一个维度与词汇表大小完全相同的向量。向量的长度 = 词汇表的大小 (例如:50,000维)。
在这个长长的向量中,只有文档实际包含的那些词所对应的位置才会有值(比如它们的TF-IDF或BM25分数),而其他成千上万个位置的值全都是0。
举个例子,假设我们的词汇表只有10个词:[a, cat, dog, is, on, sat, the, computer, pc, keyboard]。
一篇文档是 the cat sat。它对应的稀疏向量可能是:[0, 1.2, 0, 0, 0, 1.5, 0.8, 0, 0, 0]。
你看,10个位置里有7个是0。在真实的50,000维向量里,99.9% 的位置都会是0。数据分布非常“稀疏”,所以这种方法被称为稀疏检索。
稀疏检索会存在我上面说的只能够“精确”匹配、上下文丢失的问题。与之相对的是由LLMs驱动的**“密集检索(Dense Retrieval)”**。
为什么叫做“密集”?因为学者们利用LLMs去寻找另外一种关于自然语言的向量表达,这种向量每个维度的数值很少为0,相对于稀疏表达是一种更加紧凑的向量表达。
我在前几篇文章中讲到的,把自然语言的基础单元(token)进行embedding的Word2Vec算法,寻找的就是一种“密集”向量表达。
假如算法用512维向量来表示一个token,通过语言任务训练之后得到的这种向量,大多数维度数值都不为零。
虽然我们说不出每个维度的意义,但是我们是通过LLMs的学习把词语的很多特征都分别编入这个向量中,因此这也叫做“分布式表达(Distributed Representation)”。
使用这种算法得到的语义向量,能够表示出词语之间的**“相关性”和词语之间的“关系”**。
比如“苹果”和“香蕉”之间的距离,会比“苹果”和“榔头”之间的距离近。比如向量的运算满足“woman”+“queen”-“man”=“king”。
由于“密集表达”能够体现出词语的“关系”,它就能够识别出稀疏表达识别不了的“近义词”,也就是能够实现“模糊搜索”。
与此同时,使用Transformer这种算法还能够把词语的上下文也编码进词向量中,也就是解决“上下文理解”的问题。因此很多研究都采用了训练“密集表达”并且实现“密集检索”的形式,RAG也不例外。
讲了那么多前史,现在来重新整理一下RAG想要做的事情——RAG想要把用户的Query和外部的知识库文章进行匹配,匹配之后再给到大模型进行生成,但是它进行匹配的基础是找到用户Query和外部知识库文章的“密集表达”(而不是传统的稀疏表达匹配)。
五、 Query Encoder:BERT架构
现在来看Retriever分为Query Encoder和Document Index就很好理解了。Query Encoder顾名思义,就是要把用户的输入变成一种“密集表达”。但是这种“密集表达”是为了“特殊的语言任务”量身定制的,也就是在特殊的数据集上面训练出来的。
是什么语言任务呢?RAG的论文里面设置了4种问答任务:
开放领域问答(Open-domain Question Answering): 回答任意问题,信息源不限于特定文档或数据库。想象一下,你问一个问题,比如“谁发明了电灯泡?”,AI需要像人一样,从海量的知识库(比如整个互联网、维基百科等)中找到答案。
抽象式问答(Abstractive Question Answering):是一种更高级的问答形式。与仅仅从原文中提取答案(这被称为Extractive QA,抽取式问答)不同,抽象式问答模型会理解原文内容,然后用自己的话生成一个新的、语法通顺的答案。这个新答案可能不会在原文中一模一样地出现。
Jeopardy问答生成(Jeopardy Question Generation):它的名字来源于著名的美国智力竞赛节目《Jeopardy!》。在这个节目中,主持人会给出一个答案,参赛者需要反过来提出一个问题来匹配这个答案。因此,这个任务的目标是:给定一个答案和相关的文本段落,模型需要生成一个问题,而这个答案正好能回答这个问题。
事实核查 (Fact Verification) :是一项旨在判断一个给定的陈述(或“claim”)是正确(即“true”)、错误(即“false”)还是无法判断(即“not enough info”)的任务。它通常需要模型参考外部证据或知识库来做出判断。例如:陈述“美国第一任总统是亚伯拉罕·林肯”,模型需要回答“false”。
为了简化描述,后面我会用“开放领域问答”来举例子。
对于开放领域问答来说,RAG的“编码模块”要完成的任务就是把用户的Query和知识库文档进行Embedding,Embedding的效果是让“问题”和“答案”的编码向量尽量“接近”。
RAG里面使用了多个开放领域问答的数据库,比如Natural Questions (NQ,是一个由 Google Research 创建的大型、高质量的问答数据集)来进行训练。这个数据集中的每一条数据都包含一个真实的用户在Google搜索引擎中提出的问题,还包含这个问题在维基百科中匹配的答案(这些答案由人工进行标注。)。
那么“编码模块”要使用什么样的结构呢?
论文使用了BERT架构来进行编码。一个BERT模块用于对用户Query进行编码,一个BERT模块用于对知识库文档进行编码。它们两个是不共享参数的。
什么是BERT架构呢?BERT全称Bidirectional Encoder Representations from Transformers,这个名字取得非常贴切,突出了BERT的目的和特点。
第一,BERT是基于Transformer的衍生模型;
第二,BERT的“目的”是寻找一种嵌入或者说表达方法“Representations”;这种表达方法有利于下游的语言任务,下游的语言任务可以是多变的。
第三,BERT的特点是**“双向编码(Bidirectional Encoder)”**。
这很好的解释了为什么BERT是只有Encoder结构而没有Decoder结构的,因为BERT设计的目的就是要“编码”,要把信息给“加工浓缩”塞进一个向量表达,这种向量表达可以被作为“输入”传递给多个下游模型——要完成什么“具体的语言任务”是由“使用这个向量表达”的人决定的。
用比喻来说,BERT加工“输入文本”之后输出的产品就像是“浓缩味精”,大厨可以用“万能浓缩味精”做任何菜,这个“味精”生产出来是为了让第二阶段的“炒菜”变得更加丝滑。
那么什么叫做“双向编码(Bidirectional Encoder)”呢?其实这里就是使用了Transformer的Encoder模块进行编码。
我简单回顾一下,Transformer的Encoder结构是没有“掩码”环节的——一串序列输入Encoder之后,Encoder直接把它们摊平了,每个向量都可以利用“自注意力”机制把自己“左边”和“右边”的信息都吸收到,而不是只能看到“出现在自己前面的信息”,这就是“双向”。
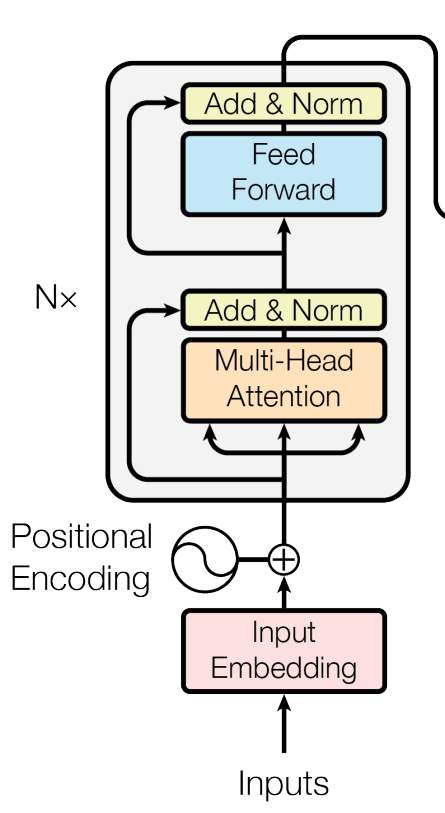
假如我们把“This apple is sweet”输入这个Encoder,每个词语使用一个5维向量表达,输入就会是一个4*5维的矩阵(每一行表示一个基础词汇)。经过Encoder加工之后,输出依然会是一个4*5维的矩阵。只不过这个矩阵的每一行向量,除了表示自己的语义,还加上了“左边”和“右边”所有词汇的语义——也就代表着蕴含了丰富的上下文信息。
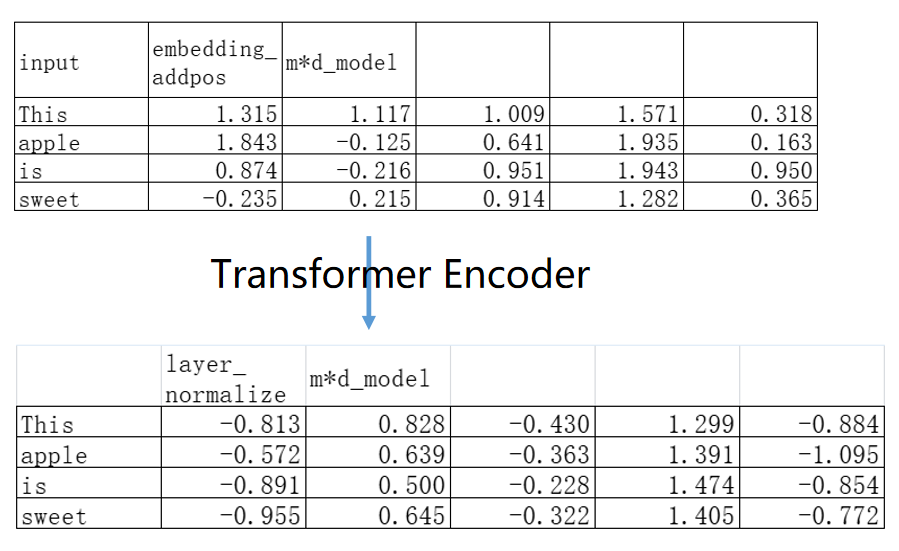
反之,在Transformer Decoder模块,Decoder的输入是“带掩码的”,强制使得一个词汇只能够看到“出现在自己之前”的信息,看不到“出现在自己之后的信息”,这就叫做“单向”。
BERT的创作者认为在完成一些语义任务的时候(比如开放领域问答),“双向的信息”非常重要,因此只采用了Transformer Encoder结构来进行“编码”。
不过我在介绍Transformer Decoder的时候,也分析过——Decoder使用“掩码”是为了“不剧透”。
因为在训练阶段,我们是知道“真实正确答案的”,我们给Decoder的输入就是这个“真实正确答案”。Decoder接收“前文信息”预测紧接的“下一个token”,为了不作弊,只能把预测位置后面的token信息都给屏蔽掉。不然要预测内容都给输入了,那还预测什么?
也就是说,“掩码”是完成训练的一种必然要求,BERT如果不想要采用掩码,就需要克服上面那个问题。为此BERT的作者设计了一个非常巧妙的任务来进行训练,那就是“完形填空(cloze task)”。
相信做过很多“完形填空”的我们都很熟悉,这个任务就是随机在一串序列数据中挖掉几个词语,然后让大模型在预测这些挖掉的词语是什么。
在BERT的论文中,作者会以15%的概率选择输入语句中的词汇进行处理,然后把处理过的语句扔给大模型。
大模型使用Encoder输出一串向量,把**“需要大模型预测”的向量**拿出来,传给一个全连接神经网络(带GELU激活函数和LayerNorm)进行处理。
这里我个人猜测增加这一层是为了增加模型的非线性拟合能力,因为在前面分析过Tansformer的Encoder线性变换比较多。
最终把处理完的向量与基础词汇表里面的向量进行对比,就能够找到大模型预测的token是什么。
这个“15%的概率进行处理”不是单纯的把“选中的词汇”使用“Mask标识”进行替代,而是需要遵循以下规则:
- 80%的情况下使用[MASK]标识替换;
- 10%的情况下使用随机标识替换;
- 10%的情况下保持被选择的token标识不变。
这种策略的目的是让模型在训练过程中不仅学会预测被“遮掩”的词,还要能够适应噪声和意外情况,从而提高其鲁棒性(Robustness)和泛化能力。
可以看见这种训练设计需要语料非常容易获得,还不用人工进行标注,可谓是非常方便巧妙了。这是一种**“自监督学习”**。
除了“训练任务”特殊之外,BERT对于输入文本向量也稍微做了一些变形处理,不仅遵循Transformer加上位置编码,还加上了一个特殊的表示“句子归属”的编码,这个编码叫做**“Segmentation Embedding”**:
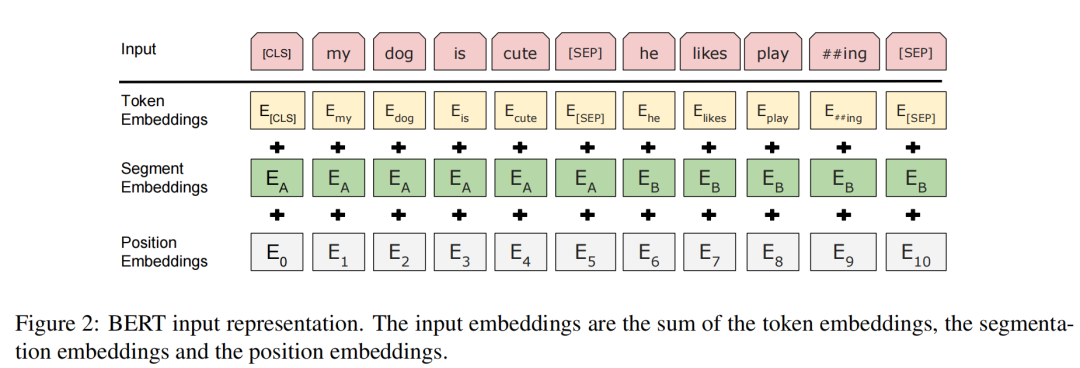
也就是:Input Embeddings = Token Embeddings + Position Embeddings + Segmentation Embeddings
Segmentation Embeddings就像是一种提前告诉模型的“辅助线”,好比我们学习文言文的时候,给你断句和不给你断句是两种难度。Segmentaion就是给大模型“断句”,有这样一种内在的辅助信息,大模型学习会更加轻松。处理一个token的时候,随时能够知道这个token的句子归属。
BERT中也设计了2个特殊的字符,只是和Transformer略有不同:
-
[CLS](Classification):表示输入文本的开始。BERT的输入文本可能是多个句子。这个标识被作者设计用来学习“整段”输入文本的意义。可以把 [CLS] 标记想象成一份报告的“摘要页”。
-
[SEP](Separator):明确地标记不同文本片段的边界。就像我们写作中的句号 ,或者段落之间的分割线。

它们扮演着不同的角色,一个负责“代表”,一个负责“分隔”。就像是写一份正式的报告,需要“封面页([CLS])”来代表整份报告,也需要“章节分隔符([SEP])”来区分不同的章节。
现在我们举一个demo来展示一下BERT是怎么训练的~
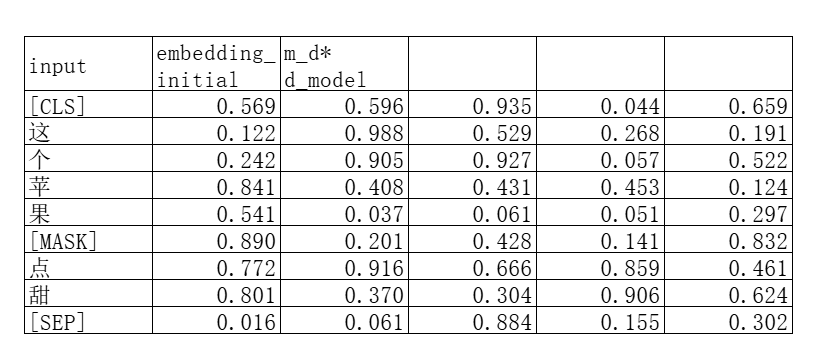
假如我们的训练资料是这句话“这个苹果有点甜”,刚刚说了BERT里面设计了2个特殊的字符,加上就变成了**“[CLS]这个苹果有点甜[SEP] ”**。
在输入模型之前我们需要随机挑选这句话里面的单词进行挖空,“这个苹果有点甜”总共7个字符(假设就以单个文字作为embedding的语义基础单元),挑选15%也就是1个字符进行处理。
假如我们就是选择了“有”这个字符用[MASK]符号进行替换(从理论上还有概率是用随机字符替换,或者不做处理,demo展示就不考虑这两种情况了)。
我们输入模型的序列就变成了“[CLS] 这 个 苹 果**[MASK]**点 甜 [SEP]”。
假如我们使用5维(BERT实际用了768维)向量来表示每个token。那么这句话的整个嵌入矩阵就是:
我们需要把这个基础的token embedding矩阵进行加工,加上位置编码(跟Transformer论文里面的一样)和分割编码(BERT特有的):
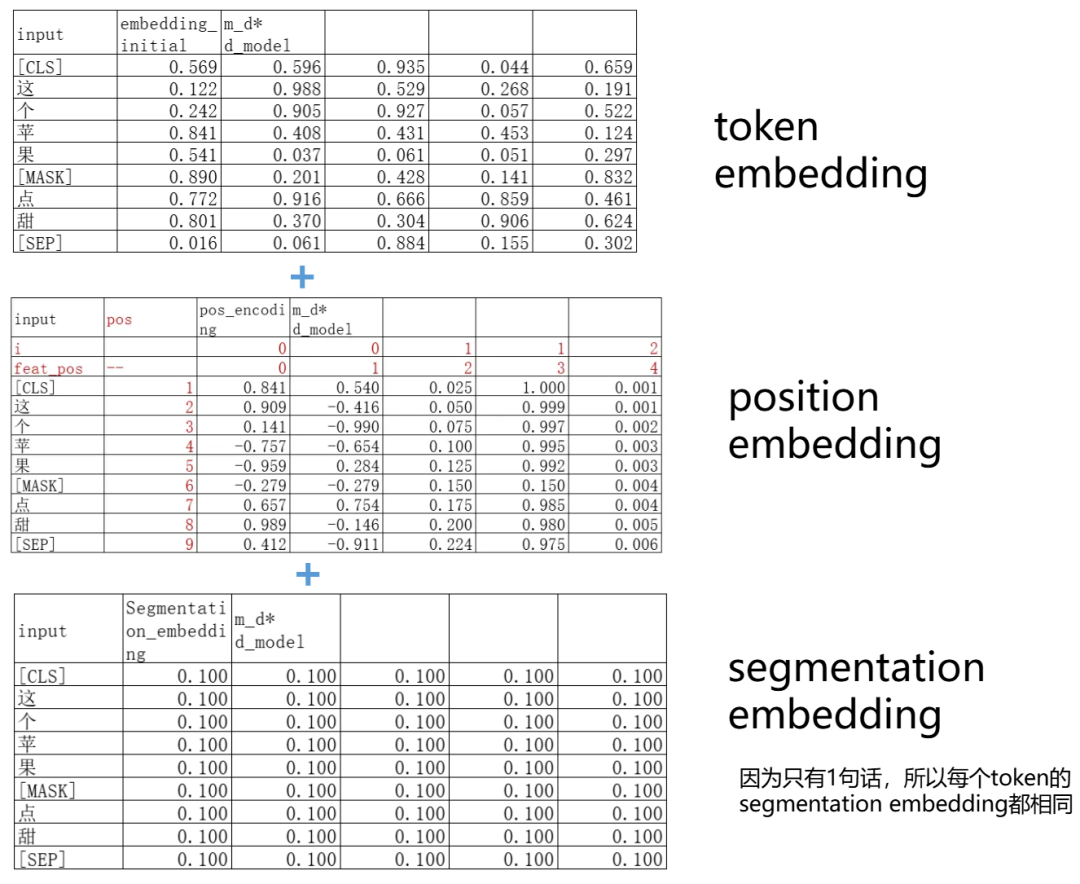
得到新的embedding矩阵:
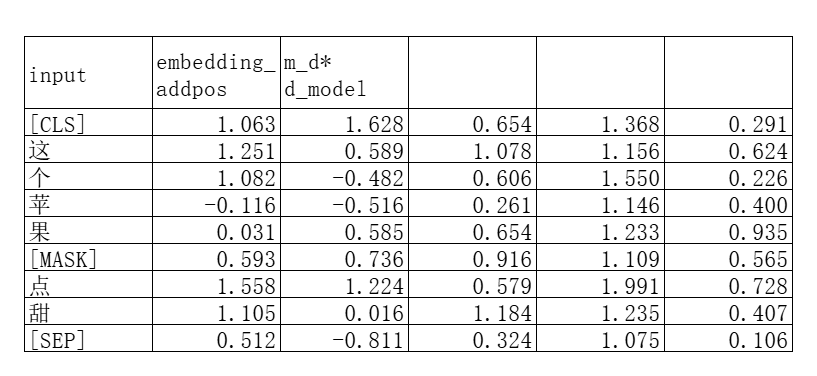
接着我们把这个序列输入BERT,也就是相当于输入了Transformer的Encoder。因为是一模一样的我这里就不再赘述了。
假如模型输出的**“浓缩了上下文的”嵌入矩阵**是下面这个样子:
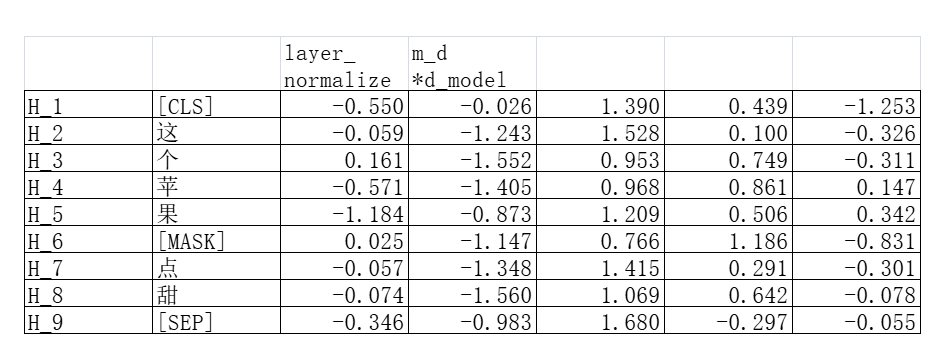
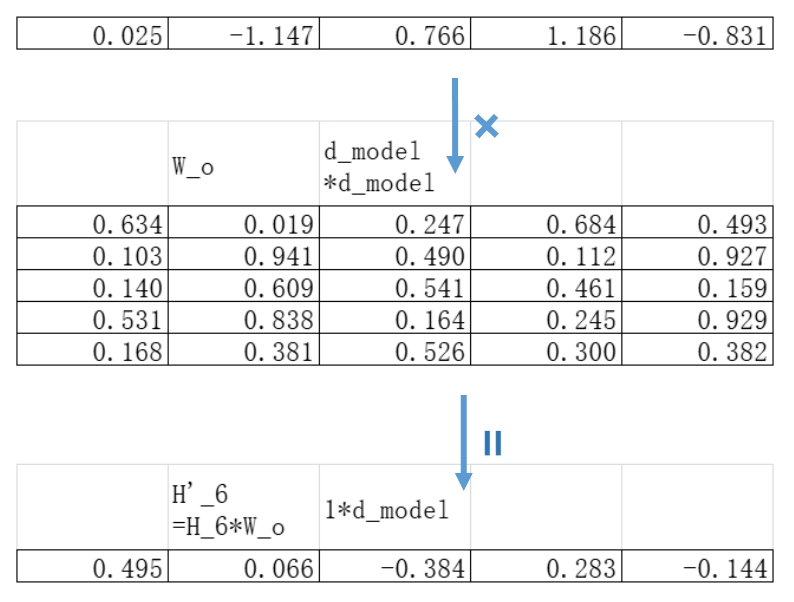
我们只需要取出最开始被遮挡的那个token的预测向量,也就是H_6的那个向量:
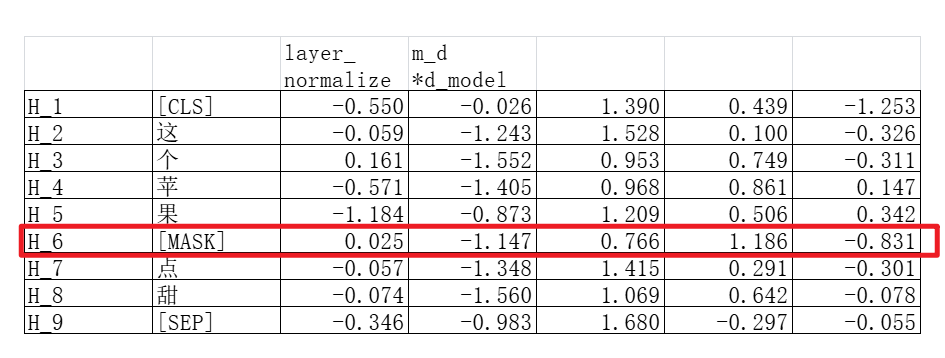
取出之后把这个H_6向量输入一个全连接神经网络。BERT里面这一层没有改变token的维度,在我们这个例子里面,也就是把H_6从5维向量转换到另外一个5维向量。我们假设这个用于转换的参数矩阵为W_o,则W_o的维度是5*5:
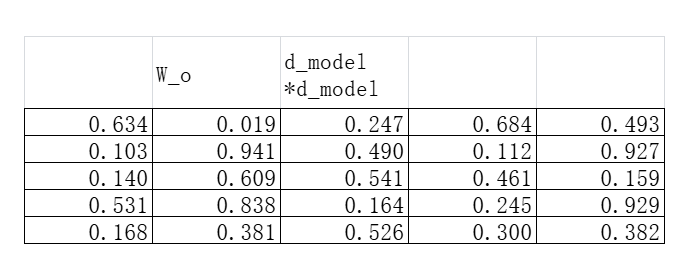
经过参数矩阵相乘,我们得到变换之后的H’_6:
变换之后的H’_6使用GERU函数进行激活。这个GELU函数的全称是 Gaussian Error Linear Unit。
简单来说,GELU可以被看作是著名激活函数ReLU的一个更平滑、更高级的替代品。它被用于解决ReLU函数引起的某些神经元可能永远不会被激活的问题(“死亡ReLU”问题)。
GELU函数的公式为:

其中P(Z<x)表示随机变量Z取值小于x的概率,随机变量Z是一个标准正态分布。假如要对0.495做GELU变换,那么:
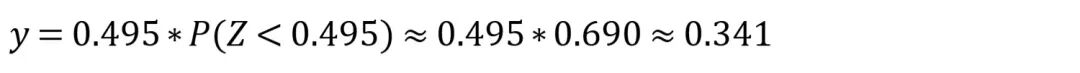
GELU的核心思想是用一个更“智能”、更“柔和”的开关来取代ReLU的硬开关。它引入了随机性的概念,决定一个神经元是否被激活(即信息是否通过)应该是一个概率性事件。
H’_6经过激活之后为:

经过激活函数,后面还有一个LayerNorm(层归一化)。(层归一化是为了减少经过深度传播之后的数据分布偏移,详细的分析可见Transformer encoder那篇文章)。

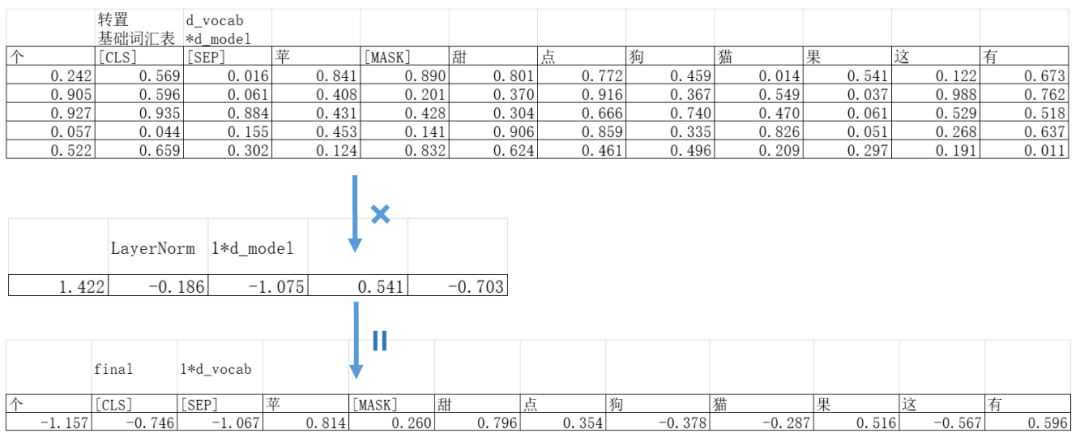
现在我们得到了处理后的新向量,BERT没有使用神经网络把这个新的向量映射到基础词汇表,而是直接把这个“新向量”和“基础词汇表里面所有向量”做了点积。
我们前面说过,向量的点积(在向量都标准化之后)可以认为是两个向量相似度的一个衡量指标。
这个操作相当于拿着一个“模板”与箱子里所有的物品做比较。哪个物品越接近这个手里的“模板”,哪个物品就更大概率是模型认为的应该出现的东西。
假如我们的基础词汇表里面包含的token仅仅有12个——“{这、个、苹、果、有、点、甜、猫、狗、CLS、MASK、SEP}”;并且它们的词嵌入如下,用d_vocab来表示词汇表中单词的数量:
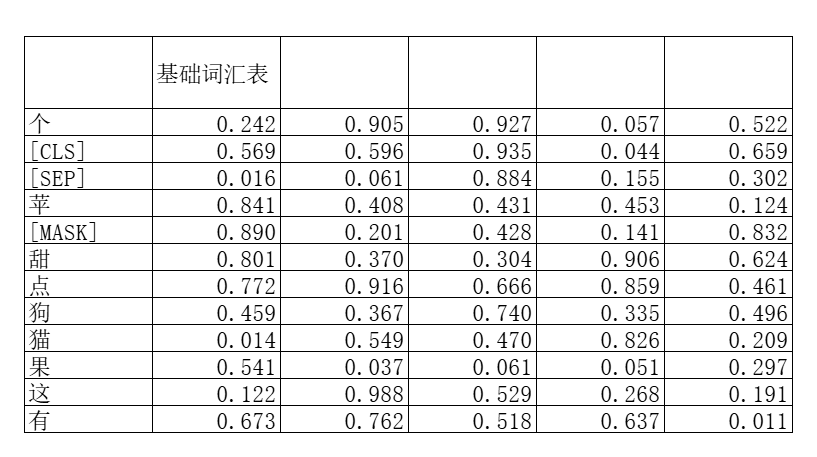
那么进行点积之后我们就得到一个d_vocab维度的向量,这个向量的每个维度是模型预测的对应token出现的“分数”。
这个分数有点抽象,学者们就会把“分数”套入一个Softmax函数,转化到0-1之间,可以看成是每个token在当前位置出现的概率:

像是这里模型预测最高概率出现的是“苹”,但我们的正确答案是“有”,这点就要通过计算损失函数并且利用反向传播去调整模型参数来修正了。BERT的损失函数也是老熟人“交叉熵损失函数”。
到这里BERT的整个训练阶段就介绍完了。
RAG论文中,作者直接使用了BERT论文(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)中已经训练好的BERT_base模型来对于用户的Query和知识库文章进行编码,然后再依据自己的任务微调参数。
注意这里RAG的Retriever使用的是中间产物,就是H_6向量经过全连接神经网络+LayerNorm处理之后的那个向量。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
六、MIPS:从Query到知识库文章
上面提到了“知识库文档”也是使用BERT模型进行编码的,但是这个“知识库文档的编码”还有一些特殊的地方。
在论文中,使用的是“维基百科2018年12月导出版本”。论文把这些维基百科条目按照**“100个词语”进行切分**,形成了2100万“文章”(用文章来表述似乎有些夸张,理解成“小片段”更加合理)。每个“文章”进行一次编码。
论文中选择100个词作为一个固定的“块”(chunk),在当时是一个简单而有效的做法,但存在许多可以优化的地方。这个选择本身就是一个典型的权衡(trade-off):块太小会丢失上下文,块太大则可能引入过多无关噪声,后面也有很多研究优化了这个切分方法。
我们现在把用户的Query和知识库的文章都从“人类可以理解的字符”变成了“密集表达向量”。那么下一步就是:要怎么把“Query”和知识库的文章用一种非常高效简洁的方式匹配在一起,这种匹配的高效程度决定这个搜索过程的性能如何。
既然我们在做Query Encoding的时候,有意让模型学习了把“问题”和“答案”的embedding向量变得尽量接近,那么在做“检索”的时候,当然要利用这个特性——所以这个检索匹配的问题就变成了“怎么迅速在一大堆向量中找到和Query的嵌入向量**‘最近接的’**代表知识库文档的向量”。
向量的“相似性”可以利用**“向量的点积”来度量,于是这个检索问题就被转化为了“MIPS(Max Inner Product Search,最大化内积搜索)**”。
我们可以这样来表示:我们的目标是“找到与问题向量q(x)最相似的文档向d(z),就是找到使得d(z)ᵀq(x)最大的d(z)。”这就是一个 MIPS 问题。
我们前面说了论文总共准备了2100万“小片段”,暴力求解(计算所有向量的内积)是不可行的,需要一些其他技巧。
学者们研究出来很多种算法来优化检索效率,Facebook AI构建了一个开源工具库FASSI,里面打包了很多解决MIPS问题的算法工具,它通过一系列创新的“索引(Indexes)”方法,让这个原本非常耗时的任务变得异常高效。
RAG论文就是直接调用了FASSI里面的工具来构建了**文档索引(Document Index)**便于搜索。
这里介绍FASSI里面一个经典的用于构建索引的办法——**IVFADC(Inverted File system with Asymmetric Distance Computation)。**让大家理解索引在干什么,以及为什么索引可以优化查询。
要详细理解IVFADC,我们需要将它拆解成两个核心技术:倒排文件索引(Inverted File Index,IVF) 和乘积量化(Product Quantization, PQ)。
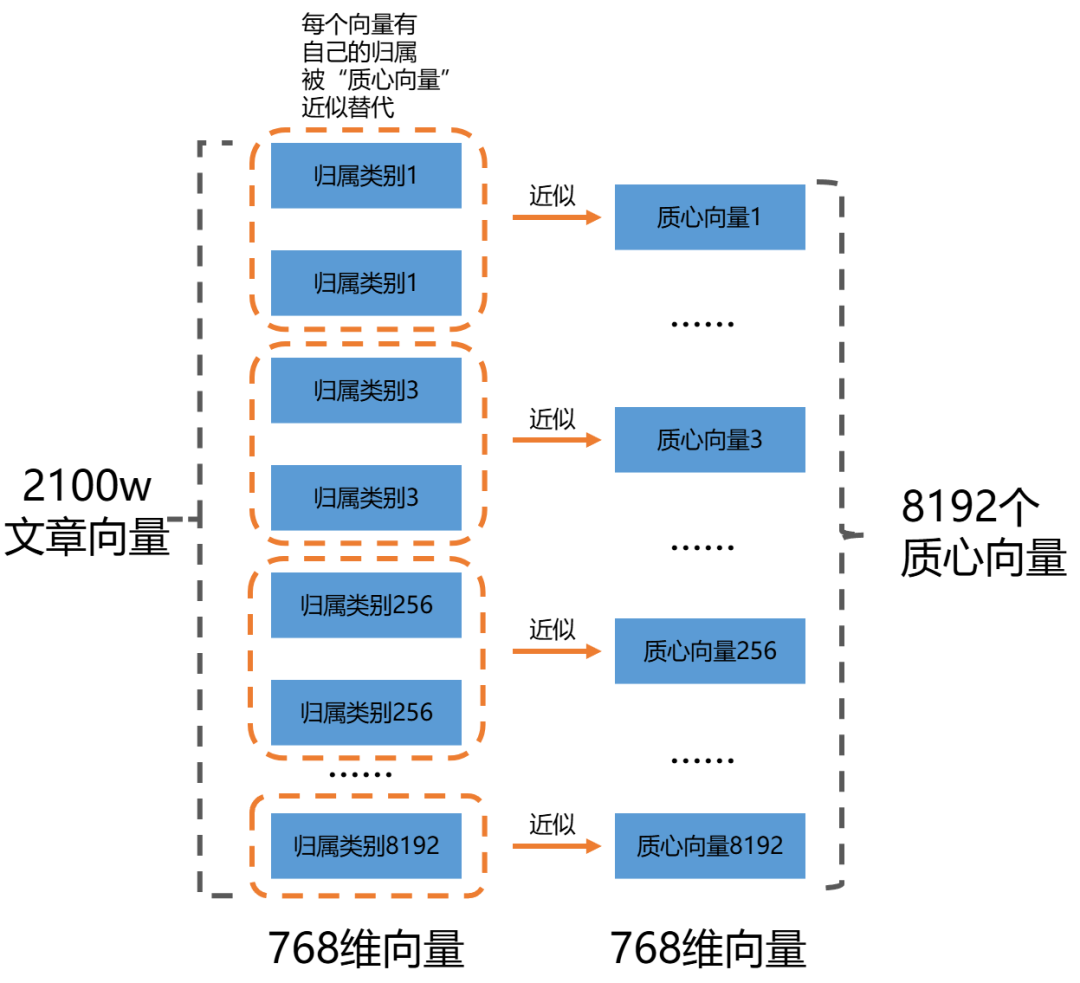
倒排文件索引的核心思想是:先把知识库文章分类成为K个类别,用K个向量来近似代替每个类别。这样在检索的时候,先把用户的Query和K个类别向量做比较,找到比较接近的几个类别,再进入这几个框定的类别内部进行更加细致的搜索。
说白了就像是我们到图书馆去借阅书籍,我们可以先看书籍的大类别“人物传记”,然后到摆放“人物传记”的书架上去寻找。
我们把已有的资料进行“分类”,然后把每个“分类”编上号,记录下每个向量的类别归属,和用于近似每个类别的“类别向量”,这就形成了一个**“倒排索引”**。
之所以叫“倒排”是因为我们是依据“关键词(也就是用于近似类别的质心向量)”来找“文章”,而不是依据“文章”来找“关键词”。
那么要使用什么办法把知识库文章进行分类呢?别忘了我们已经把知识库文章都变成密集向量了,这个问题就是**“如何把一堆向量进行聚类”**——就可以使用各种“聚类算法”了。
比如经典的**“K-means”**聚类算法:
第一步,先假定所有的向量可以被分为K个类别,这个K值是一个超参数,是人为指定的。
第二步,在样本中随机找到K个点作为质心,记录它们的坐标。
第三步,计算所有样本到这K个点的距离,把每个样本分到最近的“质心”代表的那个类别。比如样本A距离质心1最近,那么样本A就被划归为“质心1代表的类别”。
第四步,把所有样本归类完成之后,重新计算每个类别的“质心”,更新“质心”坐标。比如样本A、B、C都被归类为“质心1代表的类别”,那么重新计算样本A、B、C的坐标平均值,就产生了这个类别的新“质心”坐标,类别1的“质心坐标”被更新为“(A+B+C)/3”。
第五步,回到第三步重新计算所有样本到K个质心的距离,再次把所有样本点重新归类。如此循环,直到达“质心”坐标更新量很小,或者是循环的次数达到人为设定的门槛值。
这样能够使得每个类别“质心”的向量,能够近似表达出这个类别的特征。
当用户的Query到来的时候,把用户Query向量跟“质心”向量做点积,就能够极大缩小查询范围。比较一下,我们有2100万的“文章”,如果把它们归类成为8192个类别(2^13=8192),是不是计算量一下子小了很多?
只是这个K值的选择也是一种“艺术”,要在“减小计算量”和“精确检索”之间做出权衡。
IVFADC中另外一个核心技术是乘积量化 (Product Quantization, PQ)。乘积量化是一种压缩向量的算法,为了解决有的向量“高维度,高精度**,占用内存太多的问题**”。
像是BERT模型使用了768维向量来表达一个token,假如每个维度使用浮点数(float32)来表达,每个浮点数需要占用4个Bytes。那么储存一个768维度的向量需要占用空间约3KB:
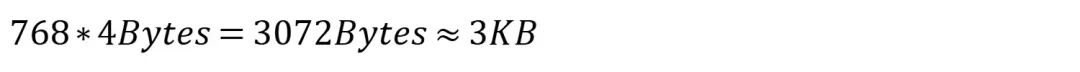
一个2100w的知识库需要占用空间约60.08GB:
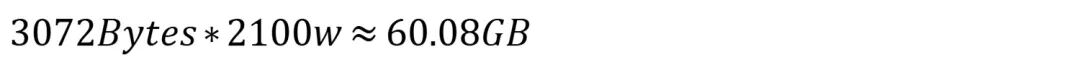
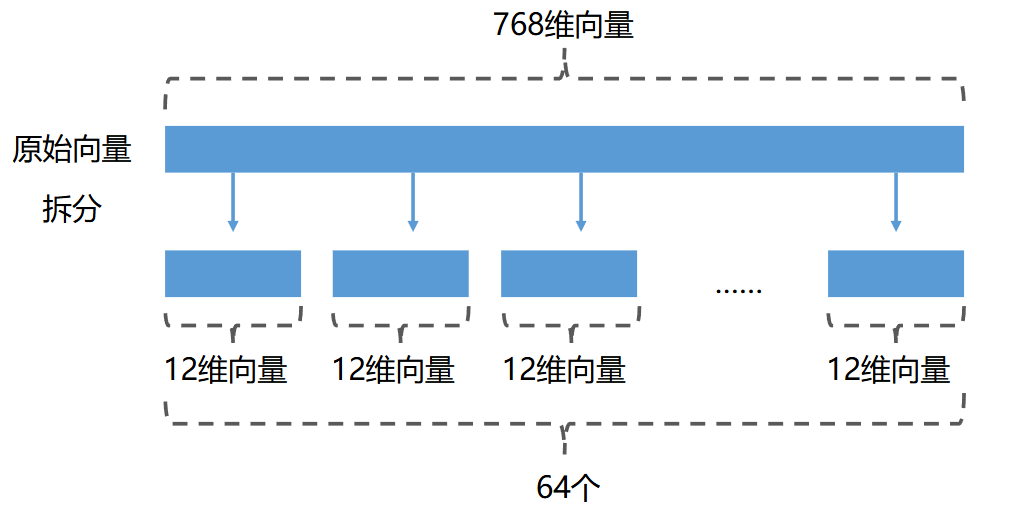
乘积量化的办法是要把一个完整的向量拆分成为N段,拆分之后的每一段用一个“质心向量”来进行近似。这样就能够把巨大的向量的“分而化之”。
继续使用上面的例子,假如我们把一个768维向量分成64段,每一段就会是一个12维的向量。这里的64段虽然段数比较多,但是能够保证每个子向量的维数比较低,提高查询精确度。
2100w知识库向量,我们把所有向量的第一段拿出来,做K-means聚类,分成256个类别,得到了256个**“(第1段的)质心向量”**。
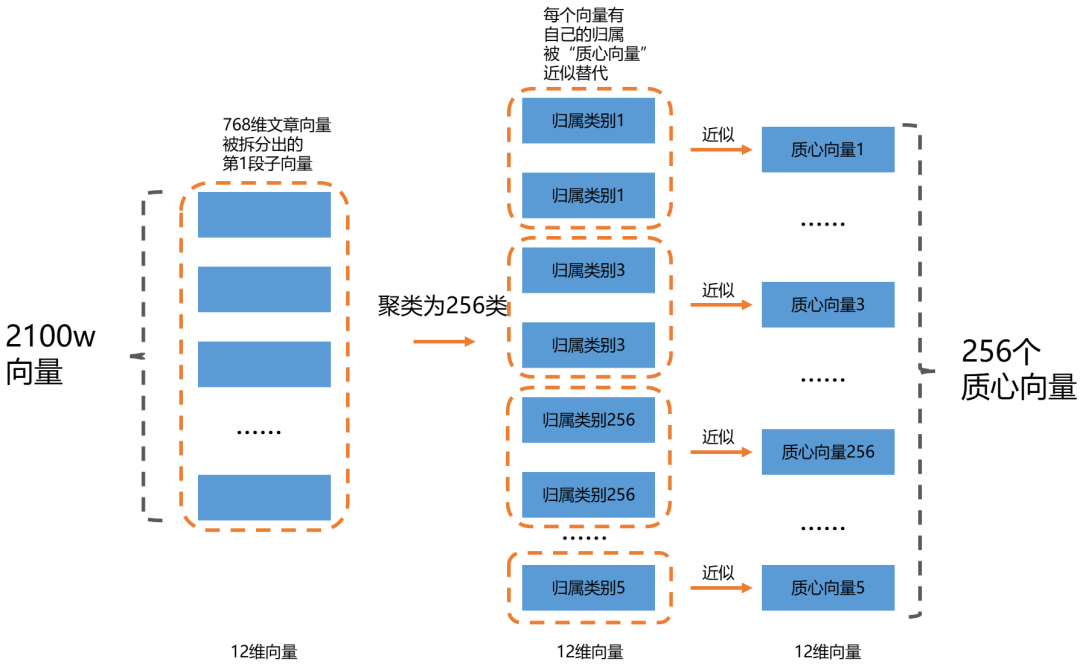
把剩下的7段也用同样的办法做聚类(所有2段跟2段聚类,3段跟3段聚类…以此类推),向量的每一段都各自被聚类好。
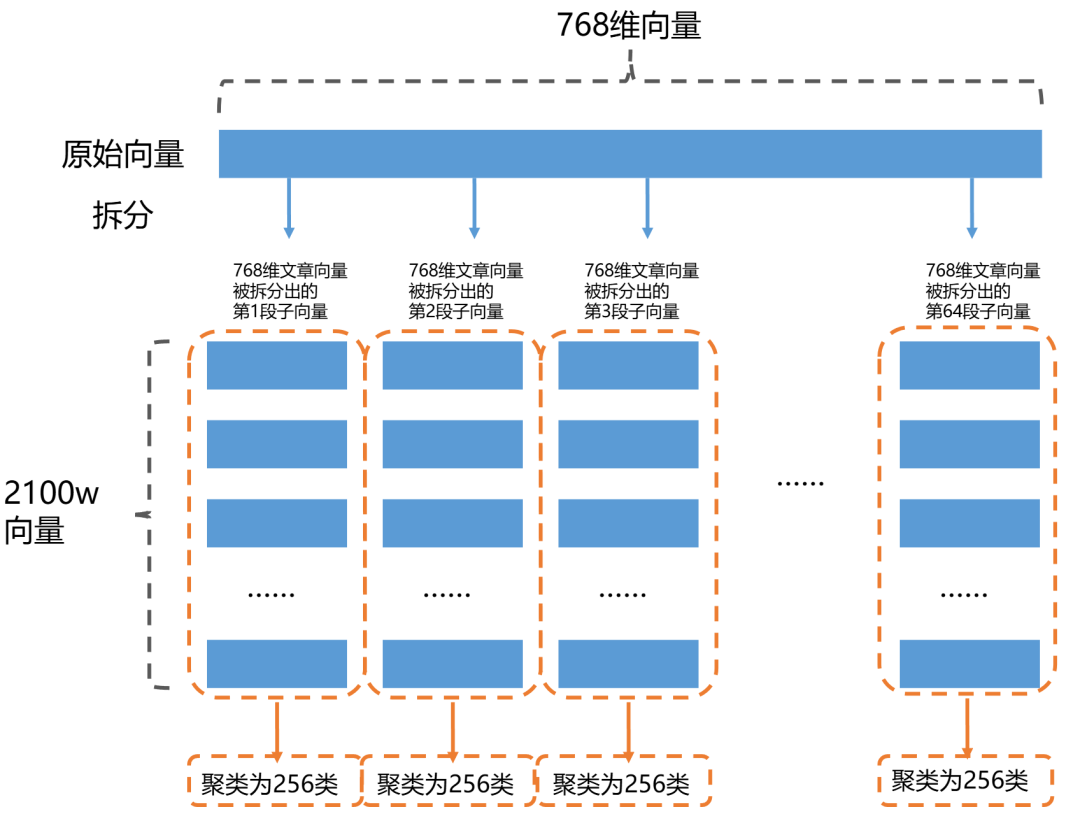
现在我们的数据量变成了下面这个样子:
对于每一个分段向量来说,质心的编号是0到256,这个编号可以使用8 bits表示出来(2^8=256)。
768维向量被分成了64段,每段用一个**“质心编号”**来替代。
一个768维的向量就被64维编码替代。
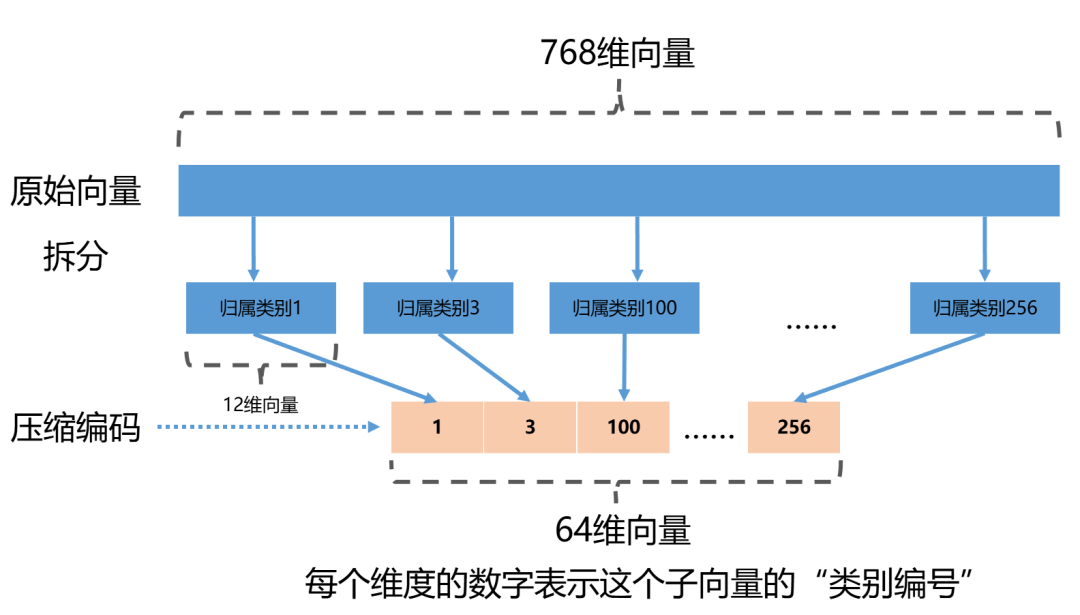
原先768维向量需要3072Bytes空间来储存,现在只需要占用约64Bytes空间:

一整个知识库也只需要1.252GB:

我们还有一张“密码表”,这个“密码表”记录着所有的质心向量,充当着解码的功能。质心向量12维,每个维度精度32bits,1个向量分段有256个质心向量,总共有64段,总占用空间还不足1MB:
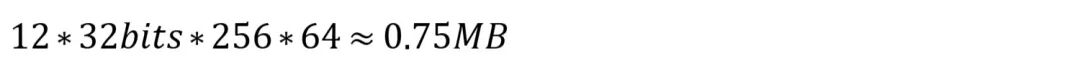
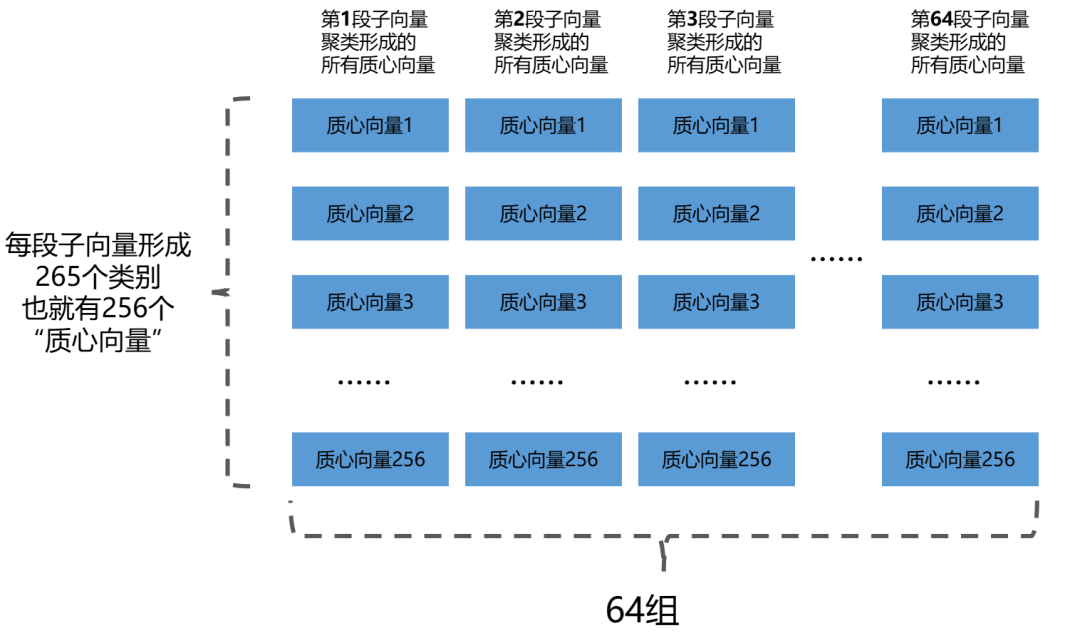
把所有数据加起来,所占内存约为1.252GB,虽然这是一个非常粗糙的模拟,但是可以看出压缩后的信息内存占用远远小于原先的60.08GB。
这里出现了很多参数,它们的选择影响IVF(倒排索引)和PQ(乘积量化)两个阶段的查询效率。
实证数据建议是这样的:使用IVF粗筛的阶段,聚类数量在4*sqrt(N)与16*sqrt(N)之间,其中N是数据集的大小。而使用PQ进行精细化查询的阶段,聚类数量一般都选择256维。
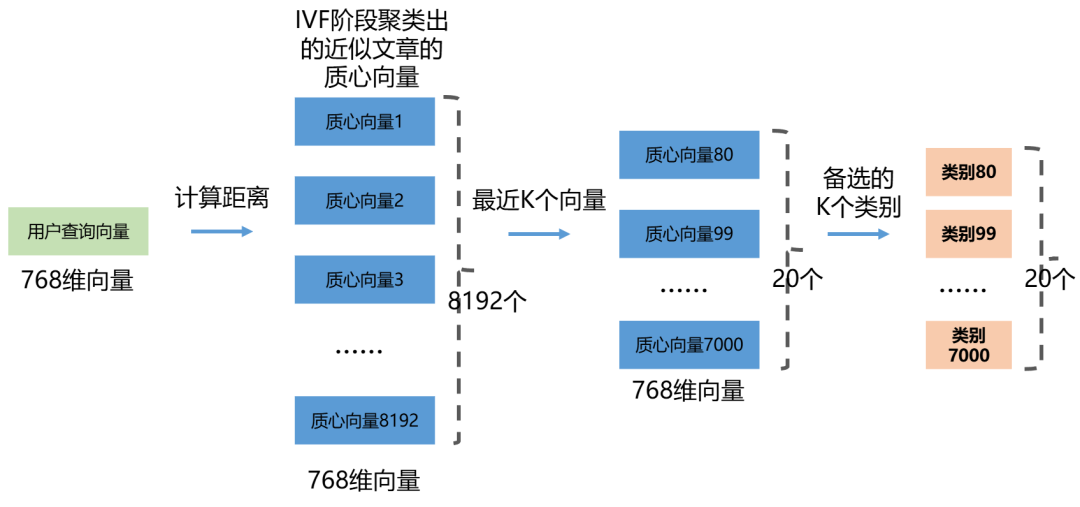
当一个用户Query来了之后,我们会先把IVF(倒排索引)阶段聚类出来的8192个质心向量拿出来与它做比较,找到最相似的K个质心向量,也就是选中了K个类别的文档作为参考。
假如K=20,意味着我们的备选文章大概有5万篇(2100w/8129*20)。
注意我们已经把这5万篇文档利用PQ(乘积量化)压缩成为了5万个64维的编码。我们接下来就要在这5万个向量中找到“距离查询向量最近”的N个,相当于返回了N篇查询文章。
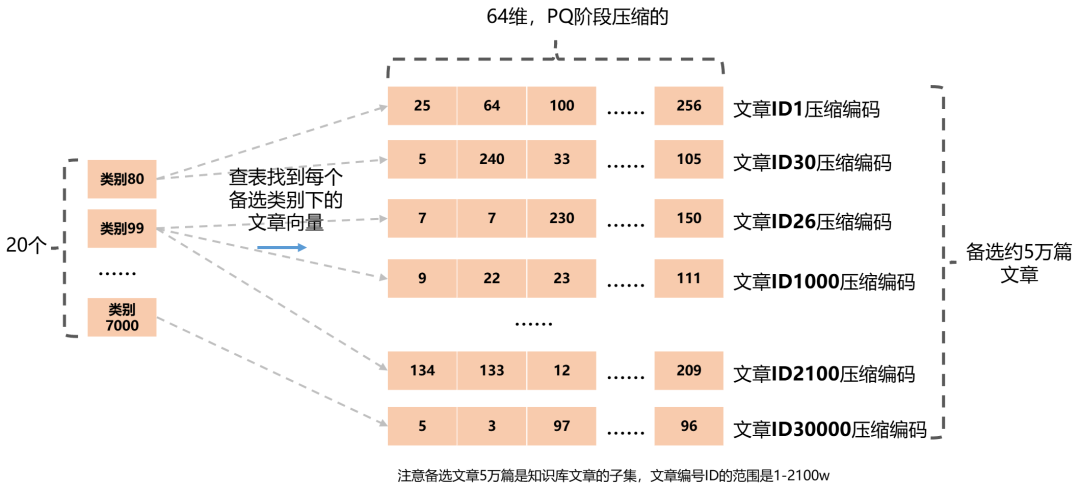
怎么比较这5万个向量与查询向量之间的距离呢?不是遍历精确的硬算,而是直接利用PQ阶段聚类的质心向量来近似计算。
我们把这个768维的用户查询向量也按照PQ阶段的拆解方法分为64段。
每一个向量分段分别计算到“256个‘PQ质心向量’”的距离,这个过程会生成一个64*256的距离查找表。这个表计算一次后会反复使用。
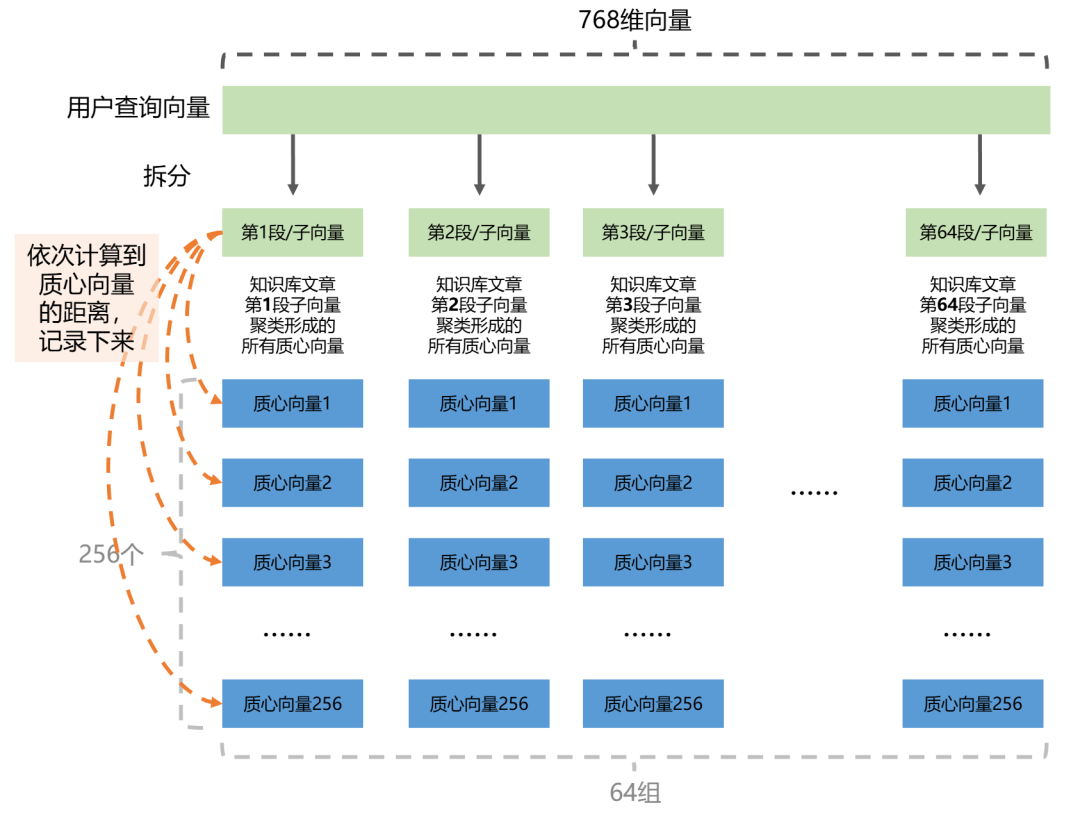
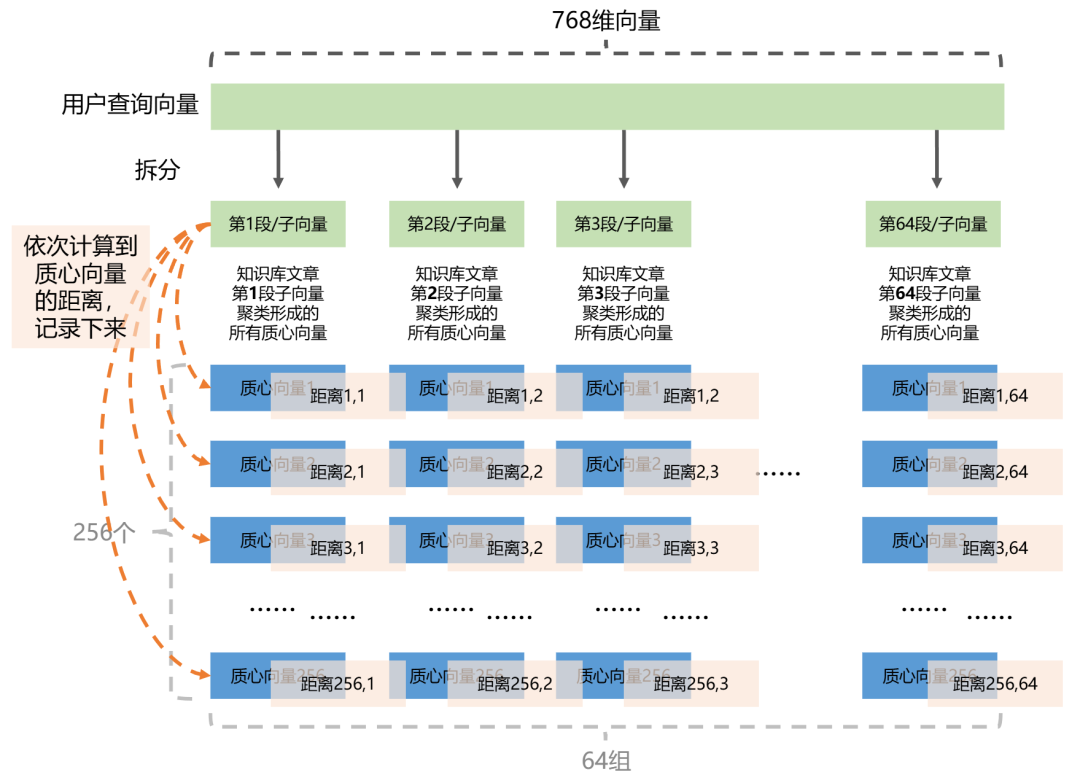
假如对于备选文章1来说,它的第一分段归属质心25,我们就找到“查询向量第1分段与质心25的距离”;它的第二分段归属质心64,我们就可以找到“查询向量第2分段与质心64的距离”…
直到找完64个分段的距离,把这64个距离加在一起,就是“备选文章1整体”与“查询向量”的近似距离。
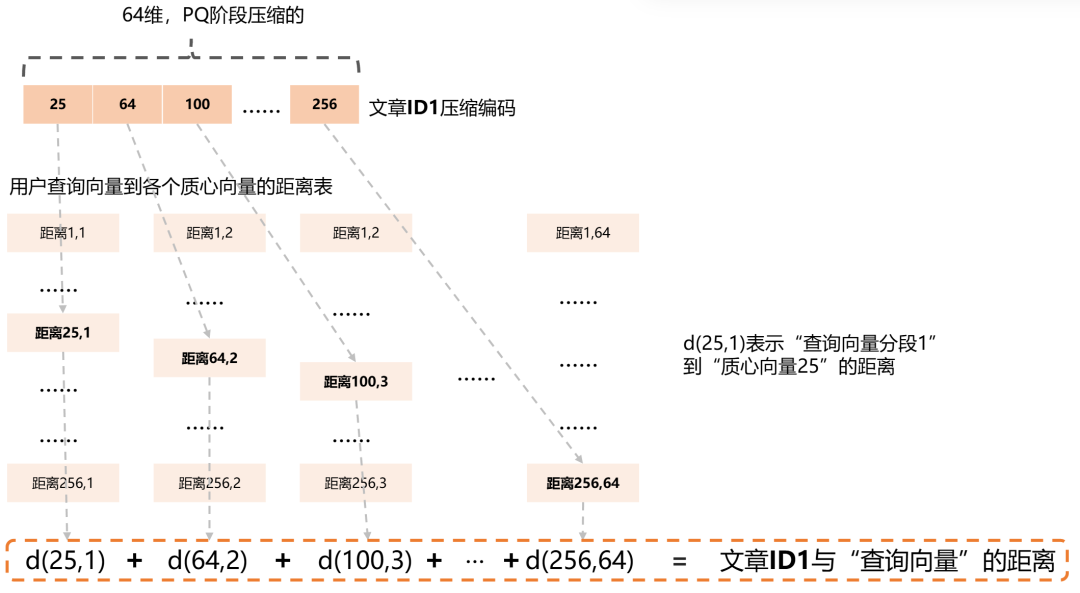
计算出“5万个备选文章”与“查询向量”之间的距离,就可以进行排序,并且找出“最近的”N篇文章进行返回了。

这就是“近似距离计算”的全部魔法:它通过一次性的预计算,将成千上万次昂贵的、高维的向量距离比较,转换成了成千上万次廉价的、简单的查表和加法操作。
整个知识库的索引都是可以**“提前处理好储存下来的”**,真正需要“即时计算的”只有跟“用户Query”相关的部分,这极大减轻了线上响应的压力。
RAG论文调用了FASSI工具库来提前构建了知识库文档索引(Document Index)。Query Encoder和向量数据库/索引共同组成了RAG的Retriever部分。
不过有意思的是,Retriever使用了密集向量表达返回了查询文章的ID之后,RAG会把这些文章的“本体”查表恢复出来,然后把这些文章的“本体”喂给下游的Generator进行生成。
我也产生过疑问,本来都费劲心机把一篇知识库文章编码成为一个密集向量了,为什么查询出来反而要退回到“本体状态”再给下游呢?
请教了一下Gemini老师,TA是这么回答的:因为第一阶段的**“检索”和第二阶段的“生成”两个“目的”**本质要求不同。
在“检索”阶段,我们希望找出来的“资料”跟“问题”紧密相关,这需要对于“问题”和“知识库文章”都有很深的“理解”能力,才能够顺利的把两者进行匹配。而BERT恰巧是这样一个为了“读懂/理解”而生的模型。
利用BERT生成的浓缩型密集向量,本质上是知识库和查询问题信息的一种压缩,它是一种概括,这种压缩一定会损失掉细节。
比如“黑神话在2024年8月20日发售”这句话,在压缩过后可能变成了“黑神话在24年发售”。这种压缩在**“捞取相关资料”这个阶段是“有利的”,因为能够辅助我们找到更多的“相关资料”,但是在“回答问题”的阶段就不合适了**。
假如用户的问题恰好是“黑神话在具体的哪一天发售?”——就需要回到这句话的本体去寻找答案,只看压缩向量的信息可能就回答不了。
压缩后的文本向量就像是图书馆里的图书卡片或索引。卡片上有书名、作者、主题分类号和一小段内容简介。你可以通过快速浏览这些卡片,找到与你研究主题(你的问题)最相关的几本书。这个过程就是检索。
原始文本就是书本本身。它包含了所有的细节、论据、引文、专有名词和完整的故事情节。
Generator的角色是一位需要写论文的学生。TA使用图书索引(向量)找到了N本最相关的书(文档)。现在,要写出高质量的论文,他需要回到“原始文本”进行阅读。
七、小结
我们现在来回顾一下,RAG想要把“参数记忆”和“非参数记忆”结合在一起给模型使用,这样不仅能够及时更新模型所拥有的知识,还能够增强模型回答的可解释性,并且减少模型的幻觉。
RAG设计了一个Retriever,这个Retriever又被分为两个模块:负责把用户Query和知识库文章进行“编码”的Query Encoder;负责把用户Query和知识库文章向量高效匹配在一起的Document Index(文档索引)。
为了能够更好的找到和用户Query相关的“资料”,RAG使用了BERT来做“编码”,这本质上是寻找一种“密集向量表达”,这种“密集向量表达”使得“问题”和“对应答案”在高维空间中的位置非常接近。从而把检索问题,变成了在高维空间中寻找“相似向量”的问题(MIPS)。
相比于传统使用TF-IVF和BM 25来进行的检索,这种在“密集表达下”的检索,能够更好地“理解语义”,能够进行“模糊搜索”,从而在挖掘相关资料方面表现得更加优秀灵活。
不过我们需要注意的是,在实践中一般会使用混合的方案,把传统检索和密集检索给结合在一起,找到一种“高效”和“周全”,“精准”和“模糊”之间的平衡。
要解决“怎么迅速在一大堆向量中找到和Query的嵌入向量**‘最近接的’**代表知识库文档的向量”这个问题,有一个开源工具库FASSI可以调用,它附送了多种算法来巧妙的构建“索引”,从而优化在检索时的效率。
其中很经典的一种算法叫做IVFADC(Inverted File system with Asymmetric Distance Computation)。它的核心思想是:把搜索分为两个阶段——利用倒排索引来初步筛选跟Query相关的备选文章;利用乘积量化来完成精细的文章筛选。
乘积量化不仅压缩了高维高精度向量占用空间,还把极其繁琐和巨大的内积计算工作转换成为了“提前的运算”和“高效的查表工作”,很好的减轻了实时计算的压力。
RAG利用Retriever找到最可能作为用户Query参考资料的知识库文章,把这些文章和用户的输入一起传递给下游的Generator模块生成答案,关于下游的工作我就放在下面一篇文章来介绍啦~
祝愿我们都享受learning~
AI大模型学习和面试资源
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 14
14 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)